*세션 교재: Optimization for Machine Learning ch14. MIT Press. edited by Suvrit Sra.
* [Week4] Robust Optimization 세션의 내용을 잘 익히고 보셔야 합니다!
0. Introduction
이번 세션에서는 robust optimization이 기계학습 문제에 어떻게 적용될 수 있는지 살펴보려고 한다.
우리는 데이터를 분석하는 다양한 기법들과 방법론들에 대해 배우지만, 막상 실제 데이터에는 그것들을 적용하기 힘들거나 의미있는 결과를 얻을 수 없는 경우가 많다. 단순히 '데이터가 부족해서, 데이터 질이 너무 떨어져서'로 치부해 버리기에는 이런 상황은 너무나도 많이 발생한다. 데이터 수집 프로세스상의 문제, 개인 정보 보호 등등 현실적으로 대응하기 힘든 문제들이 산재해 있기 때문이다. 이런 식으로 만들어진 데이터는 우리가 가치를 창출하고자 하는 대상 모집단의 특성을 완전히 반영할 수 없기 때문에 일반화가 잘 되지 않는다. 따라서 데이터를 활용한 의사 결정 문제에서는 이런 데이터의 불완전성에 강건하게(robustly) 대응할 수 있는 모델링을 해야 유의미한 가치를 창출할 수 있다.
Robust optimization 관점에서, 강건한 기계학습 모델을 만든다는 것은 주어진 데이터가 가진 불확실성(uncertainty)을 적절히 모델링해 그에 맞게 모델의 파라메터를 최적화함으로써 모델이 불확실성에 잘 대응할 수 있게 하는 것이다. 불확실성에 잘 대응한다는 것은 데이터의 불확실성으로 인해 훈련 데이터와 테스트 데이터가 조금 이질적이더라도 모델이 어느 정도 쓸만한 성능을 보일 수 있다는 것이다. 이때 불확실성은 우리가 데이터를 다룰 때 맞부딪힐 수 있는 많은 문제와 비슷하게 정의될 수 있다.
불확실성을 모델링할 때 고려해야 하는 또다른 중요한 요소는 computational tractability이다. Uncertainty set을 정의하고, deterministic한 문제로 변환했을 때 그것이 다항 시간 내에 계산 가능한 문제여야 한다. 가령 이전 세션에서 polyhedral uncertainty가 포함된 LP 문제를 duality를 이용해 동일한 LP로 변환할 수 있었다. 일반적으로, slater-like condition을 만족하는 robust optimization 문제에 대하여 uncertainty set U={x∣fi(x,ui)≤0,∀ui∈Ui,i=1,2,...,m}이 정의되었다고 하자. 만일 x∈U임을 구분할 수 있거나 separating hyperplane을 정의할 수 있는 efficient algorithm이 존재한다고 하면 이 문제는 다항 시간 내에 풀 수 있다. 그러나 각각의 fi가 x에 대한 convex function이고, 따라서 U가 convex set이라고 해도 efficient separating 알고리즘이 항상 존재하지는 않는다. 가령 LP with polyhedral uncertainty는 LP, LP with ellipsoidal uncertainty는 SOCP, SOCP with ellipsoidal uncertainty는 SDP로 표현할 수 있었다. 그러나 SDP with ellipsoidal uncertainty는 NP-hard 문제이다.
또한 저번 세션에서 다뤘듯, uncertainty의 probability distribution에 대한 가정을 통해 문제의 feasibility를 확률적으로 보장하는 방식의 최적화 또한 가능하다. 가령 support vector machine의 hinge loss가 어떤 threshold를 넘을 maximum probability를 제한하는 식이다. 이제부터 우리는 robust optimization이 ML 문제에 직접적으로 적용되는 예시로 시작해, robustness로부터 statistical learning theory의 개념들을 도출하는 데까지 나아갈 것이다.
