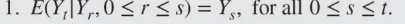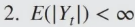8.1 Introduction
Standard Brownian Motion
📌
Notation
(B t ) t ≧ 0 B_t)_{t\geqq 0} B t ) t ≧ 0
B t B_t B t x x x
P ( B t ≤ z ) P(B_t\leq z) P ( B t ≤ z ) z z z
1차원 브라운 운동 - 위치는 반드시 R \mathbb{R} R
R n \mathbb{R}^n R n B t = ( B t ( 1 ) , … , B t ( n ) ) \mathbf{B}_t = (B_t^{(1)},\dots,B_t^{(n)}) B t = ( B t ( 1 ) , … , B t ( n ) )
Definition
아래 5가지를 만족하면 표준 Brownian motion를 만족
B 0 = 0 B_0=0 B 0 = 0
Normal Dist. : B t B_t B t
B t ∼ N ( 0 , t ) B_t\sim\bold{N}(0,t) B t ∼ N ( 0 , t )
Stationary Inc : 시작시간이 0이든, s 든 상관없이 얼마나 움직였는지의 B B B
P ( B t + s − B s ≤ z ) = P ( B t ≤ z ) = ∫ − ∞ z 1 2 π t e − x 2 / 2 t d x P(B_{t+s} - B_s \leq z) = P(B_t \leq z) = \int_{-\infty}^{z} \frac{1}{\sqrt{2\pi t}} e^{-x^2/2t} \,dx P ( B t + s − B s ≤ z ) = P ( B t ≤ z ) = ∫ − ∞ z 2 π t 1 e − x 2 / 2 t d x
Independent inc : 겹치지 않는 시간구간 간의 변위는 서로 독립이다 ( 역시 포아송 과정과 동일)
0 ≤ q < r ≤ s < t , then B t − B s and B r − B q are independent random variables 0 \leq q < r \leq s < t, \text{then } B_t - B_s \text{ and } B_r - B_q \text{ are independent random variables} 0 ≤ q < r ≤ s < t , then B t − B s and B r − B q are independent random variables
Continuous : t → B t t→B_t t → B t
Continuous Markov Chain 과 Poisson, Brownian Motion 의 관계?
Markov Property : 무기억성 - 조건부 독립
P ( X t + h ∈ A ( X u ) u ≤ t ) = P ( X t + h ∈ A X t ) . P(Xt+h∈A(Xu)u≤t)=P(Xt+h∈AXt). P ( X t + h ∈ A ( X u ) u ≤ t ) = P ( X t + h ∈ A X t ) .
조건부 독립 - 현재 상태가 주어졌을 때, 미래값이 정해짐, 즉 겹치지 않는 시간이 아예 무관하다는 것을 보장하지 않음
Independent increments : 독립증분
Independent inc 면 Markov Property를 항상 가지지만, 그 역은 항상 참은 아님
Brownian motion이나 Continuous MC는 Ind inc 면서 Markov Property 만족
고객이 1명인 상태의 Markov Chain 대기행렬 (M/M/1) 등은 markov property를 가지지만 독립 증분을 만족하지 않음. (고객 도착시간, 서비스 시간 모두 지수분포, 서버는 1명)
→ 겹치지 않는 시간대라도 대기시간 W q W_q W q
예제 2. P ( B s ≤ 3 ∣ B 2 = 1 ) \displaystyle P\bigl(B_s \le 3 \,\big|\; B_2 = 1\bigr) P ( B s ≤ 3 ∣ ∣ ∣ B 2 = 1 )
P ( B 3 ≤ 2 ) \displaystyle P(B_3 \le 2) P ( B 3 ≤ 2 )
독립증분 & 마코프성
표준 브라운 운동은 “독립증분”과 “MarkovProperty” 만족
시점 t=2에서 B 2 = 1 B_2=1 B 2 = 1 ( B s − B 2 ) (B_s - B_2) ( B s − B 2 )
포아송 과정과 동일
예제 3. C o v ( B s , B t ) = ? \displaystyle \mathrm{Cov}(B_s, B_t)=? C o v ( B s , B t ) = ?
C o v ( B s , B t ) = min ( s , t ) = s \mathrm{Cov}(B_s, B_t) = \min(s,t) = s C o v ( B s , B t ) = min ( s , t ) = s
증명 : C o v ( B s , B t ) = E [ B s B t ] − E [ B s ] E [ B t ] = E [ B s B t ] Cov(B_s,B_t)=E[B_sB_t]−E[B_s]E[B_t]=E[B_sB_t] C o v ( B s , B t ) = E [ B s B t ] − E [ B s ] E [ B t ] = E [ B s B t ] ( E [ B s ] = E [ B t ] = 0 ) . (E[B_s]=E[B_t]=0). ( E [ B s ] = E [ B t ] = 0 ) .
