[Paper Review] LLM-Det : Learning Strong Open-Vocabulary Object Detectors under the Supervision of Large Language Models

본 리뷰는 원문을 최대한 직역한 내용입니다. 여기서 "우리는"은 저자를 지칭합니다. 참고 부탁드립니다.
Abstract
최근 open-vocabulary detector들은 풍부한 region-level 주석 데이터로 유망한 성능을 달성하고 있습니다.
(참고) Region-level 주석 데이터란?
- Region-level 주석 데이터는 이미지에서 특정 영역(bounding box)과 그 영역에 해당하는 텍스트 설명을 연결한 데이터를 말합니다. 예를 들어:
- 이미지에서 사람이 있는 영역 → "person"
- 이미지에서 자동차가 있는 영역 → "car"
- 이미지에서 나무가 있는 영역 → "tree"
본 연구에서는 large language model과 함께 각 이미지에 대한 image-level 상세 caption을 생성하여 co-training하는 open-vocabulary detector가 성능을 더욱 향상시킬 수 있음을 보여줍니다.
(참고) Region-level vs Image-level
- Region-level만 사용한 경우:
- "사람", "주방", "접시"
- Image-level caption 추가한 경우:
- "이미지에는 두 사람이 주방에 있습니다. 왼쪽 사람은 빨간색, 파란색, 흰색 무늬의 체크 셔츠를 입고 있으며... 오른쪽 사람은 진한 파란색 티셔츠를 입고 싱크대에서 설거지를 하고 있습니다..."
이 목표를 달성하기 위해 먼저 GroundingCap-1M 데이터셋을 수집했습니다. 이 데이터셋의 각 이미지는 관련 grounding label과 image-level 상세 caption이 함께 제공됩니다. 이 데이터셋을 통해 표준 grounding loss와 caption generation loss를 포함한 훈련 목표로 open-vocabulary detector를 fine-tuning합니다.
Large language model을 활용하여 각 관심 영역에 대한 region-level 짧은 caption과 전체 이미지에 대한 image-level 긴 caption을 모두 생성합니다. Large language model의 지도하에 결과로 나온 detector인 LLMDet은 기준선을 명확한 차이로 능가하며, 뛰어난 open-vocabulary 능력을 보여줍니다. 또한 개선된 LLMDet이 더 강력한 large multi-modal model을 구축하여 상호 이익을 달성할 수 있음을 보여줍니다.
1. Introduction
Open-vocabulary object detection은 사용자 입력의 텍스트 레이블을 기반으로 임의의 클래스를 탐지하는 것을 목표로 하며, 이는 전통적인 closed-set object detection보다 더 일반적인 탐지 작업입니다.
- GLIP은 region-word contrastive pre-training을 통해 object detection과 phrase grounding을 처음으로 통합했습니다. 이러한 공식화는 광범위한 개념을 다루는 방대한 grounding 및 image-text 데이터로부터 이익을 얻어 학습된 표현을 의미론적으로 풍부하게 만듭니다.
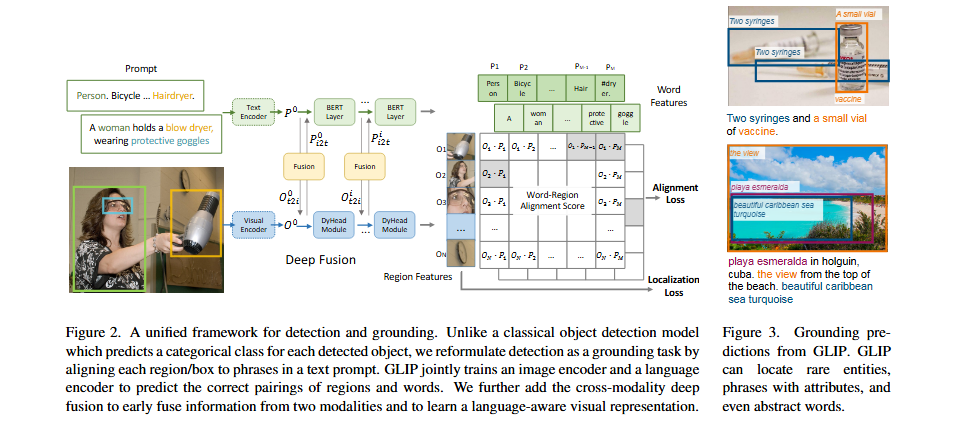
후속 연구들은 효과적인 vision-language fusion과 세심하게 설계된 word embedding 및 negative sample을 통한 세밀한 region-word alignment에 초점을 맞췄습니다. Pretraining 데이터와 연산을 확장함으로써 기존 open-vocabulary object detector들은 다양한 벤치마크에서 놀라운 zero-shot 성능을 달성할 수 있었습니다.
