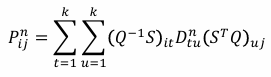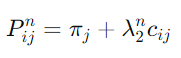
5.1 Introduction
Reminder
💡Ergodic Markov Chain
: Finite Markov Chain이
① Irreducible[기약성]: 어떤 상태에서 출발하더라도 모든 상태에 도달 가능
② Aperiodic[비주기성]: 모든 state의 period가 1 (일정한 주기 없이 방문 가능)
하면 Ergodic Markov Chain 이 된다.
💡Fundamental Limit Theorem for Ergodic Markov Chains
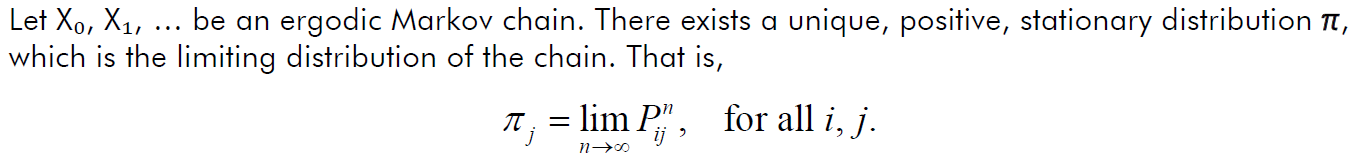
→ Ergodic Markov Chain에서는 정상분포가 unique, positive하고 그것이 극한분포와 같다.
💡Time Reversibility
Irreducible Marcov Chain 에 대해
가 성립하면(Detailed Balance Condition)
Time Reversible
→ Stationary dist.에 도달했다면 Chain을 거꾸로 진행해도 동일하다.
역으로, 을 만족하는 는
P를 전이행렬로 가지는 Markov Chain의 Stationary Distribution이 된다.
Markov Chain Monte Carlo
-Monte Carlo Method: 복잡한 문제를 근사적으로 해결하기 위해 난수를 생성하는 기법
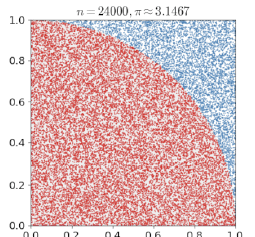
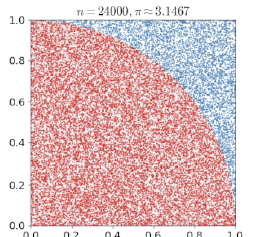
(ex) 한변이 1인 정사각형 안에 사분원을 만들고 무작위로 정사각형 내부에 점을 찍으면, 점이 사분원에 있는 확률은 /4에 근사함.
-Markov Chain Monte Carlo:
Monte Carlo Method의 원리를 기반으로 Markov Chain을 활용하여, 우리가 샘플을 얻고자 하는 어떤 타켓분포로부터 랜덤 샘플을 얻는 방법
→ 목표분포를 Stationary distribution으로 가지는 Markov chain을 만들어보자!
💡Strong Law of Large Numbers
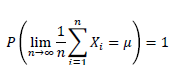
→ iid한 Xi들의 표본평균은 확률적으로 기댓값에 수렴한다.
💡Strong Law of Large Numbers for Markov Chains
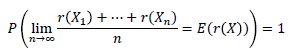
[Xi는 를 정상분포로 가지는 Ergodic Markov Chain, X는 를 분포로 하는 확률변수]
→ 시간이 충분히 지나면 Markov Chain에서의 sampling이 타겟분포 에서의 iid sampling처럼 동작
[MCMC의 활용예시: Binary Sequences with No Adjacent 1s]
0과 1로 이루어진 길이 m의 배열에 대해, 배열 안에 연속된 1이 없으면 ‘좋은 배열’이라고 하자. ‘좋은 배열’에서 1의 개수의 기댓값은?

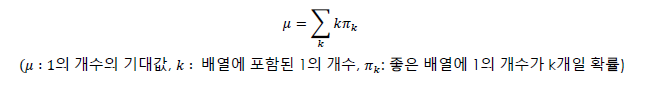
→Simulation을 통한 접근, 배열 x에 포함된 1의 개수를 r(x)라고 할때
by Strong Law of Large Numbers.
따라서, good sequence Y1~Yn을 simulate만 하면 되며, 여기에 MCMC를 사용할 수 있다.