그런데 B t = B s + ( B t − B s ) B_t=B_s+(B_t−B_s) B t = B s + ( B t − B s ) B s 와 ( B t − B s ) B_s와 (B_t−B_s) B s 와 ( B t − B s ) E [ B s B t ] = E [ B s ( B s + ( B t − B s ) ) ] = E [ B s 2 ] + E [ B s ( B t − B s ) ] . \mathbb{E}[\,B_s B_t\,] = \mathbb{E}[\,B_s \,\bigl(B_s + (B_t - B_s)\bigr)\,] = \mathbb{E}[\,B_s^2\,] + \mathbb{E}[\,B_s\, (B_t - B_s)\,]. E [ B s B t ] = E [ B s ( B s + ( B t − B s ) ) ] = E [ B s 2 ] + E [ B s ( B t − B s ) ] .
앞서 def 에서 B t B_t B t
따라서 C o v ( B s , B t ) = m i n ( s , t ) = s Cov(B_s,B_t) = min(s,t)=s C o v ( B s , B t ) = m i n ( s , t ) = s
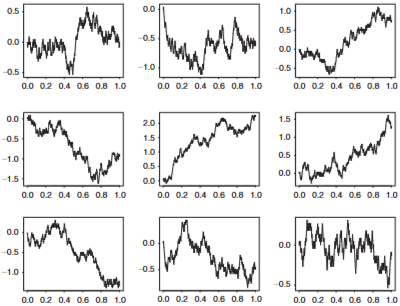
Simulation of Brownian Motion
구간 [0,t] 를 n개의 시점으로 균등분할해, 각 n개의 시점의 위치변수를 생성하고 다음과 같이 정의
→ B t 1 , B t 2 , … , B t n B_{t1} , B_{t2} , … , B_{tn} B t 1 , B t 2 , … , B t n
독립증분과 정상증분을 이용해 X i X_i X i
B t i = B t i − 1 + ( B t i − B t i − 1 ) → d B t i − 1 + X i B_{t_i} = B_{t_{i-1}} + (B_{t_i} - B_{t_{i-1}})\xrightarrow{d} B_{t_{i-1}} + X_{i} B t i = B t i − 1 + ( B t i − B t i − 1 ) d B t i − 1 + X i
X i ∼ N ( 0 , t i − t i − 1 ) X_i \sim N(0,t_i-t_{i-1}) X i ∼ N ( 0 , t i − t i − 1 ) X i ∼ N ( 0 , t n ) X_i \sim N(0,\frac{t}{n}) X i ∼ N ( 0 , n t )
따라서 B t i B_{t_i} B t i B t i − 1 B_{t_{i-1}} B t i − 1 t n \sqrt{\frac{t}{n}} n t
결국 아래와 같이 표기 가능
B t i = B t i − 1 + t n Z i , for i = 1 , 2 , … , n B_{t_i} = B_{t_{i-1}} + \sqrt{\frac{t}{n}}Z_i, \quad \text{for } i = 1, 2, \ldots, n B t i = B t i − 1 + n t Z i , for i = 1 , 2 , … , n
결국 시뮬레이션은 잘게 쪼갠 t n \frac{t}{n} n t t n \frac{t}{n} n t
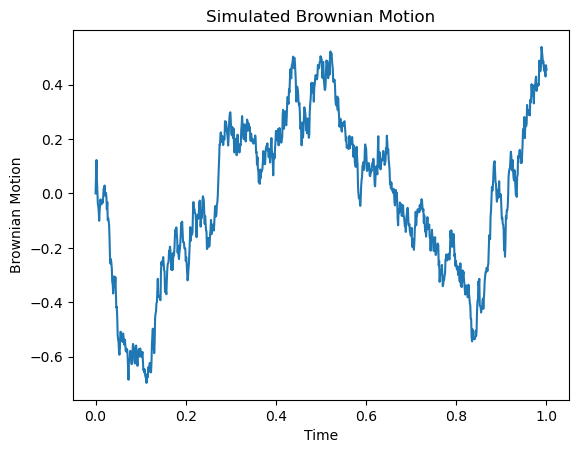
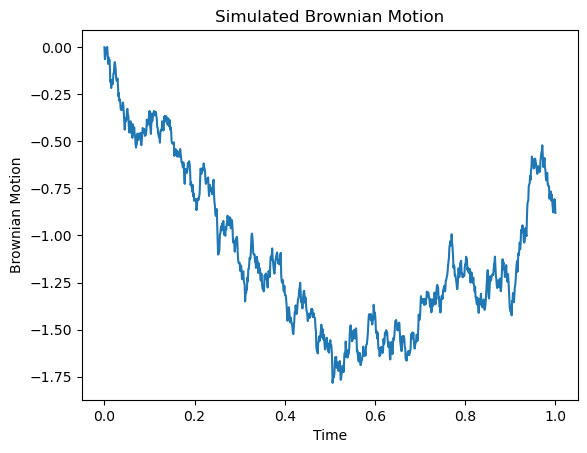
시뮬레이션
import numpy as np
import matplotlib.pyplot as plt
# 파라미터 설정
n = 1000 # 스텝 수
t = 1 # 전체 시간
dt = t / n
# 브라운 운동 시뮬레이션: 첫 값 0에 이어서 정규분포 난수의 누적합
increments = np.random.normal(0, np.sqrt(dt), n)
bm = np.concatenate(([0], np.cumsum(increments)))
# 시간 스텝 생성
steps = np.linspace(0, t, n + 1)
# 결과 플롯
plt.plot(steps, bm)
plt.xlabel("Time")
plt.ylabel("Brownian Motion")
plt.title("Simulated Brownian Motion")
plt.show()
그냥 짧은 시간단위로 시간 길이에 비례하는 정규분포 R.V 값 계속 더하면 시뮬레이션이 되네?
