다음은 아래 "Lecture 18. Videos"에 대한 요약 및 필기 내용을 정리한 것입니다. 틀린 내용이 있다면 댓글 부탁드립니다 🙌
- Course Website: https://web.eecs.umich.edu/~justincj/teaching/eecs498/
- Instructor: Justin Johnson
- Lecture 18: Videos

Lecture 18의 내용은 비디오 데이터를 처리하고 이해하기 위한 딥러닝 모델에 대해 심도 있게 다루고 있습니다. 주요 내용은 다음과 같습니다:
1. 2D 이미지에서 3D 및 비디오로의 확장
- 이전 강의 리뷰:
- 이전 강의에서는 2D 이미지에서 객체 분류, 세그멘테이션 등 다양한 작업을 처리하는 방법을 배웠습니다. 특히 이미지 분류와 2D 형상 예측에 집중했습니다.
- 이어서 3D 형상 예측을 다루었고, CNN을 3D로 확장해 2D 이미지를 입력받아 3D 형상을 예측하거나 3D 데이터를 처리하는 방법을 논의했습니다.
- 이번 강의 주제:
- 이번 강의에서는 CNN에 시간 축을 추가하여 비디오 데이터를 다루는 방법을 학습합니다. 비디오는 시간 축이 추가된 이미지 시퀀스이므로, 이를 4차원 텐서로 표현합니다.
2. 비디오의 구조와 도전 과제

-
Video Tensor:
- 비디오는 두 개의 공간 축(H, W), 채널 축(RGB), 시간 축(T)으로 구성된 4차원 텐서로 표현됩니다.
- Video Tensor = 2D Images + Time (4D Tensor)
(Time x RGB Channel(3) x Height x Width)
- Video Tensor = 2D Images + Time (4D Tensor)
- 이러한 구조를 통해 비디오를 다루기 위해서는 3차원 공간 정보와 1차원 시간 정보를 모두 처리해야 합니다.
- Task에 따라서
Time x RGB Channel(3) x Height x Width으로 사용할 때도 있고,RGB Channel(3) x Time x Height x Width으로 사용할 때도 있습니다.
- Task에 따라서
- 비디오는 두 개의 공간 축(H, W), 채널 축(RGB), 시간 축(T)으로 구성된 4차원 텐서로 표현됩니다.
-
Image vs Video:

-
이미지 분류 task:
- 객체 인식에 초점을 맞춥니다. 이미지에서 인식하고자 하는 대상은 주로 명사(nouns)로, 고유한 공간적 범위나 정체성을 가지는 것들입니다.
- 예를 들어, 개, 고양이와 같은 동물, 병, 자동차 같은 무생물 객체 등이 있습니다.
- 이미지 분류의 목표는 주어진 이미지에서 이와 같은
객체를 인식하고 분류하는 것입니다.
- 객체 인식에 초점을 맞춥니다. 이미지에서 인식하고자 하는 대상은 주로 명사(nouns)로, 고유한 공간적 범위나 정체성을 가지는 것들입니다.
-
비디오 분류 task:
- 동작 또는 활동 인식이 핵심입니다. 비디오에서 인식하고자 하는 대상은 주로 동사(verbs)로, 시간 축에서 발생하는 행동이나 활동입니다.
- 예를 들어, 수영, 달리기, 점프, 먹기, 서 있기 등의 동작이 있습니다.
- 비디오 분류의 목표는
시간에 따라 변화하는 행동을 인식하고, 이를 분류하는 것입니다.
- 동작 또는 활동 인식이 핵심입니다. 비디오에서 인식하고자 하는 대상은 주로 동사(verbs)로, 시간 축에서 발생하는 행동이나 활동입니다.
-
계산 복잡성과 메모리 문제:
-
비디오 데이터는 매우 크기 때문에 GPU 메모리에 적재하고 처리하는 것이 어렵습니다.
- 예를 들어, 비디오 스트림을 30fps로 유지하면서도 고해상도로 처리하려면 엄청난 양의 데이터가 필요합니다.

- 예를 들어, 비디오 스트림을 30fps로 유지하면서도 고해상도로 처리하려면 엄청난 양의 데이터가 필요합니다.
-
이를 처리하기 위해 프레임 속도를 줄이거나 해상도를 낮추는 등의 전처리 과정이 필요합니다.
- 예를 들어, 짧은 비디오 클립(3~5초)을 사용하고, 해상도와 프레임 속도를 줄여 연산량을 줄입니다.

- 예를 들어, 짧은 비디오 클립(3~5초)을 사용하고, 해상도와 프레임 속도를 줄여 연산량을 줄입니다.
-
3. 비디오 분류 모델
-
단일 프레임 CNN 분류기(Single Frame CNN):

- 가장 기본적인 접근법으로, 비디오의 각 프레임을 독립적으로 처리하여 분류하고, 그 결과를 평균화해 최종 예측을 만듭니다.
- 이 접근법은 비디오의 시간적 정보를 무시하므로 단순해 보이지만, 실질적으로 매우 강력한 성능을 발휘합니다.
- 특히, 복잡한 비디오 작업에서도 좋은 성능을 보여 다른 복잡한 모델의 성능 비교 기준으로 사용됩니다. (보통 baseline으로 많이 사용함)
-
지연 융합(Late Fusion):
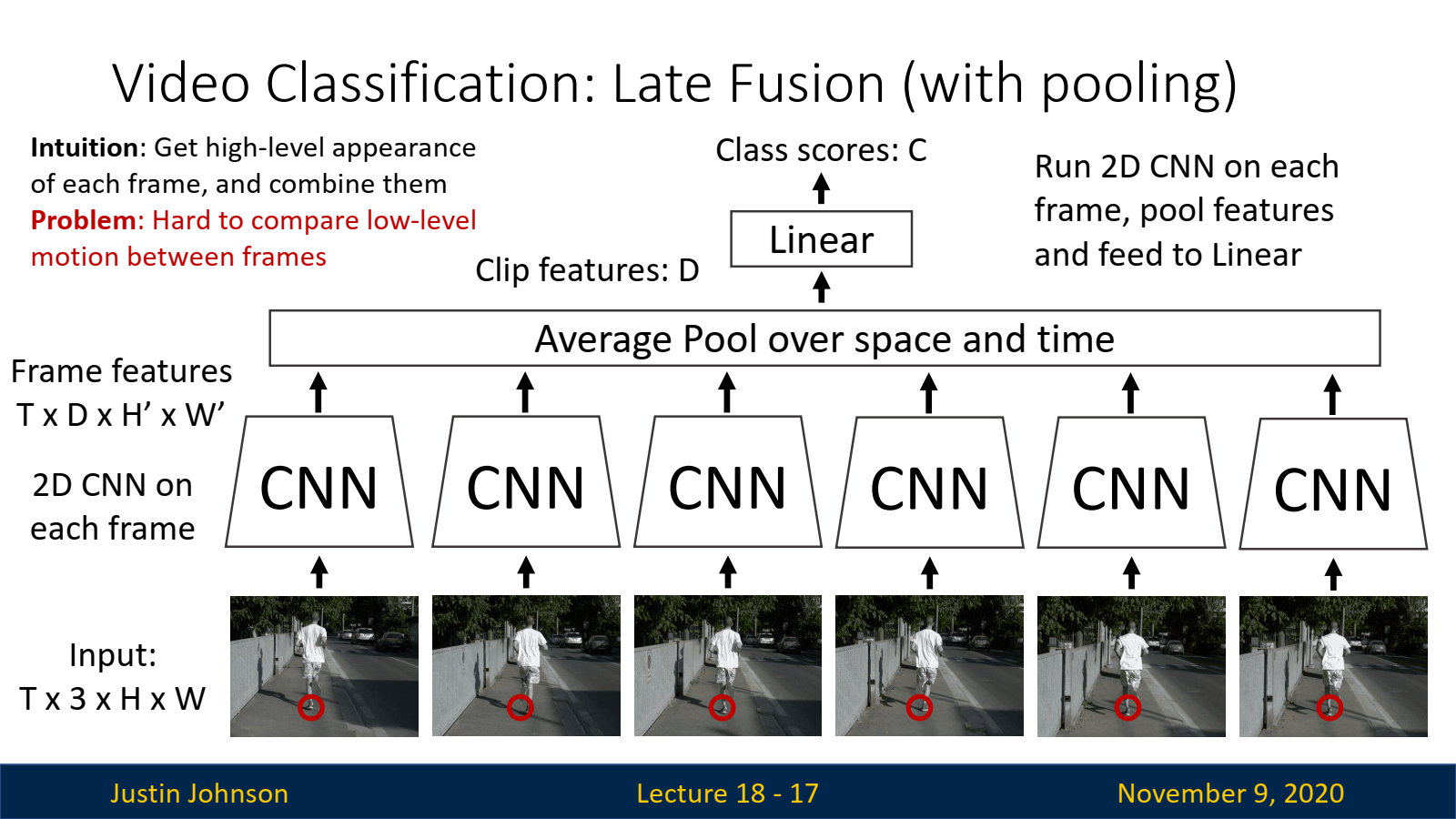
- 단일 프레임 분류기와 유사하나, 각 프레임의 결과를 네트워크 내부에서 결합하여 분류를 수행합니다. 즉, CNN을 통해 각 프레임을 독립적으로 처리한 후, 나중에 시간 정보를 결합하는 방식입니다.
- 이 접근법은 시간 축 정보를 네트워크 내에서 처리하도록 하여, 보다 정교한 시간적 패턴을 학습할 수 있습니다.
-
초기 융합(Early Fusion):

