[Paper Review] A COMPREHENSIVE REVIEW OF YOLO ARCHITECTURES IN COMPUTER VISION: FROM YOLOV1 TO YOLOV8 AND YOLO-NAS
YOLO 모델 서베이 페이퍼
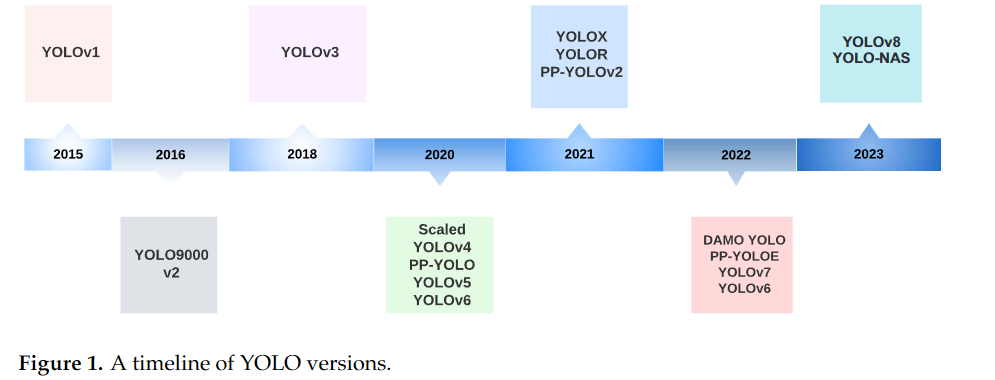
📖 (참고) YOLO 버전의 발전
💡 공식 버전: YOLO의 원 개발자인 Joseph Redmon은 YOLOv3까지 개발했습니다. 이후 그는 윤리적 이유로 객체 탐지 연구를 중단했습니다. Joseph Redmon이 객체 탐지 연구를 중단한 윤리적 이유는 주로 다음과 같습니다:
-군사적 목적으로의 활용 우려: Redmon은 자신이 개발한 기술이 군사적 목적으로 사용되는 것을 원치 않았습니다.
-감시 기술로의 악용 가능성: 객체 탐지 기술이 개인의 프라이버시를 침해하는 감시 시스템에 사용될 수 있다는 우려가 있었습니다.
-윤리적 책임감: YOLO v3 기술 보고서에서도 Redmon은 컴퓨터 비전 분야에서 객체 탐지 모델을 개발하는 것에 대한 윤리적 책임감을 강조했습니다1.
-기술의 양면성: 객체 탐지 기술이 긍정적인 용도로 사용될 수 있지만, 동시에 부정적인 목적으로도 활용될 수 있다는 점을 인식했습니다.
-사회적 영향에 대한 고려: 자신의 연구가 사회에 미칠 수 있는 잠재적인 부정적 영향을 고려한 결정이었습니다.
💡 비공식 버전: YOLOv4부터는 다양한 연구팀과 개발자들이 YOLO라는 이름을 사용하여 자체적으로 개발을 진행했습니다.
버전 번호의 의미: YOLOv4 이후의 버전 번호는 엄밀히 말해 연속성이 없습니다. 각 개발팀이 독립적으로 번호를 부여했기 때문입니다.연구와 개발의 차이: YOLOv5와 YOLOv8을 개발한 Ultralytics는 주로 소프트웨어 개발에 초점을 맞추고 있으며, 학술 논문 없이 코드를 공개하는 방식을 취하고 있습니다.다양한 YOLO 변형: YOLOv4, Scaled-YOLOv4, YOLO-R, YOLOv7 등은 YOLO의 원래 연구 방향을 더 가깝게 따르는 것으로 볼 수 있습니다.
(참고) 각 Header에 적은 논문의 년도는 각 논문(버전)의 발표 시기를 적은 것입니다. 버전 차이 등으로 인해서 자료 조사를 하면서 년도는 조금씩 상이할 수 있습니다.
1. Abstract
YOLO(You Only Look Once) 모델은 객체 탐지 분야에서 실시간 성능과 높은 정확성을 갖춘 모델로, 최신 YOLO-NAS까지 발전해 왔습니다. 이 서베이 페이퍼는 YOLO의 진화를 요약하고, YOLOv1부터 YOLOv8까지의 발전을 다룹니다. YOLO-NAS, YOLO with Transformers 같은 최신 모델들을 포함하여, 각 버전이 도입한 기술적 혁신과 성능 향상을 설명합니다.
2. Introduction
YOLO는 실시간 객체 탐지의 효율성과 정확도에서 중대한 역할을 담당하며, 다양한 응용 분야에서 널리 사용됩니다. 이 논문은 YOLO의 발전 과정과 각 모델의 핵심적인 특징들을 분석합니다. YOLOv1부터 YOLOv8, 그리고 YOLO-NAS까지의 변화와 개선점을 탐구하며, YOLO 모델이 빠르게 객체를 탐지하면서도 높은 정확도를 유지할 수 있는 비결을 설명합니다.
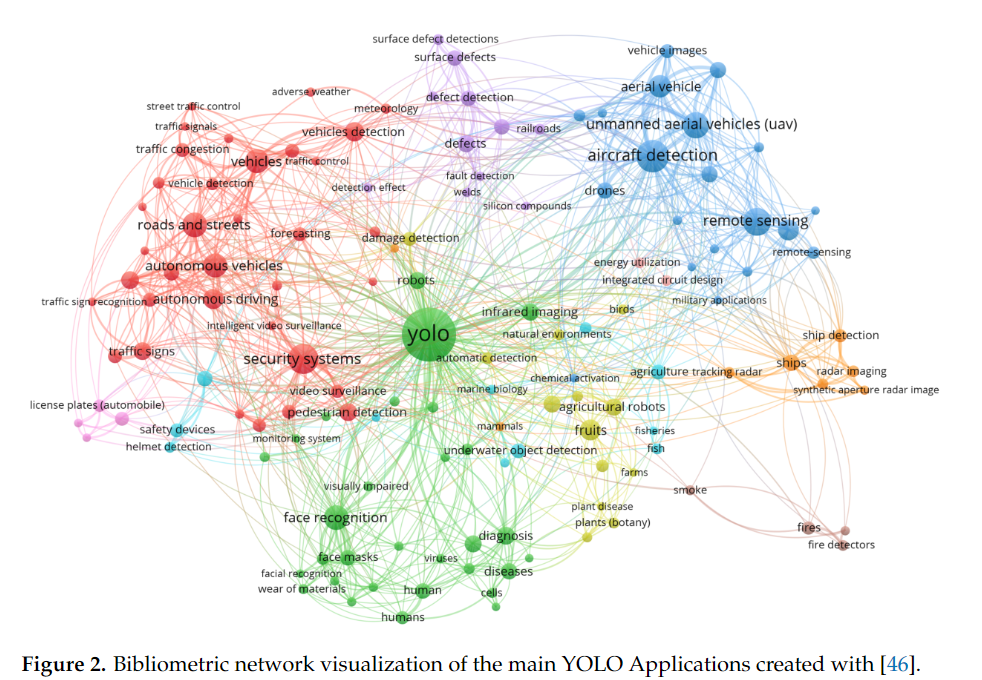
3. YOLO Applications across Diverse Fields
YOLO는 자율주행, 농업, 의료, 원격 탐사, 비디오 감시 등 다양한 분야에서 활용됩니다.
- 자율주행: 차량, 보행자, 자전거 등의 객체를 탐지하여 안전하고 효율적인 주행을 돕습니다.
- 농업: 농작물의 상태를 감지하고 병해충을 탐지하여 농업 자동화를 지원합니다.
- 의료: 암 진단, 피부 세분화 등의 의료 분야에서 객체 탐지를 통해 진단 정확도를 향상시킵니다.
- 원격 탐사: 위성 및 항공 이미지를 분석하여 환경 모니터링, 도시 계획 등에 활용됩니다.
4. Object Detection Metrics and Non-Maximum Suppression (NMS)
이 챕터에서는 객체 탐지 모델의 성능을 평가하기 위한 주요 메트릭과 객체 탐지 후처리 방법인 NMS(Non-Maximum Suppression)에 대해 설명합니다.
- 객체 탐지의 목표는 이미지에서 객체를 올바르게 탐지하고 해당 객체의 정확한 위치를 예측하는 것입니다.
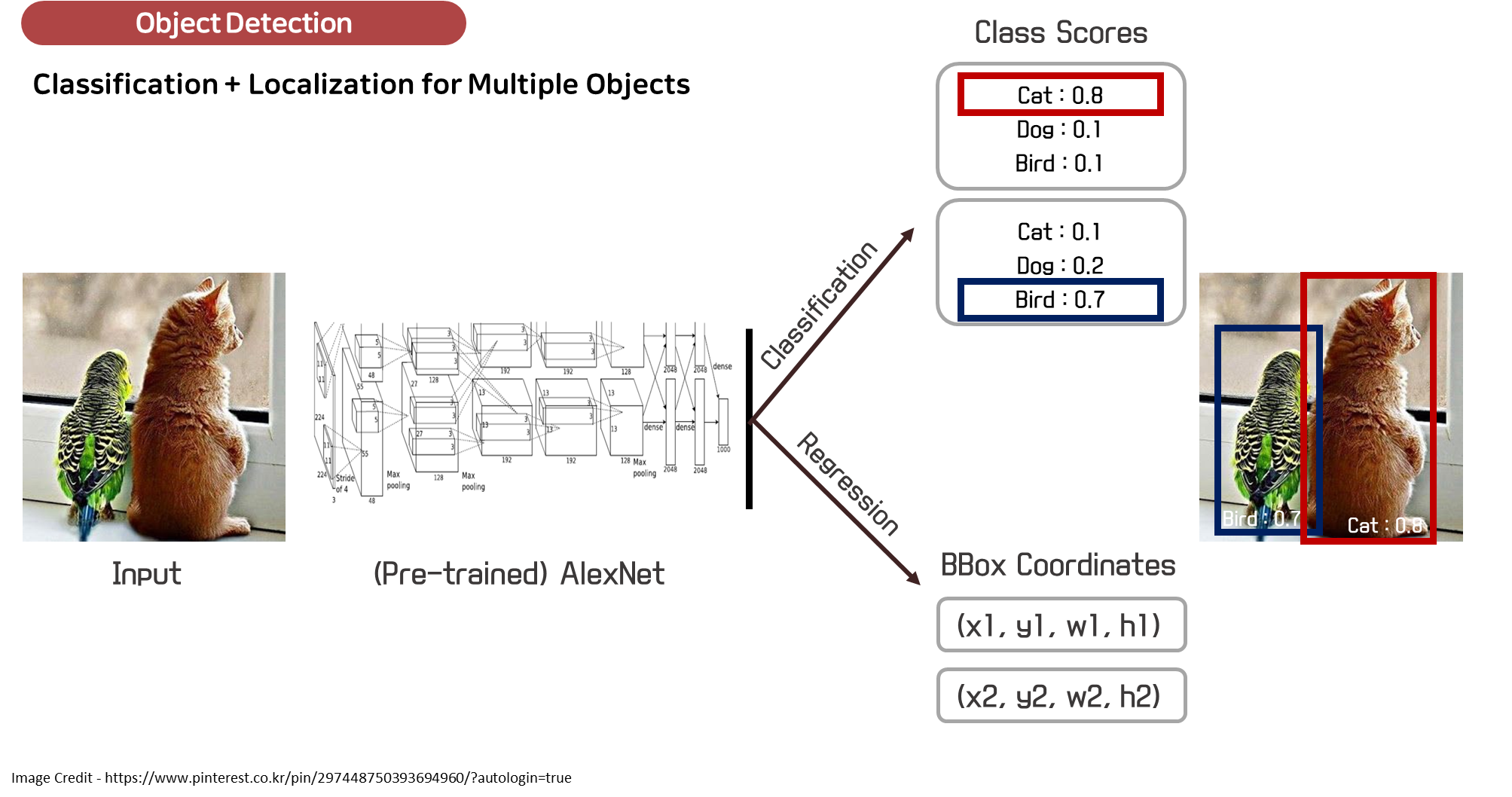
- 이때, 모델의 성능을 평가하는 메트릭으로 평균 정확도(mean Average Precision, mAP)가 자주 사용되며, NMS는 객체 탐지 결과에서 중복된 상자를 제거하는 방법입니다.
4.1 Average Precision (AP)와 Mean Average Precision (mAP)
평균 정확도(AP)는 객체 탐지 모델의 성능을 평가하기 위해 가장 널리 사용되는 지표입니다. AP는 한 이미지 내에서 모델이 예측한 객체의 위치가 얼마나 정확한지를 나타내며, 모델의 정밀도(precision)와 재현율(recall)을 기반으로 계산됩니다.
-
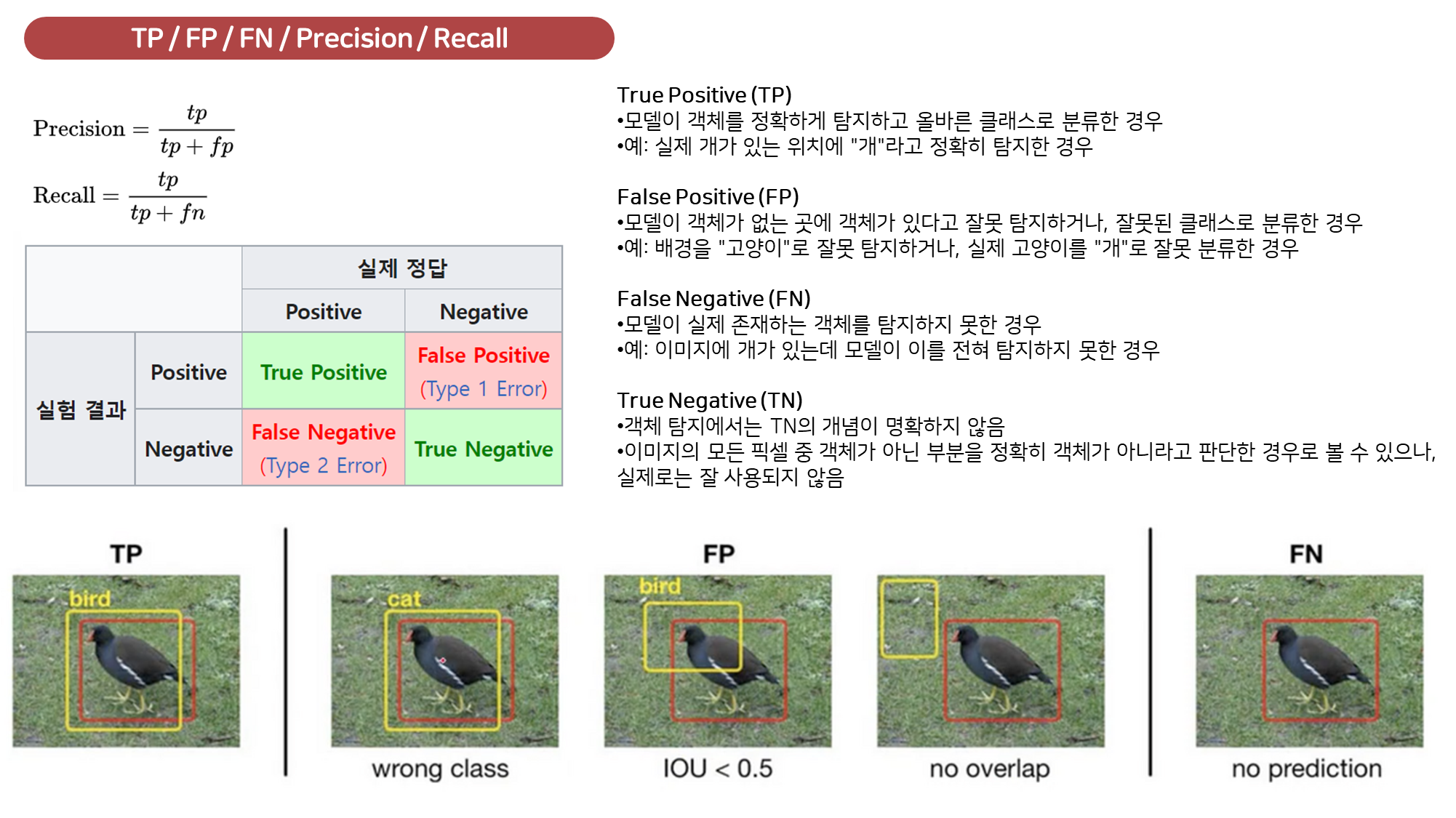
정밀도(Precision): 모델이 탐지한 객체 중 실제로 맞는 객체의 비율입니다. (예측을 Positive로 한 애들 중에서, 예측과 실제 값이 일치하는 데이터의 비율)- 즉, 모델이 탐지한 객체가 얼마나 정확한지를 평가합니다.
-
재현율(Recall): 실제 객체 중에서 모델이 맞게 탐지한 객체의 비율입니다. (실제 값이 Positive인 대상들 중에서, 예측과 실제 값이 Positive로 일치하는 데이터의 비율)- 즉, 모델이 실제로 얼마나 많은 객체를 탐지했는지를 평가합니다.

-
신뢰도 (Confidence): 모델마다 주로 로 등장하는, 해당 예측이 얼마만큼의 신뢰도를 가지는지를 나타내는 점수입니다. 그리고 Confidence Threshold란, 말 그대로 Confidence의 임계값으로, Confidence가 몇 이상인 예측들만 예측으로 볼 것인가 하는 수치라고 생각할 수 있습니다.- Confidence Threshold가 낮으면 → Bbox 예측이 많아지고 → Precision 감소, Recall 증가.
- Confidence Threshold가 높으면 → Bbox 예측이 적어지고 → Precision 증가, Recall 감소.
-
AP (Average Precision): 정밀도-재현율 곡선(precision-recall curve) 아래의 면적으로 계산되며, 주어진 임계값에서 모델이 얼마나 잘 예측하는지를 나타냅니다. 이 곡선은 모델의 탐지 임계값에 따라 변하는 정밀도와 재현율 간의 상호작용을 보여줍니다.정밀도-재현율 곡선(precision-recall curve): 분류 모델의 성능을 평가하는 데 사용되는 중요한 시각화 도구입니다. x축에 재현율(Recall), y축에 정밀도(Precision)를 표시한 그래프입니다. 다양한 분류 임계값(threshold)에 따른 정밀도와 재현율의 변화를 보여줍니다.
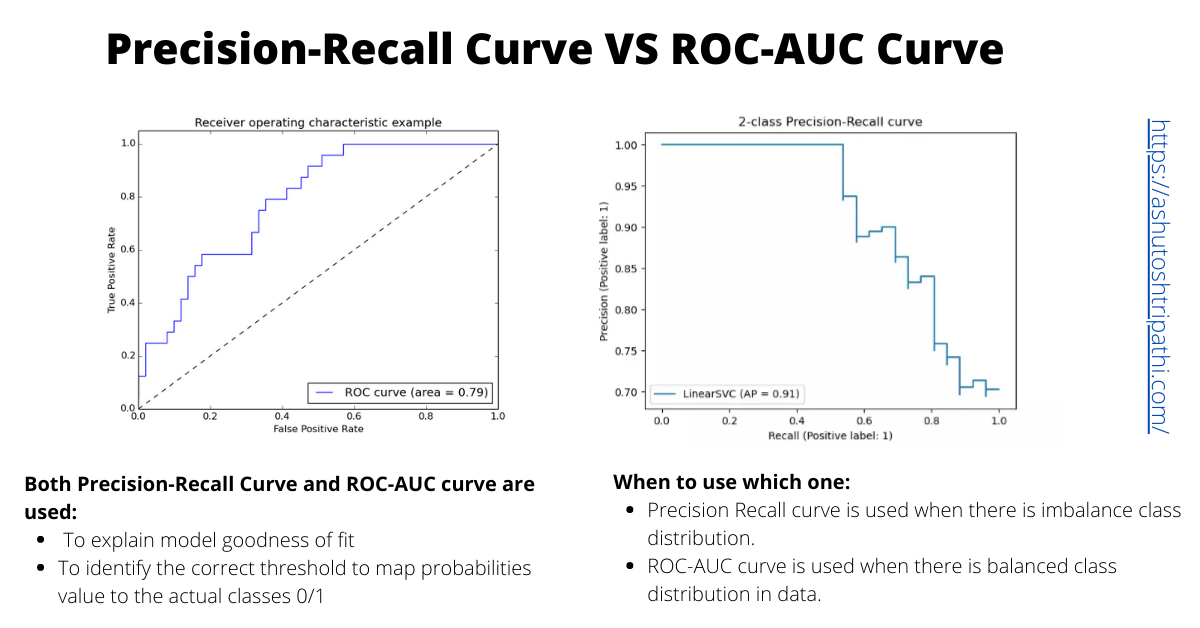
mAP (Mean Average Precision): mAP는 모든 객체 클래스에 대한 AP의 평균값을 의미하며, 여러 클래스가 포함된 데이터셋에서 모델의 전체적인 성능을 평가하는 데 사용됩니다.- 예를 들어, MS COCO와 같은 데이터셋에서는 80개의 객체 클래스가 포함되어 있으며, mAP는 이들 객체에 대한 평균 성능을 나타냅니다.
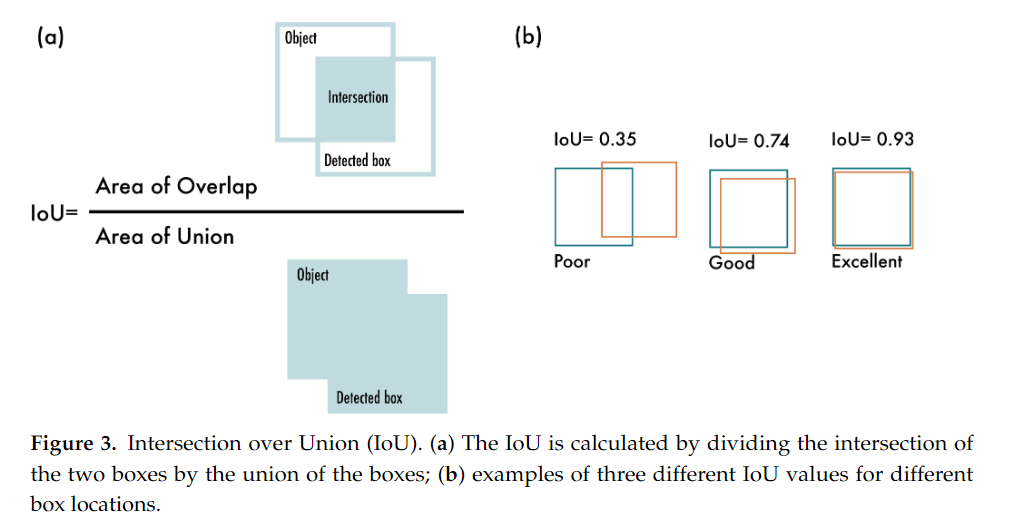
4.2 Intersection over Union (IoU)
- Intersection over Union (IoU)는 예측된 바운딩 박스와 실제 바운딩 박스 사이의 겹침 정도를 나타내는 메트릭입니다.
- IoU는 두 박스가 겹치는 영역의 크기를 두 박스가 차지하는 총 면적으로 나누어 계산됩니다.
IoU의 수식은 아래와 같이 정의할 수 있습니다:
- IoU = (예측된 박스 ∩ 실제 박스) / (예측된 박스 ∪ 실제 박스)
IoU는 모델이 예측한 바운딩 박스가 얼마나 정확한지 평가하는 데 사용되며, IoU 임계값을 높게 설정할수록 더 정확한 위치 예측을 요구하게 됩니다.
- 일반적으로 COCO 데이터셋에서는 여러 IoU 임계값을 사용하여 모델의 성능을 평가하며, AP50(IoU 0.5 이상인 경우) 및 AP75(IoU 0.75 이상인 경우)와 같은 방식으로 모델 성능을 측정합니다.
- 범위: 0 ~ 1
- 특징: 두 상자가 겹치지 않으면 항상 0
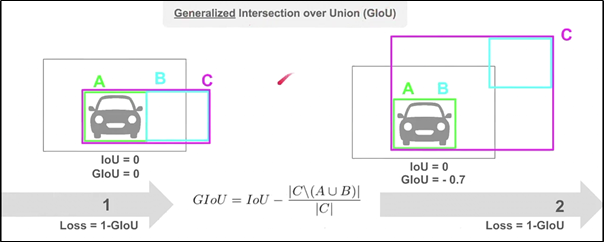
IoU (Intersection over Union) 개념을 확장하여, GIoU, DIoU, 그리고 CIoU는 바운딩 박스의 위치 정확도를 개선하고자 다양한 추가 요소를 고려한 메트릭입니다. 각 메트릭은 IoU의 한계를 보완하기 위해 제안되었으며, 특히 두 객체가 많이 겹치지 않을 때 성능이 향상됩니다.
- Generalized Intersection over Union (GIoU)는 IoU를 확장하여 두 바운딩 박스 사이의 차이가 크더라도, 해당 박스의 겹침을 더 잘 표현할 수 있도록 고안된 메트릭입니다.
- IoU는 박스가 전혀 겹치지 않으면 0을 반환하지만, GIoU는 두 박스가 겹치지 않는 상황에서도 더 나은 측정값을 제공합니다.

GIoU는 다음과 같이 정의됩니다:
여기서 C는 두 박스를 모두 포함하는 최소 바운딩 박스의 영역입니다. 이 수식에서 두 박스가 겹치지 않는 경우, 겹치지 않는 공간에 대한 정보를 추가로 반영하여 IoU보다 더 나은 측정값을 제공하게 됩니다.
- 두 박스가 완벽히 일치하면 GIoU는 IoU와 동일한 값을 가집니다.
- 범위: -1 ~ 1
- 특징: 두 상자를 모두 포함하는 최소 영역인 C 박스를 활용
- 장점: 두 상자가 겹치지 않아도 거리에 따른 페널티 부여 가능
- Distance Intersection over Union (DIoU)는 IoU에 박스의 중심점 간 거리를 반영한 메트릭입니다.
- 이는 단순히 겹치는 영역의 크기뿐만 아니라, 박스의 중심점 간의 거리를 고려함으로써 박스가 어느 정도 근접한지를 평가합니다.
- DIoU는 두 바운딩 박스의 중심점 사이의 유클리드 거리를 계산하고 이를 측정식에 반영합니다.

그 수식은 다음과 같습니다:
여기서:
- d는 두 바운딩 박스의 중심점 간 거리입니다.
- c는 두 바운딩 박스를 포함하는 최소 외접 원의 대각선 길이입니다.
DIoU는 두 박스의 중심이 얼마나 가까운지 고려하기 때문에, 객체 탐지에서 위치 오류를 줄이는 데 더 적합합니다. 특히 박스가 겹치지 않더라도 중심점이 가까운 경우 높은 점수를 줍니다.
- 범위: -1 ~ 1
- 특징: IoU와 중심점 좌표를 함께 고려
- 장점: GIoU보다 빠른 수렴 속도, 수평/수직 방향에서도 효과적
- Complete Intersection over Union (CIoU)는 DIoU에 박스의 종횡비 차이까지 고려한 메트릭입니다.
- 즉, CIoU는 IoU, 박스 중심점의 거리, 그리고 박스의 형태까지 평가하는 종합적인 척도입니다.

CIoU의 수식은 다음과 같습니다:
여기서:
- v는 두 박스의 종횡비 차이를 측정하는 항입니다.
- α는 v에 비례하는 가중치로, IoU가 낮을 때는 종횡비에 더 큰 가중치를 부여합니다.
종횡비 차이를 고려함으로써, CIoU는 단순히 두 박스가 얼마나 겹치는지 뿐만 아니라, 두 박스의 크기와 형태가 유사한지도 평가하게 됩니다. 따라서, 객체 탐지 문제에서 위치와 크기 모두를 최적화하려는 상황에 적합합니다.
- 범위: -1 ~ 1
- 특징: DIoU에 종횡비 페널티 추가
- 장점: 겹치는 영역, 중심점 거리, 종횡비를 모두 고려하여 가장 완전한 평가 가능
💡 요약
- IoU: 두 박스의 겹치는 영역을 기반으로 평가.
- GIoU: IoU에 두 박스를 모두 포함하는 최소 영역(C 박스)을 고려하여, 두 박스가 겹치지 않더라도 더 나은 평가를 제공.
- DIoU: IoU와 함께 두 박스의 중심점 간 거리를 고려하여 근접성을 평가.
- CIoU: DIoU에 더해 두 박스의 종횡비 차이까지 평가하여, 박스의 위치, 크기, 형태 모두를 고려한 종합적인 척도.
4.3 PASCAL VOC와 COCO 데이터셋에서의 AP 계산
-
PASCAL VOC: 이 데이터셋에서는 20개의 객체 클래스에 대해 AP를 계산합니다. 각 클래스에 대해 정밀도-재현율 곡선을 그린 후, 11개의 점을 사용하여 평균을 계산하는 방식으로 AP를 구합니다.
-
COCO: COCO 데이터셋은 80개의 객체 클래스와 더 복잡한 AP 계산 방식을 사용합니다. 101개의 점에서 정밀도-재현율 곡선을 계산하며, 다양한 IoU 임계값(0.5에서 0.95까지, 0.05 간격)을 사용해 AP를 구합니다. 이 방식을 통해 더욱 세밀하게 모델의 성능을 평가할 수 있습니다.
4.4 Non-Maximum Suppression (NMS)
객체 탐지 모델은 이미지에서 여러 바운딩 박스를 예측하며, 종종 동일한 객체에 대해 여러 상자를 예측하게 됩니다. Non-Maximum Suppression (NMS)는 이러한 중복된 상자를 제거하는 후처리 기법입니다.
- NMS는 객체 탐지의 최종 결과로 가장 신뢰도 높은 상자만 남기고 나머지 상자를 제거합니다.
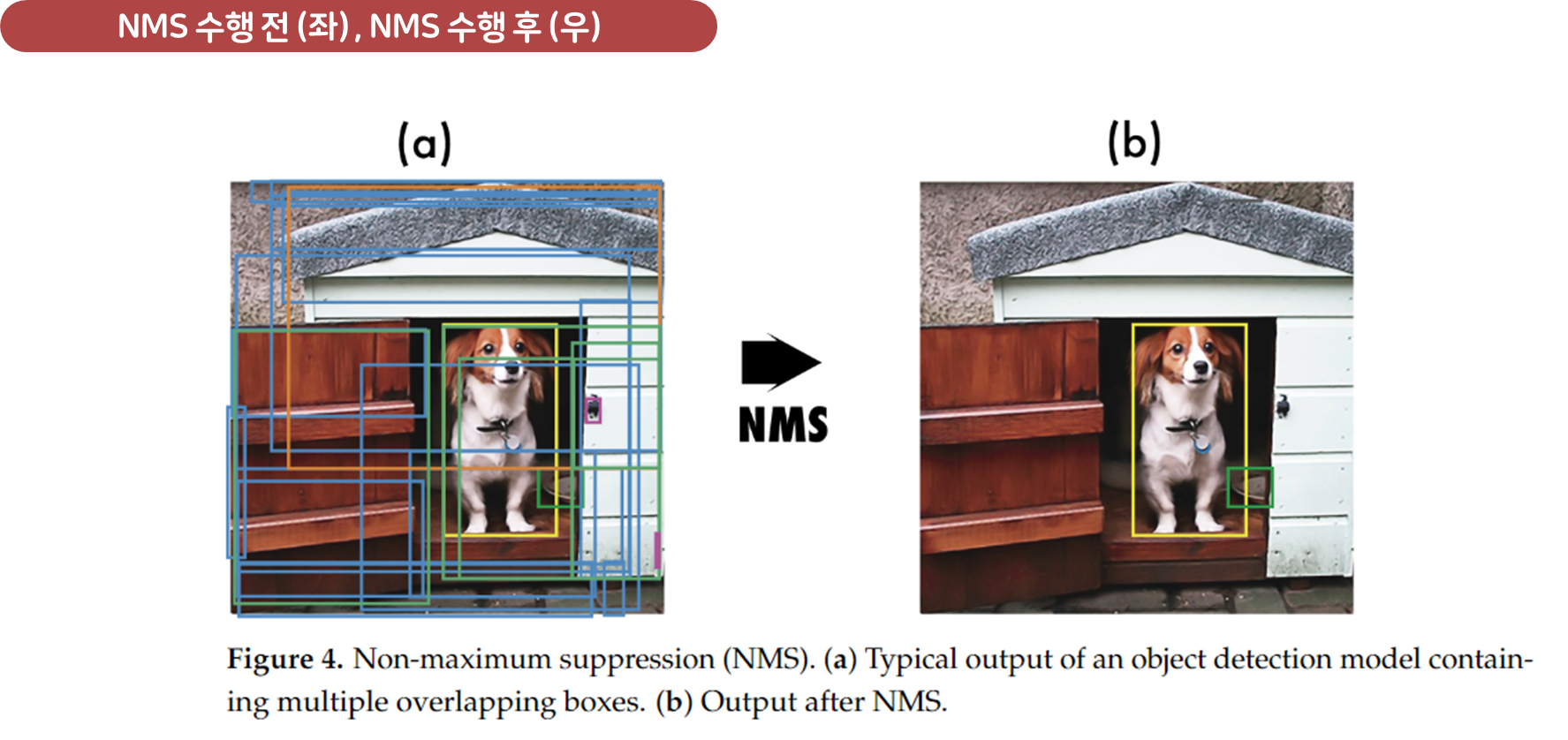
NMS의 기본 과정은 다음과 같습니다:
-
모델이 예측한 모든 상자를 신뢰도(score) 기준으로 정렬합니다.
-
가장 높은 신뢰도를 가진 상자를 선택하고, 그 상자와 겹치는 상자들 중에서 IoU 값이 임계값 이상인 상자를 제거합니다.
-
남은 상자들에 대해 동일한 과정을 반복하여 중복된 예측을 제거합니다.
NMS를 적용함으로써 객체 탐지 결과의 중복을 방지하고, 최종적으로 정확한 탐지 결과만 남게 됩니다.
이는 객체 탐지에서 매우 중요한 후처리 단계로, 탐지 정확도를 높이고 불필요한 중복 예측을 줄이는 역할을 합니다.
5. YOLO-v1: You Only Look Once (2016년)
YOLOv1은 2015년에 Joseph Redmon에 의해 소개된 최초의 실시간 객체 탐지 모델로, "You Only Look Once"라는 이름에서 알 수 있듯이 단일 패스로 객체를 탐지할 수 있는 혁신적인 모델이었습니다. YOLOv1은 이미지 전체를 한 번에 분석하여 객체를 탐지하는 방식으로 기존의 객체 탐지 방식과는 크게 다른 접근 방식을 사용했습니다. YOLOv1은 실시간 객체 탐지 시스템의 효율성과 속도를 크게 개선했으며, 자율주행, 감시 시스템, 비디오 분석 등 다양한 분야에서 널리 사용되었습니다. (CVPR 2016)
5.1 YOLOv1의 주요 특징
-
단일 신경망 패스:
- YOLOv1의 가장 큰 특징은 이미지 전체를 한 번에 처리하여 객체를 탐지하는 방식입니다.
- 이전의 객체 탐지 시스템들은 이미지 내에서 슬라이딩 윈도우를 사용해 많은 후보 영역을 만들어낸 후, 그 후보 영역에 대해 객체 여부를 판별하는 방식으로 작동했습니다.
- 그러나 이러한 방식은 이미지 전체에 대해 여러 번의 연산을 요구했기 때문에 속도가 느리고 비효율적이었습니다.
- YOLOv1은 이러한 문제를 해결하기 위해, 입력 이미지를 여러 격자(grid)로 나누고 각 격자에서 동시에 여러 바운딩 박스와 클래스 확률을 예측하는 방식을 채택했습니다.
-
격자 기반 탐지:
- YOLOv1은 입력 이미지를 크기의 격자(grid)로 나눕니다.
- 각 격자 셀은 최대 개의 바운딩 박스와 해당 객체가 있을 확률을 예측합니다.
- 바운딩 박스는 객체의 중심 좌표 (), 너비 (), 높이 (), 그리고 그 바운딩 박스에 객체가 있을 확률을 나타내는 확신도()를 포함한 5개의 값(Pc, bx, by, bh, bw)으로 이루어져 있습니다.
- 각 격자 셀은 클래스별 확률 도 예측하며, 각 클래스에 해당하는 예측 확률을 제공합니다.