→ 그렇게 Random Walk 와 Gausian Process 연결
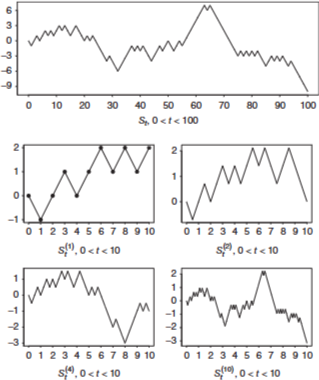
8.2 Brownian Motion
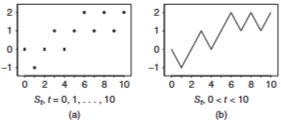
< Random Walk >
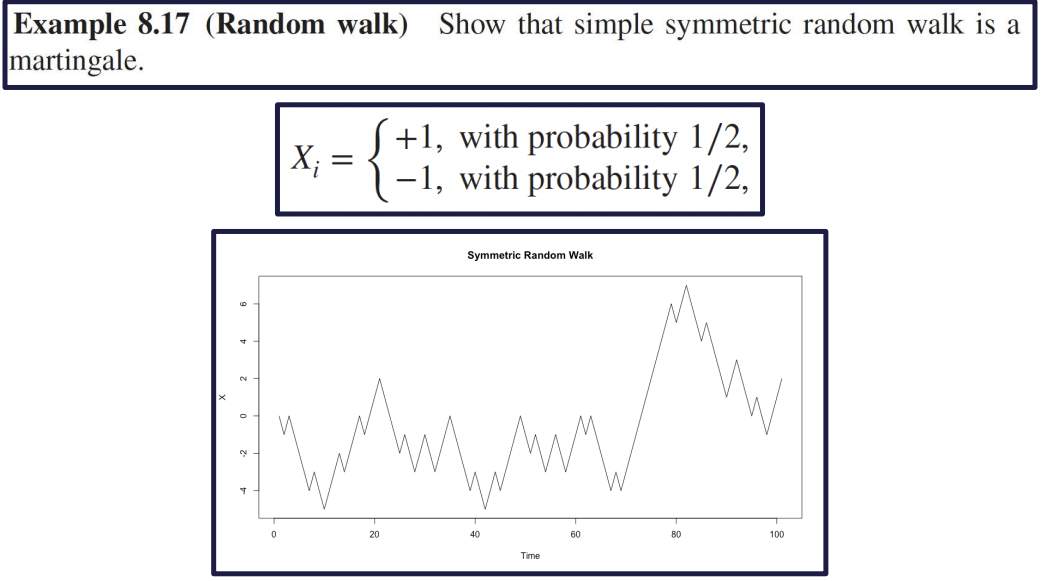
이산적 step 마다 1/2 확률로 1 or -1 을 더하는 sequence
시작 값 0, 최종 값은 각 step의 더하는 값 R.V : X i X_i X i
S t {S_t} S t
X 1 , X 2 , . . . X_1, X_2, ... X 1 , X 2 , . . . S 0 = 0 S_0 = 0 S 0 = 0 S t = X 1 + . . . + X t S_t = X_1 + ... + X_t S t = X 1 + . . . + X t
< Brownian Motion간의 유사성 >
S 0 = 0 S_0 = 0 S 0 = 0 S t ≈ N ( 0 , t ) S_t ≈ N(0,t) S t ≈ N ( 0 , t ) ( E ( S t ) = 0 , V a r ( S t ) = t ) ( E(S_t) = 0, Var(S_t) = t ) ( E ( S t ) = 0 , V a r ( S t ) = t ) S t + s − S s = X s + 1 + . . . + X t + s d = S t S_{t+s} - S_s = X_{s+1} + ... + X_{t+s} d= S_t S t + s − S s = X s + 1 + . . . + X t + s d = S t S t − S s S_t - S_s S t − S s S r − S q S_r - S_q S r − S q 함수연속성만 다름
E ( S t ) = 0 , V a r ( S t ) ≈ t E(S_t)=0, Var(S_t)\approx t E ( S t ) = 0 , V a r ( S t ) ≈ t
원래 random walk 보다 스케일링 시켜, 같은 시간동안 n배 많은 walk 이 있다고 하자,
결국 Random Walk 라는 discrete state process 는 n → ∞ n→ \infin n → ∞
증명 생략
S t ( n ) S_t^{(n)} S t ( n ) S t S_t S t
n 이 커질수록 brownian 형태를 띔
8.3 Gaussian Process
브라운 운동이 가우시안 과정이 됨을 확인
가우시안 과정이 브라운 운동이 되기 위한 조건 확인
