다음은 아래 Lecture에 대한 요약 및 필기 내용을 정리한 것입니다. 틀린 내용이 있다면 댓글 부탁드립니다 🙌
- Course Website: https://web.eecs.umich.edu/~justincj/teaching/eecs498/
- Instructor: Justin Johnson
- Lecture 17: 3D Vision

1. 3D 비전 개요
- 2D에서 3D로의 확장:
- 이전 강의에서는 이미지에서 객체를 인식하고 위치를 찾는 다양한 작업(예: 객체 탐지, 의미론적 분할, 인스턴스 분할 등)에 대해 다뤘습니다.
- 실제 세계는 2D가 아니라 3D이므로, 신경망 모델에 3차원 공간 정보를 추가하여 3D 구조를 이해하는 것이 중요합니다.
- 이 강의에서는 2D 데이터를 처리하는 모델에 3D 공간을 포함시켜 3D 구조를 이해하는 방법을 탐구합니다.
2. 3D 문제의 두 가지 주요 과제
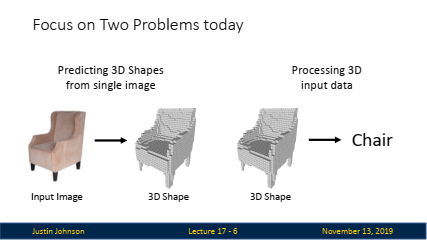
- 본격적인 설명에 앞서, 3D 문제의 두 가지 주요 과제에 대해서 가볍게 설명을 수행합니다.
-
단일 이미지에서 3D 모양 예측 (좌):
- 단일 RGB 이미지를 입력으로 받아 그 이미지 내 객체의 3D 모양을 예측하는 작업.
- 입력은 여전히 2D 이미지지만, 출력은 객체의 3D 표현이 됩니다.
-
3D 데이터를 입력으로 받는 작업 (우):
- 3D 데이터를 입력으로 받아 분류 또는 세분화 작업을 수행합니다.
- 이 작업에서는 3D 데이터를 직접 다루며, 이를 신경망 모델에서 효과적으로 활용하는 방법을 다룹니다.
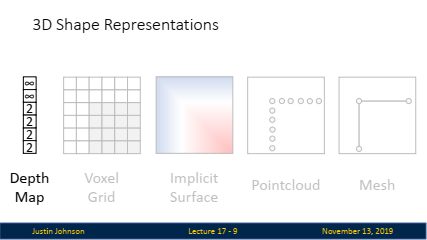
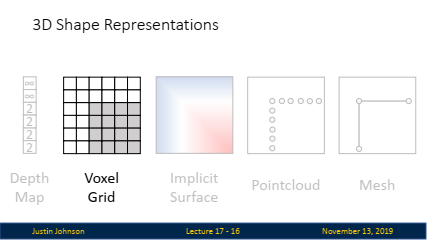
3. 5가지 3D 모양 표현 방식
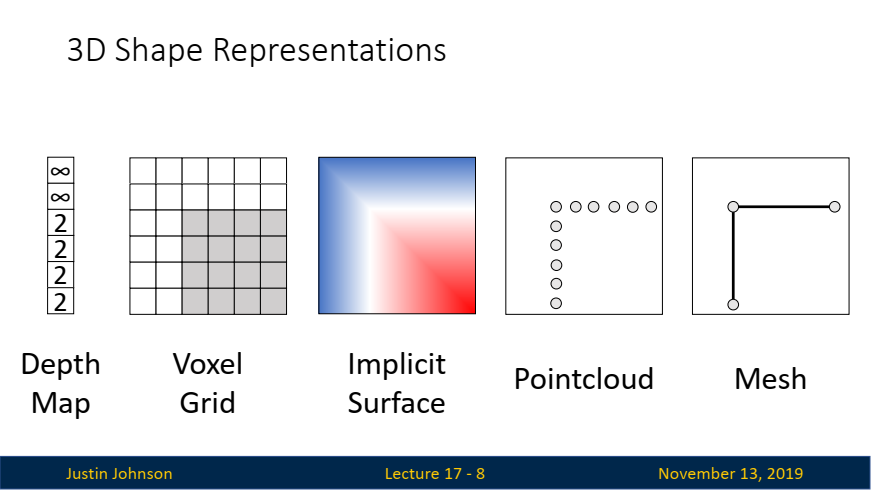
-
"
모델링"이라는 용어는 3D 모양과 3D 정보를 표현하거나 표현하는 방법을 설계하고 구성하는 과정을 의미합니다.- 구체적으로는, 컴퓨터 그래픽스나 컴퓨터 비전에서 객체의 3D 구조를 수학적 또는 데이터 기반의 방식으로 나타내는 것을 말합니다.
