
Steps of Text Analytics
텍스트 분석은 비정형 텍스트 데이터를 구조화하고 유의미한 정보를 추출하기 위한 일련의 과정입니다. 해당 포스트에서는 텍스트 분석의 주요 단계를 순차적으로 소개하여, 각 단계에서 수행되는 작업과 그 중요성을 설명하겠습니다.

① STEP 1. 정의 및 데이터 수집(Define & Collect)
- 텍스트 분석의 첫 번째 단계는 분석할 목표를 명확히 정의하고, 이를 수행하기 위해 필요한 텍스트 데이터를 수집하는 것입니다.
- 이 단계에서는 분석의 방향을 설정하고 필요한 데이터를 확보하여 분석의 기초를 다집니다. 예를 들어, 챗봇 개발을 위해 사용자와의 대화 데이터를 수집하거나, 특정 도메인에 특화된 대규모 언어 모델을 학습시키기 위해 관련 텍스트 데이터를 수집할 수 있습니다.
② STEP 2. 전처리 및 변환(Preprocess & Transform)
- 수집된 텍스트 데이터는 그대로 분석에 사용되기 어렵기 때문에, 전처리 과정을 통해 깨끗하고 분석 가능한 형태로 변환해야 합니다.
- 이 단계에서는 데이터에서 불필요한 요소를 제거하고, 문장과 단어 단위로 분리하여 의미 있는 분석 단위로 변환합니다. 전처리 작업에는 불용어 제거, 형태소 분석, 토큰화 등이 포함됩니다.
③ STEP 3. 특징 선택 및 추출(Select & Extract Features)
- 전처리가 완료된 데이터에서 분석에 필요한 중요한 특징을 선택하고 추출하는 단계입니다.
- 이 단계에서는 텍스트 데이터를 벡터 형태로 변환하고, 중요한 단어 또는 문서의 주제를 추출하여 분석의 핵심 요소를 도출합니다. 대표적인 방법으로는 TF-IDF, 주제 모델링(LDA), 단어 임베딩 등이 있습니다.
④ STEP 4. 알고리즘 학습 및 평가(Algorithm Learning & Evaluation)
- 최종 단계에서는 전 단계에서 추출된 특징을 바탕으로 적절한 머신러닝 알고리즘을 학습시키고, 모델의 성능을 평가합니다.
- 이 단계에서는 분류, 군집화, 회귀 등의 기법을 사용하여 텍스트 데이터를 분석하고, 모델의 정확도를 평가하여 최적의 모델을 선택합니다. 예를 들어, 스팸 메일 분류, 감성 분석, 문서 주제 분류 등이 포함됩니다.
각각의 단계에 대해서 자세하게 살펴보겠습니다:
STEP 1. 정의 및 데이터 수집
텍스트 분석의 첫 번째 단계는 분석할 목표를 명확히 정의하고, 이를 수행하기 위해 필요한 텍스트 데이터를 수집하는 것입니다. 이 단계는 분석의 전체적인 방향을 설정하고, 필요한 데이터를 확보하여 분석의 기초를 다지는 중요한 과정입니다.

① 목표 정의
-
텍스트 분석의 목표는 분석하고자 하는 문제의 성격에 따라 다양할 수 있습니다.
-
최신 트렌드를 반영한 예시로는 다음과 같습니다:
- 챗봇 개발: 사용자와의 자연스러운 대화를 통해 정보 제공, 고객 지원, 엔터테인먼트 등의 기능을 수행하는 챗봇을 개발하는 것이 목표일 수 있습니다. 이를 위해 챗봇의 대상 사용자, 주요 기능, 예상되는 대화 시나리오 등을 정의합니다.
- LLM(대규모 언어 모델) 학습: 특정 도메인에 특화된 대규모 언어 모델을 학습시키는 것이 목표일 수 있습니다. 예를 들어, 의료, 법률, 기술 지원 등 특정 분야의 전문 지식을 갖춘 모델을 개발하고자 할 때, 해당 도메인에 관련된 텍스트 데이터를 활용합니다.
- 감성 분석: 소셜 미디어, 고객 리뷰 등에서 텍스트 데이터를 분석하여 사용자 감정(긍정, 부정, 중립)을 파악하는 것이 목표일 수 있습니다.
- 주제 모델링: 대량의 문서에서 주요 주제들을 추출하여 문서의 내용을 요약하고, 정보를 체계적으로 분류하는 것이 목표일 수 있습니다.
② 데이터 수집
-
목표가 명확히 정의된 후에는 이를 달성하기 위해 필요한 텍스트 데이터를 수집합니다.
-
데이터 수집은 다양한 출처에서 이루어질 수 있으며, 수집된 데이터는 분석의 품질을 좌우하는 중요한 요소입니다:
- 웹 크롤링(Web Crawling): 인터넷 상의 웹사이트에서 자동으로 텍스트 데이터를 수집하는 방법입니다. 예를 들어, 뉴스 기사, 블로그 게시물, 포럼 글 등을 수집할 수 있습니다.
- API 활용: 트위터, 페이스북 등의 소셜 미디어 플랫폼에서 제공하는 API를 이용하여 사용자 게시글, 댓글 등의 데이터를 수집할 수 있습니다.
- 공개 데이터셋: 이미 공개된 데이터셋을 활용할 수 있습니다. 예를 들어, Kaggle, UCI 머신러닝 레포지토리 등에서 다양한 텍스트 데이터셋을 제공받을 수 있습니다.
- 내부 데이터: 기업 내부에서 생성된 고객 문의, 지원 티켓, 이메일 등의 데이터를 활용할 수 있습니다.
STEP 2. 전처리 및 변환
STEP 2-1: 텍스트 전처리 단계
- 텍스트 전처리 단계(Level 0, Level 1, Level 2)는 텍스트 데이터를 분석 가능한 형태로 변환하기 위한 순차적인 프로세스를 나타냅니다.
- 각 단계는 텍스트 데이터의 구조적 복잡성과 세분화 수준에 따라 구분됩니다.
- 이를 통해 원시 텍스트를 점차적으로 정리하고, 분석할 수 있는 구조로 변환합니다.

📌 Level 0: Text
- 기준: 전체 문서 수준에서의 전처리.
