2. Some standard convex problems, cont'd
이 문제는 LP를 generalized inequality로 확장한 것으로, 일반적인 형태는 아래와 같다.
minimizecTx
subject toFx+g⪯K0Ax=b
만일 proper cone K=R+m으로 정의하면 이 문제는 LP와 동일하다.
Semidefinite program (SDP)
이 문제는 교재에서 다루는 convex problem의 가장 일반적인 형태이다. 수식으로 표현하면 다음과 같다.
minimizecTx
subject tox1F1+x2F2+⋯+xnFn+G⪯0Ax=b
withFi,G∈Sk
이런 형태의 inequality constraint를 Linear matrix inequality(LMI) 로 부른다. 만일 문제에 여러 개의 LMI를 넣고 싶다고 하면, 이는 x1[F^100F~1]+x2[F^200F~2]+⋯+[G^00G~]⪯0의 constraint와 동일하다.
Example: Matrix norm minimization
A(x)=A0+x1A1+⋯+xnAn(Ai∈Rp×q)가 주어졌을 때, 이 행렬의 norm ∣∣A(x)∣∣2=(λmax(A(x)TA(x)))1/2을 최소화하고 싶다고 하자. 이런 문제는 이미지 데이터 처리, 차원 축소 등에 응용될 수 있다. 이 문제는 x∈Rn,t∈R에 대한 SDP로 다음과 같이 나타낼 수 있다.
minimizet
subject to[tIA(x)TA(x)tI]⪰0
이때 constraint는 ∣∣A∣∣2≤t⟺ATA⪯t2I이므로 위와 같이 도출된 것이다.
어떤 상황이 주어지고 이를 최적화 문제로 나타냈을 때, 나타낸 문제를 풀기 쉬운 형태로 적절히 변형하는 것은 매우 중요하다. 이번 섹션에서는 대표적인 변형 테크닉들을 알아보자.
Change of variables
Optimization variable x∈Rn에 어떤 일대일함수 ϕ:Rn→Rn을 씌워도 ϕ(x)가 problem domain을 벗어나지 않는다면 f~i(z)=fi(ϕ(z))와 같이 x=ϕ(z)로 놓고 z에 대해 문제를 풀어도 된다. 예시를 통해 살펴보자.
다음 non-convex problem을 보자.
minimizex1/x2+x3/x1
subject tox2/x3+x1≤1withx≻0
이 문제에서 x=exp(z)로 놓으면 문제는 아래와 같이 바뀐다.
minimizeexp(z1−z2)+exp(z3−z1)
subject toexp(z2−z3)+exp(z1)≤1
이처럼 간단한 변환을 통해 문제를 convex problem으로 바꿀 수도 있다.
만일 ϕ0가 monotone increasing이고,
ψi(u)≤0⟺u≤0,
φi(u)=0⟺u=0
의 조건이 성립하면 원래의 최적화 문제의 함수들에 이들을 씌워 아래처럼 변환해도 동일한 해를 얻는다. 가령 ∣∣Ax−b∣∣의 minimization이 ∣∣Ax−b∣∣2의 minimization과 동일한 것과 같은 원리이다.
minimizeϕ0(f0(x))
subject toψi(fi(x))≤0,i=1,...,mφi(hi(x))=0,i=1,...,p
Converting maximization to minimization
ϕ0가 monotone decreasing이면 목적 함수에 이것을 씌워 ϕ0(f0(x))로 쓰고, maximization 문제를 minimization 문제로 뒤집어도 동일하다. 목적함수의 부호를 뒤집는 것과 같은 원리이다.
Eliminating equality constraints
minimizef0(x)
subject tofi(x)≤0,i=1,...,mAx=b
는 아래와 동일하다.
minimize(over z)f0(Fz+x0)
subject tofi(Fz+x0)≤0,i=1,...,m
where F and x0 are such that Ax=b
⟺x=Fz+x0 for some z
Introducing equality constraints
위의 정반대 방법이다.
minimizef0(A0x+b0)
subject tofi(Aix+bi)≤0,i=1,...,m
은 아래와 동일하다.
minimize(over x,yi)f0(y0)
subject tofi(yi)≤0,i=1,...,myi=Aix+bi,i=0,...,m
Introducing slack variables for linear inequalities
Soft-margin SVM에 응용된 테크닉이다.
minimizef0(x)
subject toaiTx≤bi,i=1,...,m
은 아래와 동일하다.
minimizef0(x)
subject toaiTx+si=bi,i=1,...,msi≥0,i=1,...,m
목적함수를 epigraph로 보고 변수 t를 도입해 아래와 같이 표현할 수 있다.
