논문 제목
Knowledge Distillation: A Survey
URL: https://arxiv.org/abs/2006.05525
인용수 : 3,076회 (25.02.02 기준)
요약
- 딥러닝의 성공은 대규모 데이터를 인코딩할 수 있는 확장성과 수십억 개의 모델 파라미터를 조작할 수 있는 능력때문임.
- 하지만 이 방대한 모델을 모바일 기기 및 임베디드 장치와 같은 제한된 자원을 가진 기기에 배포하는 것은 높은 계산 복잡성과 큰 저장 공간 요구 사항 때문에 어려운 문제이다.
- Knowledge Distillation (지식 증류, KD)는 큰 Teacher 모델로부터 작은 Student model을 효과적으로 학습하는 기법이다.
- 본 논문에서는 Knowledge Distillation의 유형, 학습 방식, 아키텍쳐, 알고리즘, 성능 비교 관점에서 종합적으로 조사함.
Introduction
대규모 딥 모델은 실질적인 응용에서 뛰어난 성능을 보이며 엄청난 성공을 거두었지만, 높은 계산 복잡도와 높은 저장 공간 요구 사항으로 인해 실시간 애플리케이션, 특히 비디오 감시 시스템 및 자율주행 자동차와 같은 제한된 자원을 가진 기기에서 배포하는 것은 큰 도전 과제로 남아있다.
모델 경량화를 위한 연구 동향은 아래와 같다.
1. 효율적인 아키텍쳐 & 블록 개발
- MobileNets
- ShuffleNets
- Depthwise Separable Convolution
- 모델 압축 및 가속 방법
-
Parameter pruning & sharing
중요하지 않은 파라미터를 제거하여 신경망의 크기를 줄이는 방법이다.
대표적으로 모델 양자화 (model quantization), 모델 이진화 (model binarization), 구조적 행렬 (structural matrices), 파라미터 공유 (parameter sharing) 등이 있음. -
Low-rank factorization
행렬 및 텐서 분해 기법을 이용해 신경망의 중복된 파라미터를 제거하는 방법이다. -
Transferred compact convolutional filters
중요하지 않은 컨볼루션 필터를 제거하거나 필터를 압축하는 방법이다. -
Knowledge distillation (KD)
Teacher Model에서 Student Model로 지식을 증류하는 방법이다.
본 논문의 초점은 지식증류이기에 KD에 대해서만 다룬다고 함.
대규모 모델들은 over-parameterization을 통해 일반화 성능을 향상시킨다. 그러나 모바일 기기 및 임베디드 시스템에서는 제한된 연산 성능과 메모리 제약으로 인해 대규모 모델을 직접 배포하기가 어려운 문제가 있다.
이를 해결하기 위해 모델 압축 개념이 제안되었고, 큰 모델 또는 앙상블 모델의 정보를 작은 모델로 전달하는 방식이 제안되었다. 또한, 비지도 데이터를 활용하여 fully supervised learning 모델에서 Student Model로 정보를 전이하는 방법 또한 제시되었다.
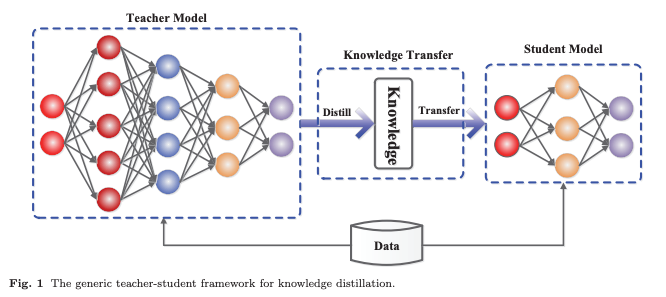
이러한 개념들이 정립된게 바로 2015년에 제안된 Knowledge Distillation (지식 증류) 방법이다. 지식 증류에서는 작은 Student Model이 큰 Teacher Model을 모방하도록 학습한다. 핵심 아이디어는 Student Model이 Teacher Model의 성능을 뛰어 넘거나 동등한 성능을 달성하는 것이다.
