GPT-1
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
Decoder-only model
- 어떤 token이 나와야 할지 확률값으로 표현
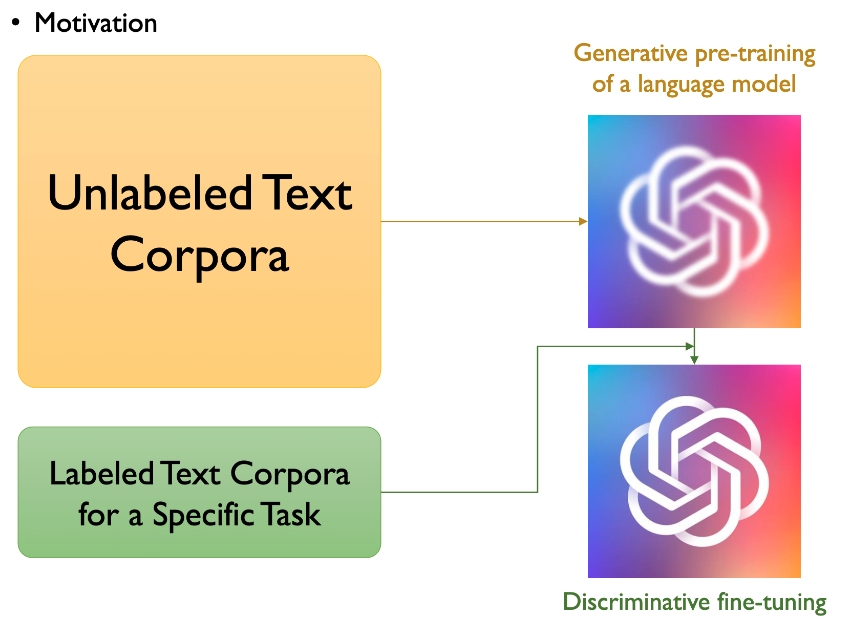
unsupervised pre-training과 supervised fine-tuning의 조합을 결합한 semi-supervised 접근 사용
transformer 구조 사용
학습은 두 단계를 거침
1. Generative Pre-training Language Model
신경망 모델의 초기 parameter를 학습하기 위해 unlabeled data에 대한 LM objective를 사용
2. Discriminative Fine-tuning Language Model
- labeled data를 활용하여 특정 과제에 맞춰 모델을 fine-tuning
- parameter를 연관된 supervised objective를 사용하여 target task에 적용
LM objective란?
GPT가 언어를 이해하고 생성하기 위해 사용하는 학습 목표
: 문맥에 맞는 다음 단어를 예측하거나 텍스트의 확률 분포를 학습
크로스 엔트로피 손실을 최소화하는 방식
기존에는 labeled 데이터셋을 사용함
labeled 데이터셋은 한정적이고 인적 자원/돈도 너무 많이 필요
unlabeled된 방대한 데이터셋을 잘 써보자
-> 이를 위해 unsupervised pre-training
라벨이 없으니까 unsupervised
unsupervised pre-training
-
k size context window를 설정
-
특정한 단어가 만약 i번째라면 i-1부터 i-k번째까지의 단어를 보고, i번째가 나올 가능성을 최대화하는 방법으로 비지도 학습을 설계한다
-
즉, i번째 text가 나올 확률을 최대화하는 것이기 때문에 maximize likelihood 기법을 loss function으로 설정하여 학습
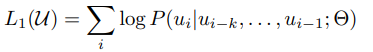
-
SGD;Stochastic Gradient Descent를 활용하여 backpropagation을 한다
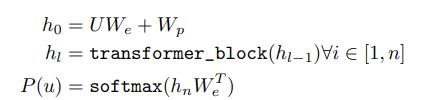
U: 입력 시퀀스의 단어 인덱스(단어들이 임베딩에 매핑되기 전의 원-핫 벡터 또는 인덱스 표현)
W_e: 단어 임베딩 행렬. 단어를 벡터로 변환하는 데 사용
W_p: 위치 임베딩(Positional Embedding) 행렬
h0: 입력 시퀀스의 단어 임베딩과 위치 임베딩이 합쳐진 초기 상태
transformer_block: attention 메커니즘과 feed-forward 신경망 포함 transformer의 구성요소
h_l-1: 이전 층의 출력
h_l: 현재 층 l의 출력
+) for all i 기호: 모든 경우에 대해
입력 상태 h0을 시작으로, transformer block을 여러 번 통과시키며 입력 시퀀스를 점점 더 높은 수준의 표현으로 변환한다.
h_n: transformer의 마지막 층의 출력
W_e^T: 단어 임베딩 행렬의 전치 행렬(출력 공간을 원래 단어 공간으로 매핑하기 위함)
P(u): 각 단어에 대한 확률 분포
단어 분포; 즉 확률을 계산하여 특정 입력 조건에서 다음 단어가 무엇인지 예측할 수 있다.
unsupervised learning을 통해서 대용량의 text데이터를 transformer decoder에 학습시켜서 LM으로 사전학습을 한 것
광범위한 언어 지식을 학습시키는 기본 단계로, 다음 단어 확률을 계산해 문맥과 의미를 이해한다.
supervised fine-tuning
두 번째 단계인 supervised fine tuning이다. unsupervised pre-training에서 학습한 것을 기반으로 특정 태스크에 맞춤화시키는 단계다.
linear+softmax의 layer만 추가하고 그 이전은 freeze시켜서 학습을 진행하여 fine-tuning 한다.