- 모델링하기 위해 사람들이 사용하는 다양한 유형의 표현 방식(representation)이 많이 있으며, 본 강의에서는 이러한 서로 다른 3D 모양 표현 방식 중에서 사람들이 실무에서 자주 사용하는 다섯 가지를 소개합니다.
-
깊이 맵(Depth Map):
-
개념: 깊이 맵은 각 픽셀에 대해 카메라와 해당 픽셀이 표현하는 객체 간의 거리를 할당하는 간단한 3D 표현 방식입니다.
-
표현 방식: 전통적인 RGB 이미지가 색상 값을 저장하는 2D 그리드라면, 깊이 맵은 각 픽셀에 거리 값을 할당하는 2D 그리드로, RGB 이미지에 깊이 정보를 추가한 것입니다.

-
장점: 깊이 맵은 다양한 3D 센서(예: 마이크로소프트 Kinect, iPhone의 Face ID 등)로부터 직접 캡처할 수 있는 유형의 3D 데이터입니다.
-
단점: 깊이 맵은 가려진 객체의 구조를 캡처할 수 없으므로, 일부 객체의 구조를 온전히 표현하지 못합니다. 이 때문에 완전한 3D가 아닌 '2.5D'로 불립니다.
-
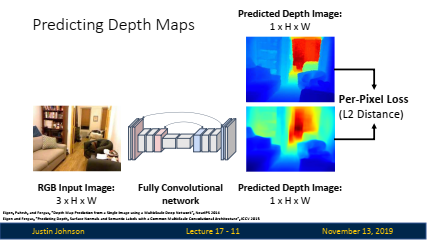
깊이 맵 예측: 신경망을 사용해 RGB 이미지로부터 깊이 맵을 예측할 수 있습니다. 이를 위해 전체적으로 합성곱 신경망(Fully Convolutional Network, FCN) 아키텍처를 사용할 수 있습니다.
-
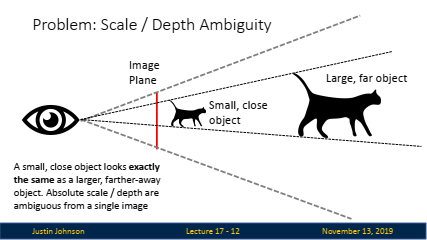
💡 Scale-depth ambiguity
- Scale-depth ambiguity는 3D 비전에서 발생하는 문제로, 단일 2D 이미지에서는 객체의 실제 크기와 거리 간의 구분이 불가능하다는 점을 의미합니다.
- 즉, 어떤 객체가 멀리 있는 큰 객체인지, 가까이 있는 작은 객체인지 단일 이미지에서만으로는 구별할 수 없다는 것입니다.
-
예를 들어, 두 배 더 큰 고양이가 두 배 더 멀리 떨어져 있다고 상상해보겠습니다(위 이미지 참고). 이 두 고양이는 서로 다른 크기와 거리에 있지만, 2D 이미지에서는 두 고양이가 동일한 크기로 보이기 때문에 이 둘을 구분하기 어렵습니다. 이러한 모호성 때문에, 3D 데이터를 예측하거나 분석할 때 신경망 모델이 객체의 절대적인 크기와 거리를 정확하게 예측하기 어렵습니다.
-
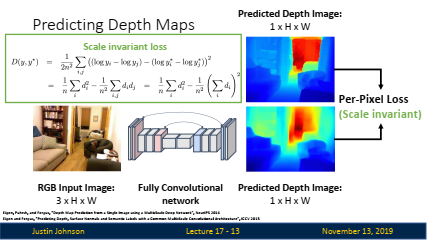
이러한 문제를 해결하기 위해, scale-invariant loss function이라는 특수한 손실 함수를 사용하여 절대적인 크기 대신, 객체의 상대적인 크기와 깊이 관계에 집중하여 모델을 학습시키는 방법이 사용됩니다. 이 방법을 통해 스케일 차이에 의한 오류를 줄이고, 모델이 보다 일관된 3D 예측을 할 수 있도록 도와줍니다.