1. Robust Optimization and Adversary Resistent Learning
일반적인 LP, SOCP 등의 문제들에서 나아가 이번에는 가장 간단한 ML 문제 중 하나인 support vector machine의 robust formulation에 관해 알아보자. 여기에서 주목할 점은 우리가 배웠던 uncertainty set의 개념을, 많이 발생하는 익숙한 문제들에 그대로 적용할 수 있다는 것이다.
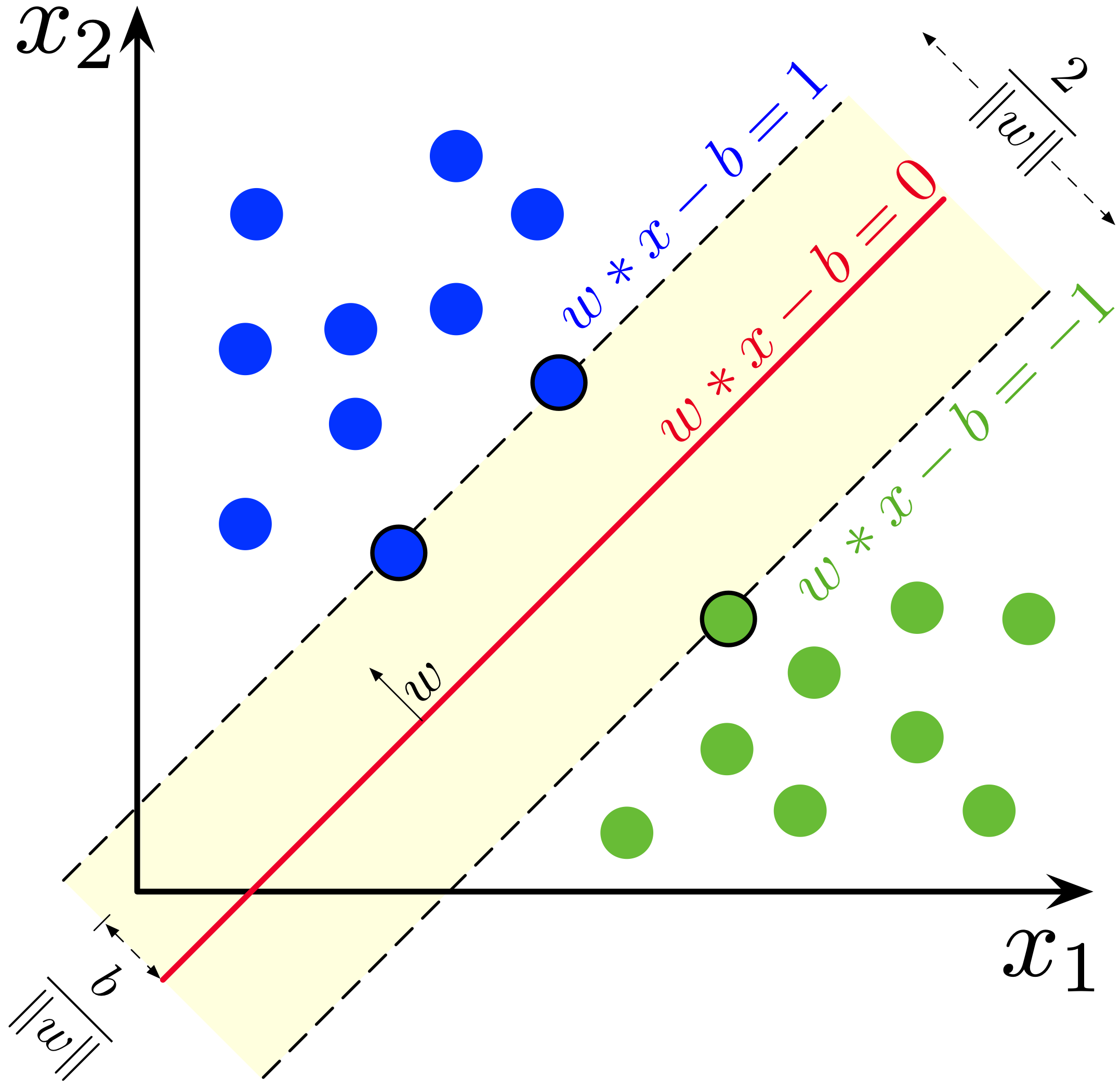
Support vector machine(SVM)은 binary classification 문제를 풀기 위한 기계학습 모델이다. m개의 training sample (xi,yi)i=1m⊂Rn×{−1,1}에 대하여, 주어진 데이터에 대한 linear classifier h(x)=sgn(⟨w,x⟩+b)를 찾는 것이 목표이다. (⟨⋅,⋅⟩은 내적을, sgn은 부호 함수를 말한다.) 이 문제는 컨벡스 최적화 문제로 다음과 같이 나타낼 수 있다.