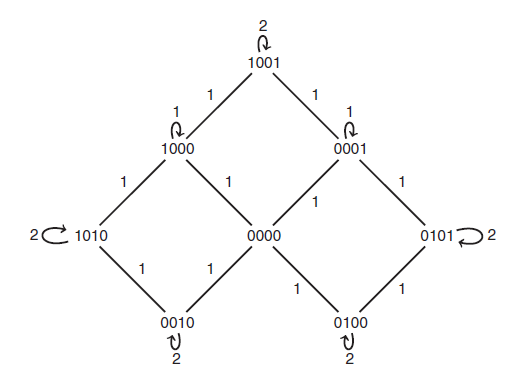
Weighted Graph의 Random Walk로 MCMC 적용가능!
5.2 M-H Algorithm
M-H Algorithm란?
- MCMC의 대표적인 예시
- 타겟 분포를 직접 샘플링하기 어렵기 때문에 Proposal Distribution을 사용하여 새로운 샘플을 제안하고, Acceptance Function을 통해 샘플을 수락하거나 거부.
과정
- 초기화
- 초기 상태 을 state space 내에서 설정.
- Markov Chain의 상태 전이
- 현재 상태 에서 다음 상태 을 결정하는 과정:
-
Proposal State j 선택
- 전이 행렬 (Proposal Distribution)에서 새로운 상태 를 선택.
- 는 irreducible Markov Chain이 되어야 함 (모든 상태를 방문 가능해야 함).
- 전이 행렬 (Proposal Distribution)에서 새로운 상태 를 선택.
-
Acceptance Probability 계산
- 제안된 상태 j를 수락할 확률(acceptance function) 계산
-
수락 또는 거부
- 이면 : 무조건 수락
- 이면 확률 을 샘플링하여 비교:
- → : 수락
- : 기각, 유지
-
- 현재 상태 에서 다음 상태 을 결정하는 과정:
M-H algorithm이 왜 타겟 분포 에서 샘플링할 수 있는가?
💡The sequence constructed by M-H algorithm is a reversible MC whose stationary distribution is
M-H 알고리즘으로 생성된 샘플 시퀀스는 Markov Chain을 형성하고 이 Markov Chain은 reversible한 성질을 가지며, 시간이 지나면 정상 분포 로 수렴한다.
증명
- irreducible Markov Chain에 대해서 detailed balance condition을 만족하면 reversible
임을 보이자
- : i→j로의 전이확률 = {다음 상태로 j가 제안될 확률} x {제안된 j가 수락될 확률}
- 다음 상태로 j가 제안될 확률:
- 제안된 j가 수락될 확률:
- 즉,

Example: Power-law distrubtion
power-law distribution:
⇒ Solution: M-H algorithm에서 power-law 분포 sampling한다. 이를 하기 위해서, Markov Chain의 stationary distribution이 여야 한다.
Proposal Distribution 와 Acceptance Function 를 적절히 설계해야 합니다.
- Proposal Distribution
- simple symmetric random walk: 현재 상태 에서 또는 로 이동할 확률이 . 단, 일 때는 무조건 로 이동하도록 설정 (Reflecting Boundary at 1).
- Acceptance Function
- Case 1:
- Case 2: 일반적인
- 가 클수록 로 이동하는 확률이 작아짐: Power-law 분포의 특성을 반영하는 부분
5.3 Gibbs Sampling
1. Gibbs sampling 종류
| 종류 | 특징 | sample로 채택 | 한 step |
|---|---|---|---|
| Systemic (fixed) scan gibbs sampling | 정해진 좌표 순서대로 업데이트 | 모든 좌표를 업데이트 한 점 | 모든 좌표 갱신 |
| Random scan gibbs sampling | 랜덤으로 뽑은 좌표를 업데이트 | 한 좌표를 업데이트 한 점 | 한 좌표 갱신 |
-
Systemic Gibbs sampling 진행 방식
- 과정
- 초깃값 (x0,y0) 설정
- X|Y=y0 에서 x1 뽑음 → (x1, y0)
- Y|X=x1 에서 y1 뽑음 → (x1, y1)
- (x1,y1)를 sample로 가져간다!