KD에서 중요한 문제는 Teacher Model가 가지고 있는 지식들을 어떻게 Student Model으로 전달하는 것이냐... 이게 관건이다.
일반적인 KD 시스템은 다음의 세 가지 핵심 요소로 구성된다.
1. 지식(Knowledge)
2. 증류 알고리즘(Distillation Algorithm)
3. 교사-학생 아키텍처(Teacher-Student Architecture)
지식 증류는 응용분야에서 큰 성공을 거뒀지만, 큰 모델이 반드시 좋은 Teacher Model이 되는 것은 아니며, Student Model의 학습을 방해하는 경우도 있다고 한다.
Knowledge
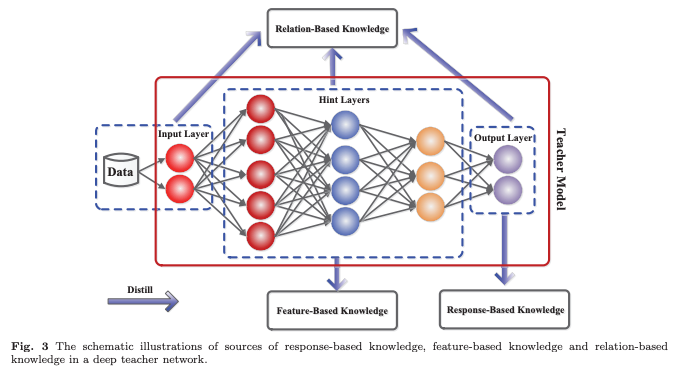
지식 증류에서 knowledge types, distillation strategies, teacher-student architectures는 student model 학습에서 중요한 역할을 한다.
기본적인 KD에서는 대형 모델의 Logits을 teacher knowledge로 사용한다. 또한, 중간 레이어의 activations, neurons 또는 feature를 지식으로 사용하여 student model의 학습을 유도할 수 있다.
본 논문에서는 다양한 형태의 지식을 response-based knowledge, feature-based knowledge, relation-based knowledge으로 분류하여 설명한다고 한다. 그림 3에서 세 카테고리에 대하여 직관적으로 표현되어있다.
Response-Based Knowledge
Response-Based Knowledge은 일반적으로 Teacher Model의 마지막 출력 레이어에서 생성된 neural response을 의미한다고 한다. 이 방법의 핵심 아이디어는 Teacher Model의 최종 예측을 직접 모방하는 것이다.
이 방법은 모델 압축을 위한 단순하면서도 효과적인 방법이며, 다양한 작업과 응용에서 널리 사용되고 있다고함. Teacher Model의 마지막 FC 층에서 출력된 logits 벡터 가 주어졌을 때, distillation loss는 다음과 같이 정의된다.
여기서 은 logits의 divergence loss를 나타내며 와 는 각각 Teacher Model과 Student Model의 logits을 의미한다.
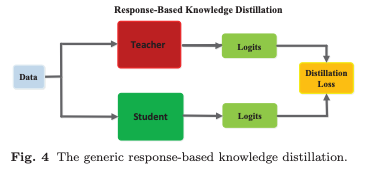
Response-Based Knowledge는 다양한 유형의 모델 예측에 사용할 수 있다. 예를 들어 Object Detection Task에서는 logits뿐만 아니라 바운딩 박스 오프셋 정보도 포함될 수 있다고 함.
이미지 분류를 위한 가장 일반적인 Response-Based Knowledge는 Soft Targets으로 알려져 있다. Soft Targets은 입력이 특정 클래스에 속할 확률을 의미하며, 이는 소프트맥스 함수를 사용하여 다음과 같이 추정한다고 한다.
여기서 T는 temperature factor이며 soft target의 중요도를 조절한다.
