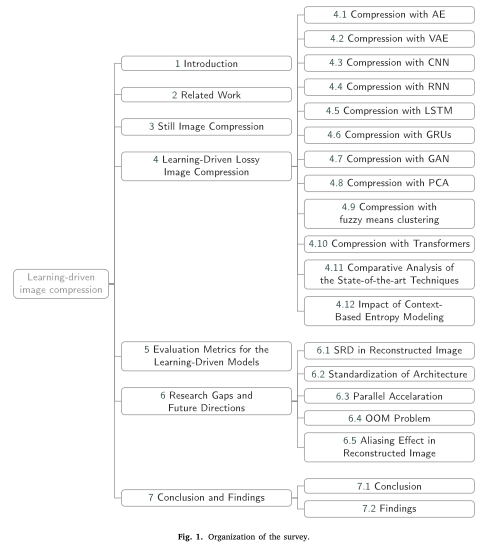
[Compression] Learning-driven lossy image compression: A comprehensive survey (2023)
Image Compression
인용수 : 2024년 5월 8일 기준
논문 제목
Learning-driven lossy image compression: A comprehensive survey (2023)
https://www.sciencedirect.com/science/article/pii/S0952197623005456
인용수 : 32회
Abstract
ML 기반 이미지 압축 프레임워크의 하위 그룹은 다음과 같이 분류된다.
- Auto-Encoder (AE)
- Variational Auto-Encoder (VAE)
- Convolutional Neural Networks (CNN)
- Recurrent Neural Networks (RNN)
- Long Short-Term Memories (LSTM)
- Gated Recurrent Units (GRU)
- Generative Adversarial Networks (GAN)
- Transformer
- Principal Component Analysis (PCA)
- Fuzzy means clustering
Introduction
빅데이터 시대에 데이터의 크기에 대해 연구자들은 우려하고 있다.
채널의 대역폭과 메모리 공간은 한정되어 있기 때문에 데이터 전송 및 저장을 위해서는 데이터 압축이 필요하다.
압축에는 오디오 압축, 이미지 압축, 동영상 압축, 문서 압축 등 다양한 압축 방법이 있다.
이미지 압축에는 크게 두 가지 범주가 있다.
- 손실 압축 (lossy compression)
- 무손실 압축 (lossless compression)
작은 데이터 압축의 경우 Huffman coding, run- length encoding (RLE), arithmetic coding, and Lempel–Ziv–Welch (LZW) coding과 같은 무손실 방법들이 효율적이다.
하지만, 무손실 압축 기술은 손실 압축 기술에 비해 효율성이 떨어진다는 단점이 있다.
이로 인해 많은 연구자들은 ML을 사용한 이미지 압축 연구를 진행하고 있다.
본 Survey에서는 아래 질문에 대해 다뤘다.
- ML을 사용한 end-to-end lossy compression 방법은 무엇인가?
- 압축된 이미지를 시각적으로 잘 표현하는가?
- GPU 메모리를 절약하는 압축 방법
- 가장 빠른 이미지 압축 방법
2. Related work
생략
3. Still image compression
연구자들은 오랫동안 이미지 압축에 대해 고민해왔다. ML이 도입되고 기존 프레임워크를 대신 ML모델을 이미지 압축에 사용했다. 이러한 인기로 이미지 압축 알고리즘은 연구 대상이 됨.
Jiang(1999) 논문에서 신경망 기반의 이미지 압축 연구를 발표. 이 연구에서는 end-to-end image compression에 대해서는 다루지 않았음.
이전에는 이산코사인 변환(DCT) 및 이산웨이블릿변환(DWT)기반의 프레임워크에 대한 연구를 수행.
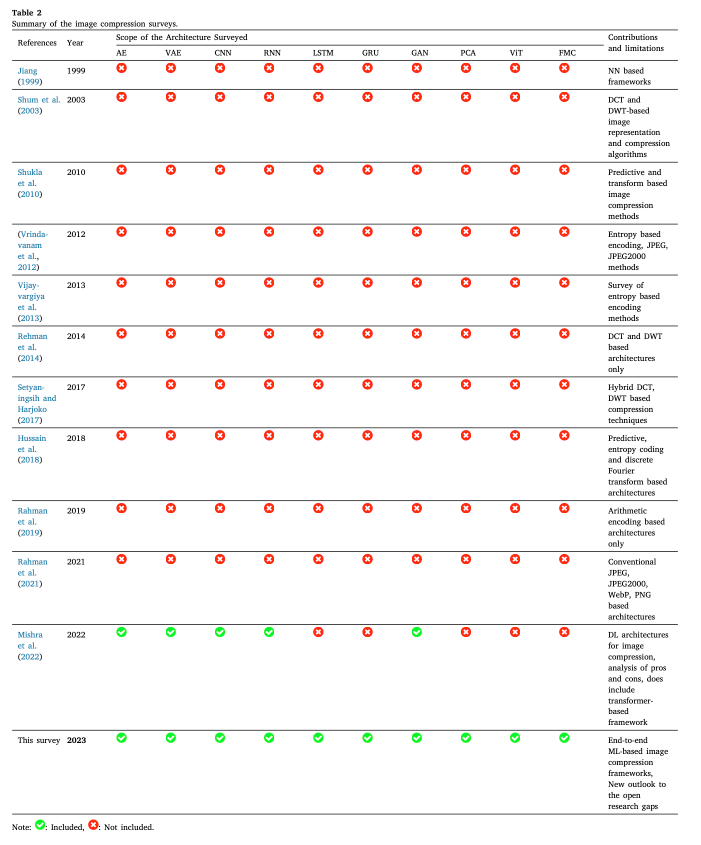
해당 논문에서는 기존 논문보다 다양한 아키텍쳐에 대해 조사하였음.