-
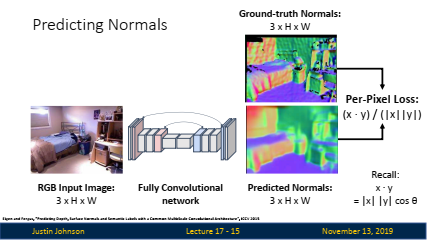
표면 법선 맵(Surface Normal Map):

- 개념: 각 픽셀에 대해 객체 표면의 방향을 나타내는 벡터를 할당하는 방식입니다.
- 표현 방식: 법선 벡터의 방향을 RGB 색상으로 표현하여, 각 픽셀에서 표면이 어느 방향을 가리키고 있는지 나타냅니다.
- 활용: 표면 법선 맵은 물체의 세부적인 표면 구조를 이해하는 데 유용하며, 표면 법선 맵과 깊이 맵을 결합하여 객체의 3D 구조를 보다 정확하게 예측할 수 있습니다.
-
복셀 그리드(Voxel Grid):
-
개념: 3D 공간을 일정한 크기의 그리드로 나누고, 각 그리드 셀이 점유되었는지 여부를 이진 값으로 나타내는 방식입니다.

-
특징: 마치 '마인크래프트'와 같은 블록 기반의 세계를 상상하면 이해하기 쉬우며, 2D의 픽셀 그리드를 3D로 확장한 개념입니다.
-
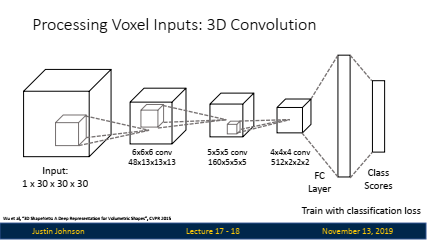
복셀 예측: 복셀 그리드에서 객체를 분류하거나 인식하기 위해 3D 합성곱 신경망(3D Convolutional Neural Network)을 사용할 수 있습니다.
-
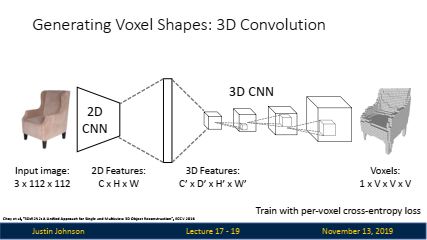
2D 입력 이미지: 입력으로 3채널 RGB 이미지(크기: 3xHxW)가 사용됩니다.
-
2D CNN: 2D 합성곱 신경망(CNN)이 이미지를 처리하여 특징 맵을 생성합니다. 이때, 생성된 2D 특징 맵의 크기는 CxHxW입니다.
-
3D CNN: 2D CNN에서 나온 특징 맵을 기반으로, 3D CNN이 사용되어 3D 특징 맵(C'xDxHxW)을 생성합니다.
-
복셀 그리드 생성: 마지막으로, 3D CNN을 사용해 4D 텐서(크기: 1xVxVxV)로 변환하여, 복셀의 점유 확률(occupancy probability)을 예측합니다.
-
학습: 각 복셀의 예측된 점유 확률을 그라운드 트루스와 비교하는 per-voxel cross-entropy loss를 사용해 학습합니다.
👉 위 방식은 3D CNN을 사용하여 3D 공간 전체에서 특징을 추출하고 복셀 점유 확률을 계산합니다. 그러나 3D CNN은 2D CNN에 비해 다음과 같은 이유로 계산 비용이 많이 듭니다:
- 큐브적 증가: 3D CNN의 계산 복잡도는 2D CNN보다 훨씬 큽니다. 이는 3D 합성곱 필터가 3D 공간 내에서 슬라이딩하며 적용되기 때문에, 계산 비용이 큐브적으로 증가합니다.
- 메모리 사용: 3D CNN은 3D 특징 맵을 사용하기 때문에, 메모리 사용량도 매우 큽니다. 특히 고해상도의 복셀 그리드를 생성하려면, 많은 메모리가 필요합니다.