minimizet
subject tof0(x)−t≤0fi(x)≤0i=1,...,mAx=b
Minimizing over some variables
두 변수에 대한 최적화 문제
minimizef0(x1,x2)
subject tofi(x1)≤0i=1,...,m
는 f~0(x1)=infx2f0(x1,x2)로 놓으면 아래와 동일하다.
minimizef~0(x1)
subject tofi(x1)≤0i=1,...,m
Convex relaxation
Example: Boolean LP
다음과 같이 0 또는 1의 값만 가지는 boolean variable이 포함된 LP 문제가 있다.
minimizecT(x,z)
subject toF(x,z)⪯g,A(x,z)=b,z∈{0,1}q
이런 문제는 일반적으로 non-convex여서 풀기 쉽지 않다. 이때 constraint set의 convex hull을 고려하자. 즉, z∈[0,1]q로 relaxation한다. 이렇게 푼 문제의 optimal value는 원래 문제의 optimal value의 lower bound이다. 마찬가지로 objective가 non-convex인 경우에도 그것의 convex lower bound를 찾아서, 약간의 오차를 감수하는 대신 문제를 훨씬 간단하게 풀 수 있다.
4. Quasiconvex optimization
Quasiconvex optimization은 objective function이 quasiconvex function이며, constraint function이 convex한 형태이다.
Quasiconvex 문제의 경우 convex와 다르게 locally optimal point가 globally optimal point가 아닐 수 있음에 주의해야 한다.
LP의 일반화인 Linear-fractional programming, Von Neumann growth model 등이 대표적인 quasiconvex 문제이다.
Convex representation of sublevel sets
f0가 quasiconvex라면, 다음과 같은 ϕt가 존재한다.
- t를 고정했을 때, x에 대해 convex
- f0의 t-sublevel set은 ϕt의 0-sublevel set (i.e. f0(x)≤t⟺ϕt(x)≤0)
따라서 t를 고정하고 다음과 같은 convex feasibility 문제를 풀었을 때,
findx
subject toϕt(x)≤0fi(x)≤0,i=1,...,mAx=b(1)
Feasible이면 t≥p∗이고, infeasible이면 t≤p∗이다.
Bisection method for quasiconvex optimization
이를 이용한 bisection 알고리즘은 다음과 같다.
givenl≤p∗,u≥p∗,toleranceϵ>0.
repeat1.t:=(l+u)/2.2.Solve the convex feasibility problem (1).3.if(1) is feasible, u:=t;else l:=t.until u−l≤ϵ.
이 알고리즘은 수렴하는 데 ⌈log2((u−l)/ϵ⌉번의 반복이 요구된다.
5. Multicriterion optimization
최적화 문제의 목적함수 값이 스칼라가 아니라 벡터인 경우, 이런 종류의 문제를 vector optimization이라고 한다.
f0(x)=(F1(x),F2(x),...,Fq(x))로 구성된 objective를 전부 명백하게 minimize하는 x∗는 존재하지 않을 때가 많다. 일반적으로는 목적함수 중 일부분의 이점을 얻기 위하여 다른 부분의 이점을 일부 포기해야 하는 trade-off 관계가 있으며, 최적화 시 이를 반드시 고려해야 한다.
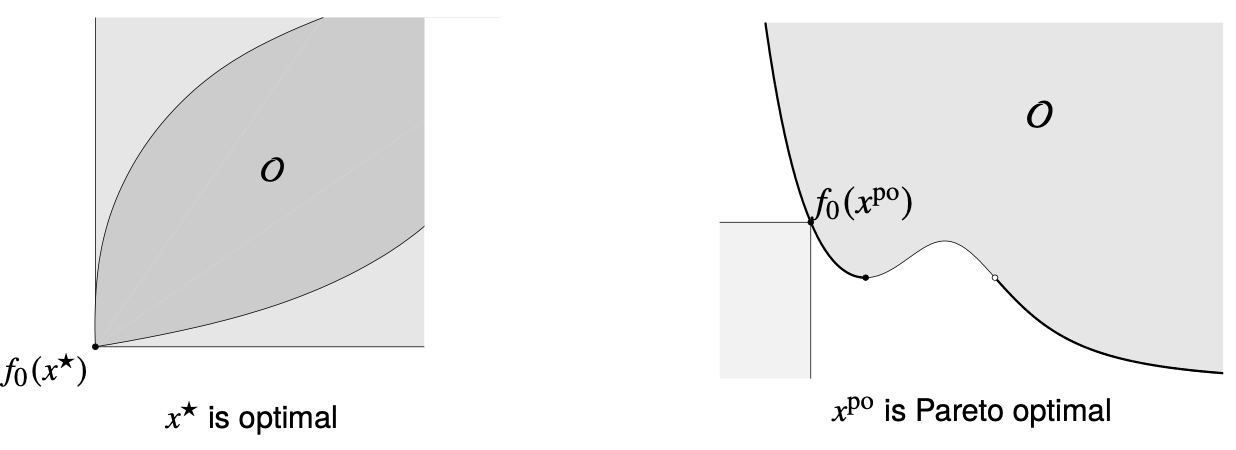
Pareto optimality
Feasible한 x와 다른 feasible한 x~에 대하여 f0(x)⪯f0(x~)이고, 최소 한 개의 i에 대하여 Fi(x)<Fi(x~)일 때 x가 x~를 dominate한다고 부른다. 만일 feasible한 xpo가 다른 feasible point에 dominate되지 않을 경우, xpo를 Pareto optimal이라고 부른다. 다시 말해 xpo보다 명백히 우월한 상태가 가능하지 않고, xpo에서 특정 부분을 개선하기 위해서는 반드시 다른 부분을 포기해야 한다는 뜻이다. Pareto optimal point는 여러 개가 존재할 수 있으며, q=2일 경우 파레토 최적인 지점의 목적함수 값들은 optimal trade-off curve를 이루고, q=3일 경우 optimal trade-off surface를 이룬다. 집합의 관점에서 optimal point는 minimum element를 뜻하고, pareto optimal point는 minimal element를 뜻한다.