- 따라서 YOLOv1의 출력은 크기의 텐서로 표현됩니다.
- 이 구조는 모든 객체 탐지를 동시에 수행할 수 있어 연산 효율성이 높습니다.
YOLOv1에서의 출력은 각 그리드 셀에 대해 예측된 값들의 배열로 구성됩니다. 예를 들어, 아래 그림처럼 class가 3개있는 task에 대해서 "3x3" 그리드에 대해, 출력은 3×3×8 형태로 나옵니다. 여기서 각 차원의 의미는 다음과 같습니다:
-
3x3 그리드:
- 입력 이미지를 3×3의 그리드로 나누어 총 9개의 그리드 셀이 형성됩니다.
- 각 그리드 셀은 자기 영역 내에서 객체를 감지하고 예측할 책임이 있습니다.
-
8개의 값: 각 그리드 셀은 다음의 8개 값을 출력합니다:
- 1개의 신뢰도 점수 : 해당 그리드 셀 내에 객체가 포함될 확률.
- 4개의 경계 상자 좌표 : 각 그리드 셀의 중심 좌표 및 경계 상자의 크기.
- 3개의 클래스 확률: 3개의 서로 다른 클래스에 대한 확률 값.
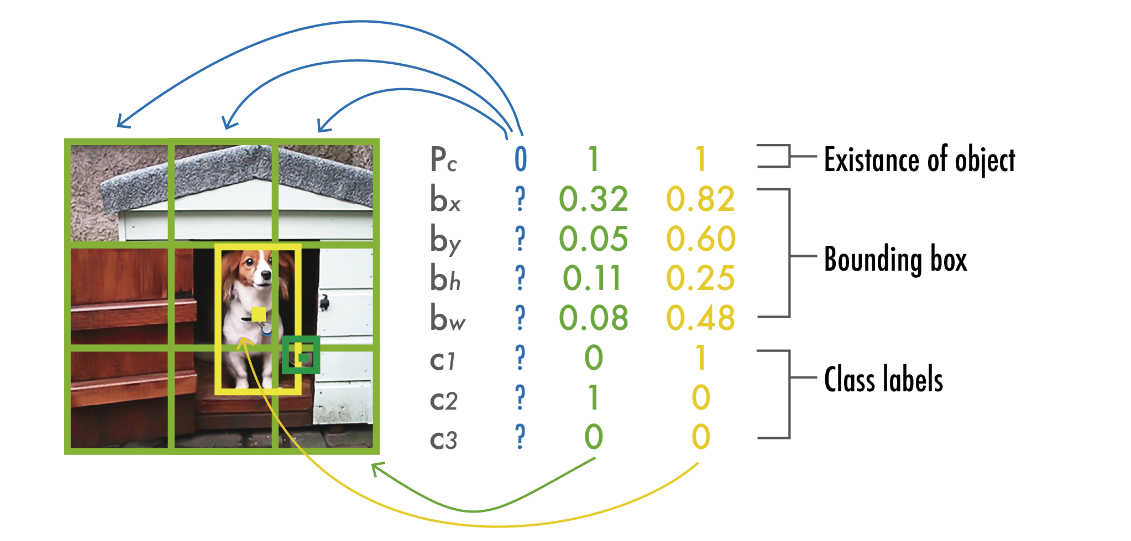
-
: 객체가 포함될 확률 (Confidence Score)
- 이 값은 특정 경계 상자 내에 객체가 존재할 확률을 나타냅니다.
- 즉, 그 경계 상자에 해당하는 클래스가 실제로 존재할 가능성을 측정합니다.
- 이 확률은 모델이 예측한 객체의 존재 여부를 반영하며, 모델의 정확성을 높이기 위해 중요합니다.
-
: 경계 상자의 중심 x좌표
- 는 그리드 셀을 기준으로한 경계 상자의 중심의 x좌표를 나타냅니다.
- 이는 이미지의 너비와 상대적으로 위치가 결정되며, 해당 셀 내의 객체 중심 좌표를 제공합니다.
-
: 경계 상자의 중심 y좌표
- 는 경계 상자의 중심의 y좌표를 나타냅니다. 마찬가지로 이 값은 해당 셀 내의 객체 중심 좌표로서, 이미지의 높이에 대한 상대적인 위치를 정의합니다.
-
: 경계 상자의 높이
- 는 예측된 경계 상자의 높이를 나타내며, 경계 상자가 커버하는 객체의 높이를 측정합니다. 이 값은 이미지 크기에 대한 상대적인 값으로 결정됩니다.
-
: 경계 상자의 너비
- 는 경계 상자의 너비를 나타내며, 경계 상자가 포함하는 객체의 너비를 측정합니다. 이 값 역시 이미지 크기에 대한 상대적인 값으로서, 와 함께 경계 상자의 크기를 정의합니다.
5.2 YOLOv1의 아키텍처
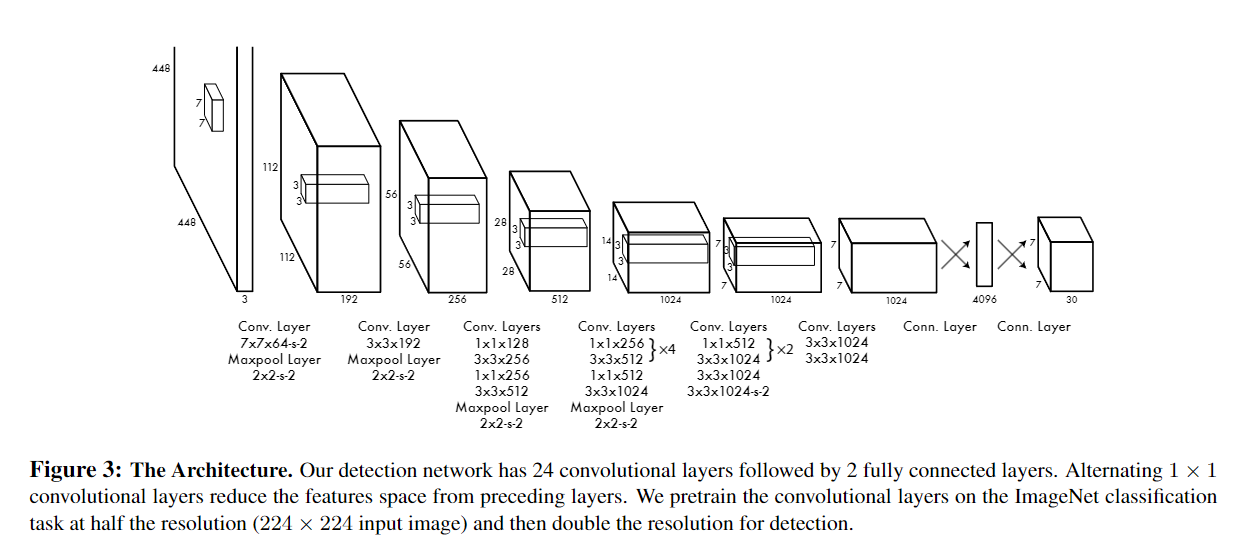
YOLOv1의 신경망 아키텍처는 24개의 합성곱(convolutional) 계층과 2개의 완전 연결(fully connected) 계층으로 구성되어 있습니다. 24개의 합성곱 계층은 이미지에서 객체의 특징을 추출하는 역할을 하며, 마지막 2개의 완전 연결 계층은 탐지된 객체의 바운딩 박스 좌표와 클래스 확률을 예측하는 역할을 합니다. 각 합성곱 계층은 Leaky ReLU 활성화 함수를 사용하며, 마지막 층에서는 선형 활성화 함수를 사용합니다.
또한, 모델을 경량화한 Fast YOLO 버전도 함께 도입되었는데, 이 버전은 9개의 합성곱 계층만을 사용하여 YOLOv1보다 더 빠른 속도를 자랑합니다.
5.3 YOLOv1의 훈련 및 데이터 증강
-
YOLOv1은 첫 20개의 합성곱 계층을 ImageNet 데이터셋에서 사전 훈련을 진행했습니다.
-
그리고 나머지 4개의 계층을 추가하여 PASCAL VOC 2007 및 2012 데이터셋으로 미세 조정(fine-tuning)을 진행했습니다.
-
훈련 중에는 이미지의 크기를 임의로 확대하거나 축소하고, 이미지를 회전시키거나 밝기 및 색상을 변형하는 다양한 데이터 증강(data augmentation) 기법을 적용하여 모델이 다양한 상황에서 잘 동작할 수 있도록 훈련되었습니다.
- Random scaling and translations: 이미지 크기의 최대 20%까지 무작위로 확대/축소 및 이동을 적용했습니다. 예를 들어, 448x448 크기의 입력 이미지라면:
- 스케일링: 358x358 ~ 538x538 사이의 크기로 무작위 조정
- 이동: 가로세로 각각 -90 ~ +90 픽셀 범위 내에서 무작위 이동
- Random exposure and saturation: HSV, 색상(Hue), 채도(Saturation), 명도(Value) 색 공간에서 노출(밝기)과 채도를 조정했습니다. 최대 1.5배까지 증가시켰습니다.
- 즉, 원본 값의 1.0 ~ 1.5배 사이에서 무작위로 조정했습니다.
- Random scaling and translations: 이미지 크기의 최대 20%까지 무작위로 확대/축소 및 이동을 적용했습니다. 예를 들어, 448x448 크기의 입력 이미지라면:
5.4 YOLOv1의 손실 함수
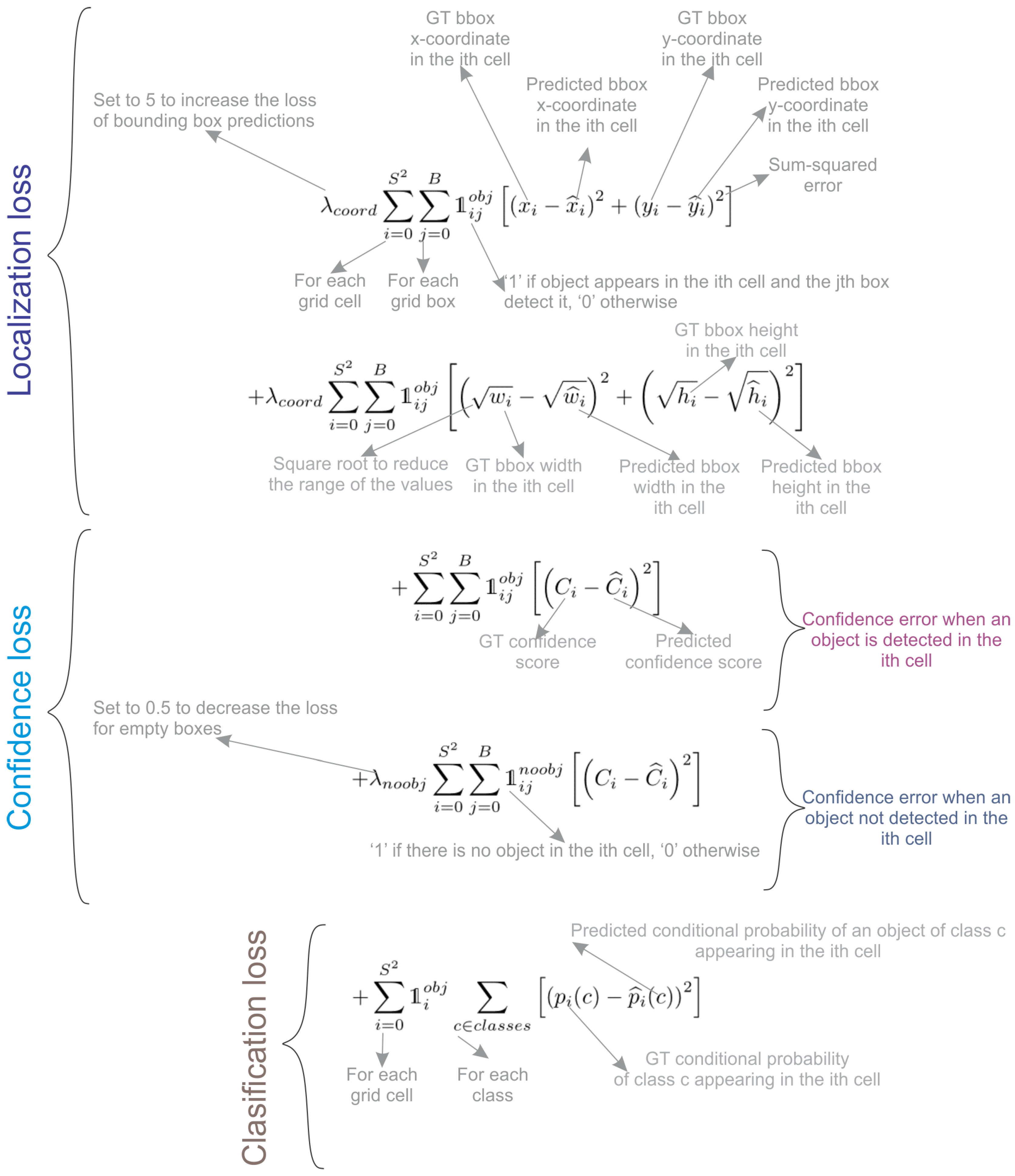
YOLOv1에서 사용된 손실 함수는 여러 개의 제곱합 오류로 구성되어 있으며, 이는 예측된 경계 상자(bounding boxes)의 정확성을 평가하는 데 사용됩니다. λcoord와 λnoobj는 YOLOv1의 손실 함수에서 사용되는 하이퍼파라미터로, 모델의 다양한 예측에 대한 중요성을 조절하는 역할을 합니다.
-
λcoord (Coordinate Scale Factor):
λcoord는 경계 상자(bounding box) 예측의 정확성을 강조하는 스케일 팩터입니다. 값이 5로 설정되어 있어, 경계 상자 위치와 크기 예측의 손실이 전체 손실에 미치는 영향을 증가시킵니다.- 즉, 모델이 객체의 위치와 크기를 정확하게 예측하는 것이 중요하다는 것을 반영합니다. 이 값이 높을수록 경계 상자 예측의 오류가 더 큰 패널티를 받게 되어, 모델이 이 부분에 더 집중하도록 유도합니다.
- 아래 그림을 보면
Localization loss에 파라미터로 곱해져있는 것으로 확인할 수 있습니다.
-
λnoobj (No Object Scale Factor):
λnoobj는 객체가 없는 경계 상자에 대한 손실의 중요성을 줄이는 스케일 팩터입니다. 값이 0.5로 설정되어 있어, 실제로 객체가 없는 곳에서 경계 상자를 예측할 때 발생하는 손실의 영향이 줄어듭니다.- 이를 통해 모델이 불필요한 예측을 줄이고, 실제 객체가 존재하는 경우에만 더 집중하도록 돕습니다.
- 아래 그림을 보면
Confidence loss에 파라미터로 곱해져있는 것으로 확인할 수 있습니다.
아래 그림과 같은 손실 함수 설계는 YOLOv1이 객체 탐지에서 정확한 예측을 할 수 있도록 돕는데, 특히 객체가 있는 경계 상자에 대한 예측을 더 주의 깊게 고려하게 합니다. 이는 전체적인 모델 성능 향상에 기여하는 중요한 요소입니다.
5.5 YOLOv1의 장점과 한계
YOLOv1은 간단한 아키텍처와 빠른 속도를 바탕으로 실시간 객체 탐지에서 뛰어난 성능을 발휘했지만, 몇 가지 한계점도 존재했습니다:
- 소형 객체 탐지의 어려움: YOLOv1은 격자 기반의 탐지 방식으로 인해, 동일한 격자 내에서 여러 객체가 있을 경우 정확하게 탐지하기 어렵다는 단점이 있었습니다.
- 비표준적인 객체 비율 탐지 문제: 훈련 데이터에서 본 적 없는 비율을 가진 객체의 경우 탐지 성능이 떨어졌습니다.
- 다운샘플링 문제: YOLOv1은 이미지의 해상도를 낮추어 특징을 추출하는 과정에서, 객체의 세부 정보를 놓치는 경우가 있었습니다.
6. YOLOv2: Better, Faster, and Stronger (2017년)
YOLOv2는 2016년 Joseph Redmon과 Ali Farhadi가 발표한 모델로, YOLOv1에서 성능과 정확도를 개선하여 "더 나은(Better), 더 빠른(Faster), 더 강력한(Stronger)" 객체 탐지 시스템을 목표로 개발되었습니다.
- Better : 정확도를 올리기 위한 방법
- Faster : detection 속도를 향상시키기 위한 방법
- Stronger : 더 많은 범위의 class를 예측하기 위한 방법
YOLOv2는 YOLOv1의 한계를 해결하고 다양한 최적화 기법을 도입하여 더욱 강력한 성능을 제공했습니다. YOLOv2는 특히 더 많은 객체를 빠르고 정확하게 탐지할 수 있도록 여러 가지 개선이 이루어졌습니다. (CVPR2017)
6.1 YOLOv2의 주요 개선 사항
-
배치 정규화(Batch Normalization) 도입
- YOLOv2는 모든 합성곱 계층에 배치 정규화(Batch Normalization)를 적용하여 모델의 수렴 속도를 높이고 과적합(overfitting)을 방지했습니다.
- 배치 정규화는 훈련 과정에서 활성화 값의 분포를 안정화시켜, 더 빠르고 안정적인 학습을 가능하게 합니다. 이 기법은 모델의 성능을 2%가량 향상시켰습니다.
📖 배치 정규화(Batch Normalization)
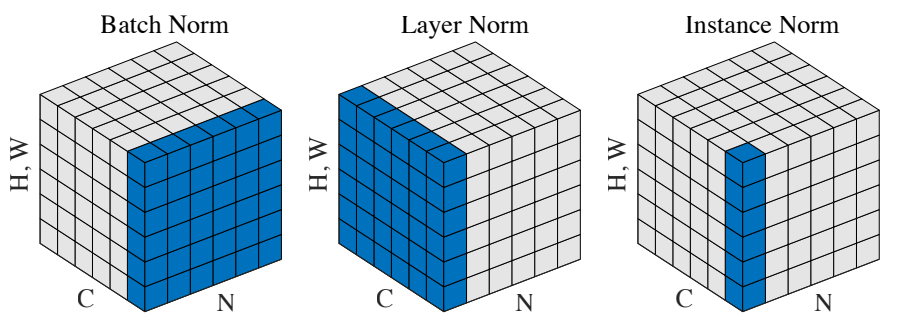
배치 정규화(Batch Normalization)는 2015년 Ioffe와 Szegedy가 소개한 기법으로, 딥러닝 모델, 특히 CNN(Convolutional Neural Networks)의 성능을 크게 향상시키는 중요한 기술입니다.💡 배치 정규화의 목적
학습 속도 향상: 더 높은 학습률을 사용할 수 있게 해줍니다.모델의 일반화 능력 개선: 과적합을 줄이는 데 도움을 줍니다.Internal Covariate Shift 감소: 각 레이어의 입력 분포 변화를 줄입니다.
✍️ 작동 원리
- 정규화: 각 배치의 활성화 값에 대해 평균(는 배치의 평균)과 분산(는 배치의 분산)을 계산하여 정규화합니다.
- 스케일링과 이동: 정규화된 값에 학습 가능한 파라미터 (감마)와 (베타)를 적용합니다.
-
고해상도 분류기(Fine-tuned High-resolution Classifier)
- YOLOv1과 마찬가지로 YOLOv2는 ImageNet 데이터셋에서 먼저 224×224 해상도의 이미지로 사전 훈련(pretraining)을 거쳤습니다.
- 이후 YOLOv2는 해상도를 448×448로 높여 10 에포크(epoch) 동안 추가 학습을 진행하여 고해상도 입력에 대한 모델 성능을 개선했습니다.
- 이 과정에서 모델이 높은 해상도에서 더 나은 예측을 할 수 있도록 최적화되었습니다.
-
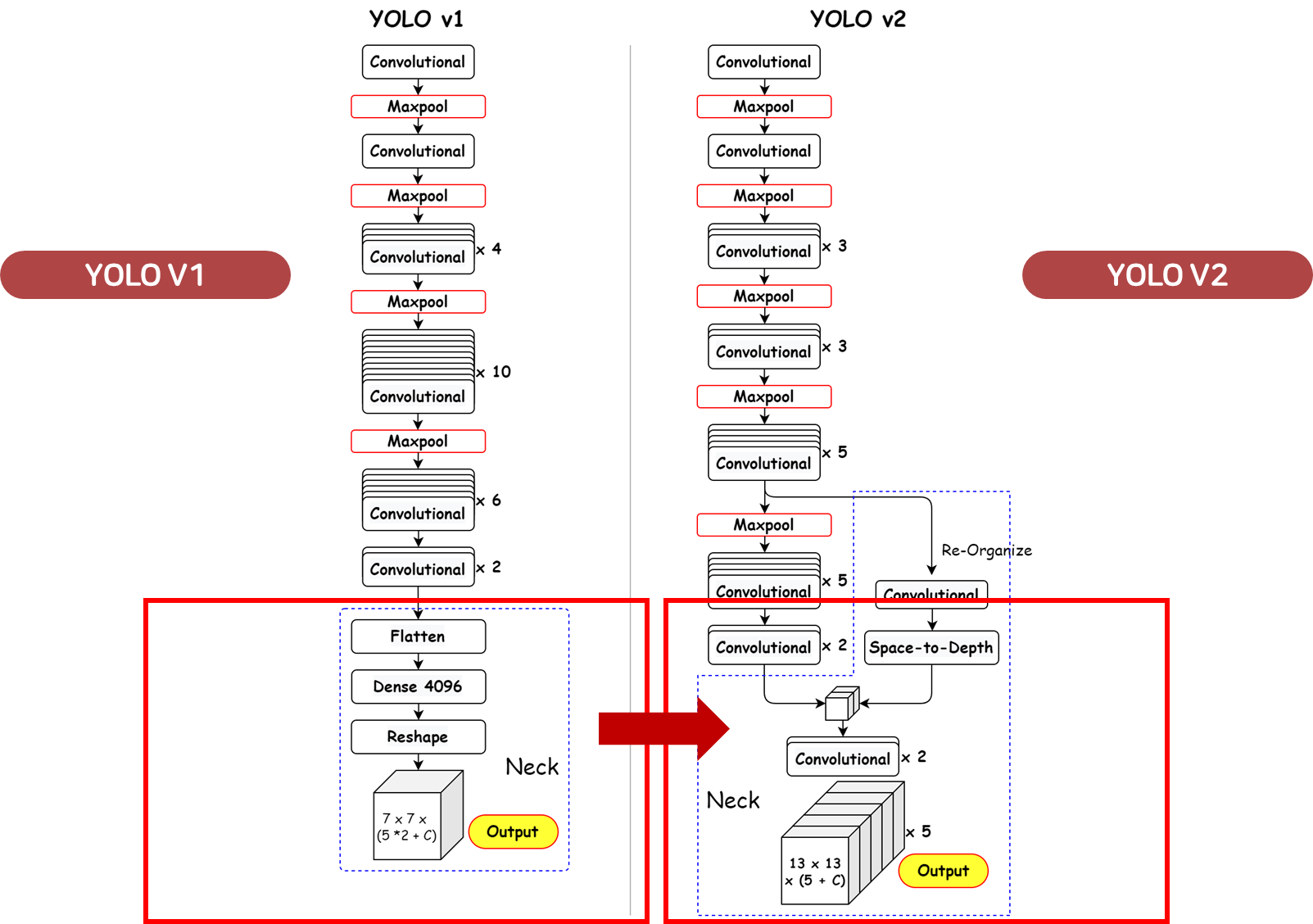
완전 합성곱 네트워크(Fully Convolutional Network)
- YOLOv2는 완전 연결 계층을 제거하고 완전 합성곱 네트워크(Fully Convolutional Network, FCN)를 도입하여 모델의 크기와 계산 비용을 줄였습니다.
- 이를 통해 YOLOv2는 더 빠른 속도와 더 작은 메모리 사용량을 달성할 수 있었습니다.
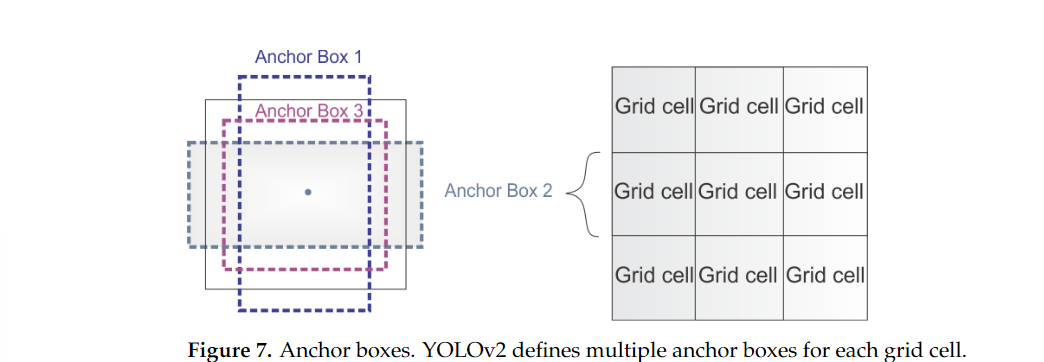
- 앵커 박스(Anchor Boxes) 도입
- YOLOv2에서 앵커 박스(Anchor Boxes)는 객체 감지 성능을 크게 향상시키기 위해 도입된 중요한 개념입니다.
- 앵커 박스는 모델이 특정 객체를 감지하는 데 예상되는 경계 상자의 구조 또는 비율을 미리 정의한 것입니다.
- 이 방식은 Faster R-CNN과 같은 모델에서 처음 도입되었으며, 다양한 크기와 비율의 객체를 탐지하는 성능을 개선할 수 있었습니다.
앵커 박스
기본 아이디어: YOLOv2는 네트워크의 각 그리드 셀에 대해 여러 개의 앵커 박스를 지정합니다.
- 이러한 앵커 박스는 미리 정의된 비율과 크기를 가지며, 다양한 객체의 크기와 형태에 대한 사전 정보를 제공합니다.
다양성: 각 그리드 셀에 여러 개의 앵커 박스를 배치함으로써, 다양한 모양과 크기의 객체를 보다 효과적으로 예측할 수 있습니다. 이는 특히 서로 다른 객체의 크기와 비율이 큰 이미지에서 유리합니다.
- 예를 들어, 사람이 있는 경우와 자동차가 있는 경우는 형태가 다르므로 서로 다른 비율을 가진 앵커 박스가 필요합니다.
🔎 Faster R-CNN은 고정된 앵커박스를 사용합니다.
Faster R-CNN에서는 고정된 크기와 비율의 앵커 박스를 사용합니다. 즉, 사전에 정의된 특정 크기와 비율의 박스를 다양한 위치에 적용하여 객체를 탐지합니다.
- Faster R-CNN은 보통 3개의 크기와 3개의 비율을 조합해 9개의 앵커 박스를 생성하며, 이는 이미지나 데이터셋에 상관없이 고정된 값입니다.
2:1,1:1,1:2x 3, 총 9개의 앵커박스 후보를 사용
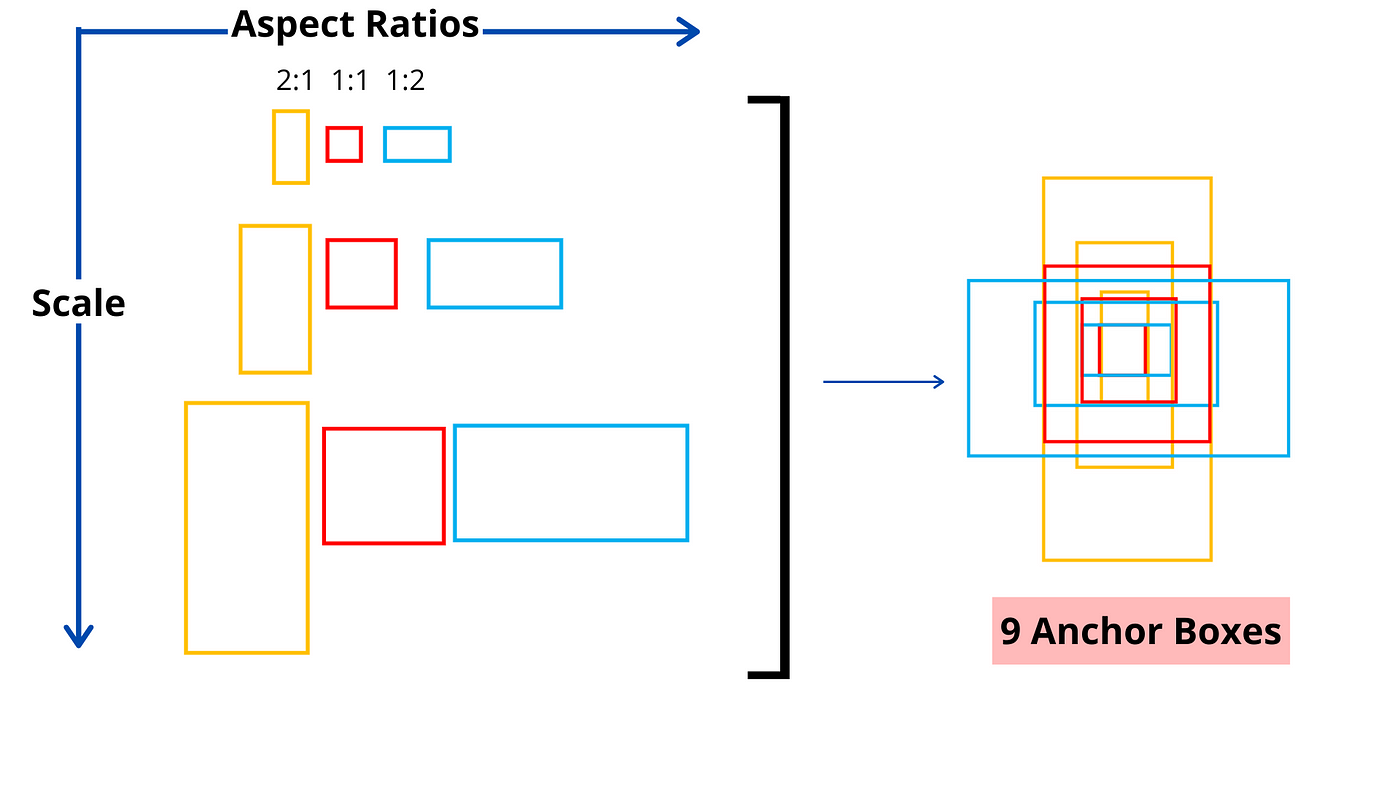
🔎 Yolo-v2는 데이터셋에 맞춘 앵커 박스를 사용합니다.
YOLO v2에서는 각 객체의 실제 바운딩 박스 크기와 비율을 기반으로 클러스터링을 수행하여, K-평균 클러스터링을 통해 데이터셋에 맞는 최적의 앵커 박스를 정의합니다. 이를 통해 모델은 더 효율적으로 객체를 탐지할 수 있습니다.
- 예를 들어, Pascal VOC와 같은 데이터셋에서 객체들의 바운딩 박스(GT, Ground Truth)를 분석한 후, K-평균 클러스터링을 적용하여 5개의 최적화된 앵커 박스를 정의합니다.
- 이 과정은 데이터셋마다 달라질 수 있으며, 이렇게 정의된 앵커 박스는 해당 데이터셋에 맞는 크기와 비율을 반영하여 더 나은 탐지 성능을 제공합니다.
- 차원 군집화(Dimensional Clustering)
차원 군집화는 YOLOv2에서 K-평균 군집화(K-means clustering)를 사용하여 최적의 앵커 박스를 선택하는 방식입니다. 이 접근법은 객체 탐지에서 바운딩 박스의 크기와 비율을 보다 정확하게 예측할 수 있도록 도와줍니다.- 과정:
- 훈련 데이터셋의 바운딩 박스 분석: 모델을 훈련할 때, 각 객체의 실제 바운딩 박스 정보를 활용합니다. 바운딩 박스의 너비와 높이(w, h)는 훈련 데이터셋에서 수집된 Ground Truth(GT) 정보에서 얻을 수 있습니다.
- K-평균 군집화: YOLOv2는 바운딩 박스의 크기와 비율에 따라 K-평균 군집화 알고리즘을 적용하여, 가장 자주 나타나는 바운딩 박스의 크기 및 비율을 그룹화합니다. 이 군집화 과정은 실제 데이터 분포를 기반으로 하기 때문에, 모델은 데이터셋에 맞는 최적의 앵커 박스를 사용할 수 있습니다.
- 앵커 박스 선택: 군집화 결과로 각 군집의 중심(centroid)을 기준으로 앵커 박스를 정의합니다. YOLOv2에서는 일반적으로 5개의 앵커 박스가 최적의 선택으로 알려져 있으며, 이 앵커 박스는 모델이 객체를 탐지할 때 초기 가이드를 제공합니다.
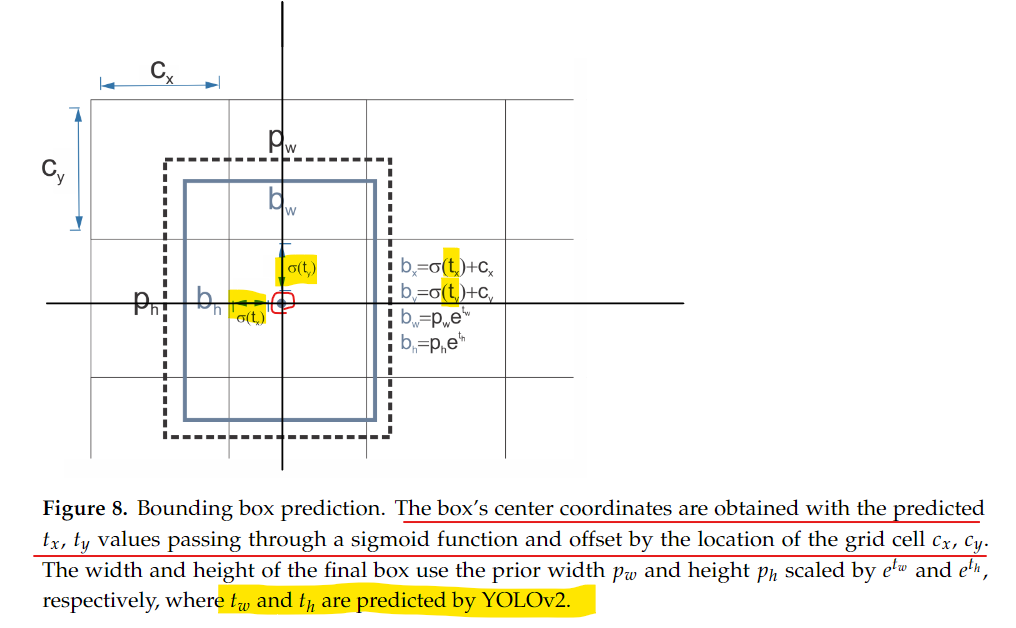
- 직접 위치 예측(Direct Location Prediction)
직접 위치 예측은 YOLOv2가 바운딩 박스의 좌표를 예측하는 방식입니다. YOLOv2는 이전 모델인 Faster R-CNN과 달리, 오프셋(offset) 기반 예측 대신 객체의 직접적인 위치를 예측합니다. 이는 YOLO의 철학을 유지하면서도 위치 예측의 정확도를 높인 방법입니다.- 과정:
- YOLO의 철학 유지: YOLO 모델은 이미지를 그리드 셀로 나누고, 각 그리드 셀이 객체의 존재 여부와 객체의 위치 정보를 예측합니다. 이 때, 그리드 셀에서 객체의 중심 좌표(X, Y)를 직접 예측하는 방식입니다.
- Sigmoid 활성화 함수 사용: 예측된 X, Y 좌표는 각 그리드 셀의 경계 내에서 0과 1 사이의 값으로 제한됩니다. 이를 위해 YOLOv2는 Sigmoid 활성화 함수를 사용해 좌표 값을 그리드 셀 경계 내에 위치시키는 방식을 적용합니다.
- 그리드 셀 내 상대 좌표 예측: YOLOv2는 그리드 셀을 기준으로 좌표를 예측하므로, 좌표의 정확도를 높이기 위해 상대적인 좌표를 예측합니다. Faster R-CNN에서 사용했던 오프셋 기반 접근법은 불안정한 훈련을 초래할 수 있었으나, YOLOv2의 방식은 안정적인 훈련을 제공합니다.