👉 두 번째 방법인 Voxel Tubes 방식은 이러한 계산 비용을 줄이기 위해 고안되었습니다:
- 효율성: 3D CNN 대신 2D CNN만을 사용하여 복셀 그리드를 예측합니다. 이는 2D CNN이 더 적은 계산 비용과 메모리를 필요로 하기 때문에, 훨씬 더 효율적입니다.
- 간단한 해석: 마지막 계층에서 복셀 그리드를 예측하는 방식이 직관적이며, Z축 방향으로 복셀의 점유 확률을 계산하는 '튜브'로 해석할 수 있습니다.
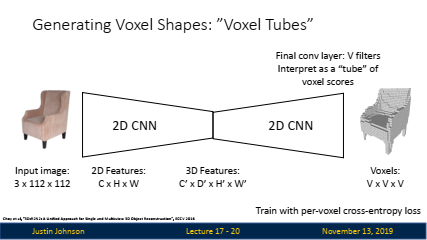
- 2D CNN: 이전과 동일하게, 2D CNN이 이미지를 처리하여 특징 맵을 생성합니다.
- 3D 특징 추출: 3D CNN을 사용하지 않고, 2D CNN의 마지막 합성곱 계층에서 '튜브' 형태의 복셀 점유 확률을 예측합니다. 여기서 '튜브'는 각 채널이 복셀 그리드의 한 축(Z축)을 따라 예측된 점유 확률을 나타내는 방식입니다.
- 튜브의 해석: 마지막 계층의 출력은 VxVxV 크기의 복셀 그리드로 해석되며, 각 채널은 3D 공간에서 Z축 방향의 복셀 점유 확률을 나타냅니다.
- 학습: 마찬가지로 per-voxel cross-entropy loss를 사용해 학습합니다.
-
-
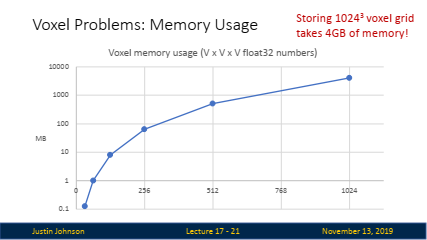
단점: 높은 해상도로 복셀 그리드를 표현하려면 많은 메모리가 필요합니다. 예를 들어, 1024×1024×1024 해상도의 복셀 그리드를 저장하는 데만 약 4GB의 메모리가 필요합니다.
-
효율성 문제 해결: 복셀의 메모리 사용량을 줄이기 위해 다중 해상도 복셀 그리드(Multi-resolution Voxel Grid)나 옥트리(Octree) 등의 기법을 사용할 수 있습니다.
-
-
암시적 표면(Implicit Surface):
-
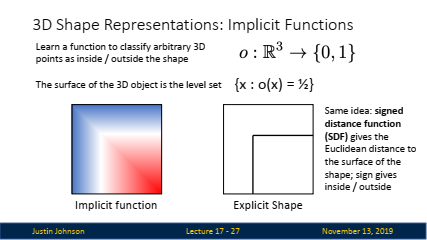
개념: 3D 모양을 함수로 표현하여, 임의의 3D 좌표가 객체의 내부인지 외부인지를 확률로 나타내는 방식입니다.
-
표현 방식: 주어진 3D 공간의 좌표를 입력으로 받아, 그 좌표가 객체의 표면인지 여부를 결정하는 함수입니다. 이 함수는 신경망으로 학습될 수 있습니다.
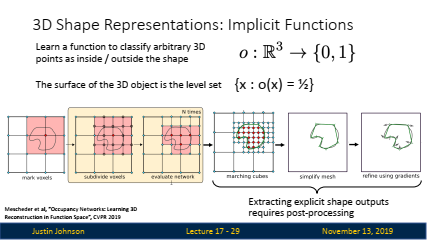
암시적 함수는 3D 공간에서 임의의 점이 특정 객체의 내부에 있는지 또는 외부에 있는지를 결정하는 함수입니다.
✔️ 이 함수는 3D 공간 내의 좌표 (x, y, z)를 입력받아, 해당 좌표가 객체의 내부에 있으면 1, 외부에 있으면 0을 반환합니다.
✔️ 결과적으로, 3D 객체의 표면은 o(x) = 1/2인 점들의 집합으로 정의됩니다. -
활용: 암시적 표면 표현은 복셀과 달리 특정 점에서만 표면을 정의하지 않고, 3D 공간 전체에서 표면을 정의할 수 있는 장점이 있습니다.
