복잡한 함수의 convexity를 체크하는 좋은 방법은 함숫값의 단면을 살펴보는 것이다. 어떤 함수 f가 convex임은 정의역과 교차하는 임의의 직선 상에서 convex임과 동치이다. 이 테크닉을 restriction to a line이라고도 한다. 예를 들어 f(X)=logdetX라고 하자. 이 함수의 정의역은 S++n이다. 이 때 임의의 V∈Sn에 대하여, f(X+tV)=g(t)=logdetX+logdet(I+tX−1/2VX−1/2)=logdetX+∑i=1nlog(1+tλi)이다. (λi는 X−1/2VX−1/2의 고윳값) 위의 계산 과정에 대한 자세한 설명은 이 글을 참고하자. 이때 restrict된 g(t)가 S++n상에서 concave function이므로, log determinant는 concave function이다.
Extended value extensions
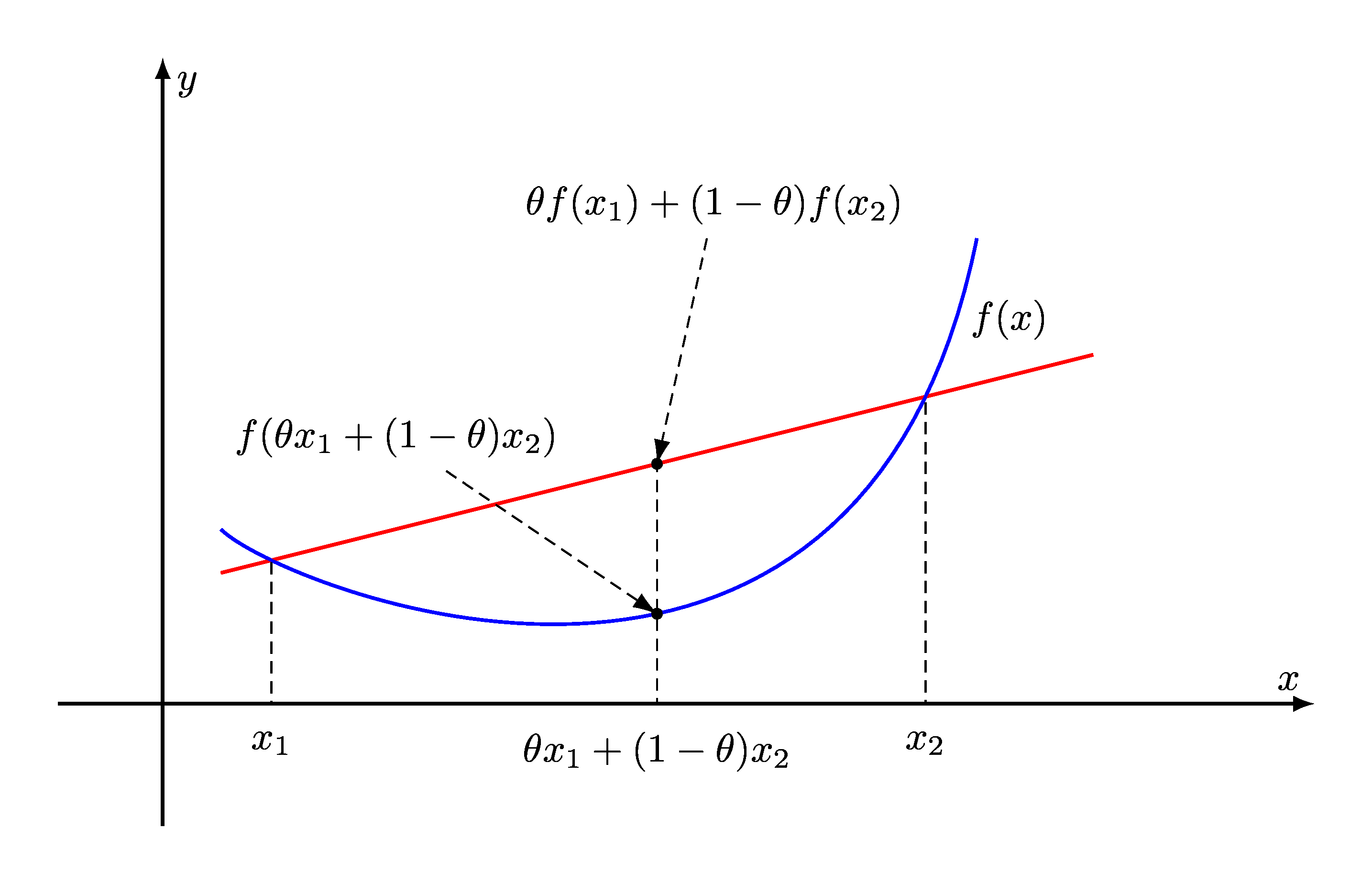
Convex function f를 수식으로 기술할 때 x가 domain set에 속하는지의 여부에 따라 아래처럼 기술할 수 있다.
