LLM: Language Models are Few-Shot Learners (GPT-3)
GPT-3
2020.05
https://arxiv.org/pdf/2005.14165
github: https://github.com/openai/gpt-3
GPT-3 특징
- few-shot learning
- 1750억 parameter(...)
- GPT-2는 14억개
GPT-2에서 fine-tuning을 하지 않는 대신 in-context learning 방식(사전학습 모델에 풀고자 하는 태스크를 텍스트 인풋으로 넣는 방식)을 채택하였지만 fine-tuning된 모델보다 성능이 떨어졌음
+) in-context learning에 zero/one/few-shot learning이 포함됨
zero-shot learning: 예제는 사용하지 않고 태스크에 대한 설명, 혹은 지시사항만을 모델에게 줌
one-shot learning: 하나의 예제만 사용
few-shot learning: 모델의 문맥 윈도우(10~100)에 넣을 수 있는 만큼 많은 예제를 넣음
+) 문맥 윈도우란 모델이 한 번에 고려하는 "문맥"의 길이. 윈도우 크기가 10이라면 최대 10개의 단어(또는 토큰)을 동시에 고려함
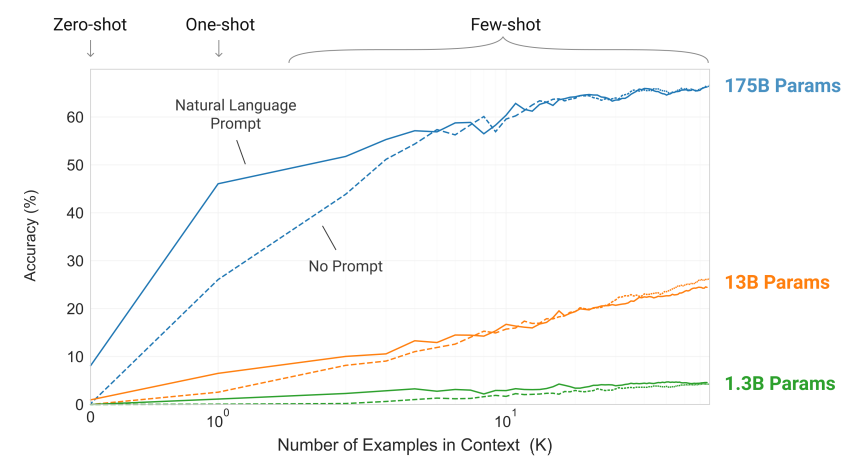
결과:
1. 테스크에 대한 자연어 설명은 모델 성능을 향상시킨다
2. 모델의 문맥 윈도우에 더 많은 예제를 놓을수록 성능이 향상(K에 비례)
3. 큰 모델일수록 in-context 정보를 잘 활용(params에 비례)
GPT-3는 대부분의 태스크에서 몇 개의 예제만 보고 잘 수행해냈다. 그중 일부는 SOTA
하지만 이 스케일로도 감당이 되지 않는 few-shot task는 ANLI 데이터, RACE, QuAC와 같은 데이터셋이었음
architecture는 GPT2와 동일
읽다보니... 파라미터 수를 엄청나게 늘리고 데이터셋도 훨씬 큰 걸 사용해서 zero/one/few-shot learning에서 성능을 대폭 향상시켰다 이정도인듯..
결론: 엄청난 스케일의 GPT-3는 fine-tuning 없이도 훨씬 더 광범위한 태스크에서 활용 가능하다~ 그중에서도 few-shot learning은 fine-tuned 모델에 근접한 성능을 보일 만큼 성능이 좋았따
