4.1 Introduction
-
Branching Process이란 무엇인가?
- 한국어로는 분지과정 또는 분기과정
- 확률 과정(Stochastic process)의 한 종류
- Stochastic process: 불확실성을 포함한 모델링 (week0)
- 사용 분야
- 대부분 인구 증가를 설명 위해 사용
- 감염병과 전염병의 확산에 대해 공부하는 생물학
- 핵 연쇄 반응과 소프트웨어 바이러스 전파
- 핵 연쇄 반응: 하나의 핵 반응이 평균적으로 하나 이상의 핵 반응을 유발하는 과정으로, 일단 하나의 핵 반응이 시작하면 이후 핵 반응 수가 기하급수적으로 증가하는 현상을 가리킨다.
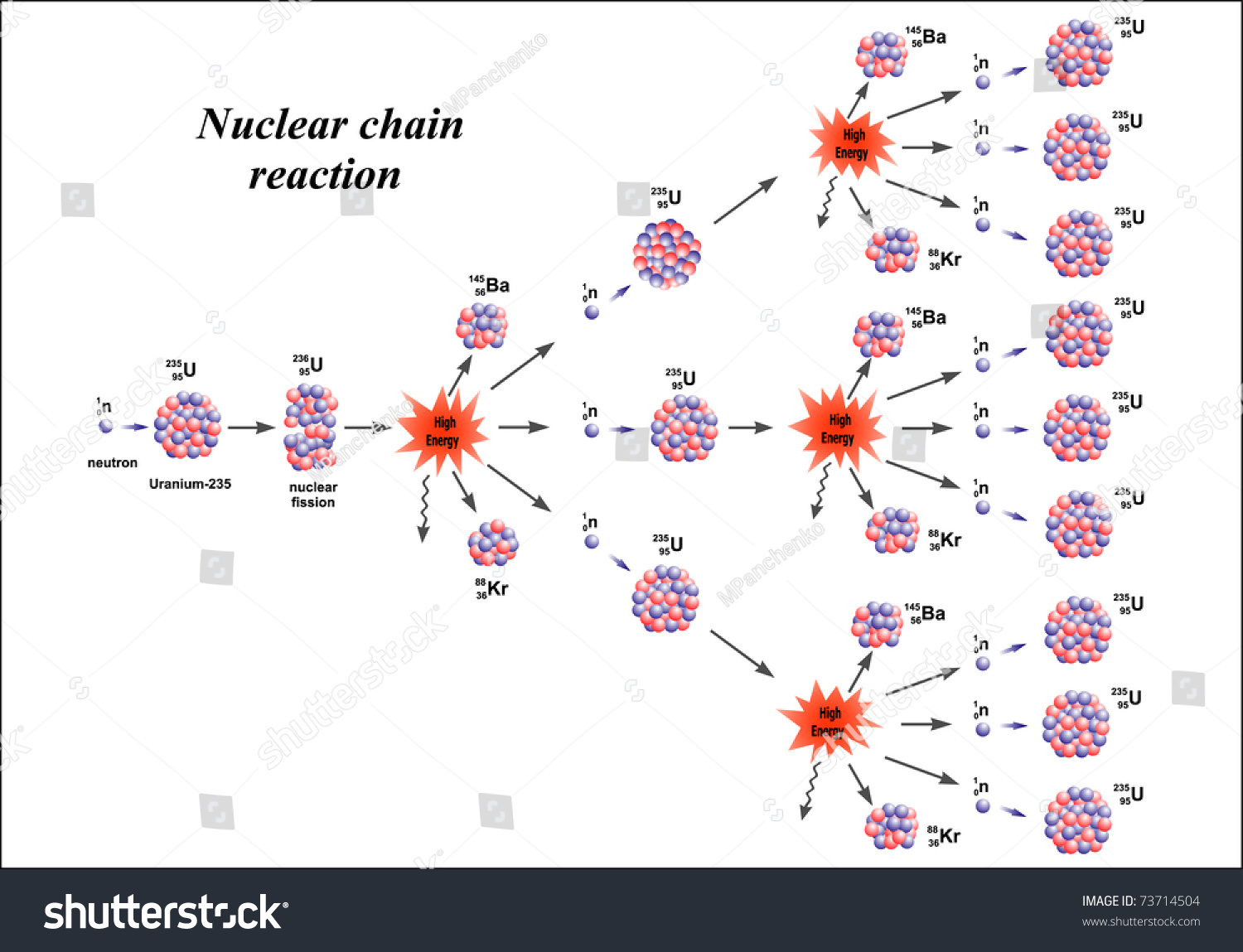
- 핵 연쇄 반응: 하나의 핵 반응이 평균적으로 하나 이상의 핵 반응을 유발하는 과정으로, 일단 하나의 핵 반응이 시작하면 이후 핵 반응 수가 기하급수적으로 증가하는 현상을 가리킨다.
-
유래: 1873년 영국의 통계학자 Galton이 이런 문제를 만들었다.
💡 Problem 4001: 한 국가에서 성인 남성이 N명 있다고 하자. 이 N명의 성은 서로 다르며, 각각 한 지역을 식민지화하여 살고 있다. 각 세대에서 성인 남성이 남자 아이 0명을 가질 확률을 $a_0$, 1명 가질 확률을 $a_1$, …, 5명 가질 확률을 $a_5$라고 하자. (1) $r$ 세대 이후 성씨 중 몇 %가 멸종할까? (2) $m$명의 사람들이 있을 때 동일한 성을 가진 사람은 몇 명일까? - 첫번째 시도는 Watson이 했다. 그는 대수학(Algebra)에서 약간의 실수로 인해 “family name would always die out with probability 1”이라 답했다. 답은 틀렸으나 그가 적용한 방법은 옳았음이 밝혀졌다. - 또한, 프랑스의 통계학자 Bienaymé도 독립적으로 연구했기에 basic branching process가 Bienaymé-Galton-Watson process라고 불리기도 한다. -
Branching process
-
인구는 세대에 따라 증가하기도 하고, 감소하기도 한다.