📊 아래 그림은 YOLOv2에서 바운딩 박스의 위치와 크기를 어떻게 예측하는지를 시각적으로 설명한 것으로, 그리드 셀을 기준으로 예측된 상대 좌표가 어떻게 최종 바운딩 박스를 생성하는지에 대한 구체적인 계산 과정을 보여줍니다.
- 바운딩 박스 중심: Sigmoid 함수를 통해 그리드 셀 내에서 상대적인 좌표를 예측하고, 그 값을 기준 그리드 셀 좌표에 더해 바운딩 박스의 중심 좌표를 계산합니다.
- 바운딩 박스 크기: 미리 정의된 앵커 박스 크기를 기반으로, 지수 함수를 통해 예측된 스케일 값을 반영하여 최종 너비와 높이를 계산합니다.
- 앵커 박스: 바운딩 박스의 초기 크기를 제공하며, YOLOv2에서는 데이터셋의 클러스터링을 통해 사전 정의된 앵커 박스를 사용합니다.
-
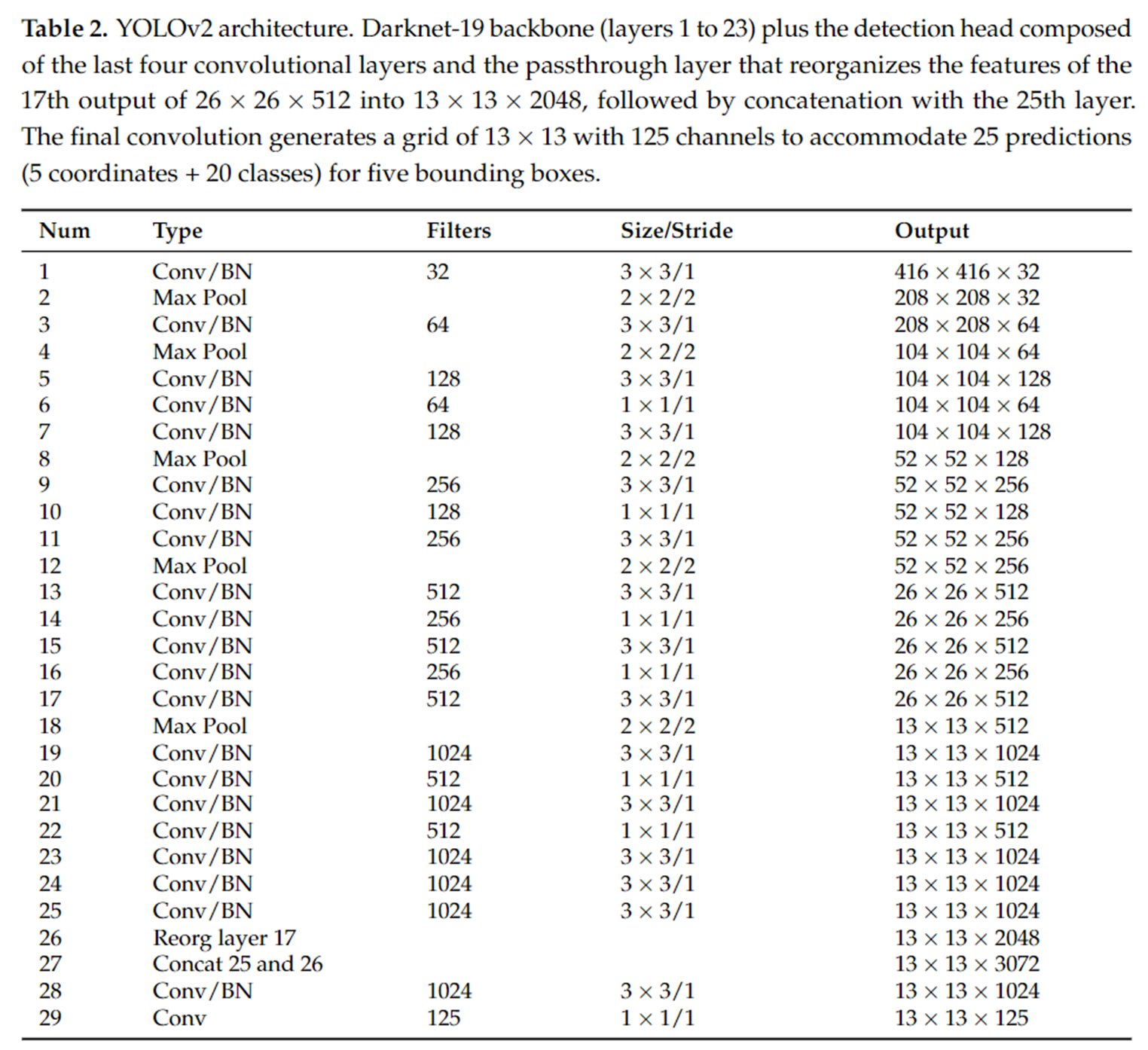
더 세밀한 특징(Finer-grained Features)
- YOLOv2는 입력 이미지의 해상도를 416×416으로 설정하고, 한 계층의 풀링(pooling)을 제거함으로써 더 큰 출력 그리드를 생성하여 더 세밀한 특징을 추출할 수 있었습니다. 또한, 패스트스루 레이어(Passthrough Layer)를 도입하여 낮은 해상도의 특징 맵을 고해상도의 특징 맵과 연결함으로써 작은 객체에 대한 탐지 성능을 향상시켰습니다.
-
다중 스케일 학습(Multi-scale Training)
- YOLOv2는 다양한 해상도의 이미지를 학습할 수 있도록 다중 스케일 학습 기법을 도입했습니다. 훈련 과정에서 이미지 크기를 320×320에서 608×608까지 무작위로 변경하여 모델이 다양한 크기의 이미지를 학습하고, 다양한 해상도에서도 일관된 성능을 발휘할 수 있도록 했습니다.
6.2 YOLO9000: 더 많은 객체 탐지
YOLOv2와 함께 발표된 YOLO9000은 모델이 단일 훈련 과정에서 객체 탐지와 분류 작업을 동시에 학습할 수 있도록 설계된 모델입니다.
- YOLO9000은 COCO 데이터셋에서 객체 탐지 작업을, ImageNet 데이터셋에서 객체 분류 작업을 학습함으로써 더 많은 객체 클래스에 대한 탐지가 가능해졌습니다.
- YOLO9000은 9000개 이상의 객체 클래스에 대한 탐지 성능을 자랑했으며, 이는 YOLOv2의 확장된 버전으로 강력한 성능을 제공합니다.
7. YOLOv3 (2018년)
YOLOv3는 2018년에 Joseph Redmon과 Ali Farhadi에 의해 발표된 모델로, YOLOv2의 성능을 개선하고 객체 탐지의 정확도를 높이는 데 중점을 둔 버전입니다.
- YOLOv3는 더 큰 네트워크 아키텍처와 향상된 기능을 도입하여, 다양한 크기의 객체를 더 잘 탐지할 수 있도록 설계되었습니다.
- 또한, 실시간 성능을 유지하면서도 복잡한 장면에서의 탐지 능력을 강화하였습니다.
7.1 YOLOv3의 주요 개선 사항
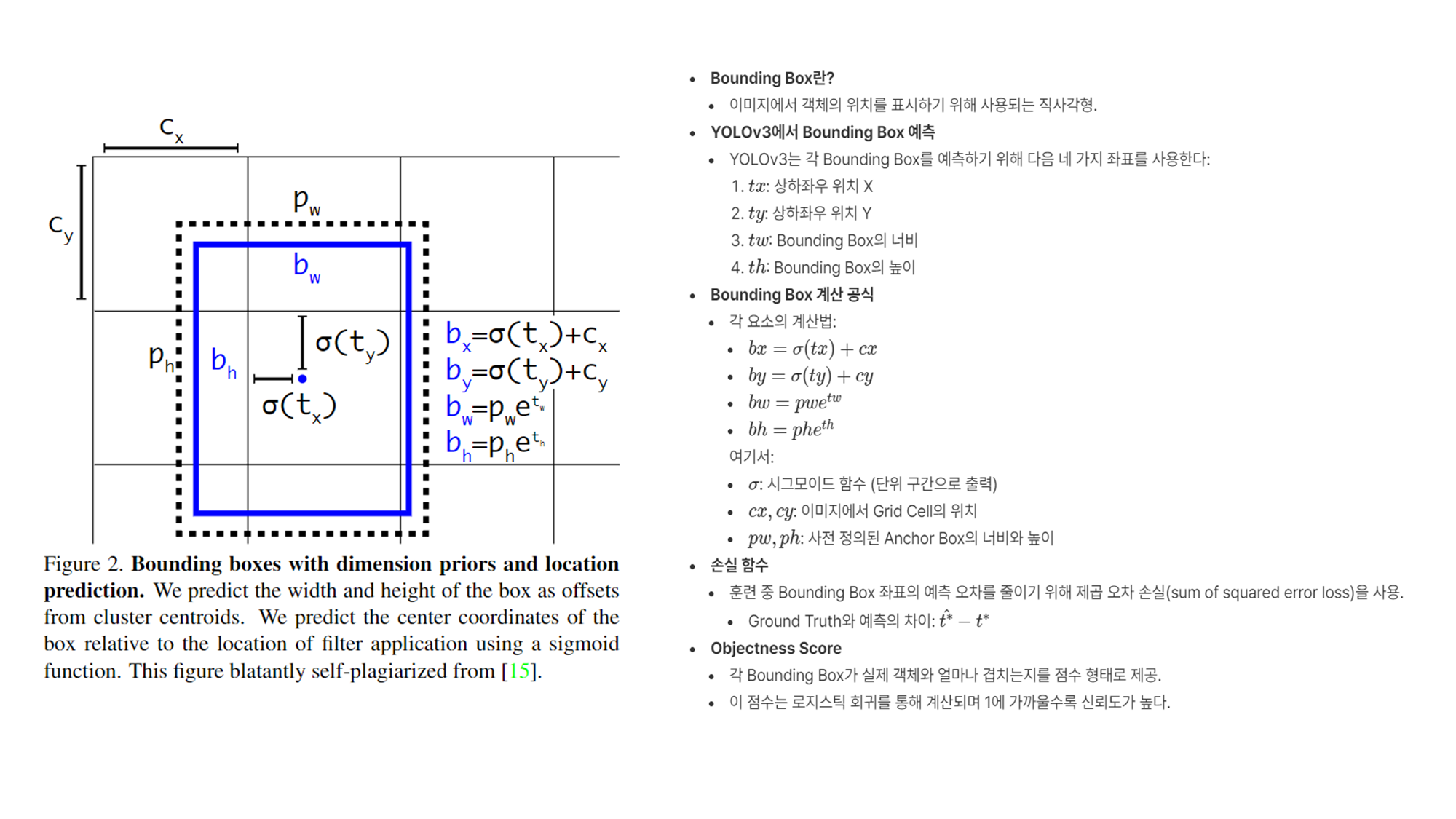
- 바운딩 박스 예측의 개선
- YOLO-V3는 앵커 박스를 사용해 바운딩 박스의 좌표를 예측합니다.
- 각 바운딩 박스는 (X좌표), (Y좌표), (폭), (높이), 객체성 점수 (해당 바운딩 박스에 객체가 있을 확률)와 클래스 확률 (해당 바운딩 박스에서 확인된 객체의 클래스)을 예측합니다.
- 이 값들은 네트워크에서 예측된 변형(, )와 사전 정의된 바운딩 박스의 차원(, )을 사용하여 계산됩니다. (아래 그림 참고)
- YOLOv3는 이전 YOLOv2와 마찬가지로 바운딩 박스를 예측하기 위해 4개의 좌표 값을 사용하지만, 객체성 점수라는 새로운 개념을 도입했습니다.
- 객체성 점수(objectness score)는 YOLOv3와 같은 객체 감지 모델에서 바운딩 박스가 실제 객체를 포함할 확률을 나타내는 값입니다. 이 점수는 특정 바운딩 박스가 객체를 포함하고 있는지를 평가하는 데 사용됩니다.
- YOLO-V3는 앵커 박스를 사용해 바운딩 박스의 좌표를 예측합니다.
-
클래스 예측의 개선
- YOLOv3는 클래스 예측에서 소프트맥스(Softmax) 대신 이진 교차 엔트로피(Binary Cross-Entropy) 손실 함수를 사용하여 각 클래스에 대한 독립적인 로지스틱 회귀 분류기를 학습시켰습니다.
- 구체적으로 말하자면, YOLOv3는 각 예측된 바운딩 박스에 대해 객체의 존재 확률을 출력하는데, 이 확률은 로지스틱 회귀를 통해 계산됩니다.
- 이 방식은 객체가 여러 개의 클래스를 가질 수 있는 경우(예: "사람"이자 "남자"인 객체)를 더 유연하게 탐지할 수 있도록 해주었습니다.
-
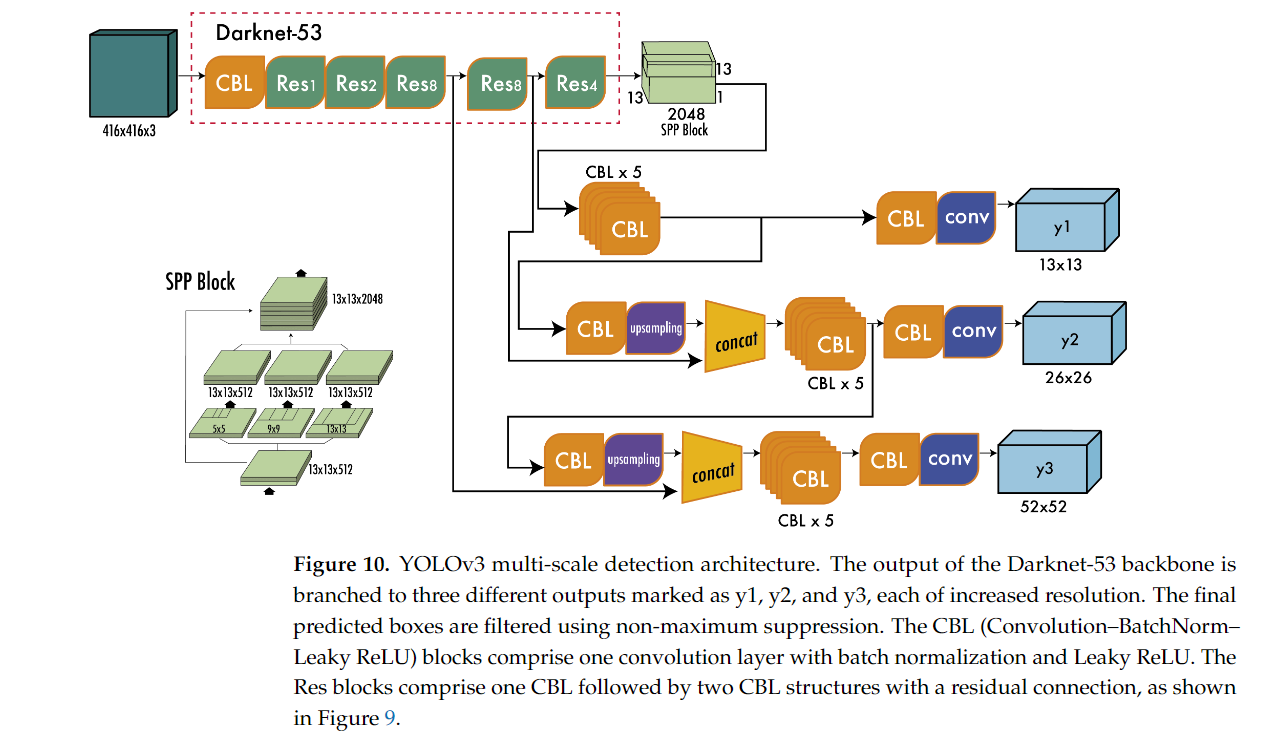
새로운 백본 네트워크: Darknet-53
- YOLOv3는 특징 추출을 위해 더 큰 백본 네트워크인 Darknet-53을 도입했습니다.
- 이 네트워크는 총 53개의 합성곱 계층으로 구성되어 있으며, 잔차 연결(residual connections)을 도입하여 학습이 더 잘 진행될 수 있도록 했습니다.
- 잔차 블록과 Leaky ReLU 활성화 함수가 사용되며, 예측은 모두 합성곱(convolutional) 레이어로 처리됩니다.
- 풀링 레이어 대신 Stride 2를 사용하여 다운샘플링을 진행하여, 정보 손실을 줄이고자 했습니다.
- Darknet-53은 ResNet-152와 유사한 정확도를 가지면서도 두 배 빠른 속도를 제공하는 효율적인 네트워크입니다.

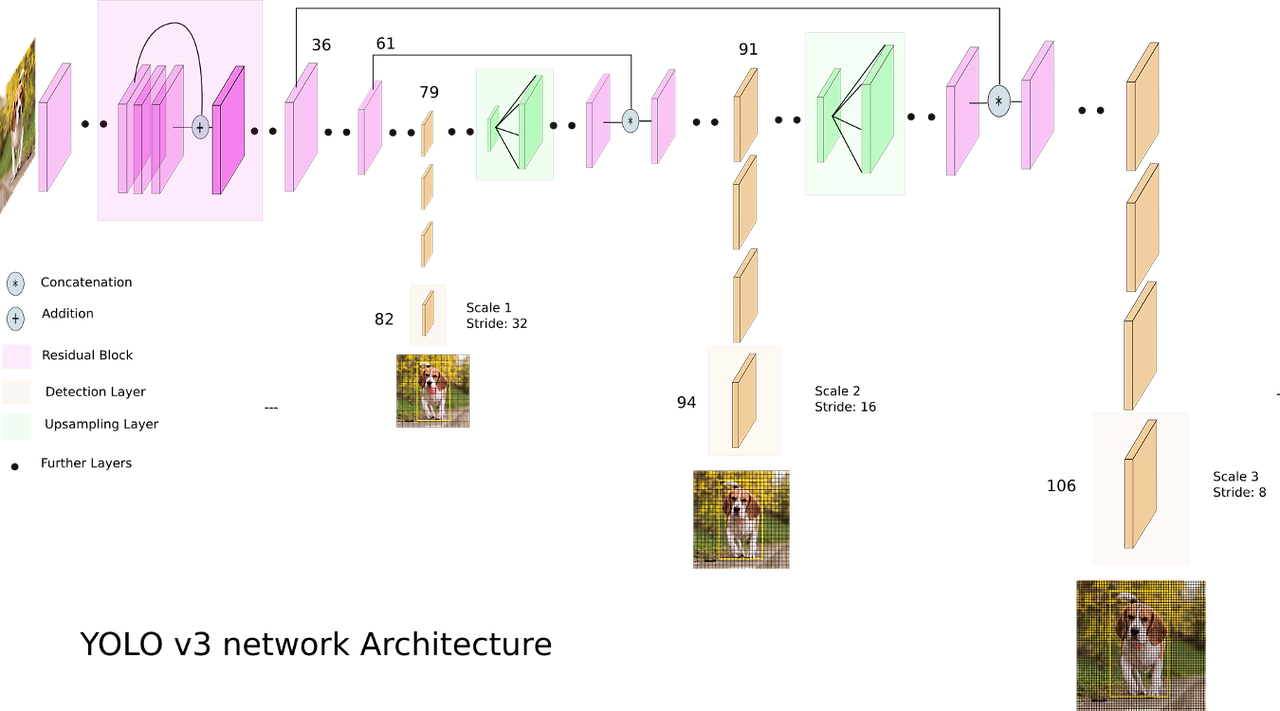
- 다중 스케일 예측(Multi-Scale Predictions)
- YOLOv3의 가장 중요한 개선 중 하나는 다중 스케일 예측 기능입니다. YOLOv3는 한 가지 해상도에서만 탐지를 수행하는 것이 아니라, 여러 해상도에서 탐지 작업을 수행함으로써 다양한 크기의 객체를 보다 정확하게 탐지할 수 있었습니다.
- 예를 들어, YOLOv3는
13×13,26×26,52×52의 서로 다른 크기의 그리드에서 탐지를 수행하여, 작은 객체부터 큰 객체까지 모두 탐지할 수 있었습니다. 이러한 다중 스케일 예측은 특히 작은 객체를 탐지하는 데 효과적이었습니다.
- 예를 들어, YOLOv3는
- YOLOv3의 가장 중요한 개선 중 하나는 다중 스케일 예측 기능입니다. YOLOv3는 한 가지 해상도에서만 탐지를 수행하는 것이 아니라, 여러 해상도에서 탐지 작업을 수행함으로써 다양한 크기의 객체를 보다 정확하게 탐지할 수 있었습니다.
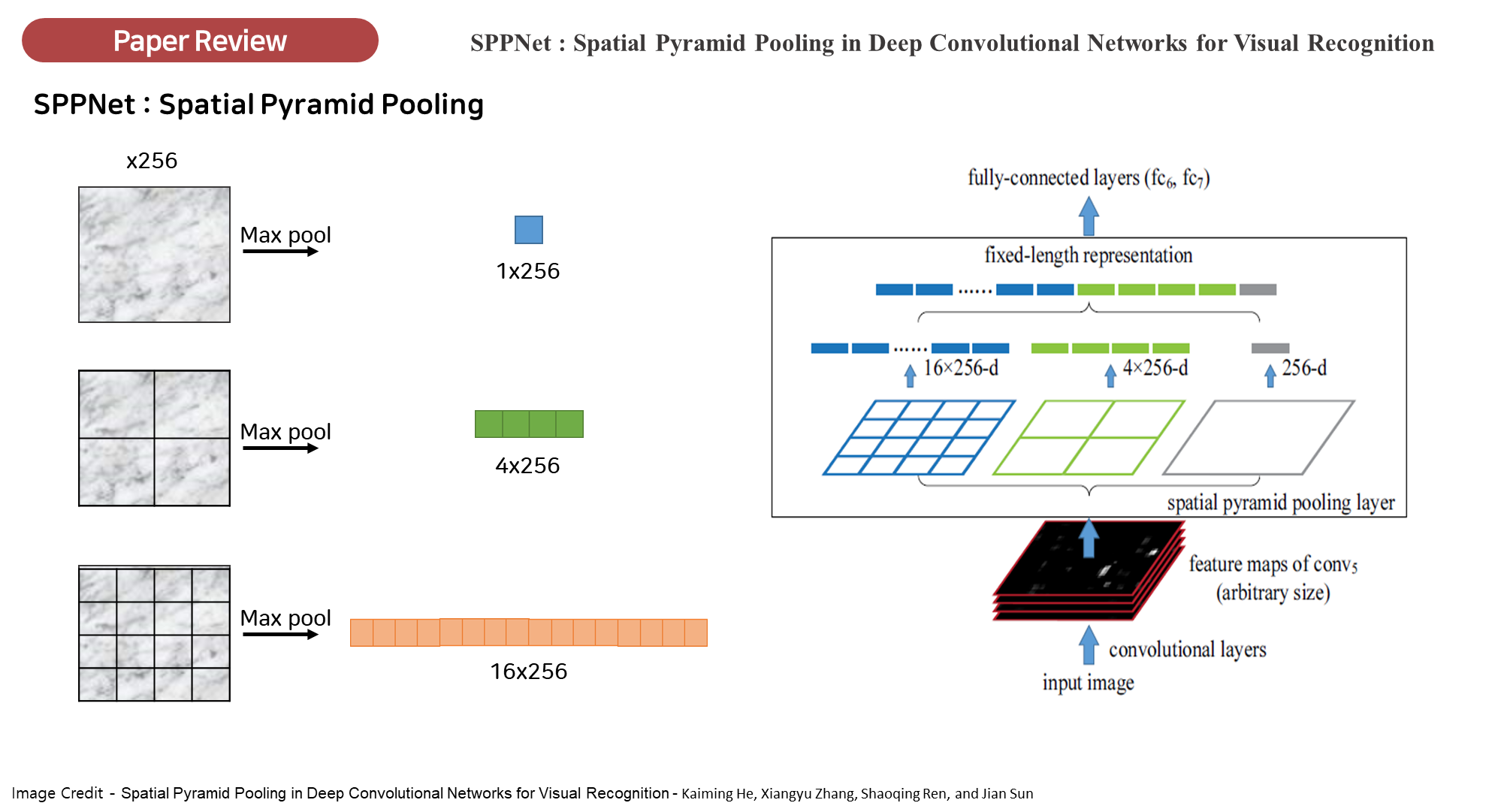
- 공간 피라미드 풀링(Spatial Pyramid Pooling, SPP)
- 해당 논문에서는 직접적인 언급은 없지만 "Predicting financial distress and corporate failure: A review from the state-of-the-art definitions, modeling, sampling, and featuring approaches" 논문에서는 YOLO-v3에 Spatial pyramid pooling (SPP)기법을 활용한 SPPBlock을 추가하려는 시도가 있었습니다.
- YOLOv3에 SPP(Spatial Pyramid Pooling) 기법을 추가하여, 다양한 크기의 맥스 풀링 연산을 통해 객체의 위치와 크기에 대한 더 넓은 수용 영역을 제공했습니다. 이는 보다 정확한 탐지를 가능하게 해주었으며, 특히 큰 객체에 대한 성능을 향상시켰습니다.
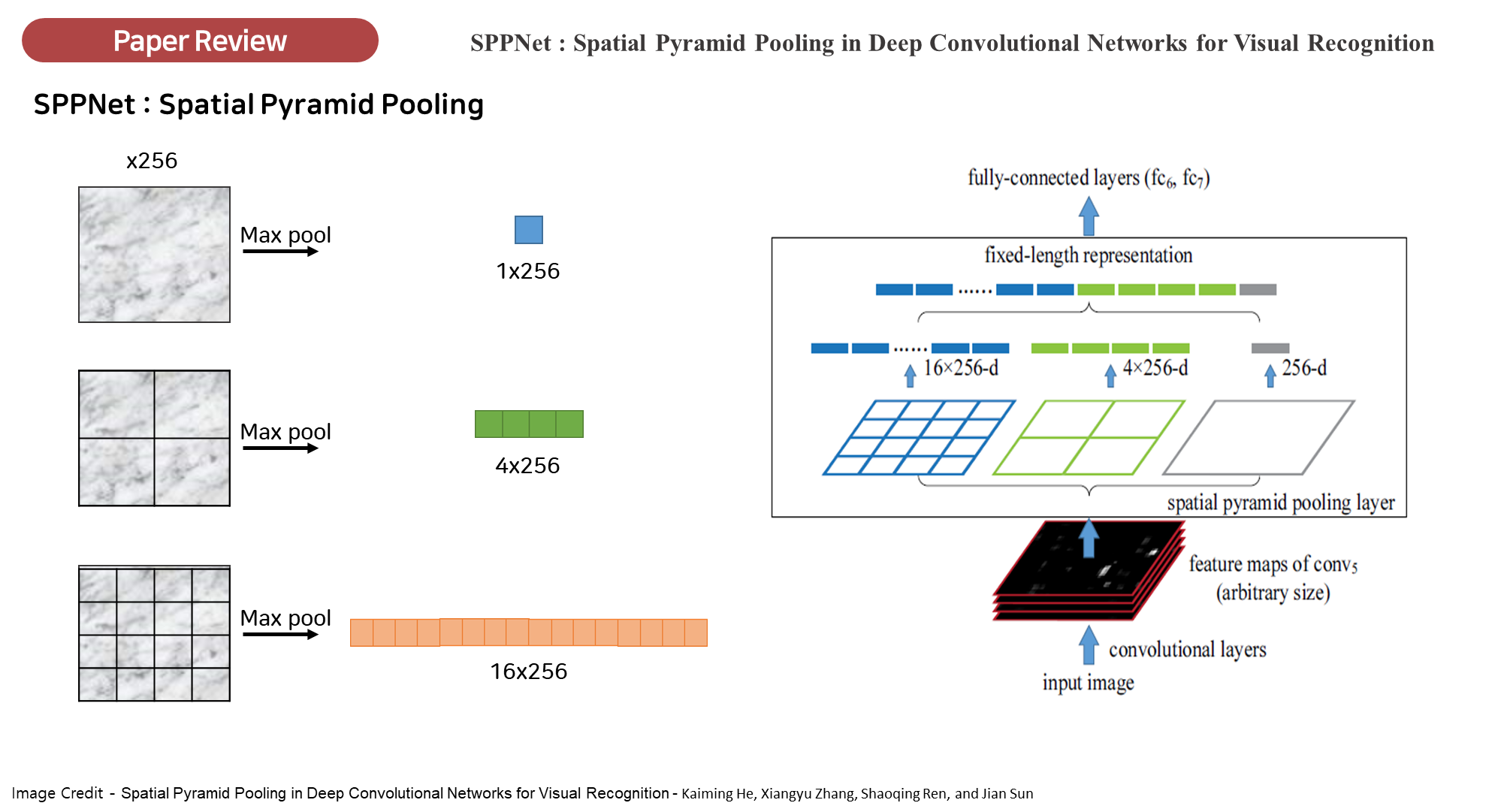
🔎 Spatial Pyramid Pooling(SPP)
다양한 크기의 입력 이미지를 고정된 크기로 변환하지 않고도 처리할 수 있게 해주는 기법입니다. SPP는 특히 다양한 스케일에서 추출된 피처를 병합하여 네트워크가 다양한 크기의 객체를 탐지하는 데 도움을 줍니다.
- 다양한 스케일의 피처맵: SPP는 이미지에서 다양한 스케일로 피처맵을 추출합니다.
- 예를 들어, 이미지를 1x1, 2x2, 4x4 크기의 풀링 윈도우로 나누어 각각 풀링을 수행하게 되면, 이미지의 크기와 상관없이 다양한 크기의 피처맵을 얻을 수 있습니다.
- 작은 윈도우는 세밀한 정보를, 큰 윈도우는 전체적인 정보를 담아냅니다.
- SPP 구조: 이미지가 다양한 크기의 영역으로 나뉘고, 각 영역에서 맥스 풀링(Max Pooling)이 수행됩니다. 이렇게 다양한 스케일로 얻어진 피처맵은 고정된 크기의 출력으로 변환되어 네트워크의 이후 단계에서 사용됩니다.
- 입력 크기 제약 제거: 일반적인 합성곱 신경망(CNN)은 입력 이미지 크기가 고정되어 있어야 하는데, SPP를 사용하면 입력 이미지의 크기를 고정할 필요 없이, 다양한 크기의 이미지를 네트워크에 입력할 수 있습니다. 이는 SPP가 다양한 스케일의 정보를 통합해 주기 때문입니다.
- 고정된 길이의 피처 벡터 생성: SPP는 다양한 크기의 입력 이미지로부터 고정된 크기의 피처 벡터를 생성하여, 후속 완전 연결 층(Fully Connected Layers)에서 처리할 수 있게 합니다. 이로 인해 네트워크의 유연성이 증가하며, 객체 탐지 성능이 향상됩니다.
(참고) Object Detection 유형
- 객체 탐지 모델은 두 가지 유형으로 크게 나뉩니다:
- 싱글 스테이지(single-stage) 객체 탐지기
- 투 스테이지(two-stage) 객체 탐지기.
이 두 가지 방식은 객체를 탐지하는 방법과 속도, 정확성 측면에서 중요한 차이를 보입니다.
1. 싱글 스테이지(Single-stage) 객체 탐지기
-
싱글 스테이지 객체 탐지기는 한 단계에서 객체의 위치(바운딩 박스)와 클래스 정보를 동시에 예측합니다.
- 대표적인 싱글 스테이지 모델로는 YOLO(You Only Look Once), SSD(Single Shot MultiBox Detector) 등이 있습니다.
-
주요 특징:
- 속도가 빠름: 한 번의 예측 과정에서 객체 탐지를 수행하기 때문에 매우 빠르며, 실시간 탐지가 가능합니다. 특히 YOLO는 이 속도 때문에 널리 사용됩니다.
- 단일 네트워크: 입력 이미지를 단일 합성곱 신경망(CNN)에 통과시켜 객체의 위치와 클래스 정보를 예측합니다.
- 밀집 예측(Dense Prediction): 이미지의 각 영역을 그리드 셀로 나누고, 각 셀에서 객체의 존재 여부와 바운딩 박스를 예측합니다.
- 이미지 전체를 그리드로 나누어 모든 그리드 셀이 객체를 탐지할 수 있는 가능성을 갖게 됩니다.
- 단일 단계 예측(One-step Prediction): 백본 네트워크를 통해 추출한 피처맵에서 바로 객체 위치와 클래스 예측이 이루어집니다. 이 과정에서 리전 제안(region proposals)이나 후속 단계가 필요 없습니다.
-
장점:
- 실시간 처리: 매우 빠르기 때문에 자율 주행, CCTV 모니터링 같은 실시간 애플리케이션에 적합합니다.
- 단순한 아키텍처: 네트워크가 단순하며, 학습이 빠릅니다.
-
단점:
- 정확도 낮음: 투 스테이지 방식에 비해 객체 탐지의 정확도가 다소 낮을 수 있습니다. 특히 작은 객체나 복잡한 배경에서의 탐지가 어려울 수 있습니다.
2. 투 스테이지(Two-stage) 객체 탐지기
-
투 스테이지 객체 탐지기는 객체 탐지를 두 단계로 나누어 처리합니다.
- 대표적인 투 스테이지 모델로는 Faster R-CNN과 R-CNN 계열이 있습니다.
-
주요 특징:
- 1단계 - 리전 제안(Region Proposal): 첫 번째 단계에서는 객체가 있을 만한 위치를 제안하는 영역(리전)을 생성합니다. 이 과정에서는 입력 이미지에서 객체가 있을 가능성이 높은 후보 영역을 찾습니다.
- 2단계 - 클래스 예측(Classification) 및 박스 조정(Bounding Box Regression): 두 번째 단계에서 제안된 영역을 바탕으로 객체의 정확한 위치(바운딩 박스)를 예측하고, 해당 객체가 어떤 클래스인지 분류합니다.
- 이 과정에서 RoI Pooling(Region of Interest Pooling)과 같은 기법을 통해 제안된 영역에서 고정된 크기의 피처맵을 추출하고, 이 피처맵을 활용해 객체를 분류하고 위치를 정확히 예측합니다.
-
장점:
- 높은 정확도: 두 단계로 나누어 탐지를 수행하므로, 작은 객체나 복잡한 배경에서도 높은 정확도를 유지할 수 있습니다.
- 세밀한 탐지: 리전 제안 단계에서 객체의 위치를 더 정확하게 좁힐 수 있어, 최종적으로 더 정교한 바운딩 박스를 얻을 수 있습니다.
-
단점:
- 속도가 느림: 리전 제안과 분류 단계가 분리되어 있어, 실시간 애플리케이션에는 적합하지 않습니다.
- 복잡한 아키텍처: 네트워크가 복잡하며, 훈련과 추론 속도가 느릴 수 있습니다.
(정리) 싱글 스테이지와 투 스테이지 모델 비교
| 특징 | 싱글 스테이지 | 투 스테이지 |
|---|---|---|
| 예시 모델 | YOLO, SSD | Faster R-CNN, Mask R-CNN |
| 속도 | 매우 빠름 (실시간 처리 가능) | 비교적 느림 (실시간 애플리케이션에 부적합) |
| 정확도 | 상대적으로 낮음 | 높은 정확도 |
| 단계 수 | 1단계로 객체 탐지 및 분류를 동시에 수행 | 2단계로 리전 제안 후 분류 및 바운딩 박스 |
| 구조 | 단순 | 복잡 |
| 용도 | 실시간 객체 탐지(예: 자율 주행, 보안) | 세밀한 객체 탐지(예: 의료 이미지 분석) |
8. Backbone, Neck, and Head
YOLO 모델의 성능을 이해하기 위해서는 객체 탐지에서 사용하는 네트워크 구조를 살펴봐야 하며, 이는 크게 Backbone(백본), Neck(넥), Head(헤드)로 나뉩니다.
- 이 구조는 YOLO뿐만 아니라 싱글 스테이지 객체 탐지 네트워크에서 공통적으로 사용되는 세 가지 주요 부분입니다.
- 이 세 가지 구성 요소는 각기 다른 역할을 수행하며, 함께 작동하여 최종적으로 객체를 탐지하고 위치를 예측합니다.
Backbone, Neck, Head의 각 구성 요소는 서로 상호작용하며 전체 모델의 성능에 중요한 역할을 합니다.
