✒️ Probability and Distributions
📌 Probability
- 표본공간 (sample space) : 모든 관측 데이터를 모아놓은 집합
- 사건 (event) : 표본공간의 부분집합
표본공간 S가 주어졌을 때, 확률 P는 아래의 세 조건을 만족시키는 함수를 뜻한다
-
(positive measure) , ,
- 이 조건은 확률값의 범위를 나타냄. 0은 절대 일어나지 않음을, 1는 사건이 반드시 일어날 것을 의미함에 따라 일반적으로 0<P(A)<1은 사건이 일어날 가능성이 있음을 의미
-
(probability measure) ,
- 표본공간 전체의 확률을 나타냄
- 표본공간 S는 모든 가능한 사건들을 포함하고 있으므로, 그 확률은 반드시 1이 됨
-
(countable additivity) with (mutually distinct)
- 이 조건은 가산 가법성을 의미함. 만약 A1, A2,...가 서로 독립적인 사건들이라면, 독립된 사건들의 합집합의 확률은 각각의 확률을 더한 것과 같음
🔻Cardinality
- cardinality : 집합 A가 주어져 있을 때, 집합의 크기 |A|를 의미
-
유한 집합 : 원소의 개수가 유한한 집합
-
무한 집합 : 원소의 개수가 무한한 집합으로, 가산과 비가산으로 나뉨
- 가산 무한 집합 : 자연수 집합과 1대1 대응이 가능한 무한 집합
- 비가산 무한 집합 : 자연수 집합과 1대1 대응이 불가능한 무한집합으로, 예로 실수 집합이 있음
🔻Sequence
- sequence : 자연수 집합 N에서 어떤 집합으로 사상되는 함수로, 이 함수는 각 자연수 n에 대해 해당 집합의 원소 an을 대응시킨다. 따라서 시퀀스는 보통 an으로 표현되며, n이 변함에 따라 일련의 값들 a1,a2,a3,...를 생성한다
📌 Random Variables (확률 변수)
- 정의 : 확률 변수는 표본공간 S의 결과를 실수 R로 매핑하는 함수로, 어떤 무작위 실험의 결과를 숫자로 표현해주는 것
📍 이산 확률 변수 (Discrete Random Variable)
만약 확률 변수의 범위가 셀 수 있을 정도로 한정되어 있다면 (ex. 동전 던지기의 앞면의 수), 이를 이산 확률 변수라고 한다.
📍 연속 확률 변수 (Continuous Rnadom Variable)
만약 확률 변수의 범위가 무한하고 연속적이라면 (ex. 키, 몸무게 등), 이를 연속 확률 변수라고 한다.
🔻 확률 계산
어떤 확률 변수 X가 주어진 구간 [a,b]에 잇을 확률은, 그 확률 변수가 이산인지 연속인지에 따라 계산 방법이 다르다.
- 이산인 경우 : 특정 구간 내에 있는 모든 가능한 값에 대한 확률을 더한다
이때 f(x) 함수는 확률 질량 함수 (PMF, probability mass function)라 부른다
ex. 주사위를 던질 때 X라는 확률 변수가 3 이하의 값을 가질 확률을 계산하려면, X=1, X=2, X=3 각각의 확률을 더하면 됨!
- 연속인 경우 : 확률 밀도 함수 를 구간 [a,b]에서 적분하여 계산한다
이때 f(X) 함수는 확률밀도함수(PDF, probability density function)라 부른다
📌 Distributions
어떠한 사건에 있어서 나올 수 있는 상황을 모두 고려해 확률을 고려해보며 확률이 어떻게 분포하고 있는지 표로 보여주는 것을 확률분포표라고 한다.
| 0 | 1 | 2 | ||
|---|---|---|---|---|
| 1/4 | 1/2 | 1/4 | 1 |
즉, 확률 분포 (probability distribution)는 학률밀도함수 pdf로 이해해도 무방하다. 일반적으로 discrete(이산적)이라 하더라도 위 경우보단 경우가 많을테고, continuous(연속적)라면 표로 표현하지 못할 것이기 때문이다. 중요한 것은 표가 아니라 P(X=x) 값이 무엇이냐를 얘기해주는 것임을 유념하면 된다!
📌 Expectation, Variance, Standard Deviation, Median
📍 Expectation 기댓값
- 기댓값 : 확률분포에 따라 값을 가질 때 평균적으로 기대되는 값을 의미
기대값은 확률 가중 평균으로, 어떤 실험을 여러 번 반복할 때 평균적으로 얻을 수 있는 값이다
continuous한 경우에는 integration으로만 바꿔주면 완전히 동일하다!