최근 연구들은 grounding 작업을 다른 언어 작업과 통합하는 것이 language knowledge로 시각적 표현을 풍부하게 하여 더 강력한 open-vocabulary detector를 만든다는 것을 보여줍니다.
- GLIPv2는 grounding loss와 masked language modeling loss 하에서 모델을 pre-train합니다. 이어서 CapDet과 DetCLIPv3는 dense captioning과 grounding을 통합하는 것도 open-vocabulary 능력을 향상시킨다는 것을 보여줍니다.
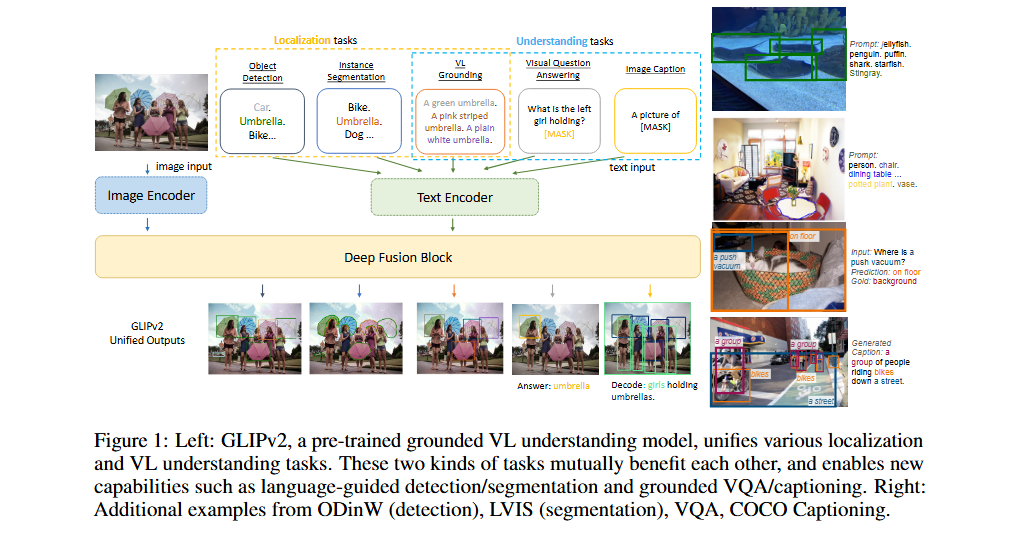
GLIPv2 - https://arxiv.org/pdf/2206.05836
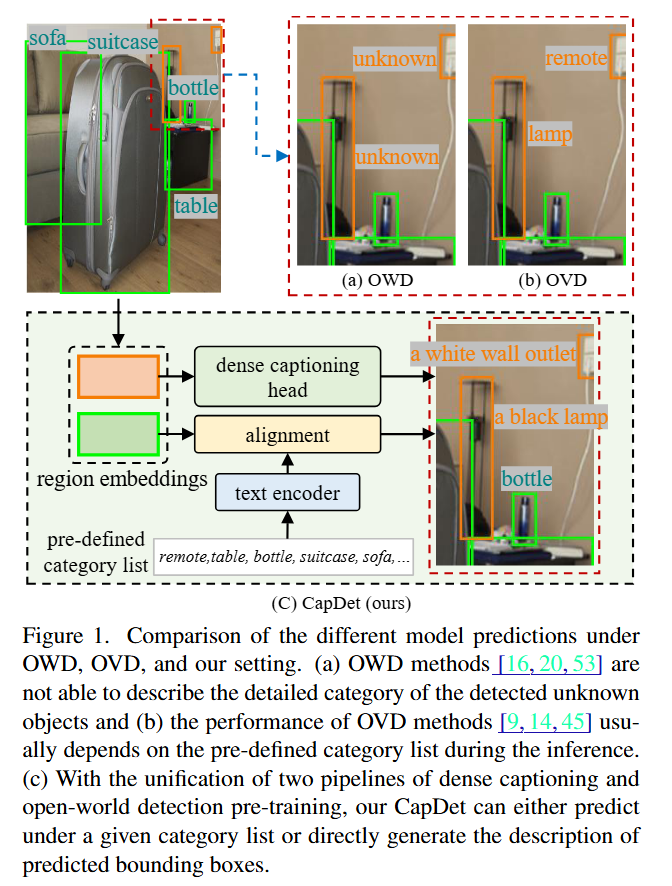
CapDet - https://arxiv.org/pdf/2303.02489
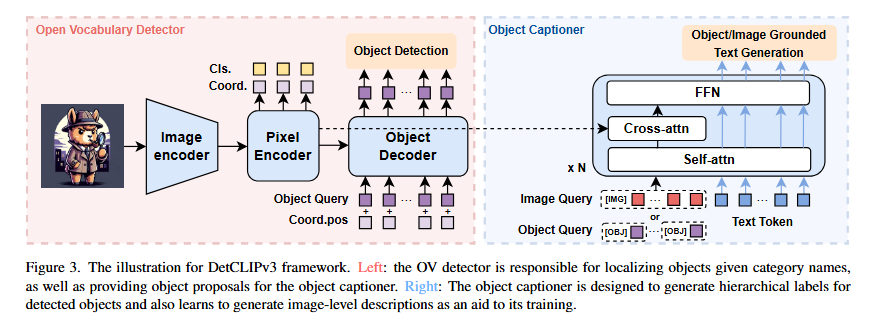
DetCLIPv3 - https://arxiv.org/pdf/2404.09216
하지만 이들은 각 object에 대해 짧은 caption을 사용합니다(예: 거친 설명과 계층적 클래스 레이블). 이는 거칠고 개별적이며 객체 간의 연관성이 부족합니다.
- 반면, 풍부한 세부사항과 이미지에 대한 포괄적 이해를 포함하는 긴 image-level caption은 짧은 region-level 설명보다 더 많은 정보를 제공합니다.
2. Related Work
2.1. Open-Vocabulary Object Detection