이때 왼쪽의 r(w,b)는 w에 대한 regularization term을 말한다. 주로 2-norm을 사용하고, 1-norm을 사용해도 된다. SVM에 대한 더 자세한 설명은 ESC github에 있는 julia practice with solution 파일 4번 문제의 설명을 참고하자. SVM에서 발생할 수 있는 data uncertainty는 크게 x벡터 좌표의 오염(corruption), y label의 오염, missing data로 인한 오염을 들 수 있다. 이 세 가지의 경우에 대한 robust formulation을 살펴보자.
1-1. Corrupted Location
a. Deterministic case
데이터의 feature vector의 관측값 xi가 모종의 이유로 오염된 상태라고 하자. 실제 (알 수 없는) 데이터의 값은 xitrue=xi+ui로 나타낼 수 있다. Robust SVM은 uncertainty set 안의 모든 가능한 ui에 대해 loss function을 최소화하는 문제이다.
먼저 Ellipsoidal uncertainty set을 살펴보자. 이 uncertainty set은 Ui={ui∣uiTΣiui≤1},∀i=1,...,m으로 정의될 수 있고, duality에 의해 constraint yi(⟨w,xi+ui⟩+b)≥1−ξi,∀ui∈Ui를 deterministic 하게 변환해 다시 표현하면 이 문제는 아래와 같이 재표현될 수 있다.
이는 불확실성을 고려했을 때, worst case에서 support vector(constraint에서 등식을 만족하는 벡터)는 불확실성을 고려했을 때 ellipsoid의 반지름만큼 원래의 위치에서 벗어나 있을 수 있고, 이것을 고려해 constraint를 더 여유 있게 만족하는 hyperplane을 찾아야 함을 말한다. 이 문제는 SOCP에 속하기 때문에 비교적 쉽게 풀 수 있다.
b. Probabilistic case
만약 ellipsoidal uncertainty ui가 어떤 확률분포(알려졌든, 알려지지 않았든)를 가지고 있다고 가정한다면, robust SVM은 constraint가 만족될 확률을 선택한 값 이상으로 보장하는 hyperplane을 찾는 문제가 될 수도 있다. 이런 종류의 문제를 chance-constrained optimization이라고 했다. SVM에서의 chance constraint 두 가지를 살펴보자.
(a)는 ui가 알려진 정규분포를 따른다고 할 때, (b)는 ui가 분산 Σi를 가지고 0 주변에 분포한 임의의 확률 분포를 따른다고 할 때의 worst-case를 조정하는 경우이다. 다음 theorem을 통해 이 constraint들을 위의 deterministic case와 유사하게 표현할 수 있음을 알 수 있다. 증명은 multivariate chebyshev inequality를 이용하면 되는데, 여기에서는 생략하겠다.
이는 κi를 1에 가깝게 선택할수록 γi가 더 커지기 때문에, 결국 찾을 hyperplane이 constraint를 더 여유 있게 만족해야 한다는 뜻이다. 그러면 SVM의 margin은 작아질 수밖에 없다. 일반적으로, 더 보수적인 결과를 원할 경우 성능 하락을 감수해야 한다는 것을 기억하자.