-
-
포인트 클라우드(Point Cloud):
-
개념: 3D 모양을 표현하는 대표적인 방법 중 하나로, 객체의 표면을 3D 공간의 수많은 점으로 표현합니다. 각 점은 3D 좌표계에서 (x, y, z) 위치 정보를 가지고 있으며, 이러한 점들의 집합이 객체의 전체 모양을 형성합니다.

-
특징: 포인트 클라우드는 복셀 그리드보다 더 적응적인 방법으로, 객체의 세부 사항을 표현하기 위해 점의 밀도를 조절할 수 있습니다.
-
장점:
- 세부 구조 표현: 많은 점들을 사용하여 객체의 세밀한 부분(예: 비행기 날개의 끝부분)을 정확하게 표현할 수 있습니다.
- 적응성: 점의 Loss Function 밀도를 상황에 맞게 조절할 수 있습니다. 예를 들어, 세부 사항이 필요한 부분에는 점을 더 배치하고, 세부 사항이 덜 중요한 부분에는 점을 덜 배치할 수 있습니다.
-
단점:
- 명시적 표면 표현 부족: Point Cloud는 점들의 집합으로만 표현되기 때문에, 객체의 명시적 표면을 직접적으로 나타내지 않습니다. 따라서, 렌더링이나 다른 응용 프로그램에서 사용하려면 추가적인 후처리가 필요합니다. 예를 들어, 점들로부터 삼각형 메쉬를 추출해야 합니다.
- 새로운 아키텍처와 손실 함수 필요: Point Cloud를 효과적으로 처리하기 위해서는, 새로운 신경망 아키텍처와 손실 함수가 필요합니다.
💡 PointNet
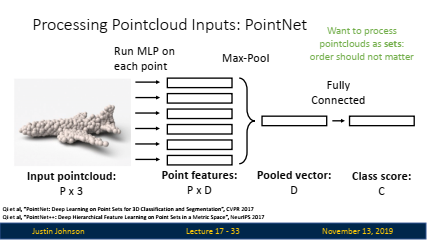
PointNet은 Point Cloud 데이터를 효과적으로 처리하기 위한 신경망 아키텍처로, 다양한 응용 분야에서 Point Cloud 데이터를 분석하고 활용할 수 있는 중요한 도구입니다.💡 Loss Function
=> Chamfer Distance는 두 개의 Point Cloud 집합 간의 유사성을 비교하는 데 사용되는 손실 함수입니다.- Point Cloud는 3D 공간 내에서 객체의 표면을 표현하는 점들의 집합이기 때문에, 두 Point Cloud를 비교하기 위해서는 두 집합 내 각 점들이 얼마나 가까운지를 측정하는 방식이 필요합니다.
- Chamfer Distance는 이러한 비교를 수행하는 대표적인 방법입니다. 슬라이드에서 보이는 수식을 아래와 같이 설명할 수 있습니다:

▶️ (첫번째항) 집합 𝑆1의 각 점 𝑥에 대해, 𝑆2에서 가장 가까운 점 𝑦까지의 L2 거리(유클리드 거리)를 계산합니다. 이 최소 거리를 모든 𝑆1의 점들에 대해 합산합니다.
▶️ (두번째항) 집합 𝑆2의 각 점 𝑦에 대해, 𝑆1에서 가장 가까운 점 x까지의 L2 거리를 계산하고, 이를 합산합니다.
-
- 활용 예: 자율 주행 차량의 LiDAR 센서가 포인트 클라우드 데이터를 생성하여, 이를 바탕으로 주행 환경을 인식합니다.
-
메쉬(Mesh) 표현
-
개념: 메쉬는 3D 공간에서
정점(Vertices),모서리(Edges), 그리고면(Faces)의 집합으로 객체를 표현하는 방식입니다.정점(Vertices): 폴리곤의 모서리를 정의하는 공간의 점입니다.모서리(Edges): 꼭지점을 연결하는 선입니다.면(Faces): 모서리로 둘러싸인 평평한 표면입니다. 대부분의 모델에서 면은 삼각형 또는 사각형입니다.- 메쉬는 삼각형 메쉬(Triangle Mesh)가 많이 사용되며, 이 방식은 객체의 표면을 명확하게 정의하고 시각적으로 표현할 수 있는 장점이 있습니다.