Open-vocabulary object detection(OVD)에서 detector는 제한된 훈련 데이터셋에서 훈련되지만 임의의 테스트 시점 사용자 입력 클래스를 탐지하는 것을 목표로 합니다. 임의의 클래스를 탐지하기 위해 open-vocabulary object detection은 클래스 이름으로 보지 못한 클래스를 탐지할 수 있도록 vision-language 작업으로 공식화됩니다.
- CLIP의 인상적인 zero-shot 능력에 동기를 받아, detector를 CLIP과 정렬하거나 CLIP을 모델의 일부로 통합하는 것이 OVD를 다루는 직접적인 방향입니다. 하지만 CLIP은 image-level 목표로 pre-train되었기 때문에 CLIP의 특징이 OVD에 완벽하게 적합하지는 않습니다.
대안적으로, 다양한 리소스로부터의 방대한 데이터로 object-aware visual-language 공간을 구축하는 것이 인상적인 결과를 보여주었습니다. 또한 masked language modeling이나 dense captioning과 같은 다른 언어 작업과의 multi-task learning이 더 나은 vision-language alignment를 달성할 수 있어 detector의 open-vocabulary 능력을 향상시킵니다.
2.2. Large Vision-Language Model
최근 large vision-language model들은 large language model에 뛰어난 시각적 인식 및 이해 능력을 부여합니다.
일반적인 large vision-language model은 세 부분으로 구성됩니다: (1) vision token을 추출하는 vision foundation model, (2) vision feature를 language 공간으로 매핑하는 projector, 그리고 (3) 시각적 및 텍스트 입력을 모두 이해하는 large language model입니다.