이런 선형조합이 정규분포를 따르면, 확률변수열 X 1 … X k X_1…X_k X 1 … X k
def : Gausian Process
μ = ( μ 1 , … , μ k ) = ( E ( X 1 ) , … , E ( X k ) ) \mu = (\mu_1, \ldots, \mu_k) = (E(X_1), \ldots, E(X_k)) μ = ( μ 1 , … , μ k ) = ( E ( X 1 ) , … , E ( X k ) )
V i j = Cov ( X i , X j ) , for 1 ≤ i , j ≤ k . V_{ij} = \text{Cov}(X_i, X_j), \quad \text{for } 1 \leq i, j \leq k. V i j = Cov ( X i , X j ) , for 1 ≤ i , j ≤ k .
f ( x ) = 1 ( 2 π ) k / 2 ∣ V ∣ 1 / 2 exp ( − 1 2 ( x − μ ) T V − 1 ( x − μ ) ) f(x) = \frac{1}{(2\pi)^{k/2} |V|^{1/2}} \exp\left(-\frac{1}{2}(x - \mu)^T V^{-1} (x - \mu)\right) f ( x ) = ( 2 π ) k / 2 ∣ V ∣ 1 / 2 1 exp ( − 2 1 ( x − μ ) T V − 1 ( x − μ ) )
A Gaussian process ( X t ) t ≥ 0 (X_t)_{t≥0} ( X t ) t ≥ 0 n = 1 , 2 … n=1,2… n = 1 , 2 … 0 ≤ t 1 < ⋅ ⋅ ⋅ < t n 0 ≤ t_1 < · · · < t_n 0 ≤ t 1 < ⋅ ⋅ ⋅ < t n X t 1 … X t n X_{t1}… X_{tn} X t 1 … X t n
Gaussian Process 는
mean function E ( X t ) , f o r t ≥ 0 E(X_t), for\ t ≥ 0 E ( X t ) , f o r t ≥ 0
covariance function C o v ( X s , X t ) Cov(X_s, X_t) C o v ( X s , X t ) f o r s , t ≥ 0 for \ s, t ≥ 0 f o r s , t ≥ 0
이 둘에 의해 완전히 결정됨.
가우시안 → 브라운 조건
B 0 = 0 B_0=0 B 0 = 0 mean function은 모든 t에서 0
Cov function은 모든 s,t 에서 min(s,t)
함수 연속성
→ 그냥 2번 정규성 조건만 가우시안 과정이라 맞췄으니까 1,3,4,5 조건 맞추면 Brownian motion 이란 말.
