LLM: CoT; Chain-of-Thought
https://taeyuplab.tistory.com/15
arkiv
2022.01
https://arxiv.org/abs/2201.11903
요약
- Chain-of-Thought Prompting 방식을 사용하면 LLM의 성능을 효과적으로 올릴 수 있다.
- series of intermediate reasoning steps
- few-shot prompting
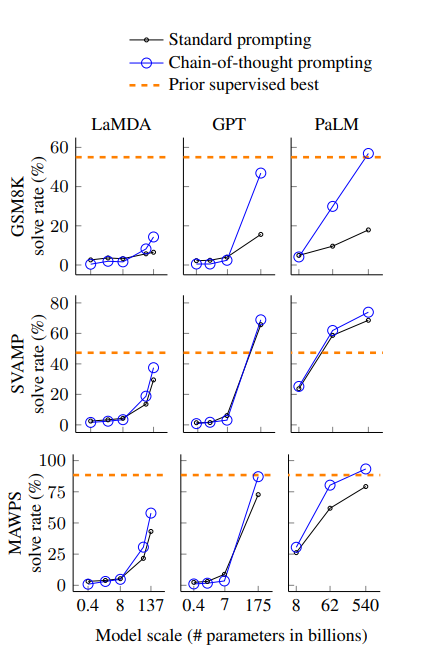
- 8개의 프롬프트 예시만 가지고 PaLM 540B의 SOTA 달성
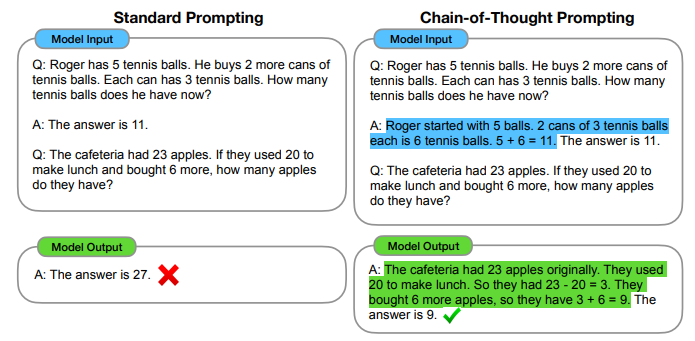
- 모델이 논리적인 프로세스를 거쳐 해답을 찾을 수 있게 함
-> 최종 결과를 생성할 때 필요한 중간 과정 및 추론 과정 역시 모델 스스로 생성할 수 있게 하는 것
CoT의 특징
- decompose multi-step problems into intermediate steps
- require more reasoning steps
- provide opportunities to debug where the reasoning path went wrong
- few-shot prompting에 Chain-of-Thought를 추가한 것
- robustness; 모든 상황에서 기존의 standard prompting(few-shot prompting)보다 성능이 좋았다.
arithmetic(산술) reasoning, commonsense(상식) reasoning, symbolic reasoning(기호적 추론; last letter concentration, coin flip) 모두 성능을 향상시킴. 모델의 크기가 커질수록 효과가 더욱 좋고, 기호적 추론 태스크에서는 적어도 100B 크기의 모델 파라미터가 필요하다는 의견