이번에는 이전에 살펴보았던 예시를 일반화해서, constraint 만족을 높은 확률로 보장하는 기회 제한 최적화(chance-constrained optimization)에 대해 알아보자. Robust optimization에서 solution이 너무 보수적(too conservative)인지 혹은 리스크가 너무 큰지, 문제 상황의 불확실성을 잘 반영하는지 여부는 문제 표현의 실용성을 평가하는 중요한 기준이 된다. 기회 제한 최적화에서 우리는 어떤 분포(알려져 있을 수도 있고, 아닐 수도 있다.)를 따르는 확률변수 U에 대해 아래의 문제를 풀려고 한다.
여기에서 ϵ은 constraint를 만족하지 못할 확률로, 0.05,0.01 등의 작은 값을 보통 선택한다. 이런 형태의 문제는 일반적으로 non-convex이기 때문에, convex 문제로 safe approximation을 시도한다. 다시 말해 어떤 convex function gi(x)≤0이면 P(fi(x,U)>0)≤ϵ이 보장되도록 하는 gi를 찾는 것이다. 가장 직접적인 해결책은 적절한 uncertainty set U를 찾는 것이다. 구체적으로, P(U∈U)≥1−ϵ이면 fi(x,u)≤0foru∈U가 P(fi(x,U)>0)≤ϵ을 보장한다. 이 때 확률 조건을 만족하는 U를 최대한 작게 설정하는 것이 문제가 된다. 또는 uncertainty set을 직접 선택하는 대신 chance constraint의 확률을 approximation하는 식의 간접적인 접근도 가능하며, 지금부터 차근차근 살펴보자.
Value at Risk (VaR)
확률변수 Z에 대해 value at risk ϵ은 다음과 같이 계산된다.
VaR(Z;ϵ)=inf{γ∣P(Z≤γ)≥1−ϵ}=inf{γ∣P(Z>γ)≤ϵ}.
즉, Z가 γ보다 1−ϵ의 확률로 작거나 같음이 보장되는 가장 작은 γ값이다. 금융 분야에서는 보통 1−ϵ=η로 반대로 표기하는데, 이 때 Z를 자산의 수익률이라고 하면 VaR(Z;η)는 자산 수익률의 lower η quantile의 lower bound, 즉 최대화 문제의 objective가 된다. 컨벡스 최적화 문제에서, Z=f(x,U), 즉 높은 확률로 0보다 작거나 같길(만족되길) 원하는 constraint라고 하면 VaR(Z;ϵ)≤0iffP(Z>0)≤ϵ
이다. 다만 일부 특수한 경우를 제외하고 value at risk 역시 다루기 어려운 non-convex constraint를 도출하기 때문에, 조금 다른 접근이 필요하다.
Example. normal distribution and value at risk
Value at risk가 convex constraint를 도출하는 특수한 예시이다. U∈Rn이 평균이 μ, covariance matrix가 σ2I인 정규분포를 따르고 f(x,U)가 x와 U에 대한 쌍선형 형식(bilinear form)일 때, 즉 f(x,u)=∑i,k=1naikxiuk를 만족할 때 value at risk는 convex constraint를 도출한다. Z=xTU라고 하자. 그러면 P(Z≤γ)=Φ(σ∣∣x∣∣2γ−μTx)이므로 VaR(UTx−γ;ϵ)≤0은 γ≥μTx+σΦ−1(1−ϵ)∣∣x∣∣2의 second-order cone constraint와 동치이다. (ϵ≤1/2)
Safe convex approximations for chance constraints
Chance constraint를 1−ϵ의 확률로 보장할 수 있는 convex function을 construct하는 방법으로 돌아가 보자. 확률변수 Z에 대해 ϕ:R→R+가 non-negative, non-decreasing이면 1(z≥0)≤ϕ(z)임이 성립한다고 하자. 여기로부터 P(Z≥0)≤Eϕ(α−1Z)forα>0이 성립함을 확인할 수 있다. (Indicator function의 기댓값은 확률과 같고, z≥0일 때 ϕ(z)≥1인데 α−1z≥0이기 때문이다.) 따라서 Eϕ(α−1Z)≤ϵ임을 확인하면 P(Z≥0)≤ϵ을 보장할 수 있다.
또한, α를 적절히 조정하여 더욱 가까운 근사를 해낼 수도 있다. ϕ가 nonnegative, nondecreasing convex function일 때, αEϕ(αf(x,U))≤αϵ에서 perspective function (w,α)→ϕ(αw)는 w,α에 대해 jointly convex이므로, 우리는 x와 α를 optimization variable로 놓고 풀 수 있다. 이 때 구해진 α는 α≥0inf{αEϕ(αf(x,U))−αϵ}≤0, 즉 가장 가까운(tightest) convex approximation이다.