3. GroundingCap-1M 데이터셋
Data Formulation
LLMDet 훈련을 지원하기 위해 각 훈련 샘플을 quadruple (I, Tg, B, Tc)로 공식화합니다.
- 여기서 I는 이미지, Tg는 짧은 grounding 텍스트, B는 grounding 텍스트의 구문에 매핑된 주석이 있는 bounding box들, Tc는 전체 이미지에 대한 상세한 caption입니다.
전체 이미지에 대한 상세한 caption을 수집할 때 두 가지 핵심 원칙을 따릅니다:
- Caption은 가능한 한 많은 세부사항을 포함해야 합니다.
Caption이 object 유형, 질감, 색상, object의 부분, object 동작, 정확한 object 위치, 이미지의 텍스트를 설명하여 정보가 풍부하도록 기대합니다.
- Caption은 이미지에 대한 사실적 세부사항만 포함해야 합니다.
너무 많은 상상적이거나 추론적인 caption은 정보 밀도를 감소시키거나 모델 학습을 방해할 수 있습니다.
Dataset Construction
구축 비용을 절약하기 위해 bounding box나 상세한 caption이 있는 기존 데이터셋에서 시작합니다. 이전 연구들을 따라 object detection 데이터셋, grounding 데이터셋, image-text 데이터셋에서 데이터를 수집합니다.
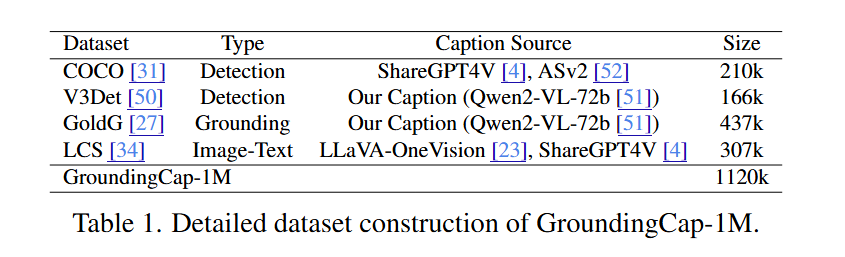
GroundingCap-1M은 여러 기존 데이터셋을 조합하고 새로운 정보를 추가하여 만든 통합 데이터셋입니다.
- Object detection 데이터셋 → caption 추가
- Grounding 데이터셋 → 상세한 caption 추가
- Image-text 데이터셋 → bounding box 추가
Object detection 데이터셋의 경우:
- COCO와 V3Det 데이터셋을 선택
- COCO의 상세한 caption은 ShareGPT4V(168k)와 ASv2(42k)에서 수집
- V3Det의 caption은 Qwen2-VL-72b를 사용하여 생성
Grounding 데이터셋의 경우:
- GQA와 Flickr30k를 포함하는 GoldG를 선택
- 계산을 절약하고 negative를 증가시키기 위해 동일한 이미지의 일부 grounding 텍스트를 병합
- 상세한 caption도 Qwen2-VL-72b를 사용하여 생성
Image-text 데이터셋의 경우:
- LLaVA-OneVision과 ShareGPT4V의 caption이 있는 LCS-558k 사용
- 이 데이터셋의 이미지에 대한 pseudo box를 생성하기 위해 먼저 전통적인 언어 parser를 사용하여 caption에서 명사구를 추출한 다음 MM Grounding DINO를 활용하여 각 구문에 대한 bounding box를 생성
최종 데이터셋인 GroundingCap-1M은 112만 개의 샘플을 포함합니다.

Quality Verification
데이터 수집 과정에서 prompt를 신중하게 선택하고 접근 가능한 최고 모델(Qwen2VL-72b)을 사용했습니다. 하지만 데이터셋에 어느 정도 노이즈가 있는 것은 불가피하므로 몇 가지 후처리를 도입하여 데이터셋을 정리합니다:
적용 후처리 방법
-
Caption 모델이 상상적 내용을 설명하지 않도록 prompt했지만, 모델이 여전히 "indicating", "suggesting", "possibly"와 같은 명백한 단어로 출력하는 경향이 있어 추측적 단어가 포함된 하위 문장을 삭제
-
의미 없는 caption을 필터링하는 규칙 설계
-
Caption이 세부사항으로 풍부하도록 보장하기 위해 처음 생성된 caption이 100 token 미만인 이미지에 대해 Qwen2VL-72b를 사용하여 caption을 재생성
후처리 후 각 caption은 평균 약 115단어를 포함합니다.