paper 선정에 대한 알고리즘은 다음과 같다고 한다.

JPEG에서는 압축 표준인 DCT가 사용되며 다음과 같이 계산할 수 있다.
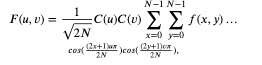
여기서 𝐶(𝑢),𝐶(𝑣)는 다음과 같습니다.

JPEG 프레임워크 파이프라인 Figure
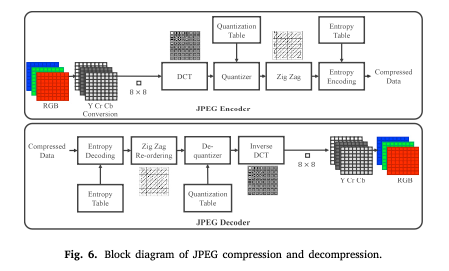
JPEG는 20001년 JPEG-2000이 제안되기 전까지 이미지 압축에서 널리 사용되었음.
JPEG-2000은 DCT 대신 DWT를 사용한다. JPEG-2000에서 사용하는 엔트로피 인코딩 방식은 Huffman encoding, RLE, Arithmetic encoding이다.
JPEG-2000 프레임워크 파이프라인 Figure
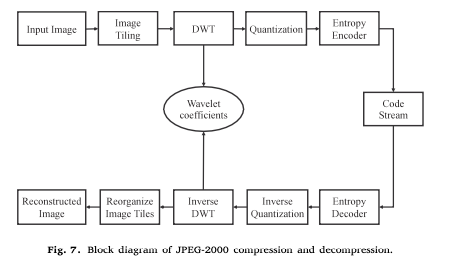
JPEG 및 JPEG-2000은 널리 사용되었음. 이후 연구자들은 JPEG 한계를 극복하기 위해 JPEG extended range (JPEG XR), JPEG XT를 개발하였음. 그러나 두 알고리즘은 하드웨어 호환성 문제로 실패함.
최근에는 high dynamic range (HDR) 이미지 압축을 위해 WebP, better portable graphics (BPG),JPEG XL 알고리즘이 제안되었다.
이러한 기존 알고리즘에도 여전히 한계가 있다.
이미지 압축의 시각적 품질 개선과 같은 여러문제는 ML을 통해 해결되었다.
4. Learning-driven lossy image compression
ML은 오늘날 모든 연구분야에 큰 영향을 미치고 있다. CNN의 feature extraction은 이미지 처리에 혁명을 일으켰다.
그 결과 이미지 압축을 위해 많은 ML 아키텍쳐가 제안되었다.
Compression with AE
Ball 등은 2016년에 가장 널리 사용되는 학습 기반 손실 이미지 압축 모델을 제안했다. AE에는 input, bottleneck, output 등 세가지 부분이 있다. 잠재 공간(Latent space)은 CAE에서 bottleneck을 나타낸다.
이미지 압축은 입력 이미지의 크기를 줄여 크기를 줄이기 때문에 인기를 얻었음.
저자들은 MSE loss function으로 AE를 훈련하여 JPEG, JPEG-2000, WebP보다 더 나는 성능을 달성함.
Dumas 등(2018)에서는 이미지 압축을 위한 AE를 제안함. 이들은 훈련 과정의 속도를 높이기 위해 ReLU 대신 generalized divisive normalization (GDN) 및 inverse generalized divisive normalization (IGDN) 레이어를 사용함.
Compression with VAE
probabilistic graphical model과 variational Bayesian method에서 VAE는 NN의 한 버전이다. VAE는 평균과 분산을 통합하여 잠재 공간 분포를 압축한다. VAE는 단순 AE보다 더 나은 결과를 생성함.