- Backbone은 이미지에서 유용한 특징을 추출하고,
- Neck은 이를 보강하여 다중 스케일의 객체에 대해 학습할 수 있게 하며,
- Head는 객체의 위치와 클래스를 예측하여 최종적인 탐지를 수행합니다.
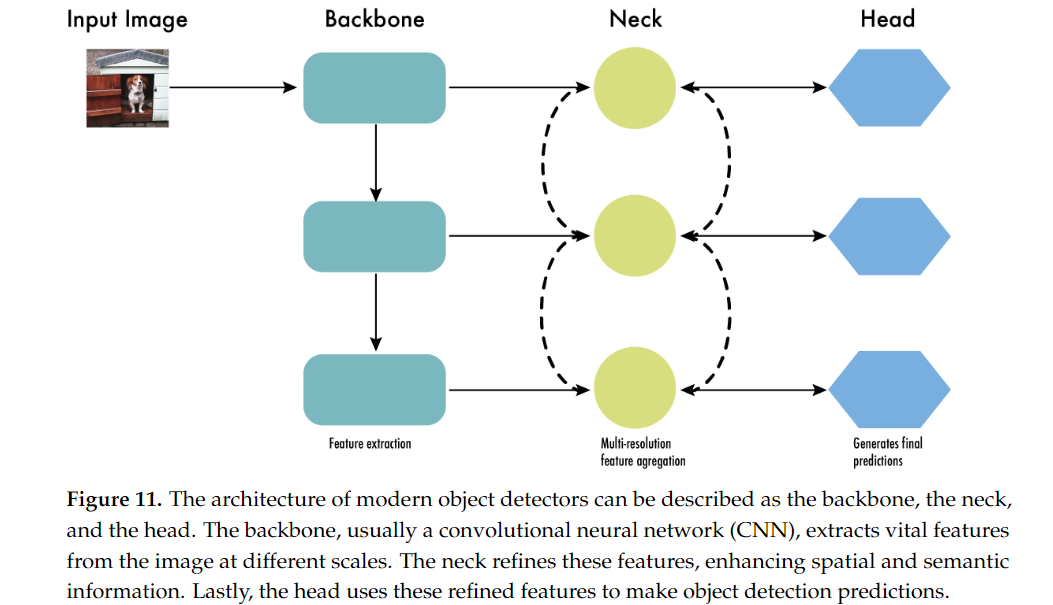
8.1 Backbone(백본)
Backbone(백본)은 YOLO와 같은 객체 탐지 모델의 첫 번째 부분으로, 입력 이미지에서 특징을 추출하는 역할을 합니다. 백본은 주로 합성곱 신경망(CNN)으로 구성되며, 다양한 크기의 특징 맵을 생성하여 이미지의 정보들을 추출합니다.
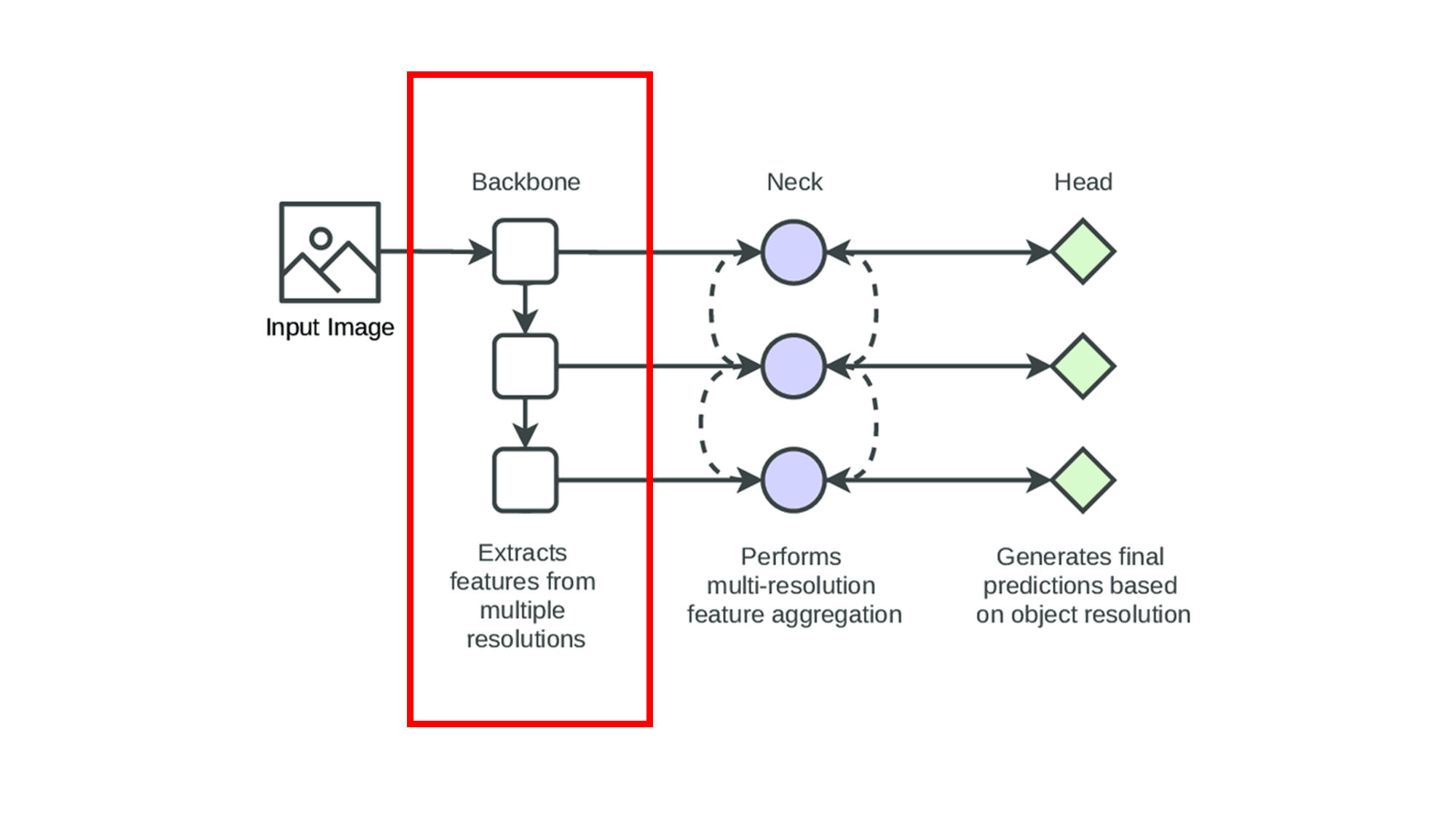
- YOLOv1의 Backbone: 초기 YOLOv1에서는 간단한 CNN 구조가 사용되었습니다. 하지만 네트워크가 상대적으로 얕고 단순했기 때문에 복잡한 장면이나 작은 객체를 탐지하는 데 한계가 있었습니다.
- Darknet Backbone: YOLOv2와 YOLOv3는 특징 추출을 위해 Darknet이라는 백본 네트워크를 도입했습니다. 특히 YOLOv3에서는 Darknet-53이 사용되었으며, 이 네트워크는 잔차 연결(residual connections)을 사용하여 깊은 계층에서도 학습이 잘 이루어지도록 설계되었습니다. Darknet-53은 53개의 합성곱 계층을 사용하여 매우 강력한 특징 추출 능력을 제공하며, 이미지의 다양한 세부 정보를 추출합니다.
8.2 Neck(넥)
Neck(넥)은 Backbone에서 추출된 특징을 Head로 전달하는 중간 역할을 하는 부분입니다. Neck은 특징의 공간적 및 의미적 정보를 보강하고 결합하여, 다양한 크기와 형태의 객체를 더 잘 탐지할 수 있도록 도와줍니다. 주로 Feature Pyramid Networks (FPN) 또는 Path Aggregation Networks (PAN) 같은 구조가 사용됩니다.
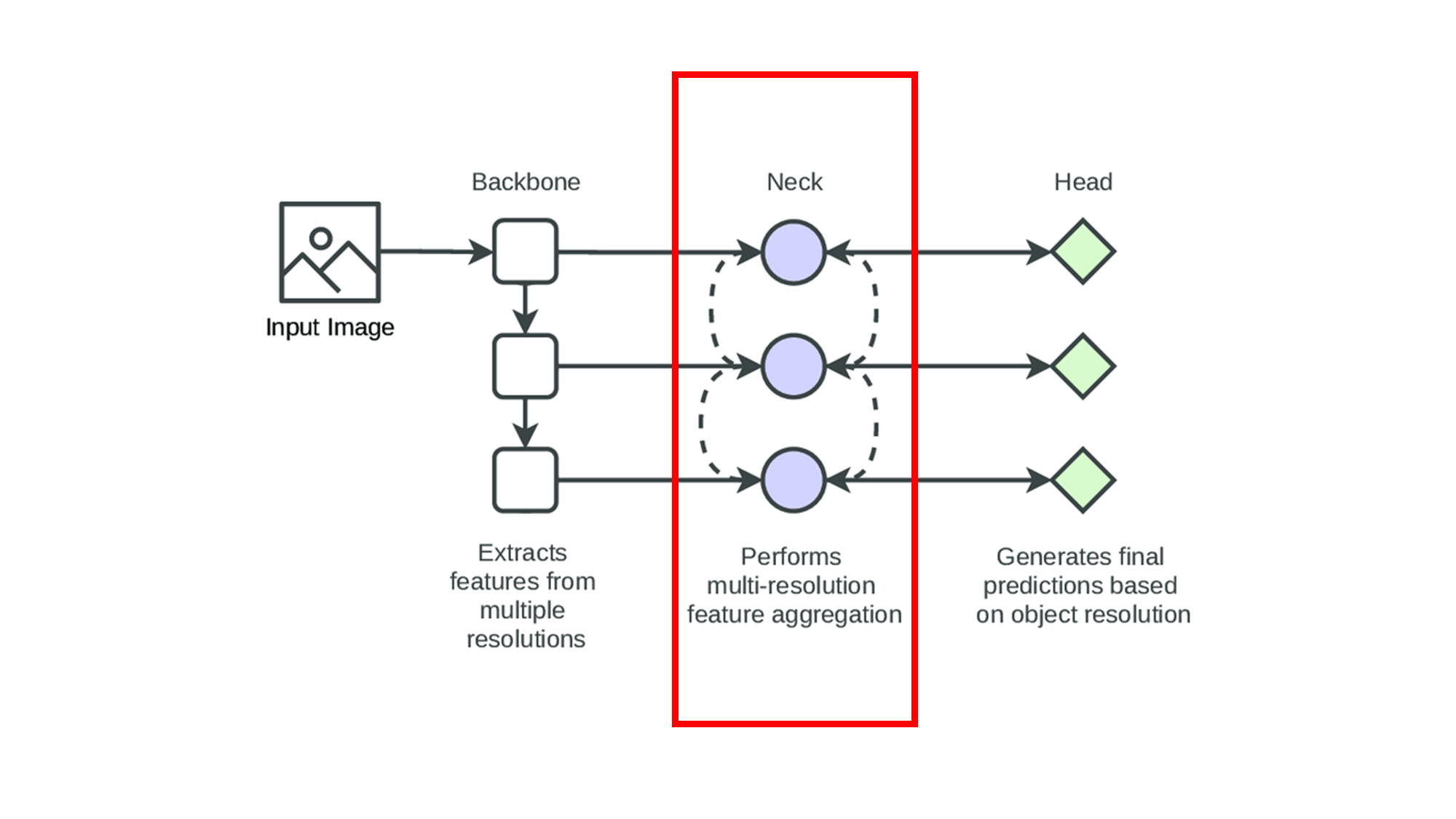
- Feature Pyramid Networks (FPN): FPN은 여러 해상도의 특징 맵을 결합하여, 객체의 크기에 상관없이 더 정확한 탐지가 가능하도록 합니다. FPN은 특히 다양한 크기의 객체가 혼재한 이미지에서 매우 유용하게 사용됩니다.
8.3 Head(헤드)
Head(헤드)는 최종적으로 객체를 탐지하고, 객체의 클래스와 위치를 예측하는 부분입니다. Head는 각 특징 맵에서 바운딩 박스 좌표(x, y, w, h)와 객체성(objectness) 점수, 클래스 확률을 예측합니다. 이때 비최대 억제(Non-Maximum Suppression, NMS)와 같은 후처리 기법을 사용하여 겹치는 바운딩 박스 중 가장 높은 신뢰도를 가진 박스만 남기게 됩니다.
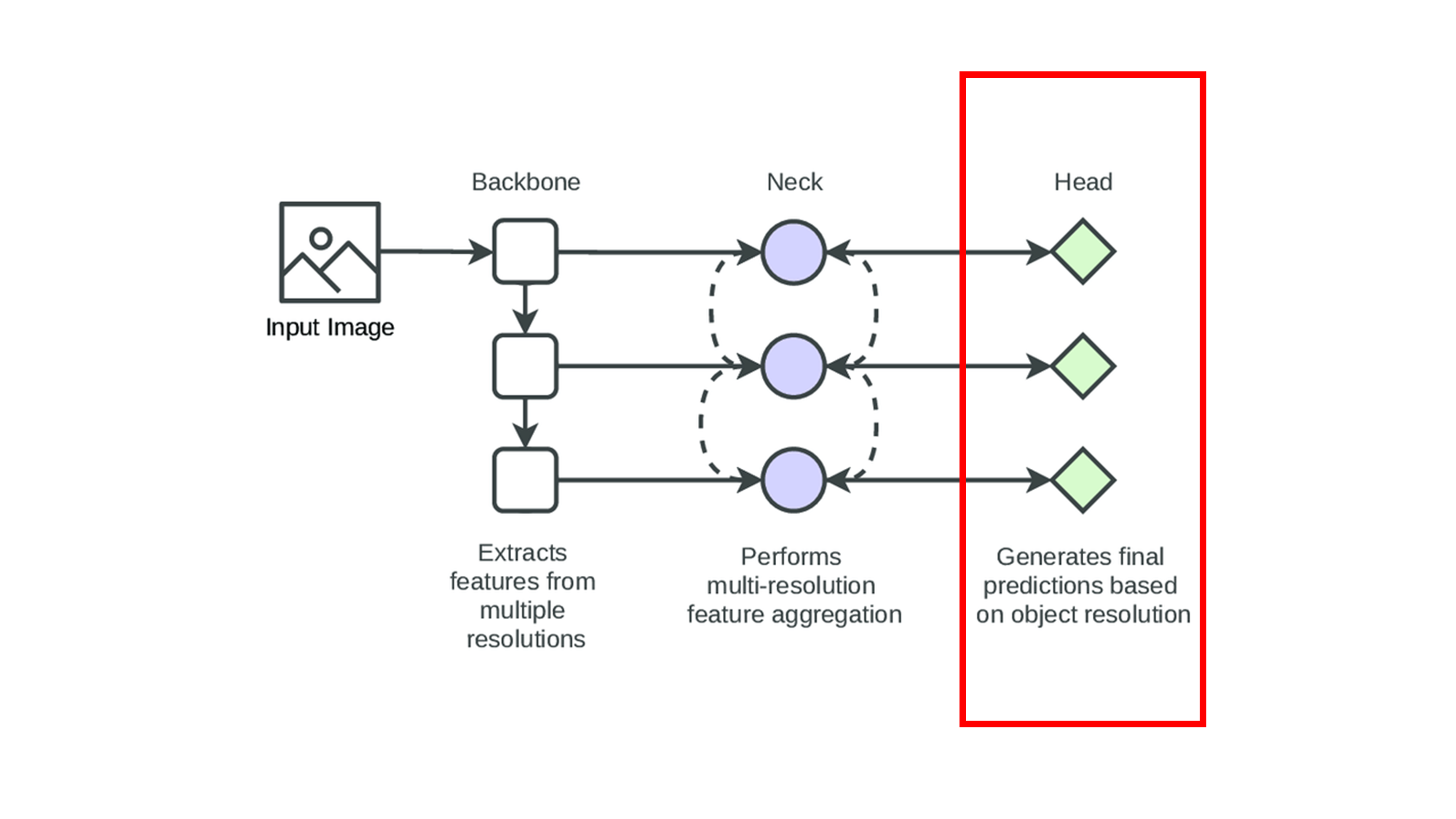
- YOLOv3의 Head: YOLOv3는 다중 스케일 예측을 사용하여 13×13, 26×26, 52×52 크기의 그리드에서 각각 다른 크기의 객체를 예측할 수 있었습니다. 이를 통해 큰 객체뿐만 아니라 작은 객체에 대한 탐지 성능도 크게 향상되었습니다.
9. YOLOv4 (2020년 4월)
YOLOv4는 2020년 Alexey Bochkovskiy, Chien-Yao Wang, 그리고 Hong-Yuan Mark Liao에 의해 발표된 모델로, YOLO 시리즈의 네 번째 버전입니다.
- YOLOv4는 YOLOv3의 성능을 개선하고, 더 빠르고 정확한 객체 탐지 모델을 만들기 위해 여러 가지 최신 기술을 도입하였습니다.
- 특히 YOLOv4는 실시간 객체 탐지에서 뛰어난 성능을 발휘하며, 연구자들과 엔지니어들에게 강력한 도구로 자리 잡았습니다.
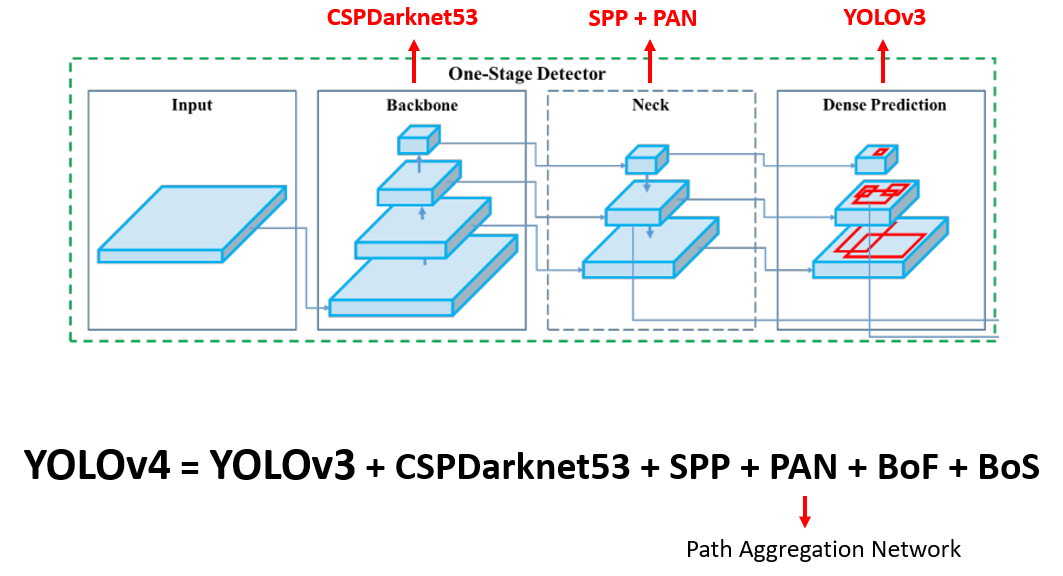
Bag of Freebies와 Bag of Specials는 YOLOv4 논문에서 소개된 두 가지 주요 개념으로, 각각 객체 탐지 모델의 성능을 향상시키는 다양한 기법들을 묶어서 설명하는 용어입니다.
이 두 개념의 차이는 모델 성능을 향상시키기 위해 "추론 과정에서 추가적인 계산 비용을 얼마나 요구하는가에 따라 구분"됩니다.
9.1 Bag of Freebies (BoF)
- 개념: Bag of Freebies는 추론(inference) 단계에서 추가적인 계산 비용을 요구하지 않고, 학습(training) 과정에서만 성능을 개선하는 기법들을 말합니다.

출처: https://hoya012.github.io/blog/yolov4/
-
컨셉: BoF는 학습 전략이나 데이터 증강 기법을 활용하여 모델의 학습 과정에서 객체 탐지 성능을 향상시키는 방법입니다.
- 이 기법들은 모델이 학습하는 동안만 추가적인 비용이 발생하고, 추론 시에는 성능 저하 없이 더 나은 정확도를 제공할 수 있습니다.
-
Mosaic data augmentation: 네 개의 이미지를 혼합하여 학습 데이터의 다양성을 높임으로써, 다양한 상황에서의 객체 탐지 성능을 향상시킵니다.
- 소개 시기: 2020년, YOLOv4 논문에서 처음 소개되었습니다.
- 개념:
- Mosaic은 네 개의 이미지를 혼합하여 하나의 새로운 이미지를 생성하는 데이터 증강 기법입니다.
- 세부 설명:
- Mosaic은 네 개의 서로 다른 이미지를 하나의 큰 이미지로 결합함으로써 네트워크가 객체를 다양한 배경, 위치, 비율에서 탐지할 수 있게 도와줍니다. 이를 통해 네트워크가 여러 상황에서도 성능이 유지되도록 만듭니다.

-
Self-Adversarial Training (SAT): 네트워크가 자기 자신을 공격하는 방식으로 학습하여 객체 탐지 성능을 향상시킵니다.
- 소개 시기: 2020년, YOLOv4 논문에서 처음 소개되었습니다.
- 개념: 네트워크가 자기 자신을 공격하는 방식으로 학습하는 기법입니다.
- 세부 설명:
- SAT는 네트워크가 처음에는 이미지를 변형시켜 마치 객체가 없는 것처럼 위장하고, 그런 후에 그 변형된 이미지에서 객체를 찾아내는 과정을 거칩니다. 이 과정은 두 단계로 이루어집니다:
- 첫 번째 단계에서 네트워크는 이미지를 변형하여 객체가 보이지 않도록 '자기 자신을 공격'합니다.
- 두 번째 단계에서는 변형된 이미지에서 객체를 다시 인식하게 합니다.
- 이 방법을 통해 네트워크는 더 강력한 방어력을 갖추게 되고, 노이즈가 많거나 객체가 위장된 이미지에서도 성능을 향상시킬 수 있습니다.

- CutMix: 이미지를 합성하여 학습에 사용, 객체를 더 효과적으로 인식할 수 있도록 도와줍니다.
- 소개 시기: 2019년, Yun, Sangdoo, et al., "CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features"
- 개념: 두 개의 이미지를 합성하여 하나의 이미지로 만드는 데이터 증강 기법입니다.
- 세부 설명:
- CutMix는 두 이미지를 선택한 후, 한 이미지의 특정 부분을 잘라 다른 이미지에 붙이는 방식으로 학습 데이터를 생성합니다.
- 이때 잘려진 부분에 해당하는 레이블도 섞여서 학습되며, 이를 통해 학습 모델이 객체의 일부분만으로도 해당 객체를 탐지할 수 있도록 도와줍니다.
- Mosaic과 차이점은 Mosaic은 네 개의 이미지를 결합하는 반면, CutMix는 두 개의 이미지를 섞습니다. 이 방식은 모델이 다양한 상황에서 객체를 더 잘 탐지할 수 있도록 해줍니다.

- CIoU loss: 객체 바운딩 박스 회귀를 최적화하는 손실 함수로, 바운딩 박스의 정확성을 향상시킵니다.
- 소개 시기: 2020년, Zheng, Zhishuai, et al., "Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression"
- 개념: 객체의 바운딩 박스 회귀(예측)를 최적화하는 손실 함수입니다.
- 세부 설명:
- 바운딩 박스(bounding box)는 객체의 위치를 네트워크가 예측할 때 사용하는 사각형입니다.
- CIoU Loss는 바운딩 박스의 정확성을 향상시키기 위한 손실 함수입니다. 기존의 IoU (Intersection over Union) 손실 함수는 두 박스가 얼마나 겹치는지를 계산하지만, CIoU는 겹치는 면적뿐만 아니라, 중심점의 거리와 가로세로 비율까지 고려합니다.
- 즉, 객체와 예측된 바운딩 박스 간의 중첩 정도뿐만 아니라, 두 상자의 중심 간 거리와 상자의 가로세로 비율도 고려함으로써 더 정확한 예측을 할 수 있게 돕습니다.
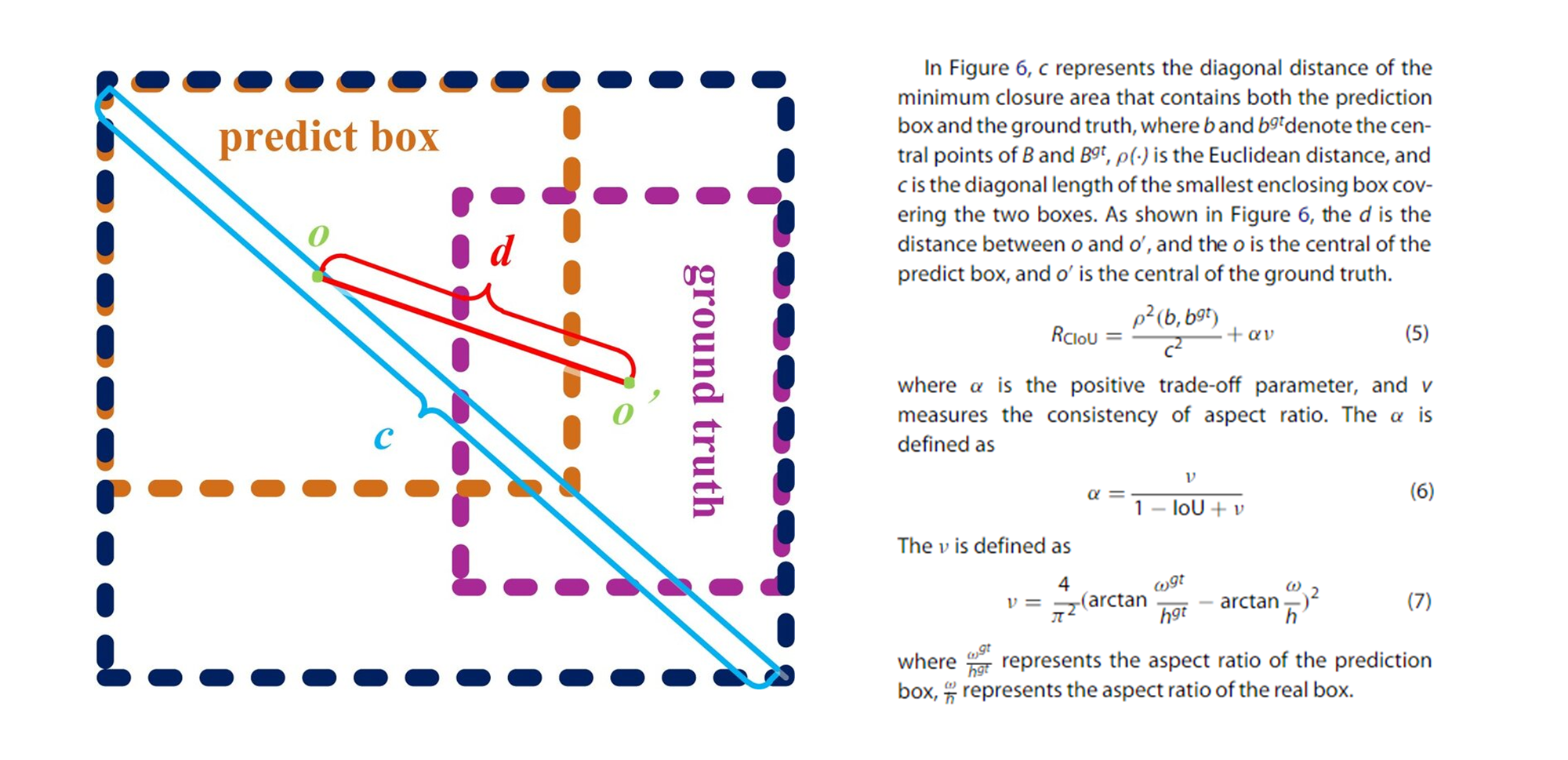
출처: An improved Tiny YOLOv3 for real-time object detection
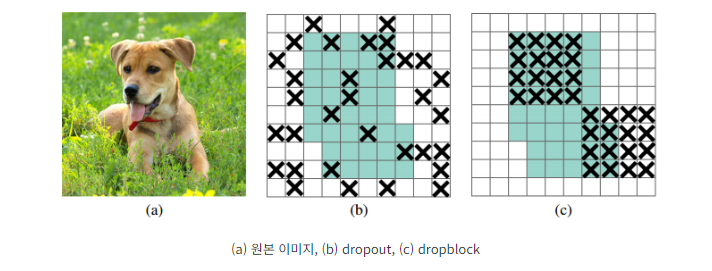
- DropBlock regularization: 과적합을 방지하기 위한 정규화 기법입니다.
- 소개 시기: 2018년, Ghiasi, Golnaz, Tsung-Yi Lin, and Quoc V. Le, "DropBlock: A Regularization Method for Convolutional Networks"
- 개념: 과적합을 방지하기 위한 정규화 기법입니다.
- 세부 설명:
DropBlock은 Dropout의 확장된 형태로, 연속적인 영역을 비활성화하는 방식입니다. Dropout은 임의의 개별 뉴런을 비활성화하지만, DropBlock은 피처 맵에서 연속된 영역(정사각형 블록)을 차단하여 네트워크가 특정 세부 정보에 의존하지 않도록 합니다.- DropBlock은 피처 맵의 일정 영역을 무작위로 제거함으로써 과적합을 줄이고, 네트워크가 전체 이미지에 대해 더 일반화된 학습을 하도록 유도합니다.
9.2 Bag of Specials (BoS)
- 개념: Bag of Specials는 추론(inference) 과정에서도 추가적인 계산 비용을 요구하지만, 그럼에도 불구하고 성능 향상에 중요한 기여를 하는 기법들을 말합니다.
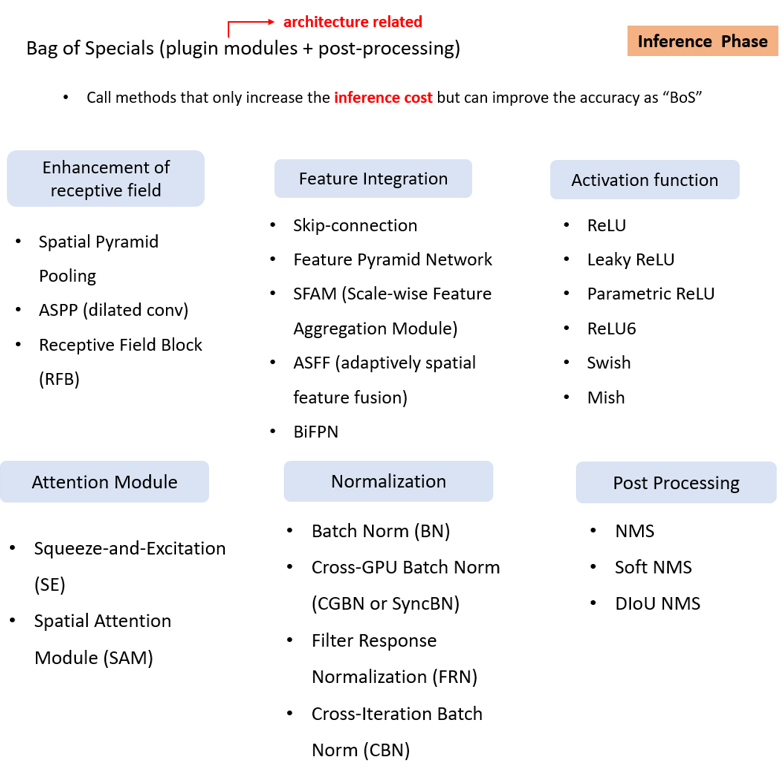
출처: https://hoya012.github.io/blog/yolov4/
-
컨셉: BoS는 추론 단계에서 모델 성능을 높이기 위해서 일부 계산 비용을 추가적으로 지불해야 하는 방법들입니다.
- 이러한 기법들은 모델이 더 복잡한 구조를 가지도록 하거나, 보다 세밀한 정보를 처리할 수 있게 도와줍니다.
-
Mish activation: 스무스하게 미분 가능한 활성화 함수로, 성능을 높이면서도 계산 복잡성을 크게 늘리지 않습니다.
- 소개 시기: 2019년, Diganta Misra, "Mish: A Self Regularized Non-Monotonic Neural Activation Function"
- 개념: 신경망에서 더 나은 성능을 제공하는 스무스하게 미분 가능한 활성화 함수입니다.
- 세부 설명:
- Mish는 최근 제안된 활성화 함수로, 기존 ReLU 함수보다 성능이 뛰어난 것으로 알려져 있습니다.
- Mish는 tanh와 softplus 함수가 결합된 형태로, ReLU와 달리 음수 구간에서도 정보가 유지됩니다. 이를 통해 더 부드러운 그래디언트 흐름을 만들어 네트워크가 더 잘 학습할 수 있도록 돕습니다.
- Mish 활성화 함수의 수식은 다음과 같습니다:
- 여기서 softplus 함수는 다음과 같이 정의됩니다:
- Mish는 네트워크의 학습 속도를 크게 늦추지 않으면서도 성능을 높이는 특징을 가지고 있습니다.
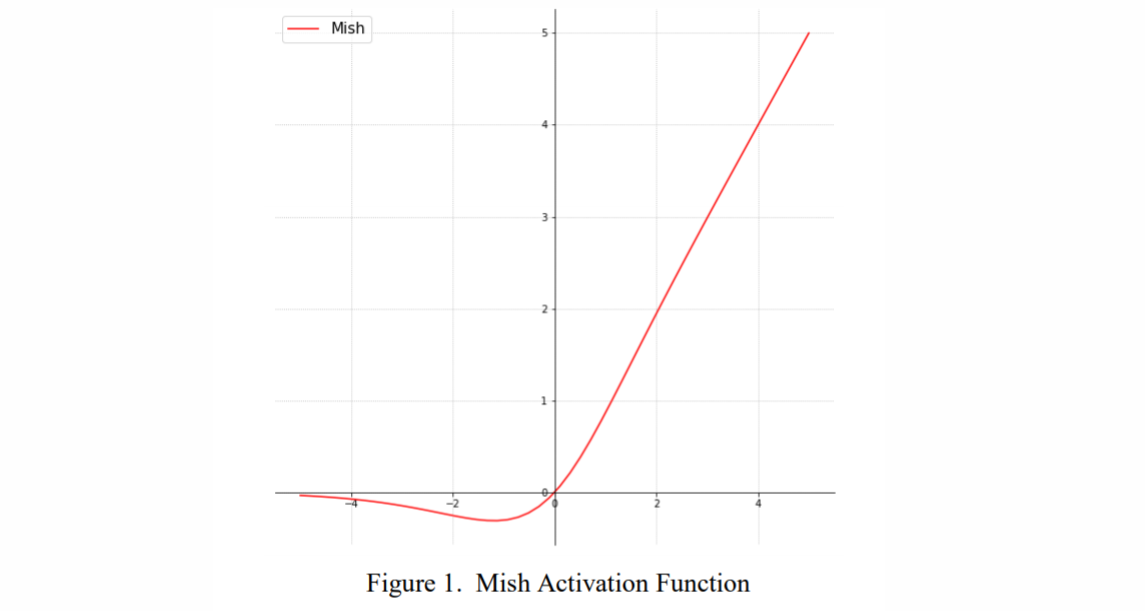
-
Cross-Stage Partial connections (CSP): 피처 맵을 두 부분으로 나눠 연산하여 중복된 그라디언트 정보를 줄이고 연산 효율을 높입니다.
- 소개 시기: 2019년, Wang, Chien-Yao, et al., "CSPNet: A New Backbone That Can Enhance Learning Capability of CNN"
- 개념: 피처 맵을 두 부분으로 나누어 중복된 그라디언트 정보를 줄이고 연산 효율성을 높이는 기법입니다.
- 세부 설명:
- CSPNet은 네트워크가 동일한 정보로 여러 번 학습하는 문제(중복 그라디언트)를 방지하기 위해 피처 맵을 두 부분으로 나누어 처리하는 기법입니다.
- 한 부분은 Dense Block과 같은 연산을 거치고, 다른 부분은 바로 다음 단계로 전달되어, 불필요한 계산을 줄이면서도 성능을 유지할 수 있게 합니다.
- YOLOv4에서는 CSP를 적용하여 네트워크의 연산 효율성을 극대화하고 메모리 사용량을 줄입니다.
