CAD 데이터에서 가장 원초적이면서도 가장 난도가 높은 작업이 바로 텍스트를 읽어내는 일이다.
CAD PDF를 열어보면 텍스트가 잘 보인다. 폰트도 있고, 치수도 잘 보이고, 주석도 있다.
그런데 막상 이걸 프로그램으로 읽어보려고 하면 금세 현실을 맞닥뜨린다. 도면 속 텍스트는 텍스트 객체일 수도 있고, 그냥 픽셀 형태로 그려진 이미지일 수도 있다.
즉, 어떤 PDF는 복사가 되지만 어떤 PDF는 복사가 되지 않는다. 결국 이미지로 저장된 텍스트는 OCR을 적용해야 하는 대상이 된다.
문제는 여기서부터다.
일반 문서 OCR은 비교적 잘 해결된 분야처럼 보이지만, CAD 도면에 OCR을 적용하는 순간, 바로 계단이 아니라 절벽을 마주하게 된다.
왜 그럴까?
이 질문에 답하기 위해 먼저 찾아본 논문이 L. Jamieson, 2024 의 서베이다.
그리고 이 논문은 한 가지 매우 중요한 사실을 짚어낸다.
“CAD·엔지니어링 도면은 OCR이 전혀 예상하지 못한 환경이다.”
도면을 단순히 ‘이미지가 포함된 문서’ 정도로 상상하면 안 된다.
여기서 텍스트는 문단의 일부도 아니고 문서 레이아웃 안에 정렬되어 있지도 않다.
오히려 ‘텍스트에 가려진 선’, ‘선에 가려진 텍스트’, ‘심볼인지 글자인지 구분이 안 되는 패턴’ 같은 것들이 도면 전체에 퍼져 있다.

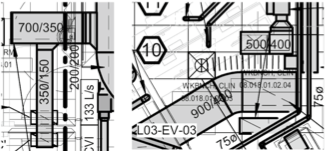
이게 OCR 면에서 보면 어떨까?
한 문장으로 요약하면, “기본 가정이 모두 깨진다.”
문서 OCR이 기대하는 “정렬된 줄배치, 일정한 방향, 단일 폰트, 여백 확보” 같은 조건이 도면에서는 하나도 만족되지 않는다.
오히려 도면에 존재하는 텍스트는 정렬되지 않고, 방향도 제각각이며, 선과 겹쳐서 모양이 찌그러져 있고, 서로 다른 크기와 폰트를 한 페이지 안에 섞어 쓰는 것이 자연스럽다.
엔지니어링 도면에서는 한쪽에는 “Ø150” 같은 기호 기반 텍스트가 있고, 바로 옆에는 “B3F MACHINE RM” 같은 긴 문자열이 있고, 그 아래에는 거의 눈에 보이지도 않을 만큼 작은 ‘치수 텍스트’가 붙어 있다.
게다가 도면의 배경은 텍스트 인식을 어렵게 만드는 요소로 가득하다.
치수선이 텍스트를 관통하기도 하고, 해칭 패턴이 글씨 위에 깔려 있기도 하고, 산업 도면에서는 점선이나 도형이 문자 “I”, “1”, “|”처럼 보이는 경우가 흔하다.
여기에 기관마다 도면 스타일이 다 다르기 때문에 공개 데이터셋조차 충분하지 않다.
즉, 기계학습 모델을 학습시키려면 데이터부터 직접 만들어야 하는 경우가 많다.
서베이는 이런 문제들을 소개하면서, 텍스트 검출(Text Detection)과 텍스트 인식(Text Recognition) 을 나누어 설명한다.
이 두 단계는 도면 OCR에서도 동일하지만, 적용 방식은 완전히 달라진다.