f~(x)={f(x)∞x∈domfx∈/domf
이렇게 정의해도 임의의 x,y에 대해 convex function의 정의를 만족함을 쉽게 확인할 수 있다. 반대로 concave function의 경우 domain 바깥을 −∞로 나타내면 된다. 이렇게 기술하는 것은 단순히 편의에 의한 것이다.
First-order conditions
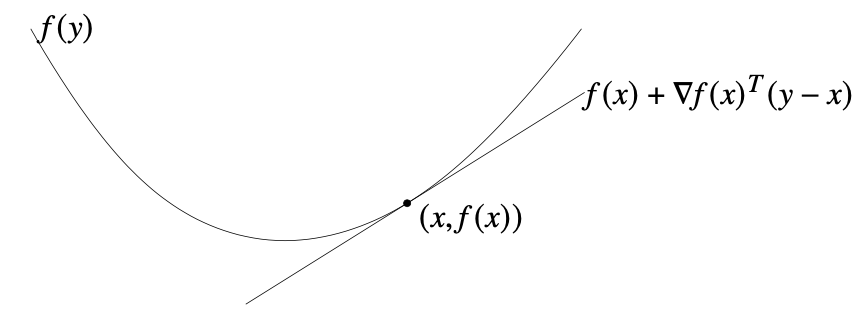
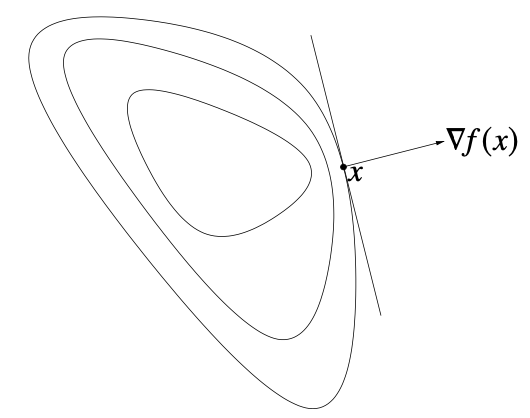
f:Rn→R가 미분 가능하다는 것은 domain이 open set이고, gradient ∇f(x)=⎣⎢⎢⎢⎡∂x1∂f(x)⋮∂xn∂f(x)⎦⎥⎥⎥⎤가 존재함을 말한다. 이때 미분 가능한 f가 convex function임은 domf가 convex이고, 임의의 x,y∈domf에 대해 f(y)≥f(x)+∇f(x)T(y−x)임과 동치이다.
이 부등식의 우변은 y에 대한 affine function이자, x를 고정시켰을 때 f(x)의 first-order Taylor approximation이다. 이것이 항상 f(y)보다 작거나 같으므로, 이 선형 근사는 f의 global underestimator가 된다. 또 만약 ∇f(x)=0이라면 f(y)≥f(x)이므로, convex function에서 ∇f(x)=0이면 x는 global minimizer가 됨을 알 수 있다.
*우리 세션에서는 증명은 다루지 않았다. 교재를 참고하자.
Second-order conditions
f:Rn→R가 두 번 미분 가능하다는 것은 domain이 open set이고, hessian ∇2f(x)∈Sn=∂xi∂xj∂2f(x),i,j=1,2,...,n이 존재함을 말한다. 이때 두 번 미분 가능한 f가 convex function임은 domf가 convex이고, hessian ∇2f(x)이 임의의 x∈domf에 대하여 positive semidefinite임과 동치이다. 또한 hessian이 positive definite이면 f는 strictly convex이다.
이는 R상의 함수로 축소해서 보았을 때, 도함수가 non-decreasing이라는 조건인 f′′(x)≥0과 같다. 또한 기하학적으로 함수의 그래프가 x에서 positive (upward) curvature를 가진다는 조건으로도 해석될 수 있다.
*우리 세션에서는 증명은 다루지 않았다. 교재를 참고하자.
Examples
Quadratic function: f(x)=(1/2)xTPx+qTx+r,P∈Sn
이 함수는 ∇2f=P⪰0이면 convex, P⪯0이면 concave이다.
Least squares objective: f(x)=∣∣Ax−b∣∣22
이 함수는 ∇2f=2ATA이므로 A에 관계 없이 convex이다.