1-2. Missing data
이번에는 데이터 x의 feature 중 일부가 모종의 이유로 손실되어 있는 경우를 살펴보자. 우선 SVM의 formulation은 다음과 같았다. Soft-margin SVM은 아래 오른쪽 항과 같은 hinge loss function을 사용하는 것과 동일하다고 했다. (Offset b는 x벡터에 원소 1을 넣어서 w벡터에 포함시켰다고 하자.)
wmin:21∣∣w∣∣2+C∑i=1m[1−yi⟨w,xi⟩]+
K개의 feature가 삭제되었다고 하고 w를 어떤 벡터로 선택했을 때, hinge loss function term의 값은 아래와 같다. ∘는 pointwise multiplication을 나타낸다.
이 경우에는 이전보다 훨씬 복잡한 이론이 필요한데, 데이터가 애초에 잘못 분류되어 수집되었을 경우의 확률을 고려한 분류기의 optimal policy를 도출하는 것이다. 우리 세션에서는 분량과 난이도 상 생략하였다. 자세한 내용이 궁금하다면 참고 논문을 확인해 보자.
2. Robust Optimization and Regularization
이번에는 우리가 흔히 사용하는, 알고리즘의 테스트 성능(일반화)을 높이기 위한 테크닉인 regularization이 robust optimization의 관점에서 도출될 수 있음을 확인해 볼 것이다. 결론부터 미리 말하자면, 둘은 수학적으로 동일하다.
또한 확률론적인 분석도 함께 살펴보자. uncertainty가 위에서 살펴본 것처럼 어떤 확률분포를 따른다고 가정하고 큰 수의 법칙이나 중심 극한 정리와 같은 이론들을 모델 학습에 적용할 때, 최적화의 관점에서 효율적인 계산 방법을 도출할 수 있다. 데이터의 수 m이 늘어날 때, uncertainty vector ui의 집합적인 성질에 의해 불확실성의 증가율은 감소한다. 따라서 앞에서처럼 constraint를 하나씩 따로 살펴보는 것보다는 데이터 수에 따라 확률 이론들을 이용하는 것이 좋다.
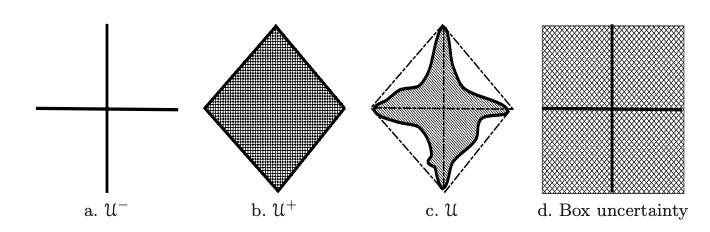
위 그림은 n=1,m=2일 때의 예시이다.
직관적으로, 이 정의는 uncertainty m개가 aggregate 되었을 때 불확실성이 그대로 더해져서 linear하게 증가하는 것이 아니라 sublinear하게 증가하도록 정의된 집합을 말한다. (d)는 이를 만족하지 않는 예시이다.
SAU의 예시로는 다음이 있다.
I. U={(u1,...,um)∣∑i=1m∣∣ui∣∣≤c}
II. U={(u1,...,um)∣∃t∈[1:m]s.t.∣∣ut∣∣≤c,ui=t=0}
III. U={(u1,...,um)∣∑i=1mc∣∣ui∣∣≤c}
이들은 모두 atomic uncertainty set U0={u∣∣∣u∣∣≤c}로부터 aggregate된 것이다. 이제 결론인 다음 Theorem으로 나아가 보자.
Theorem 2. Linearly separable하지 않은 데이터에 대한 robust SVM 문제를 정의하자. SAU와 임의의 regularization term에 대하여 위의 robust SVM 문제는 아래의 최적화 문제와 동일하다. r(⋅,⋅)이lower-semi continuous 일 경우 이 문제를 풀 수 있다.
proof idea. 자세한 증명은 이 논문에서 확인할 수 있다. v(w,b)=defu∈U0sup(wTu)+∑i=1m[1−yi(⟨w,xi−ui⟩+b)]+라고 하자.