15년도의 연구에 따르면 소프트 타깃은 Teacher Model의 유용한 Dark Knowledge를 포함하고 있다고한다. 이에 따라, 소프트 logits에 대한 distillation loss 은 다음과 같이 다시 작성될 수 있다.
일반적으로 은 Kullback-Leibler(KL) 발산 손실을 사용한다.
이를 최적화함으로써 Student Model의 logits가 Teacher Model의 logits와 일치하도록 학습할 수 있다.
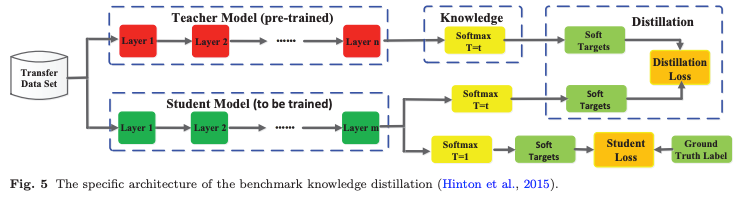
그림 5는 기본적인 Knowledge Distillation(KD) 모델이다.
Student Model의 손실은 항상 Cross-Entropy Loss 로 정의되며, Student Model의 soft logits과 Ground Truth 레이블 𝑦 사이의 차이를 측정한다.
Response-Based Knowledge의 개념은 "Dark Knowledge" 관점에서 매우 직관적이며 이해하기 쉽다고 한다. 다른 관점에서 보면, 소프트 타깃의 효과는 Label Smoothing 또는 Regularization과 유사하다. 그러나 이 방법은 일반적으로 마지막 레이어의 출력에 의존하며, 이는 Teacher Model의 intermediate-level supervision 정보를 활용하지 못하는 한계를 가진다.
이러한 intermediate-level supervision은 매우 깊은 신경망에서 Representation Learning에 중요한 역할을 한다. 또한, 소프트 logits이 class probability distribution이므로, 지도 학습에 한정되는 경우가 많다.
"Dark Knowledge"란?
Teacher Model의 Softmax 출력을 통해 Student Model로 전달되는 추가적인 정보를 의미함. -> 클래스 간 관계 정보, 유사도 등
Feature-Based Knowledge
신경망은 추상화된 여러 수준의 feature representation을 학습하는데 뛰어나다. 이는 Representation Learning으로 알려져 있다. 따라서, 마지막 레이어의 출력뿐만 아니라 중간 레이어의 출력(feature map)도 Student Model 학습을 감독하는 지식으로 사용할 수 있다.
특히, 중간 레이어에서 얻은 Feature-Based Knowledge은 Response-Based Knowledge의 확장으로 볼 수 있으며, 얇고 깊은 네트워크를 학습하는 데 유용하다.
intermediate representations은 Student Model 학습을 향상하기 위한 힌트(Hint)를 제공하는 역할을 한다. 기본적인 아이디어는 Teacher Model과 Student Model의 feature activations를 직접적으로 매치시키는 것이다. 이를 기반으로 다양한 연구가 간접적인 특징 매치 방법이 제안됨.
이후 주의 맵(Attention Map)을 원본 특징 맵에서 유도하여 특징 표현을 학습하는 방식등 다양한 Variation 제안되었다.
일반적으로, Feature-Based Knowledge Transfer의 증류 손실은 다음과 같이 정의된다.
여기서 와 는 각각 각각 Teacher Model과 Student Model의 중간 레이어에서 추출된 feature maps이다.
함수는 eacher Model과 Student Model의 특징 맵이 동일한 형태(shape)가 아닐 경우 적용되는 변환 함수임.
은 Teacher Model과 Student Model의 특징 맵을 정렬하는 데 사용되는 유사도 함수이다.