- 입력 비디오의 시간 축을 채널 축으로 재해석하고, 첫 번째 CNN 레이어에서 시간 정보를 결합합니다.
Reshape 수행: (T x 3 x H x W) ▶ (3T x H x W)
- 이렇게 함으로써 CNN의 초기 레이어에서 시간 축을 처리할 수 있으며, 낮은 수준의 시간적 상호작용을 학습할 수 있습니다.
- 하지만 시간 정보를 한 번에 결합하는 방식이라 정보 손실이 발생할 수 있습니다.
- 입력 비디오의 시간 축을 채널 축으로 재해석하고, 첫 번째 CNN 레이어에서 시간 정보를 결합합니다.
-
3D CNN (Slow Fusion):

-
3D CNN을 사용해 공간 및 시간 정보를 여러 층에 걸쳐 점진적으로 융합합니다.
-
CNN의 각 층에서 3D 컨볼루션과 3D 풀링을 사용하여 공간적, 시간적 정보를 동시에 처리합니다. 이 접근법은 느리지만 지속적으로 시간 정보를 결합해 성능이 뛰어나며, 특히 움직임이 중요한 비디오에서 효과적입니다.
-
- Summary:
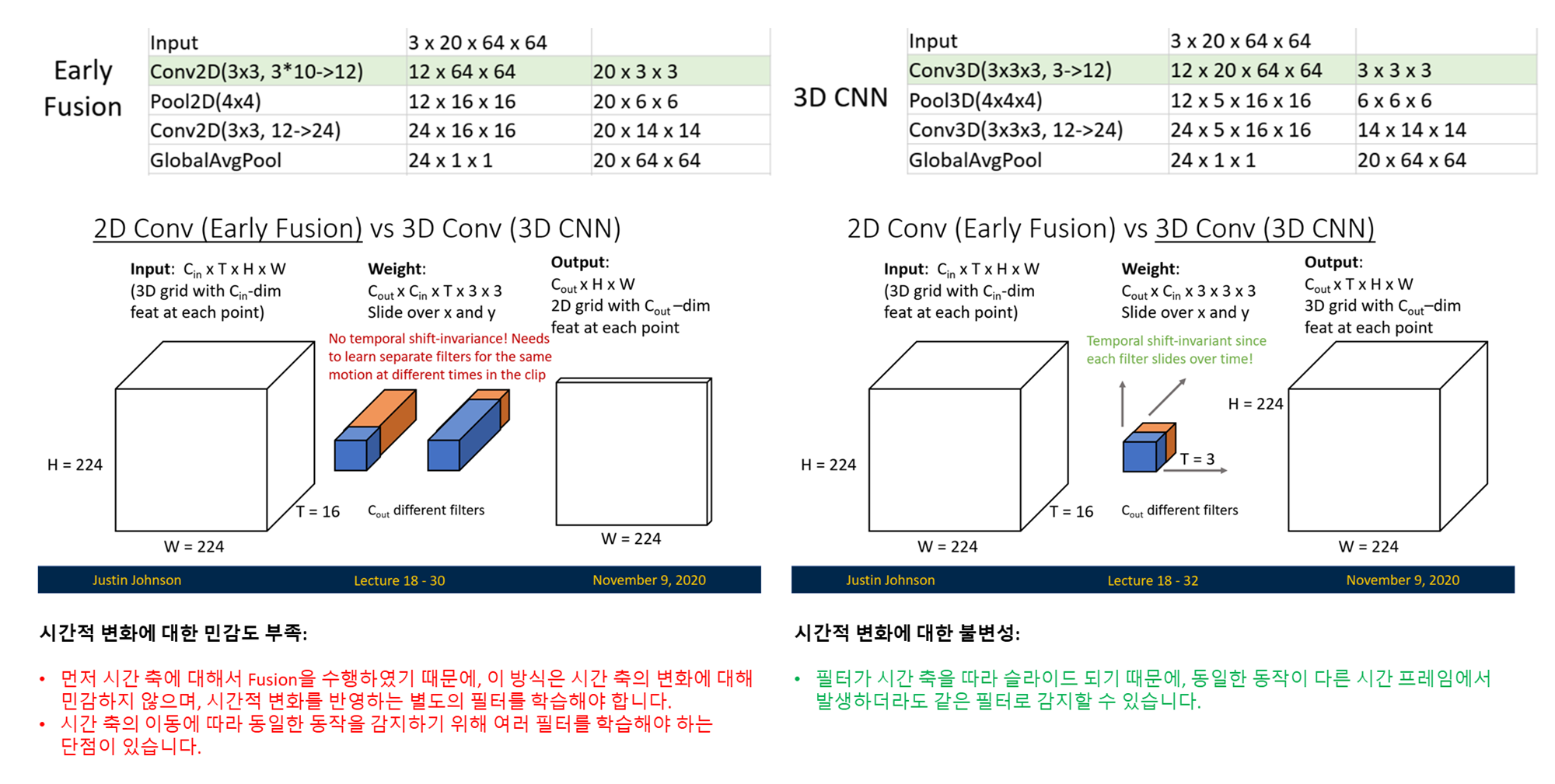
해당 테이블은 Late Fusion, Early Fusion, 3D CNN의 구조적 차이점을 비교한 것입니다. 이 테이블은 각 레이어의 입력 크기, 수용 영역(Receptive Field), 그리고 모델이 시간과 공간 정보를 결합하는 방식을 시각적으로 보여줍니다.

-
Late Fusion
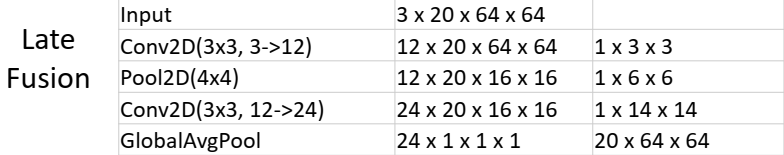
- 구조:
- 입력 데이터는
3 x 20 x 64 x 64텐서입니다. 여기서 3은 채널 수(RGB), 20은 프레임 수(Time), 64 x 64는 공간적 해상도(Image Size)입니다. - 첫 번째 레이어는 2D Conv (3x3 필터, 출력 채널 12개)로, 각 프레임을 독립적으로 처리합니다. 이 레이어는 시간 정보를 고려하지 않고, 공간적 특징만 추출합니다.
- 이후 풀링(Pooling)을 통해 공간 정보를 축소한 뒤, 또 다른 2D Conv 레이어를 통해 공간적 수용 영역을 확장합니다.
- 마지막으로 Global Average Pooling 레이어를 통해 모든 공간 및 시간 정보를 결합하여 출력합니다. (
Late Fusion)
- 입력 데이터는
- 특징:
- 시간 정보 결합: 전체 네트워크에서 시간 정보는
마지막 Global Average Pooling에서 한 번에 결합됩니다. - 공간 정보 결합: 여러 레이어에 걸쳐 천천히 공간 정보를 결합합니다.
- 시간 정보 결합: 전체 네트워크에서 시간 정보는
- 구조:
-
Early Fusion

- 구조:
- 입력 데이터는
3 x 20 x 64 x 64텐서입니다. - 첫 번째 2D Conv 레이어에서 시간 축(T)을 채널 축(C)에 합친 후(예: 3 채널이 아닌 3x20=60 채널), 이를 처리합니다. 즉,
처음부터 시간 정보를 결합합니다. (Early Fusion) - 이후 풀링(Pooling)과 2D Conv 레이어를 통해 공간 정보를 처리하고, Global Average Pooling에서 최종 출력을 만듭니다.
- 입력 데이터는
- 특징:
- 시간 정보 결합: 첫 번째 레이어에서 시간 정보를 모두 결합합니다.
- 공간 정보 결합: 시간 정보를 결합한 후 여러 레이어를 거쳐 천천히 공간 정보를 결합합니다.
- 단점: 시간 정보를 초기 단계에서 결합하므로, 초기의 정보 손실 가능성이 존재합니다.
- 구조:
-
3D CNN (Slow Fusion)