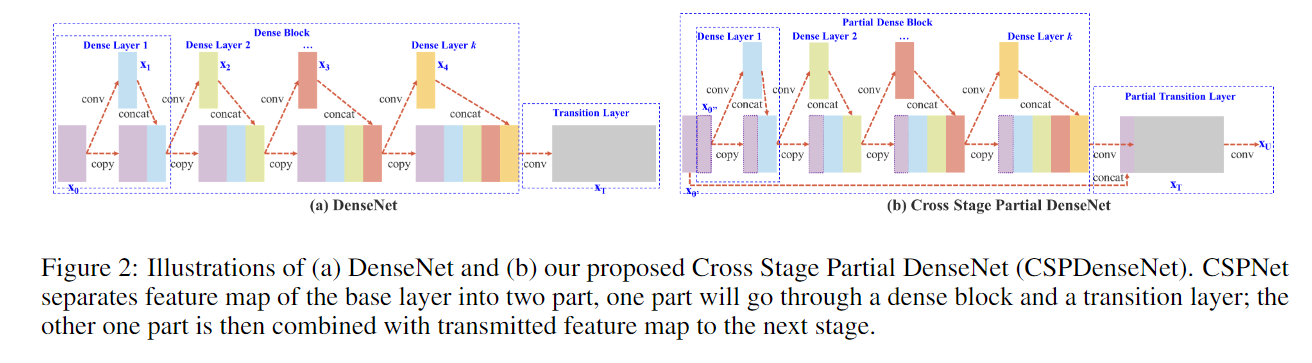
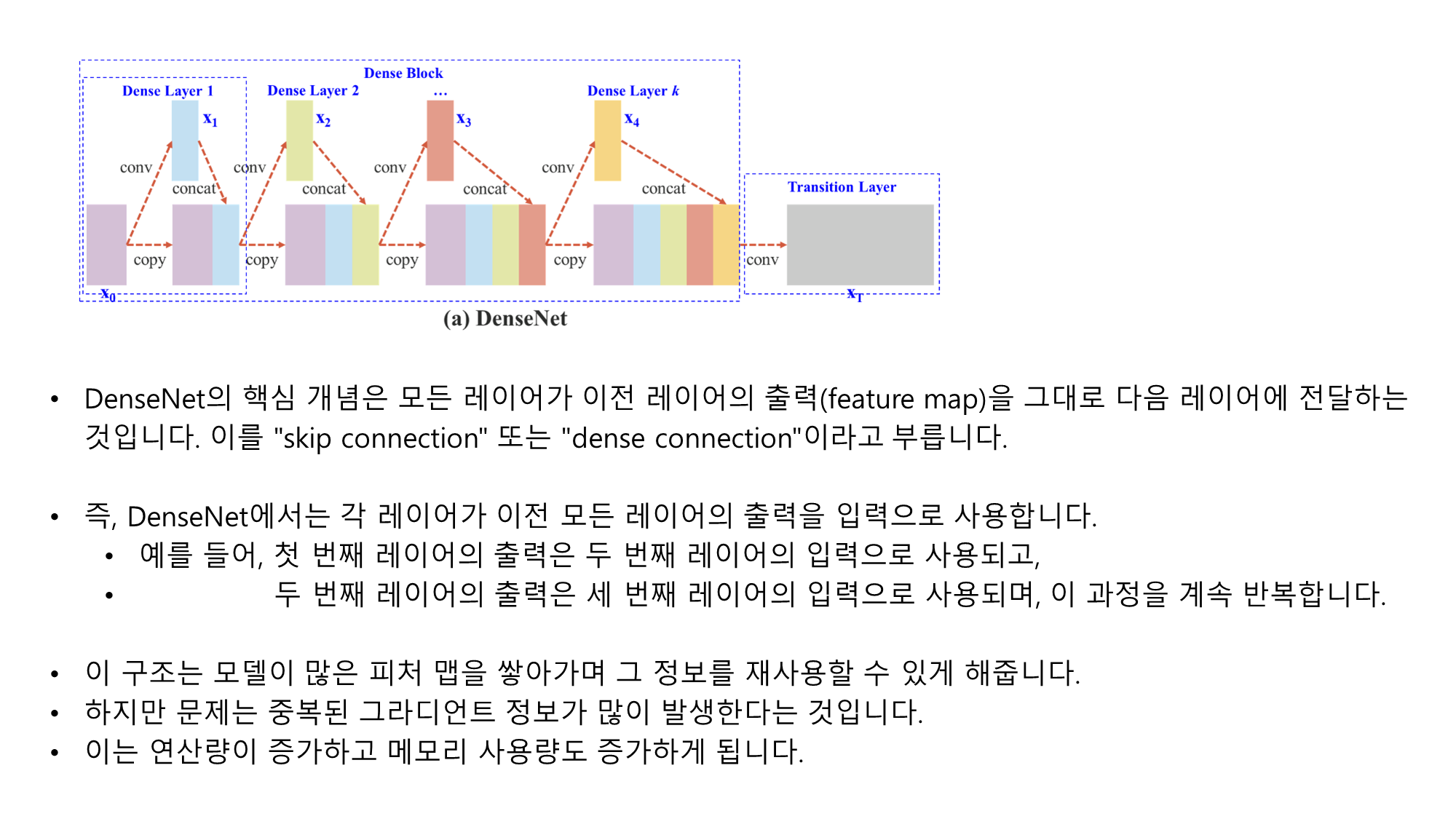
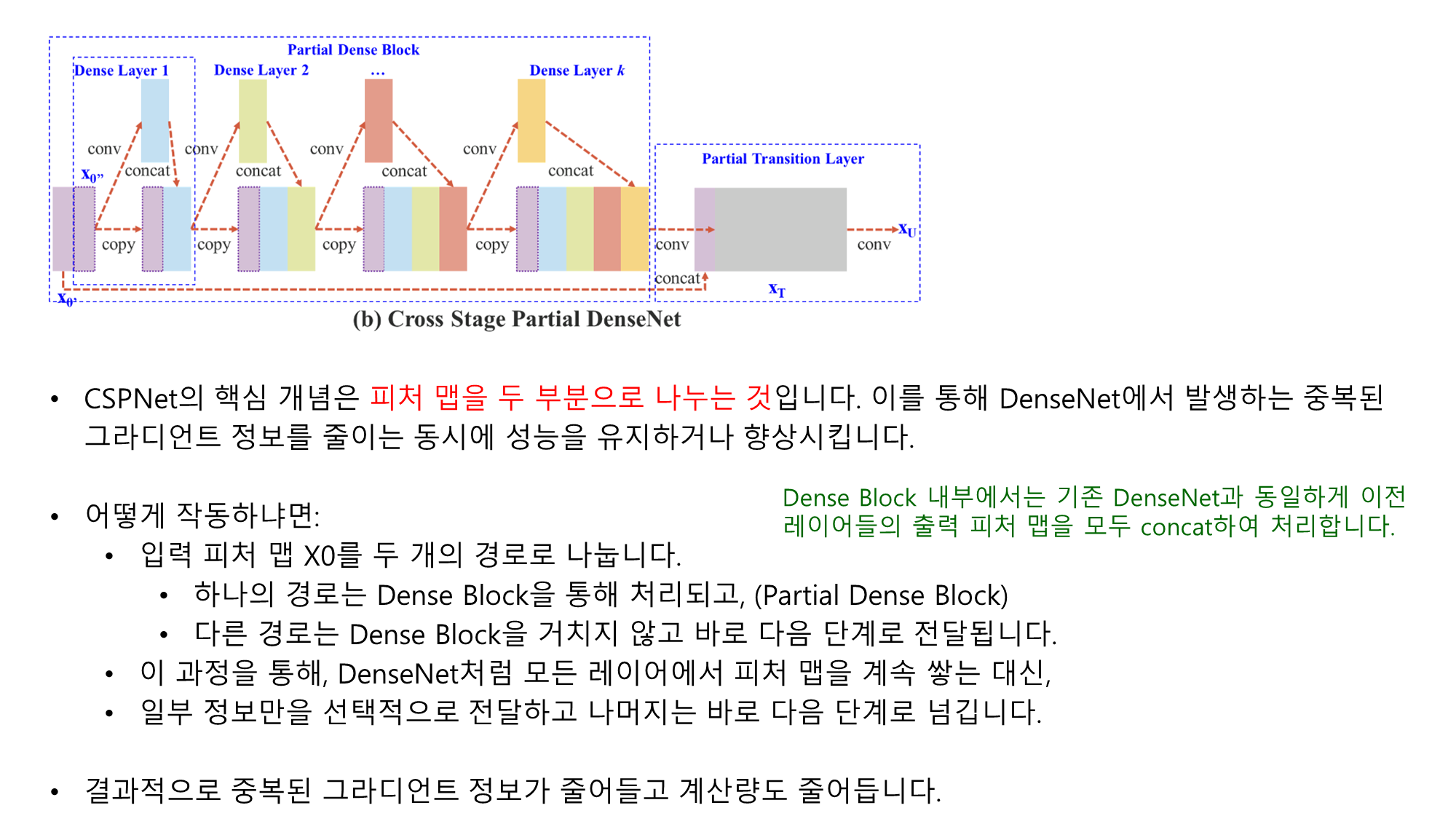
- 위 그림을 보면 CSPDenseNet 구조가 어떻게 작동하는지 설명할 수 있습니다. CSPNet이 연산량을 줄이고 학습 능력을 유지하는 방법은 다음과 같은 주요 개념에 기반합니다:
- Figure 2 (a) DenseNet에서는 각 층에서 생성된 피처 맵(feature map)이 다음 층으로 전부 전달됩니다. 이 과정에서 피처 맵이 중복적으로 결합되고, 그로 인해 중복된 그라디언트 정보가 생성될 수 있습니다.
- Figure 2 (b) CSPDenseNet에서는 피처 맵을 두 부분으로 나누어 처리합니다. 한 부분은 Dense Block을 통해 연산을 거치고, 다른 부분은 이를 통과하지 않고 바로 다음 단계로 전달됩니다. 이로써 중복된 그라디언트 정보를 방지하고 연산량을 줄이게 됩니다.
-
Spatial Pyramid Pooling (SPP): 객체의 다양한 크기를 효과적으로 처리하기 위해, 피처 맵의 수용 영역을 확장합니다.
- 소개 시기: 2014년, He, Kaiming, et al., "Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition"
- 개념: 객체의 다양한 크기와 비율을 처리하기 위해 피처 맵의 수용 영역을 확장하는 기법입니다.
- 세부 설명:
- SPP는 입력 이미지의 크기가 다를 때도 고정된 크기의 출력을 얻기 위해 사용됩니다. 이는 객체가 이미지 내에서 차지하는 공간이 다를 경우에도 동일하게 처리할 수 있도록 돕습니다.
- SPP는 여러 크기의 풀링 레이어를 사용하여 피처 맵의 다양한 영역을 고려한 정보를 추출합니다. 이를 통해 네트워크가 여러 크기의 객체를 더 잘 인식할 수 있게 합니다.
-
Path Aggregation Network (PAN): 피처 맵을 효율적으로 결합하여 객체 탐지 성능을 높이는 목적으로 사용됩니다.
-
소개 시기: 2018년, Liu, Shuyang, et al., "Path Aggregation Network for Instance Segmentation"
-
개념: 피처 맵을 결합하여 객체 탐지 성능을 높이는 네트워크 구조입니다.
-
세부 설명:
-
Path Aggregation이라는 이름은 여러 경로를 통해 전파되는 정보를 효율적으로 결합하여, 객체 탐지나 인스턴스 세그멘테이션 성능을 극대화하는 구조라는 것을 나타냅니다.
-
특히, 기존의 단일 경로(top-down 방식)에서 벗어나 다양한 경로들(위에서 아래로, 아래에서 위로)에서 정보를 모으는 방식을 강조합니다. 이를 통해, 네트워크가 객체의 세부적인 위치 정보만 아니라 큰 맥락 정보도 동시에 학습할 수 있도록 합니다.
-
즉, PANet이라는 이름은 네트워크가 다양한 정보 경로를 활용하여 더 정확하고 풍부한 피처를 결합하는 방식을 나타내는 것으로, 이는 아래 기법들을 포함하고 있습니다:
Bottom-up Path Augmentation: 저수준 피처에서 상위 레벨로 정보가 효율적으로 전달되도록 함.Adaptive Feature Pooling: 객체 크기와 상관없이 여러 피처 레벨에서 정보를 통합.Fully-connected Fusion: 마스크 예측 시 다양한 뷰를 결합하여 예측 성능 향상.
-
-
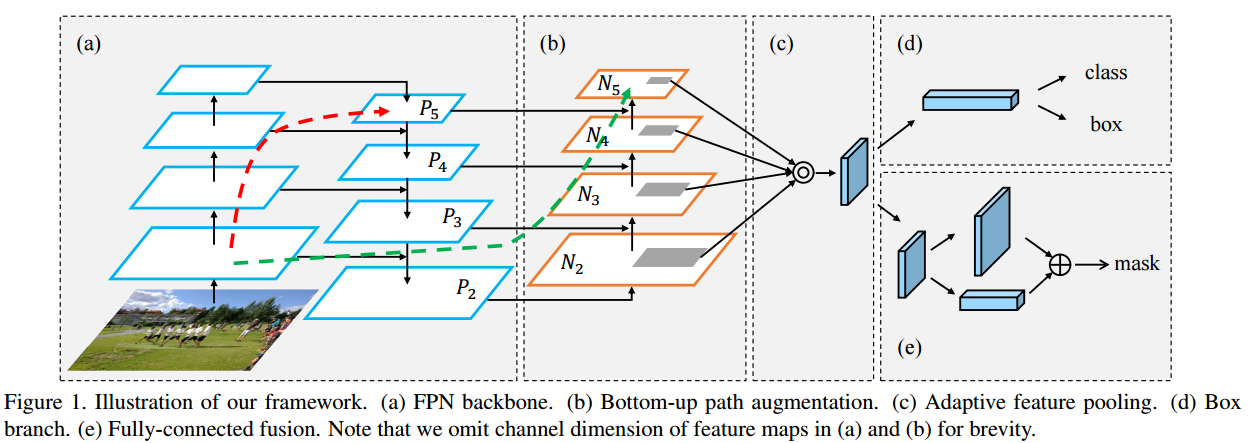
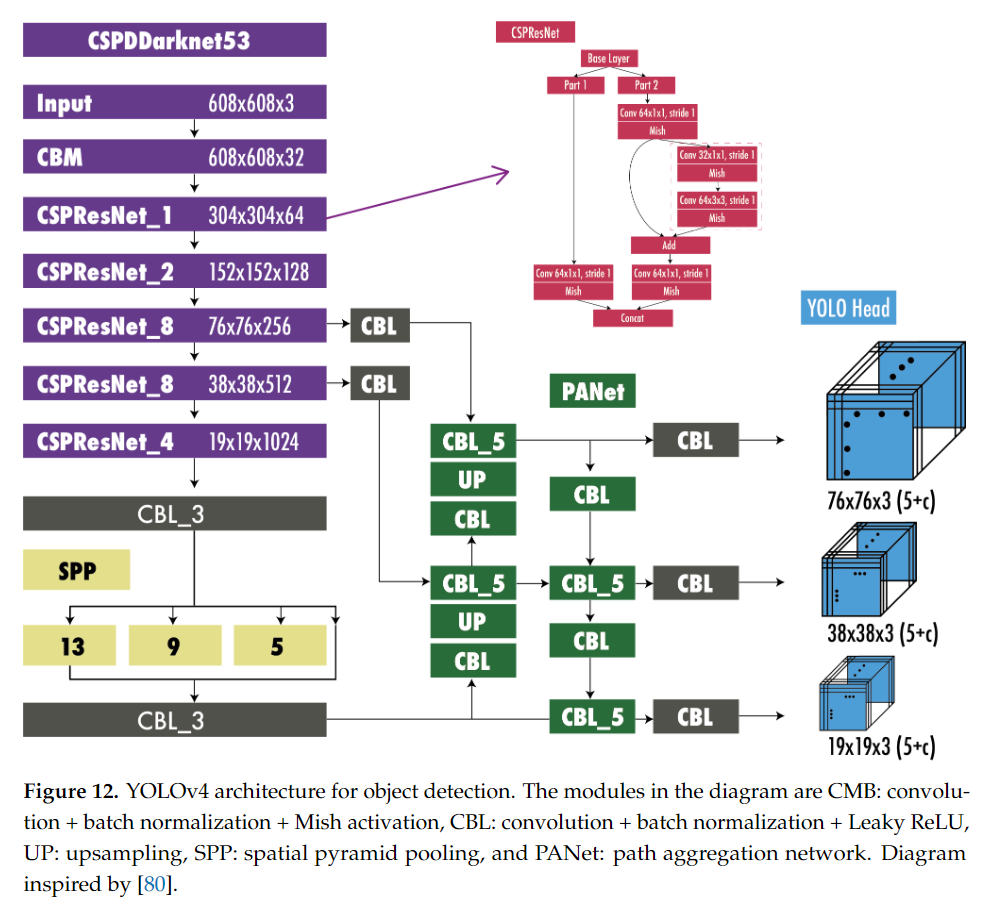
9.2 YOLOv4의 구조
위에서 소개한 각각의 구조들을 활용하여 Backbone, Neck, Head를 구성합니다:
-
Backbone: CSPDarknet53을 사용하여 강력한 피처 추출을 수행합니다.
-
Neck: SPP와 PAN을 사용하여 여러 피처 맵을 효과적으로 결합하고 객체의 다양한 크기와 위치에 대응합니다.
-
Head: 기존 YOLOv3의 anchor 기반 출력 구조를 사용하여 객체의 바운딩 박스와 클래스를 예측합니다.
10. YOLOv5 (2020년 6월)
YOLOv5는 2020년 Ultralytics에서 발표된 YOLO 시리즈의 다섯 번째 버전입니다. YOLOv5는 YOLOv4에서 이어지는 모델이지만, YOLOv4와는 달리 PyTorch 프레임워크로 처음부터 구현되었으며, 개발자들이 손쉽게 사용할 수 있는 사용자 친화적인 구조를 제공합니다. YOLOv5는 특히 경량화된 구조와 다양한 크기의 모델을 제공하여 성능과 사용 편의성 측면에서 큰 인기를 얻었습니다.
10.1 YOLOv5의 주요 특징
-
PyTorch 기반 구현
- YOLOv5는 PyTorch 프레임워크를 사용하여 구현되었기 때문에, 연구자들과 개발자들이 모델을 쉽게 수정하고 실험할 수 있게 되었습니다.
- YOLOv4는 Darknet으로 구현되었지만, YOLOv5는 PyTorch의 풍부한 생태계를 활용해 모델을 더 간편하게 다루고 확장할 수 있는 장점이 있습니다.
-
다양한 크기의 모델 제공
- YOLOv5는 모델 크기에 따라 YOLOv5n (nano), YOLOv5s (small), YOLOv5m (medium), YOLOv5l (large), YOLOv5x (extra-large)의 다섯 가지 버전을 제공합니다.
- 이는 사용자가 속도와 정확도 간의 트레이드오프를 조절할 수 있도록 해주며, 작은 버전은 임베디드 시스템이나 모바일 장치에서도 사용할 수 있을 정도로 경량화되었습니다.
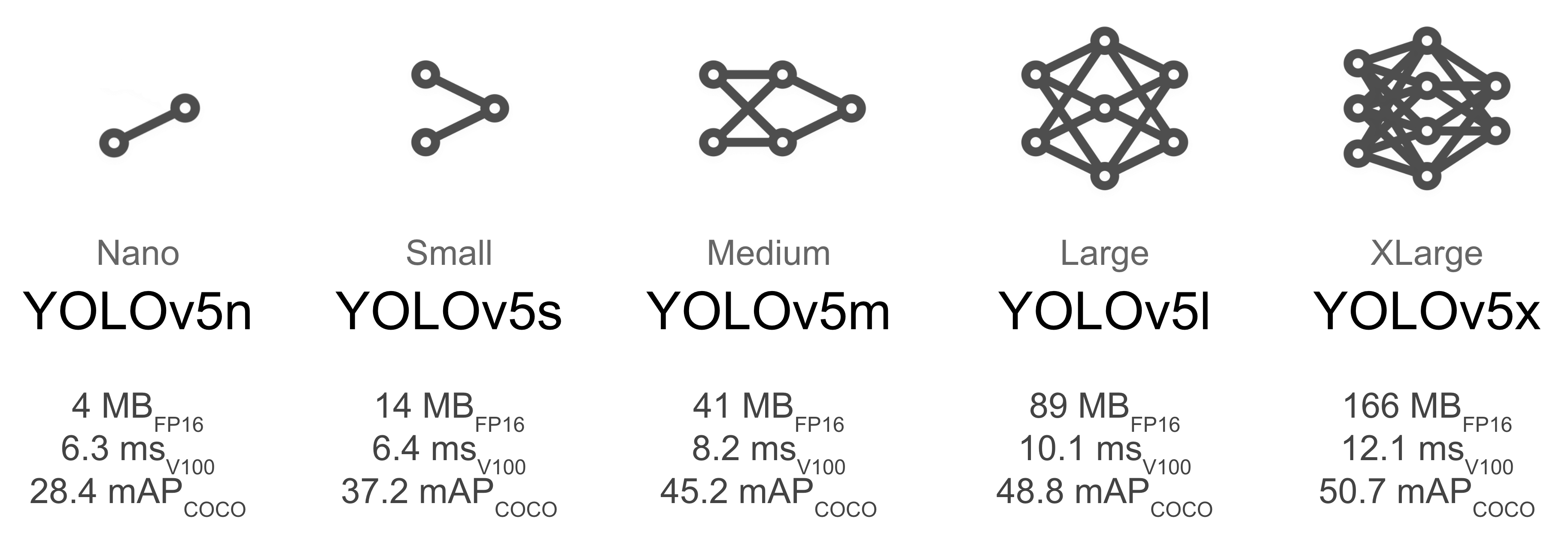
출처: https://pytorch.kr/hub/ultralytics_yolov5/
- AutoAnchor 및 AutoBatch
YOLOv5는 AutoAnchor와 AutoBatch 기능을 도입하여 사용자가 모델을 더 쉽게 조정할 수 있게 했습니다.
AutoAnchor
- 정의: AutoAnchor는 최적의 앵커 박스를 자동으로 생성하는 알고리즘입니다.
- YOLOv5에서 앵커 박스는 객체의 크기와 비율을 모델링하는 데 사용됩니다.
- 작동 원리:
데이터 기반: AutoAnchor는 주어진 데이터셋을 분석하여 객체의 크기 및 비율에 맞는 최적의 앵커 박스를 생성합니다.K-평균 클러스터링: AutoAnchor는 K-평균 알고리즘을 이용하여 데이터셋에서 이미지를 분석하고, 그에 따라 초기 앵커 박스를 설정합니다.진화 알고리즘: 이후, 이 초기 앵커 박스는 유전자 알고리즘(GA)을 통해 세대를 거치며 진화하여, 객체 감지 성능을 극대화합니다.
AutoBatch
- 정의: AutoBatch는 훈련 과정에서 배치 크기를 자동으로 조정하여 더욱 효율적으로 모델을 훈련할 수 있게 돕는 기능입니다.
- 작동 원리:
하드웨어 감지: AutoBatch는 GPU 메모리의 사용 현황을 실시간으로 감지하여, 그에 맞게 배치 크기를 조정합니다.동적 조정: 훈련중에 GPU 메모리에 여유가 남아있으면 배치 크기를 늘릴 수 있는 방식을 통해, 최대한의 자원을 활용합니다.
- 데이터 증강(Data Augmentation)
- YOLOv5는 YOLOv4에서 도입된 Mosaic, copy paste, MixUp, random affine, HSV 증강 등과 같은 데이터 증강 기법을 활용하여 학습 데이터를 풍부하게 만들고, 모델의 일반화 성능을 높였습니다. 이를 통해 모델은 다양한 배경과 조명 조건에서 객체를 더 잘 탐지할 수 있게 되었습니다.
-
Mosaic data augmentation: 네 개의 이미지를 혼합하여 학습 데이터의 다양성을 높임으로써, 다양한 상황에서의 객체 탐지 성능을 향상시킵니다.
- 소개 시기: 2020년, YOLOv4 논문에서 처음 소개되었습니다.
- 개념:
- Mosaic은 네 개의 이미지를 혼합하여 하나의 새로운 이미지를 생성하는 데이터 증강 기법입니다.
- 세부 설명:
- Mosaic은 네 개의 서로 다른 이미지를 하나의 큰 이미지로 결합함으로써 네트워크가 객체를 다양한 배경, 위치, 비율에서 탐지할 수 있게 도와줍니다. 이를 통해 네트워크가 여러 상황에서도 성능이 유지되도록 만듭니다.
-
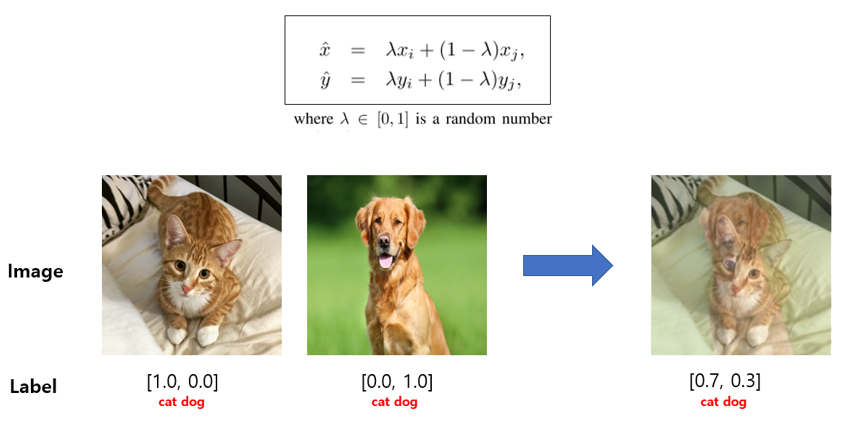
Mixup data augmentation: 두 개의 이미지를 선형 결합하여 새로운 학습 샘플을 생성하는 데이터 증강 기법입니다.
- 소개 시기: 2018년, Zhang, Hongyi, et al., "Mixup: Beyond Empirical Risk Minimization"
- 개념:
- Mixup 기법은 기존 이미지와 레이블을 섞어 새로운 이미지를 만들고, 레이블도 두 이미지의 비율에 맞게 섞어서 새로운 레이블을 생성합니다.
- 세부 설명:
- MixUp은 단순히 두 이미지를 더해서 새로운 이미지를 생성하는 방식입니다. 이때, 두 이미지 간의 가중치를 랜덤하게 설정하여 두 이미지를 선형 결합합니다.
- 이미지 뿐만 아니라 레이블 역시 선형 결합하여, 소프트 라벨을 생성하게 됩니다. 이를 통해 모델이 객체 분류나 탐지 시 하나의 정답만을 고집하지 않고, 더 일반화된 성능을 발휘할 수 있도록 도와줍니다.
- MixUp은 과적합 방지, 모델의 일반화 성능 향상 및 노이즈에 대한 강건함 강화 등의 장점을 가지고 있습니다.
-
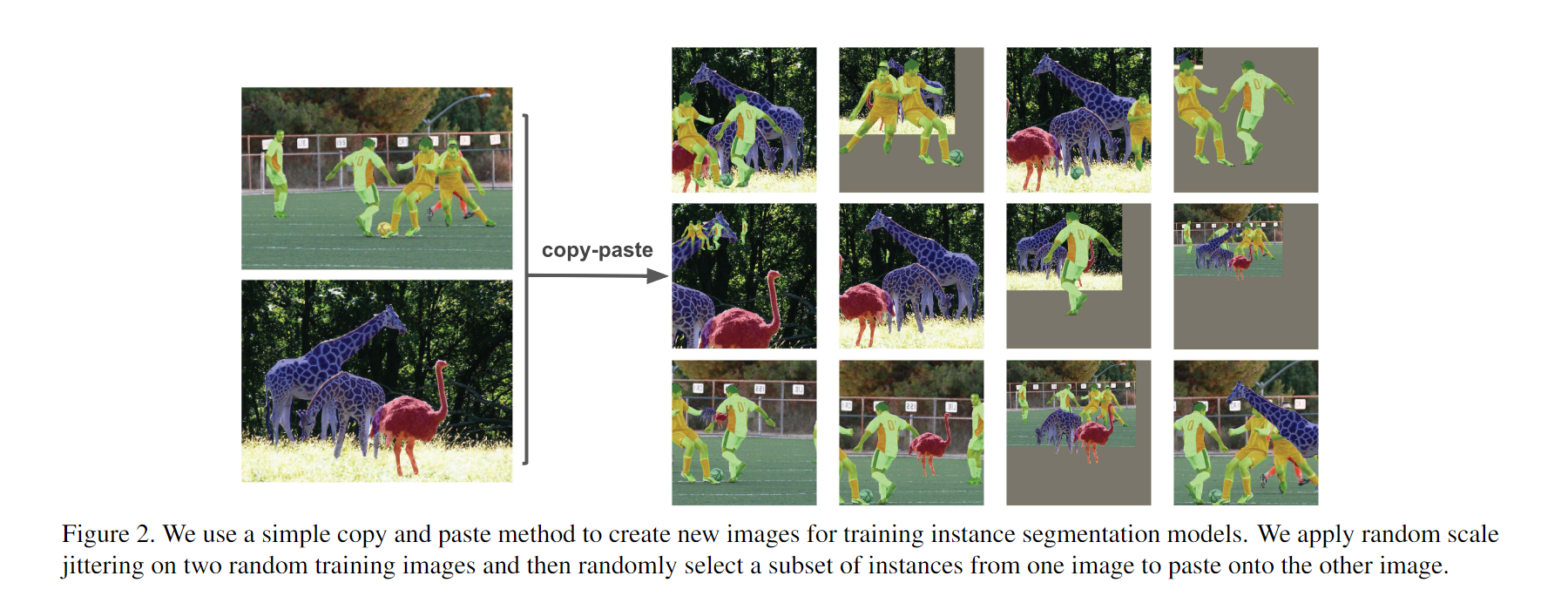
copy-paste data augmentation: 이미지에서 특정 객체를 복사한 후 다른 이미지에 붙여 넣는 데이터 증강 기법입니다.
- 소개 시기: 2021년, Ghiasi, Golnaz, et al., "Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation"
- 개념:
- Copy-Paste는 객체 탐지에서 한 이미지의 객체를 복사하여 다른 이미지에 붙여 넣는 데이터 증강 기법입니다.
- 세부 설명:
- 한 이미지에서 특정 객체를 복사한 후 다른 이미지에 붙여 넣음으로써 객체의 위치, 배경, 그리고 상호작용 환경을 다양화하는 증강 방법입니다.
- CutMix와 비슷한 개념이지만, Copy-Paste는 특정 객체를 대상으로만 수행되며, 객체를 복사하여 원래 이미지와는 다른 맥락의 이미지에 삽입합니다.
- 이 기법은 복잡한 배경에서 객체를 탐지하거나 객체 간의 상호작용을 학습하는 데 유리합니다. 특히 객체 간의 위치나 상호작용을 더 복잡하게 만들어 모델이 다양한 환경에서 학습할 수 있도록 도와줍니다.
-
Random Affine Transformation: 이미지를 회전, 평행 이동, 스케일 조정, 또는 비틀기 등의 변환을 수행 후 모델이 다양한 형태의 변형된 이미지를 학습할 수 있도록 합니다.
- 소개 시기: 랜덤 어파인 변환은 머신러닝과 컴퓨터 비전에서 오랫동안 사용되어 온 기법입니다. 정확한 출처보다는 기하학적 변환의 한 기법으로 고전적인 증강 방법으로 자리 잡고 있습니다.
- 개념:
- Random Affine은 회전, 이동, 스케일 조정, 기울임(shear) 등의 어파인 변환(affine transformation)을 무작위로 적용하여 학습 데이터를 변형하는 증강 기법입니다.
- 세부 설명:
- Affine 변환은 이미지를 회전, 평행 이동, 스케일 조정, 또는 비틀기 등의 변환을 수행하는 기법입니다. 이는 이미지의 기하학적 성질을 변경하면서도 객체 탐지나 분류에 영향을 주지 않도록 학습 데이터를 변형할 수 있게 합니다.
- Random Affine 변환은 이러한 변형을 무작위로 적용하여 모델이 다양한 형태의 변형된 이미지를 학습할 수 있도록 합니다. 특히, 이미지의 원본 정보가 크게 손실되지 않도록 하면서도 다양한 모양과 위치에서의 학습이 가능합니다.
- 이를 통해 모델은 객체가 다양한 각도나 위치에서 등장하더라도 제대로 탐지할 수 있게 됩니다.

-
HSV (Hue, Saturation, Value) Augmentation: 색조(Hue), 채도(Saturation), 명도(Value)를 무작위로 조정하여 이미지의 색상을 다양하게 변형 후 모델이 다양한 형태의 변형된 이미지를 학습할 수 있도록 합니다.
- 소개 시기: HSV 색 공간 자체는 오래된 개념이지만, 이를 데이터 증강에 활용하는 방법은 컴퓨터 비전과 딥러닝 분야에서 널리 사용되어 온 고전적인 데이터 증강 기법입니다.
- 개념:
- HSV 증강은 이미지의 색조(Hue), 채도(Saturation), 명도(Value)를 조정하여 색상 변형을 통해 데이터 다양성을 높이는 기법입니다.
- 세부 설명:
- HSV 색 공간은 이미지를 구성하는 색상 정보를 색조(Hue), 채도(Saturation), 명도(Value)로 분리하여 표현하는 방식입니다.
- HSV 증강은 이 세 가지 요소를 무작위로 조정하여 이미지의 색상을 다양하게 변형합니다. 예를 들어, 색조를 변경하면 이미지의 색상이 변하고, 채도를 조정하면 색의 강도가 달라지며, 명도를 변경하면 이미지의 밝기가 변합니다.
- 이러한 색상 변형을 통해 네트워크는 조명 변화나 색상 왜곡 등 실제 환경에서 발생할 수 있는 다양한 변형에 적응할 수 있게 됩니다.
- 기하학적 변형 대신 색상 관련 정보를 변형하여 다양한 환경에서 모델이 일반화 성능을 가지도록 합니다.

-
CSPNet Backbone
- YOLOv5는 YOLOv4에서 사용된 CSPNet 백본을 사용하여 연산 효율성을 높였습니다. CSPNet은 신경망의 반복적인 정보 흐름을 줄여 연산량을 최적화하며, 모델의 크기를 줄이면서도 높은 정확도를 유지할 수 있도록 도와줍니다.
-
성능 향상을 위한 최적화
- YOLOv5는 FP16 혼합 정밀도 학습을 통해 속도와 메모리 효율성을 향상시켰습니다. 이를 통해 모델은 더 빠르게 학습할 수 있고, GPU 메모리 사용량도 줄어들어 대형 데이터셋 학습 시에도 효율적으로 동작합니다.