4. Large Language Model의 지도하에 LLMDet 훈련
전체 시스템 구조
LLMDet은 3개의 독립적으로 사전 훈련된 모듈을 결합한 시스템입니다:
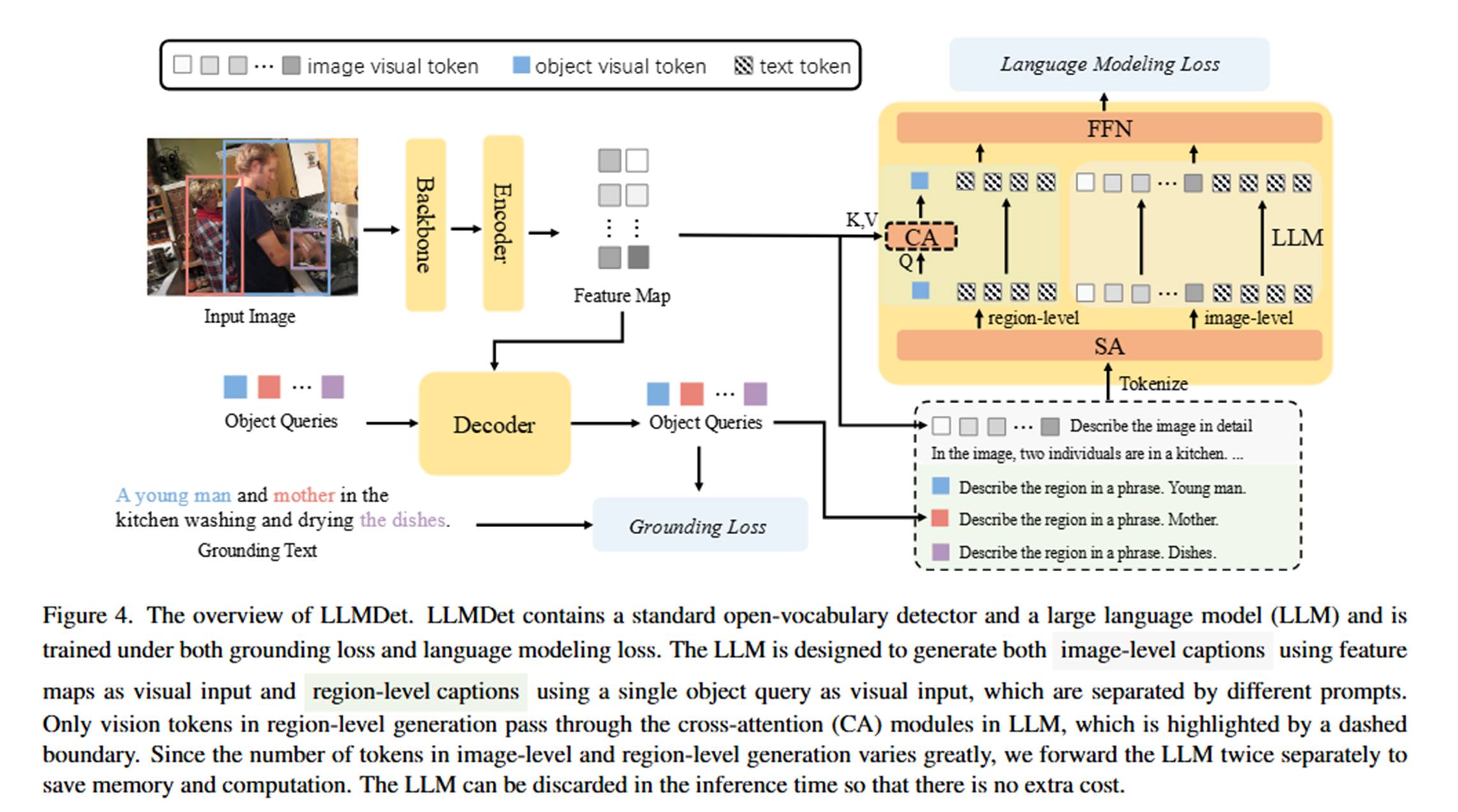
🔍 Detector (MM Grounding DINO)
- 역할: 이미지 → 시각적 특징 추출 + 객체 탐지
- 상태: 이미 완전히 훈련된 상태
🔗 Projector
- 역할: 시각적 특징 → 언어 모델이 이해할 수 있는 형태로 변환
- 상태: 처음에는 무작위 초기화 (학습 필요)
🤖 LLM (Large Language Model)
- 역할: 변환된 시각적 특징 → 자연어 caption 생성
- 상태: 이미 완전히 훈련된 상태
단계별 훈련 전략
📍 Step 1: Alignment Training (정렬 학습)
목표: Detector와 LLM 사이의 "번역기" 역할을 하는 Projector 학습
이미지 → Detector (🔒고정) → Projector (🔄학습) → LLM (🔒고정) → Caption-
학습 내용:
- 입력: Detector의 전체 feature map
- 출력: 이미지 전체에 대한 상세한 caption
- Loss: Language modeling loss만 사용
-
왜 Projector만 학습하는가?