-
: 세대의 크기 (인구 수) (정의)
-
로 가정한다. → 인구가 한 개인으로부터 시작된다
-
sequence 이 branching process이다. (확률 과정의 한 종류)
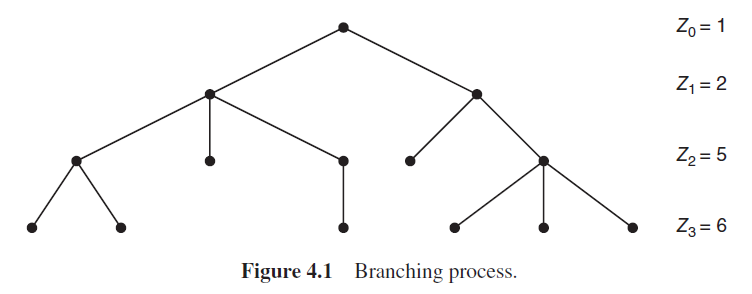
0세대에서 인구는 1명 (가정 사항), 1세대에서는 2명, 2세대에서는 5명, 3세대에서는 6명이다.
-
-
Branching process 는 Markov chain이다.
이유: n 세대의 인구 수는 오직 (n-1)번째 세대의 인구 수와 그 때의 자손 수에만 영향을 받기 때문이다. 0번째부터 (n-2)번째 세대까지 인구가 어떻게 성장해 왔는지는 n번째 세대의 인구 수를 구하는데 영향을 주지 않는다.
-
Branching process 가정 사항과 offspring dist. 정의
- Branching Process의 기본적 가정 사항
- population의 모든 개인은 자손을 낳을 수 있다.
- 자손 수는 랜덤이며 다른 개인과 독립적이다.
- 한 개인의 자손 수는 알려진 분포를 따른다.
- 그 알려진 분포가 "offspring distribution"이다.
- probability distribution
- 의 확률로 0명을 낳고, 의 확률로 1명을 낳는 것
- 즉, 한 개인은 의 확률로 명의 아이를 낳는다. ()
- 몇 명의 자손을 낳을지에 대한 확률 분포이기에 offspring distribution이라고 한다.
- offspring dist에 대한 두 가지 가정
- : 0명을 낳는 확률인 는 0과 1 사이이다.
- → 각 개인마다 무조건 한 명은 낳음 → 인구는 항상 증가 → 0이 state space에 들어가지 않게 된다. (왜 0이 들어가야하나? 프로세스가 끝날 수 있어야 함)
- → 모든 개인이 아무도 안 낳음 → 시간이 지나도 인구 수에 변화가 없음 → 모든 에 대하여
- : 자손을 2명 이상 낳을 확률이 무조건 있다.
- : 0명을 낳는 확률인 는 0과 1 사이이다.
-
Lemma 4.1 : In a branching process, all nonzero states are transient.
- 증명에 사용되는 성질: Absorbing state에 도달 가능한 state들은 모두 transient하다.
- 왜 그럴까? absorbing은 아니지만 absorbing state에 도달 가능한 state가 있다고 하면, 그 state에서 출발했을 때 absorbing state에 가는 순간 출발지로는 절대 못 돌아가기 때문에 transient하다.
- transient 의미: 출발점으로 돌아가지 못하는 경로가 있다.
- 먼저, state 0은 absorbing state이다.
- Absorbing state: 인 가 존재함
- 의미: i state에서 출발했을 때 직후에 반드시 i로 돌아온다면, i에 한번 도달하는 순간 평생 i에 머물게 된다.
- state 0은? state 0에 있다는 의미는 세대에 인구가 없다는 의미 ()이고 인구가 없으면 자손도 없음 → 평생 state 0에 머문다.
- 모든 nonzero state은 state 0로 갈 수 있다
- 인구가 감소하여 0에 도달할 수 있기 때문이다.
- 증명에 사용되는 성질: Absorbing state에 도달 가능한 state들은 모두 transient하다.
-
long-term에서는?
-
all nonzero states are transient by lemma 4.1
-
the chain has infinite state space (인구 수는 셀 수 있는 무한 개의 정수)
⇒ long-term에서는 두 가지의 결과가 나올 수 있다.
하나는 state 0으로 흡수되는 것, 즉 인구가 멸종하는 것이고
또 하나는 인구가 제한 없이 커지는 것이다.