Nowhere Differentiable paths : 브라운 운동의 경로는 전 구간 미분 불가
브라운 운동의 변환. 표준 브라운운동을 변환해도 그대로 브라운 운동
Let ( B t ) t ≥ 0 (B_t)_{t≥0} ( B t ) t ≥ 0
Property :
Markov Property
discrete-time discrete-state : P ( X n + 1 = j ∣ X 0 = x 0 , . . . , X n − 1 = x n − 1 , X n = i ) = P ( X n + 1 = j ∣ X n = i ) P(X_{n+1} = j | X_0 = x_0, ..., X_{n-1} = x_{n-1}, X_n = i) = P(X_{n+1} = j | X_n = i) P ( X n + 1 = j ∣ X 0 = x 0 , . . . , X n − 1 = x n − 1 , X n = i ) = P ( X n + 1 = j ∣ X n = i )
continuous-time discrete-state : P ( X t + s = j ∣ X s = i , X u = x u , 0 ≤ u ≤ s ) = P ( X t + s = j ∣ X s = i ) P(X_{t+s} = j | X_s = i, X_u = x_u, 0 \leq u \leq s) = P(X_{t+s} = j | X_s = i) P ( X t + s = j ∣ X s = i , X u = x u , 0 ≤ u ≤ s ) = P ( X t + s = j ∣ X s = i )
continuous-time continuous-state : P ( X t + s ≤ y ∣ X u , 0 ≤ u ≤ s ) = P ( X t + s ≤ y ∣ X s ) P(X_{t+s} \leq y | X_u, 0 \leq u \leq s) = P(X_{t+s} \leq y | X_s) P ( X t + s ≤ y ∣ X u , 0 ≤ u ≤ s ) = P ( X t + s ≤ y ∣ X s )
Transition Matrix/Function/Kernel (when time homogeneous)
discrete-time discrete-state : P i j = P ( X 1 = j ∣ X 0 = i ) P_{ij} = P(X_1 = j | X_0 = i) P i j = P ( X 1 = j ∣ X 0 = i )
Continuous-time discrete-state : P i j ( t ) = P ( X t = j ∣ X 0 = i ) P_{ij}(t) = P(X_t = j | X_0 = i) P i j ( t ) = P ( X t = j ∣ X 0 = i )
Continuous-time continuous-state : K t ( x , y ) = 1 2 π t e − ( y − x ) 2 / 2 t K_t(x,y) = \frac{1}{\sqrt{2\pi t}} e^{-(y-x)^2 / 2t} K t ( x , y ) = 2 π t 1 e − ( y − x ) 2 / 2 t
Distribution
discrete-time discrete-state : α P n \alpha P^n α P n
Continuous-time discrete-state : α P ( n ) \alpha P(n) α P ( n )