- 구조:
- 입력 데이터는
3 x 20 x 64 x 64텐서로 시작합니다. - 첫 번째 레이어는 3D Conv (3x3x3 필터, 출력 채널 12개)를 사용하여, 시간 및 공간 정보를 동시에 처리합니다.
- 이후의 풀링과 3D Conv 레이어도 동일하게 3차원 공간(2D 공간 + 시간 축)을 처리하며, 천천히 시간 및 공간 정보를 결합합니다.
- 입력 데이터는
- 특징:
- 시간 및 공간 정보 결합: 네트워크 전체에서 시간과 공간 정보를 천천히 결합합니다. 이 방식을 "Slow Fusion"이라고 합니다.
- 장점: 공간과 시간 정보를 동시에 결합하여 보다 정확한 특징을 추출할 수 있습니다. 특히 복잡한 시간적 패턴을 다룰 때 유리합니다.
- 구조:
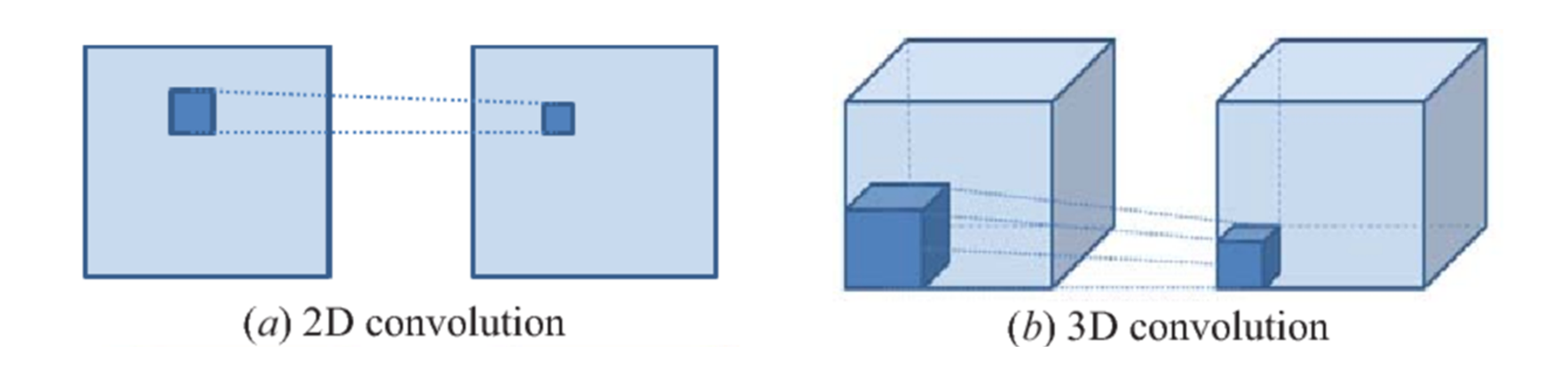
✅ Early Fusion vs 3D CNN
1. Conv2D(3x3, 3*20->12):
- 여기서
3x3은 필터의 크기이며,3*20은 결합된 입력 채널의 수(3 RGB 채널 x 10 프레임 = 30),->12에서 12는 출력 채널(필터)의 수입니다.- 출력 채널이 12개라는 것은, 이 컨볼루션 레이어가 12개의 서로 다른 필터를 학습하고, 각각의 필터가
3x3크기의 입력 데이터에 적용된다는 의미입니다.- 모든 프레임을 결합하여 한 번에 처리하므로, 시간 축의 정보를 단일 레이어에서 완전히 결합해 버립니다.
2. Conv3D(3x3x3, 3 -> 12):- 이 경우,
3x3x3필터가 3D 공간(시간 포함)을 통해 이동하면서 입력 데이터를 처리합니다.- 입력 채널이 3개이므로, 이 레이어에는 12개의 필터가 각 3개의 입력 채널에 적용됩니다. 여기서도 출력 채널의 수는 12로, 이는 설계자가 지정한 값입니다.
- 필터가 시간 축을 따라 슬라이드하면서 시간적 특성을 고려하여 정보를 처리합니다.
4. 추가적 접근법
- 예제 비디오 데이터셋: Sports-1M:

- Google에서 제작한 Sports-1M 데이터셋은 1백만 개의 YouTube 스포츠 비디오로 구성된 데이터셋으로, 다양한 스포츠 카테고리로 레이블링되어 있습니다.
- 이 데이터셋은 비디오 분류 작업의 도전을 잘 보여줍니다. 특히, 단일 프레임 분류기, Late Fusion, Early Fusion, 3D CNN 등의 접근법을 통해 비디오 분류의 성능을 비교할 수 있습니다.
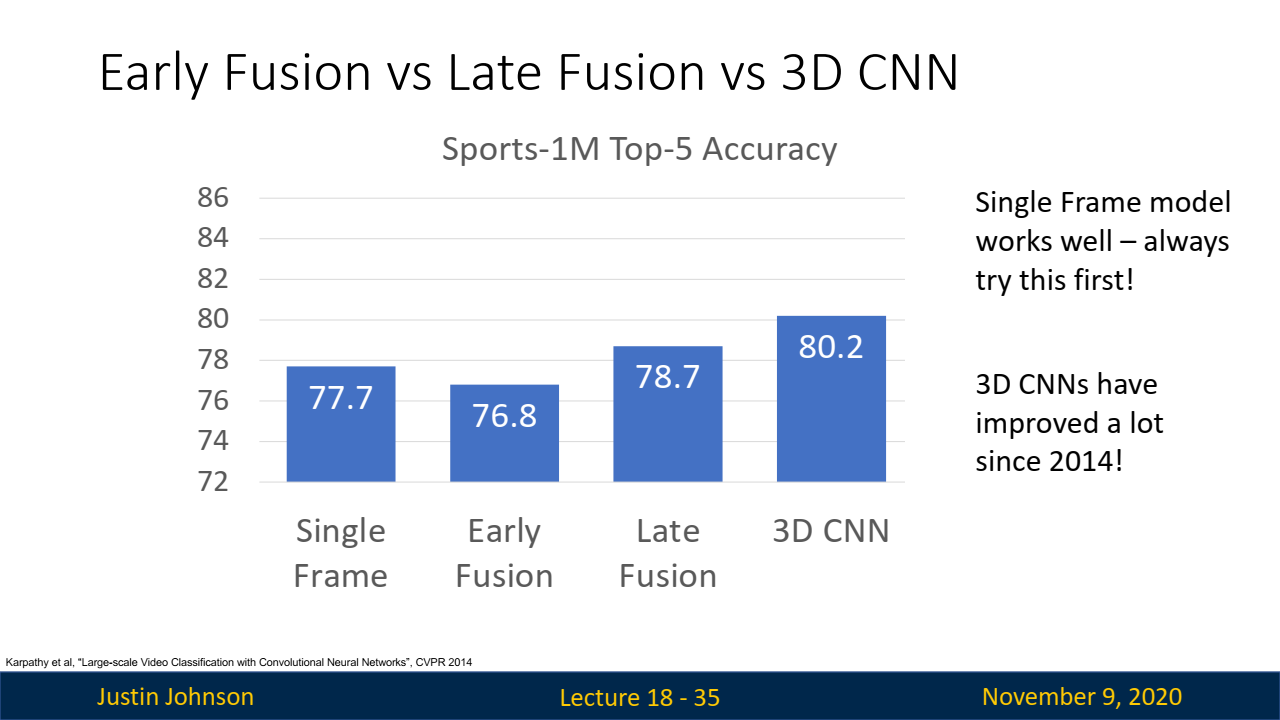
- 단일 프레임 분류기가 77% 이상의 정확도를 보여 단순한 접근법이 매우 강력함을 입증했으나, Late Fusion과 3D CNN은 조금 더 나은 성능을 보였습니다.
-
C3D: 3D CNN의 VGGNet:
-
C3D는 VGG 네트워크와 유사하게 3x3x3 컨볼루션과 2x2x2 풀링으로 구성된 단순한 3D CNN 아키텍처입니다.