4.2 Mean generation size
-
-
구하는 방법
-
: 번째 generation의 크기 (number of individuals)
-
이전 세대 개인들의 자손의 총합으로 구한다
여기서 : (n-1)세대 i번째 개인의 자손 수
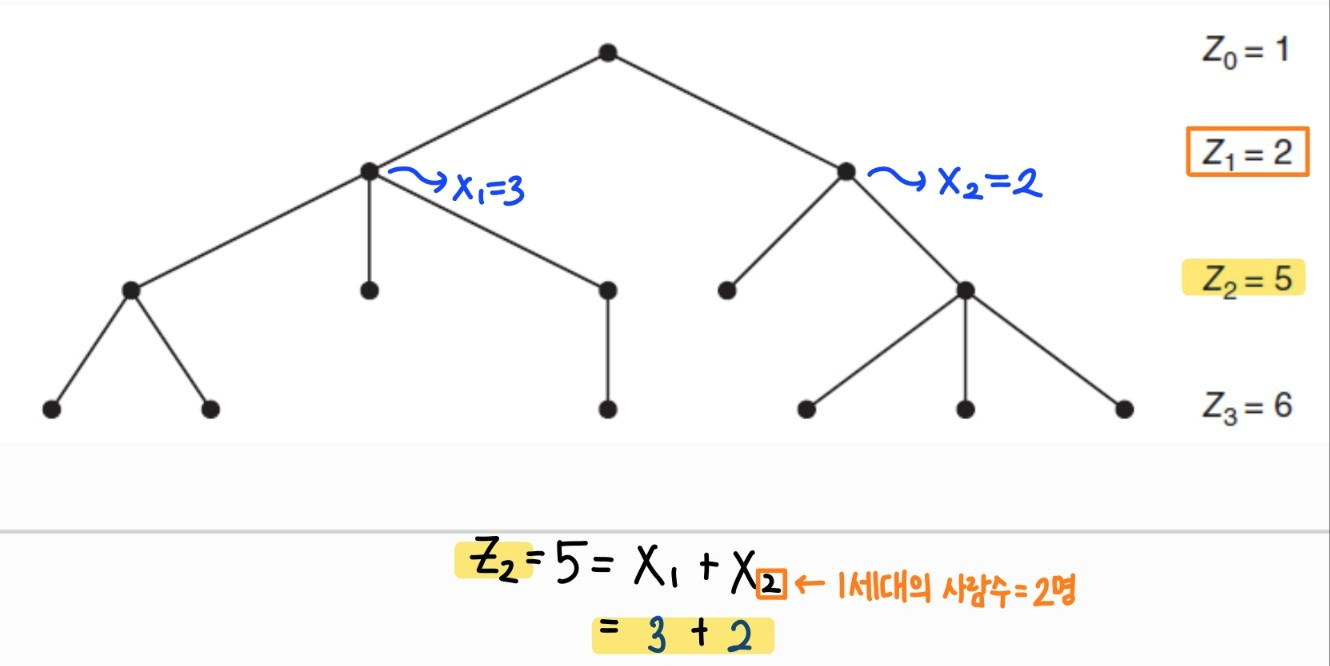
-
where
- 왜 iid? 는 한 개인의 자손 수이므로 offspring dist를 따르고, 각 는 각 개인에 대해 정의되므로 서로 독립이다.
- 따라서 는 i.i.d. random variables의 sum이다.
-
는 와 서로 독립이다.
- 앞서 본 예시에서 과 은 독립이다. 과 은 독립이 아니다.
-
-
구하는 방법
-
: n세대 크기의 기댓값. 즉 n세대 인원 수의 기댓값
-
: offspring distribution의 평균. 즉 한 개인이 낳을 자손 수의 기댓값
-
수식적 증명: 을 condition으로 걸어서 the law of total expectation 사용 → 생략
-
결론
의미: 이전 세대 인원 수의 기댓값에 한 개인이 낳을 자손 수의 기댓값을 곱하면 현 세대 인원 수의 기댓값이 나온다. (이전 세대의 개인이 모두 같은 수의 자손을 낳는다는 () 계산으로 들어감)
-
이 결론을 반복적으로 적용하면
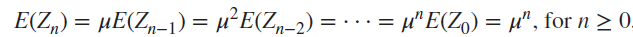
(가정에 의해 )
-
- Three Cases of long-term expected generation size ()
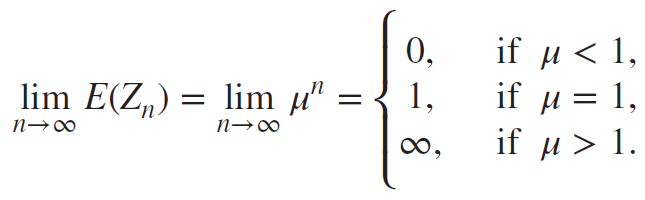
| 조건 | 조건의 의미 | branching process is called | mean generation size |
|---|---|---|---|
| 한 개인이 낳는 자손의 기댓값이 1명 보다 적음 | subcritical | long-term extinction | |
| 한 개인이 낳는 자손의 기댓값이 1명 | critical | stability | |
| 한 개인이 낳는 자손의 기댓값이 1명보다 많음 | supercritical | boundless growth |
-
simulation
-
Poisson offspring distribution으로 진행
- 에서 , k=0,1,2,3,….
-
10 generations
-
, , 세 가지 경우로 각각 5번씩 진행
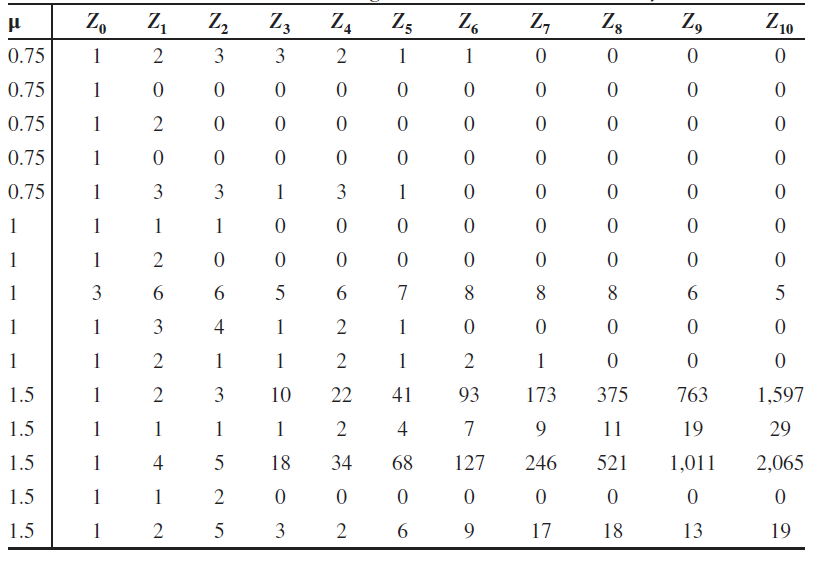
-
: 모든 simulation이 결국 0으로 수렴함. 상당히 빠르게 멸종
-
: 5번 중 오직 한 번만 10번까지 살아남음
-
: 5번 중 4번은 without bound으로 커짐. 그러나 한번은 멸종.
For a general branching process,: P(population이 멸종) → 1 as n→inf~~
: 0 < P(population이 멸종)<1 즉. 0보다 크다는 것은 멸종 할 수 있다는 얘기~~
-
-
Extinction in the Subcritical Case ⇒ 생략!