Norm: ∣∣x∣∣는 항상 convex이다. 증명은 기본 성질을 이용하면 간단하다. ∣∣θx+(1−θ)y∣∣≤∣∣θx∣∣+∣∣(1−θ)y∣∣by triangle inequality=θ∣∣x∣∣+(1−θ)∣∣y∣∣by homogeneity
Max function: f(x)=maxkxk f(θx+(1−θ)y)=kmax(θxk+(1−θ)yk)≤θkmaxxk+(1−θ)kmaxyk=θf(x)+(1−θ)f(y)
이므로 convex이다.
Log-sum-exp: f(x)=∑k=1nexpxk는 multivariate softplus라고도 부르며, max function에 대한 smooth approximation이다. 구체적으로, max{x1,...,xn}≤f(x)≤max{x1,...,xn}+logn이 성립한다. 또한 이 함수의 그래디언트는 softmax function이다. 이것이 convex function임을 증명해 보자.
우선 z=(ex1,...,exk)로 놓으면 ∇2f(x)=1Tz1diag(z)−1Tz1zTz이다.
이때 임의의 벡터 v=0에 대해 vT∇2f(x)v=(∑kzk)2(∑kzkvk2)(∑kzk)−(∑kvkzk)2이고 Cauchy-Schwarz inequality에 의해 (∑kzkvk2)(∑kzk)≥(∑kvkzk)2이므로 이 함수는 convex이다.
Geometric mean: f(x)=(∏k=1nxk)1/n은 concave function이다. 증명은 위와 유사하게 할 수 있다.
Sublevel sets
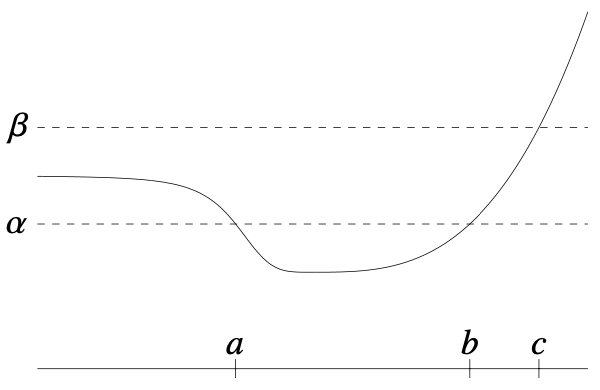
Sublevel set은 함숫값의 범위를 특정 범위로 제한한 집합을 말한다. 함수 f:Rn→R의 α-sublevel set은 다음과 같이 정의된다.
Cα={x∈domf∣f(x)≤α}
모든 α에 대하여, convex function의 α-sublevel set은 convex set이다. 또한 concave function의 α-superlevel set(f가 α보다 크거나 같은 집합)도 convex set이다. 역은 성립하지 않음에 주의하자. 가령 f(x)=−ex는 strictly concave function이지만 sublevel set은 convex이다.
Epigraph
함수 f:Rn→R의 그래프는 Rn+1의 subset인 {(x,f(x))∣x∈domf}로 정의할 수 있다.
함수 f:Rn→R의 epigraph는 Rn+1의 subset인 epif={(x,t)∣x∈domf,f(x)≤t}로 정의할 수 있다. 즉 epigraph는 그래프의 윗 부분을 의미한다. 함수 f가 convex인 것은 epigraph가 convex임과 동치이다. 또 함수 f가 concave인 것은 hypograph hypof={(x,t)∣x∈domf,t≤f(x)}가 convex임과 동치이다.
Jensen's inequality
ϕ를 열린 구간 I에서 convex function이라고 하자. 만일 확률변수 X의 support가 I에 포함되고 finite expectation을 가지면 아래가 성립한다.
ϕ[E(X)]≤E[ϕ(X)].
Example. p(x)를 X의 true probability distribution이라 하고, q(x)를 다른 density라 하자. 그리고 Y(X)=q(X)/p(X)라 하자. 그러면 Jensen's inequality에 의해,
이때 D(p(x)∥q(x))를 KL-divergence라 부르며, q(x)를 p(x)의 estimation으로 사용했을 때 두 분포가 얼마나 다른지를 측정하는 지표이다.