-

- 특징: 그래픽스에서 널리 사용되며, 표면을 명시적으로 표현하기 때문에 텍스처나 색상 등의 정보를 쉽게 부여할 수 있습니다.
- 장점:
- 정확한 표면 표현: 메쉬는 객체의 표면을 명시적으로 표현하기 때문에, 그래픽스나 렌더링에 매우 유용합니다.
- 텍스처 매핑: 메쉬 구조를 통해 표면에 텍스처나 색상, 다른 데이터를 쉽게 부여하고 이를 시각적으로 표현할 수 있습니다.
- 단점:
- 복잡성: 메쉬를 신경망으로 처리하는 것은 복잡한 작업입니다. 특히, 메쉬는 그래프 구조로 표현되므로, 기존의 합성곱 신경망(CNN)으로 처리하기 어렵습니다.
- TASK: Predicting Meshes (Pixel2Mesh)
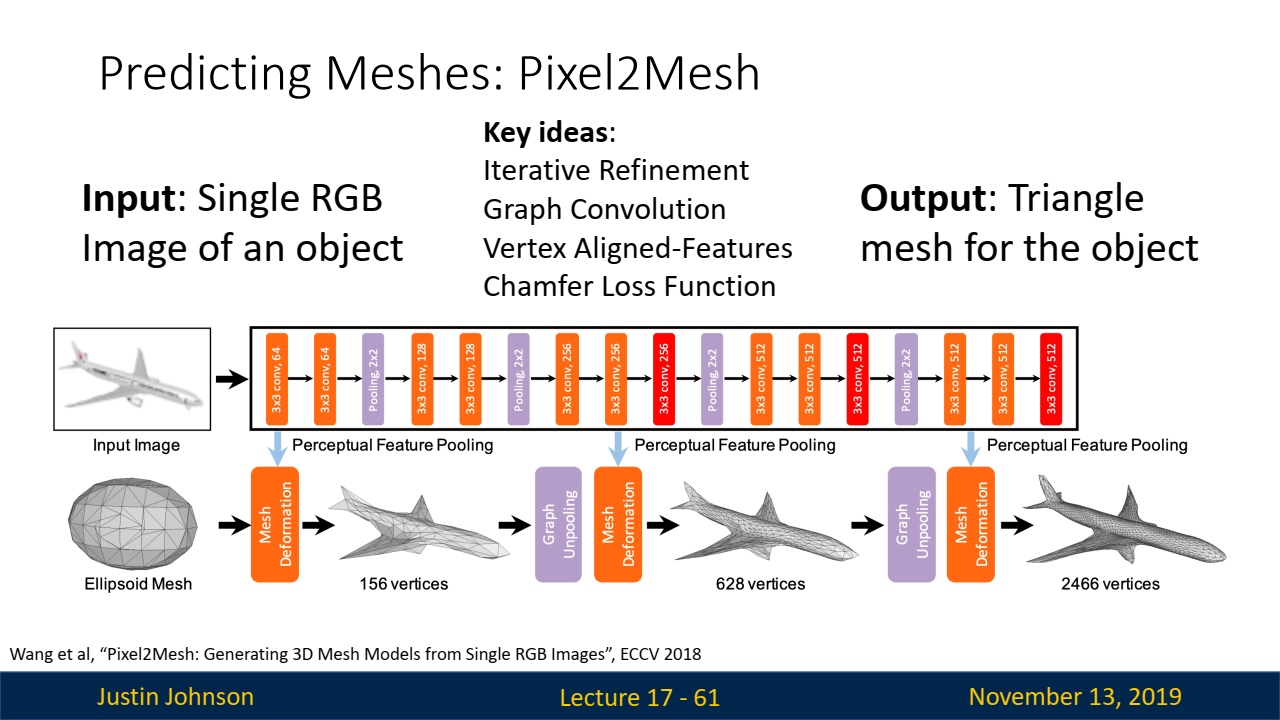
- Pixel2Mesh의 아키텍쳐는 크게
Mesh Deformation Block과Graph Unpooling Layer영역으로 구분되어 있습니다:- Mesh Deformation Block은 원하는 3D-shape으로 피쳐를 학습하는 단계
- Graph Unpooling Layer은 좀 더 높은 resolution의 3D 결과를 학습할 수 있도록 정교화하는 단계
- 아래는 이에 대해서 논문에서 찾아서 정리한 내용입니다.