-
이 모델은 Sports-1M에서 좋은 성능을 보여, 많은 비디오 인식 작업에서 사용되었습니다.
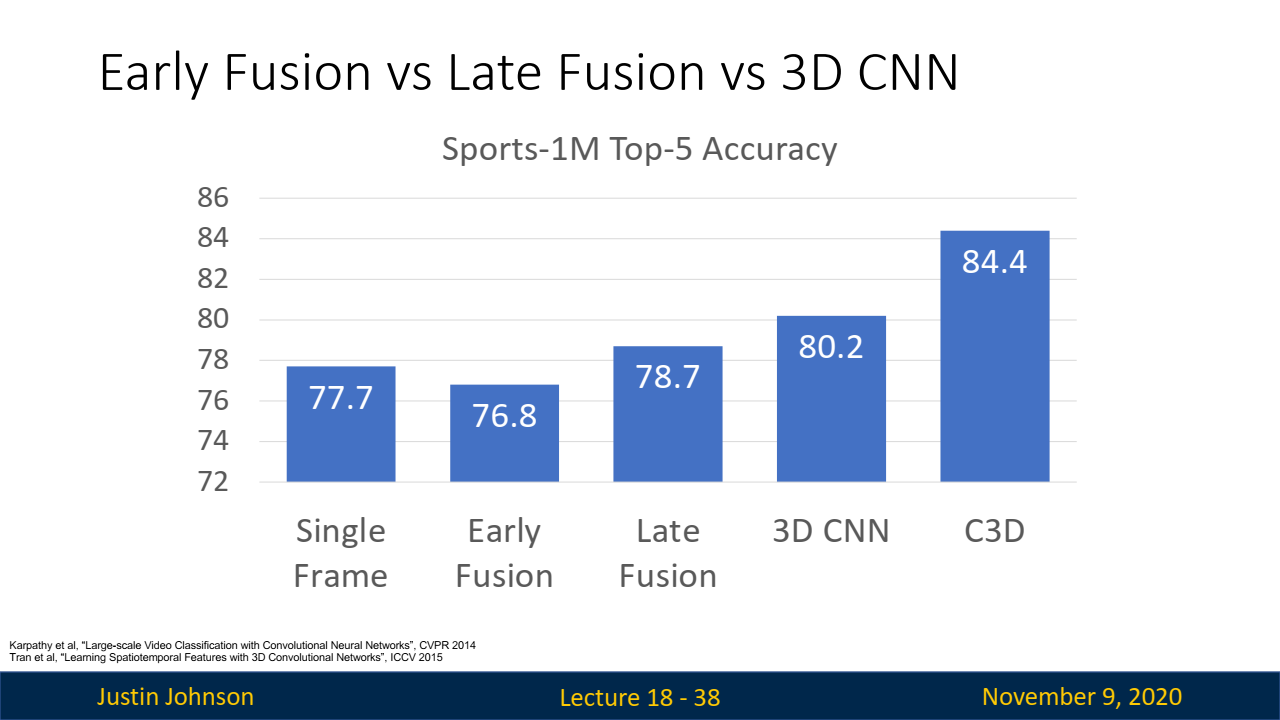
-
그러나 계산 비용이 매우 높아 실행하기 어려운 단점이 있습니다. (3x3x3 conv is very expensive!)
AlexNet: 0.7 GFLOPVGG-16: 13.6 GFLOPC3D: 39.5 GFLOP (VGG의 약 2.9배!!)
-
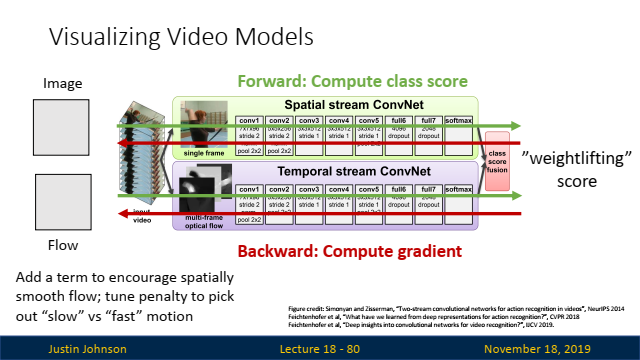
🔎 Measuring Motion을 측정할 방법이 있을까? => Optical Flow
✍️ Optical Flow는 연속된 이미지 프레임에서 각 픽셀의 움직임을 추정하는 기술로, 이미지에서의 움직임을 감지하고 그 방향과 속도를 벡터 필드로 표현하여 시각화합니다. 이 기술은 주로 비디오 처리, 동작 인식, 비디오 안정화 등 다양한 분야에서 사용됩니다.
- 기본 개념:
- Optical Flow는 특정 시간 에서의 이미지 와 다음 시간 에서의 이미지 사이에서 각 픽셀이 어떻게 이동했는지를 나타내는 벡터 필드를 계산합니다.
- Optical Flow는 각 픽셀의 이동을 나타내는 벡터 를 생성합니다.
- 이 벡터는 픽셀이 프레임 에서 로 이동할 때 얼마나 움직였는지를 보여줍니다.
- 주요 활용:
움직임 감지: 비디오에서 특정 물체가 어떻게 움직이는지 추적하는 데 사용됩니다.동작 분석: 사람의 동작을 분석하고 특정 행동을 인식할 수 있습니다.비디오 안정화: 프레임 간의 차이를 보정하여 비디오를 안정화할 수 있습니다.- 계산 과정:
프레임 선택: 연속된 두 프레임을 선택합니다.밝기 차이 계산: 픽셀의 밝기 변화가 없다는 가정하에, 프레임 간의 픽셀 위치 변화를 계산합니다. 이 과정에서 일반적으로 사용되는 수식은 다음과 같습니다:
- 수식:
벡터 필드 생성: 계산된 이동 벡터를 기반으로 전체 프레임에 대한 움직임 벡터 필드를 만듭니다.- 시각화:
Optical Flow는 수평 이동 와 수직 이동 를 시각화할 수 있습니다. 이는 동영상에서 물체의 움직임을 파악하는 데 매우 유용합니다.

