LLM: Language Models are Unsupervised Multitask Learners (GPT-2)
abstract
머신러닝 모델을 개발하는 일반적인 방법은 원하는 태스크에 맞는 데이터셋 수집/이 task를 모방할 수 있는 모델을 학습/iid hold-out example들로 검증
이들은 narrow experts로, task의 변화에 취약
이 논문에서는 다양한 태스크를 동시에 수행할 수 있는 multi-tasker 모델을 만들고자 함
근데 데이터가 너무 많이 필요하다. semi-supervised 접근이 있지만 여전히 데이터가 많이 필요함
이 문제를 해결한 GPT2는 기존 LM의 트렌드를 이어 flexible transfer가 가능하며, 지도학습 형태의 fine-tuning 없이 zero-shot setting에서 downstream task 수행이 가능한 generalist!
+유연한 transfer란, task에 따라 모델 구조를 조금만 바꿔도 금방 적용 가능하다는 말
+downstream task란, pretrained 모델을 활용하여 해결하는 특정 태스크(specific task랑 같은 말이지만 pretrained모델과 관련된 문맥에서 사용. fine tuning여부는 상관없이 용어 사용)
architecture
GPT2의 접근법의 핵심은 language modeling이다.
문장 x = (x1, x2, ..., xn)의 token sequence s=(s1, s2, ..., sn)를 사용하여 문장 x의 비지도 분포 p(x)를 측정하는 방법이다.
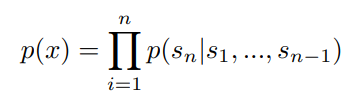
zero-shot learning
- 모든 태스크를 언어 모델링으로 통합했기 때문에(+대규모 학습 데이터) 특정 태스크의 구조를 별도로 학습하지 않아도(fine-tuning 없이도) 다양한 태스크에 적용할 수 있게 됨
모델 구조 자체는 GPT1과 크게 다르지 않다.
바뀐 점:
- GPT1에서는 layer normalization이 각각의 sub block 이후에 위치했는데, GPT2에서는 이전으로 옮겨짐
- residual layer의 initialization이 변경됨. GPT의 각 레이어는 residual connection, 즉 입력값을 그대로 다음 층으로 전달하여 신경망이 더 안정적으로 학습할 수 있도록 돕는 구조를 사용하는데, GPT2는 residual layer의 가중치를 깊이에 따라 축소하여, 네트워크가 깊어질수록 가중치 폭발이나 소실 문제를 방지한다. 이를 통해 학습이 더 안정적으로 이루어짐
training dataset
GPT2의 가장 큰 차별점은 훈련 데이터이다.
다양한 domain의 데이터를 확보하기 위해 web scraping dataset을 사용함
: 저자들이 직접 만든 WebText dataset
vocabulary와 context size가 엄청 커졌다.
- 파라미터도 13배 가량 많아졌고
- 한 번에 기존의 512 토큰의 2배인 1024 토큰까지 처리 가능해져서 더 긴 문맥 이해 능력이 크게 향상
: 더 큰 데이터셋과 residual layer initialization 개선(더 깊은 네트워크에서도 안정적으로 학습 가능하게) 덕분
input representation
본 논문에서는 BPE(Byte Pair Encoding) 방식을 채택
subword 기반의 인코딩 방법으로 문자 단위로 단어를 분해하여 vocabulary를 생성하고, 반복을 통해 빈도수가 높은 문자 쌍을 지속적으로 vocabulary에 추가하는 방법(greedy)
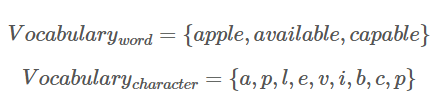
그 후, 매회 반복을 통해 자주 등장하는 문자 쌍을 greedy하게 추가한다.
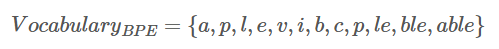
- BPE는 기존에는 유니코드 시퀀스에서 주로 동작했는데, 이는 13만개 수준의 너무 큰 vocabulary가 필요하기 때문에 저자들은 256개 수준으로 가능한 byte 수준의 string에 적용하는 시도를 했다
- 문제는 유의미하지 않은 variation(dog?, dog! 등)을 추가하는 경향이 크다는 것인데, 이를 해결하기 위해 문자 수준 이상의 병합을 막았다
실험 중 하나로 generalization vs memorization에 대한 실험이 있었는데 GPT-2는 둘다 잘하는걸로..
train set과 test set의 성능이 모델의 크기(파라미터 수)에 비례하여 같이 향상되는 경향이 있었는데 이건 모델 크기 확장이 overfitting을 유발하지 않고 generalization이 함께 향상되었다는걸 뜻한다. 학습데이터에 지나치게 의존하지 않는다는 말(과적합 되었으면 train>>test)
결론: GPT-1을 기반으로 하여 unsupervised 모델을 극대화 시켜 fine-tuning이 필요하지 않은 pretrained lm이다. 모델의 크기가 커졌기 때문에 성능이 높아졌다=multitask 가능해졌다~