- Pixel2Mesh의 아키텍쳐는 크게
4. 3D 모양 평가 방식

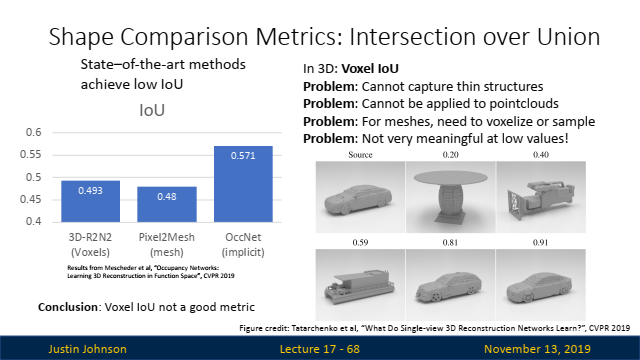
- Intersection over Union (IoU):
- 설명: IoU는 겹치는 부분을 측정하는 지표로, 두 3D 형태 사이의 겹치는 부피를 두 형태의 결합된 부피로 나눈 값입니다.
- 장단점: 미세한 구조를 잘 포착하지 못하며, 값이 낮을 때는 의미 있는 결과를 제공하지 못합니다.
-
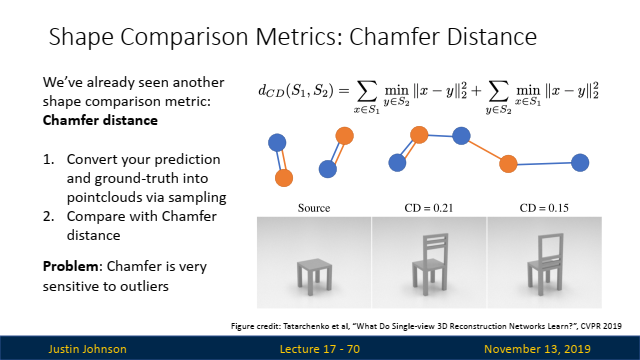
Chamfer Distance (CD):
- 설명: Chamfer Distance는 두 3D 점 구름 간의 평균 최소 거리로 측정됩니다. 한 형태의 각 점이 다른 형태에서 가장 가까운 점까지의 거리를 계산하여 평균을 구합니다.
- 장단점: 이상치에 매우 민감하며, 직접적으로 최적화할 수 있는 지표입니다.
-
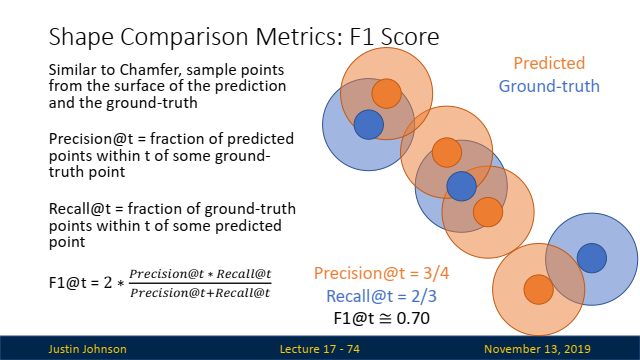
F1 Score:
- 설명: Precision과 Recall을 결합한 F1 Score는 임계값을 조정함으로써 다양한 스케일에서의 디테일을 포착할 수 있습니다.
- 장단점: 이상치에 대해 강건하지만, 다양한 스케일에서 디테일을 포착하기 위해서는 다른 임계값을 설정해 주어야 합니다.

뒤에 나오는 개념들을 이해하기 위해서는 3D Vision에 대한 이해를 해야하기 때문에 다음과 같이 "3D Vision" 강의를 듣고, 정리해보았습니다.
-
이 강의는 2D 이미지에서 3D 구조를 이해하고 표현하는 다양한 방법과 그 한계, 그리고 이를 극복하기 위한 여러 가지 혁신적인 기술을 탐구합니다.
-
각각의 표현 방식은 특정 작업에 따라 장단점이 있으며, 복잡한 3D 데이터의 처리와 예측을 위한 다양한 접근법을 제공합니다.
읽어주셔서 감사합니다 🤗