- 설명:
- 목적: 문서에서 불필요한 요소들을 제거하여 깨끗한 텍스트 데이터를 확보하는 것.
- 작업 내용:
- 광고, 그림, HTML 태그, 하이퍼링크 등의 제거.
- 문서의 전체적인 청소 작업을 수행하여 분석에 방해가 되는 요소들을 배제.
- 예시:
- 웹 페이지에서 텍스트만 추출하고 불필요한 요소(이미지, 광고 등)를 제거.
- 텍스트 파일에서 메타데이터(작성자, 날짜 등)를 제거하지 않고 유지.
📌 Level 1: Sentence
- 기준: 문장을 기본 단위로 하는 전처리.
- 설명:
- 목적: 문장을 구분하여 각 문장을 개별적인 분석 단위로 만들기.
- 작업 내용:
- 문장 경계를 인식하고 구분(문장부호를 활용하여 문장을 분리).
- 문장 경계 인식의 어려운 사례 처리(약어, 문장 내부의 마침표 등).
- 예시:
- "Mr. Smith went to Washington."처럼 약어가 포함된 문장에서도 정확히 문장 경계를 인식.
- "그는 오늘 U.S.에 갔다."처럼 약어와 문장 종료 부호를 구분.
📌 Level 2: Token
- 기준: 단어를 기본 단위로 하는 전처리.
- 설명:
- 목적: 문장을 구성하는 단어, 숫자, 기호 등을 개별 토큰으로 분리하여 분석할 수 있는 최소 단위로 만드는 것.
- 작업 내용:
- 토큰화: 문장에서 의미 있는 단어들을 추출.
- 불용어 제거: 의미 없는 단어들 제거.
- 형태소 분석: 형태소 단위로 분리하여 단어의 기본 형태로 변환(형태소는 의미를 갖는 가장 작은 단위).
- 일관성 있는 토크나이저 사용.
- 예시:
- "John’s house"를 "John", "’s", "house"로 분리.
- 불용어 "the", "a" 등을 제거.
- "running"을 "run"으로 변환(형태소 분석).
💡Level 2 추가 설명
위에서 소개한 Level2 단계에서 수행하는 형태소 분석, 형태소 단위로 분리하여 단어의 기본 형태로 변환(형태소는 의미를 갖는 가장 작은 단위)의 주요 개념인불용어 제거/Token화기법에 대해서 추가적인 설명을 드리겠습니다:
(1) Stop-words 제거
- 목적: 텍스트 데이터에서 아무런 의미가 없는 단어를 제거하여 데이터의 품질을 향상시키고 분석 속도를 높임.
- Power Distribution: 단어 빈도의 멱-급수 법칙에 따르면, 텍스트 데이터에서 일부 단어가 매우 빈번하게 출현하는데, 이 중 대부분이 불용어입니다.
- How?: 불용어 리스트를 만들어 해당 단어들을 제거함.
- 예시: 영어의 "a", "an", "the"와 같은 단어들.
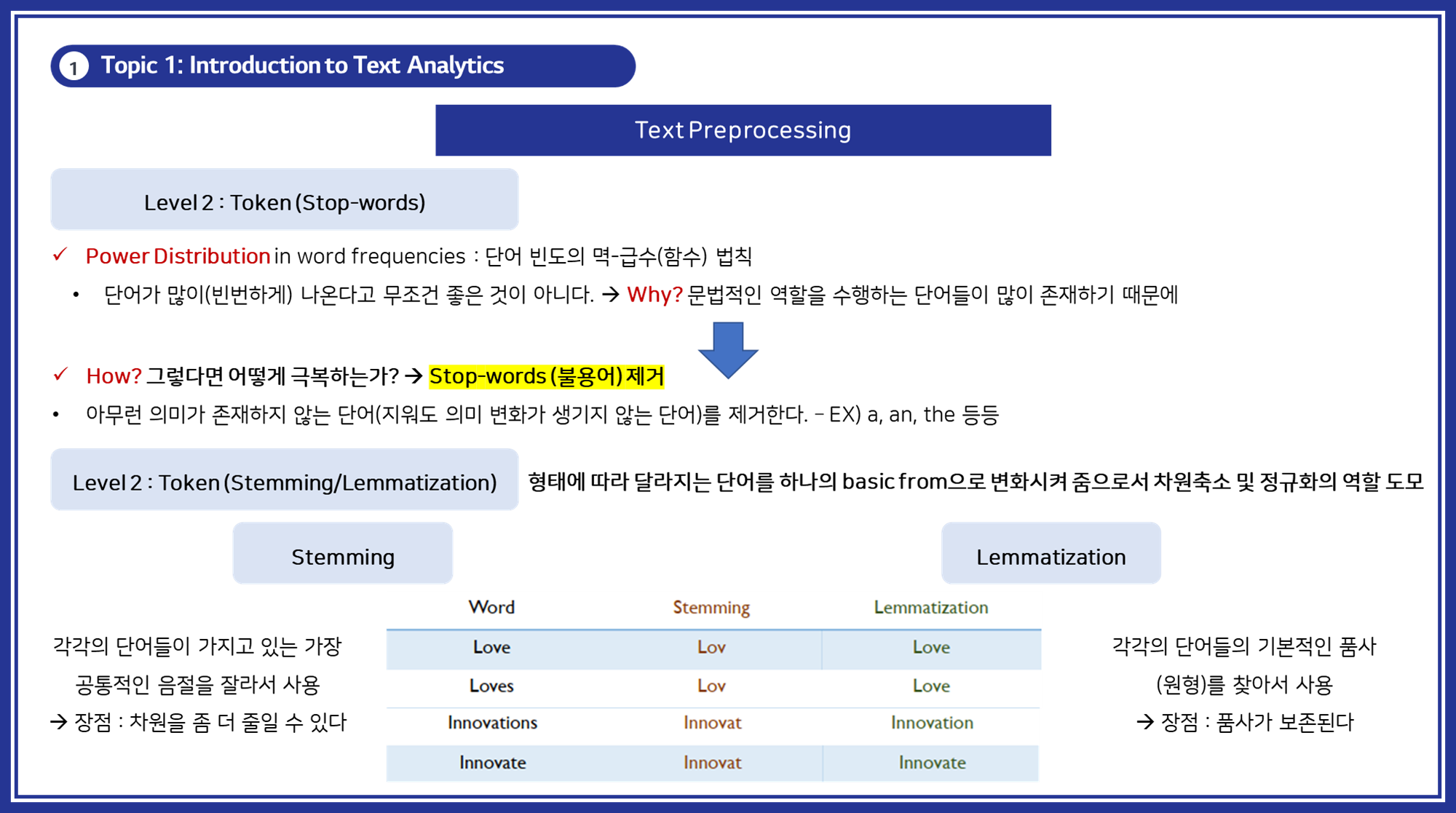
(2) Stemming 및 Lemmatization
- 목적: 단어의 다양한 형태를 정규화하여 분석의 일관성을 유지하고 차원을 축소함.