- 예시: 정해진 업데이트 순서가 x→y→z일 때
- (x0,y0,z0) → (x1,y0,z0) → (x1,y1,z0) → (x1,y1,z1) → (x2,y1,z1) → (x2,y2,z1) → (x2,y2,z2) → (x3,y2,z2) → (x3,y3,z2) → (x3,y3,z3)
- 과정
-
Random Gibbs sampling 진행 방식
- 과정
- 초깃값 (x0,y0) 설정
- 0.5의 확률로 x와 y중 하나 선택 → x가 나왔다고 가정해보자
- X|Y=y0 에서 x1 뽑음 → (x1, y0)
- 0.5의 확률로 x와 y중 하나 선택 → x가 나왔다고 가정해보자
- X|Y=y0 에서 x2 뽑음 → (x2, y0)
- 0.5의 확률로 x와 y중 하나 선택 → y가 나왔다고 가정해보자
- Y|X=x2 에서 y1 뽑음 → (x2, y1)
- 예시: 1/3의 확률로 x,y,z 중 뽑았을 때 → y,z,x,x가 나왔다고 가정
- (x0,y0,z0) → (x0,y1,z0) → (x0,y1,z1) → (x1,y1,z1) → (x2,y1,z1)
- 과정
2. Acceptive Function of Gibbs sampler
gibbs sampler의 acceptive function은 1이다.
- 증명
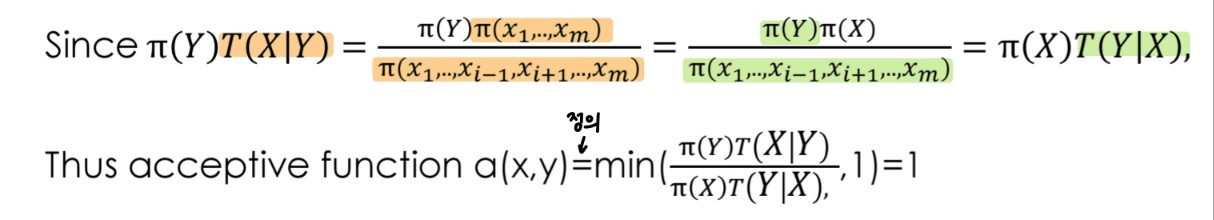
- 의미: 제안된 값을 reject 없이 무조건 accept한다는 의미이다. reject이 없으므로 조건부 분포에서 동일한 값이 추출되지 않는 이상 직전의 sample과 항상 다르다.
3. Time-reversibility
- 사용되는 성질: (Irreducible MC에 대해) Detailed Balance Condition 만족한다면, Gibbs를 통해 생성된 sample은 를 stationary dist로 하는 reversible Markov chain이 된다.
- Detailed Balance Condtion:
- random Gibbs는 M-H의 일종으로 볼 수 있고 (인 case), time-reversible하다!
- 증명
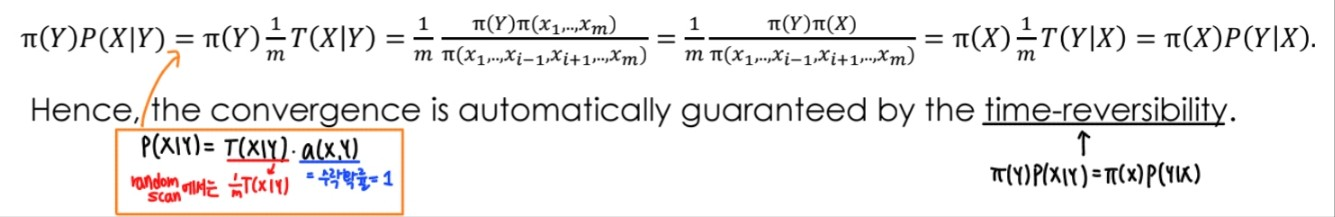
- 증명
- Fixed scan Gibbs는 sample 정의에 따라 Detailed balance condition을 만족하기도, 안하기도 한다. 그러나 만족하지 않더라도, stationary dist가 존재함이 알려져있다.
sample Detailed balance condition case1 (x0,y0) → (x0,y1) → (x1,y1) 만족X case2 (x0,y0) → (x0,y1) → (x1,y1) 만족
4. Autocorrelation을 줄이기 위한 방법
- 자기상관: t시점과 그로부터 k시점 후의 상관관계 → 즉 표본들이 얼마나 독립적인지를 나타내는 좌표 (낮을수록 독립적)
- 낮추기 위한 방안: Burn-in, Thinning
-
Burn-in
- chain의 초반 sample들은 목표 분포에 충분히 수렴하기 전의 데이터이므로 앞의 적당한 수의 sample을 버리는 방법
- 얼마나 버릴지는 plot을 보고 결정하거나, Gelman-Rubin Statistics를 보고 결정
-
R이 1.1 이하 일 때 수렴했다고 본다.

