Bibtex 인용
@inproceedings{qi2017pointnet,
title={Pointnet: Deep learning on point sets for 3d classification and segmentation},
author={Qi, Charles R and Su, Hao and Mo, Kaichun and Guibas, Leonidas J},
booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
pages={652--660},
year={2017}
}요약
- Point cloud는 irregular한 geometric data라서 보통 3D voxel grid나 collection of image로 변환해서 사용함
- 이거 불필요하게 voluminous함 그래서 여기서는 directly point를 다루는 neural network를 제시
- Object classification, part segmentation으로 scene semantic parsing
- 간단해서 efficient effective하다
1. 인트로
- 포인트클라우드나 메시들은 불규칙적인 형태를 가지고 있음 → 3D 복셀이나 cxollection of image로 변환해서 사용해야함
- 이렇게 하면 불필요하게 voluminous함
- 포인트 클라우드는 매시와는 다르게 simple and unified함 → 학습에 용이함
- 본 논문ㄴ에서 제안하는 PointNety은 unified architecture를 통해 포인트 자체를 입력으로 받아서 모든 포인트 혹은 seggment or part에 대해 label을 반환하는 네트워크
- 단순히 좌표값만을 사용함 → 다른 dimension에 대한 정본는 normal이나 other local/global feature를 계산하면서 더해질것이라 간주
- key approach는 simple symmetric function and max pooling을 이용해서 네트워크를 학습시키는것
- 놀랍게도(라는데) PointNet은 sparse한 키 포인트 셋에서 skeleton of object를 visualization기반으로 학습함
기여
- novel deep net architecture 근데 이제 unordered 3D 포인트클라우드에 대해 적합한
- 3D shape classsification, shape part segmentation, scene semantic parsing task를 하는 net을 학습시킴
- network에 대한 stability, efficency을 emperical, theoretical한 방식으로 분석을 제공
2. Related Work
Point Cloud Feature
Deep Learning on 3D Data
Deep Learning on Unordered Sets
3. Problem Statement
- object classification을 위해서는 각 포인트들이 directly sampled shape or pre-segmented from a scene point cloud여야함
- coordinate이외에도 여러 feature에 대한 정보들이 필요함
- 근데 이제 point net에서는 만 사용해서 할거고 각 class에 대해서 각각 score를 매길거임 → n포인트 m클래스면 output
4. Deep Learning on Point Sets
4.1. Properties of Point Sets in
- 입력은 euclidean space에서 추출된 point cloud의 subset
- 이미지랑 다르게 unordered라서 네트워크는 permutation invarient를 보장해야함
- not isolated라서 주위의 점이 meaningful한 subset을 이룰 수 있음
- transformation이 적용되어도 그것이 category나 segmentation of point에 invarient하게 작용해야함
4.2. PointNet Architecture
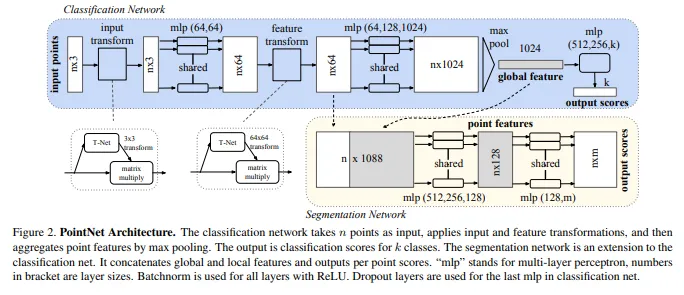
- 3개의 키 모듈
- max pooling layer as a symmetric function to aggregate information
- local/global information융합을 위한 구조
- point랑 피쳐 align을 위한 alignment network
Symmetry Function for Unordered Input
- 보통 unsorted데이터를 활용할때 아래의 세가지 정도의 solution을 사용하곤함
- 입력을 canonical order로 sort
- sort자체가 ordering issue를 완전히 resolve하지는 못함
- sort가 언제나 stable하게 유지되어야 학습이 잘되는데 보통 그렇지 못해서
- MLP는 unsorted point set에 대해서 더 나은 성능을 보임
- 입력을 RNN을 훈련하기 위한 seq로 취급
- randomly permuted seq를 RNN학습에 사용하면 학습된 네트워크는 인풋의 order에 invarient함
- 근데 RNN특성상 입력 seq에 대해서 완전히 독립적인 아웃풋을 낸다고 생각할 수 없어서 순서가 중요한 요소로 남긴함
- 그냥 각 포인트에 대해서 information을 aggregate하는 simple symmetric function
- empirically이거 잘 작동함
- 심플해서 분석도 쉽댐
- 입력을 canonical order로 sort
Local and Global Information Aggregation
- point classification은 SVM나 MLP로 간단히 됐대
- 근데 point segmentation은 llocal and global knowledge를 필요로 함
- global point cloud feature vector를 계산한 다음에 이걸 per point feature로 feedback함
- 그렇게 각 point feature에 global feature를 combine한 다음에 다시 per point feature를 extract하는 방식으로 local/global feature를 combine한다함
Joint Alignment Network
- mini network를 통해서 affine transformation 행렬을 예측하고 이거를 입력된 point의 coordinate에 적용
- mininetwork 자체는 그냥 network랑 구조는 유사하고 각 point대해 독립적인 feature 추출 및 ㅡmax pooling and fully connected layer로 이루어져있음
- 이거 똑같은거 나중에 feature level에서 한번 더 이루어지는데 이때는 단순히 공간에서 계산하는거보다 차원 짱큼 → 최적화 difficulty 커짐
- 그래서 여기에는 regularization term을 softmax loss에 추가함
4.2. Theoretical Analysis
Universal approximation
- intuitively small perturbation은 결과에 영향을 줄 수 없음
- max pooling layer에 충분히 많은 뉴런 전달시 아웃풋을 뽑아내는 function이 arbitrary approximated가능
Theorem 1.
- 가 Hausdorff distance를 기준으로 하는 function set이라 해봄
- 이론적으로 최악의 상황에서는 동일한 크기의 voxel로 분할해서 point cloud를 volumetirc representation으로 바꿀수있음
- 근데 practically network가 much smarter하게 space를 probe하는 방법을 익혔대
Bottleneck dimension and stability
- theoretically and experimentally 자기들 네트워크의 expressiveness가 dimension of max pooling layer에 크게 영향을 받음 → 이라 하고 아무말도 안하냐
- 암튼 다음 theorem을 보면 stability에 영향을 주는 properties에 대해 알 수 있대
Theorem 2.
- , , 라 가정하고
- a)
- b)
- a)는 모든 포인트가 보존된다면 extra noise에 영향받지 않는다는 거고
- b)는 가 결론적으로 element보다 작거나 같은 finite subset에 의해서 결정된다는 거래
- 그래서 critical한 point set이 된다?
- 아무튼 위에 두개를 합치면 robustness를 나타낸다네
- intuitively point net learns how to summarise a shape by a sparse set of key points
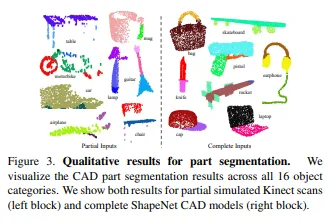
- 암튼 잘됨 ~ 1080에서 3-6시간이면 학습 ㄱㄴ

Studying