- Detector와 LLM의 기존 지식을 보존
- 계산 효율성 (작은 모듈만 학습)
- 학습 안정성 확보
📍 Step 2: End-to-End Training (통합 학습)
목표: 전체 시스템을 하나의 통합된 객체 탐지기로 발전
이미지 → Detector (🔄학습) → Projector (🔄학습) → LLM (🔄LoRA) → Caption동시에 3가지 작업 수행:
-
기존 Grounding 작업 (Detector 주도)
- "young man"이라는 텍스트 ↔ 해당 영역 매칭
- Loss:
-
Image-level Caption Generation (전체 협력)
- 전체 이미지 → "이미지에는 두 사람이 주방에서..."
- Loss:
-
Region-level Caption Generation (세밀한 매칭)
- 특정 영역 → "young man", "dishes" 등
- Loss:
왜 이런 복잡한 구조가 필요한가?
🎯 Image-level vs Region-level의 상호 보완
-
Image-level만으로는 부족한 이유:
- LLM이 "dishes"라고 말했을 때, 이미지의 어느 부분인지 모호함
- 전체적인 맥락은 잘 이해하지만 정확한 위치 매핑이 어려움
-
Region-level의 필요성:
- Object query → Cross-attention → Feature map에서 정보 수집
- "이 특정 영역은 정확히 'young man'이다"라는 명확한 매핑 제공
🔄 Cross-Attention의 역할
- 문제: Object query 하나만으로는 정보가 부족
- 해결: Cross-attention을 통해 전체 feature map에서 관련 정보 수집
Object Query (제한된 정보) + Cross-Attention → Feature Map (풍부한 정보) → 정확한 Region Caption최종 Loss 함수
- : 기존 객체 탐지 성능 유지
- : 전체적인 맥락 이해 능력 향상
- : 정확한 영역-단어 매핑 능력 향상
5. Experiment
5.1. Implementation Details
MM Grounding DINO(MM-GDINO)를 기준 모델로 선택했습니다. 이는 완전히 오픈소스이며 SOTA 성능을 보여주기 때문입니다. Pre-trained checkpoint를 다시 로드하고 GroundingCap-1M 데이터셋으로 grounding loss와 caption generation loss의 지도하에 모델을 fine-tuning합니다.
Large language model은 LLaVA-OneVision-0.5b-ov에서 초기화됩니다. 메모리와 훈련 효율성을 절약하기 위해 image-level generation의 최대 token 길이를 1600으로, region-level generation의 것을 40으로 설정합니다. 이미지당 caption generation을 위한 최대 영역 수는 16으로 제한됩니다.