SAU의 정의에 의해 임의의 w^,b^에 대해 항상 아래의 부등식이 성립한다. (u1,...,um)∈U−sup(w^Tu)+∑i=1m[1−yi(⟨w^,xi−ui⟩+b^)]+≤(u1,...,um)∈Usup(w^Tu)+∑i=1m[1−yi(⟨w^,xi−ui⟩+b^)]+≤(u1,...,um)∈U+sup(w^Tu)+∑i=1m[1−yi(⟨w^,xi−ui⟩+b^)]+
먼저 주어진 데이터가 non separable인 것으로부터 v(w^,b^)≤(u1,...,um)∈U−sup(w^Tu)+∑i=1m[1−yi(⟨w^,xi−ui⟩+b^)]+를 증명할 수 있다. 다음으로 (u1,...,um)∈U+sup(w^Tu)+∑i=1m[1−yi(⟨w^,xi−ui⟩+b^)]+≤v(w^,b^)를 separable 여부와는 관계없이 보일 수 있다. 따라서 등식 관계가 성립하는 것을 알 수 있고, regularization term을 양변에 더한 뒤 infimum을 취하면 theorem 2 형태와 같아진다.
여기로부터 다음 따름정리를 얻을 수 있다. Corollary. dual norm으로 bound된 uncertainty set T={(u1,...,um)∣∑i=1m∣∣ui∣∣∗≤c} 에 대한 robust SVM 문제에서 다음 두 표현은 서로 동치이다.
proof. U0={u∣∣∣u∣∣∗≤c},r(w,b)=0이라고 하면 sup∣∣u∣∣∗≤c(wTu)=c∣∣w∣∣이므로 Theorem 2에서 유도할 수 있다.