-
Separating Motion and Appearance: Two-Stream Networks:
-
Two-Stream Networks는 동작 인식과 같은 비디오 분석 작업에서 "Motion"과 "Appearance"를 분리하여 처리하는 구조입니다.
-
여기서
Optical Flow는 Temporal Stream에서 움직임 정보를 추출하는 데 핵심적인 역할을 합니다.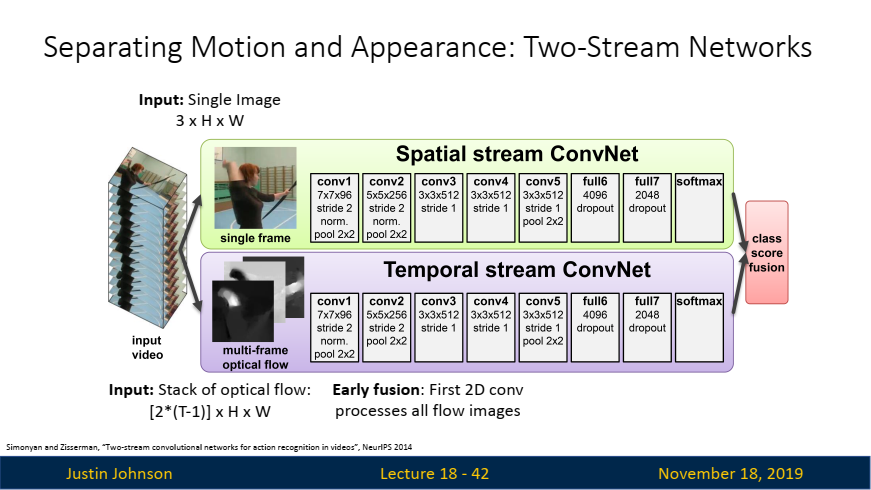
-
Two-Stream Network 구조:
두 스트림이 각각 다른 입력 데이터를 사용하므로, 각각의 CNN은 자신에게 주어진 입력 데이터의 특성에 맞는 패턴을 학습하게 됩니다. 이는 두 네트워크가 서로 보완적인 정보를 학습할 수 있게 만드는 중요한 요소입니다.Spatial Stream: 단일 프레임을 입력으로 사용하여, 정적인 외형 정보(객체의 모양, 색상, 배경 등)를 학습합니다. 이 스트림은 이미지 분류에서 사용되는 전통적인 CNN 아키텍처와 유사합니다.Temporal Stream: 연속된 프레임들 간의 Optical Flow를 입력으로 사용하여, 비디오 내의 움직임 정보를 학습합니다. Optical Flow는 특정 프레임 사이의 움직임 벡터 필드이므로, 움직임의 방향성과 속도 정보를 효과적으로 학습할 수 있습니다.
-
Two-Stream Network 계산:
- 비디오에서 여러 연속된 프레임을 가져옴.
- 연속된 두 프레임 사이에서 Optical Flow를 계산하여 움직임 벡터 필드를 생성.
- 계산된 Optical Flow를 Temporal Stream의 입력으로 사용.
- Spatial Stream과 Temporal Stream의 출력은 결합(Fusion)되어 최종 클래스를 예측.
-
🤔 Q. 왜 Optical Flow의 Input은 2(T-1)인가
Optical Flow 입력의 계산 방식
- T는 비디오에서 선택된 연속된 프레임의 수를 의미합니다.
- T-1은 Optical Flow 벡터 필드를 계산하기 위해 필요한 프레임 쌍의 수를 의미합니다. 예를 들어, T개의 프레임이 있다면, 그 중 두 프레임씩 짝을 지어 T-1개의 Optical Flow를 계산할 수 있습니다.
- Optical Flow는 일반적으로 두 개의 성분으로 구성됩니다: 수평(x) 방향 성분과 수직(y) 방향 성분. 따라서 각 프레임 쌍에서 두 개의 채널이 생성되므로, T-1개의 프레임 쌍에서 총 2*(T-1)개의 채널이 만들어집니다.
2: Optical Flow가 두 개의 채널(수평 및 수직 성분)로 구성되기 때문입니다.(T-1): 연속된 두 프레임 사이에서 Optical Flow를 계산하는데 필요한 프레임 쌍의 수입니다.
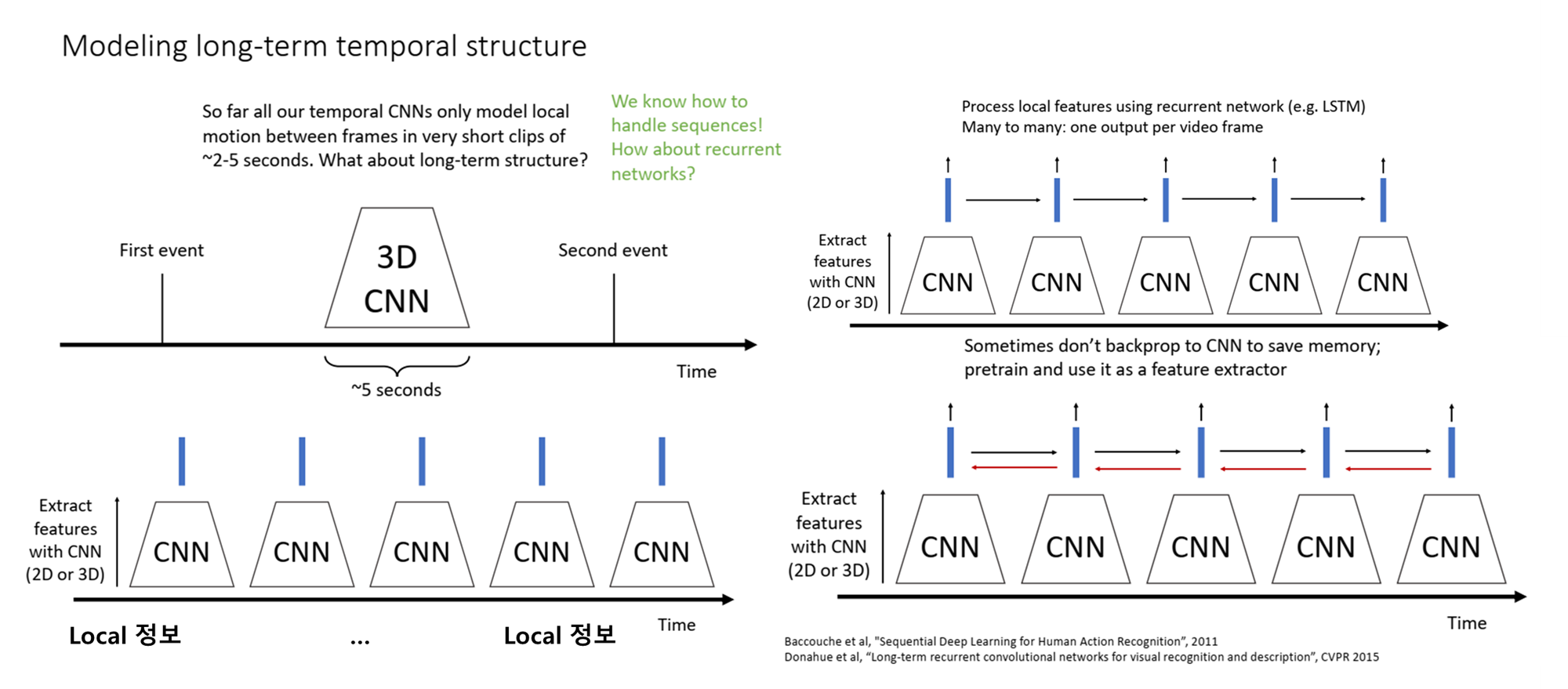
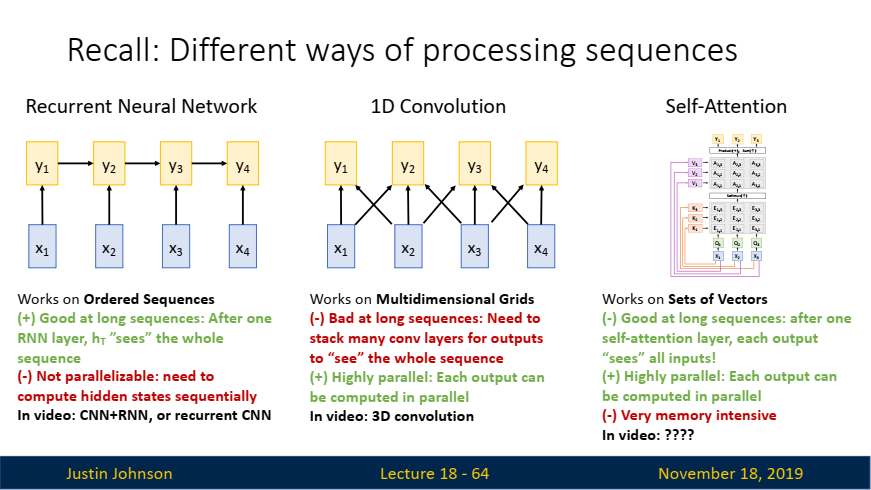
-
Recurrent Neural Network (RNN):
-
장점:
- 장기 시퀀스 처리에 강함: RNN은 이전 시간 단계의 숨겨진 상태를 기억하며, 이는 긴 시퀀스에서 유용합니다. 한 층의 RNN 레이어가 전체 시퀀스를 '볼' 수 있게 됩니다.
-
단점:
- 병렬 처리 불가능: RNN은 시퀀스의 각 시간 단계에서 숨겨진 상태를 순차적으로 계산해야 하기 때문에 병렬 처리에 적합하지 않습니다. 이는 긴 시퀀스를 처리할 때 비효율적입니다.
-
비디오 작업에서의 활용:
- CNN과 RNN을 결합하거나 Recurrent CNN을 사용해 비디오 데이터를 처리할 수 있습니다.
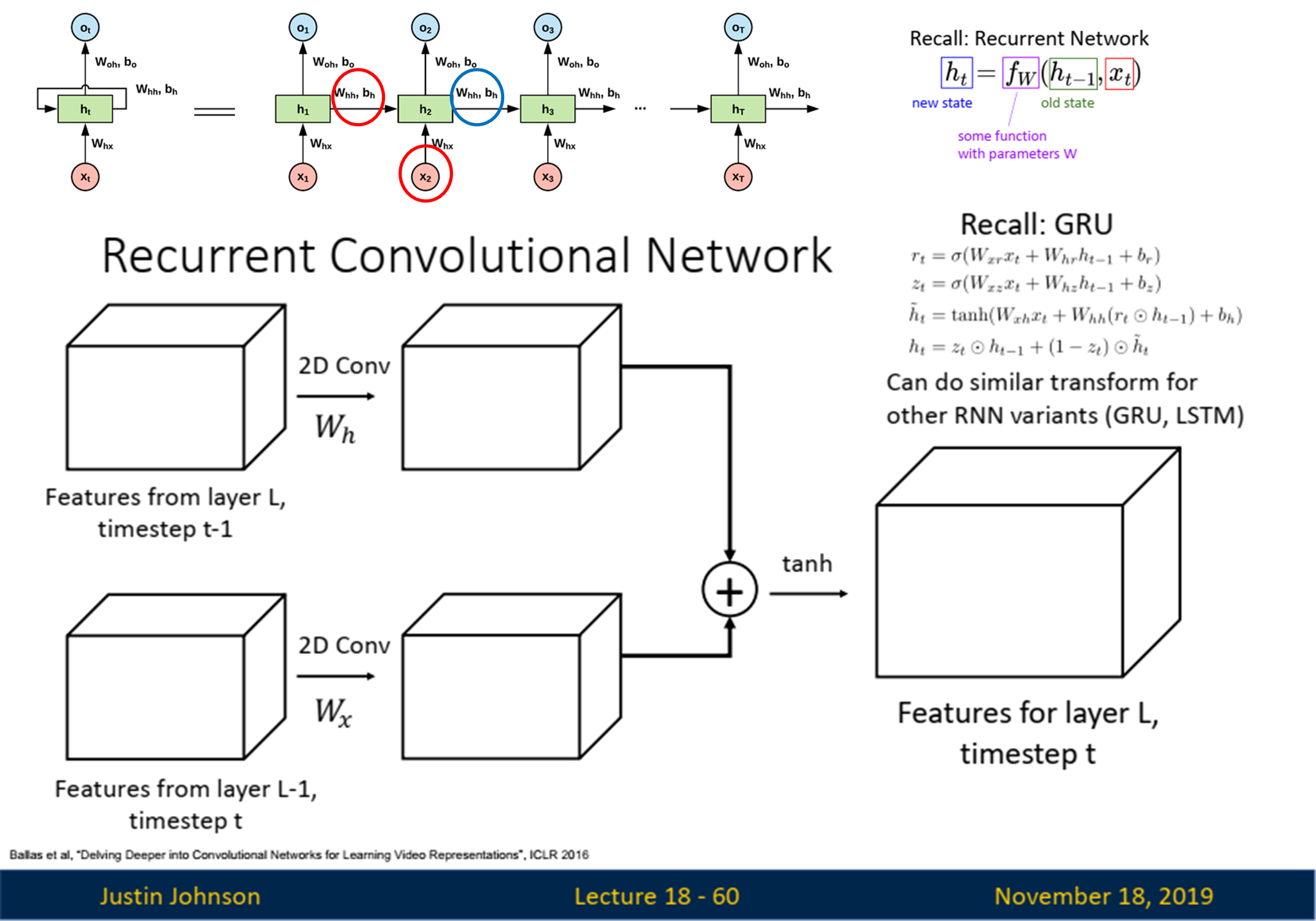
-
기존 RNN과 차이: Recurrent Convolutional Network (RCN)에서 정보가 업데이트되는 과정은 기존 RNN과 유사하지만, 중요한 차이점은 행렬 곱셈 (matmul) 대신 2D 합성곱 연산(Convolution)을 사용한다는 점입니다.