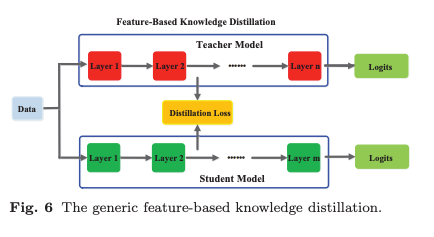
Feature-Based Knowledge Transfer는 Student Model의 학습에 유리한 정보를 제공하지만, Teacher Model에서 어느 Hint Layer를 선택하고, Student Model에서 어느 Guided Layer를 선택해야 하는가에 대한 연구는 아직 해결되지 않은 문제이다. 또한, Hint Layer와 Guided Layer 간 크기 차이가 상당히 클 수 있으므로, Teacher Model과 Student Model의 특징 표현을 적절하게 정렬하는 방법도 추가적인 연구가 필요함.
Relation-Based Knowledge
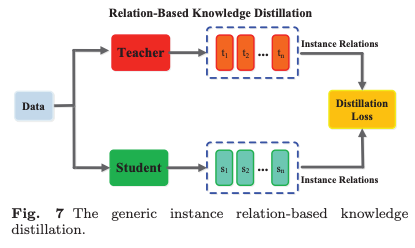
앞서 두 방법은 Teacher Model의 특정 레이어 출력만을 이용한다.
Relation-Based Knowledge은 Teacher Model의 여러 레이어 간 관계 또는 데이터 샘플 간 관계를 탐색하는 방식이다.
관련 연구로는 Flow of Solution Process (FSP), Singular Value Decomposition(SVD) 등을 활용하여 feature map에서 중요한 정보를 추출하여 feature map 간의 상관관계를 증류된 지식으로 활용한다.
일반적으로, feature map 간 관계를 활용하는 Relation-Based Knowledge Distillation의 손실 함수는 다음과 같이 정의된다.
여기서 와 는 Teacher Model에서 선택된 feature map pair이며, 와 는 Student Model에서 선택된 feature map pair이다.
과 는 각각의 모델에서 feature map 쌍을 비교하는 유사도 함수이다.
은 Teacher Model과 Student Model의 특징 맵 간 상관관계(Correlation Function)를 측정하는 함수임.
Traditional knowledge transfer method는 개별적인 지식증류를 포함하는 경우가 종종 있다.
Teacher Model의 개별적인 Soft Target을 Student Model로 직접 증류하는 방식이다.
하지만 실제로 증류된 지식에는 단순한 특징 정보뿐만 아니라 Mutual Relations of Data Samples도 포함된다. 즉 샘플간의 관계도 포함된다.
relation based knowledg에서 instance 간 관계를 활용하는 distillation loss는 아래와 같이 정의된다.
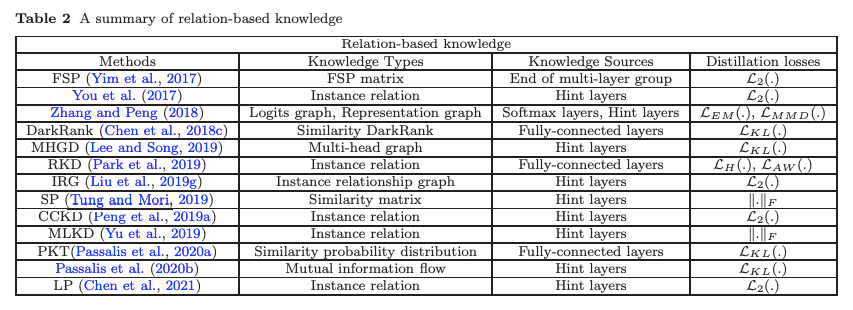
최근 여러 유형의 relation-based knowledge이 제안되었지만, feature maps 또는 데이터 샘플에서 관계 정보를 지식으로 모델링하는 방법에 대한 연구는 여전히 추가적인 연구가 필요.