- Stemming: 단어의 접미사를 제거하여 기본 형태로 변환하는 과정.
- 장점: 간단하고 빠르며, 차원을 많이 줄일 수 있음.
- 단점: 문법적 정확성이 떨어질 수 있음.
- 예시:
- Love -> Lov
- Loves -> Lov
- Innovations -> Innovat
- Innovate -> Innovat
- Lemmatization: 단어의 기본 사전형을 찾아 변환하는 과정.
- 장점: 문법적 정확성을 유지하며 단어의 기본 의미를 보존.
- 단점: 상대적으로 복잡하고 처리 속도가 느림.
- 예시:
- Love -> Love
- Loves -> Love
- Innovations -> Innovation
- Innovate -> Innovate
텍스트 전처리의 각 단계는 점진적으로 텍스트 데이터를 정리하고 구조화하여 최종적으로 분석 가능한 형태로 만드는 것을 목표로 합니다. 아래 단계들을 통해 텍스트 데이터의 복잡성을 줄이고, 효율적인 분석을 가능하게 합니다.
- Level 0에서는 전체 문서에서 불필요한 요소를 제거하고,
- Level 1에서는 문장 단위로 구분하며,
- Level 2에서는 단어 단위로 세분화하여 최종적으로 분석에 활용할 수 있는 상태로 변환합니다.
STEP 2-2: 텍스트 변환 단계
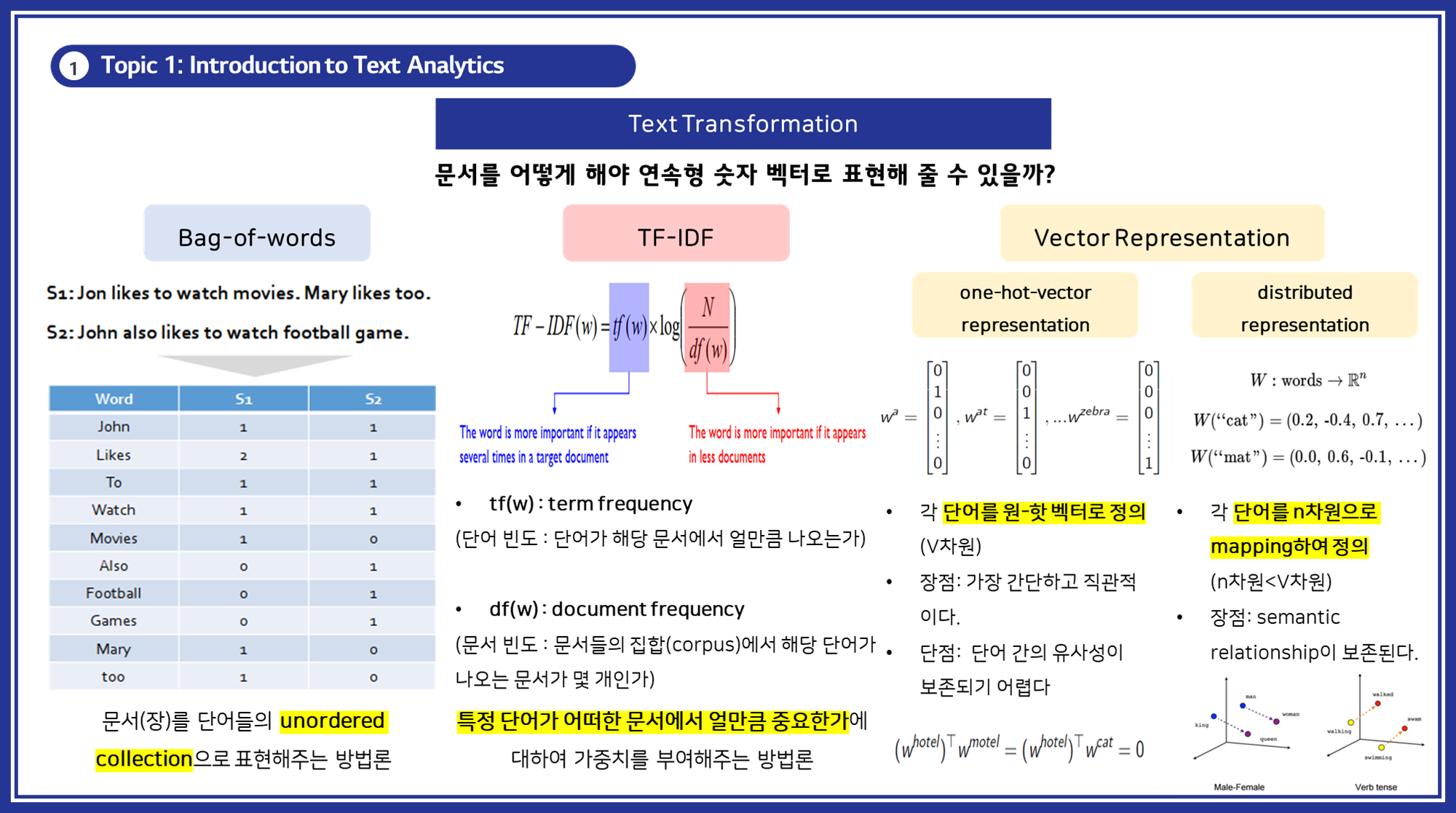
텍스트 변환 단계에서는 텍스트 데이터를 머신러닝 모델에서 처리할 수 있는 연속형 숫자 벡터(인코딩/임베딩 벡터)로 변환하는 작업을 수행합니다.