-
-
Thinning: 쉽게 말해, 띄엄띄엄 sample을 가져가는 방법
- 연속된 값들은 자기상관이 높게 나타나니까, 1번째, 11번째, 21번째, 31번째 sample만을 가져다 쓰는 방법이다
- 간격 정하는 방법: 상관성이 클수록 간격을 크게 설정
5.4 Perfect Sampling
1. Perfect Sampling
“체인을 얼마나 오래 돌려야 정상 상태(stationarity)에 가까워질까?”
무한 과거에서 현재로 돌아오며 정상 분포에 수렴한 상태를 찾는 과정
- 알고리즘 원리
- Ergodic Marcov Chain이 극한 분포 를 가진다고 가정
시간이 무한히 흘러 t=0에 도달하면 이미 정상 분포 에 도달했을 가능성이 큼
- 여러 개의 체인을 서로 다른 초기 상태에서 시작시킴
시간이 거꾸로 흐르면서 모든 체인이 병합될 때까지 시뮬레이션 진행
병합되면 정상 상태에 도달한 것으로 간주하고, 정상 분포에서 추출한 표본으로 선택
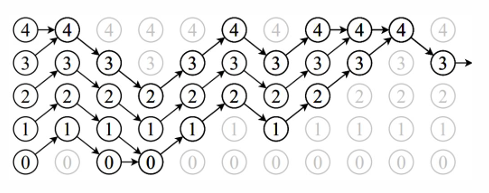
- 각 체인은 시간이 지날수록 동일한 상태로 병합
- 병합된 상태가 정상 분포의 표본
- 이산형 Markov Chain에서 사용
2. Inverse Transform Method
- 누적분포함수를 이용해 난수로부터 값을 반환하는 방법
- 난수 ∼Unif(0,1)를 생성 후, 누적분포함수의 역함수 ()로 값을 결정
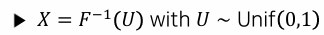
난수 의 값에 따라 반환값 가 결정됨
이산형 변수의 경우 공식
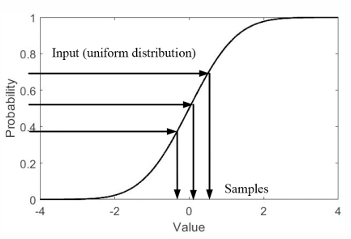
x축: 상태
y축: 누적 확률 값
(예시)
- State Space: {a,b,c,d}
- 확률 분포: p=(0.1,0.2,0.3,0.4)
- 난수 ∼Unif(0,1)를 생성해 반환값을 결정
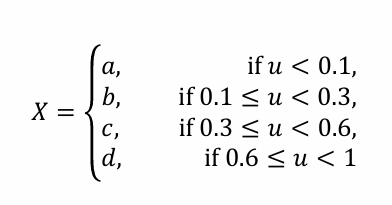
Update Function
- Markov Chain의 전이 과정을 Update Function으로 정의
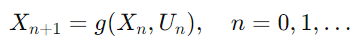
- 전이 행렬 에 따라 를 이용해 다음 상태를 결정

(예시)
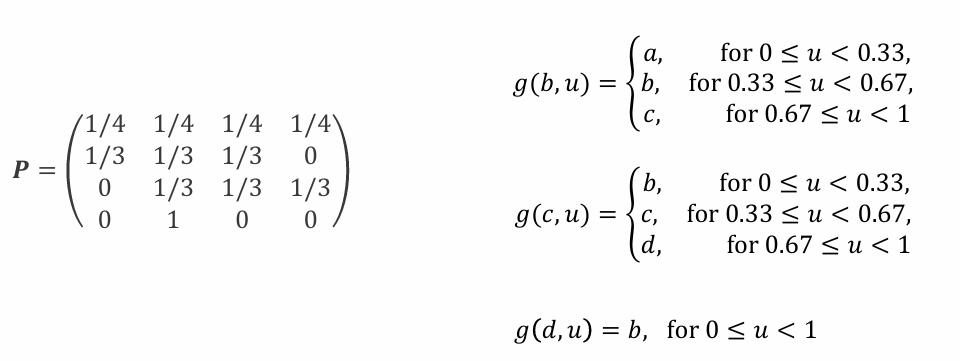
Perfect Sampling
:정상 분포로부터 완벽한 표본을 추출하는 알고리즘.