Continuous-time continuous-state : K n ( x , y ) = 1 2 π n e − ( y − x ) 2 / 2 n K_n(x,y) = \frac{1}{\sqrt{2\pi n}} e^{-(y-x)^2 / 2n} K n ( x , y ) = 2 π n 1 e − ( y − x ) 2 / 2 n
(Brownian motion)
discrete-state의 경우에는 특정 시점/시간 후에 특정 상태에 있을 확률들이 제시됨
continuous-state의 경우에는 특정 시간 후에 특정 위치에 있을 확률 대신, 특정 시간 후의 위치의 분포가 제시됨
P ( X t ≤ y ∣ X 0 = x 0 ) = ∫ − ∞ y K t ( x 0 , w ) d w P(X_t \leq y | X_0 = x_0) = \int_{-\infty}^{y} K_t(x_0, w) dw P ( X t ≤ y ∣ X 0 = x 0 ) = ∫ − ∞ y K t ( x 0 , w ) d w
Markov property를 활용하여 다양한 확률계에 대한 통계적 분석이 가능함
T a = min { t : B t = a } T_a = \min \{t: B_t = a\} T a = min { t : B t = a } / M t = max 0 ≤ s ≤ t B s / M_t = \max_{0 \leq s \leq t} B_s / M t = max 0 ≤ s ≤ t B s z_{T,t} = P(at least one zero in (T,t))의 값 / L_t = last zero in (0,t)의 분포
n스텝 후 α P n \alpha P^n α P n
αPn로 분포 기술
Continuous time Discrete state
생성행렬
( − q 1 q 12 ⋯ q 1 N q 21 − q 2 ⋯ q 2 N ⋮ ⋮ ⋱ ⋮ q N 1 q N 2 ⋯ − q N ) \begin{pmatrix}-q_{1} & q_{12} & \cdots & q_{1N} \\q_{21} & -q_{2} & \cdots & q_{2N} \\\vdots & \vdots & \ddots & \vdots \\q_{N1} & q_{N2} & \cdots & -q_{N}\end{pmatrix} ⎝ ⎜ ⎜ ⎜ ⎜ ⎛ − q 1 q 2 1 ⋮ q N 1 q 1 2 − q 2 ⋮ q N 2 ⋯ ⋯ ⋱ ⋯ q 1 N q 2 N ⋮ − q N ⎠ ⎟ ⎟ ⎟ ⎟ ⎞ 브라운 운동 :
K t ( x , y ) = 1 2 π t e − ( y − x ) 2 2 t K_t(x,y) = \frac{1}{\sqrt{2\pi t}} e^{-\frac{(y-x)^2}{2t}} K t ( x , y ) = 2 π t 1 e − 2 t ( y − x ) 2
8.5. Variations and Applications
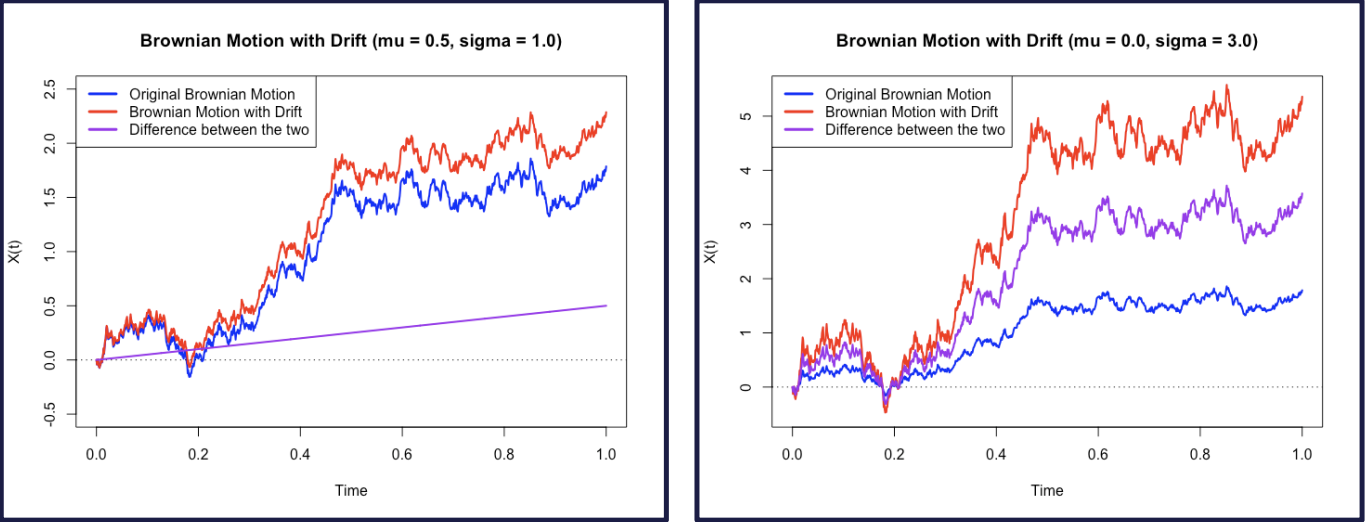
Brownian Motion with Drift
For real μ \mu μ σ > 0 \sigma >0 σ > 0
X t = μ t + σ B t X_t= \mu t+ \sigma B_t X t = μ t + σ B t t ≥ 0 t\geq0 t ≥ 0
drift parameter: μ \mu μ
variance parameter: σ 2 \sigma^2 σ 2
example 8.11
Q: 스포츠 게임에서의 Home Team이 게임에 대한 이득이 있을까?
l : l: l :