- 목적: 텍스트 데이터를 숫자 벡터로 변환하여 머신러닝 모델에서 처리할 수 있도록 하는 것이 주요 목적입니다.
- 주요 방법:
- Bag-of-words, TF-IDF, One-hot-vector, Distributed representation이 있으며, 각각의 방법에 대해 자세히 설명하겠습니다.
1. Bag-of-words
- 개념: 텍스트를 단어들의 비정렬 컬렉션으로 변환합니다.
- 목적: 각 단어의 빈도 정보를 사용하여 문서를 벡터로 표현합니다.
- 설명: Bag-of-words(BOW) 모델은 문서를 단어들의 비정렬 컬렉션으로 표현합니다. 이 방법에서는 각 문서를 고유한 단어들의 빈도를 기반으로 표현합니다.
- 작동 방식:
- 텍스트 데이터를 개별 단어로 분할(토큰화)합니다.
- 각 단어의 발생 빈도를 계산하여 벡터를 생성합니다.
- 벡터의 각 요소는 해당 단어가 문서에서 등장한 횟수를 나타냅니다.
- 장점:
- 간단하고 직관적입니다.
- 계산 비용이 낮습니다.
- 단점:
- 문맥 정보를 잃어버립니다.
- 단어 순서가 고려되지 않습니다.
- 고차원의 희소 벡터를 생성합니다.
예시:
문서1: "I love machine learning"
문서2: "I love deep learning"
단어 목록: ["I", "love", "machine", "learning", "deep"]
문서1 벡터: [1, 1, 1, 1, 0]
문서2 벡터: [1, 1, 0, 1, 1]2. TF-IDF

- 개념: 특정 단어의 중요도를 가중치로 표현합니다.
- 목적: 문서 내 단어의 중요성을 반영한 벡터화합니다.
- 설명: TF-IDF(Term Frequency-Inverse Document Frequency)는 단어의 빈도(Term Frequency)와 역문서 빈도(Inverse Document Frequency)를 조합하여 특정 단어가 문서에서 얼마나 중요한지를 가중치로 표현합니다.
- 작동 방식:
- TF: 단어 빈도는 문서 내에서 특정 단어의 발생 횟수를 나타냅니다.
- IDF: 역문서 빈도는 단어가 전체 문서 집합에서 얼마나 드물게 나타나는지를 나타냅니다.
- TF와 IDF를 곱하여 각 단어의 가중치를 계산합니다.
- 장점:
- 단어의 중요도를 반영합니다.
- 흔히 나타나는 단어의 가중치를 낮춰줍니다.
- 단점:
- 계산 비용이 높습니다.
- 여전히 문맥 정보를 잃어버립니다.
TF (Term Frequency)
- TF는 특정 단어가 문서 내에서 얼마나 자주 등장하는지를 나타냅니다.
- 계산 방법에는 여러 가지가 있지만, 가장 일반적인 방법들은 다음과 같습니다:
- Raw Count:
- TF(t,d) = 문서 d에서 단어 t의 출현 횟수
- 로그 스케일링:
- TF(t,d) = 1 + log(문서 d에서 단어 t의 출현 횟수)
- 0을 방지하기 위해 1을 더합니다.
- 이진화:
- TF(t,d) = 1 (단어 t가 문서 d에 존재하면)
- TF(t,d) = 0 (그렇지 않으면)
- 정규화:
- TF(t,d) = (문서 d에서 단어 t의 출현 횟수) / (문서 d의 총 단어 수)
IDF (Inverse Document Frequency)
- IDF는 특정 단어가 전체 문서 집합에서 얼마나 희귀한지를 나타냅니다.
- 계산 방법은 다음과 같습니다: IDF(t) = log(N / DF(t))
- N: 전체 문서의 수
- DF(t): 단어 t가 출현한 문서의 수 (Document Frequency)
- 로그를 사용하는 이유는 문서 수가 증가함에 따라 IDF 값이 너무 크게 증가하는 것을 방지하기 위함입니다.
예시:
- 아래 5개의 문장으로 TF, IDF, TF-IDF를 계산해보도록 하겠습니다:
① 사과는 빨갛다.
② 사과는 맛있다.
③ 바나나는 노랗다.
④ 바나나는 맛있다.
⑤ 강아지는 귀엽다.
1. TF (Term Frequency) 계산
-
각 문서(문장)에서의 단어 빈도를 계산합니다.
