CAD·BIM 연계를 위해 OCR 기술을 조사하기 시작했을 때, 처음 마주한 인상은 “생각보다 훨씬 넓고 깊은 분야구나”였다.
텍스트를 읽는 일은 너무 기본적인 문제처럼 보이지만, 실제로는 컴퓨터 비전과 NLP가 동시에 얽혀 있는 복합적인 영역이다.
그 복잡한 판을 가장 잘 정리해준 논문이 바로 Deshmukh et al., 2025의 서베이다.
이 논문은 “이미지·PDF 기반 텍스트 추출 기술의 전체 흐름”을 아주 현실적인 관점에서 설명하고 있다.
특히 개발자 입장에서 현재 기술이 어디까지 가능한지, 그리고 어디서 막히는지가 잘 드러난다.
1. OCR 기술의 현재 한계
가장 먼저 논문이 지적하는 것은 “기존 OCR의 태생적 한계”다.
우리가 흔히 알고 있는 Tesseract 같은 전통 OCR 엔진은 깔끔한 문서에서는 잘 작동한다.
하지만 조금만 현실적인 상황이 되면, 예를 들어
• 해상도가 낮거나
• 글자가 기울어져 있거나
• 폰트가 특수하거나
• 문서 레이아웃이 복잡하거나즉, “문서가 실제 인간이 사용하는 문서처럼” 복잡해지기 시작하면 정확도가 급격히 떨어진다.
이 때문에 최근에는 CNN 기반(예: CRAFT, EAST) 모델이 기본 선택지가 되었고,
Transformer 기반 모델(TrOCR, LayoutLM)까지 등장하면서 텍스트 자체뿐 아니라 레이아웃, 구조, 문맥을 함께 이해하는 방향으로 진화하고 있다.
하지만 이것도 완벽하지 않다.
논문에서는 특히 다음 네 가지가 여전히 어려운 지점으로 남아 있다고 말한다.
• 여러 언어가 뒤섞인 문서
• 손글씨
• 표(table) 같은 레이아웃 유지
• 저화질 스캔그래서 결론은 명확하다.
앞으로의 발전은 이미지 + 텍스트를 함께 이해하는 멀티모달 Transformer 모델이 이끌게 될 것이라는 것.
단순히 “글자를 읽는 기술”은 이미 충분히 발전했고, 이제는 “문서를 이해하는 기술”로 넘어가는 단계라는 이야기다.
⸻
2. 텍스트 검출(Text Detection)
텍스트 추출의 첫 단계는 텍스트 영역을 찾는 것이다.
이게 생각보다 더 어려운 이유는, 텍스트라는 것이 문서 안에서 일정한 규칙을 따라 배치되는 것이 아니기 때문이다.
특히 이미지 기반 pdf에서는 텍스트와 배경이 뒤섞이며, 패턴조차 일정하지 않다.
초기 방식들은 대부분 사람이 만든 규칙에 기대고 있었다. Stroke Width Transform(SWT), MSER, Edge detection처럼 “문자처럼 보이는 패턴”을 찾는 방식이다.
이런 방식은 빠르지만 배경이 조금만 복잡해지면 바로 무너진다.
그래서 엔지니어링 도면, 스캔 문서, 잡음이 많은 데이터에서는 거의 쓸 수 없다.
딥러닝 기반 모델의 등장 이후 상황이 완전히 달라졌다.
• CTPN은 문장을 세로로 쪼개 단위 블록으로 찾음
• EAST는 단일 네트워크로 텍스트 영역을 실시간에 가깝게 검출
• CRAFT는 문자를 구성하는 영역(affinity)을 학습얇은 글씨, 기울어진 글씨, 크기가 극단적으로 다른 글씨까지 안정적으로 찾아낸다
텍스트가 회전되어 있든, 크기가 작든, 배경이 복잡하든 이 모델들은 “텍스트의 특성을 이해하는 방향”으로 학습된다.
논문이 말하는 핵심은 간단하다.
텍스트 검출은 더 이상 규칙 기반으로는 불가능하고, 딥러닝 기반 모델이 사실상 표준이 되었다는 것.
⸻
3. 텍스트 인식(Text Recognition)
텍스트 검출이 “어디에 글자가 있는지 찾는 과정”이라면, 텍스트 인식은 “그 글자가 무엇인지 읽는 과정”이다.
Tesseract는 오랫동안 사실상 표준이었지만,“정확히 인쇄된 문서”를 기본 가정으로 설계된 만큼 회전, 흐림, 작은 글씨, 복잡한 배경에는 약하다.
이 한계를 보완한 것이 CRNN 같은 딥러닝 기반 OCR 모델이다.
특히 CNN + RNN 구조는 이미지에서 패턴을 추출하고 문자열 순서를 자연스럽게 모델링해 내면서 Tesseract보다 훨씬 탄탄한 결과를 보여준다.
가장 최근의 흐름은 Transformer 기반 OCR, 대표적으로 TrOCR이다.
이미지에서 글자 패턴을 추출하고, 그 패턴을 시퀀스로 변환해 문자열을 생성하는 과정 자체를 Transformer가 담당한다.
문서 형태가 깨져 있어도, 해상도가 낮아도 비교적 안정적으로 읽어낸다는 점에서 “OCR의 판도를 바꾸고 있는 기술”이라고 볼 수 있다.
⸻
4. 문서 이해(Document Understanding) ― LayoutLM이 왜 등장했을까?
OCR에서 한 단계 더 나아가면, “문서를 읽는” 문제가 등장한다.