Distillation Schemes
Teacher Model이 Student Model과 동시에 업데이트되는지 여부에 따라, 지식 증류의 학습 방식은 다음 세 가지 주요 범주로 나뉜다:
1. Offline distillation
2. Online Distillation
3. Self-Distillation
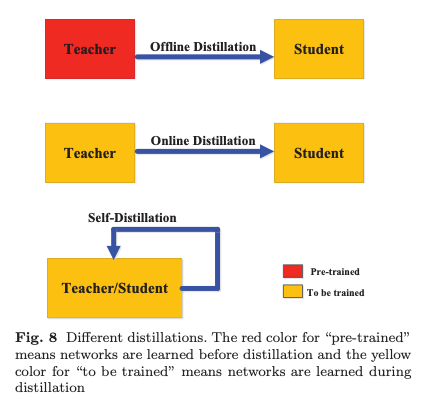
Offline Distillation
대부분의 Knowledge Distillation 방법은 오프라인으로 작동한다.
2015년 지식 증류 논문에서는 사전 학습된 Teacher Model에서 Student Model로 지식을 전이함.
따라서 전체 학습 과정은 두 단계로 나뉜다.
1. 대규모 Teacher Model이 학습 데이터셋을 이용해 사전 학습됨
2. Teacher Model이 logits 또는 intermediate features의 형태로 지식을 추출하여 Student Model 학습을 지도
오프라인 증류의 첫 번째 단계는 일반적으로 지식 증류의 일부로 간주되지는 않음.
Teacher Model이 이미 사전 학습된 것으로 가정되며, Teacher Model의 구조나 Student Model과의 관계에는 큰 관심 X
따라서 오프라인 방식에서는 주로 Knowledge Transfer의 다양한 측면을 개선하는 것에 초점을 맞춤.
오프라인 방식의 주요 장점은 다음과 같다.
1. 구현이 간단하고 사용이 용이
2. Teacher Model은 여러 가지 소프트웨어 패키지를 이용하여 학습될 수 있으며, 다른 기기에서 학습된 모델도 포함될 수 있음
3. Teacher Model의 지식은 캐시에 저장되어있음.
오프라인 지식 증류 방식은 일반적으로 단방향 지식 전이와 2단계 학습 프로세스를 따름.
그러나 고성능 Teacher Model의 학습에 상당한 시간과 연산 비용이 소요되는 문제가 있음.
그렇지만 오프라인 증류에서 Student Model의 학습은 Teacher Model의 지도를 통해 효율적으로 수행될 수 있음.
대규모 Teacher Model과 소규모 Student Model 간의 Capacity Gap는 항상 존재하며, Student Model은 종종 Teacher Model에 크게 의존하는 경향이 있음.
Online Distillation
오프라인 증류 방식이 단순하고 효과적이지만, 최근 연구에서는 오프라인 증류의 한계에 대한 관심이 증가.
이를 해결하기 위해 온라인 증류(Online Distillation)가 제안되었으며, 이는 특히 고성능 Teacher Model을 사용할 수 없는 경우 Student Model의 성능을 향상시키는 방법으로 활용.
온라인 증류에서는 Teacher Model과 Student Model이 동시에 업데이트되며, 전체적인 지식 증류 프레임워크는 End-to-End 방식으로 학습 가능하다
온라인 증류는 단일 단계의 end-to-end 학습 방식으로 진행되며, 병렬 연산이 가능하여 효율적인 학습이 가능하다. 그러나 기존의 온라인 방식(mutual learning)은 높은 용량을 가진 Teacher Model을 처리하는 데 한계를 가진다. 온라인 셋팅에서 Teacher Model과 Student Model 간의 관계를 더욱 심층적으로 탐구하는 것은 흥미로운 주제가 될 것임.
Self-Distillation
Self-Distillation에서는 동일한 네트워크가 Teacher Model과 Student Model 역할을 동시에 수행한다. 이는 Online Distillation의 특수한 경우로 간주될 수 있음.
구체적으로, 네트워크의 깊은 부분에서 학습된 지식을 얕은 부분으로 증류하는 방식이다.