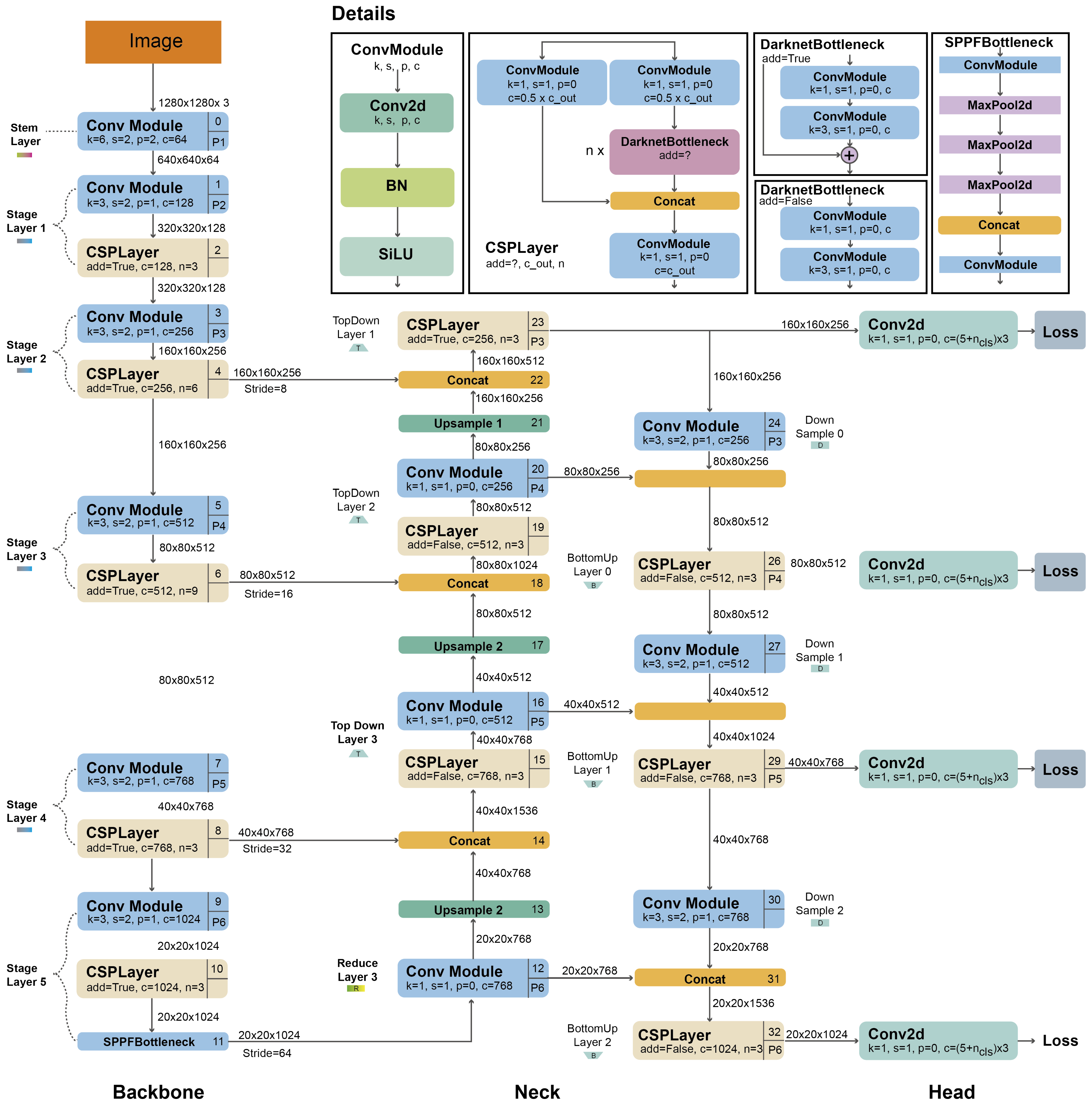
10.2 YOLOv5의 아키텍처
YOLOv5의 기본 구조는 이전 버전의 YOLO와 유사하지만, 몇 가지 최적화된 요소를 추가하여 더 나은 성능을 발휘할 수 있도록 설계되었습니다.
YOLOv5의 아키텍처는 크게 다음과 같은 구성 요소로 나뉩니다:
-
Backbone: YOLOv5는 CSPNet 기반의 백본을 사용하여 입력 이미지에서 특징을 추출합니다. 이 백본은 YOLOv4에서 소개된 것과 유사하지만, PyTorch 프레임워크에서 더 효율적으로 동작할 수 있도록 최적화되었습니다.
-
Neck: YOLOv5는 PANet (Path Aggregation Network) 구조를 사용하여 여러 계층에서 추출된 특징을 결합합니다. 이를 통해 다양한 크기의 객체를 더욱 정확하게 탐지할 수 있게 됩니다.
-
Head: YOLOv5는 앵커 박스 기반의 탐지 방식을 사용하며, 각 바운딩 박스의 좌표, 객체성(objectness) 점수, 클래스 확률을 예측합니다. YOLOv5는 후처리 과정에서 Non-Maximum Suppression (NMS) 기법을 사용하여 중복된 박스를 제거합니다.
11. Scaled-YOLOv4 (2020년 11월)
Scaled-YOLOv4는 YOLOv4의 확장 버전으로, 2021년 발표된 모델입니다. Scaled-YOLOv4는 YOLOv4의 성능을 더욱 향상시키기 위해 다양한 크기의 모델을 제공하고, 여러 크기 스케일에서 객체 탐지를 더 효율적으로 수행할 수 있도록 설계되었습니다. 모델의 스케일링을 통해 실시간 객체 탐지 성능을 유지하면서도 고성능을 제공하는 것이 목표입니다.
- Scaled-YOLOv4는 여러 버전의 모델을 제공하여, 작은 크기부터 대형 모델까지 다양한 크기와 성능 요구에 맞출 수 있도록 설계되었습니다.
- 이로 인해, Scaled-YOLOv4는 경량화된 환경에서부터 고성능 GPU를 사용하는 환경에 이르기까지 폭넓게 적용될 수 있습니다.
11.1 Scaled-YOLOv4의 주요 목표
Scaled-YOLOv4의 개발 목표는 다음과 같습니다:
-
다양한 크기의 객체 탐지: 작은 모델은 빠르고 경량화되어 있으며, 큰 모델은 높은 정확도를 제공하여 사용자가 필요에 따라 성능을 조정할 수 있도록 합니다.
-
범용성: 다양한 컴퓨팅 환경에 적응할 수 있는 모델을 제공하여, 임베디드 장치나 실시간 응용뿐만 아니라 GPU 기반의 고성능 시스템에서도 사용할 수 있습니다.
-
고효율 스케일링: 모델 크기와 성능 사이의 균형을 조정할 수 있도록 하여, 작은 모델은 속도와 메모리 사용을 최적화하고, 큰 모델은 정확도를 극대화할 수 있습니다.
모델 스케일링의 기본 원칙
정량적 비용 최적화: 이미지 크기, 네트워크 깊이 및 필터 수(너비)를 조정함으로써 계산 비용을 줄이면서도 성능을 유지하거나 향상시키는 것을 목표로 합니다.최소 계산 주문 유지: 계산 순서가 O(whkb2)보다 작도록 하여 경량 모델에서 효율적인 메모리 이용을 가능하게 합니다.
스케일링 변수를 통한 조정
스케일링은 주로 세 가지 변수로 진행됩니다:
α (이미지 크기): 입력 이미지의 해상도를 조정합니다. 크기를 증가시키면 점검할 수 있는 정보의 양이 증가하지만 계산 비용도 함께 증가합니다.β (깊이): 네트워크의 층 수를 조정하여 모델의 깊이를 변화시킵니다. 깊이를 늘리면 모델의 표현력이 높아지지만, 훈련과 추론 속도는 느려질 수 있습니다.γ (너비): 각 층의 필터 수를 조정합니다. 필터 수를 늘리면 네트워크의 용량이 증가하여 더 복잡한 패턴을 학습할 수 있지만, 동시에 계산 비용이 상승합니다.
11.2 Scaled-YOLOv4의 스케일링 기법
Scaled-YOLOv4는 YOLOv4의 기본 아키텍처를 바탕으로 모델의 크기(α), 깊이(β), 폭(γ)을 조절하여 다양한 버전의 모델을 제공합니다. (위 참고)
이러한 스케일링 기법은 모델의 복잡도를 조정하는 방법으로, EfficientDet에서 사용된 방식과 유사하게 모델을 세 가지 측면에서 확장할 수 있습니다:
-
크기 스케일링 (Resolution Scaling):
기본 개념: 크기 스케일링은 입력 이미지의 해상도를 조절하는 것을 의미합니다. 입력 이미지의 해상도가 높아지면, 모델은 더 많은 픽셀 정보를 처리하게 되며, 이를 통해 더욱 세밀한 특징을 추출할 수 있습니다.효과: 고해상도 이미지는 물체의 작은 세부 사항을 더 잘 포착할 수 있지만, 이로 인해 계산 복잡도가 증가하고 처리 시간이 길어질 수 있습니다. 반대로, 저해상도 이미지는 계산이 더 빠르지만 물체의 세부 정보를 포착하기 어려울 수 있습니다.Scaled-YOLOv4에서의 사용: Scaled-YOLOv4는 다양한 해상도의 이미지를 처리할 수 있도록 설계되었습니다. 예를 들어, 큰 모델은 고해상도 입력을 처리해 더 정밀한 탐지를 수행하고, 작은 모델은 저해상도 입력을 통해 실시간 성능을 제공할 수 있습니다. 이로 인해, Scaled-YOLOv4는 다양한 환경에서 최적화된 성능을 발휘할 수 있습니다.
-
깊이 스케일링 (Depth Scaling):
기본 개념: 깊이 스케일링은 합성곱 계층의 수를 조정하는 것을 의미합니다. 즉, 네트워크의 레이어 수를 늘리거나 줄여 네트워크의 깊이를 조정하는 방식입니다.효과: 더 깊은 네트워크는 더 많은 계층을 통해 더욱 복잡하고 추상적인 특징을 학습할 수 있습니다. 이를 통해 더 정확한 객체 탐지가 가능하지만, 연산량이 많아지면서 처리 속도가 느려질 수 있습니다. 반면, 얕은 네트워크는 빠르게 연산할 수 있지만, 복잡한 물체의 특징을 충분히 학습하지 못할 수 있습니다.Scaled-YOLOv4에서의 사용: Scaled-YOLOv4는 YOLOv4의 기본 아키텍처에서 각 모델 버전에 따라 깊이를 확장하거나 축소할 수 있습니다. 예를 들어, YOLOv4-tiny는 깊이가 얕아 경량화된 장치에서 실시간으로 동작할 수 있고, YOLOv4-large는 더 깊은 네트워크 구조로 복잡한 객체를 보다 정확하게 탐지할 수 있습니다.
-
폭 스케일링 (Width Scaling):
기본 개념: 폭 스케일링은 각 계층의 필터 수를 조정하는 것을 의미합니다. 즉, 각 레이어에서 사용하는 필터(커널)의 개수를 늘리거나 줄이는 방식입니다.효과: 더 넓은 네트워크는 각 계층에서 한 번에 더 많은 특징을 학습할 수 있습니다. 이는 더 풍부한 정보를 기반으로 객체를 탐지할 수 있게 하지만, 필터 수가 많아질수록 연산량도 증가합니다. 반대로, 좁은 네트워크는 계산 비용이 적지만 학습하는 정보의 양이 제한될 수 있습니다.Scaled-YOLOv4에서의 사용: Scaled-YOLOv4는 폭 스케일링을 통해 각 모델의 성능을 조정할 수 있습니다. 예를 들어, YOLOv4-large는 넓은 폭을 가진 레이어들을 사용하여 더 많은 필터를 통해 복잡한 패턴을 학습하고, YOLOv4-tiny는 좁은 폭을 사용해 빠르고 경량화된 연산을 수행합니다.
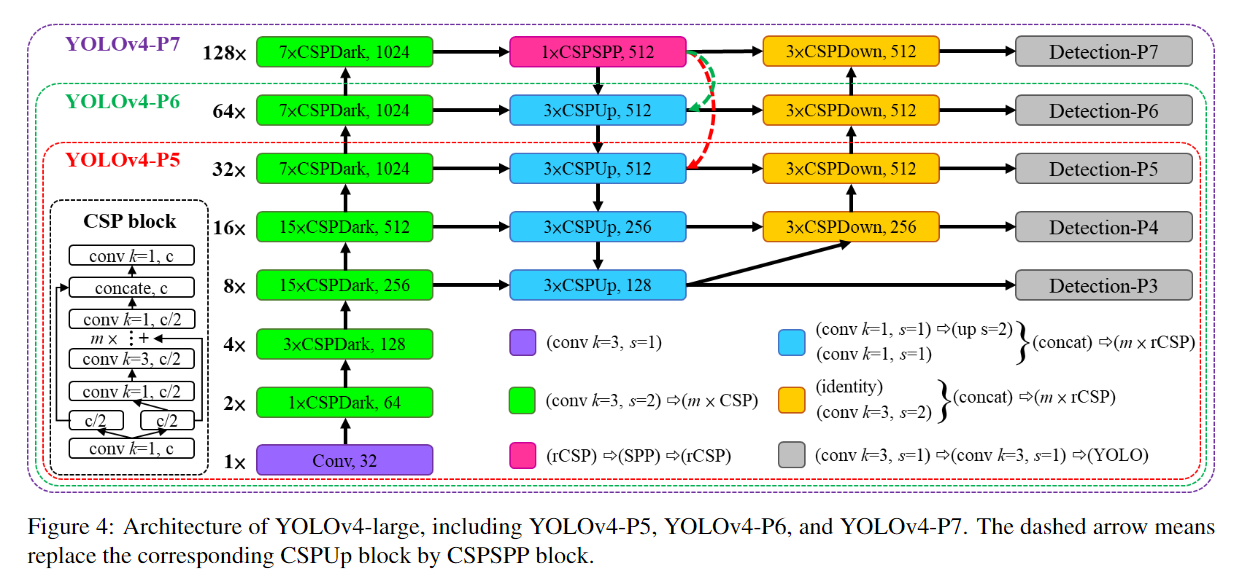
11.3 모델 아키텍처
Scaled-YOLOv4의 기본 아키텍처는 YOLOv4와 매우 유사합니다. 기본적으로 CSPNet 기반의 CSPDarknet53 백본을 사용하며, Path Aggregation Network (PANet)을 넥으로 사용하여 다양한 크기의 객체를 탐지할 수 있는 특징을 결합합니다. 이 아키텍처는 높은 연산 효율성을 유지하면서도 매우 강력한 성능을 제공하도록 설계되었습니다.
-
Backbone (CSPDarknet53): YOLOv4에서 사용된 CSPNet을 기반으로 한 백본을 그대로 사용하여, YOLOv4의 높은 성능을 유지합니다.
-
Neck (PANet): YOLOv4에서 사용된 PANet을 통해 상하위 계층에서 추출된 특징을 결합하여, 작은 객체와 큰 객체를 모두 정확하게 탐지합니다.
-
Head: YOLOv4와 마찬가지로, 각 스케일에서 객체의 바운딩 박스 좌표와 클래스 확률을 예측하며, Non-Maximum Suppression (NMS) 기법을 사용해 중복된 바운딩 박스를 제거합니다.
💡 Scaled-YOLOv4에서 "Scaled"라는 의미
Scaled-YOLOv4의 "scaled"라는 용어는 단순히 하나의 고정된 모델이 아니라, 필요에 따라 최적화된 크기로 조정할 수 있는 모델이라는 의미에서 사용된 것입니다.
- 확장 가능한(Scalable): Scaled-YOLOv4는 상황에 맞게 모델의 크기(해상도), 깊이(레이어 수), 폭(필터 수)를 유연하게 조정할 수 있도록 설계되었습니다. 이를 통해 작은 모델에서 큰 모델까지 다양한 요구를 충족할 수 있습니다.
- 조정 가능: 모델이 적용될 환경이나 성능 요구 사항에 맞춰 동적으로 크기, 깊이, 폭을 조절할 수 있다는 뜻입니다. 예를 들어, 고성능 GPU에서는 더 큰 모델을 사용하고, 실시간 성능이 중요한 장치에서는 더 작은 모델을 사용할 수 있습니다.
12. YOLOR (2021년 5월)
YOLOR(You Only Learn One Representation)는 2021년에 발표된 객체 탐지 모델로, YOLO 시리즈와 마찬가지로 실시간 객체 탐지에서 뛰어난 성능을 제공합니다.
- YOLOR의 가장 큰 특징은 다중 작업 학습(Multi-task Learning)을 통해 객체 탐지뿐만 아니라 분류, 회귀, 포즈 추정 등의 여러 작업을 동시에 수행할 수 있다는 점입니다.
- YOLOR은 신경망의 암묵적 지식(Implicit Knowledge)을 학습하여, 다양한 작업에 대한 유연한 처리 능력을 제공합니다.
12.1 YOLOR의 주요 특징
YOLOR의 핵심 아이디어는 하나의 신경망이 여러 작업을 동시에 학습하고 처리할 수 있다는 것입니다.
- YOLOR은 YOLO 모델을 기반으로 하지만, 기존 YOLO 모델과 달리 명시적(explicit) 학습뿐만 아니라 암묵적(implicit) 학습도 통합하여 모델의 성능을 높였습니다.
암묵적 지식(Implicit Knowledge)과 명시적 지식(Explicit Knowledge)
암묵적 지식: 입력 데이터에서 직접 관찰할 수 없는 정보로, 신경망의 깊은 층에서 학습되며 모델이 다양한 작업에 적응하는 데 도움이 됨. 사람의 무의식적 학습과 비슷한 개념.명시적 지식: 전통적인 신경망에서 얻은 피쳐로, 주로 입력된 데이터에서 바로 관찰할 수 있는 정보.
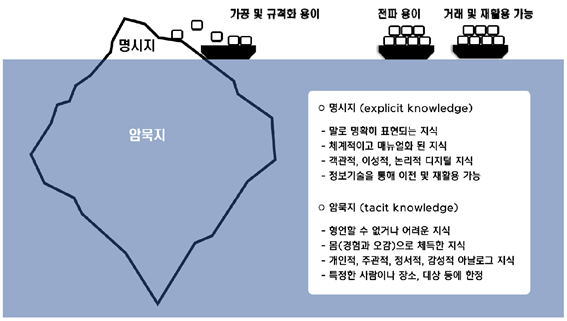
이미지 출처. 디지털 시대 암묵적 지식 활용의 전략적 가치 (네이버 블로그)
- 암묵적 지식(Implicit Knowledge) 학습
- YOLOR의 가장 큰 차별화 요소는 암묵적 표현 학습(Implicit Representation Learning)입니다.
- 기존의 모델들은 명시적인 피쳐(예: 객체의 위치, 크기, 클래스)를 학습하는 반면, YOLOR은 이러한 명시적 학습 외에도 신경망이 학습 과정에서 자동으로 학습하는 암묵적 피쳐(implicit features)를 활용합니다.
- 이 암묵적 지식은 여러 작업에서 재사용될 수 있으며, 모델이 더 많은 정보를 기반으로 다양한 작업을 수행할 수 있도록 도와줍니다.
🔎 암묵적 지식의 역할
- 암묵적 지식은 다양한 작업에서 모델이 더 나은 결정을 내릴 수 있도록 도움을 줍니다. 예를 들어, 한 작업에서 학습한 암묵적 지식이 다른 작업에 적용되어 그 작업의 성능을 향상시킬 수 있습니다.
- YOLOR에서 암묵적 지식은 다양한 작업을 동시에 학습하는 데 매우 유용합니다. 명시적 지식은 특정 작업에만 적합할 수 있지만, 암묵적 지식은 다양한 작업에 적용 가능한 범용적인 정보를 제공합니다.
🤔 암묵적 지식 그럼 어떻게 학습하는데
- YOLOR에서 암묵적 지식은 벡터, 신경망, 행렬 분해(matrix factorization) 등의 방식으로 모델링될 수 있습니다. 이 방식들은 다음과 같은 방법으로 암묵적 지식을 학습하게 됩니다.
벡터(Vector): 암묵적 지식은 벡터 형태로 표현되며, 각 차원은 서로 독립적입니다. 이 벡터는 특정 작업의 특징을 학습하는 데 사용됩니다.신경망(Neural Network): 벡터를 입력으로 받아 신경망을 통해 더 복잡한 형태의 암묵적 표현을 학습합니다. 여기서는 각 차원이 상호 의존적입니다.행렬 분해(Matrix Factorization): 여러 벡터의 조합으로 암묵적 표현을 학습합니다. 이러한 방식은 더 복잡한 암묵적 관계를 모델링할 수 있으며, 이를 통해 더 풍부한 표현을 얻습니다.
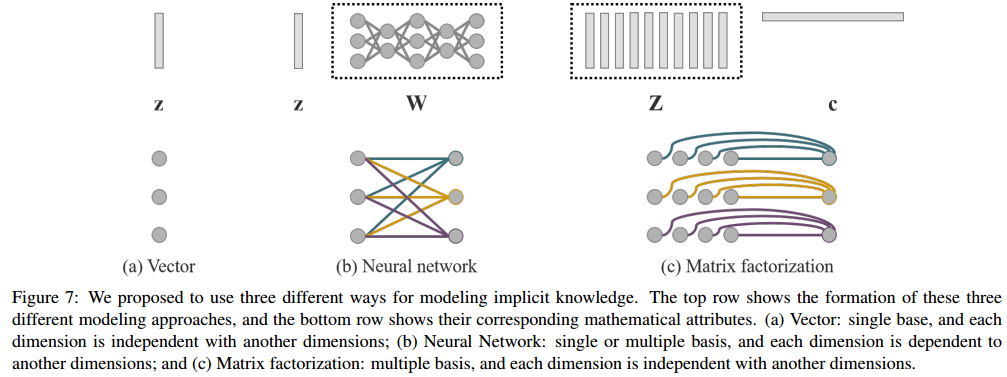
-
다중 작업 학습(Multi-task Learning)
- YOLOR은 객체 탐지, 이미지 분류, 포즈 추정 등 여러 작업을 동시에 학습하고 처리할 수 있습니다. 이러한 다중 작업 학습은 모델의 효율성을 크게 높여주며, 다양한 작업을 동시에 해결해야 하는 복잡한 환경에서 특히 유리합니다. 예를 들어, YOLOR은 객체 탐지를 수행하는 동시에 객체의 포즈나 분류 작업도 함께 처리할 수 있습니다.
-
YOLO 시리즈의 확장
- YOLOR은 YOLOv4 및 YOLOv5의 성능을 기반으로 하지만, 더 나아가 여러 작업을 동시에 학습할 수 있도록 개선되었습니다. 기존 YOLO 모델들이 주로 객체 탐지에 집중한 반면, YOLOR은 객체 탐지 외에도 포즈 추정과 같은 추가 작업을 수행할 수 있습니다.
-
명시적 및 암묵적 학습 통합
-
YOLOR에서 암묵적 지식(Implicit Knowledge)과 명시적 지식(Explicit Knowledge)을 학습하고 이를 최종적으로 처리하는 방법은 두 가지 지식을 효과적으로 결합하여 다양한 작업을 처리할 수 있도록 설계되었습니다.
-
이를 위해 YOLOR은 명시적 지식과 암묵적 지식을 구분하고, 두 가지 지식을 학습 및 결합하는 고유한 방법을 사용합니다. 정리하면 다음과 같습니다.
-
명시적 지식(Explicit Knowledge)의 학습-
명시적 지식은 입력 데이터로부터 직접 관찰할 수 있는 정보입니다. 이는 신경망의 얕은 층에서 주로 학습되며, 주로 입력 이미지에서 구체적이고 물리적인 특징을 추출하는 데 사용됩니다.
-
학습 방법:
- YOLOR에서는 YOLOv4-CSP 기반의 네트워크를 사용하여, 입력 데이터에서 명시적인 특징을 학습합니다. 이때 얕은 레이어를 통해 주로 이미지에서의 물체 경계, 모양, 크기 등 명확히 관찰할 수 있는 정보를 학습합니다.
- 명시적 지식은 주어진 작업에 맞는 특화된 정보로서, 예를 들어 객체 탐지에서는 물체의 위치나 크기와 같은 구체적인 정보를 학습하게 됩니다.
-
활용 방법:
- 학습된 명시적 지식은 주로 특정 작업에 필요한 구체적인 목표를 달성하는 데 사용됩니다.
- 예를 들어, 객체 탐지 작업에서 물체의 경계나 클래스 정보를 정확하게 추론하는 데 사용됩니다.
-
-
암묵적 지식(Implicit Knowledge)의 학습-
암묵적 지식은 입력 데이터에서 직접적으로 관찰되지 않는 정보로, 깊은 층에서 학습되며 다양한 작업에 적용 가능한 범용적인 정보입니다.
-
학습 방법:
-
YOLOR에서는 다양한 기법을 통해 암묵적 지식을 학습합니다. 이는 주로 Manifold space reduction과 Kernel space alignment와 같은 기법을 사용하여 추상적이고 범용적인 특징을 학습합니다.
-
Manifold space reduction: YOLOR는 내부적으로 매니폴드 학습을 통해 데이터의 복잡한 구조를 이해하고 표현합니다. 이를 위해 암묵적 표현을 계산하여 데이터의 고차원 특성을 저차원 공간에 투영합니다. 이 과정에서, 모델은 데이터 포인트를 그들의 잠재적인 특성과 관계에 따라 그룹화하고 분류합니다. 이를 통해 여러 작업을 수행할 수 있는 적합한 저차원 표현을 생성합니다.
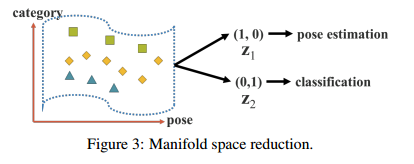
-
Kernel space alignment: 다중 작업(다중 헤드) 네트워크에서는 각 작업에 대한 출력을 동일한 커널 공간에 정렬해야 합니다. YOLOR는 출력 피쳐와 암묵적 표현을 결합하여 이렇게 하는데, 이를 통해 출력의 커널을 이동, 회전 및 스케일 조정합니다. 이는 각 작업의 최적화를 촉진하며, 줄어든 차원에서 서로 다른 작업 간의 기능을 쉽게 공유하고 조정할 수 있습니다. YOLOR는 이러한 정렬 과정을 통해 커널 공간 내의 불일치를 해결하여 더 효과적으로 데이터를 처리합니다.
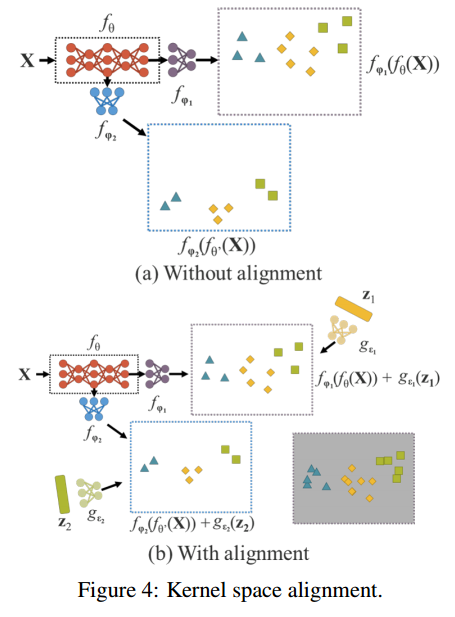
-
-
암묵적 지식은 신경망의 깊은 층에서 학습되며, 데이터의 추상적 패턴을 학습하여 다양한 작업에 유용한 범용적 특징을 제공합니다.
-
-
활용 방법:
- 암묵적 지식은 다양한 작업에서 공통적으로 적용될 수 있는 범용적인 정보로 사용됩니다. 모델은 암묵적 지식을 통해 다중 작업 학습(Multi-task Learning)을 할 때, 각 작업에서의 성능을 개선할 수 있습니다.
- 예를 들어, 객체 탐지뿐만 아니라 다중 레이블 분류나 임베딩 등의 다른 작업에도 활용될 수 있는 범용적인 임베딩을 제공합니다.
-
-
명시적 지식과 암묵적
지식의 결합-
YOLOR의 핵심 기여 중 하나는 명시적 지식과 암묵적 지식의 결합입니다. 이 결합을 통해 모델은 특정 작업에 대한 구체적인 목표와 다양한 작업에서 사용할 수 있는 범용적인 지식을 함께 사용할 수 있게 됩니다.
-
결합 방법:
- YOLOR은 명시적 지식과 암묵적 지식을 결합할 때, 덧셈(Addition), 곱셈(Multiplication), 연결(Concatenation)과 같은 연산을 사용합니다.
- 덧셈(Addition): 두 지식을 더하여 최종 예측에 기여하는 방식으로, 단순하지만 효과적으로 정보를 결합합니다.
- 곱셈(Multiplication): 두 지식을 곱하여 정보 간의 상호작용을 증대시킵니다.
- 연결(Concatenation): 두 지식을 연결하여, 각각의 정보가 독립적으로 처리되면서 더 풍부한 표현을 제공할 수 있게 합니다.
- 이러한 결합 방식은 YOLOR에서 특정 작업을 위한 명시적 지식과 여러 작업을 위한 암묵적 지식이 조화롭게 사용되도록 만듭니다.
- YOLOR은 명시적 지식과 암묵적 지식을 결합할 때, 덧셈(Addition), 곱셈(Multiplication), 연결(Concatenation)과 같은 연산을 사용합니다.
-
추가 기능 (More Functions):
- YOLOR는 암묵적 지식을 활용하여 모델의 예측력을 높이기 위한 다양한 기능을 구현합니다. 예를 들어, 예측 보정(Prediction Refinement)은 네트워크가 제공한 예측을 수정하여 더 정확한 결과를 생성합니다.
- 하이퍼파라미터 검색(Hyperparameter Search)은 데이터에 대한 최적의 설정을 자동으로 찾는 과정으로, 네트워크 성능을 더욱 개선합니다. 각 작업에 필요한 특성을 선택하고 조정할 수 있는 다중 작업 기능 선택(Multi-task Feature Selection)도 지원합니다.
-
-
-
최종 처리과정-
다양한 작업에서의 적용:
- YOLOR은 학습된 명시적 지식과 암묵적 지식을 결합하여 다양한 작업에서 사용할 수 있는 통합된 표현을 만듭니다. 이 통합된 표현은 모델이 다양한 작업을 동시에 처리할 수 있도록 돕습니다.
- 예를 들어, YOLOR은 객체 탐지, 다중 레이블 이미지 분류, 임베딩 학습 등 다양한 작업에서 동시에 좋은 성능을 발휘할 수 있습니다.
- YOLOR은 학습된 명시적 지식과 암묵적 지식을 결합하여 다양한 작업에서 사용할 수 있는 통합된 표현을 만듭니다. 이 통합된 표현은 모델이 다양한 작업을 동시에 처리할 수 있도록 돕습니다.
-
추론 단계에서의 처리:
- 추론 단계에서는 학습된 명시적 특징과 암묵적 특징을 바탕으로, 최종 예측을 도출하게 됩니다. 이때 암묵적 지식은 고정된 텐서로서 더 이상 추가적인 계산 복잡도를 야기하지 않으면서도, 다양한 작업에서 유용한 정보를 제공합니다.
- 각 작업에 맞는 구체적인 예측값을 명시적 지식으로 처리하고, 동시에 다양한 작업에서 적용 가능한 범용적 정보를 암묵적 지식으로 제공하여 결과를 도출합니다.
-
12.2 YOLOR의 아키텍처
YOLOR은 YOLOv4와 YOLOv5의 기본 아키텍처를 기반으로 하지만, 더 나은 성능을 위해 몇 가지 중요한 개선 사항을 포함하고 있습니다:
-
Backbone
- YOLOR은 YOLOv5에서 사용된 CSPNet을 기반으로 한 백본을 사용합니다. CSPNet은 특징 추출을 최적화하여 모델의 연산 효율성을 높이고, 특징 맵을 생성하는 과정에서의 정보 손실을 줄입니다. 이로 인해 YOLOR은 높은 성능을 유지하면서도 메모리 사용을 줄일 수 있습니다.
-
Neck
- YOLOR은 YOLOv4에서 도입된 Path Aggregation Network (PANet) 구조를 사용합니다. PANet은 상위 계층과 하위 계층에서 추출된 특징을 결합하여 다양한 크기의 객체에 대해 더 나은 탐지를 제공합니다. 특히 작은 객체와 큰 객체를 모두 정확하게 탐지할 수 있도록 도와줍니다.
-
Head
- YOLOR의 Head는 기존 YOLO 모델과 유사하게, 여러 해상도에서 바운딩 박스와 객체의 클래스를 예측합니다. 또한, Non-Maximum Suppression (NMS)을 사용하여 중복된 바운딩 박스를 제거합니다. 하지만 YOLOR은 다중 작업 학습을 위해 Head에서 추가적인 출력을 지원하며, 포즈 추정 등 다양한 작업을 동시에 처리할 수 있습니다.
13. YOLOX (2021년 7월)
YOLOX는 2021년에 발표된 YOLO 시리즈의 확장 모델로, 기존 YOLO 모델들의 성능을 개선하고 몇 가지 새로운 기술적 접근 방식을 도입한 모델입니다.
- YOLOX는 YOLOv3에서 영감을 받았지만, 앵커리스(anchor-free) 객체 탐지와 디커플드 헤드(decoupled head) 구조를 채택하여 이전 YOLO 모델들과 차별화된 특징을 갖추고 있습니다.
- YOLOX는 더 유연하고 강력한 성능을 제공하면서도 실시간 객체 탐지에 적합한 속도를 유지합니다.
13.1 YOLOX의 주요 개선 사항
YOLOX는 기존 YOLO 모델들과는 몇 가지 중요한 차이점이 있습니다. 특히 앵커리스(anchor-free) 탐지 방식과 디커플드 헤드(decoupled head) 구조는 YOLOX를 다른 YOLO 모델들과 구별되게 만드는 핵심 요소입니다.
-
앵커리스(Anchor-free) 탐지
- 기존 앵커 기반 방식: 기존 YOLO 모델들은 사전에 정의된 앵커 박스를 기반으로 객체를 탐지합니다. 앵커 박스는 다양한 크기와 비율로 미리 설정된 바운딩 박스들로, 이미지의 각 위치에서 이 박스들을 기반으로 객체가 있는지 없는지를 예측합니다. 이 과정에서는 앵커 박스의 크기나 비율을 미리 설정하고 학습 전 클러스터링을 통해 최적화해야 했습니다.
- 앵커리스 방식의 도입: YOLOX는 이러한 앵커 박스를 사용하지 않고, 객체의 중심점을 직접 예측하고 그를 기준으로 바운딩 박스를 생성하는 방식입니다. 앵커리스 탐지 방식은 객체의 좌표와 크기를 예측하는 과정에서 직접적인 예측을 사용하여, 사전에 설정된 앵커가 필요 없습니다.
- 장점:
- 더 간결한 구조: 앵커 기반 방식에서는 각 이미지의 모든 위치에서 여러 개의 앵커 박스를 예측해야 했지만, 앵커리스 방식에서는 하나의 위치에서 한 개의 예측만으로 처리할 수 있어 모델의 복잡성이 감소합니다.
- 성능 향상: 앵커를 최적화하거나 세밀하게 설정할 필요가 없기 때문에, 모델의 학습 과정이 더 간단하고 효율적이며, 성능이 향상됩니다. 앵커 박스를 사용할 때 발생할 수 있는 오버헤드(Anchor Clustering, Grid Sensitivity 등)를 줄일 수 있습니다.
- 속도 증가: 앵커 박스의 수가 줄어들면서, 탐지 과정에서 필요한 연산량도 감소해 처리 속도가 빨라집니다.
-
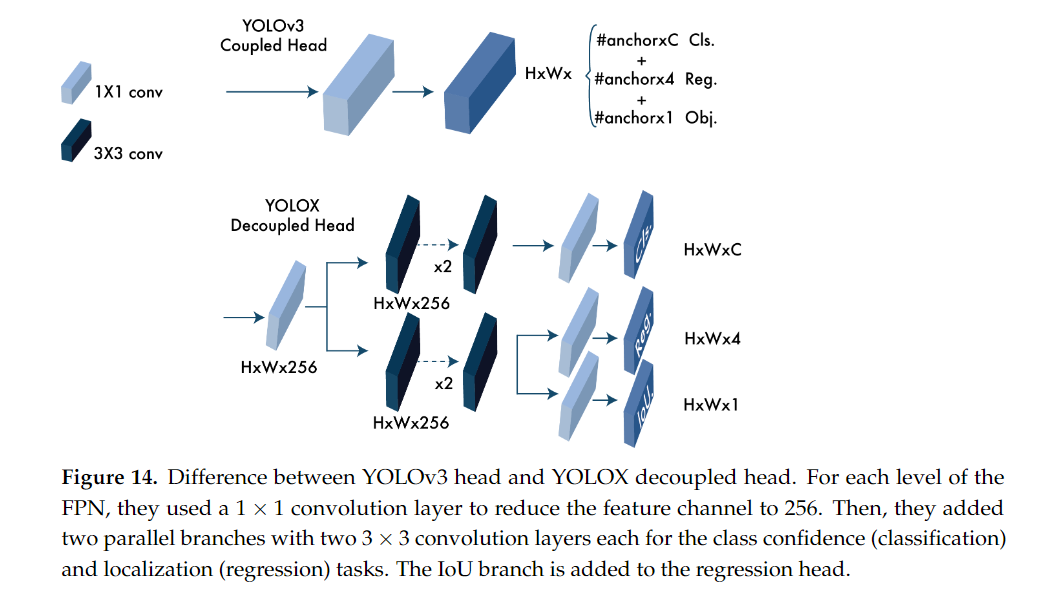
디커플드 헤드(Decoupled Head)
-
기존 헤드 구조: 기존 YOLO 모델에서는 분류(Classification)와 회귀(Regression) 작업을 하나의 네트워크에서 동시에 처리했습니다. 즉, 객체가 무엇인지(분류)와 어디에 있는지(위치 예측)를 하나의 탐지 헤드에서 수행하는 구조였습니다. 그러나 이 방식은 두 작업 간의 충돌(conflict) 문제를 야기할 수 있습니다. 예를 들어, 정확한 객체 위치를 예측하는 작업과 객체를 분류하는 작업은 서로 다른 목표를 가지기 때문에, 이를 함께 처리할 때 학습 성능이 떨어질 수 있습니다.