📍 Variance 분산, Standard Deviation 표준편차
- 분산 : 데이터가 평균으로부터 얼마나 떨어져 있는지를 나타낸다
- 표준편차 : 분산의 제곱근으로, 데이터를 좀 더 직관적으로 이해할 수 있게 한다
🔻 A반 : 점수들이 50,60,60,70이고 평균이 60이므로 분산은
이고 표준편차는
🔻 B반 : 점수들이 30, 30, 90, 90이고 평균이 60이므로, 분산은 900이고 표준편차는 30이다
A반의 표준편차는 7, B반은 30으로, B반의 데이터가 더 분산되어 있음을 알 수 있다. 즉 B반의 성적은 A반보다 변동이 크다는 것을 의미한다
A = [50, 60, 60, 70]
B = [30, 30, 90, 90]
# case 1 - 직접 구현
def get_mean(scores: list) -> float:
mean = sum(scores) / len(scores)
return mean
mean_a = get_mean(A) # 60
mean_b = get_mean(B) # 60
# case 2 - import
import numpy as np
mean_a = np.mean(A)
mean_b = np.mean(B)
var_a = np.var(A)
std_a = np.std(A)📍 Median 중앙값
- 중앙값 : 데이터를 정렬했을 때 중간에 위치한 값
중앙값은 극단적인 값(outlier)의 영향을 덜 받아 대표값으로 유용하다. 특히 소득 같은 데이터에서 평균 대신 중앙값을 사용하는 것이 더 적절할 수 있다.
📍 Standarization and Normalization 표준화와 정규화
- 표준화 : 데이터를 평균이 0, 표준편차가 1이 되도록 변환하는 과정으로, 데이터가 다양한 분포를 가질 때 이를 동일한 기준으로 비교하기 위해 사용된다
- 정규화 : 데이터를 0과 1 사이의 값으로 변환하여 비교하기 쉽게 한다
혹은 아예 절댓값으로 나눠주어서 크기를 1로 만들어주기도 한다
📍 Quantiles 사분위수
- 사분위수 : 데이터를 크기 순으로 나열한 후 4등분했을 때 각 구간의 값을 의미한다.
박스플롯(boxplot)은 데이터를 시각적으로 비교하기 좋은 도구로, 각 데이터의 분포와 극단값을 한눈에 파악할 수 있게 해준다
import pandas as pd
import matplotlib.pyplot as plt
data_normal = {
'A': [1, 2, 3, 8, 10, 30],
'B': [7, 8, 10, 11, 15, 20],
'C': [3, 7, 11, 14, -5, 10]
}
df_normal = pd.DataFrame(data_normal)
quantiles_normal = df_normal.quantile([0.25, 0.5, 0.75])
plt.figure(figsize=(10, 6))
df_normal.boxplot()
for i, column in enumerate(df_normal.columns, start=1):
y = df_normal[column]