Tightest convex bounds and conditional value at risk
convex function ϕ(z)=[1+z]+=max{0,1+z}로 설정하자. 그러면 1(z≥0)≤[1+z]+을 만족한다. 위에서 얻은 tightest convex approximation을 적용하면 α≥0inf{αE[αf(x,U)+1]+−αϵ}=α≥0inf{E[f(x,U)+α]+−αϵ}≤0을 얻는다. 여기에서 α대신 −α를 대입하면 E[f(x,U)−α]++αϵ≤0를 얻는다. 이것은 conditional value at risk의 표현식으로, 아래와 같다.
CVaR(Z;ϵ)=αinf{ϵ1E[Z−α]++α}
Conditional value at risk는 x에 대한 convex function이므로 CVaR(f(x,Z);ϵ)≤0은 convex constraint가 된다.
CVaR의 정의로부터 α를 minimize out 해보자. 그러면 ∂αα{α+ϵ1E[Z−α]+}=1−ϵ1E1(Z≥α)=1−ϵ1P(Z≥α)=0이 되게 하기 위해, ϵ=P(Z≥α∗)가 되도록 α∗를 정하면 아래의 관계식을 얻는다.
CVaR(Z;ϵ)=ϵ1E[Z−α∗]++α∗ =ϵ1E[Z−α∗]+VaR(Z;ϵ)
즉 conditional value at risk는 항상 value at risk보다 크거나 같고, 추가된 term은 α∗로부터의 deviation에 대한 penelty term이다. 정확한 approximation은 필연적으로 높은 deviation을 동반할 수밖에 없기 때문이다. 따라서 CVaR을 minimize하는 것은 Z의 upper ϵ quantile과 deviation penelty를 동시에 minimize하는 것과 같고, VaR에 비해 보수적인 결과를 낸다.
또한 CVaR은 VaR 밖의 tail에 대한 expection으로 해석할 수 있다. 왜냐하면 E[Z∣Z≥α∗]=E[α∗+(Z−α∗)∣Z≥α∗]=α∗+P(Z≥α∗)E[Z−α∗]+=α∗+ϵ1E[Z−α∗]+=CVaR(Z;ϵ)이기 때문이다.
CVaR은 convex constraint를 도출하지만, E[f(x,U)−α∗]+를 analytic하게 계산할 수 없는 경우가 많아 보통 monte carlo simulation을 이용해 계산하게 된다. 따라서 계산 비용이 너무 많이 들 수 있어, 규모가 큰 문제에서는 다른 방법을 활용해야 한다.
Analytic approximation using moment generating functions
계산 비용을 줄이기 위한 수단으로, mgf를 이용해 constraint를 analytic하게 도출하는 방법에 대해 살펴보자. Safe convex approximation으로 다시 돌아가, ϕ(z)=ez로 설정하자. 이 경우에도 1(z≥0)≤ez가 만족된다. 그러면 Chernoff bound로부터 모든 λ≥0에 대해 P(Z≥t)≤Eexp(λZ−λt)가 성립한다. (Chernoff bound는 https://en.wikipedia.org/wiki/Chernoff_bound)를 참고하자. Markov inequality에 u(z)=exp(λz),c=M(λ)를 대입하면 얻어낼 수 있다.) 따라서 Eexp(α−1f(x,U))≤ϵ은 P(Z>0)≤ϵ에 대한 safe approximation임을 알 수 있다.
만약 random function f(x,U)가 모든 U에서 x에 대한 convex function이면, log-sum-exp function인 logEexp(f(x,U)) 역시 x에 대해 convex임이 성립한다. 그 증명은 아래와 같다. λ∈[0,1]에 대해 logEexp(f(λx+(1−λ)y,U))≤logEexp(λf(x,U)+(1−λ)f(y,U))=logEexp(f(x,U)λ+f(y,U)(1−λ))≤log[(Eexp(f(x,U)))λ(Eexp(f(y,U)))(1−λ)]=λlogEef(x,U)+(1−λ)logEef(y,U)
3번째에서 4번째 줄은 Hölder's inequality로, p1+q1=1일 때 aTb≤∣∣a∣∣p∣∣b∣∣q가 성립한다.