⸻
Text Detection — 텍스트가 있는 위치를 찾아라
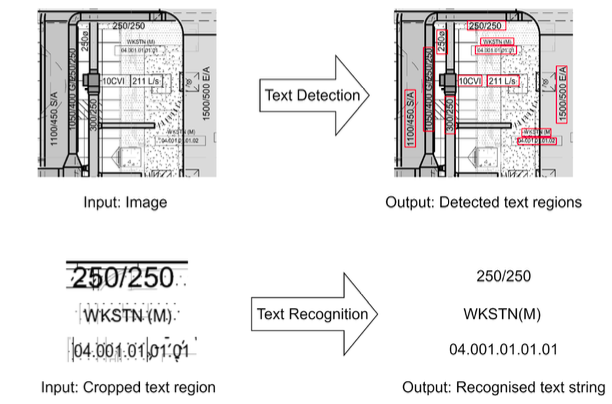
이 단계에서 우리는 도면 전체를 훑어서 “여기에 텍스트가 있을 확률이 높다”는 영역을 찾아야 한다.
딥러닝 이전에는 문자처럼 보이는 패턴을 규칙 기반으로 찾아내는 방식(HOG, MSER 등)이 존재했지만,
선과 기호가 밀집된 CAD 환경에서는 거의 작동하지 않는다.
그래서 최근 연구는 대부분 CNN 기반 검출 모델(CRAFT, EAST, CTPN)을 사용한다.
이 모델들은 “문자의 형태적 패턴”을 학습하기 때문에 텍스트가 회전되어 있어도, 크기가 달라도, 배경이 복잡해도 어느 정도 안정적으로 위치를 찾아낸다.
흥미로운 점은 객체 탐지 모델(YOLO, Faster R-CNN)도 텍스트 검출에 많이 활용된다는 점이다.
텍스트를 “문자 집합”이 아니라 “하나의 객체”로 보는 방식인데, 이 모델들은 텍스트와 심볼을 동시에 탐지하도록 확장할 수 있기 때문에 도면 전체 구조를 분석해야 하는 작업에서 특히 강점을 보인다.
Text Recognition — 이제 글자를 읽어라
텍스트 영역을 찾았다면 그다음은 문자열을 읽는 일이다.
Tesseract 같은 전통 OCR 엔진부터 CRNN, Transformer 기반 OCR까지 다양한 기술이 활용된다.
하지만 도면에서는 여기서도 문제가 발생한다.
문자가 회전되어 있거나, 일부가 선에 가려져 있거나, 도면 특유의 코드 형식이 섞여 있기 때문이다.
그래서 많은 연구가 후처리(Post-processing) 단계에 공을 들인다.
오인식된 문자(I ↔ 1 ↔ | 등)를 교정하거나, 도면에서 자주 등장하는 코드(A-05, Ø150 등) 패턴을 다시 맞추고, 텍스트의 회전이나 좌표를 재보정하는 과정이 꼭 필요하다.
⸻
CAD 도면 OCR은 “문서 OCR과 전혀 다른 세계”
L. Jamieson(2024)의 서베이를 읽고 가장 크게 와닿은 건 바로 이 부분이다.
도면은 문자 기반 문서가 아니다. 텍스트가 중심이 되는 문서를 OCR로 처리하는 것과, 기하·기호·레이어·곡선·치수·주석이 모두 섞인 도면을 OCR로 처리하는 것은 애초에 완전히 다른 문제다.
도면에서 텍스트를 찾는 과정은 글자를 읽는 문제라기보다, “복잡한 그래픽 속에서 텍스트라는 개념을 구별해내는 문제” 에 가깝다. 그래서 최근 기술들이 모두 딥러닝 기반으로 이동하고 있고, 객체 검출 모델과의 결합, 후처리 규칙의 도입 등 하이브리드 접근이 기본이 되어가고 있다.
이 논문은 그런 흐름을 한눈에 정리해주기 때문에 CAD–BIM 연계를 위한 텍스트 파이프라인을 설계하기 전에 “어떤 기술이 어떤 한계를 가지고 있고, 어떤 조합이 필요한지” 전체 숲을 보게 해주는 중요한 기준이 되었다.
⸻
출처
Deep learning for digitisation of engineering drawings and diagrams” (L. Jamieson, 2024, AI Review)