2. Operations that Preserve Convexity
어떤 문제 상황이 주어졌을 때 그것을 convex function으로 나타내고 적절히 코딩하는 것은 최적화 문제를 푸는 핵심 과정이다. 이때 문제 상황을 convex problem으로 구성하기 위해, 모든 수식 표현은 cvxpy와 같은 패키지 라이브러리 내에 있는 함수와 수식의 조합으로 표현되는데, 이것을 Disciplined Convex Programming이라고 한다. 이번 섹션은 그 기초가 되는 이론으로, convex function에 대해 convexity를 보전하는 연산에 대해 알아보자.
어떤 함수 f가 convex function인지 판단할 수 있는 방법에는 크게 세 가지가 있다.
Convex function의 정의를 그대로 이용 (위의 restriction to a line을 이용해도 좋다.)
Second-order condition 확인 (Hessian을 계산하기 쉽지 않을 때가 많으므로, 거의 단순한 함수에만 사용한다.)
Convex function에 다음 연산을 해도 여전히 convex이다.
Non-negative weighted sum
Composition with affine function
Point-wise maximum and supremum
Composition
Minimization
Perspective
Nonnegative scaling, sum, and integral
정의로부터 바로 확인할 수 있고 concave function에서도 동일하다.
f가 convex일 때, α≥0에 대하여 αf도 convex이다.
f1,f2가 convex일 때, f1+f2도 convex이다.
f1,f2,...가 convex일 때, infinite sum ∑i=1∞fi도 convex이다.
f(x,α)가 α∈A에서 x에 대해 convex일 때, ∫α∈Af(x,α)dα도 convex이다.
Composition with affine function
f(x)가 convex이면 f(Ax+b)도 convex이다.
Log barrier function f(x)=−∑i=1mlog(bi−aiTx)은 convex이다.
Norm이 convex이므로, approximation error로 많이 쓰이는 ∣∣Ax−b∣∣도 convex이다.
Piecewise linear function f(x)=maxi=1,...,m(aiTx+b)는 convex이다.
x∈Rn의 가장 큰 원소부터 r개의 합 f(x)=x[1]+⋯+x[r]은 f(x)=max{xi1+⋯+xir∣1≤i1≤⋯≤ir≤n}으로 볼 수 있으므로 convex이다.
Pointwise supremum
f(x,y)가 y∈A에서 x에 대해 convex일 때, g(x)=supy∈Af(x,y)는 convex이다.
집합 C에서 가장 먼 점과의 거리 f(x)=supy∈C∣∣x−y∣∣는 convex이다.
symmetric matrix의 maximum eigenvalue λmax(X)=sup∣∣y∣∣2=1yTXy는 convex이다.
집합 C의 support function SC(x)=supy∈CyTx는 convex이다.
Partial minimization
g(x)=infy∈Cf(x,y)를 f의 partial minimization이라고 한다. 만약 f(x,y)와 C가 convex라면 g도 convex이다.
dist(x,S)=infy∈S∣∣x−y∣∣는 convex이다.
Composition with scalar functions
g:Rn→R, h:R→R에 대해 f(x)=h(g(x))는 다음 조건 중 하나를 만족 시 convex이다.
g convex, h convex, h~ nondecreasing g concave, h convex, h~ nonincreasing
g is convex ⟹expg(x) is convex
g is concave and positive ⟹1/g(x) is convex
General composition rule
g:Rn→Rk, h:Rk→R에서 f(x)=h(g1(x),g2(x),…,gk(x))는 함수의 각 argument gi에 대해 다음 조건 중 하나를 만족 시 convex이다.
gi convex, h~ nondecreasing in its ith argument gi concave, h~ nonincreasing in its ith argument gi affine
g is convex ⟹∑i=1mexpgi(x) is convex
f(x)=p(x)2/q(x) is convex if p is nonnegative and convex, q is positive and concave
Perspective
함수 f:Rn→R의 perspective는 g:Rn×R→R,g(x,t)=tf(x/t)로 정의된다. g의 정의역은 domg={(x,t)∣x/t∈domf,t>0}이다.
함수 f가 convex이면 함수 g도 convex이다.
f(x)=−logx is convex ⟹ relative entropy g(x,t)=tlogt−tlogx is convex on R++2
3. The conjugate function
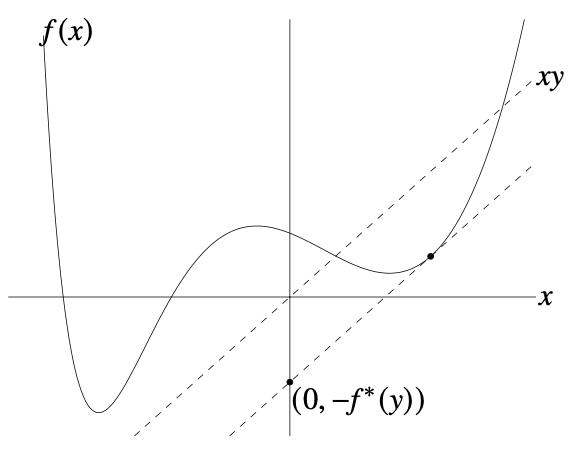
함수 f:Rn→R 에 대하여, f의 conjugatef∗:Rn→R는 다음과 같이 정의된다.
f∗(y)=supx∈domf(yTx−f(x))
이때 domf∗는 supremum이 bounded인 범위이다.