따라서 logEexp(α−1f(x,U))≤logϵ은 safe convex approximation이다. 아까의 perspective function 개념을 적용해 α에 대해 minimization하면 아래와 같은 conservative approximiation을 얻을 수 있다.
α≥0inf{αlogEexp(αf(x,U))+αlogϵ1}≤0
만약 moment generating function Eexp(f(x,U))를 계산하기 어렵다면 대체 수단을 찾아야 하는데, 좋은 방법은 적절한 mgf의 적절한 convex upper bound Eexp(f(x,U))≤ψ(x)를 찾아 대체하는 것이다. (less conservative하지만 여전히 좋은 approximation일 수 있다.)
예시로 random variable이 sub-Gaussian일 때, 그리고 f(x,U)=UTx로 linear 형태일 때를 살펴보자. Sub-gaussian 확률 분포는 정규분포에 비해 평균 근처에 집중되어 있고, variability가 제한되어 있어 극단적인 값이 나올 확률이 극히 적은 분포를 말한다. Sub-gaussian 확률 분포를 따르는 평균이 0인 independent random vector U=(U1,U2,...,Un)에 대하여, λ∈R과 σi≥0에 대해 Eexp(λUi)≤exp(2λ2σi2)이 성립한다. 또한 이 부등식은 gaussian일 경우(Ui∼N(0,σi2)), bounded random variable (Ui∈[−σi,σi]a.s.)인 경우에도 성립한다. (이 경우 이전의 Hoeffding's inequality와 동일하다.)
따라서 f(x,t;U)=UTx−t라 할 때 logEexp(αUTx−αt)≤∑i=1n2α2xi2σi2−αt이다. 따라서 위의 safe convex approximation은 아래의 조건으로 대체할 수 있다.
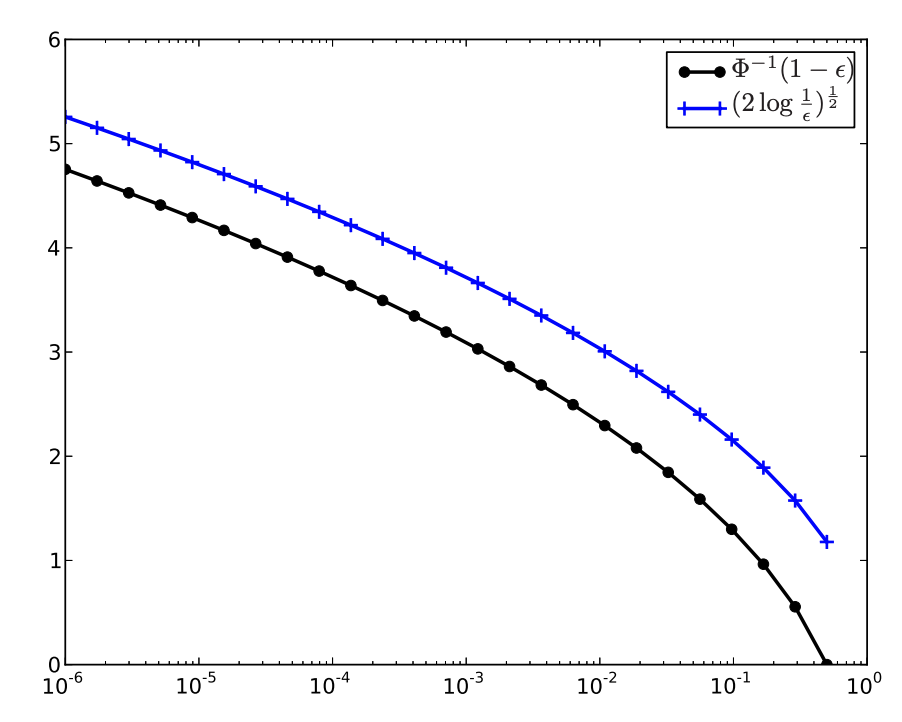
위의 normal random variable의 예시를 다시 살펴보자. U∈Rn이 평균이 μ, covariance matrix가 σ2I인 정규분포를 따르고 f(x,U)가 x와 U에 대한 쌍선형 형식(bilinear form)일 때, P(UTx>0)≤ϵ⟺VaR(UTx;ϵ)≤0⟺0≥μTx+σΦ−1(1−ϵ)∣∣x∣∣2 라고 했다. 위와 달리 mgf approximation을 이용해 구한 constraint는 μTx+2logϵ1∣∣diag(σ)x∣∣2≤0이다. 밑의 그림으로부터 mgf approximation이 VaR에 비해 더 보수적임을 알 수 있다.