5.2. Zero-Shot Detection Transfer Ability
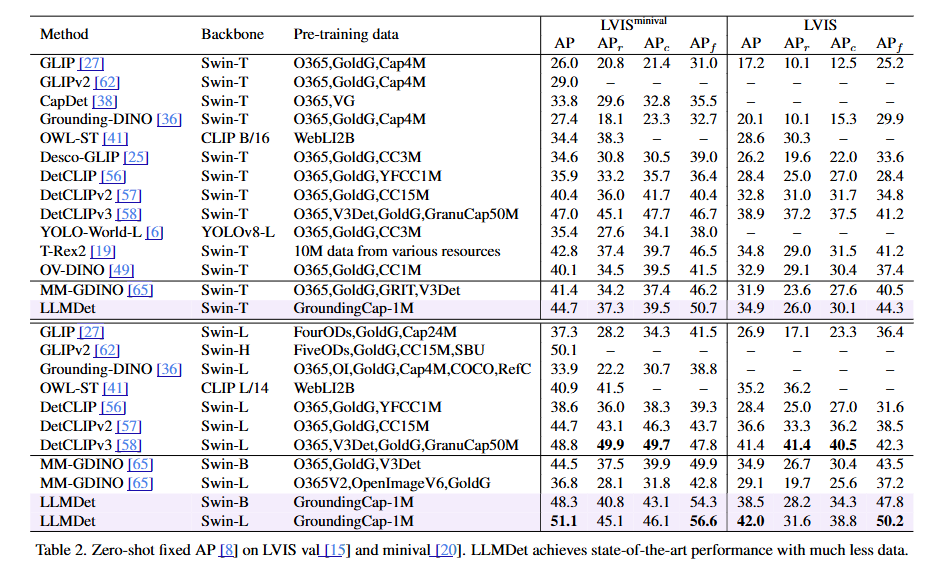
LVIS에서의 Zero-shot 성능:
- LVIS는 1203개 클래스를 가진 detection 데이터셋입니다.
- 새로운 훈련 목표와 새로운 데이터셋으로 LLMDet은 다양한 backbone에서 LVIS minival에서 기준선 MM-GDINO를 3.3%/3.8%/14.3% AP와 3.1%/3.3%/17.0% APr로 능가합니다.
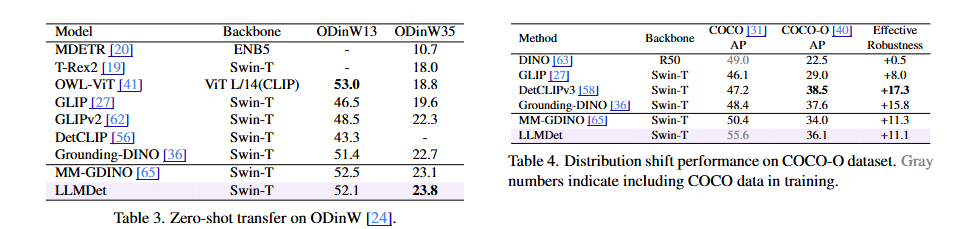
ODinW에서의 Zero-shot 성능:
- ODinW는 다양한 도메인과 어휘에 걸친 35개 데이터셋의 모음으로, open-vocabulary detection을 위한 도전적이고 포괄적인 벤치마크입니다.
- LLMDet은 ODinW35에서 가장 높은 AP를 얻어 광범위한 데이터셋으로의 뛰어난 전이 능력을 보여줍니다.
COCO-O에서의 Zero-shot 성능:
- COCO-O는 COCO와 동일한 80개 클래스를 공유하지만 sketch, weather, cartoon, painting, tattoo, handmake와 같은 다른 도메인을 가진 데이터셋입니다.
- LLMDet은 여전히 MM-GDINO를 2.1% AP로 능가하여 도메인 변화에 더 강건함을 보여줍니다.
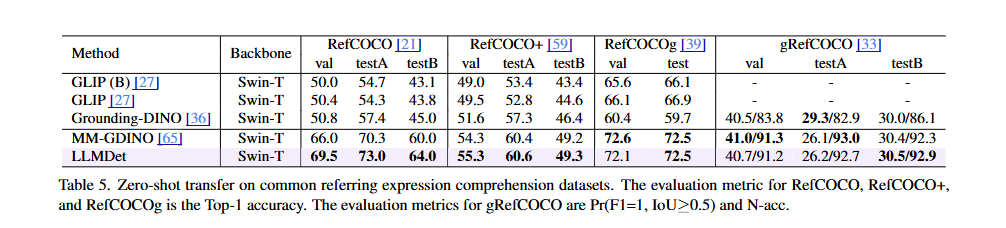
Referring expression comprehension 데이터셋에서의 Zero-shot 성능:
- Referring expression comprehension(REC)은 구문으로 언급된 객체를 지역화하는 작업으로, 포괄적인 언어 이해와 세밀한 vision-language alignment가 필요합니다.