- E: the event that the population is ultimately extinct
- 결론: 일 때 P(E)=1
- 의미: With probability 1, a subcritical branching process eventually goes extinct.
- 증명: 수식
- Example 4.1: 문제도 아니고 그냥 과거 연구에 대한 설명…
-
Variance of Generation Size
- n세대 인원수를 분산을 계산한다.
- : offspring distribution의 분산
- 증명: EVVE+ 수식 왕창
- 결론
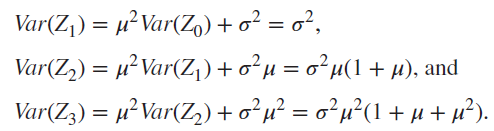
- 일반화
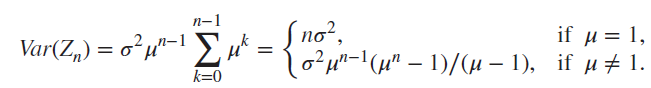
- 해석
- (subcritical) : 의 기댓값과 분산이 모두 0 → 무조건 멸종할 수 밖에 없음
- (critical) : 모든 의 기댓값은 1이지만, 분산은 n에 대해 선형적으로 증가
- (supercritical) : 분산이 지수적으로 증가함. 분산이 매우 크기 때문에 멸종과 boundless growth가 모두 가능한 것.
4.3 Probability Generating Functions

- 정의
이산확률변수 가 의 값을 가질 때, 의 확률생성함수 는 다음과 같이 정의된다.
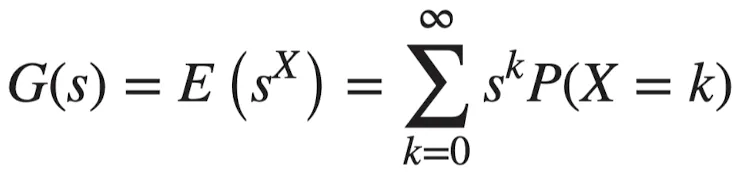
계수가 인 무한급수
G(1)=1 → 전체 확률의 합 = 1
일 때, 수렴
생성함수는 이산확률변수의 분포를 무한급수로써 나타낸다.
만약 두 무한급수가 같다면, 같은 분포를 가진다는 뜻.
example 4.2 pass
example 4.3
X가 파라미터 p를 가진 geometric distribution (기하분포)인 경우
기하분포의 pdf →
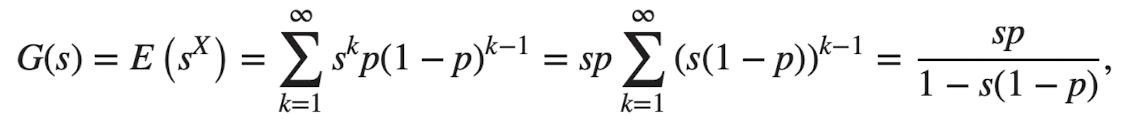
X의 확률은 생성함수를 미분해서 구할 수 있다.
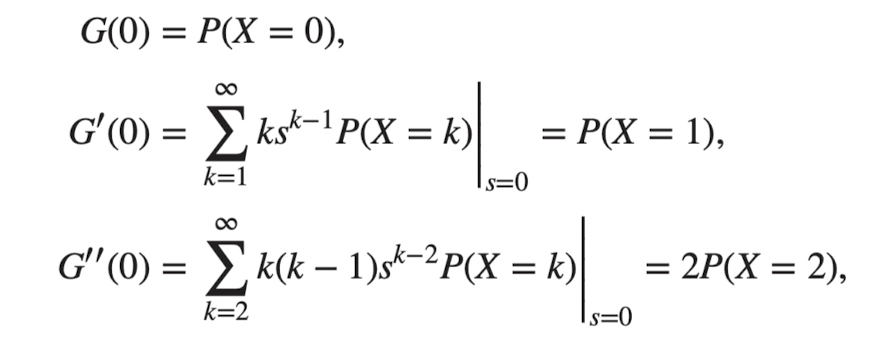
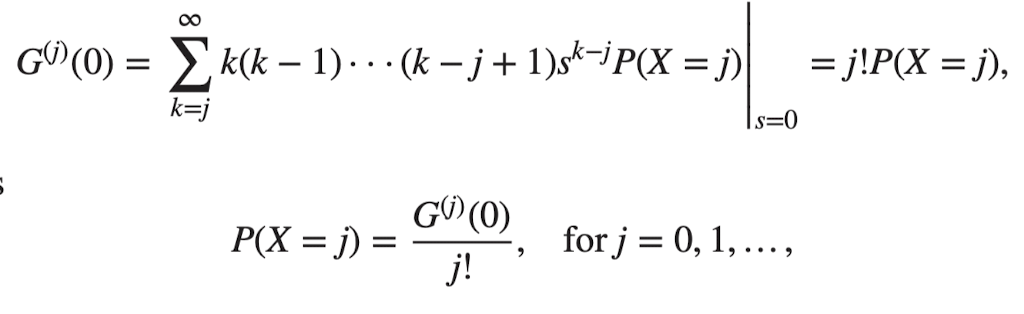
Sums of Independent Random Variables
이 서로 독립일 때, 이면 의 확률생성함수는
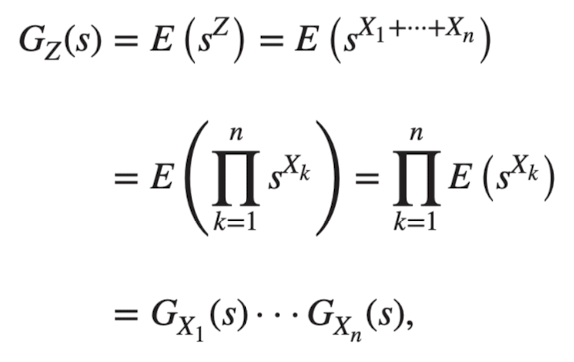
iid(independent and identically distributed: 서로 독립적이고 동일한 확률분포를 가진다) 조건까지 붙으면
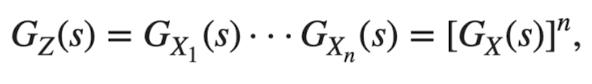
Moments
X의 확률생성함수로 평균과 분산을 구할 수 있음
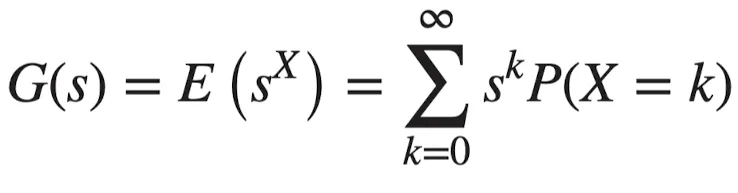
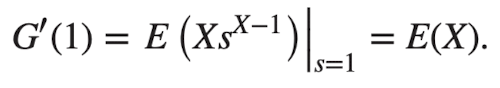
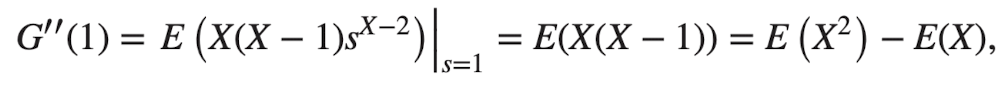
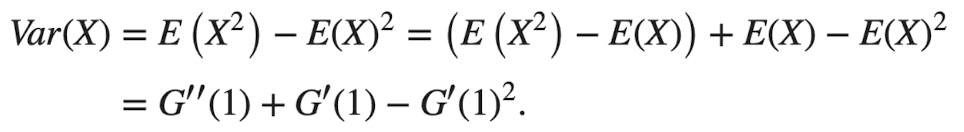
- 확률생성함수의 성질
- 가 이산확률변수 의 확률생성함수일 때
- → 정의에 의해 확률의 합 = 1
- for → example 4.3에서 보임