이 정리는 노이즈가 있는 데이터에서 regularization이 robustness를 가져다줌을 수학적으로 보인 것이다. 또한 uncertainty set을 데이터에 따라 적절히 디자인할 수 있다면, cross validation을 사용할 필요 없이 좋은 regularizer를 얻어낼 수도 있음을 알 수 있다.
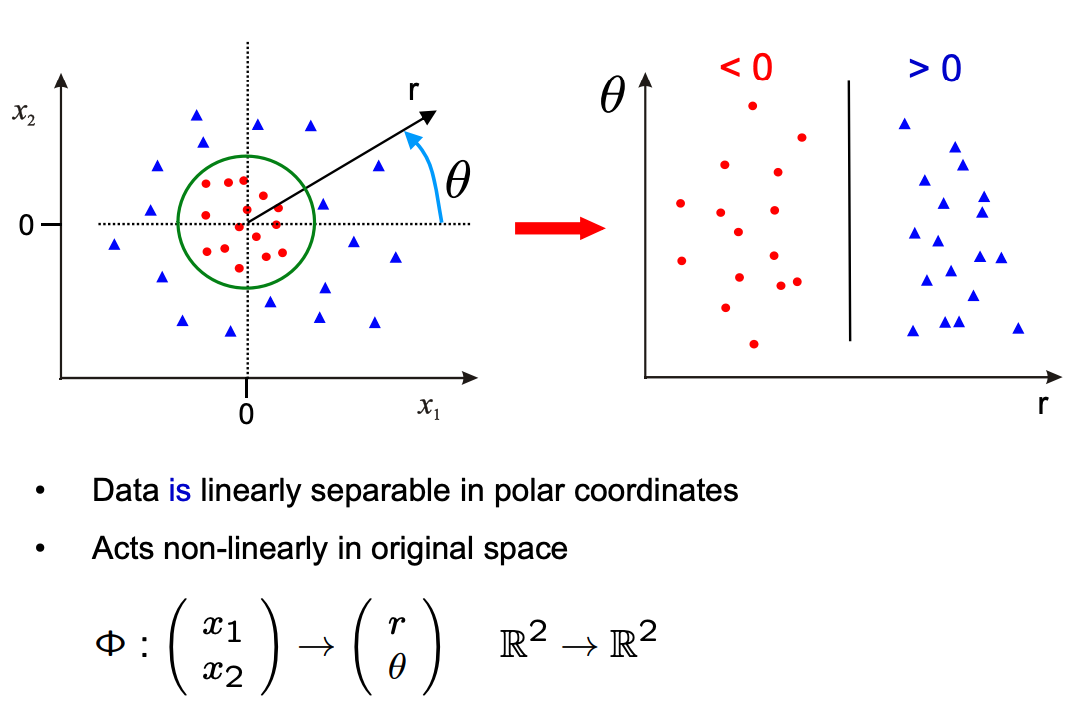
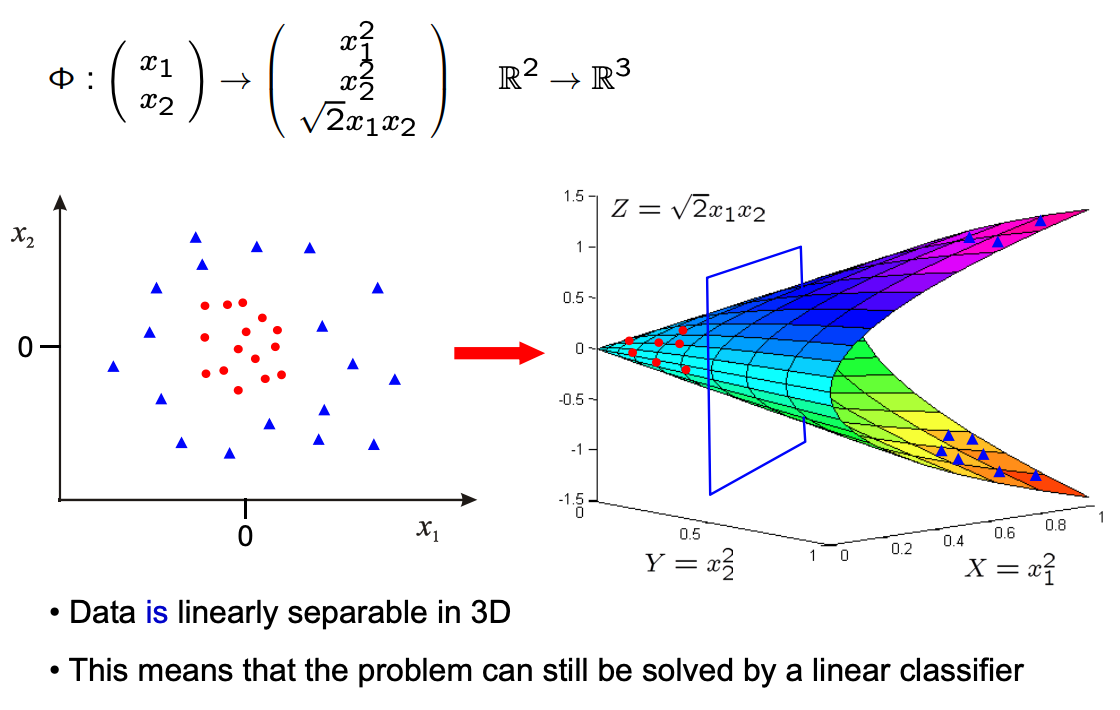
또한 이 정리의 결과는 kernel SVM으로도 일반화될 수 있다. (kernel SVM은 데이터가 non-linearly separable하거나 더 큰 차원에서 separable할 때 데이터 x를 feature space(Hilbert space) H로 맵핑해 nonlinear decision boundary를 찾아내는 것을 말한다. 자세한 내용은 이 자료나 이 글을 참고하자.)
즉 위의 theorem들에서 x,u∈Rn을 Φ(x),u∈H로 바꾸어도 모두 성립한다는 뜻이다. 다만 무한 차원으로의 맵핑인 가우시안 커널을 사용할 경우에는 (Φ(x),y)가 항상 separable한데, 이 경우에는 동치 관계가 성립하지 않지만 Theorem 2의 objective가 원래 문제 objective의 upper bound이다. 또 따름정리 역시 norm, dual norm ∣∣⋅∣∣,∣∣⋅∣∣∗ 대신 z∈H에 대한 RKHS norm ∣∣z∣∣H=⟨z,z⟩로 바꾸어도 성립한다.