-
디커플드 헤드의 도입: YOLOX는 분류와 회귀 작업을 분리된 네트워크(디커플드 헤드)에서 처리합니다. 즉, 하나의 서브 네트워크는 객체가 어떤 종류인지 분류하는 작업만 담당하고, 다른 서브 네트워크는 객체의 위치와 크기를 예측하는 데만 집중합니다. 이를 통해 각 작업의 효율성이 극대화됩니다.
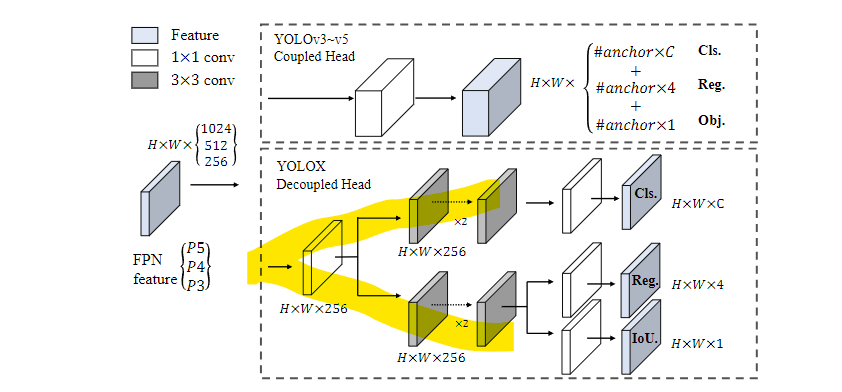
-
장점:
- 성능 향상: 분류와 회귀 작업이 분리됨으로써 두 작업이 독립적으로 최적화될 수 있어, 탐지 성능이 향상됩니다. 특히 회귀 작업이 분류 작업에 영향을 받지 않아 더 정밀한 바운딩 박스 예측이 가능해집니다.
- 빠른 수렴: 분리형 헤드를 사용하면 학습 속도가 빠르게 수렴하며, 더 빠르게 좋은 성능을 낼 수 있습니다. 이는 모델이 더 효율적으로 학습할 수 있다는 의미입니다.
-
-
다중 긍정 샘플(Multi-positives) 전략
- 기존 방식: 기존 YOLO 모델에서는 각 객체에 대해 한 개의 위치만 긍정(positive) 샘플로 선택하여 학습에 사용했습니다. 예를 들어, 객체의 중심에 해당하는 한 점만 긍정 샘플로 선택하고 나머지는 부정(negative) 샘플로 처리합니다. 이는 학습 중 객체와 관련된 정보가 충분히 반영되지 않을 수 있습니다.
- 다중 긍정 샘플 전략의 도입: YOLOX는 한 개의 긍정 샘플만 사용하는 대신, 여러 개의 긍정 샘플을 사용합니다. 구체적으로는, 객체의 중심을 포함한 주변 3x3 영역을 모두 긍정 샘플로 지정하여 학습에 사용합니다.
- 장점:
- 더 많은 정보 반영: 다중 긍정 샘플을 사용함으로써, 각 객체에 대해 더 많은 정보를 학습에 활용할 수 있게 됩니다. 이는 특히 복잡한 장면에서 객체가 여러 개 겹쳐 있을 때 더 좋은 탐지 성능을 발휘할 수 있습니다.
- 더 나은 성능: 객체의 여러 위치에서 긍정 샘플을 생성함으로써, 모델이 더 다양한 정보를 학습할 수 있으며, 결과적으로 더 정확한 탐지 결과를 얻을 수 있습니다.
-
SimOTA (Optimal Transport Assignment)
- 기존 라벨 할당 방식: 기존 YOLO 모델에서는 객체와 예측된 바운딩 박스 간의 매칭을 위해 고정된 규칙에 따라 라벨을 할당했습니다. 예를 들어, 바운딩 박스가 객체의 중심점과 가장 가까운 예측 값만 긍정 샘플로 할당하는 방식입니다. 그러나 이 방식은 객체 크기와 위치에 따라 최적의 할당이 이루어지지 않을 수 있습니다.
- SimOTA의 도입: YOLOX는 SimOTA라는 최적 운송 할당(Optimal Transport Assignment) 전략을 사용하여 라벨 할당 과정을 최적화합니다. SimOTA는 객체와 예측 값 간의 비용(cost)을 계산하여, 가장 적절한 예측 값을 긍정 샘플로 선택하는 방식입니다. 이 방법은 객체 크기나 위치에 상관없이 더 유연하게 라벨을 할당할 수 있습니다.
- 장점:
- 효율성 증가: SimOTA는 학습 과정에서 각 객체에 대해 더 정확한 라벨 할당을 가능하게 하여, 성능을 크게 향상시킵니다. 특히 동적 탑-k(Dynamic Top-k) 방식을 통해 객체마다 다른 수의 긍정 샘플을 할당하여 더 정교한 탐지가 가능합니다.
- 학습 시간 단축: SimOTA는 라벨 할당 과정을 간소화하여, 추가적인 하이퍼파라미터 조정 없이도 효과적인 라벨 할당이 가능합니다. 또한, 기존의 복잡한 최적화 알고리즘에 비해 학습 시간이 단축되며, 성능 저하 없이 더 빠르게 모델을 학습할 수 있습니다.
13.2 YOLOX의 아키텍처
YOLOX의 아키텍처는 기본적으로 기존 YOLO 모델들의 구조를 따르지만, 몇 가지 중요한 개선 사항이 포함되어 있습니다.
-
Backbone
- YOLOX는 YOLOv4 및 YOLOv5에서 사용된 CSPNet 백본을 기반으로 하여, 이미지에서 특징을 추출합니다. CSPNet은 신경망의 연산 효율성을 극대화하고 정보 손실을 최소화하여, 더 나은 특징을 학습할 수 있도록 도와줍니다.
-
Neck
- YOLOX는 FPN (Feature Pyramid Network)과 PANet (Path Aggregation Network)을 사용하여 상위 및 하위 계층에서 추출된 특징을 결합하고, 다양한 크기의 객체를 탐지할 수 있도록 지원합니다. 이는 다양한 크기의 객체를 더 잘 탐지할 수 있는 능력을 제공합니다.
-
Head
- YOLOX의 디커플드 헤드(decoupled head)는 세 가지 주요 작업(분류, 회귀, 객체성)을 독립적으로 처리하여 더 정밀한 탐지 결과를 도출합니다. 이를 통해 YOLOX는 객체의 위치, 크기, 그리고 클래스에 대한 예측을 더 정확하게 수행할 수 있습니다.
14. YOLOv6 (2022년 9월)
YOLOv6는 Meituan Vision AI 팀이 2022년에 발표한 모델로, YOLO 시리즈의 최신 발전 중 하나입니다. YOLOv6는 고성능 실시간 객체 탐지 모델로, YOLO 시리즈의 전통적인 속도와 정확도를 유지하면서도 효율성을 극대화할 수 있도록 설계되었습니다.
-
특히 YOLOv6는 경량화된 모델로도 강력한 성능을 발휘하며, 다양한 하드웨어 플랫폼에서 최적의 성능을 보입니다.
-
YOLOv6는 YOLO 시리즈의 빠른 속도를 유지하면서도 최신 기술을 통합하여 정확도를 크게 향상시키기 위한 다양한 최적화 기법을 도입하였습니다.
-
이 모델은 특히 산업용 애플리케이션에 적합한 객체 탐지 모델로 설계되었으며, 기존 YOLO 모델들과의 차별화를 위해 몇 가지 중요한 개선 사항을 적용하였습니다.
14.1 YOLOv6의 주요 특징
-
Efficient Backbone: RepVGG
- YOLOv6는 백본 네트워크로 RepVGG 구조를 사용합니다. RepVGG는 기존의 VGG 네트워크를 기반으로 한 효율적인 구조로, 학습 시 복잡한 구조를 단순화하고 추론 시 매우 빠른 속도를 제공합니다. RepVGG는 학습 단계에서 여러 가지 합성곱 계층을 통합해 학습한 뒤, 추론 시 이를 간소화된 구조로 변환해 빠른 연산을 가능하게 합니다. 이를 통해 YOLOv6는 높은 정확도와 함께 실시간 추론 성능을 유지할 수 있습니다.
-
양자화 지원 (Quantization Support)
- YOLOv6는 양자화 기법을 지원하여 경량화된 디바이스에서도 높은 성능을 발휘할 수 있도록 설계되었습니다. 양자화는 모델의 정밀도를 줄여서 연산 효율성을 높이는 기법으로, YOLOv6는 8비트 양자화를 지원하여 성능 저하 없이 매우 높은 연산 효율성을 제공합니다. 이 기능은 특히 임베디드 시스템이나 모바일 환경에서의 객체 탐지에 매우 유용합니다.
-
고성능 객체 탐지
- YOLOv6는 특히 소형 객체 탐지 성능을 크게 향상시켰습니다. 이 모델은 다양한 크기의 객체를 정확하게 탐지할 수 있도록 설계되었으며, 실시간 객체 탐지에서 높은 성능을 유지합니다. YOLOv6는 단일 GPU에서 매우 빠른 추론 속도를 제공하면서도, MS COCO와 같은 대형 데이터셋에서 높은 정확도를 자랑합니다.
-
채널 기반 지식 증류 (Channel-based Knowledge Distillation)
- YOLOv6는 학습 과정에서 채널 기반 지식 증류 기법을 사용합니다. 이 기법은 고성능의 교사 모델(teacher model)에서 학습된 특징을 경량화된 학생 모델(student model)에 전달하여, 경량 모델이 더 좋은 성능을 낼 수 있도록 돕습니다. 이를 통해 경량화된 YOLOv6 모델도 높은 정확도를 유지할 수 있습니다.
-
높은 효율성의 최적화 기법
- YOLOv6는 객체 탐지 성능을 극대화하기 위해 여러 가지 최신 최적화 기법을 도입했습니다. 특히, RepOptimizer와 같은 새로운 옵티마이저를 사용하여, 모델의 수렴 속도를 높이고, 더 적은 학습 단계에서도 좋은 성능을 발휘할 수 있게 했습니다. 이를 통해 모델 학습 시간이 단축되고, 더 적은 자원으로도 높은 성능을 얻을 수 있습니다.
14.2 YOLOv6의 아키텍처
YOLOv6의 아키텍처는 기존 YOLO 모델들과 유사하지만, 성능과 효율성을 높이기 위한 몇 가지 중요한 변경 사항이 적용되었습니다:
-
Backbone: RepVGG
- YOLOv6는 RepVGG 기반의 백본을 사용하여 입력 이미지에서 특징을 추출합니다. RepVGG는 복잡한 연산을 단순화하는 동시에 강력한 특징 추출 능력을 제공합니다. 이 백본은 실시간 객체 탐지에서 매우 빠른 속도를 보장합니다.
-
Neck: PANet (Path Aggregation Network)
- YOLOv6는 PANet을 사용하여 상위 계층의 고수준 정보와 하위 계층의 저수준 정보를 결합합니다. PANet은 다양한 크기의 객체를 탐지할 수 있도록 설계되어, YOLOv6는 작은 객체부터 큰 객체까지 모두 정확하게 탐지할 수 있습니다.
-
Head
- YOLOv6는 객체의 위치와 크기를 예측하기 위한 Dense Prediction Head를 사용합니다. YOLOv6는 여러 해상도에서 예측을 수행하며, 다중 스케일에서 객체를 탐지할 수 있습니다. 또한, YOLOv6는 Non-Maximum Suppression (NMS) 기법을 사용하여 중복된 바운딩 박스를 제거하고 더 정확한 결과를 제공합니다.
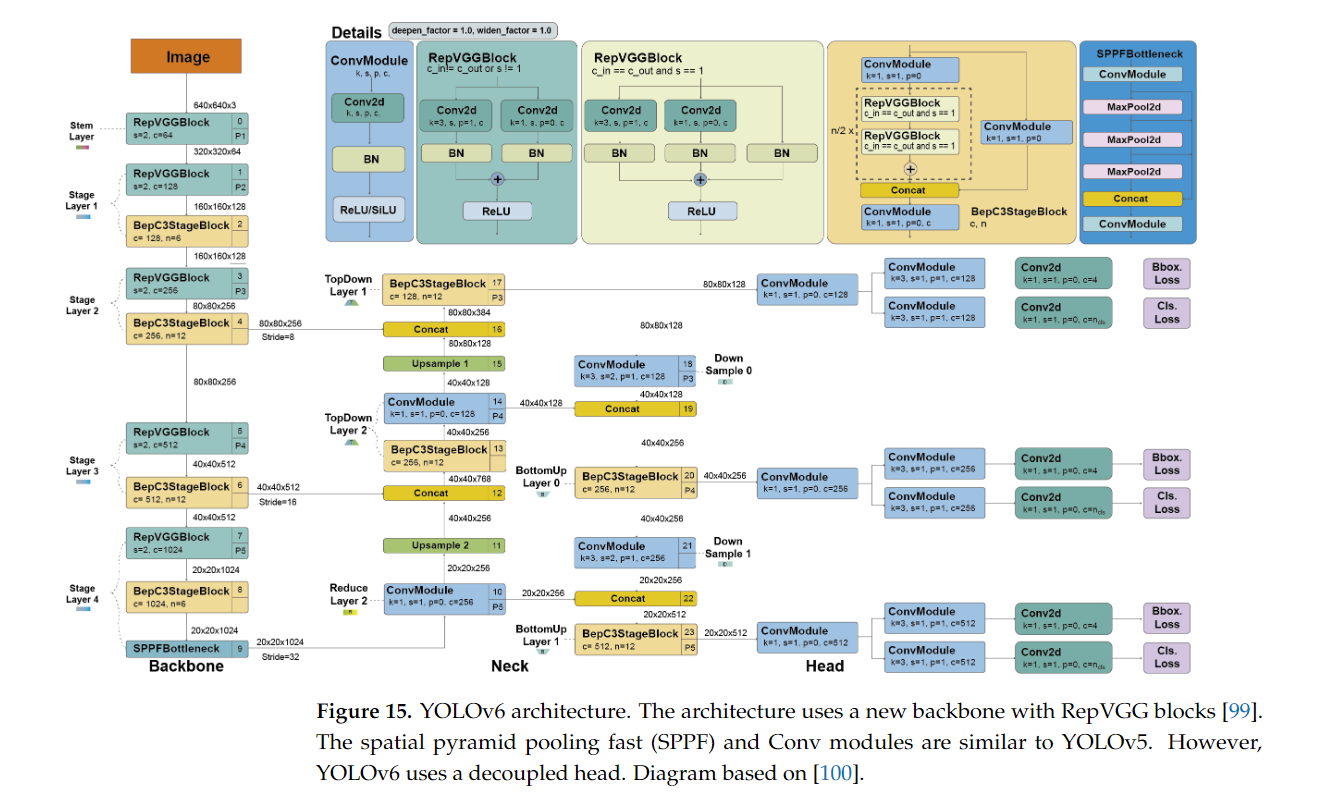
15. YOLOv7 (2022년 7월)
YOLOv7은 2022년 YOLO 모델의 개발자들이 발표한 최신 객체 탐지 모델로, 기존 YOLO 모델들의 장점을 계승하면서도 속도와 정확도에서 중요한 개선을 이루었습니다.
- 특히, YOLOv7은 실시간 객체 탐지에 최적화되어 있으며, 높은 효율성과 성능을 제공하는 모델입니다.
- 이 모델은 단일 GPU에서 최고의 성능을 발휘할 수 있도록 설계되었으며, 여러 가지 새로운 기술적 개선이 적용되었습니다.
15.1 YOLOv7의 주요 특징
-
Extended Efficient Layer Aggregation Network (ELAN)
- YOLOv7은 Extended Efficient Layer Aggregation Network (ELAN) 구조를 도입하여, 이전 YOLO 모델들보다 더 효율적인 특징 추출이 가능합니다. ELAN은 여러 계층의 특징을 효과적으로 결합하여, 네트워크의 학습 능력을 향상시키고 더 나은 특징 표현을 가능하게 합니다. 이를 통해 YOLOv7은 더 깊은 네트워크 구조에서도 효율적으로 학습할 수 있게 되었습니다.
-
Dense Detection Head
- YOLOv7은 Dense Detection Head 구조를 사용하여, 더 정밀한 객체 탐지를 가능하게 합니다. 이는 기존 YOLO 모델들이 사용한 탐지 헤드보다 더 많은 정보를 처리할 수 있으며, 작은 객체부터 큰 객체까지 더 정확하게 탐지할 수 있습니다. Dense Detection Head는 특히 작은 객체 탐지에서 성능을 크게 개선하였습니다.
-
Re-parameterization Techniques (RepConv)
- YOLOv7은 Re-parameterization 기법을 사용하여 학습 시 복잡한 모델 구조를 단순화하고, 추론 시에는 모델의 성능을 높이는 방식으로 동작합니다. 특히, YOLOv7은 RepConv 구조를 사용하여 여러 합성곱 계층을 단일 계층으로 병합하여 추론 속도를 높입니다. 이로 인해, YOLOv7은 학습 단계에서는 더 복잡한 구조를 사용하지만, 추론 단계에서는 간소화된 구조로 빠르게 동작할 수 있습니다.
-
스케일 효율성 (Scale Efficiency)
- YOLOv7은 기존 YOLO 모델보다 스케일 효율성이 뛰어납니다. 이는 모델의 파라미터 수와 연산량을 크게 줄이면서도 성능을 극대화할 수 있도록 설계되었습니다. YOLOv7은 모델 크기를 줄이면서도 높은 정확도를 유지할 수 있으며, 이를 통해 저사양 하드웨어에서도 실시간 객체 탐지가 가능합니다.
-
더 적은 연산량으로 더 높은 성능
- YOLOv7은 이전 YOLOv4 및 YOLOv5와 비교했을 때, 75% 적은 파라미터와 36% 적은 연산량으로도 더 나은 성능을 제공합니다. 이는 효율적인 모델 구조와 최적화 기법 덕분에 가능하며, 단일 GPU에서 최대 성능을 발휘할 수 있도록 설계되었습니다.
15.2 YOLOv7의 아키텍처
YOLOv7의 아키텍처는 기존 YOLO 모델들과 유사하지만, 몇 가지 중요한 최적화가 추가되었습니다:
-
Backbone: ELAN
- YOLOv7의 백본은 Extended ELAN 구조를 사용합니다. ELAN은 특징 추출을 더욱 효율적으로 수행하기 위해 여러 층에서 정보를 결합하여 신경망이 학습할 수 있는 표현을 더 풍부하게 만듭니다. 이 백본은 다양한 크기의 객체를 정확하게 탐지할 수 있도록 도와줍니다.
-
Neck: PANet
- YOLOv7은 PANet (Path Aggregation Network)을 사용하여 상위 계층과 하위 계층에서 추출된 특징을 결합하고, 작은 객체부터 큰 객체까지 모두 탐지할 수 있게 합니다. PANet은 특히 작은 객체를 더 정확하게 탐지할 수 있도록 설계되었습니다.
-
Head: Dense Detection Head
- YOLOv7의 Dense Detection Head는 각 특징 맵에서 객체를 탐지하고, 바운딩 박스의 위치, 크기, 클래스 확률을 예측합니다. Dense Detection Head는 기존 YOLO 헤드보다 더 많은 정보를 처리하여 탐지 정확도를 높이며, 특히 작은 객체에 대한 성능이 크게 개선되었습니다.
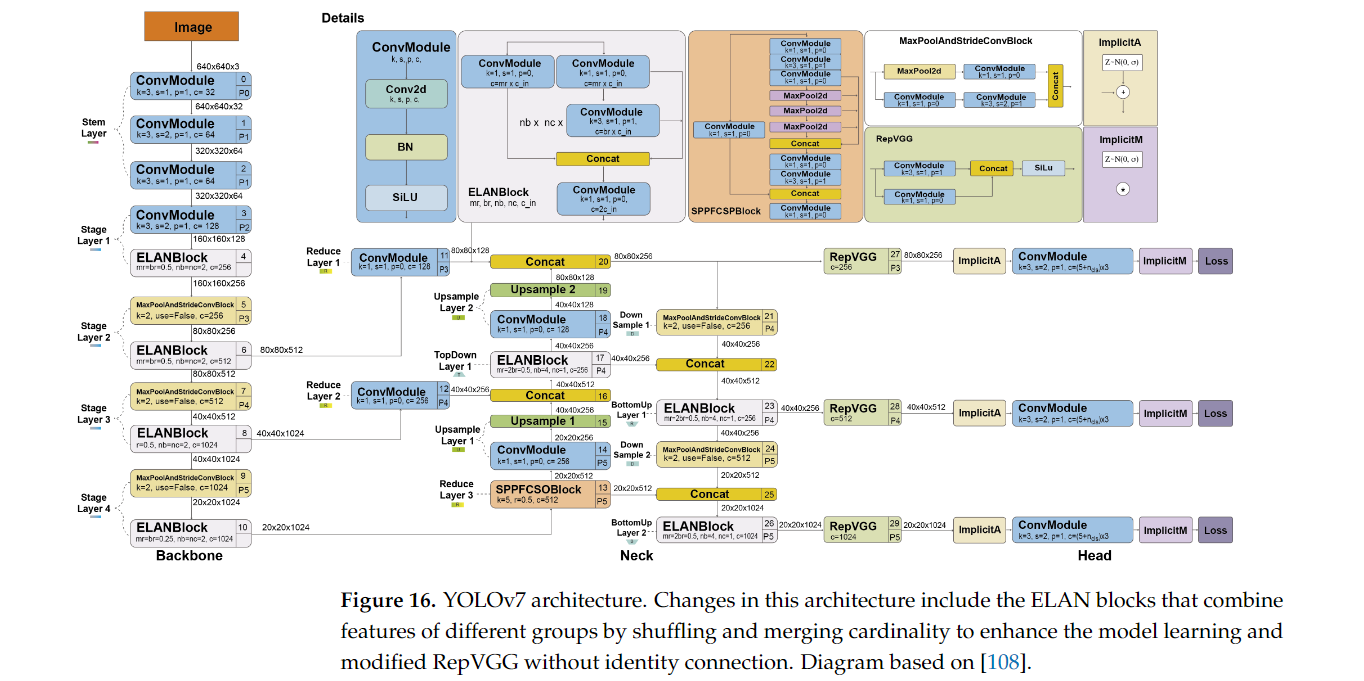
16. DAMO-YOLO (2022년 12월)
DAMO-YOLO는 2022년 알리바바의 DAMO Academy에서 개발한 최신 객체 탐지 모델로, YOLO 시리즈의 빠른 속도와 높은 정확도를 계승하면서도 여러 기술적 혁신을 통해 성능을 더욱 향상시킨 모델입니다.
- DAMO-YOLO는 주로 실시간 객체 탐지와 고성능을 목표로 설계되었으며, 특히 경량 모델에서 성능과 효율성을 극대화하는 데 중점을 두고 있습니다.
16.1 DAMO-YOLO의 주요 특징
- Neural Architecture Search (NAS) 기반 설계
- DAMO-YOLO는 신경망 아키텍처 탐색(Neural Architecture Search, NAS) 기법을 사용하여 최적의 아키텍처를 자동으로 설계합니다. NAS는 다양한 네트워크 구조를 실험하고 최적의 성능을 낼 수 있는 구조를 찾아내는 기법으로, DAMO-YOLO는 이 기법을 통해 고성능 모델을 효율적으로 개발할 수 있었습니다. 이를 통해 모델은 특정 하드웨어 환경에 최적화되며, 특히 경량화된 모델에서도 높은 성능을 발휘할 수 있습니다.
NAS(Neural Architecture Search)란?
- Neural Architecture Search(NAS)는 신경망 구조를 자동으로 설계하는 기술입니다. 전통적으로 딥러닝 모델을 설계할 때는 사람 전문가가 직접 신경망 구조를 정의하고 하이퍼파라미터를 조정하는 작업을 수행했습니다. 하지만 NAS는 이 과정을 자동화하여 최적의 신경망 구조를 탐색하는 방법을 제안합니다.
- NAS는 크게 세 가지 주요 구성 요소로 나눌 수 있습니다:
- 탐색 공간(Search Space): NAS에서 가능한 모든 신경망 구조의 집합을 정의하는 공간입니다. 예를 들어, 네트워크 깊이, 각 층의 크기, 활성화 함수, 합성곱 필터 크기 등이 탐색 대상이 될 수 있습니다.
- 탐색 전략(Search Strategy): 이 전략은 탐색 공간에서 최적의 아키텍처를 찾기 위해 사용됩니다. 여기에는 무작위 탐색, 진화 알고리즘, 강화학습 또는 그래디언트 기반 방법 등이 사용될 수 있습니다. 탐색 전략에 따라 아키텍처의 평가를 효율적으로 수행할 수 있는 방식이 결정됩니다.
- 평가 방법(Evaluation Strategy): 각 아키텍처의 성능을 평가하는 방법입니다. 이를 위해 일반적으로 아키텍처를 훈련시키고 테스트 데이터셋에서 성능을 평가합니다. 하지만 모든 아키텍처를 직접 훈련하는 것은 매우 비용이 크기 때문에, 모델을 완전하게 훈련하지 않고 성능을 예측하는 기술들이 사용되기도 합니다(예: proxy 모델, weight sharing 등).
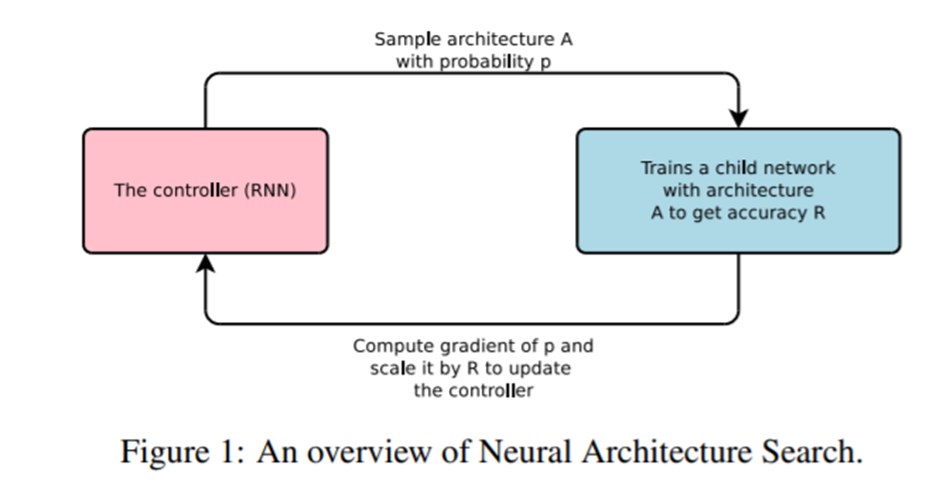
-
Anchor-free 구조
- DAMO-YOLO는 앵커리스(anchor-free) 구조를 채택하여, 기존 앵커 기반 YOLO 모델들에서 필요했던 앵커 박스 설정 과정을 생략하고도 높은 성능을 제공합니다. 앵커리스 구조는 모델의 복잡성을 줄이고, 학습과 추론을 더 간결하게 만들며, 다양한 크기의 객체에 대해 더 높은 탐지 정확도를 제공합니다.
-
Efficient Backbone
- DAMO-YOLO는 효율적인 백본 네트워크를 사용하여 높은 성능을 유지하면서도 연산량을 크게 줄였습니다. CSPNet과 유사한 경량화된 구조를 사용하여, 연산량을 줄이면서도 다양한 해상도에서 우수한 성능을 발휘합니다. 또한, 이 백본은 경량화된 환경에서도 높은 정확도를 유지할 수 있도록 설계되었습니다.
-
Dynamic Head
- DAMO-YOLO는 Dynamic Head 구조를 도입하여, 객체 탐지 헤드에서 다양한 크기와 위치의 객체를 더 정확하게 탐지할 수 있습니다. Dynamic Head는 고정된 헤드 구조 대신 입력 데이터에 따라 유동적으로 변형되며, 다양한 환경에서 더 높은 탐지 성능을 제공합니다.
-
FP16 및 INT8 양자화 지원
- DAMO-YOLO는 FP16 및 INT8 양자화를 지원하여 경량화된 디바이스에서 매우 효율적으로 동작할 수 있습니다. 양자화는 모델의 정밀도를 줄여 연산을 최적화하면서도 성능 저하를 최소화하는 기법입니다. DAMO-YOLO는 이를 통해 모바일 환경이나 임베디드 시스템에서 실시간 객체 탐지를 수행할 수 있습니다.
16.2 DAMO-YOLO의 아키텍처
DAMO-YOLO의 아키텍처는 기존 YOLO 모델들과 몇 가지 유사한 점이 있지만, NAS 기법을 통해 자동으로 설계된 최적화된 구조를 사용합니다. 이 아키텍처는 실시간 객체 탐지에서 최고의 성능을 낼 수 있도록 설계되었습니다:
-
Backbone: Lightweight Efficient Backbone
- DAMO-YOLO는 CSPNet 기반의 백본을 사용하여 경량화와 성능을 모두 극대화했습니다. 이 백본은 다양한 크기의 특징 맵을 효율적으로 추출하여 객체 탐지 성능을 높이며, 연산량을 줄여 더 빠른 추론 속도를 제공합니다.
-
Neck: PANet
- YOLO 모델에서 자주 사용되는 PANet (Path Aggregation Network) 구조를 사용하여, 상위 계층과 하위 계층에서 추출된 특징을 결합하여 다양한 크기의 객체를 탐지할 수 있습니다. 특히, PANet은 작은 객체 탐지 성능을 크게 개선합니다.
-
Head: Dynamic Head
- DAMO-YOLO의 Dynamic Head는 기존 고정된 구조의 탐지 헤드 대신, 입력 데이터의 특성에 맞춰 유연하게 조정되는 구조를 사용합니다. 이를 통해 다양한 크기와 복잡한 장면에서 객체를 더 정확하게 탐지할 수 있으며, 다양한 환경에서 높은 성능을 발휘합니다.
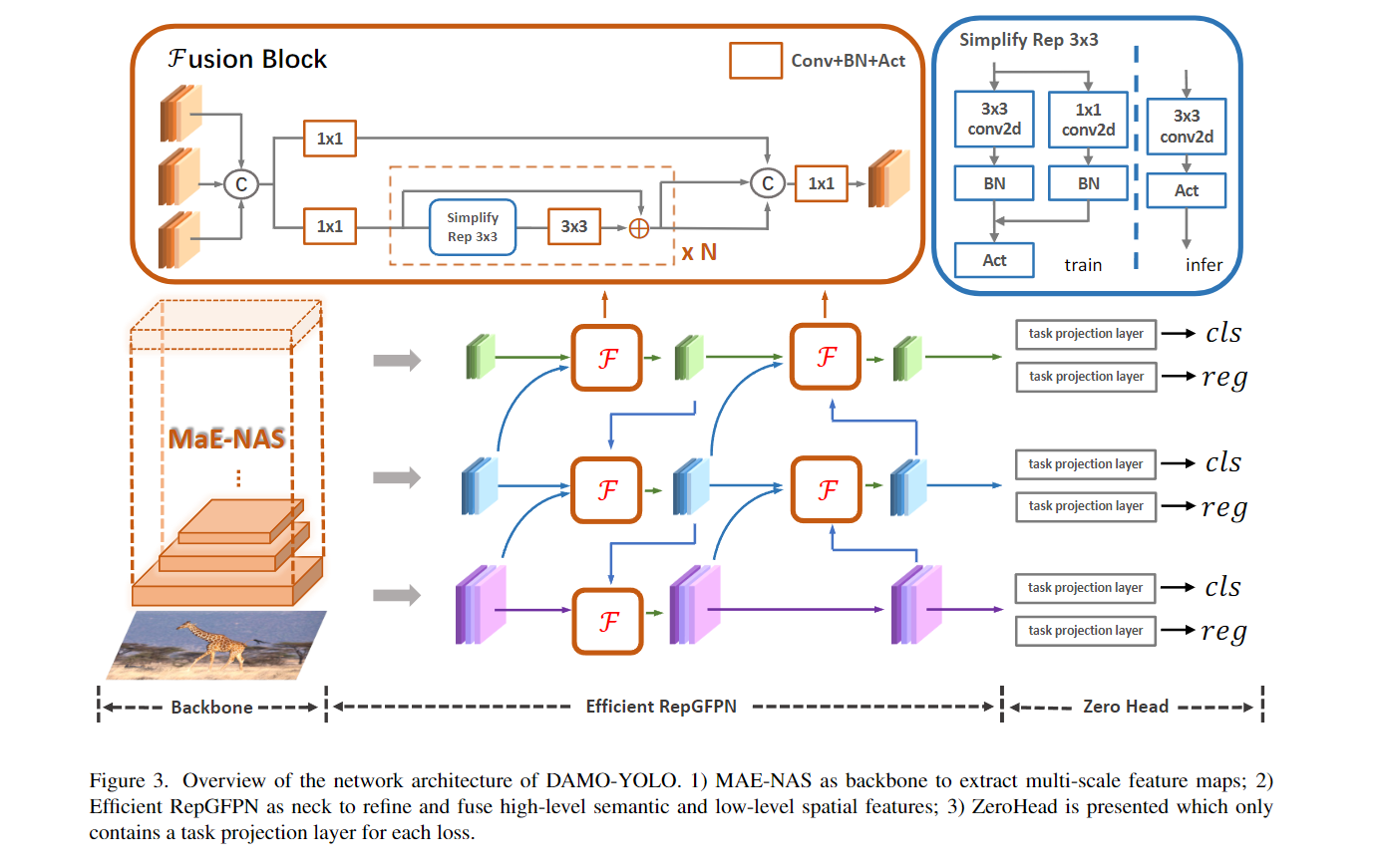
17. YOLOv8 (2023년 1월)
YOLOv8은 2023년 1월 Ultralytics에 의해 발표된 최신 객체 탐지 모델로, YOLO 시리즈의 가장 최근 버전입니다. YOLOv8은 이전 버전인 YOLOv5의 개선된 구조를 기반으로 더 높은 성능을 제공하며, 특히 경량화와 정확도 모두에서 큰 성장을 이루었습니다.
- YOLOv8은 객체 탐지뿐만 아니라 세그멘테이션, 분류, 포즈 추정 등 다양한 컴퓨터 비전 작업에 적합하게 설계되었습니다.
- YOLOv8은 PyTorch 기반으로 구현되어 있으며, 사용자들이 쉽게 사용할 수 있도록 최적화되었습니다.
- YOLOv8은 모델 구조의 간소화, 성능 최적화, 더 나은 데이터 증강 기법 적용을 통해 실시간 객체 탐지에서 뛰어난 성능을 발휘합니다.
17.1 YOLOv8의 주요 특징
-
Anchor-free 구조
- YOLOv8은 앵커리스(anchor-free) 탐지 방식을 채택하였습니다. 이 방식은 기존 YOLO 모델들에서 사용되었던 앵커 박스(anchor boxes) 설정이 불필요하며, 객체의 중심점을 기반으로 바운딩 박스를 예측합니다. 이를 통해 모델 구조가 간소화되고 학습 속도가 빨라졌으며, 앵커 박스 조정에 대한 복잡성이 사라졌습니다.
-
Improved Backbone: C2f 모듈
- YOLOv8은 YOLOv5에서 사용된 CSPNet 백본 대신 C2f (Cross Stage Partial with Focus) 모듈을 도입하여 성능을 개선하였습니다.
C2f 모듈은 경량화된 구조로, 모델의 연산량을 줄이면서도 더 강력한 특징 추출을 가능하게 합니다. 이로 인해 YOLOv8은 YOLOv5보다 더 나은 성능을 발휘합니다.