- → moments
- → moments
- 와 가 모든 에 대하여 인 확률변수이면 와 는 같은 분포 → 정의
- 와 가 독립이면 → sums of independent RV
PGF의 property로, 책에는 나와있지 않으나
💡P(X>1)>0이면 pgf G(s)는 strictly increasing하고 convex하다.
를 보이면 extinction probability 유도에서 G가 증가함수인 부분이랑 y=x와 pgf의 그래프 해석에서 convex하고 증가인 내용이 쓰이므로 소개하면 좋을 것 같음.
약식의 proof)
s가 0<s≤1이므로 모든 항이 non-negative하고, P(X>1)>0이므로 와 같이 s에 의존하는 항이 적어도 하나는 존재하므로 모두 strictly increasing 한다. 특히 pgf의 도함수가 증가하므로 pgf는 convex하다.
[참고]
교재에서 branching process를 정의할 때 으로 정의했기 때문에 P(X>1)은 반드시 0보다 클 수밖에 없다.
이 조건은 P(X=0)+P(X=1)=1로 인해 s에 의존하는 항이 모두 사라져 pgf의 도함수가 0이 되는 것을 방지하는 역할을 한다.
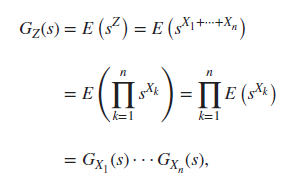
위 사진의 개념과 관련된 example 4.5로 Bin(n, p)를 pgf의 정의가 아닌 위의 성질을 이용하여 계산하는 예시가 나오는데, 비록 4.4 Extinction Probabilities에서 위 개념이 쓰이지는 않으나 offspring distribution이 binomial로 주어지는 경우가 꽤 존재하는 것 같아서 Bin(n, p)를 Bern(p)의 합으로 생각해 pgf를 구하는 과정을 설명은 안해도 언급은 하면 좋을 것 같음
4.4 Extinction is Forever
= 멸종은 영원하다 (한 번 멸종되면 되돌릴 수 없다. 멸종은 absorbing state이기 때문)
: 크기가 인 nth generation의 생성함수
: offspring dist.의 generating function (한 개인은 의 확률로 명의 아기를 낳음)
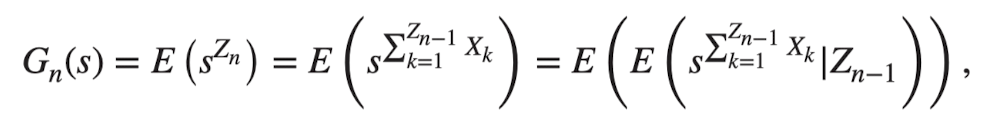
마지막 equality → law of total expectation
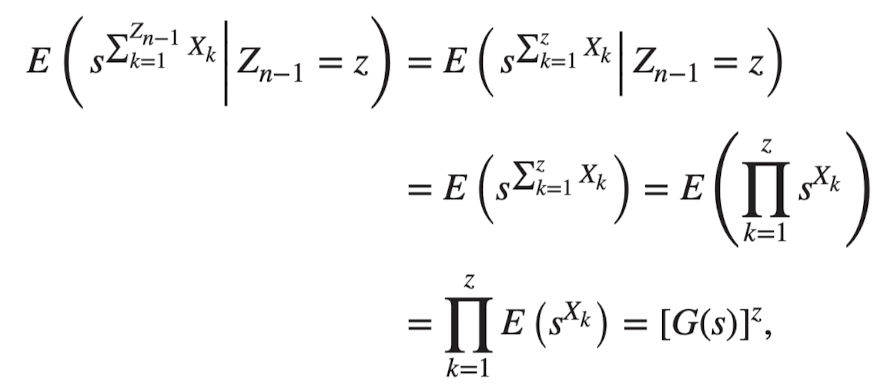
expectation 안의 수식에 대한 설명 (앞서 4.2에서 과 가 독립임을 보였기 때문에 조건부로 붙었던 이 없어져 다음과 같은 결과가 나옴)
→ 직관: n의 분포를 n-1단계의 결과를 기반으로 도출한다
예) G(s): 한 사람이 다른 사람을 감염시킬 확률
명의 사람들이 새로운 감염원을 만들 확률의 누적
이것의 전체적인 평균적인 효과가 다음 세대의 생성함수
: branching process 재귀함수 공식
재귀: 자기 자신을 다시 만들어낸다
이전 단계의 모든 개체가 새로운 G(s)에 따라 자손을 낳은 결과
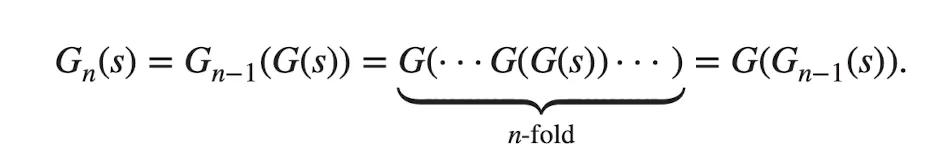
→ 의 생성함수는 offspring dist. 생성 함수의 n배로 구성된다.