plt.plot([i] * len(y), y, 'r.', alpha=0.6)
for j, value in enumerate(y):
plt.text(i, value, f'{value}', fontsize=9, ha='left', va='bottom')
plt.title('Box Plot for Quantiles')
plt.ylabel('Values')
plt.grid(True)
plt.tight_layout()
plt.show()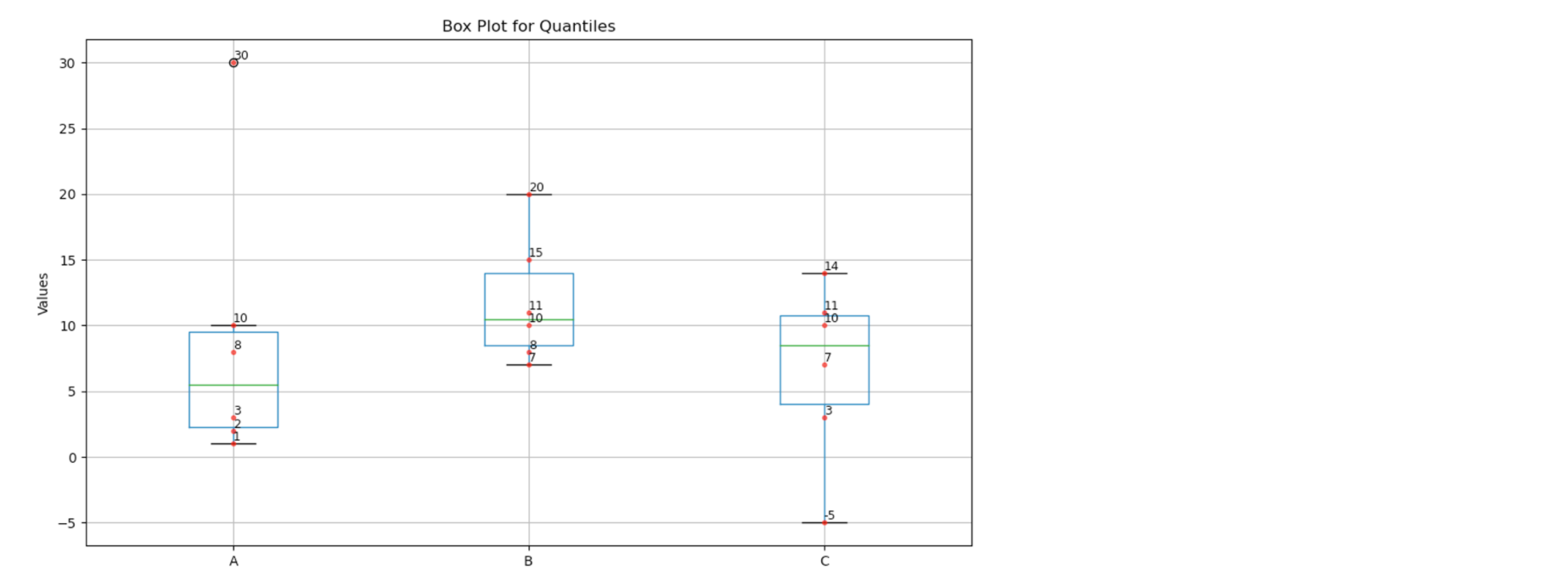
📌 Conditional Probability 조건부 확률
- 조건부 확률 : 어떤 사건이 이미 발생한 상태에서 다른 사건이 발생할 확률을 말한다
-
수학적으로는 사건 A와 B에 대해 B가 일어난 후 A가 일어날 확률을 P(A|B)로 표현하고 다음과 같이 표현한다...
-
예를 들어 확인해보자~
동전 던지기 게임을 생각해보면 두 번 동전을 던질 때 가능한 모든 결과는 HH, HT, TH, TT일 것이다
첫 번째 동전이 앞면일 때, 두 번째 동전도 앞면이 나올 확률을 구해보자
- 첫 번째 동전이 앞면일 경우의 모든 결과 : A={HH, HT}
- 두 번째 동전이 앞면일 경우의 모든 결과 : B={HH, TH}
- A와 B가 모두 일어나는 경우는 HH 하나 뿐이다. 따라서 이고, 이다
조건부 확률 는
❓ 단순 교사건과 다른 점이 무엇일까?
위 상황을 생각해봤을 때 결국 첫 번째 동전과 두 번째 동전이 모두 앞면이 나오는거 아닌가하고 의문을 품을 수 있다. 그러면 답은 1/2이 아닌 1/2 x 1/2 = 1/4가 되기 때문!
여기서 유의할 점은, 첫 번째 사건이 일어난 상황에서 두 번째 사건이 일어나는 것을 본다는 점이다!! 즉, 표본공간이 축소되는 효과가 있다.
위 예의 경우, 첫 번째 동전에서 앞면이 나오는 사건으로 표본공간 축소되었기 때문에, 그 중에서 두 번째에서도 앞면이 나오는 사건을 따지는 경우가 되는 것이다!
앞으로 모델링을 할 때 표본공간이 축소가 되어야 하는 상황인지 꼭 살펴보자~!!
📍Bayes' Rule
- 사후확률 posterior probability :
- 사건 B가 발생했을 때 A가 일어날 확률
- 달리 표현하면, B를 근거로 A가 일어날 확률을 보는 것
- 가능도, 우도 likelihood :
- 사전확률 prior probability :
- 주변확률 marginal probability :
📍Independence
사건 A,B에 대해서 사건 B가 일어날 때 A가 영향을 주지 않았다는 말은 다음과 같은 식으로 표현할 수 있다.
이를 정리하면 를 얻을 수 있다. 이러한 상황을 보고 A,B가 서로 독립이라고 한다
참고로 이를 잘못 이해해서 배반사건과 헷갈릴 수 있는데, 배반사건은 인 경우!
📌 Several Distributions
📌 Multivariate Statistics
✒️ Sample Distributions
📌 Sampling
📌 Sampling Statistics
📌 Sample Distributions