t : t: t : 0 ≤ t ≤ 1 0\leq t \leq 1 0 ≤ t ≤ 1
μ : \mu: μ :
X t : X_t : X t :
p ( l , t ) = P ( X 1 > 0 ∣ X t = l ) = P ( X 1 − X t > − l ) p(l,t)=P(X_1>0|X_t=l)=P(X_1-X_t>-l) p ( l , t ) = P ( X 1 > 0 ∣ X t = l ) = P ( X 1 − X t > − l )
$=P(X_{1-t}>-l)=P(\mu(1-t)+\sigma B_{1-t}>-l)$
$=P(B_{1-t}<\frac{l+\mu(1-t)}{\sigma})$
$=P(B_t<\frac{\sqrt{t}[l+\mu(1-t)]}{\sigma\sqrt{1-t}})$ $\leftarrow$여기 넘어가는거는 모르겠어요!!Brownian Bridge
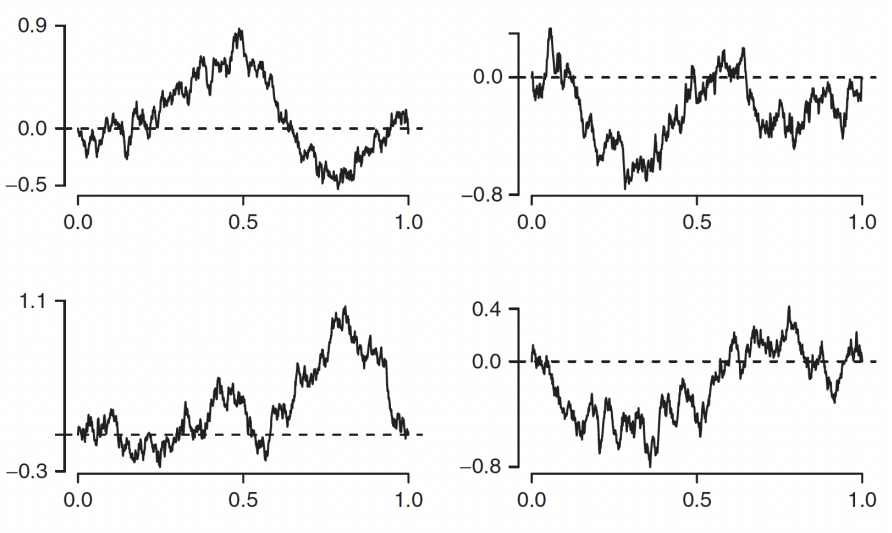
From standard Brownian Motion, the conditional process ( B t ) 0 ≤ t ≤ 1 (B_t)_{0\leq t \leq1} ( B t ) 0 ≤ t ≤ 1 B 1 = 0 B_1=0 B 1 = 0
example 8.12
Let X t = B t − t B 1 , X_t=B_t-tB_1, X t = B t − t B 1 , 0 ≤ t ≤ 1 0\leq t\leq1 0 ≤ t ≤ 1 ( X t ) 0 ≤ t ≤ 1 (X_t)_{0\leq t\leq1} ( X t ) 0 ≤ t ≤ 1
Solution
SInce X t X_t X t ( B t ) t ≥ 0 (B_t)_{t\geq0} ( B t ) t ≥ 0
X 0 = B 0 = 0 X_0=B_0=0 X 0 = B 0 = 0
E [ X t ] = E [ B t − t B 1 ] = E [ B t ] − t E [ B 1 ] = 0 E[X_t]=E[B_t-tB_1]=E[B_t]-tE[B_1]=0 E [ X t ] = E [ B t − t B 1 ] = E [ B t ] − t E [ B 1 ] = 0
C o v ( X s , X t ) = E ( X s X t ) = E ( ( B s − s B 1 ) ( B t − t B 1 ) ) Cov(X_s,X_t)=E(X_sX_t)=E((B_s-sB_1)(B_t-tB_1)) C o v ( X s , X t ) = E ( X s X t ) = E ( ( B s − s B 1 ) ( B t − t B 1 ) )
$=E(B_sB_t)-tE(B_sB_1)-sE(B_tB_1)+stE(B_1^2)$
$=min(s,t)-ts-st+st=min(s,t)-st$
Geometric Brownian Motion
Let ( X t ) t ≥ 0 (X_t)_{t\geq0} ( X t ) t ≥ 0 μ \mu μ σ 2 \sigma^2 σ 2
The process ( G t ) t ≥ 0 (G_t)_{t\geq0} ( G t ) t ≥ 0
G t = G 0 e X t G_t=G_0e^{X_t} G t = G 0 e X t t ≥ 0 t\geq0 t ≥ 0
where G 0 > 0 G_0>0 G 0 > 0
More Formal Definition
d G t = μ G t d t + σ G t d W t dG_t=\mu G_tdt+\sigma G_tdW_t d G t = μ G t d t + σ G t d W t
distribution?
