이번 포스팅은 Data Visualization에 관한 것이다.
Data Cleaning을 하는 과정에서 데이터가 어떻게 분포되어 있고, 각각이 어떤 관계를 가지고 있는지를 파악하는 것이 중요하다.
하지만 csv형식의 데이터를 그대로 읽어내서는 유의미한 정보를 파악하는 것이 쉽지 않다. 따라서, 적절한 방법으로 데이터를 시각화하는 것은 데이터를 파악하는데 큰 도움을 준다.
Python에서 시각화 라이브러리로 가장 많이 쓰이는 것은 Matplotlib이다. 또한, Matplotlib을 바탕으로 부가 기능을 추가한 Seaborn 패키지도 있다. 이번 포스팅에서는 이 두가지를 활용하여 몇 가지 시각화 방법에 대해서 알아보겠다.
1. 기본 사용법
import matplotlib.pylot as plt %matplotlib inline import seaborn as snsMatplotlib과 Seaborn을 import 해오는 구문이다. 사용상 편의를 위해 plt, sns로 줄여서 사용하는 것이 일반적인 사용법으로 보인다.
%matplotlib inline두 번째 줄의 해당 코드는 그래프의 결과를 해당 브라우저에서 바로 보여지게 하는 용도로 쓴다. 일반적으로 jupyter notebook이나 Kaggle 환경에서 코드를 실행할 때 바로 결과 그래프를 확인할 수 있어 간편하다.
plt.figure(figsize=(10,6)) sns.lineplot(data=example_data)그 이후에 plt.figure의 figsize 옵션으로 그래프가 표시되는 크기를 결정하고, seaborn 패키지의 lineplot등을 사용하여 그래프를 표시한다.
- seaborn 패키지의 API Reference는 다음 링크에 자세히 나와있다.
https://seaborn.pydata.org/api.html
2. 각종 그래프들
위 seaborn api를 통해서 어렵지 않게 그래프를 그리는 방법을 익힐 수 있다. 따라서 각종 그래프들의 사용하기 적합한 상황과 결과가 어떻게 나타나는지에 초점을 두어 결과를 확인해보자.
2.1. Lineplot
plt.figure(figsize=(10,6)) sns.lineplot(data=example_data)
Lineplot의 장점은 x축의 변화에 따라 y값이 어떻게 변화하는지 추세를 나타내는데 적절하다. 시간의 변화에 따라 값이 어떻게 변화하는지를 나타내거나, 두 변수간의 상관관계를 직관적으로 파악하는데 도움이 된다.
2.2. Barplot
plt.figure(figsize=(20,6)) sns.barplot(x=ign_data.index, y=ign_data['Racing'])
Barplot은 option으로 x의 값과 y의 값을 각각 주어 표현 가능하다. Barplot은 카테고리별 y값을 시각적으로 표현하는데 용이하다는 장점이 있다.
2.3. Heatmap
plt.figure(figsize=(20,20)) sns.heatmap(data=ign_data, annot=True)
Heatmap은 x축 데이터의 가짓수 * y축 데이터의 가짓수의 직사각형을 만들어 수치를 직접 표기하고, 값에 따라 색깔로 강도를 표현해준다. 정확한 수치를 알 수 있다는 점과 색을 통해 직관적으로 데이터를 확인할 수 있다는 것이 장점이다. 따라서, 학습 모델의 feature간 correlation을 표현하는 데도 자주 쓰인다. 그러나, feature가 너무 많은 경우에는 Heatmap의 크기가 너무 커져서 주의해서 사용해야 한다. option중 'annot=True'는 값을 표기할지의 여부를 결정한다.

2.4. Scatterplot
Scatterplot은 각각의 데이터를 점으로 표현하여 시각적으로 표현해주는 방법이다. 데이터를 가장 왜곡없이 표기할 수 있으며, 회귀곡선등을 그릴 때 많이 사용하는 방법이다.