따름정리만 다시 기술해 보자.
Corollary. RKHS norm으로 bound된 uncertainty set TH={(u1,...,um)∣∑i=1m∣∣ui∣∣H≤c} 에 대한 robust SVM 문제에서 다음 두 표현은 서로 동치이다.
그러면 아래 부등식이 성립한다. ∣∣Φ(x^+u)−Φ(x^)∣∣H≤f(∣∣u∣∣22),∀∣∣u∣∣2≤ρ,x^+u∈X
k(x,x)=⟨Φ(x),Φ(x)⟩임을 이용해 쉽게 보일 수 있다. 이 정리는 feature space에서의 robustness가 sample space에서의 robustness보다 더 강한 조건임을 나타낸다. 즉 feature space 관점에서의 robust classifier는 sample space의 관점에서도 robust classifier이다.
2-2. Probabilistic interpretations
이제 aggregated uncertainty에서의 chance-constrained SVM에 살펴보자.
uncertainty (u1r,...,umr)이 어떤 알려진 확률 분포를 따르는 확률변수라고 하자. 이때 어떤 신뢰 수준 η 하에서 hinge loss의 upper bound를 찾을 수 있다. 즉 chance-constrained SVM은 average hinge loss의 η-quantile을 최소화하는 문제이다. 수식으로 나타내면 아래와 같다.
섹션 1에서 살펴봤던 것은 각각의 hinge loss에 대한 constraint를 모두 만족시키는 경우이지만, 너무 보수적인 세팅일 수 있기 때문에 이번에는 모든 샘플에 대한 loss의 합 또는 평균에 대한 제약 조건을 살펴보는 것이다. 위의 문제는 일반적으로 풀기 어렵기 때문에 풀기 쉬운 constraint로 근사해야 한다. c^=definf{α∣P(∑i=1m∣∣ui∣∣∗≤α)≥1−η}라고 하자. c^는 uncertainty의 분포를 안다고 가정했기 때문에 쉽게 찾을 수 있다. 이때 임의의 (w,b)에 대하여, 최소 1−η의 확률로 다음이 성립한다.
따라서 이 protection의 upper bound는 위의 따름정리에서 살펴본 regularization term을 조금 완화시킨 것과 같다.
b. Bayesian regularizer
이번에는 regularization parameter cr=def∑i=1m∣∣uir∣∣∗가 prior distribution ρ(⋅)을 따르는 확률변수라고 하자. 이런 세팅은 데이터가 특성이 다른 집단들에서 혼합되어 수집되었을 경우 유용하다. Bayesian hinge loss를 최소화하는 문제는 다음과 같이 표현될 수 있고, 위의 따름정리에 의해 변환할 수 있다.
w,bmin:∫{∑i=1m∣∣ui∣∣∗≤cmaxi=1∑m[1−yi(⟨w,xi−ui⟩+b)]+}dρ(c) is equivalent to w,bmin:cˉ∣∣w∣∣+∑i=1m[1−yi(⟨w,xi⟩+b)]+
즉 베이지안 관점에서 최적의 cr은 cˉ=∫cdρ(c)로 prior distribution의 기댓값이고, 이는 cross validation 없이 도출된 유용한 결과이다.
3. Consistency of Learning
지금까지 설명한 기계학습 문제에서 robust optimization의 의의는 데이터 수집의 불완전성에 대비할 수 있다는 것이었다. 우리가 일반적으로 생각할 수 있는, 이런 데이터의 불확실성에 대처하는 가장 좋은 방법은 데이터의 수를 아주 많이 늘리는 것이다. 그리고 데이터의 수가 늘어나면 몇몇 조건 하에서 우리가 아는 asymptotic theory를 이용할 수 있다. 이번 문단에서는 이런 이론들 중 매우 중요하게 다루어지는 consistency의 개념에 대해 알아볼 것이다. 그리고 세션 교재의 참고 논문에서는 SVM의 consistency를 robust optimization 문제의 관점에서 접근해 수학적으로 증명하고 있다. 즉 statistical learning theory를 다루는 하나의 통합된 관점을 제시하는 것이 교재 저자의 의도이다.