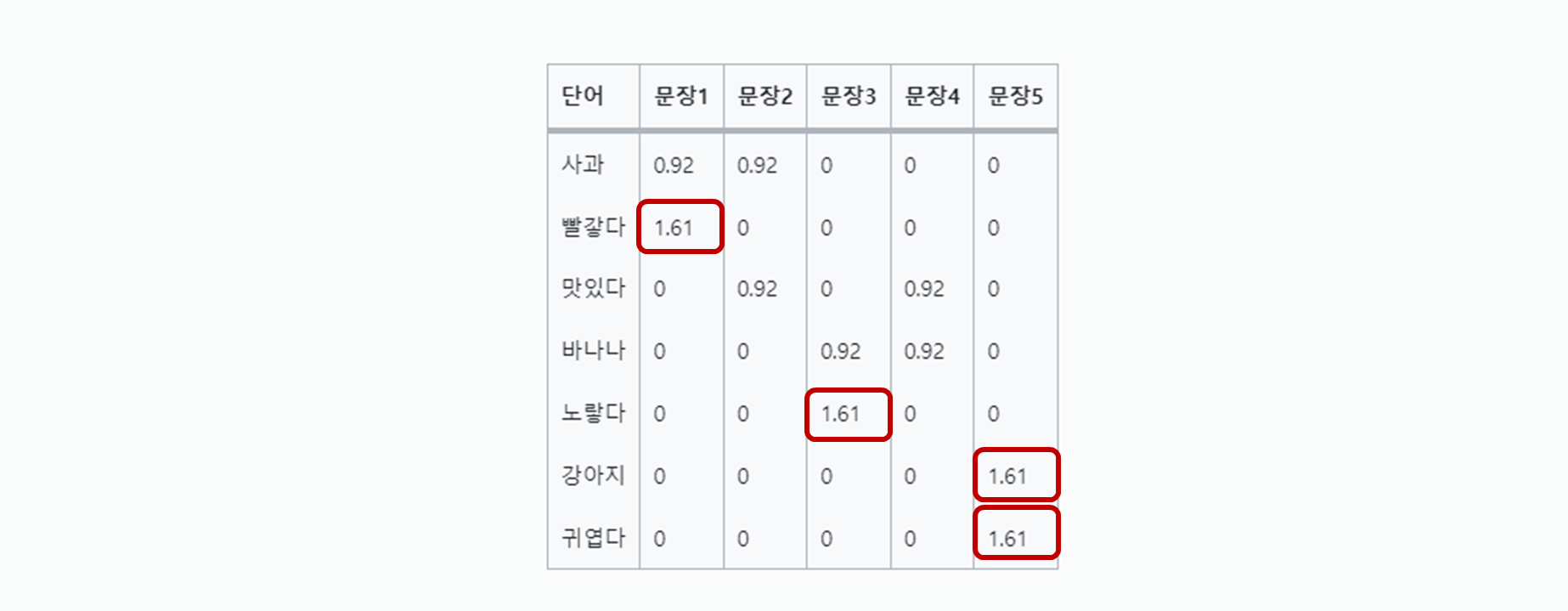
단어 문장1 문장2 문장3 문장4 문장5 사과 1 1 0 0 0 빨갛다 1 0 0 0 0 맛있다 0 1 0 1 0 바나나 0 0 1 1 0 노랗다 0 0 1 0 0 강아지 0 0 0 0 1 귀엽다 0 0 0 0 1
2. IDF (Inverse Document Frequency) 계산
-
IDF = log(총 문서 수 / 단어가 출현한 문서 수)
이때, 총 문서 수는 5(5개 문장)입니다.단어 출현 문서 수 IDF 계산 IDF 값 (반올림) 사과 2 log(5/2) 0.92 빨갛다 1 log(5/1) 1.61 맛있다 2 log(5/2) 0.92 바나나 2 log(5/2) 0.92 노랗다 1 log(5/1) 1.61 강아지 1 log(5/1) 1.61 귀엽다 1 log(5/1) 1.61
3. TF-IDF 계산
-
TF-IDF = TF * IDF
단어 문장1 문장2 문장3 문장4 문장5 사과 0.92 0.92 0 0 0 빨갛다 1.61 0 0 0 0 맛있다 0 0.92 0 0.92 0 바나나 0 0 0.92 0.92 0 노랗다 0 0 1.61 0 0 강아지 0 0 0 0 1.61 귀엽다 0 0 0 0 1.61 -
이 TF-IDF 값을 통해 각 문장에서 어떤 단어가 더 중요한지 알 수 있습니다.
-
예를 들어, "빨갛다", "노랗다", "강아지", "귀엽다"는 각각의 문장에서 높은 TF-IDF 값을 가지므로, 해당 문장을 특징짓는 중요한 단어라고 볼 수 있습니다.
3. One-hot-vector
- 개념: 단어를 고유한 인덱스의 벡터로 변환합니다.
- 목적: 단어 간의 구별을 명확히 합니다.
- 설명: One-hot-vector는 각 단어를 고유한 벡터로 정의하는 방법입니다.
- 머신러닝에서도 많이 쓰이는 기법입니다.
- 벡터의 각 요소는 해당 단어의 위치를 나타내며, 나머지는 모두 0입니다. - 작동 방식:
- 고유한 단어마다 고유한 인덱스를 할당합니다.
- 각 단어를 해당 인덱스에 1을 부여하고 나머지는 0으로 설정한 벡터로 변환합니다.
- 장점:
- 가장 간단하고 직관적입니다.
- 단점:
- 단어 간의 유사성을 표현하지 못합니다.
- 차원이 매우 높아집니다.
예시:
단어 목록: ["I", "love", "machine", "learning", "deep"]
"I" -> [1, 0, 0, 0, 0]
"love" -> [0, 1, 0, 0, 0]
"machine" -> [0, 0, 1, 0, 0]
"learning" -> [0, 0, 0, 1, 0]
"deep" -> [0, 0, 0, 0, 1]4. Distributed representation
- 개념: 단어를 다차원 공간의 벡터로 표현합니다.
- 목적: 단어 간의 의미적 유사성을 유지합니다.
- 설명: Distributed representation은 단어를 다차원 공간의 벡터로 표현하여 단어 간의 유사성을 유지하는 방법입니다.
- 대표적인 방법으로 Word2Vec, GloVe, BERT 등이 있습니다. - 작동 방식:
- Word2Vec: 단어를 고정된 크기의 벡터로 임베딩합니다. 단어의 의미적 유사성을 반영합니다.
- GloVe: 단어의 통계적 정보를 이용하여 벡터를 학습합니다.
- BERT: 문맥을 고려하여 단어의 벡터를 동적으로 생성합니다.
- 장점:
- 단어 간의 의미적 관계를 반영합니다.
- 차원이 비교적 낮아집니다.
- 문맥 정보를 포함할 수 있습니다.
- 단점:
- 학습에 많은 데이터와 시간이 필요합니다.
- 복잡한 모델일수록 계산 비용이 높습니다.
예시:
Word2Vec 예시:
"I" -> [0.2, 0.1, 0.4, 0.7]
"love" -> [0.3, 0.2, 0.1, 0.6]
"machine" -> [0.6, 0.4, 0.5, 0.3]
"learning" -> [0.7, 0.5, 0.6, 0.2]
"deep" -> [0.5, 0.3, 0.4, 0.8]🤔 잠깐! 뒤에서도 Word2Vec과 유사한 Doc2Vec이 나오는데요?
=> 텍스트 변환과 텍스트 차원 축소는 뭐가 다른거죠?
- 텍스트 변환(Text Transformation)은 텍스트 데이터를 숫자 벡터로 변환하는 과정입니다. 이 과정에서는 단어의 빈도, 중요도, 또는 의미적 유사성을 고려하여 벡터를 생성합니다. 변환된 벡터는 여전히 고차원일 수 있습니다.