→ 실제 의 분포를 구하는데는 유용하지 않으나 theorem 4.2의 첫번째 파트 증명하는데 사용되는 수식
- Extinction Probability (Theorem 4.2)
-
branching process하에서 G가 offspring dist.의 확률생성함수일 때, eventual extinction의 확률 (결국 소멸할 확률 e)은 의 가장 작은 양수 루트값이다.
-
인 경우 (subcritical, critical case),
이 theorem에서 주목해야 할 점
-
앞서 인 경우 임을 보임 (4.2에서)
-
그러나 이 theorem에서는 인 경우도 이며
-
인 경우도 임을 말하고 있음!
⇒ **$\mu>1$이어도** 소멸할 수 있다!example 4.7 → 인 경우의 extinction probability 계산
example 4.8 → geometric dist.인 offspring dist.의 extinction probability 계산
시뮬레이션을 사용하여 example 4.8의 extinction probability 결과를 살펴보자!
-
-
-

- branch (n, p) : parameter p를 가진 offspring dist.를 n번 branching process 시뮬레이션을 한 코드
- replicate : 시뮬레이션을 10000번 반복하겠다
- 각 시도에 대한 의 결과를 벡터 simlist에 저장함
- 0의 비율로 e(extinction probability)를 추정
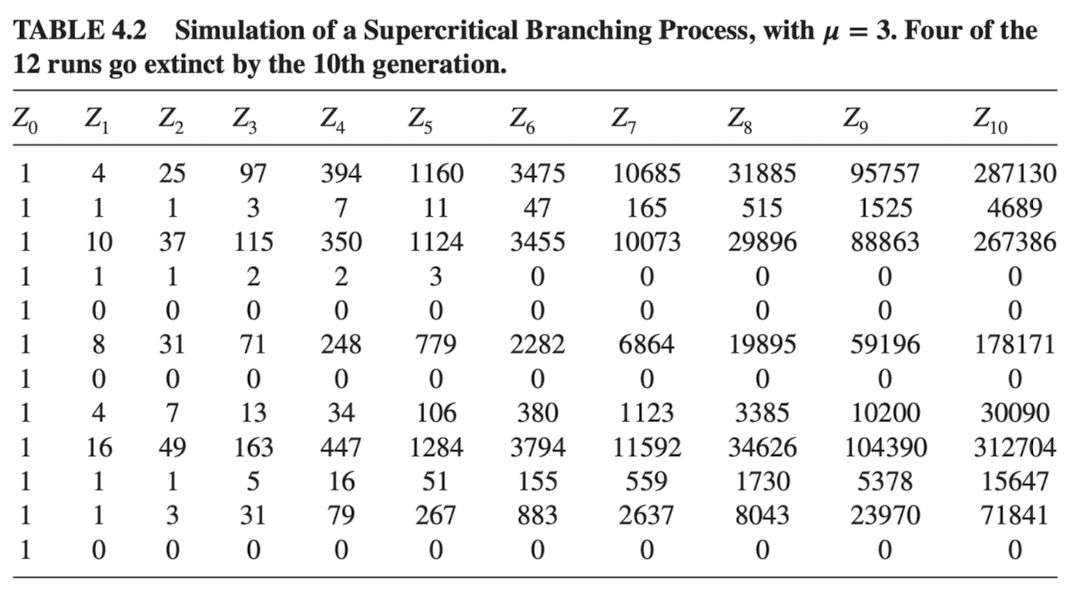
- 인 경우로 진행 → 12개 중 4개의 경우 extinct함을 확인 가능 ( )
example 4.9 Lotka의 소멸 확률(e) 추정 → 실제 사례
- Lotka는 1920년 인구 조사 데이터를 바탕으로 남성 혈통이 eventual extinction의 확률을 추정
- 계산을 통해 e = 0.819라는 것을 찾아냄.
- 남성 offspring dist.의 평균은 ( 인 경우!)