- 먼저 , , ⋯를 Uniform(0,1) 분포에서 난수로 생성한다.
- 시간을 거슬러 올라가며( = -1, -2, …) 각 체인을 시뮬레이션한다.
- 모든 체인이 동일한 상태로 병합될 때까지 반복하며, 그 상태를 정상 분포의 표본으로 간주한다.
Perfect Sampling with R Code
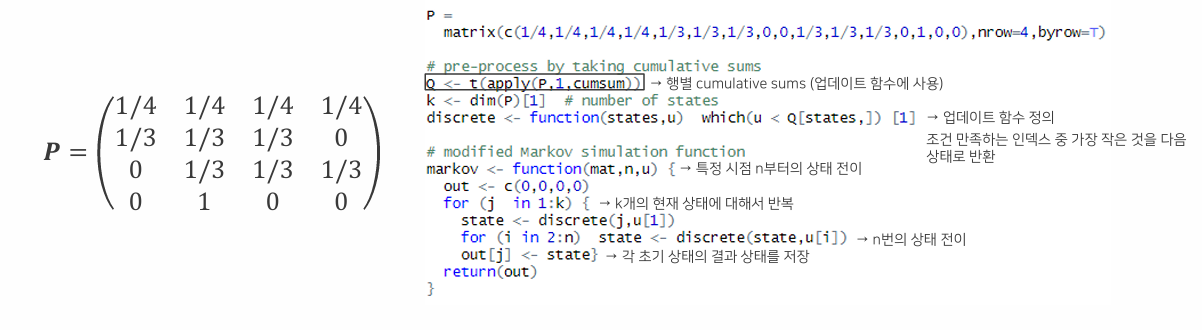
- 전이 행렬 : 상태 전이 확률을 정의.
- 누적합 계산: 전이 구간 설정을 위해 행별 누적합 계산.
- markov 함수: 현재 상태에서 난수로 다음 상태를 결정.

- 시뮬레이션 반복: 30,000번 반복해 정상 분포를 추출.
- 결과 요약: 각 상태의 비율을 확인해 정상 분포 비율을 계산.
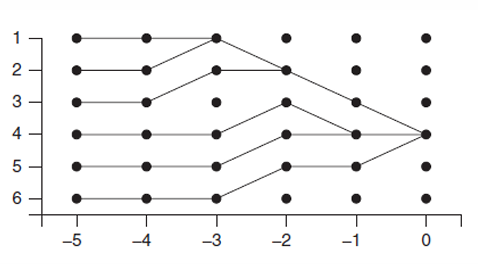
Monotonicity (단조성)
- 상태가 순서를 보존하면서 전이하는 특성.
조건:
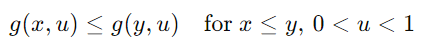
단조성에서의 최소·최대 경로
단조적인 Markov Chain에서는 모든 경로가 특정 두 경로 사이에서 제한됨.
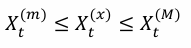
3. Rate of Convergence
타겟 분포에서 샘플링의 적절성을 평가하려면 rate of convergence를 확인해야 한다.
- 핵심 내용: 수렴 속도는 전이 행렬의 두 번째로 큰 고윳값에 의해 결정된다.
- 전제 조건: finite, reversible, ergodic한 Markov Chain이 필요하다.
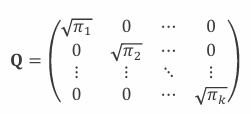
행렬은 limiting distribution 의 각 원소에 대해 제곱근을 대각선 원소로 갖는 행렬.
이때 는 limiting distribution로 모든 원소가 positive여야 의 역행렬 을 구할 수 있다.
행렬 A의 정의와 고유값 계산
A는 대칭 행렬로, 모든 고유값이 실수
고유값을 크기 순으로 정렬하면,
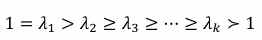
Spectral Representation Formula