Self-Distillation은 또한 동일한 아키텍처를 가진 Teacher Model과 Student Model을 차례로 최적화하는 데 사용되기도 함. 각 네트워크는 이전 네트워크의 지식을 Teacher-Student 최적화 방식을 사용해 증류.
Offline Distillation, Online Distillation, Self-Distillation는 인간의 Teacher-Student 학습 관점에서 직관적으로 이해될 수도 있음.
- 오프라인 증류는 유능한 Teacher Model이 Student Model에게 지식을 전달하는 방식을 의미한다.
- 온라인 증류는 Teacher Model과 Student Model이 서로 협력하며 함께 학습하는 방식
- 자기 증류는 Student Model이 스스로 지식을 학습하는 방식
또한, 인간 학습 방식과 마찬가지로, 이러한 세 가지 증류 방법은 각각의 장점을 활용하여 서로를 보완할 수 있도록 결합될 수 있다.
예를 들어, Self-Distillation과 Online Distillation은 Multiple Knowledge Transfer Framework를 통해 적절하게 통합될 수 있다고함.
Teacher-Student Architecture
지식 증류에서 Teacher-Student 아키텍처는 Knowledge Transfer를 수행하는 기본적인 구조임.
즉, Teacher Model에서 Student Model로 지식을 얻고 증류하는 과정의 quality는 Teacher와 Student의 네트워크 구조 설계에 의해 결정된다.
사람의 학습 방식과 유사하게, Student Model이 적절한 Teacher Model을 찾는 것이 중요하다.
따라서, 지식 증류 과정에서 Teacher Model과 Student Model의 구조를 선택하거나 설계하는 것은 매우 중요한 문제임.
현재 대부분의 연구에서는 Teacher Model과 Student Model의 크기 및 구조를 pre-fixed하고 증류를 진행하는 방식을 따른다. 그러나 이 방식은 Model Capacity Gap를 초래할 가능성이 크다고 한다.
그러나 Teacher와 Student의 아키텍처를 구체적으로 설계하는 방법과 이러한 모델 설정에 따라 아키텍 쳐가 결정되는 이유에 대한 설명은 거의 빠져 있다고 한다.
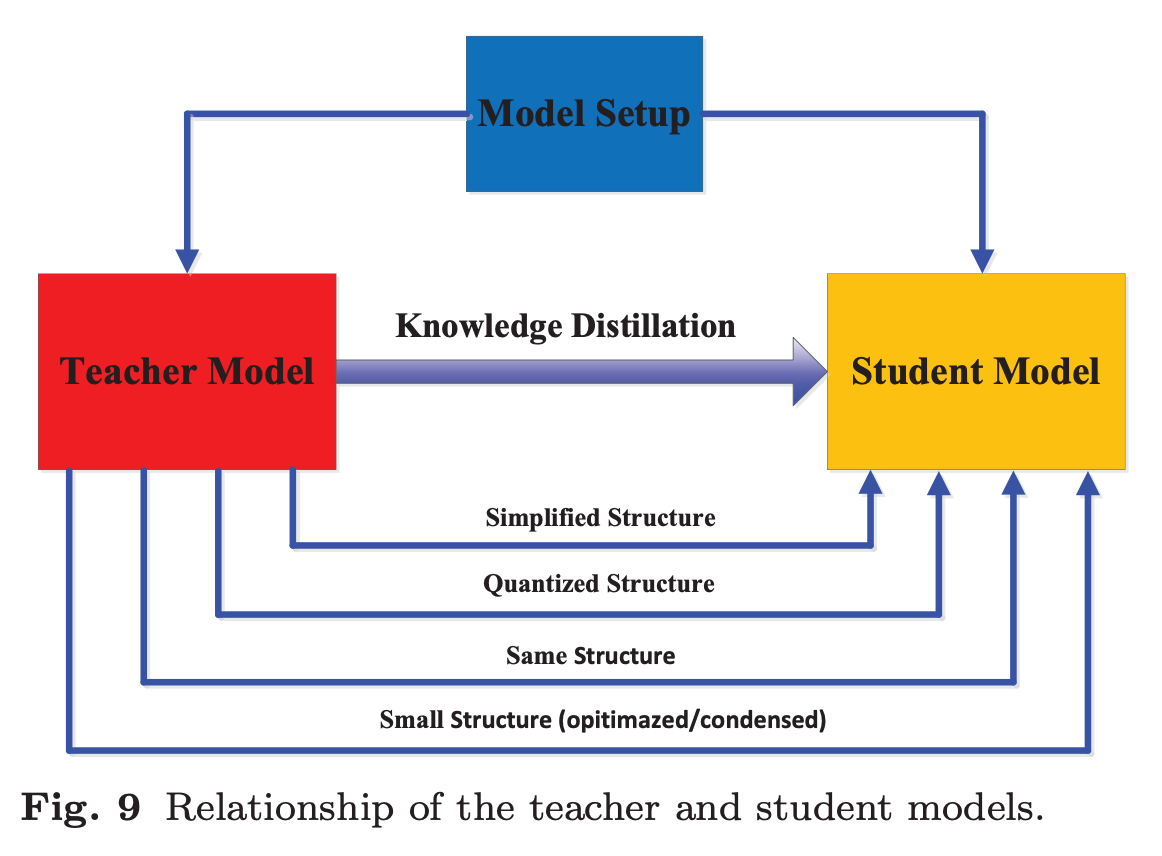
지식 증류는 원래 신경망을 압축하는 기법 (model compression)으로 설계되었다.