- 개인당 평균 자녀 수(아들 + 딸)가 약 2.5명임에도 불구하고 가족 성이 소멸될 확률이 80% 이상이라는 것이 흥미로운 점
⇒ 수식 계산 (example 4.7, 4.8) + R코드 구현 + 실제 사례 (example 4.9)를 통해
-
인 경우도 임을 말하고 있음! → 이걸 보여줌
-
theorem 4.2 proof
- branching process하에서 G가 offspring dist.의 확률생성함수일 때, eventual extinction의 확률 (결국 소멸할 확률 e)은 의 가장 작은 양수 근이다. → 재귀식을 이용한 수식 증명
- 인 경우 (subcritical, critical case),
- branching process하에서 G가 offspring dist.의 확률생성함수일 때, eventual extinction의 확률 (결국 소멸할 확률 e)은 의 가장 작은 양수 근이다. → 재귀식을 이용한 수식 증명
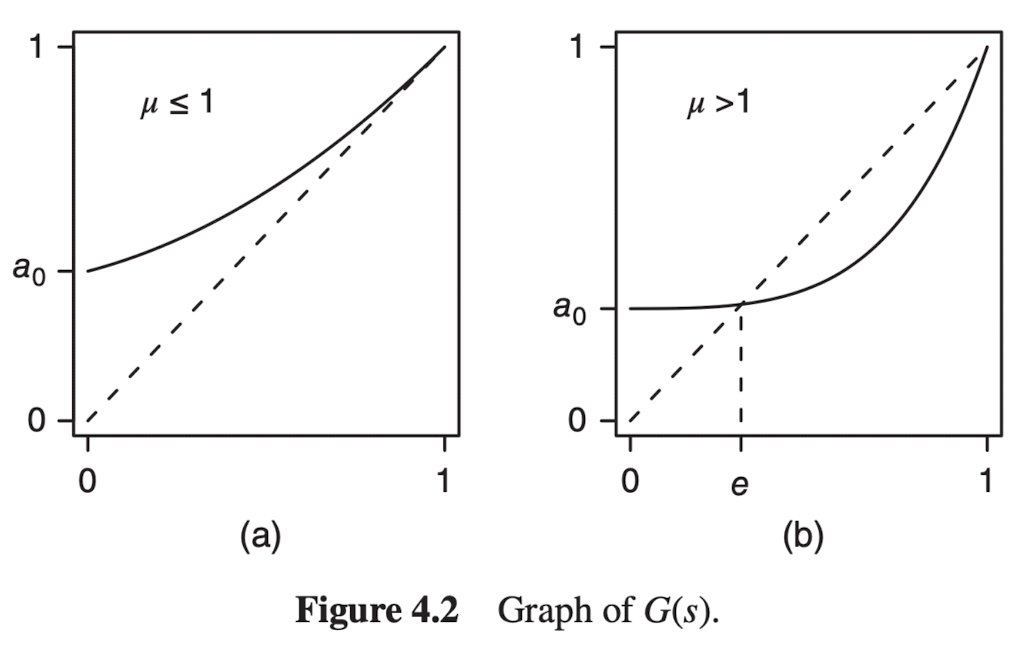
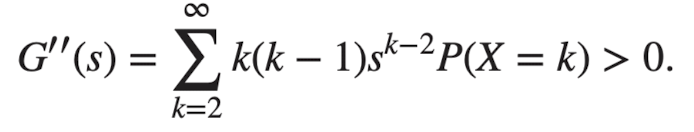
→ 이 수식에 따라 G(s)는 아래로 볼록한 형태 (이계도함수가 0보다 크기 때문)
: 모든 확률의 합 = 1 (확률생성함수의 성질)
→ 확률생성함수의 성질
(개인이 아이 0명을 낳을 확률 0과 1 사이)
(a)
0<s<1 (s가 기하급수적으로 작아지기 때문에 1이 될 수 없음)
이 말은 G(s)의 그래프의 기울기(순간변화율)가 항상 1보다 작다 = 직선 s보다 항상 위에 위치해야 한다.
따라서 1에서만 만남
(b)
이므로 중간에 선을 지나야
4.4 Extinction is Forever
💡앞 파트에서는 offspring distribution(한 개인의 자손 수 가 따르는 분포)의 평균 를 기준으로, 시간 이 충분히 커졌을 때(long-term), 개체수 가 멸종(0으로 흡수)되는지, 혹은 무한히 커지게 되는지를 살펴보았다.
- [subcritical] : 기댓값과 분산이 모두 0 → 반드시 멸종()
- [critical] : 기댓값은 1이지만 분산은 에 대해 선형적으로 증가 → 알 수 없음
- [supercritical] : 기댓값도 , 분산도 기하급수적으로 증가 → 알 수 없음
⇒ PGF를 도입해, 구체적인 멸종 확률 를 구해보자.
1. Relation between PGF of offspring distribution and
각 개체가 낳는 자손의 분포, offspring distribution를 라고 할 때, 이 분포에 대한 확률생성함수 PGF는 다음과 같이 정의할 수 있다.
그리고 번째 세대의 총 개체 수 에 대한 PGF는 다음과 같이 정의할 수 있다.
이때, branching process의 특성상 한 세대의 개체 수 분포는 이전 세대의 분포에 의해 결정되므로 다음과 같은 결론을 확인할 수 있다.
- proof\begin{align*} G_n(s) &= \text{E}(s^{Z_n}) \text{ by definition of PGF} \\ &= \text{E}\left(s^{\sum_{k=1}^{Z_{n-1}} X_k}\right) \\ & = \text{E}\left( \text{E}\left( s^{\sum_{k=1}^{Z_{n-1}}X_k}|Z_{n-1}\right)\right) \ \because \text{E}(X)=\text{E(E}(X|Y))\end{align*}\begin{align*} \text{E}\left( s^{\sum_{k=1}^{Z_{n-1}}X_k}|Z_{n-1}=z\right)&= \text{E}\left( s^{\sum_{k=1}^{z}X_k}|Z_{n-1}=z\right)\\ &= \text{E}\left(s^{\sum_{k=1}^z X_k}\right) \ \because Z_{n-1}\text{, } X_i \text{ : independent}\\ &= \text{E}\left( \prod _{k=1}^zs^{X_k}\right) \\ & = \prod _{k=1}^z \text{E} (s^{X_k}) \ \because X_i\text{' s : independent}\\ & = [G(s)]^z \end{align*}따라서, 다음의 결과를 얻을 수 있다. 이때 은 의 PGF에서 대신 가 들어간 꼴이다.위의 결과를 바탕으로, 귀납적으로 다음과 같은 규칙을 확인할 수 있다.