- 기본적인 Scatterplot을 그리는 방법이다. x, y 데이터를 정해준다.
sns.scatterplot(x=candy_data['sugarpercent'], y=candy_data['winpercent'])
- 회귀곡선을 포함하여 그리는 방법이다.
sns.regplot(x=candy_data['sugarpercent'], y=candy_data['winpercent'])
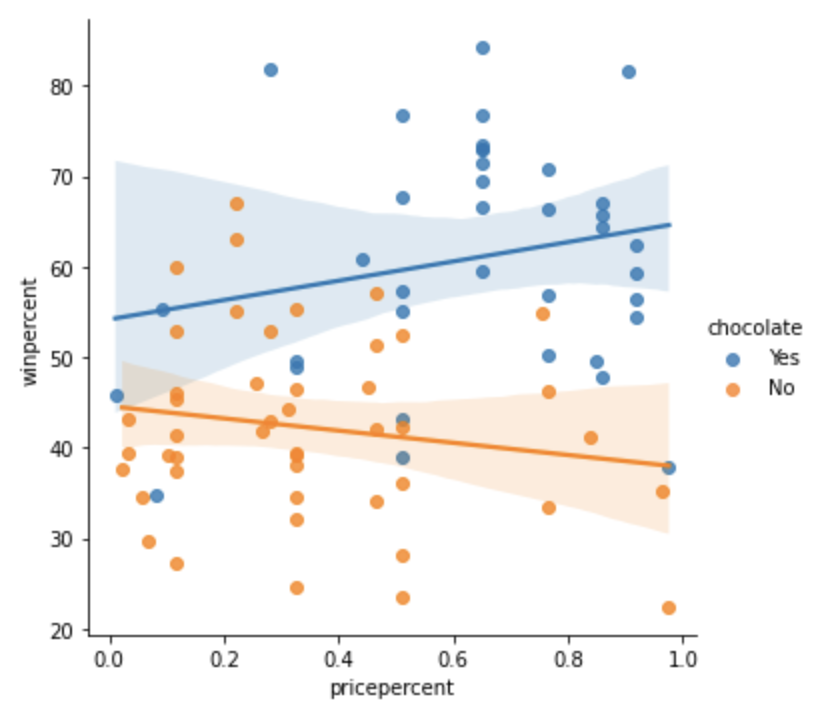
- 다음 예시는 hue옵션을 통해서 chocolate이 들어가 있는 데이터와 그렇지 않은 데이터를 색으로 구분해준다.
sns.scatterplot(x=candy_data['pricepercent'], y=candy_data['winpercent'], hue=candy_data['chocolate'])
- 위의 예시에서 구분한 것을 바탕으로 각각의 회귀곡선을 그려준다.
sns.lmplot(x="pricepercent", y="winpercent", hue="chocolate", data=candy_data)
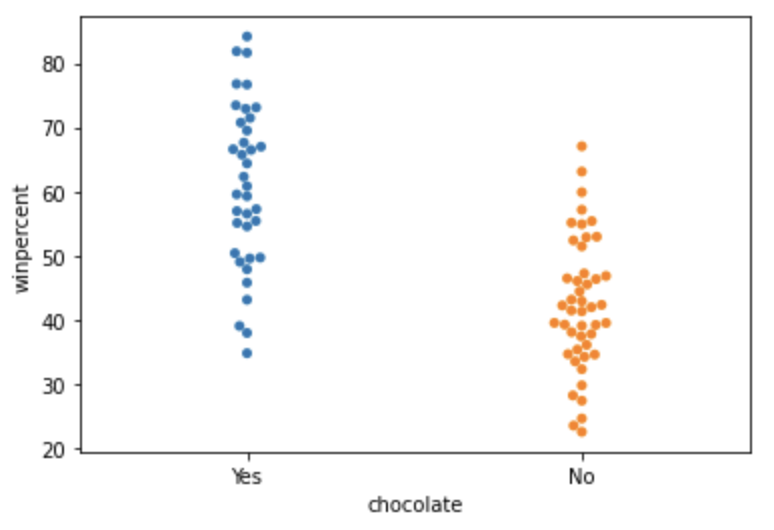
- 다음은 swarmplot으로 카테고리의 개수가 다양하지 않은 경우에 어느 곳에 많은 데이터가 분포해있는지 파악하기 더 쉽게 시각화하는 방법이다.
sns.swarmplot(x=candy_data['chocolate'], y=candy_data['winpercent'])

2.5. Distribution
지금까지는 한 가지 데이터 셋에서 항목에 따라 어떤 특징을 찾아낼 수 있는지 찾아보는 과정이었다면, 이번에는 여러가지 데이터를 사용할 때 이들의 분포를 나타내는 방법에 대해서 알아보려고 한다.