-
Decoupled Head 구조
- YOLOv8은 디커플드 헤드(Decoupled Head) 구조를 사용하여, 객체성(objectness), 회귀(regression), 분류(classification) 작업을 분리하여 처리합니다.
- 기존의 YOLO 모델들이 모든 작업을 하나의 헤드에서 동시에 처리했던 것과 달리, YOLOv8은 각각의 작업을 독립적으로 처리하여 탐지 성능을 더욱 개선했습니다. 이 방식은 특히 객체의 크기와 위치 예측을 더욱 정확하게 만듭니다.
-
높은 확장성: 다양한 모델 크기 제공
- YOLOv8은 다양한 크기의 모델을 제공하여 사용자가 자신의 용도에 맞게 선택할 수 있습니다. 경량화된 모델부터 대형 모델까지 선택할 수 있어, 작은 디바이스에서도 사용할 수 있으며 고성능 시스템에서는 최고의 성능을 발휘할 수 있습니다.
- YOLOv8n (nano): 매우 경량화된 모델로, 임베디드 시스템 및 모바일 장치에 적합.
- YOLOv8s (small): 빠르고 효율적인 성능을 제공하는 모델로, 중간 수준의 작업에 적합.
- YOLOv8m (medium): 더 복잡한 작업에서도 높은 성능을 발휘하는 모델.
- YOLOv8l (large) 및 YOLOv8x (extra-large): 고성능을 필요로 하는 작업에 적합하며, 높은 정확도를 제공합니다.
- YOLOv8은 다양한 크기의 모델을 제공하여 사용자가 자신의 용도에 맞게 선택할 수 있습니다. 경량화된 모델부터 대형 모델까지 선택할 수 있어, 작은 디바이스에서도 사용할 수 있으며 고성능 시스템에서는 최고의 성능을 발휘할 수 있습니다.
-
세그멘테이션 및 포즈 추정 지원
- YOLOv8은 객체 탐지 외에도 세그멘테이션, 포즈 추정, 추적, 분류 작업을 지원합니다. 이를 통해 단일 모델로 여러 작업을 동시에 수행할 수 있으며, 컴퓨터 비전 분야에서의 활용도를 더욱 넓혔습니다.
-
손실 함수: DFL 및 CIoU
- YOLOv8은 바운딩 박스 예측에 대해 CIoU (Complete Intersection over Union) 손실 함수를 사용하여 위치 예측의 정확도를 높였습니다. 또한, DFL (Distribution Focal Loss)을 사용하여 바운딩 박스의 경계 예측 성능을 더욱 향상시켰습니다.
17.2 YOLOv8의 아키텍처
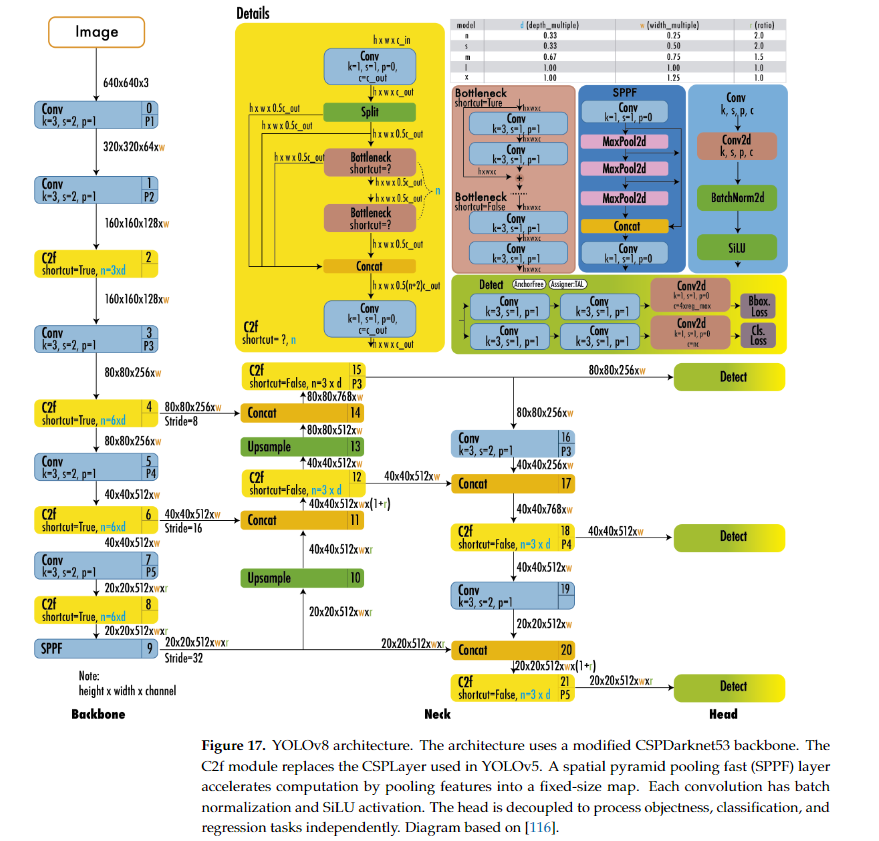
- YOLOv8의 아키텍처는 기존 YOLOv5와 유사하지만, 여러 가지 중요한 개선 사항이 포함되어 있습니다:
-
Backbone: C2f 모듈
- YOLOv8은 YOLOv5에서 사용된 CSPNet 대신 C2f (Cross Stage Partial with Focus) 백본을 사용하여 더 효율적인 특징 추출을 가능하게 합니다. C2f 모듈은 연산량을 줄이면서도 고성능을 유지할 수 있게 도와줍니다.
-
Neck: PANet
- YOLOv8은 PANet (Path Aggregation Network) 구조를 사용하여 상위 계층과 하위 계층에서 추출된 특징을 결합하고, 다양한 크기의 객체를 탐지할 수 있도록 지원합니다.
-
Head: Decoupled Head
- YOLOv8의 헤드는 디커플드 헤드 구조를 사용하여 객체성, 분류, 회귀 작업을 각각 독립적으로 처리합니다. 이를 통해 각 작업의 정확도가 더욱 향상되며, 특히 객체의 위치 예측과 크기 예측에서 성능이 크게 개선되었습니다.
18. PP-YOLO, PP-YOLOv2, PP-YOLOE
PP-YOLO 시리즈는 PaddlePaddle 프레임워크를 기반으로 한 객체 탐지 모델로, Baidu의 AI 연구소에서 개발되었습니다.
- PP-YOLO는 기존 YOLOv3 모델을 기반으로 다양한 최적화 기법을 적용하여 성능을 향상시킨 모델이며, 이후 PP-YOLOv2와 PP-YOLOE로 발전해 왔습니다.
- PP-YOLO 시리즈는 YOLO의 강력한 실시간 성능을 유지하면서도 정확도와 효율성을 크게 개선하였습니다.
패들패들(PaddlePaddle)이란?
패들패들(PaddlePaddle)은 바이두에서 개발한 오픈소스 딥러닝 프레임워크입니다. 이 프레임워크의 이름은 'PArallel Distributed Deep LEarning'의 앞글자를 따서 만들어졌습니다.
- C++로 작성되었으며 파이썬 인터페이스를 제공합니다.
- 수학 연산 성능, 분산 환경, 그리고 순환 신경망에 대해 최적화되었습니다.
- 바이두의 여러 제품에 이미 널리 적용되고 있습니다.
18.1 PP-YOLO (2020)
- PP-YOLO는 2020년에 발표된 모델로, YOLOv3를 기반으로 여러 가지 최적화 기법을 도입하여 성능을 크게 향상시킨 객체 탐지 모델입니다.
- PP-YOLO는 PaddlePaddle이라는 오픈소스 딥러닝 프레임워크에서 구현되었으며, 기존 YOLOv3보다 높은 성능을 자랑합니다.
-
PP-YOLO의 주요 최적화 기법
- PP-YOLO는 YOLOv3에 여러 가지 Bag of Tricks 기법을 적용하여 성능을 높였습니다:
- ResNet50-vd 백본: YOLOv3의 Darknet 백본 대신 ResNet50-vd를 사용하여 특징 추출 성능을 개선하였습니다. ResNet50-vd는 더 깊은 신경망 구조를 가지고 있으며, 더 정교한 특징을 추출할 수 있습니다.
- DropBlock: 과적합을 방지하기 위해 DropBlock을 도입하여, 신경망의 일반화 성능을 개선하였습니다.
- IoU-Aware Loss: 바운딩 박스 예측 시 IoU 기반 손실 함수(IoU-Aware Loss)를 적용하여, 위치 예측의 정확도를 향상시켰습니다.
- Grid Sensitive: 그리드 셀의 중심 위치를 고려하여 위치 예측 성능을 개선하였습니다.
- Matrix NMS: 기존의 NMS(Non-Maximum Suppression) 방식보다 성능이 향상된 Matrix NMS 기법을 사용하여 중복된 바운딩 박스를 효과적으로 제거합니다.
- CoordConv: 객체의 위치와 좌표 정보를 더 잘 학습할 수 있도록 CoordConv를 적용하였습니다.
- PP-YOLO는 YOLOv3에 여러 가지 Bag of Tricks 기법을 적용하여 성능을 높였습니다:
-
PP-YOLO 성능
- PP-YOLO는 MS COCO 데이터셋에서 AP50 45.2%를 기록하며, 기존 YOLOv3에 비해 성능이 크게 개선되었습니다.
- 특히, PP-YOLO는 YOLOv3보다 더 높은 정확도와 빠른 속도를 제공합니다.
18.2 PP-YOLOv2 (2021)
- PP-YOLOv2는 2021년에 발표된 PP-YOLO의 업그레이드 버전으로, 기존 PP-YOLO의 성능을 더욱 향상시키기 위해 몇 가지 추가적인 최적화 기법을 도입하였습니다.
-
PP-YOLOv2의 주요 개선 사항
- ResNet101-vd 백본: PP-YOLOv2는 ResNet50-vd 대신 ResNet101-vd 백본을 사용하여 더 깊은 네트워크를 통해 특징 추출 성능을 향상시켰습니다.
- Path Aggregation Network (PANet): PP-YOLOv2는 Neck 구조로 PANet을 도입하여 상하위 계층의 특징을 결합하고, 작은 객체부터 큰 객체까지 더 정확하게 탐지할 수 있게 하였습니다.
- Deformable Convolution (DCNv2): 특징 추출 성능을 극대화하기 위해 DCNv2를 도입하여, 객체의 크기와 위치에 따라 더 유연한 특징 맵을 생성할 수 있게 하였습니다.
- IoU Loss & GIoU Loss: PP-YOLOv2는 바운딩 박스 예측 성능을 높이기 위해 IoU Loss 및 GIoU (Generalized IoU) Loss를 사용하여 예측 정확도를 더욱 개선했습니다.
-
PP-YOLOv2 성능
- PP-YOLOv2는 MS COCO 데이터셋에서 AP50 49.5%를 기록하며, PP-YOLO보다 약 4%의 성능 향상을 보였습니다.
- 또한, PP-YOLOv2는 더 높은 해상도의 이미지를 처리할 수 있으며, 복잡한 장면에서도 높은 정확도를 제공합니다.
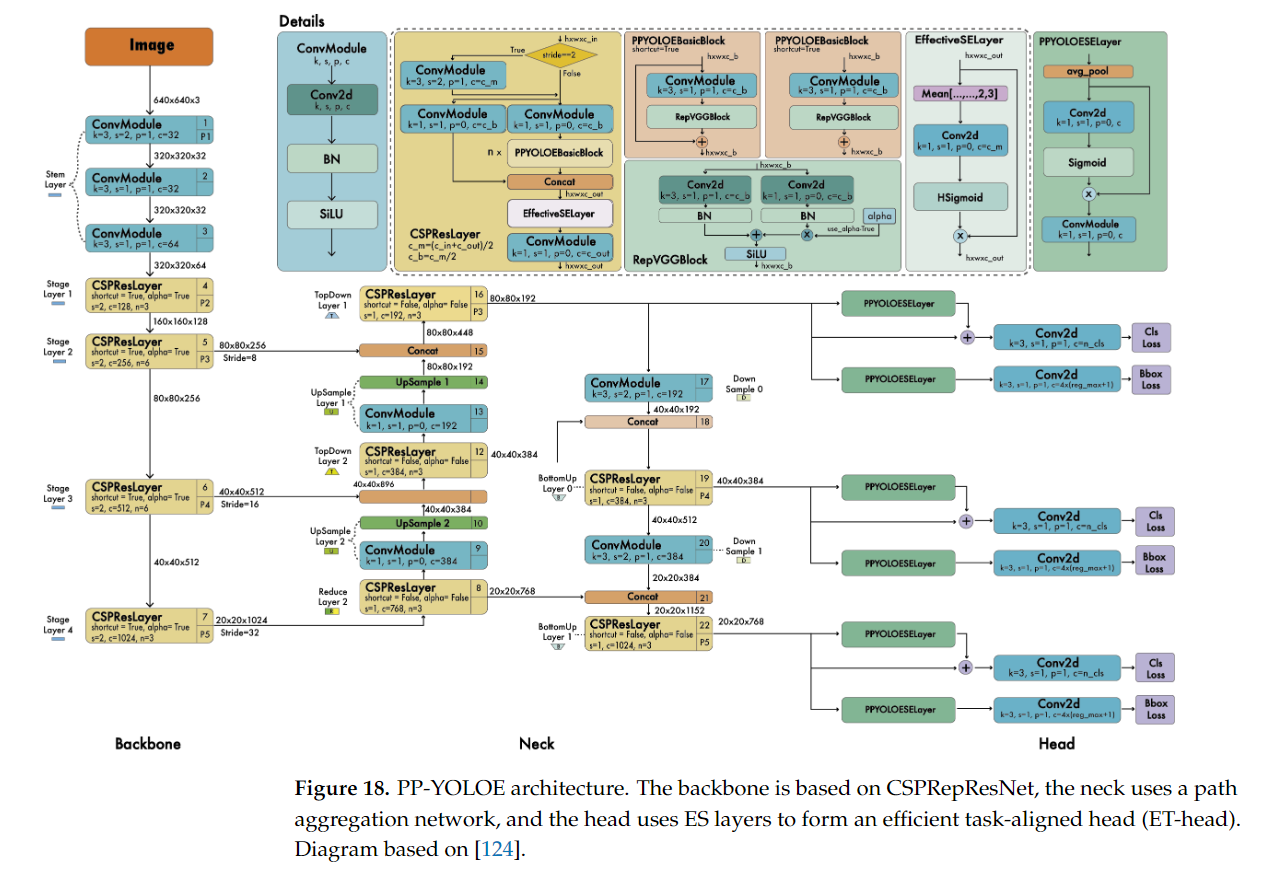
18.3 PP-YOLOE (2022)
- PP-YOLOE는 PP-YOLO 시리즈의 최신 모델로, 2022년에 발표되었습니다.
- PP-YOLOE는 성능을 극대화하기 위해 앵커리스 탐지 방식을 도입하였으며, 경량화된 모델부터 대형 모델까지 다양한 크기를 제공합니다.
- PP-YOLOE는 실시간 객체 탐지에서 최상의 성능을 제공하기 위해 설계되었습니다.
-
PP-YOLOE의 주요 개선 사항
- Anchor-free 구조: PP-YOLOE는 앵커리스 탐지 방식을 채택하여, 기존의 앵커 기반 모델보다 더 간단한 구조로 빠른 학습과 추론이 가능합니다. 앵커리스 방식은 모델의 복잡성을 줄이고, 다양한 크기의 객체 탐지 성능을 향상시킵니다.
- TAL (Task Alignment Learning): PP-YOLOE는 TAL(Task Alignment Learning) 기법을 도입하여, 객체 탐지와 회귀 작업 간의 상호작용을 최적화하였습니다. TAL은 객체 탐지에서 위치와 클래스 예측의 균형을 맞추어 탐지 성능을 높입니다.
- Decoupled Head: YOLOv8과 유사하게, PP-YOLOE도 디커플드 헤드(Decoupled Head) 구조를 사용하여, 객체 탐지 작업을 분리하여 더 정확하게 처리합니다.
- Advanced Data Augmentation: PP-YOLOE는 Mosaic, Copy-paste와 같은 최신 데이터 증강 기법을 사용하여 학습 데이터의 다양성을 극대화하고, 더 일반화된 성능을 제공합니다.
-
PP-YOLOE 성능
- PP-YOLOE는 다양한 크기의 모델을 제공하여 경량 모델부터 대형 모델까지 선택할 수 있습니다.
- MS COCO 데이터셋에서 AP50 50.0% 이상의 성능을 기록하며, 특히 실시간 객체 탐지에서 우수한 성능을 제공합니다.
- PP-YOLOE는 경량화된 환경에서도 높은 정확도를 유지하면서 빠른 추론 속도를 제공합니다.
19. YOLO-NAS
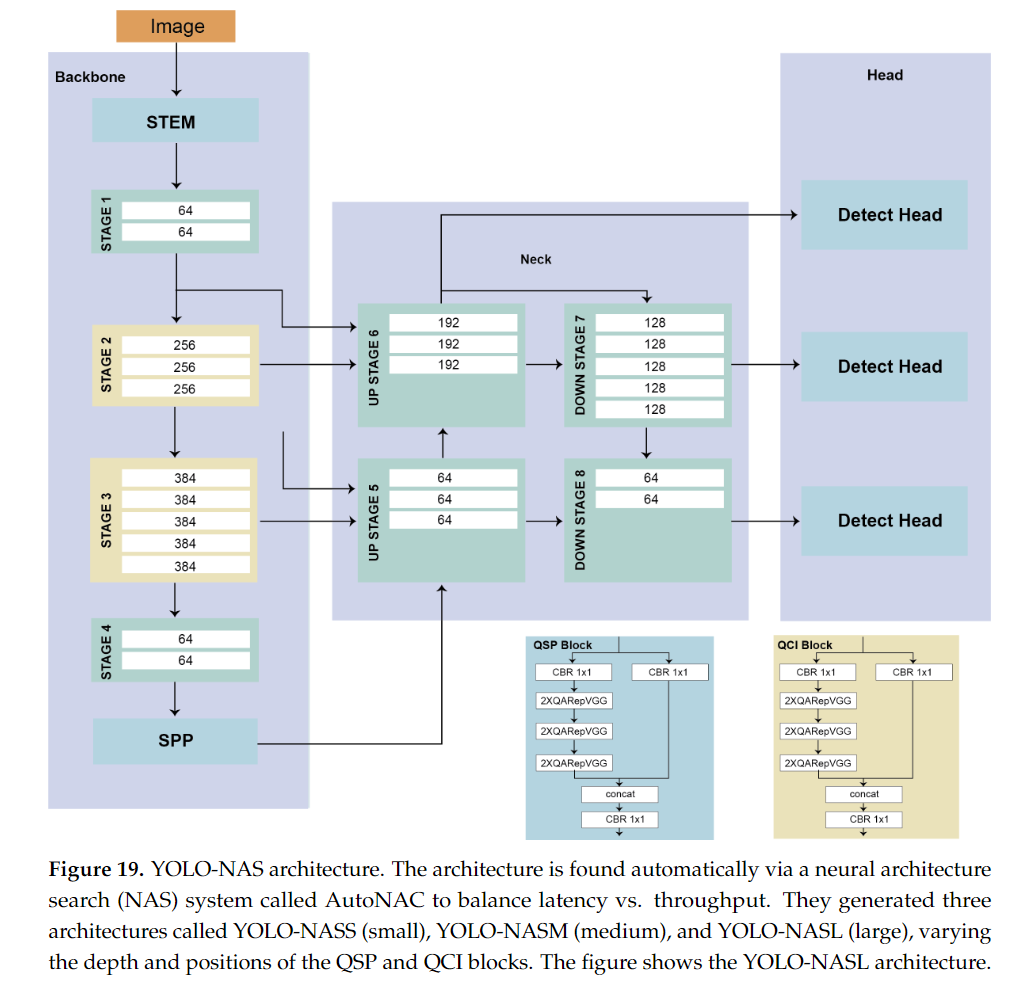
YOLO-NAS는 2023년 5월에 Deci라는 AI 스타트업에서 발표한 최신 객체 탐지 모델로, YOLO 시리즈의 강력한 성능을 기반으로 자동 신경망 아키텍처 탐색(NAS: Neural Architecture Search)을 통해 성능을 최적화한 모델입니다.
- YOLO-NAS는 YOLOv8과 유사한 성능을 제공하면서도, 더 높은 정확도와 효율성을 목표로 설계되었습니다.
- 특히 YOLO-NAS는 실시간 객체 탐지에 적합하도록 최적화되었으며, 다양한 크기와 연산 자원을 고려하여 효율성을 극대화한 것이 특징입니다.
19.1 YOLO-NAS의 주요 특징
-
Neural Architecture Search (NAS) 기반 설계
- YOLO-NAS는 자동 신경망 아키텍처 탐색(NAS) 기법을 통해 개발되었습니다.
- NAS는 머신러닝을 사용해 최적의 네트워크 구조를 자동으로 설계하는 방법으로, YOLO-NAS는 이 기법을 통해 최적화된 아키텍처를 구축하여 연산 효율성과 성능을 극대화했습니다.
- NAS를 통해 YOLO-NAS는 다양한 하드웨어 환경에서도 최적의 성능을 발휘할 수 있는 구조로 설계되었습니다.
-
Anchor-free 구조
- YOLO-NAS는 기존의 앵커 박스(anchor boxes)를 사용하는 방식 대신, 앵커리스(anchor-free) 객체 탐지 방식을 채택했습니다.
- 이는 객체 중심점에서 직접 바운딩 박스를 예측하는 방식으로, 앵커 박스 설정의 복잡성을 제거하고 더 빠르고 정확한 탐지를 가능하게 합니다.
- 앵커리스 방식은 학습 속도를 가속화하고, 모델의 간소화를 돕습니다.
-
Decoupled Head
- YOLO-NAS는 디커플드 헤드(Decoupled Head) 구조를 사용하여, 객체 탐지의 세 가지 주요 작업인 객체성(objectness), 회귀(regression), 분류(classification)를 독립적으로 처리합니다. 이를 통해 각 작업의 효율성을 최적화하고, 더 높은 탐지 정확도를 제공합니다.
-
추론 속도 및 정확도 최적화
- YOLO-NAS는 객체 탐지 성능을 극대화하면서도 추론 속도를 최적화하도록 설계되었습니다. 이는 특히 엣지 디바이스나 임베디드 시스템과 같은 제한된 자원 환경에서 매우 중요한 특징입니다. YOLO-NAS는 실시간 성능을 제공하면서도 높은 정확도를 유지하며, 다양한 응용 분야에서 강력한 성능을 자랑합니다.
-
양자화 지원
- YOLO-NAS는 양자화(quantization)를 지원하여 모델의 크기를 줄이고, 더 적은 연산 자원으로도 높은 성능을 발휘할 수 있습니다. 특히 8비트 양자화를 지원하여, 메모리 사용량과 연산 시간을 줄이면서도 성능 저하 없이 효율적인 객체 탐지를 수행할 수 있습니다. 이는 모바일 장치나 엣지 디바이스와 같은 경량화된 하드웨어에서 매우 유용합니다.
-
Task-aware Attention (TAA) 기법
- YOLO-NAS는 Task-aware Attention (TAA) 메커니즘을 통해 객체 탐지 작업에서 중요한 특징을 자동으로 학습하고, 여러 작업 간의 상호작용을 최적화하여 성능을 극대화합니다. TAA는 모델이 각 작업(분류, 위치 예측 등)에서 중요한 정보를 효율적으로 처리할 수 있도록 돕습니다.
19.2 YOLO-NAS의 아키텍처
- YOLO-NAS의 아키텍처는 기존 YOLO 모델들과 유사하지만, NAS 기법을 통해 최적화된 구조를 갖추고 있으며, 더 높은 효율성을 제공합니다:
-
Backbone
- YOLO-NAS는 EfficientNet이나 CSPNet과 유사한 경량 백본을 사용하여, 연산 효율성을 극대화하면서도 특징 추출 성능을 높였습니다. 이 백본은 경량화된 구조이면서도 강력한 특징 학습 능력을 제공합니다.
-
Neck
- YOLO-NAS는 Path Aggregation Network (PANet)과 같은 구조를 사용하여 상위 및 하위 계층의 특징을 결합합니다. 이를 통해 다양한 크기의 객체를 탐지할 수 있도록 지원합니다.
-
Head: Decoupled Head
- YOLO-NAS의 디커플드 헤드(Decoupled Head)는 분류, 회귀, 객체성 작업을 각각 독립적으로 처리하여 더 높은 탐지 성능을 제공합니다. 이 구조는 기존 YOLO 모델들보다 더 정교한 탐지를 가능하게 하며, 특히 작은 객체 탐지 성능이 크게 향상되었습니다.
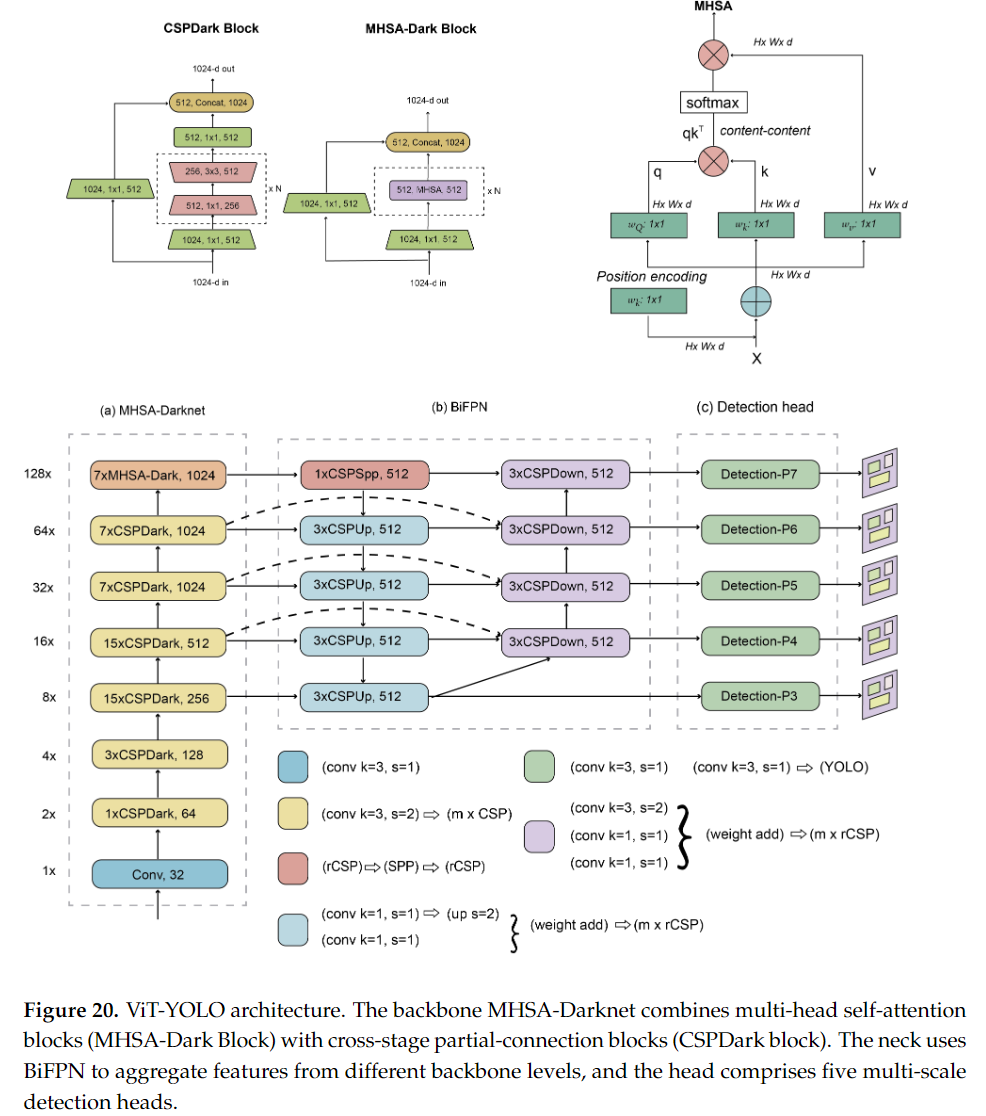
20. YOLO with Transformers
YOLO with Transformers는 YOLO 모델과 트랜스포머(Transformers) 아키텍처를 결합한 새로운 객체 탐지 모델로, 자연어 처리(NLP) 분야에서 성공적으로 사용된 트랜스포머 구조를 컴퓨터 비전에 적용하여 객체 탐지 성능을 극대화한 모델입니다.
-
트랜스포머는 기존 합성곱 신경망(CNN) 기반의 모델들이 갖는 한계를 극복하고, 더 긴 범위의 종속성을 학습할 수 있는 장점을 제공하여, 컴퓨터 비전 분야에서도 자기 주의 메커니즘(Self-Attention Mechanism)을 통해 탁월한 성능을 발휘하고 있습니다.
-
이를 YOLO와 결합함으로써, 트랜스포머의 장점과 YOLO의 실시간 탐지 성능을 결합한 새로운 객체 탐지 모델을 만들었습니다.
20.1 트랜스포머(Transformers) 개요
- 트랜스포머는 원래 자연어 처리 작업에서 문장의 각 단어 간의 종속성을 학습하기 위해 개발된 모델입니다.
- 트랜스포머는 자기 주의 메커니즘(Self-Attention)을 통해, 입력의 각 요소가 다른 모든 요소와의 관계를 학습할 수 있습니다.
- 이 메커니즘은 이미지와 같은 비정형 데이터에서도 적용할 수 있으며, 이를 통해 이미지 내의 모든 픽셀 간 상호작용을 학습할 수 있습니다.
20.2 YOLO와 트랜스포머 결합의 필요성
- 기존 YOLO 모델은 합성곱 신경망(CNN)을 사용하여 입력 이미지에서 국소적인 특징을 추출하고 이를 바탕으로 객체를 탐지합니다.
- CNN은 인접한 픽셀 간의 관계를 잘 학습할 수 있는 반면, 장거리 관계를 학습하는 데는 한계가 있습니다.
- 이미지 내에서 장거리 종속성(Long-Range Dependency)을 학습하는 데 트랜스포머가 탁월한 성능을 발휘하기 때문에, YOLO와 트랜스포머를 결합하면 이미지 내의 모든 픽셀 간의 상호작용을 학습할 수 있어, 더 정밀한 객체 탐지가 가능합니다.
20.3 YOLO with Transformers의 주요 특징
-
Self-Attention Mechanism
- 트랜스포머 기반의 모델들은 자기 주의(Self-Attention) 메커니즘을 통해 이미지 내의 모든 요소 간의 상관관계를 학습할 수 있습니다.
- 이는 이미지의 특정 부분이 다른 부분과 어떻게 연결되어 있는지에 대한 정보를 더욱 잘 반영할 수 있으며, 특히 복잡한 장면에서 객체 탐지 성능을 향상시킵니다.
-
Global Context Learning
- YOLO와 트랜스포머의 결합은 이미지의 전역 정보(Global Context)를 학습할 수 있다는 장점이 있습니다.
- CNN은 국소적 필터로 인해 이미지의 작은 부분에만 집중하는 경향이 있지만, 트랜스포머는 전체 이미지를 동시에 분석하므로 더 넓은 문맥을 학습할 수 있습니다.
- 이를 통해, 더 정확한 객체 탐지 및 위치 예측이 가능합니다.
-
Hierarchical Feature Learning
- YOLO with Transformers는 트랜스포머의 전역 정보 학습 능력과 YOLO의 계층적 특징 학습(Hierarchical Feature Learning)을 결합합니다.
- YOLO는 다양한 크기의 특징 맵을 생성하여 여러 크기의 객체를 탐지할 수 있지만, 트랜스포머는 이러한 특징 맵 내에서 픽셀 간의 관계를 더 잘 학습할 수 있습니다.
- 이를 통해 다중 스케일 탐지 성능이 향상됩니다.
-
Spatial and Channel Attention
- 트랜스포머는 이미지의 공간적 특징(Spatial Features)과 채널 간 상호작용(Channel Interaction)을 동시에 학습할 수 있는 능력이 있습니다.
- YOLO with Transformers는 이러한 트랜스포머의 능력을 활용하여, 이미지 내의 중요한 영역과 채널 간의 상호작용을 학습하여 탐지 성능을 극대화합니다.
20.4 트랜스포머 기반의 YOLO 모델들
-
DETR (Detection Transformer)
- DETR는 트랜스포머를 처음으로 객체 탐지에 성공적으로 적용한 모델로, 트랜스포머 아키텍처를 기반으로 전역적인 관계를 학습하고 객체 탐지 성능을 극대화하였습니다.
- DETR은 YOLO와 결합하여 장거리 정보와 국소적 정보를 동시에 처리할 수 있으며, 더 복잡한 장면에서 뛰어난 성능을 발휘합니다.
-
Swin Transformer 기반 YOLO
- Swin Transformer는 트랜스포머를 컴퓨터 비전에 더 적합하게 개선한 모델로, 윈도우 기반(Self-Attention) 메커니즘을 사용하여 이미지의 각 영역을 국소적으로 학습하면서도 전역적인 문맥을 유지합니다.
- Swin Transformer와 YOLO의 결합은 더 효율적인 전역 특징 학습을 가능하게 하며, 고해상도 이미지에서도 뛰어난 성능을 제공합니다.
-
YOLO-ViT (Vision Transformer)
- YOLO-ViT는 YOLO 모델과 비전 트랜스포머(ViT: Vision Transformer)를 결합한 모델입니다.
- ViT는 순수 트랜스포머 아키텍처를 사용하여 이미지 내의 모든 패치(patch) 간의 상호작용을 학습할 수 있습니다.
- YOLO-ViT는 ViT의 장점인 전역 상호작용 학습을 활용하여, 더 정확한 바운딩 박스 예측과 객체 탐지를 수행합니다.
Discussion
-
YOLO 버전 분석: 16개의 YOLO 버전을 분석하고, 각각의 주요 패턴을 식별합니다.
-
앵커(Anchors): 원래 YOLO 모델은 앵커를 사용하지 않았으나, 이후 YOLOv2에서 앵커가 도입되어 바운딩 박스 예측 정확도 개선에 기여하였습니다. 이후 YOLOX는 앵커 없는 접근 방식을 도입해 상태에서의 최고의 결과를 달성했습니다.
-
프레임워크: 초기 YOLO 버전은 Darknet 프레임워크를 사용하였으나, YOLOv3부터 PyTorch로 포팅되면서 이후 버전들은 PyTorch 기반으로 발전하였습니다.
-
백본(Backbone): YOLO 모델의 백본 아키텍처는 Darknet에서 시작하여, 이후 CSP, 재파라미터화 및 Neural Architecture Search를 포함한 다양한 구조로 발전하였습니다.
-
성능: YOLO 모델은 속도와 정확성 간의 균형을 지속적으로 추구하여, 다양한 애플리케이션에 실시간 객체 감지를 가능하게 하는 것이 특징입니다.
The Future of YOLO
-
최신 기술 적용: YOLO 아키텍처를 지속적으로 개선하여 모델 성능과 효율성을 높이는 최신 딥러닝 및 데이터 증강 기법을 채택할 것으로 기대됩니다.
-
벤치마크의 진화: 현재의 COCO 2017 벤치마크는 더 도전적인 기준으로 향후 대체될 가능성이 있으며, 이는 YOLO 모델의 발전과 함께 더욱 정교한 기준을 요구하는 필요성을 반영합니다.
-
YOLO 모델 및 응용의 확산: 매년 더 많은 YOLO 모델이 출시되고 다양한 분야에서의 응용이 확대될 것으로 예상됩니다.
-
새로운 도메인으로의 확장: YOLO 모델이 객체 감지 및 세그멘테이션을 넘어 비디오에서 객체 추적, 3D 키포인트 추정과 같은 새로운 분야로 확장될 가능성이 있습니다.
-
다양한 하드웨어에 대한 적응성: YOLO 모델은 IoT 장치에서 고성능 컴퓨팅 클러스터까지 다양한 하드웨어 플랫폼에 적응할 수 있을 것으로 예상되며, 이는 사용자 및 산업의 요구와 제약에 따라 맞춤형으로 배포될 수 있도록 합니다.
이상으로 YOLO Survey 논문을 다루어봤는데요. YOLO 버전들이 너무 많아서 정리할 엄두가 안나다가 Survey Paper를 발견한 김에 정리해보았습니다 🤗