이 함수는 기하적으로 closed convex function을 epigraph의 관점에서 살펴보았을 때, supporting hyperplane의 x=0에서의 offset으로 해석될 수 있다. Conjugate function은 뒤에서 배울 Lagrange dual function과 깊은 관련이 있다. 또, conjugate function은 affine function의 supremum 형태이므로, 원래 함수와 관계 없이 항상 convex이다.
Examples
Affine function: f(x)=ax+b일 때 yx−ax−b는 y=a일때만 bounded이다. 따라서 f∗의 domain은 singleton {a}이고 f∗(a)=−b이다.
Negative logarithm: f(x)=−logx (x>0)일 때 y≥0이면 xy+logx는 unbounded이다. 반대로 y<0이면 y=−1/x일 때 maximum이므로 domf∗={y∣y<0}이고 f∗(y)=−log(−y)−1이다.
Inverse: f(x)=1/x,x>0일 때 f∗(y)=−2(−y)1/2,y≤0이다.
strictly convex quadratic: f(x)=21xTQx,Q∈S++n일 때 f∗(y)=supx(yTx−(1/2)xTQx)=21yTQ−1y이다.
Fenchel’s inequality
Conjugate function의 정의로부터 그대로 도출된다.
f(x)+f∗(y)≥yTx
Conjugate of the conjugate
함수 f가 closed / convex일 때, f∗∗=f이다.
Differentiable functions
미분 가능한 함수 f의 conjugate를 f의 Legendre transform이라고 한다. Rn에서 정의된 f가 convex이고 미분 가능하다고 하자. 이때 yTx−f(x)의 maximizer x∗는 y=∇f(x∗)를 만족하며, 반대로 y=∇f(x∗)를 만족하는 x∗는 yTx−f(x)의 maximizer이다.
따라서 y=∇f(x∗)에 대해 f∗(y)=x∗T∇f(x∗)−f(x∗)가 성립하므로, 임의의 y에 대한 conjugate function의 값을 gradient equation y=∇f(z)를 z에 대해 풀어서 구할 수 있다.
4. Quasiconvex functions
Quasiconvex는 convex보다 조금 약한 개념이지만, 여전히 유용한 성질들을 많이 보존하고 있다. 함수f:Rn→R의 정의역 domf가 convex이고, 모든 α에 대해 sublevel sets Sα={x∈domf∣f(x)≤α}가 convex라면 f를 quasiconvex function이라고 한다.
만약 −f가 quasiconvex라면 f를 quasiconcave라고 하며, f가 quasiconvex인 동시에 quasiconcave이면 quasilinear라고 한다.
Examples
∣x∣는 R에서 quasiconvex이다.
ceil(x)=inf{z∈Z∣z≥x}는 quasilinear이다.
logx는 R++에서 quasilinear이다.
f(x1,x2)=x1x2는 R++2에서 quasiconcave이다.
linear fractional function f(x)=cTx+daTx+b,cTx+d>0은 quasilinear이다.
Properties of quasiconvex functions
Modified Jensen inequality
Quasiconvex function f와 0≤θ≤1에 대하여 f(θx+(1−θ)y)≤max{f(x),f(y)}이다.
First-order condition
Domain이 convex이고 미분 가능한 함수 f가 quasiconvex인 것은 아래와 동치이다.
f(y)≤f(x)⟹∇f(x)T(y−x)≤0
Operations that preserve quasiconvexity
대부분 convex function과 유사하지만, 한 가지 주의할 점은 quasiconvex function의 합은 quasiconvex가 아닐 수도 있다는 것이다.
5. Log-concave and log-convex functions
어떤 함수 f:Rn→R 이 정의역에 속하는 모든 x에 대해 f(x)>0 이고, logf 가 concave이면, f 를 log-concave라고 한다. 반대로, logf가 convex이면 f는 log-convex하다. (log가 concave function이므로 log-concave 표현을 조금 더 많이 쓴다.)
만일 concave인 f가 non-negative라면, 그것은 log-concave function이기도 하다.