예를 들어 다음처럼 문서 구조를 이해해야 정보 추출이 가능해지는 경우가 있다.
• 표 안의 헤더와 셀 값 구분
• 주소 블록, 날짜 영역 식별
• 항목명과 수치 값 매칭이 단계에 등장한 것이 LayoutLM과 같은 레이아웃 이해 모델이다.
흔히 텍스트 + (x, y) 좌표 + 이미지 패치를 함께 학습하는 방식이다.
즉, 글자뿐 아니라 글자가 어디에 위치하는지, 그리고 그 주변에 어떤 시각적 요소가 있는지를 함께 학습하는 구조다.
레이아웃까지 모델이 이해하게 되면 단순히 문자열을 읽는 것에서 벗어나 “문서라는 구조 자체를 파악”할 수 있게 된다.
이것이 OCR 기술의 궁극적인 방향이기도 하다.
물론 이런 모델들은 대규모 데이터와 계산 비용이 필요하다는 단점이 있지만,
문서 이해 문제에 있어서는 확실히 기존 모델들보다 한 단계 위의 성능을 보여준다.
⸻
5. 논문이 제시한 텍스트 추출 파이프라인 흐름
이 논문은 텍스트 추출을 아래와 같은 전체 파이프라인으로 설명한다.
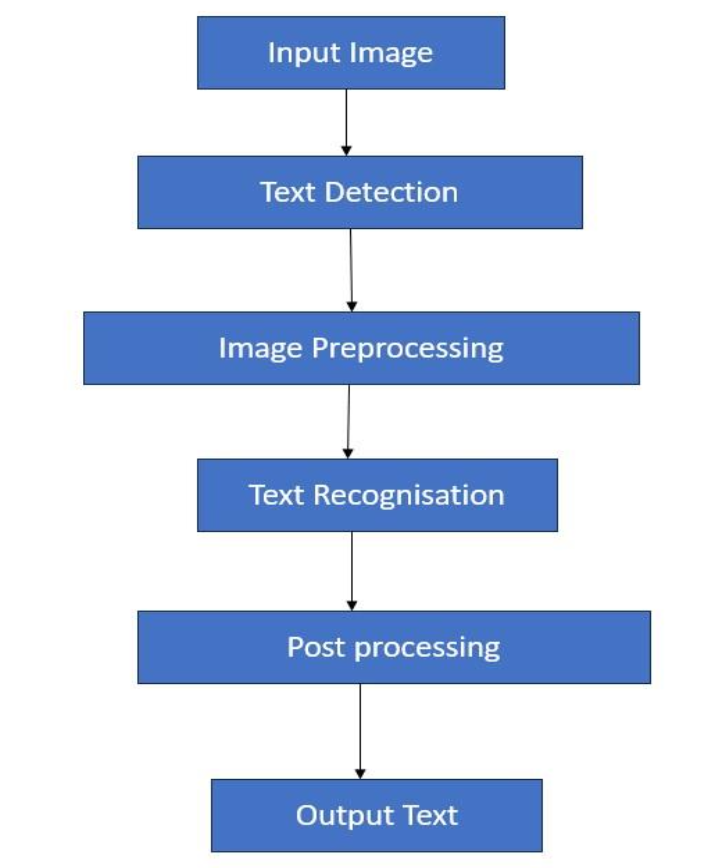
1) 전처리
문서의 품질을 모델이 읽을 수 있는 수준으로 정제한다.
흑백 변환, 노이즈 제거, Otsu 이진화, 기울기 보정이 포함된다.
2) 텍스트 검출
CRAFT/EAST 같은 모델로 텍스트 영역을 찾아낸다.
3) 텍스트 인식
Tesseract, CRNN, TrOCR 등의 모델이 문자열을 읽는다.
4) 후처리
맞춤법 보정, 규칙 기반 코드 교정, 레이아웃 기반 구조화(JSON/CSV) 생성 등이 이루어진다.
이 전체 흐름은 사실 CAD 도면 OCR에서도 거의 동일하게 적용되는 구조다.
특히 도면 특화 규칙이나 후처리 모듈이 강력해져야 한다는 점이 인상 깊다.
⸻
6. 결론 ― OCR은 “문자를 읽는 기술”에서 “문서를 이해하는 기술”로 넘어가고 있다
Deshmukh(2025)는 OCR 기술의 진화를 한 문장으로 요약한다.
“규칙 기반 → 딥러닝 기반 → 멀티모달 Transformer 기반”
전통 OCR은 깨끗한 문서에서는 여전히 의미가 있지만, 복잡한 문서나 CAD 도면 같은 비정형 데이터에서는 딥러닝 기반 방식이 압도적으로 우수하다.
그러나 딥러닝만으로도 해결되지 않는 영역들이 존재한다.
비표준 글꼴, 손글씨, 레이아웃, 표 구조 등은 여전히 도전 과제다.
그래서 논문은 미래 방향을 이렇게 제시한다.
텍스트와 이미지를 동시에 이해하는 멀티모달 Transformer 모델이 OCR의 다음 단계다.
CAD 도면 OCR 파이프라인을 설계하는 나 같은 개발자에게는 이 방향성이 매우 중요한 힌트가 된다.
단순히 “텍스트를 읽는 모델을 고르는 일”이 아니라 “문서 전체를 이해하는 구조”를 염두에 둬야 하기 때문이다.
⸻
출처
A Comprehensive Study on Text Detection and Extraction from Images and PDF Documents (Deshmukh et al., 2025)