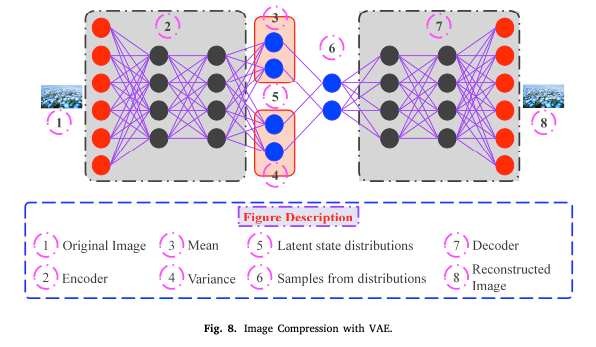
Training process를 boost하기 위해 저자들은 non-local attention module (NLAM)을 제안. 하지만 모델 복잡성이 크게 증가하는 문제가 있음.
이와 유사하게 Kullback–Leibler (KL) loss function을 사용하는 VAE를 제안.(Larsen(2016))
Gregor는 VAE를 사용하여 이미지를 압축하여 4.10 bbp를 달성함. 하지만 모델 구조가 매우 복잡하였음.
Compression with CNN
feature extraction으로 인해 이미지처리에서 CNN은 핵심적인 역할을 함. CNN 기반의 이미지 압축 모델은 SSIM 및 PSNR 측면에서 JPEG 및 JPEG-2000 보다 우수한 성능을 보임.
Compression with RNN
RNN 또한 이미지 압축에서 사용할 수 있음. RNN 기반 이미지 압축 아키텍쳐에는 convolutional layers, GDN layer, RNN modules, binarized convolutional layers, and an IGND layer가 있다.
Compression with GRU
GRU는 2014년에 Cho 등(2014)이 제안한 RNN의 게이팅 메커니즘이다. GRU는 손실 이미지 압축에도 유용하게 적용한 연구가 있음.
Chowdary 등(2022) 위성 이미지 압축을 위해 GRU기반 non- negative tucker decomposition을 사용함. 그 결과 컴퓨팅 효율이 향상됨.
Compression with GAN
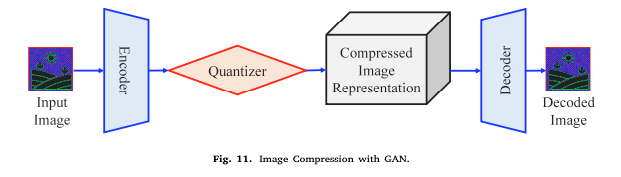
GAN은 이미지 생성을 위해 두개의 NN을 서로 경쟁시킨다. GAN에는 Generator와 Discriminator가 포함됨.
GAN 기반의 아키텍쳐 또한 JPEG 및 JPEG-2000보다 훨씬 더 우수했지만, 배포 비용이 많이 든다는 단점이 있다.
Compression with PCA, fuzzy means clustering
딥러닝 방법론이 아니여서 제외.
Compression with transformers
컴퓨터 비전의 많은 분야에서 vision transformers (ViTs)가 CNN을 대체하고 있다.
이미지 압축에서도 ViT가 적용되어 BPG(4:4:4)와 비교했을 때 PSNR과 MS-SSIM 측면에서 더 뛰어난 성능을 보였다. 시각적 품질 측면에서도 재구성된 이미지가 크게 개선되었다.
이전에 언급한 모델들에 트랜스포머 블록을 적용하는 연구가 진행됨.
트랜스포머 기반 엔트로피 모델
- Entroformer (2022)
트랜스포머 기반 컨텍스트 모델
- Contextformer (2022)
Impact of context-based entropy modeling
현재 lossy image compression algorithm은 entropy loss로 인한 속도 저하로 어려움을 겪고 있다.
codec의 확률 분포를 정확하게 추정하는 것은 엔트로피를 줄이고 joint rate– distortion performance를 개선하는데 중요한 역할을 한다.
Context-based entropy modeling은 대부분의 learning-driven architectures의 RD 성능을 개선하는데 사용했음. 이 아키텍쳐는 local context를 고려할 뿐만 아니라 non-local (NL) contexts도 고려한다.
Context(맥락) : 이미지의 각 요소를 예측할 때 주위에 있는 정보나 특징
5.Evaluation metrics for the learning-driven models
learning-driven models에서 사용할 수 있는 다양한 평가척도가 있음.
평가척도에는 PSNR, SSIM, MS-SSIM, Visual Information Fidelity (VIF), Video Multimethod Assessment Fusion (VMAF)이 있다.
이후의 내용은 크게 다룰 것이 없어 생략하였습니다.
Image Compression이 어떻게 발전해왔고,압축을 위해 어떤 방법론들이 사용되었는지 잘 소개해준 논문이었습니다.
단, 딥러닝 부분에서 수식이 없기 때문에 다른 Survey paper나 model paper를 통해 학습해야할 것 같습니다.