➡️ 번째 세대의 총 개체 수에 대한 PGF는 1) offspring distribution의 PGF를 번 합성하여 구하거나, 2) 번째 세대의 PGF를 이용해 구할 수 있다.
2. Extinction Probability
가 offspring distribution의 PGF이고, 는 평균, 는 멸종 확률이라고 하자. 다음과 같이 멸종 확률을 구할 수 있다.
- [subcritical + critical] :
- proof of 2 : n번째 세대에서 인구가 멸종할 확률이라고 하자. \begin{align*} e_n = P(Z_n=0) & = G_{n}(0) \ \because \text{PGF property } G(0) = P(X=0) \\ & = G(G_{n-1}(0)) \ \because G_n(s) = G(G_{n-1}(s)) \text{ for } n\ge 1 \\ & = G(P(Z_{n-1}=0))\\ & = G(e_{n-1}) \end{align*} \\ \text{Since } n\to \infin : e_n, e_{n-1} \to e, \ e= G(e)✅ 먼저, 가 의 근이 됨을 보였다. 하지만 근이 여러 개라면, 무엇이 멸종 확률 가 될까? 의 또 다른 양근을 라고 두자. 는 에서 증가 함수이므로, 다음을 확인할 수 있다.이제 양변에 를 번 합성하면, 다음과 같다.위의 부등식에 limit을 씌우면 다음과 같은 결과를 얻을 수 있다.✅ 멸종 확률 는 모든 양근 중 가장 작은 값이다.
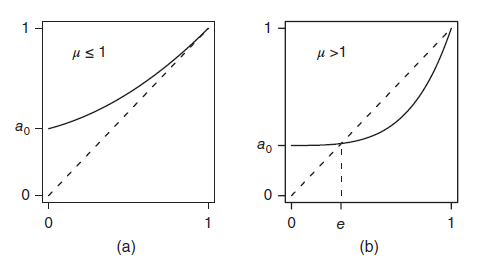
➡️ 일 때, 에서의 유일한 교차점은 이고, 그 교차점이 곧 멸종 확률 가 된다.
Example
(a)
- Root of :
⇒
(b)
- Root of :
⇒
(c)
- Root of :
⇒
3. Example + R
offspring distributipn이 와 같은 기하분포이며, branching process가 supercritical case일 때, 멸종 확률을 구해보자.
- PGF 구하기 (등비급수)
- 구하기
✅ 이때, 이면 로 supercritical case가 된다.
- 를 풀어서 멸종 확률 구하기
➡️ 에 대해, 멸종 확률은
- R 코드
branch(10, 1/4) #파라미터 p를 가진 기하 분포 -> n steps simulate
trials = 10000
simlist = replicate(trials, branch(10, 1/4)[11])
#simulation을 10000번 반복해서, Z_10 (마지막 인덱스의 값)이 0인지 확인
#멸종 확률 추정
sum(simlist == 0) / trials4. Recursive Method of finding Extinction Probability
의 해를 직접 구하기 어렵다면, 다음과 같은 반복적인 방법을 통해 근삿값을 구할 수 있다.
- 초기값 를 설정한다.
- 연속적으로 을 계산한다.
- 큰 에 대해, 이라고 둔다.
Example
일때, R을 활용해 멸종 확률을 근사적으로 구해보자. → 이 경우에는 에서만 양의 확률을 가진다(자손 수가 일 확률은 없음).
pgf = function(s) {
0.6 + 0.2*s^3 + 0.1*s^6 + 0.1*s^12}
x = 0.5 #initial value
e = pgf(x)
for (i in 1:100) {
e = pgf(e) }G: pgf of offspring distribution, : mean of offspring distribution, e:extinction probabliity
(a) ≤ 1 [Subcritical+Critical] : e=1
(b) >1 [Supercritical] : smallest positive root of equation s=G(s)
Note that equation s=G(s) for subcritical and critical also, but always results e=1, therefore no need to solve the equation.
Proof)
(b)
n세대에 인구가 멸종할 확률 으로 정의하자.
n이 무한대로 가면 e_n→e이므로 e=G(e)
[의의: s=G(s) 식에서 e는 반드시 근이 됨. 하지만 근이 더 있을 수 있는데 s=G(s)의 근이 여러개라면 여러개의 근 중 무엇이 e가 돼야할까?]
s=G(s)의 또 다른 양근을 x라 하자. G는 (0, 1]) 에서 증가함수이므로
G(0)≤G(x)=x. 여기서 양변에 G를 n번 합성하면
G(G(G(…G(0)…))) ≤ G(G(G(…G(x)…)))=x 이고, n을 무한대로 보내면
≤ x
따라서, extinction probability e 는 모든 s=G(s)의 양근 중 가장 작은 값이 된다.
(a)
Note that pgf is strictly increasing and convex if P(X>1)>0,
and
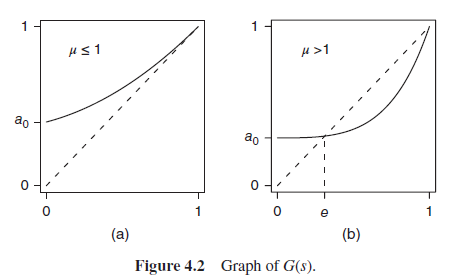
직관) 이면 s=1에서의 미분계수가 1보다 작거나 같아야하고, 증가하는 convex함수이므로 s=G(s)의 그래프와 만나지 않고 G(1)=1에서만 만날 것이라 직관적으로 생각해볼 수 있다.
따라서, 1만이 유일한 교점이 되어 =1
직관) 이면 0과 1에서 e=G(e)인 지점이 반드시 존재해야 할 것을 생각해볼 수 있다.
특히 이여도 증가하는 convex함수이므로 1보다 작은 s에 대해서 G’(s)는 1보다 작을 것이고, 따라서 s=G(s)의 교점이 s=1에서만 생기는 것은 변함이 없을 것이다.