X,Y를 데이터가 분포된 sample space라고 하고, sample space에서 뽑힌 (x,y)가 따르는 분포를 P라고 하자. Sample space는 가능한 데이터를 모두 가진 공간이라는 점에 유의하자. SVM과 같은 supervised learning 문제의 목적은 f(x)=y라고 가정하고 이 f를 최대한 가깝게 추정한 f^를 찾는 것이다. 그러면 sample space 상의 임의의 데이터에 대한 Mean squared loss function은 EP∣∣y−f^(x)∣∣2로 나타낼 수 있다. 이것을 True loss라고 하자. 그리고 inff^EP∣∣y−f^(x)∣∣2는 가능한 모든 모델이 가지는 loss 중 최솟값이다. 이것을 Bayes loss라고 하자. 우리는 sample space에서 m개의 데이터 (xi,yi)i=1m을 추출해 f^(xi)를 추정한다. 이때의 loss는 m1∑i=1m∣∣yi−f^(xi)∣∣2로 나타낼 수 있다. 이것을 training loss라고 하자.
이때 learning이 consistent하다는 것은 training loss가 bayes loss로 converge in probability 또는 almost surely converge하는 것을 뜻한다. 즉, 표본 수를 늘릴수록 모델의 성능이 좋아진다는 뜻이다.
다음 thorem은 SVM의 consistency에 대해 말해준다.
Theorem 3. Bound된 sample spaceX⊆Rn 에 대해 iid training sample (xi,yi)i=1∞가 X×{−1,1}를 support로 갖는 임의의 probability distribution P에서 생성되었다고 하자. 또K=maxx∈X∣∣x∣∣2로 정의하자. 그러면 임의의 (w,b)에 대해 다음 두 조건을 만족하는 random sequence{γm,c}가 존재한다.
2.
모든 c>0에 대하여 limm→∞γm,c=0a.s.이고, 수렴은 P상에서 uniform하다.
1번 명제를 보면, 첫째 줄은 가능한 모든 분류를 수행한 뒤 남은 오류의 숫자이므로 Bayes loss를 나타낸다. 둘째는 모든 데이터에 대한 hinge loss를 말하므로 true loss를 나타낸다. 그리고 두 loss의 upper bound는 training loss + regularization term + γ term이다. 따라서 샘플 수 m이 무한대로 늘어나면, c→0에서 consistency가 성립한다. (당연하게도 무한히 많은 샘플에서 regularization은 필요 없을 것이다.)
proof idea. 자세한 증명은 이곳에서 확인할 수 있다.
우선 test data를 training data의 값에 perturbation이 포함되었다고 생각하자. 만약 이 perturbation이 그리 크지 않다면 c∣∣w∣∣+m1∑i=1m[1−(yi⟨w,xi⟩+b)]+가 total loss의 upper bound임을 아까의 따름정리로부터 바로 얻을 수 있다. 따라서 남은 것은 perturbation이 큰, 즉 training data와 이질적인 test data에 대해서 알아보는 것이다. 논문에서는 sample space를 서로 동질적인 Tc개로 분할한 뒤, 샘플이 분할된 각 공간에 속하는 것을 multinomial distribution으로 생각해 이에 대한 Bretagnolle-Huber-Carol inequality를 이용해 probability bound를 도출한다. 이 bound와 Borel-Cantelli lemma에 의해, 이질적인 test data의 비율은 0으로 수렴한다. 즉 이론상 표본 수가 무한대로 늘어나면 모든 test data를 training data와 짝지을 수 있고 이에 의해 정리가 증명된다.
4. Robustness and Generalization
TODO...
세션에서는 머신러닝 알고리즘들의 generalization에 대해 조금 더 다뤘지만, 글로 옮기는 것은 나중으로 미루겠다. 이 섹션은 이 논문을 바탕으로 구성되어 있다.