- 차원 축소(Dimensionality Reduction)는 변환된 벡터의 차원을 줄여 데이터의 복잡성을 낮추고, 분석의 효율성을 높이는 과정입니다. 이는 중요한 특징만을 남기거나 의미 있는 잠재 변수를 추출하여 이루어집니다.
추가 예시
- Bag-of-words와 TF-IDF는
텍스트 변환 방법으로, 각각 단어의 빈도와 중요도를 고려하여 벡터를 생성합니다.- Distributed representation은
텍스트 변환의 일종이지만, 의미적 유사성을 반영하여 벡터를 생성합니다. 이는 차원 축소 기법을 추가로 적용하지 않아도 차원 축소 효과를 얻을 수 있습니다.- 뒤에 STEP3에서 나올 LSA, LDA, Doc2Vec는
차원 축소 방법으로, 변환된 벡터에서 중요한 특징을 추출하거나 의미 있는 잠재 변수를 통해 차원을 줄입니다.
STEP 3: 특징 선택 및 추출
특징 선택 및 차원 축소(특징 추출)는 데이터를 효율적으로 분석하기 위해 중요한 과정입니다:
-
특징 선택 (Feature Selection):
-
개념: 가장 중요한 특징을 선택합니다.
-
목적: 분석에 유의미한 특징만 선택하여 차원을 줄입니다.
-
방법:
- 정보 이득(Information gain)
- 교차 엔트로피(Cross-entropy)
- 상호 정보량(Mutual information) 등을 사용합니다.
-

- 특징 추출 (Feature Extraction):
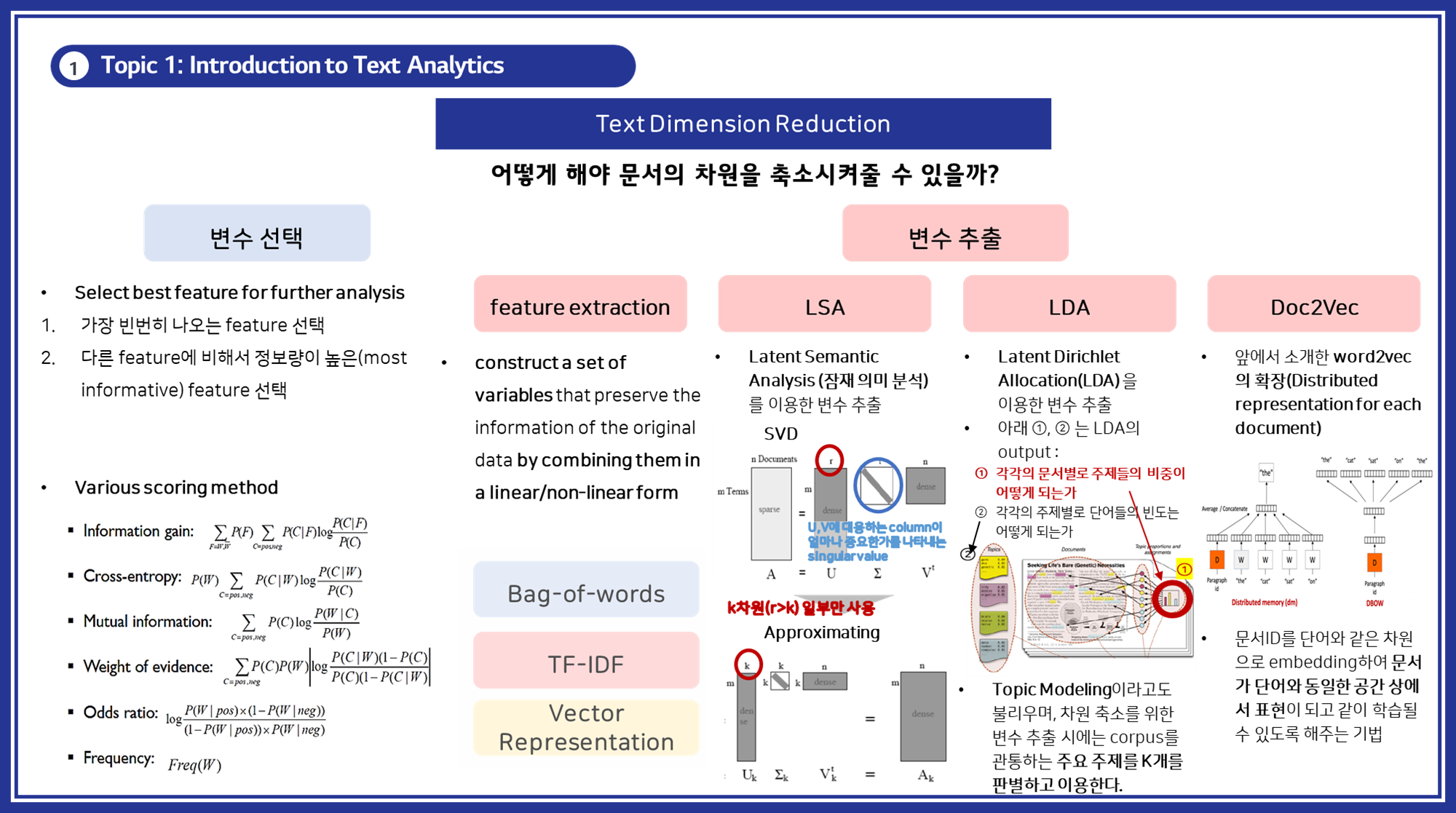
- LSA (Latent Semantic Analysis):
- 개념: 단어-문서 행렬을 SVD로 분해하여 의미를 추출합니다.
- 목적: 의미 있는 잠재 변수들을 통해 차원을 축소합니다.
- 설명: LSA는 단어-문서 행렬을 특이값 분해(SVD)를 통해 분해하여 잠재적인 의미 구조를 파악하는 기법입니다.
- 작동 방식:
① 문서-단어 행렬을 생성합니다.
② SVD를 적용하여 이 행렬을 세 개의 행렬로 분해합니다.
③ 상위 k개의 특이값만 선택하여 차원을 축소합니다.