-
- 1D Convolution:
- 장점:
- 고도로 병렬화 가능: 시퀀스의 각 출력이 독립적으로 계산될 수 있어 병렬 처리가 가능합니다. 이는 모델 학습과 추론 속도에 유리합니다.
- 단점:
- 장기 시퀀스에 불리함: 긴 시퀀스를 처리하려면 많은 컨볼루션 레이어를 쌓아야 하며, 이는 복잡성을 증가시킵니다. 장기적인 시간 의존성을 처리하기 어려울 수 있습니다.
- 비디오 작업에서의 활용:
- 3D Convolution을 통해 비디오의 공간적(Spatial) 및 시간적(Temporal) 정보를 동시에 처리합니다.
- 장점:
-
Self-Attention:
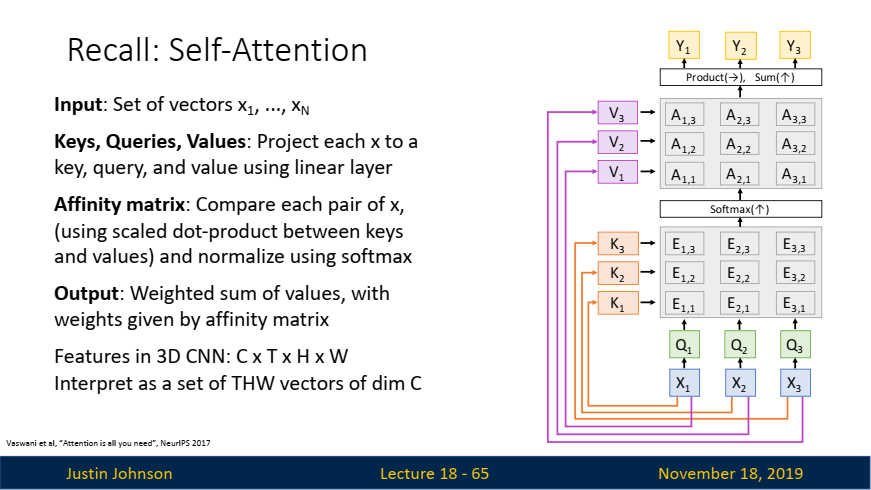
-
장점:
- 장기 시퀀스 처리에 강함: Self-Attention은 시퀀스의 모든 입력 벡터 간의 관계를 계산해, 각 출력이 한 번의 계산으로 전체 시퀀스를 '볼' 수 있게 합니다. 따라서 장기적인 시간 의존성을 잘 처리합니다.
- 고도로 병렬화 가능: 모든 출력이 병렬로 계산될 수 있어, 계산 효율이 높습니다.
-
단점:
- 메모리 소모 큼: 시퀀스의 모든 쌍을 계산하기 때문에 메모리 소모가 크고, 특히 긴 시퀀스에서는 부담이 될 수 있습니다.
-
비디오 작업에서의 활용:
- Self-Attention 기법은 비디오 분석에서
장기적인 시간 의존성과복잡한 공간적 관계를 효과적으로 모델링할 수 있습니다.
- Self-Attention 기법은 비디오 분석에서
-
5. 모델 최적화 및 최신 기술
Spatio-Temporal Self-Attention (Nonlocal Block)
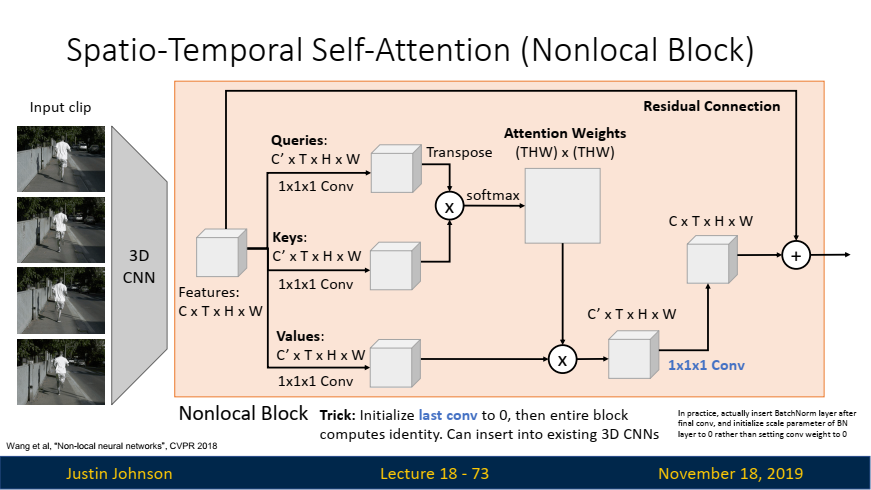
Nonlocal Block
-
Nonlocal Block:
- 3D CNN 구조 내에 추가할 수 있는 Nonlocal Block 블록을 통해, 공간적 및 시간적 차원에서 모든 위치 간의 상호작용을 모델링하여 장기적인 의존성을 효과적으로 처리합니다. 이를 통해 복잡한 비디오 데이터의 인식 성능을 크게 향상시킬 수 있습니다.
-
Nonlocal Block 구조:
Nonlocal Block: Nonlocal Block은 1x1x1 컨볼루션을 사용해 입력 텐서에서 쿼리(Query), 키(Key), 값(Value)을 생성합니다. 그런 다음 쿼리와 키 간의 점곱(Dot Product)을 통해 Attention 가중치를 계산하며, 이를 기반으로 입력 텐서를 가중합하여 최종 출력을 생성합니다.Residual Connection: Nonlocal Block은 Residual Connection을 통해 추가적인 학습 없이도 효과적으로 사용할 수 있습니다. 이는 기존 3D CNN 아키텍처에 쉽게 통합할 수 있으며, 초기 가중치를 설정할 때 마지막 1x1x1 컨볼루션 레이어의 가중치를 0으로 초기화해 블록을 처음에는 항등 함수로 작동하도록 설정할 수 있습니다. 이를 통해 기존 모델의 성능을 유지하면서 Nonlocal Block을 점진적으로 통합할 수 있습니다.
-
Nonlocal Block 역할:
-
글로벌 문맥 이해: Non-local block은 비디오 전체에서 발생하는 장기적인 시공간적 의존성을 모델링합니다.- 비디오의 어느 한 부분에서의 변화가 다른 부분에 미치는 영향을 전역적으로 학습하여, 멀리 떨어진 프레임 사이의 상호작용을 이해할 수 있습니다.
- 예를 들어, 비디오의 초반에 발생한 동작이 후반부에 어떻게 영향을 미치는지를 학습할 수 있습니다.
-
전역적인 특징 학습: Non-local block은 모든 위치 간의 관계를 계산하여 전체 비디오의 전역적인 특징을 학습합니다.- 이는 CNN이 가지는 지역적 한계를 극복하는 데 도움이 됩니다.
- 주로 특정 프레임 내 또는 여러 프레임 간의 전역적인 패턴(예: 전체적인 움직임 궤적, 장기적인 행동)을 학습합니다.
-
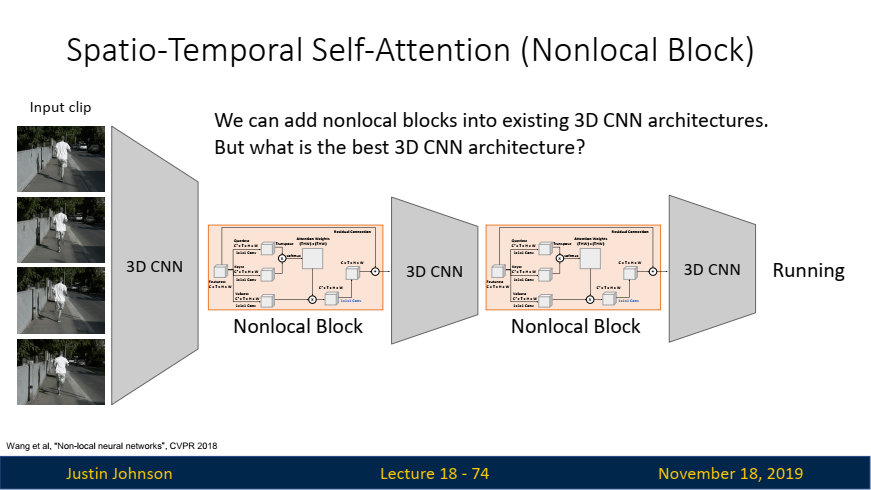
3D-CNN이 왜 있지?
위 그림에 나와있는 3D CNN은 아래와 같은 역할을 수행합니다:
로컬한 시공간 특징 추출:- 3D-CNN은 연속된 비디오 프레임에서 짧은 시간 내의 움직임 및 공간적 패턴을 학습합니다.
- 예를 들어, 손을 흔드는 동작이나 물체의 작은 이동과 같은 짧은 시간 동안 발생하는 움직임을 잘 포착할 수 있습니다.
- CNN의 필터는 지역적인 특징을 탐지하며, 이러한 지역적 특징은 합성곱과 풀링을 통해 점진적으로 더 높은 수준의 추상적 특징으로 변환됩니다.
계층적(hierarchical) 정보 처리:- 3D-CNN은 여러 계층(layer)을 통해 로우레벨(low-level)에서 하이레벨(high-level)까지 특징을 추출합니다.
- 이를 통해 이미지의 저수준 특징(예: 에지, 코너)부터 고수준의 의미적 정보(예: 객체, 장면)를 학습합니다.
이처럼 Spatio-Temporal Self-Attention (Nonlocal Block)
은 3D-CNN과 Non-local block의 조합을 통해 비디오 데이터를 계층적으로 처리합니다. 로컬 정보와 글로벌 정보를 모두 활용하여 비디오 이해의 정확성을 높히고, 이를 통해 비디오의 다양한 시공간적 패턴을 효과적으로 분석할 수 있게 됩니다.
Inflated 2D Networks, I3D (2D 네트워크의 3D 확장)