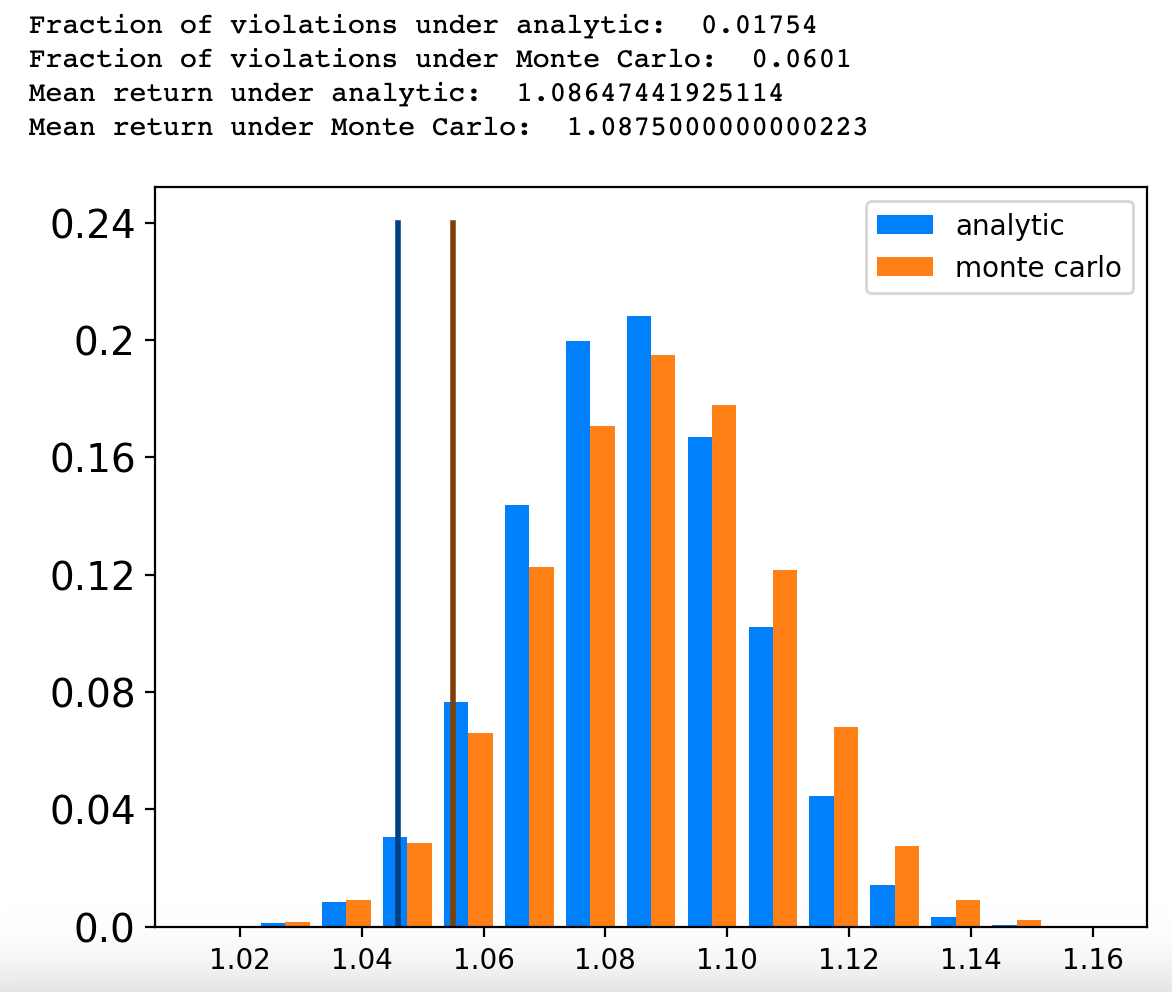
Example: analytic versus monte carlo approximations
이전의 포트폴리오 최적화를 다시 살펴보자. 이전에는 자산의 평균 수익률을 μi=1.05+0.3/i로, 수익률을 Ri∈[μi−0.6/i,μi+0.6/i]의 bounded random variable로 설정한 뒤 robust optimization을 통해 결과를 확인해 보았다. 사실 두 번째 objective인 μTx−2logϵ1∣∣diag(u)x∣∣2는 lower bound 관점에서의 VaR(RTx;ϵ)과 같다. 이번에는 convex constraint의 upper bound 관점에서 CVaR과 mgf approximation을 비교해 보자. 이 최적화 문제를 수식으로 나타내면