ln G t = ln G 0 + X t \ln{G_t}=\ln{G_0}+X_t ln G t = ln G 0 + X t
E [ ln G t ] = E [ ln G 0 + X t ] = ln G 0 + μ t E[\ln{G_t}]=E[\ln{G_0}+X_t]=\ln{G_0}+\mu t E [ ln G t ] = E [ ln G 0 + X t ] = ln G 0 + μ t
V a r ( ln G t ) = V a r ( ln G 0 + X t ) = V a r ( X t ) = σ 2 t Var(\ln{G_t})=Var(\ln{G_0}+X_t)=Var(X_t)=\sigma^2t V a r ( ln G t ) = V a r ( ln G 0 + X t ) = V a r ( X t ) = σ 2 t
for each t > 0 t>0 t > 0 G t G_t G t
example 8.15
stock price가 Geometric Brownian Motion으로 model되는 이유
장기적으로 Exponential Growth/Decline이 대부분의 주식
가격은 음수일 수 없으며, Geometric Brownian Motion은 양수만 받는다
특정 날의 가격과 다음날의 가격은 독립이 아닐 수 있지만 Day to Day Percent Changes는 iid하게 모델링 가능
8.6 Martingales
우리가 게임을 하고 있을 때 얻는 이득이 stochastic process라고 하면, 이게 fair game 이라는 notion을 generalize하는게 martingale
fair game= expected future winnings가 past history와 무관
discrete-time martingale Y 0 , Y 1 , ⋯ Y_0,Y_1,\cdots Y 0 , Y 1 , ⋯
E [ Y n + 1 ∣ Y 0 , ⋯ , Y n ] = Y n E[Y_{n+1}|Y_0,\cdots,Y_n]=Y_n E [ Y n + 1 ∣ Y 0 , ⋯ , Y n ] = Y n E [ ∣ Y n ∣ ] < ∞ E[|Y_n|]<\infty E [ ∣ Y n ∣ ] < ∞
important property
E [ Y t ] = E [ E [ Y t ∣ Y r , 0 ≤ r ≤ s ] ] = E [ Y s ] , 0 ≤ s ≤ t E[Y_t]=E[E[Y_t|Y_r,0\leq r\leq s]]=E[Y_s],0\leq s\leq t E [ Y t ] = E [ E [ Y t ∣ Y r , 0 ≤ r ≤ s ] ] = E [ Y s ] , 0 ≤ s ≤ t
E [ Y t ] = E [ Y 0 ] , ∀ t ∈ [ T ] E[Y_t]=E[Y_0],\forall t \in[T] E [ Y t ] = E [ Y 0 ] , ∀ t ∈ [ T ]
example 8.17 (Random Walk)
Let S n = X 1 + ⋯ + X n S_n=X_1+\cdots+X_n S n = X 1 + ⋯ + X n S 0 = 0 S_0=0 S 0 = 0
E ( S n + 1 ∣ S 0 , ⋯ , S n ) = E ( X n + 1 + S n ∣ S 0 , ⋯ , S n ) E(S_{n+1}|S_0,\cdots,S_n)=E(X_{n+1}+S_n|S_0,\cdots,S_n) E ( S n + 1 ∣ S 0 , ⋯ , S n ) = E ( X n + 1 + S n ∣ S 0 , ⋯ , S n )
$=E(X_{n+1}|S_0,\cdots,S_n)+E(S_n|S_0,\cdots,S_n)$
$=E(X_{n+1})+S_n=S_n$
using Jensen’s inequality
E ( ∣ S n ∣ ) = E ( ∣ Σ i = 1 n X i ∣ ) ≤ E ( Σ i = 1 n ∣ X i ∣ ) = n < ∞ E(|S_n|)=E(|\Sigma^n_{i=1}X_i|)\leq E(\Sigma^n_{i=1}|X_i|)=n<\infty E ( ∣ S n ∣ ) = E ( ∣ Σ i = 1 n X i ∣ ) ≤ E ( Σ i = 1 n ∣ X i ∣ ) = n < ∞
Martingale with Respect to Another Process
Let ( X t ) t ≥ 0 (X_t)_{t\geq0} ( X t ) t ≥ 0 ( Y t ) t ≥ 0 (Y_t)_{t\geq0} ( Y t ) t ≥ 0 ( Y t ) t ≥ 0 (Y_t)_{t\geq0} ( Y t ) t ≥ 0 ( X t ) t ≥ 0 (X_t)_{t\geq0} ( X t ) t ≥ 0 t ≥ 0 t\geq0 t ≥ 0
Y t = g ( X t ) Y_t=g(X_t) Y t = g ( X t )
X t X_t X t
example 8.19
Optional Stopping Theorem
First Hitting time: a단계에 처음 도달하는 시간
Martingale은 모든 Fixed time에 대해서의 기댓값이 같아야한다. Random time에서는 해당되지 않음
example (Gambler’s Ruin)
1 franc을 이기면 얻고 지면 잃는 게임
베팅 전략: 이기면 멈추고 지면 판돈을 두배로
T: 이길 때까지의 판수(a.k.a Stopping time)
k번만큼 했으면
2 k − ( 1 + 2 + ⋯ + 2 k − 1 ) = 2 k − ( 2 k − 1 ) = 1 2^k-(1+2+\cdots+2^{k-1})=2^k-(2^k-1)=1 2 k − ( 1 + 2 + ⋯ + 2 k − 1 ) = 2 k − ( 2 k − 1 ) = 1
확률 1로 이기기에 T가 Winning Stragedy로 보이지만
E [ Y t ] = 1 ≠ 0 = E [ Y 0 ] E[Y_t]=1\neq0=E[Y_0] E [ Y t ] = 1 = 0 = E [ Y 0 ]
무한 자산이 아니기에 Winning Stragedy가 아님
example 8.22
T = m i n ( t : B t = a o r B t = − b ) T=min(t:B_t=a ~~or~~B_t=-b) T = m i n ( t : B t = a o r B t = − b )