2D -> 3D 확장: I3D 모델의 핵심은 2D CNN의 공간적 필터를 시간 축으로 확장하여 3D CNN을 구성하는 것입니다. 이 확장은 단순히 필터를 복사하는 것이 아니라, 시간 축을 고려해 학습하도록 만듭니다. 이렇게 하면, 영상의 시간적 변화를 캡처할 수 있습니다.- 기존의 2D CNN에서는 커널이 Cin × Kh × Kw 크기의 필터를 사용합니다. 여기서 Cin은 입력 채널 수, Kh와 Kw는 각각 필터의 높이와 너비를 의미합니다.
- 비디오 데이터를 처리하기 위해, 이 필터를 시간 축으로 확장합니다. 즉, Kt라는 시간 축 필터 크기를 추가하여 3D 컨볼루션 필터 Cin × Kt × Kh × Kw를 만듭니다.
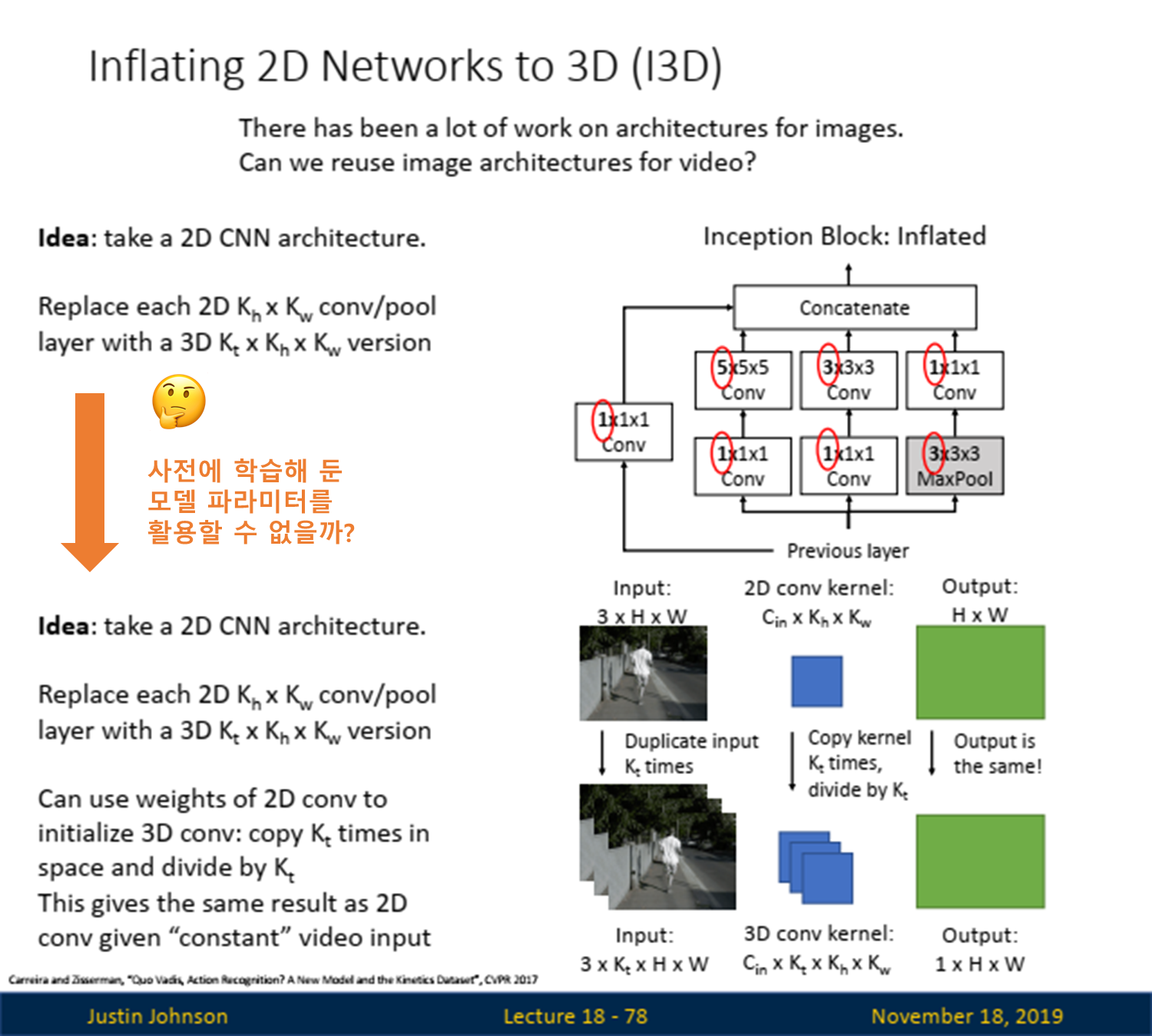
전이 학습(Transfer Learning): I3D는 ImageNet과 같은 대규모 이미지 데이터셋에서 학습된 2D CNN의 가중치를 초기화하는 데 사용됩니다. 이는 비디오 데이터셋에서 3D CNN을 처음부터 학습하는 것보다 빠르게 수렴하고, 더 높은 성능을 발휘합니다.- 가중치 복사: 2D CNN에서 학습된 가중치(필터)를 시간 축으로 복사하여 3D CNN의 가중치로 확장합니다. 예를 들어, 2D CNN의 필터가 Kh × Kw 크기라면, 이를 Kt번 복사하여 Kt × Kh × Kw 크기의 3D 필터로 변환합니다.
- 가중치 나누기: 시간 축으로 확장된 필터의 가중치를 Kt로 나눕니다. 이렇게 하면, 2D CNN에서 얻었던 동일한 출력 특성을 유지하면서도 시간 축을 반영한 3D 필터를 사용하게 됩니다.