Scalarization
vector optimization 문제를 푸는 가장 간단한 테크닉은 scalarization으로, 말 그대로 목적함수를 스칼라로 바꿔 주는 것이다. λ≻0을 선택해, 목적함수를 아래와 같이 바꿔 준다.
λTf0(x)=λ1F1(x)+λ2F2(x)+⋯+λqFq(x)
이 목적함수의 optimal point x는 pareto optimal이다.
이때 λ는 목적함수의 구성 요소 중 무엇을 우선시할 것인지를 나타내는 상대적 가중치이다. 가령 최소화 문제에서 i번째 가중치를 크게 잡으면, 그 요소가 조금만 커져도 목적함수 값이 크게 증가하므로 그 요소의 값을 우선적으로 고려하게 된다.
이전 1주차 세션에서 배웠듯, convex problem이 아닌 이상 scalarization을 통해 모든 pareto optimal point를 찾아낼 수는 없다. 아래 그림에서 x3은 pareto optimal이지만 scalarization을 통해 찾아지지 않는다.
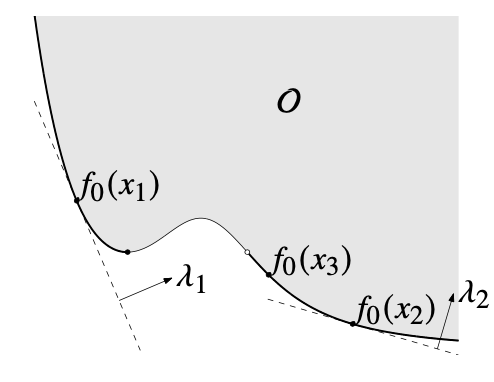
Convex problem의 경우 이론상 λ⪰K∗0을 바꿔 가며 모든 pareto optimal point를 찾을 수 있다. (등호가 들어간 이유는 몇몇 극단적인 경우, 가령 수직 접선에서의 optimal point 때문이다.) 그러나 λ≻K∗0에서 찾은 모든 지점은 pareto optimal이지만, λ⪰K∗0에서 찾은 지점은 pareto optimal이 아닐 수 있으므로 따로 체크해 주어야 한다. 이는 1주차 세션 마지막 내용과 일치한다.
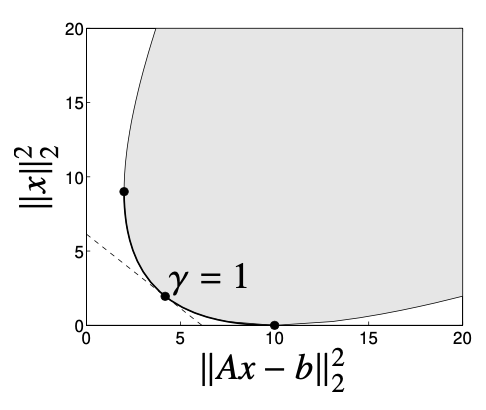
Example: Regularized least-squares
minimize(w.r.t R+2)(∣∣Ax−b∣∣22,∣∣x∣∣22)
γ>0에 대해 λ=(1,γ)로 선택하자. 아래 그림은 trade-off curve이며, limiting case(γ→0,γ→∞, 양쪽의 두 경계)만 제외하고 sclarization을 통해 굵은 실선의 모든 pareto optimal
x=((ATA)+γI)−1ATb을 찾아낼 수 있다.