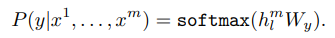
x1~xm: 입력 시퀀스(단어 또는 토큰)
h_l^m: transformer의 마지막 층 l에서 나온 m번째 입력 토큰에 대한 출력(hidden state;입력 데이터를 압축해 저장한 중간 표현:문맥 정보 등을 저장함)
W_y: 출력 단어 분포를 생성하기 위한 가중치 행렬
P(~): 입력 시퀀스 x1~m이 주어졌을 때, 특정 단어 y가 출력될 확률
softmax: 각 단어가 출력될 확률의 합이 1이 되도록 만드는 확률 분포 계산을 위한 함수
unsupervised가 문맥 정보를 기반으로 다음 단어를 예측하는 작업이었다면 supervised는 특정 입력 시퀀스에 대해 레이블(정답) y가 출력될 확률. 일반적인 언어 구조 학습보다는 특정 입력과 출력 간의 관계를 학습한다.
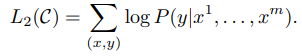
L2는 GPT1이 학습하고자 하는 task에 대한 loss function이다.
L1과 L2는 학습 목표와 데이터에 있어 차이가 있지만 방식은 같다.
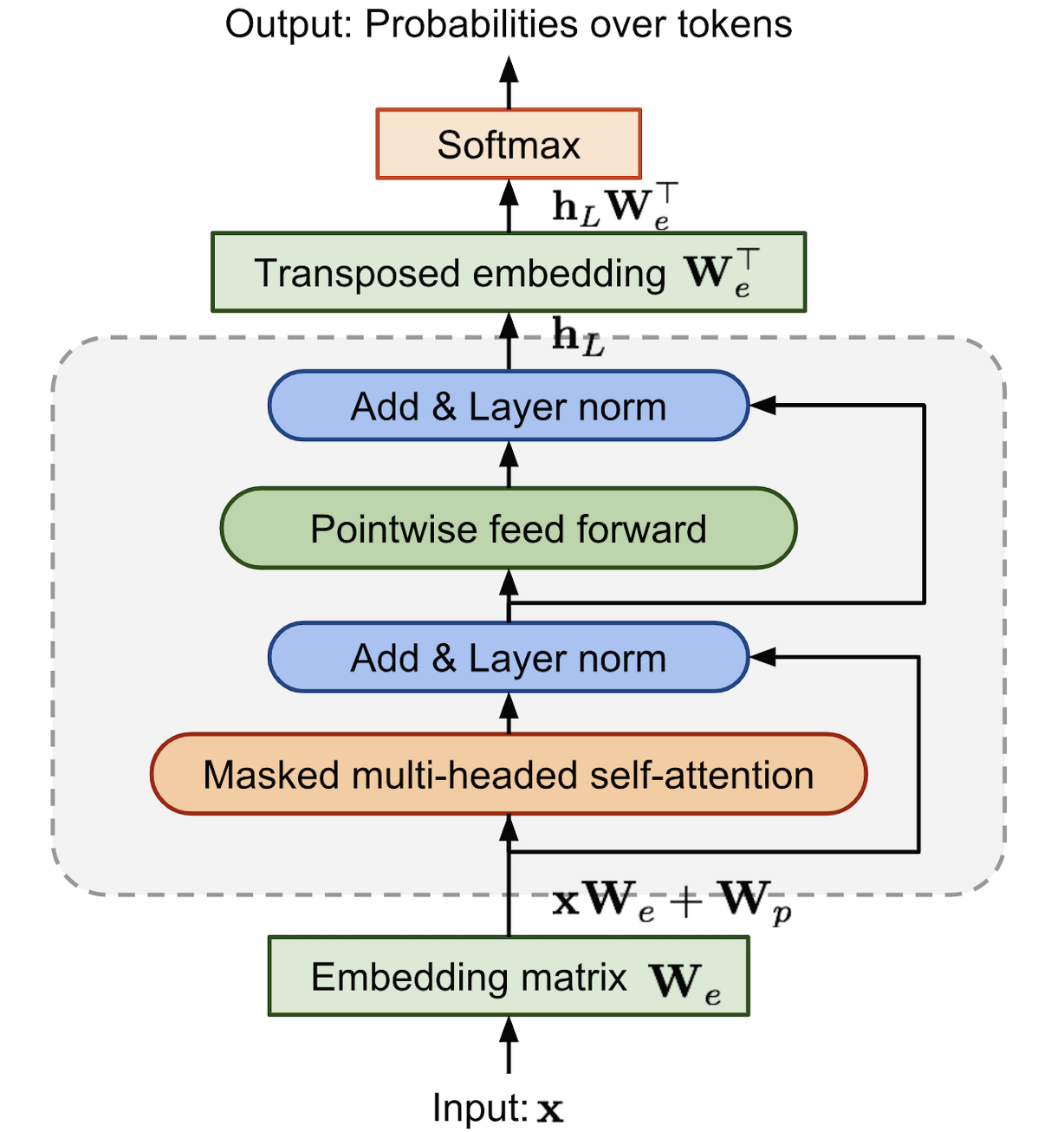
결론: GPT1은 unlabeled data를 효과적으로 사용하기 위해 unsupervised pre-training과 supervised fine tuning을 결합한 semi-supervised 접근을 사용해서 당시 NLP분야에서 SOTA를 달성했다~