- LSA (Latent Semantic Analysis):
- LDA (Latent Dirichlet Allocation):
- 개념: 문서 집합에서 잠재적인 주제를 추출하기 위한 확률적 토픽 모델링 기법입니다.
- 목적: 대규모 문서 집합에서 의미 있는 주제를 추출하여 문서의 차원을 축소하는 것입니다.
- 설명: LDA는 문서 집합에서 추상적인 "주제"를 발견하기 위한 확률적 토픽 모델링 기법입니다.
- (가정) 각 문서는 다양한 주제의 혼합으로 구성되어 있고, 각 주제는 특정 단어들의 분포로 표현됩니다.
- 작동 방식:
① 각 문서는 여러 주제의 혼합으로 구성되어 있다고 가정합니다.
② 각 주제는 특정 단어들의 분포로 표현됩니다.
③ 디리클레 분포를 사용하여 문서-주제 분포와 주제-단어 분포를 모델링합니다.

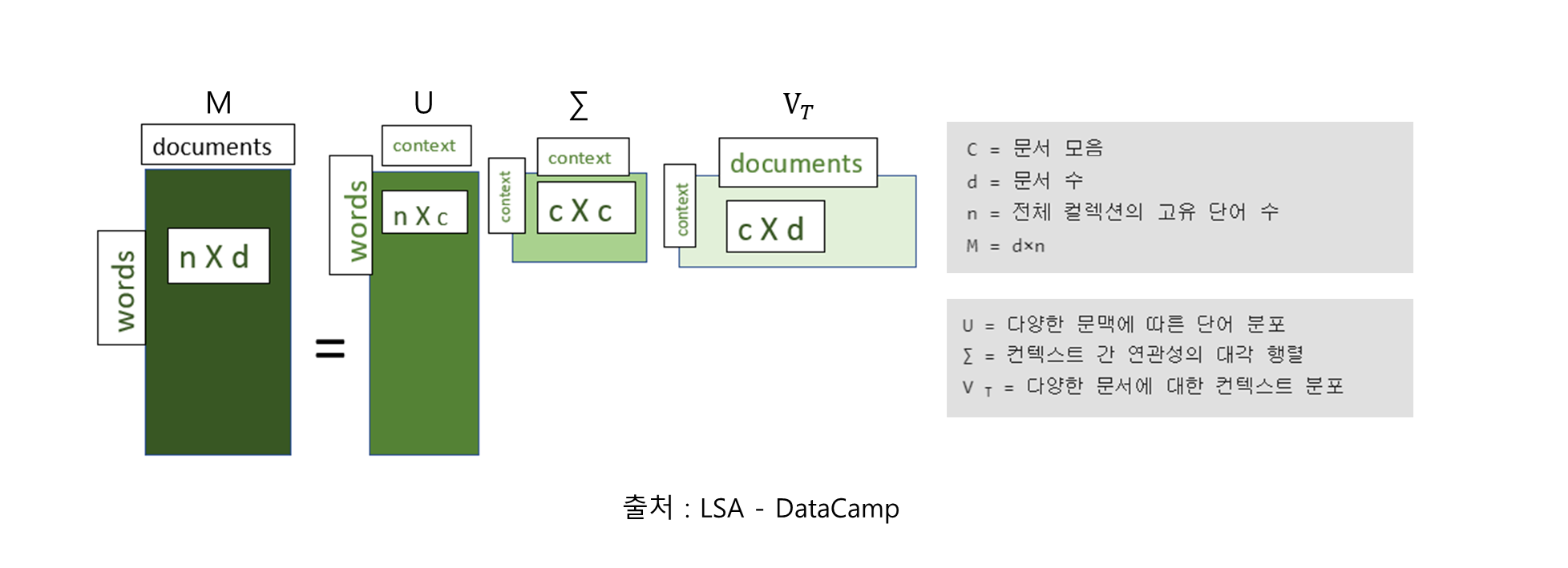
- Doc2Vec:
- 개념: 문서를 벡터 공간에 임베딩합니다.
- 목적: 문서 간의 의미적 관계를 유지하면서 차원을 축소합니다.
- 설명: Doc2Vec은 Word2Vec의 확장으로, 문서 전체를 벡터로 표현하는 기법입니다.
- 작동 방식:
① 문서 ID를 추가적인 입력으로 사용하여 Word2Vec 모델을 확장합니다.
② 단어와 문서를 동시에 학습하여 벡터 공간에 임베딩합니다.
STEP 4: 알고리즘 학습 및 평가
Text Analytics에서 모델을 학습하고 평가하는 과정은 다양한 알고리즘과 기법을 활용하여 텍스트 데이터를 분석하고 유용한 정보를 도출하는 단계입니다. 이 과정은 크게 Clustering, Classification, Extraction & Retrieval 세 가지로 나눌 수 있습니다.