신경망의 복잡성은 주로 Depth와 Width라는 두 가지 차원에서 결정된다. 일반적으로, 깊고 넓은 신경망(Teacher Model)의 지식을 더 얕고 좁은 신경망(Student Model)으로 전이하는 방식이 사용된다.
Student Model은 다음과 같은 방식으로 선택될 수 있다.
- Teacher Model을 Simplified Structure하여, 더 적은 층과 더 적은 채널을 포함하는 네트워크
- Teacher Model의 구조를 유지하면서 Quantized Structure하여 경량화한 네트워크
- 연산 효율이 높은 연산 블록을 활용한 소형 네트워크
- 글로벌 네트워크 구조를 최적화한 소형 네트워크
- Teacher Model과 동일한 구조를 가지는 네트워크
큰 Teacher Model과 작은 Student Model 간의 Capacity Gap는 지식 전이 성능을 저하시킬 수 있음. 이 문제를 해결하기 위해, Student Model의 복잡도를 조절하는 다양한 연구가 진행되었다고함. (Teacher Assistant 구조, Residual Learning, Quantization, Depth-Wise Separable Convolution, Neural Architecture Search, Reinforcement Learning 등)
지금까지 대부분의 연구는 Teacher Model과 Student Model의 구조 설계 또는 Knowledge Transfer Scheme 개선에 집중되어 있었다.
대형 Teacher Model과 소형 Student Model 간의 지식 전이를 효과적으로 수행하기 위해서는 Adaptive Teacher-Student Learning 구조가 필요.
최근에는 지식 증류에서 Neural Architecture Search를 활용하여 Teacher Model의 지도 하에 Student의 구조와 knowledge transfer를 joint-search하는 아이디어는 향후 연구에서 중요한 주제가 될 것이라고 한다.
Distillation Algorithms 이후 생략
지식증류를 처음 공부하면서 기초 개념인 Knowledge & Distillation Schemes, Teacher-Student Architecture에 대해 이해할 수 있는 서베이 논문이었다. 인용수가 높은 만큼 쉽게 이해가능했고, 관련 연구 사례도 잘 정리되어서 좋았다..!
*뒷 섹션은 본인의 Task와 맞는 섹션만 읽어도 충분해 보임.
번역 보조
DeepL
ChatGPT