성능 비교: 위의 성능 비교 그래프에 따르면, I3D는 전통적인 2D CNN과 비교할 때 비디오 분석에서 매우 우수한 성능을 나타냅니다. 특히, Top-1 정확도에서 큰 향상을 보입니다. 이는 I3D의 구조가 비디오에서의 시간적 특징을 잘 포착할 수 있기 때문입니다.
SlowFast Network
-
시간적 해상도: SlowFast Network의 주요 특징은 서로 다른 시간적 해상도를 사용하는 두 개의 경로(Slow pathway와 Fast pathway)를 통해 비디오를 분석한다는 것입니다.
-
Slow Pathway: 낮은 FPS (예: 30 FPS) - 비디오의 전체적인 컨텍스트와 긴 시간 프레임을 학습.
-
이 경로는 낮은 프레임 속도로 비디오의 전체적인 컨텍스트를 학습하는 데 초점을 맞춥니다.
🔎 낮은 FPS: Slow Pathway는 비디오에서 상대적으로 적은 수의 프레임을 사용하여 비디오를 처리합니다. 예를 들어, 초당 30개의 프레임만 처리한다면, 이는 비디오에서 덜 빈번한 업데이트를 의미합니다.
-
주로 비디오의 전반적인 구조와 흐름을 이해하기 위해 사용되며, 높은 채널 깊이를 사용하여 강력한 표현을 학습합니다.
-
일반적으로 α(프레임 속도 비율)는 8로 설정되어, Fast Pathway보다 8배 느린 속도로 비디오를 처리합니다.
-
-
Fast Pathway: 높은 FPS (예: 240 FPS) - 비디오의 세부적인 동작과 짧은 시간 내의 변화 포착.
-
이 경로는 높은 프레임 속도로 세부적인 움직임을 포착하는 데 중점을 둡니다.
🔎높은 FPS: Fast Pathway는 비디오의 세밀한 변화를 포착하기 위해 매우 높은 FPS로 비디오를 처리합니다. 예를 들어, 초당 240개의 프레임을 처리한다면, 이는 짧은 시간 간격 내의 작은 변화도 포착할 수 있음을 의미합니다.
-
세부적인 동작 패턴을 빠르게 캡처하기 위해 설계되었으며, 상대적으로 적은 채널을 사용하여 가볍게 구성됩니다.
-
채널 비율 θ는 1/8로 설정되어, Slow Pathway에 비해 적은 채널로 동작합니다.
-
-
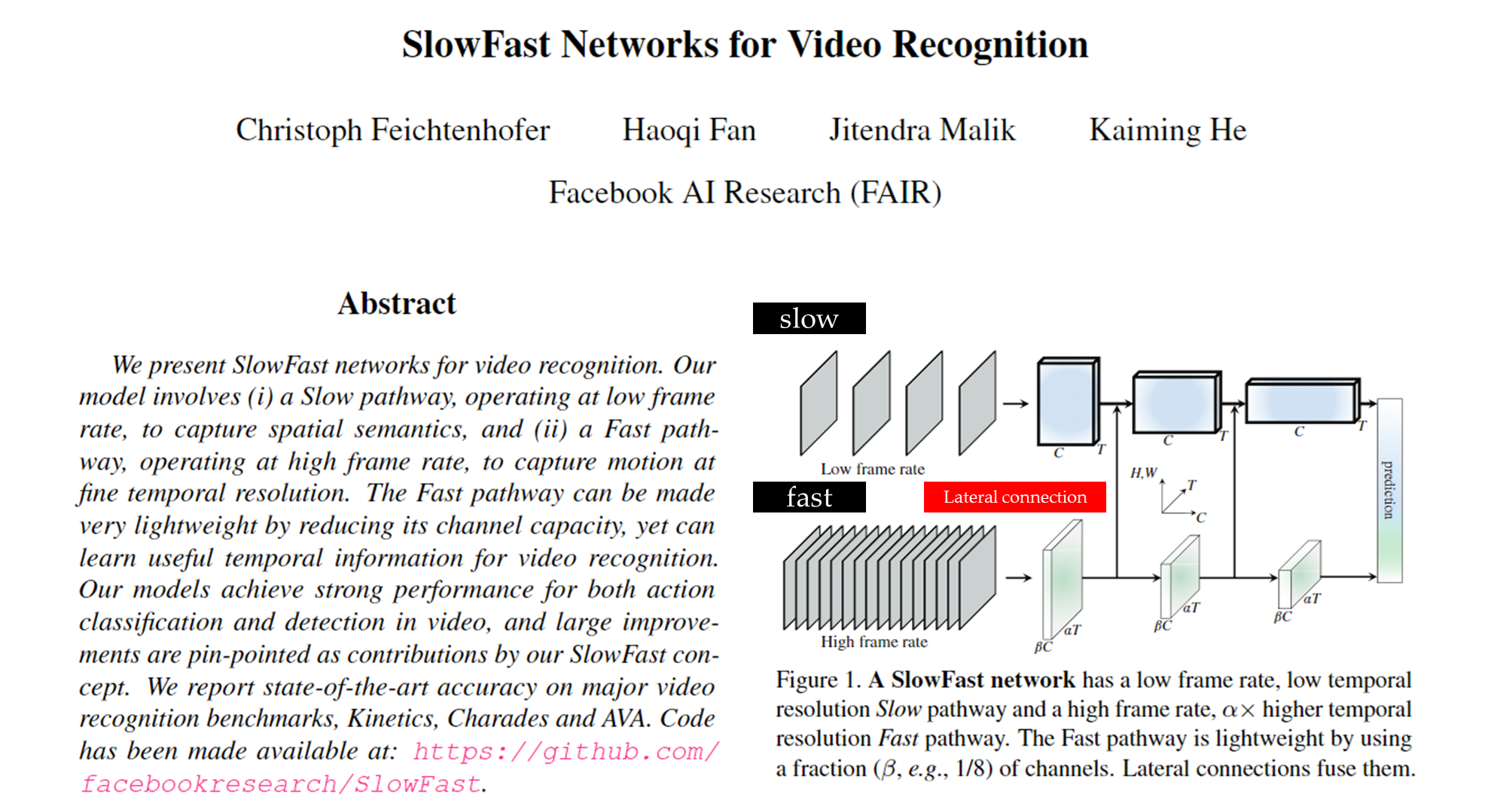
- 측면 연결(Lateral Connections): Slow pathway와 Fast pathway 간의 lateral connections은 두 경로 사이의 정보를 교환하며, 시간적 다이나믹스를 잘 통합할 수 있도록 도와줍니다. 이를 통해 복잡한 시간적 패턴을 더 잘 이해할 수 있습니다.

- 테이블 해석:
- 속도 비율(α)과 채널 비율(β):
- 속도 비율(α): Slow와 Fast 경로의 프레임레이트 차이를 나타냅니다. α = 8은 Slow Pathway가 Fast Pathway보다 8배 적은 프레임을 처리한다는 의미입니다.
- 채널 비율(β): Slow Pathway와 Fast Pathway 사이의 채널 수 비율을 나타냅니다. β = 1/8은 Fast Pathway가 Slow Pathway보다 8배 적은 채널을 사용한다는 뜻입니다
- ResNet-50 Backbone
- ResNet-50 백본을 기반으로 구축되었으며, 이를 확장해 비디오 데이터에서의 시간 및 공간 정보를 동시에 학습하도록 했습니다.
- 위 표는 각 단계에서 사용하는 스트라이드와 출력 크기, 그리고 각 경로에서의 특성 추출 방법을 보여줍니다.
- 시간적 풀링 X (No temporal pooling):
- 모든 단계에서 시간 차원 정보를 최대한 보존하며, 최종 레이어에서 글로벌 평균 풀링과 결합하여 예측을 수행합니다.
- 속도 비율(α)과 채널 비율(β):
본 강의는 비디오 데이터를 처리하고 이해하기 위한 다양한 딥러닝 모델을 비교하고, 각각의 모델이 어떤 상황에서 효과적인지에 대해 자세히 설명합니다. 딥러닝이 비디오 분석에 적용되는 방법과 그 한계를 파악하는 데 매우 유용한 자료입니다.