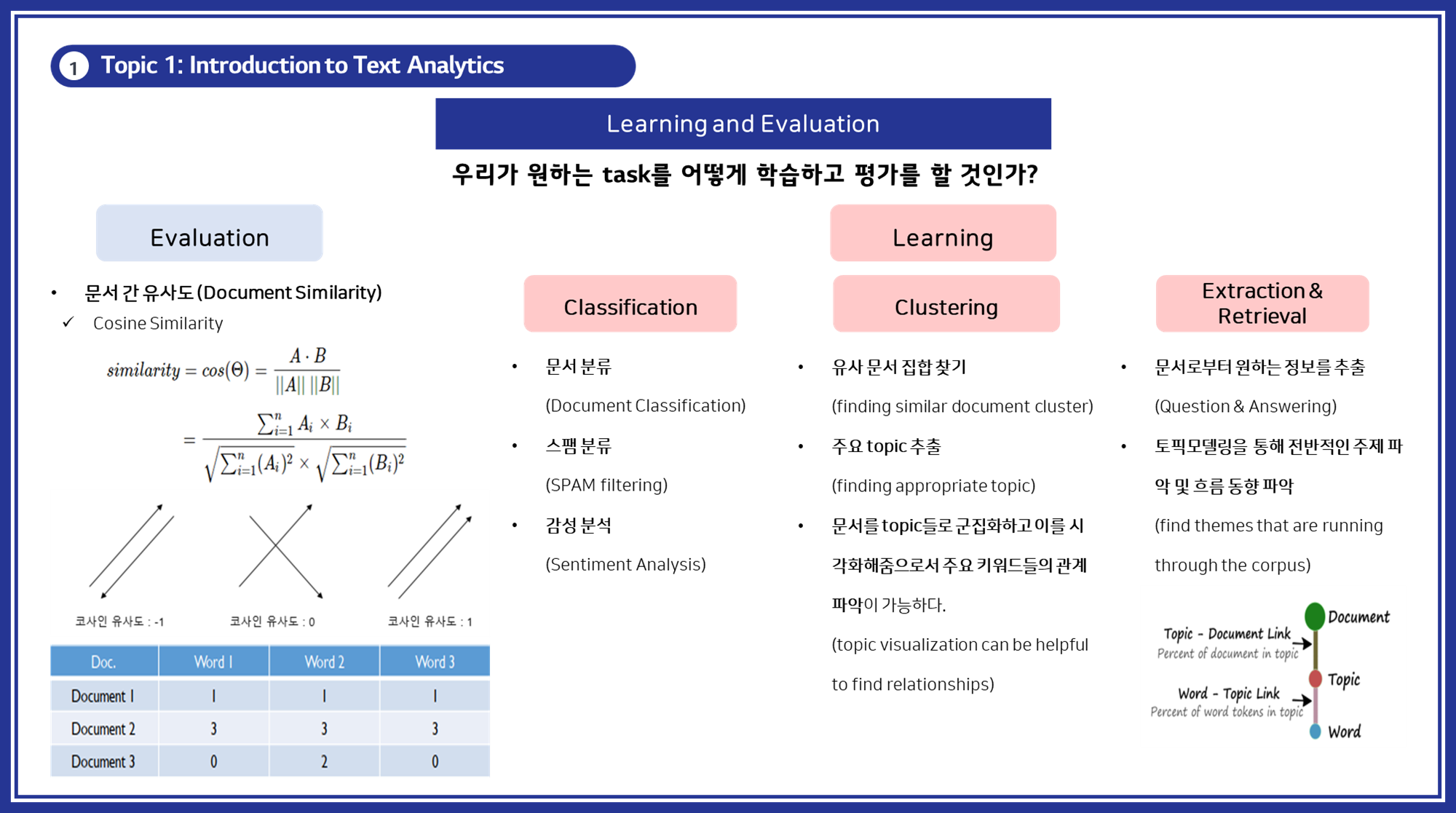
1. Clustering
Clustering은 문서들을 유사한 특성을 가진 그룹으로 묶는 과정입니다. 이를 통해 문서 군집화 및 시각화를 통해 주요 키워드 간의 관계를 파악할 수 있습니다.
- 알고리즘: K-means, DBSCAN, Hierarchical Clustering 등 다양한 군집화 알고리즘을 사용하여 문서를 군집화할 수 있습니다.
- 과정:
- 특성 추출: TF-IDF, Word2Vec, BERT 등 텍스트 임베딩 기법을 사용하여 문서의 특성을 벡터로 변환합니다.
- 군집화: 선택한 군집화 알고리즘을 사용하여 문서를 군집으로 묶습니다.
- 시각화: t-SNE, PCA 등을 사용하여 고차원 벡터를 2차원 또는 3차원으로 시각화하여 각 군집의 관계를 파악합니다.
- 응용: 뉴스 기사 군집화, 고객 리뷰 분석, 소셜 미디어 데이터 군집화 등을 통해 주요 주제나 패턴을 발견합니다.
2. Classification
Classification은 문서를 사전 정의된 범주로 분류하는 과정입니다. 이 과정은 스팸 필터링, 감성 분석, 주제 분류 등 다양한 응용에 사용됩니다.
- 알고리즘: Naive Bayes, SVM, Random Forest, Deep Learning (CNN, RNN) 등 다양한 분류 알고리즘을 사용하여 문서를 분류합니다.
- 과정:
- 데이터 전처리: 텍스트 정규화, 불용어 제거, 어간 추출 등을 통해 데이터를 정제합니다.
- 특성 추출: Bag-of-Words, TF-IDF, Word Embeddings 등을 사용하여 텍스트 데이터를 벡터로 변환합니다.
- 모델 학습: 학습 데이터를 사용하여 분류 모델을 학습합니다.
- 모델 평가: 교차 검증, 혼동 행렬, 정확도, 정밀도, 재현율, F1 점수 등을 사용하여 모델의 성능을 평가합니다.
- 응용: 이메일 스팸 필터링, 소셜 미디어의 감성 분석, 고객 리뷰의 긍정/부정 분류 등을 통해 중요한 인사이트를 도출합니다.
3. Extraction & Retrieval
Extraction & Retrieval은 문서에서 필요한 정보를 추출하고 검색하는 과정입니다. 이를 통해 중요한 정보를 효율적으로 찾고 사용할 수 있습니다.
- 정보 추출:
- Named Entity Recognition (NER): 인명, 지명, 조직명 등 명명된 개체를 추출합니다.
- 관계 추출: 개체 간의 관계를 추출하여 지식 그래프를 구축합니다.
- 요약: 문서의 주요 내용을 자동으로 요약합니다.
- 정보 검색:
- 검색 엔진: 문서 내에서 사용자가 원하는 정보를 검색합니다.
- 질문 응답 시스템: 사용자의 질문에 대해 문서에서 답을 찾아 제공합니다.
- 과정:
- 데이터 준비: 대용량 텍스트 데이터베이스를 구축합니다.
- 특성 추출: 텍스트 데이터를 인덱싱하여 검색 효율을 높입니다.
- 모델 적용: 다양한 검색 알고리즘 및 NLP 기법을 적용하여 정보 추출 및 검색 기능을 구현합니다.
- 응용: 법률 문서에서의 판례 검색, 고객 문의에 대한 자동 응답, 대규모 문서 데이터베이스에서의 정보 검색 등을 통해 시간과 비용을 절감합니다.
이번 포스팅에서는 Steps of Text Analytics, 텍스트 분석의 순서에 대해서 살펴봤습니다 🤗