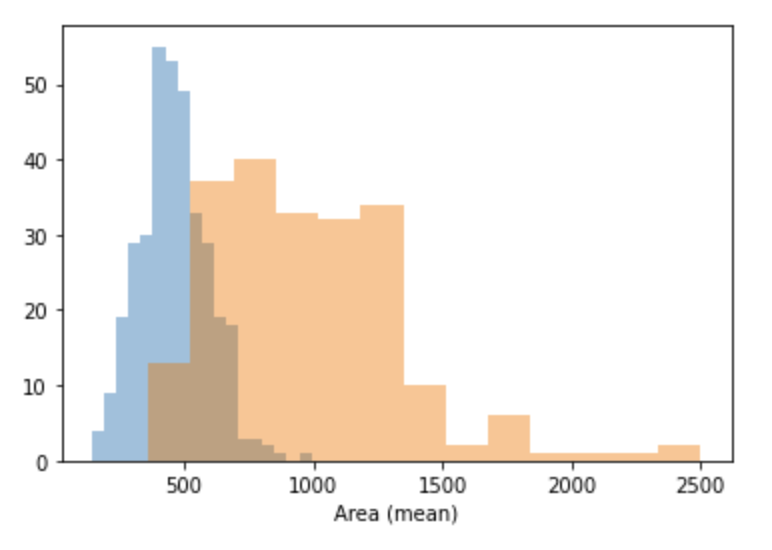
- Histogram
sns.distplot(a=cancer_b_data['Area (mean)'], kde=False) sns.distplot(a=cancer_m_data['Area (mean)'], kde=False)
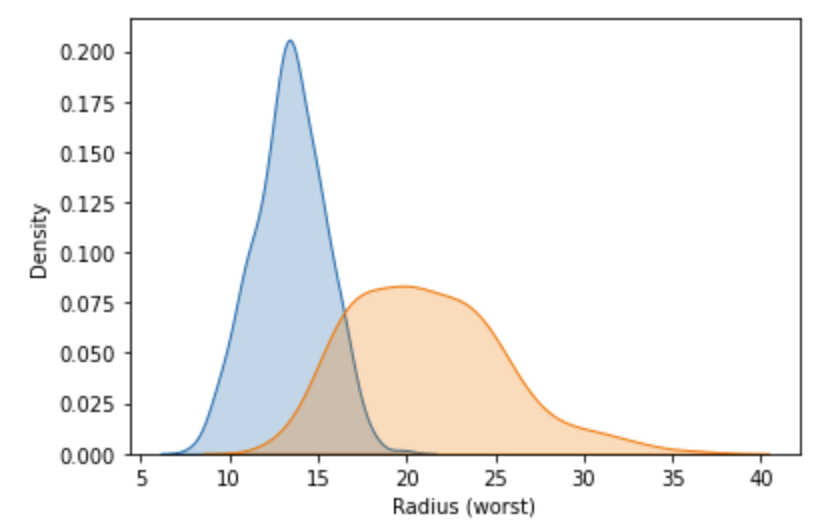
- KDE plot: KDE plot이란 간단히 말해서 Histogram의 non-parametric한 결과값을 parametric하게 추정하는 방법이다. Seaborn에서는 간단하게 KDE plot을 시각화 할 수 있는 방법을 제공한다.
sns.kdeplot(data=cancer_b_data['Radius (worst)'], shade=True) sns.kdeplot(data=cancer_m_data['Radius (worst)'], shade=True)
2.5 Design Customization
Seaborn에서 제공하는 기능으로 디자인을 Customization 할 수 있다. 아래 코드는 배경색을 바꾸는 코드이다. 기타 다른 디자인 방법들은 위 링크에 담긴 Seaborn 공식 API 문서에서 확인할 수 있다.
sns.set_style("darkgrid") sns.set_style("whitegrid") sns.set_style("dark") sns.set_style("white") sns.set_style("thicks")
(출처) Kaggle Courses <Data Visualization>