- 상세한 caption을 사용하여 LLM과 co-training함으로써 LLMDet은 풍부한 시각적 세부사항을 풍부한 vision-language alignment로 모델링할 수 있습니다.
5.3. Ablation Study
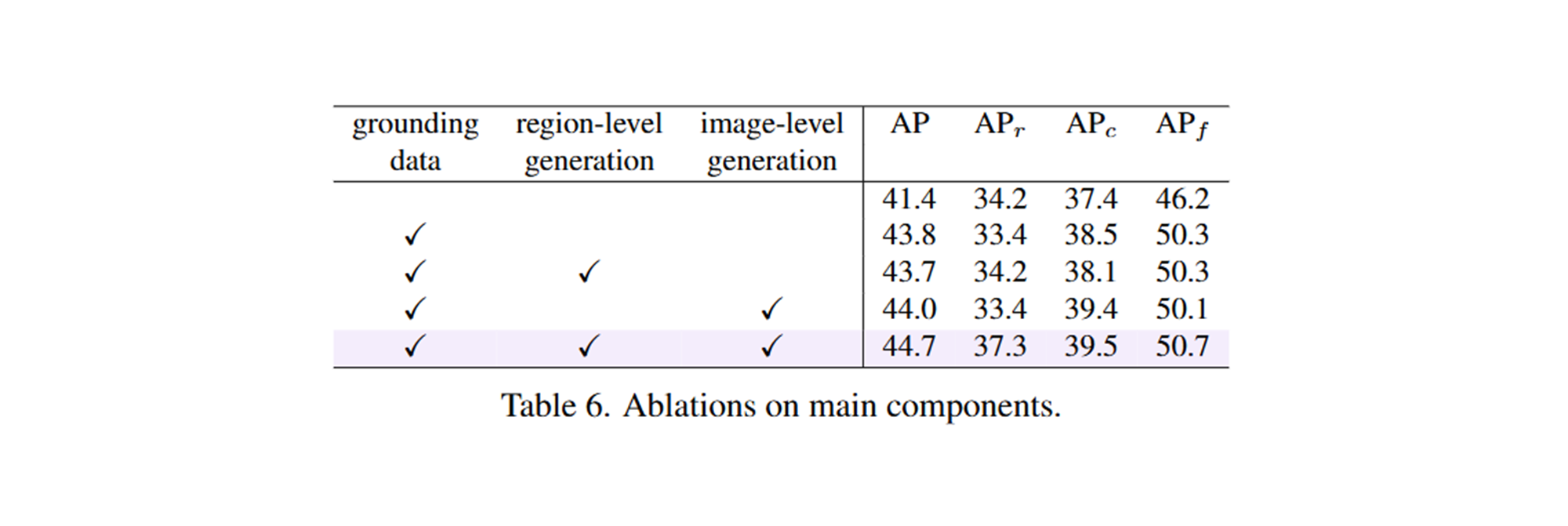
주요 구성 요소의 효과:
- Grounding annotation만으로 fine-tuning하면 성능이 41.4% AP에서 43.8% AP로 향상됩니다.
- Region-level generation만으로는 성능이 향상되지 않는데, 이는 LLMDet의 region-level caption이 영역의 클래스 이름이나 grounding phrase일 뿐이어서 추가 정보를 제공하지 않기 때문입니다.
- Image-level generation만 사용해도 성능이 약간 향상됩니다.
- Image-level과 region-level generation을 모두 결합하면 LLM의 지도 신호의 이익을 완전히 발휘할 수 있으며, 상세한 caption에서 학습된 풍부한 vision-language 표현이 rare class 인식에 도움이 되어 3.9% APr를 크게 향상시킵니다.
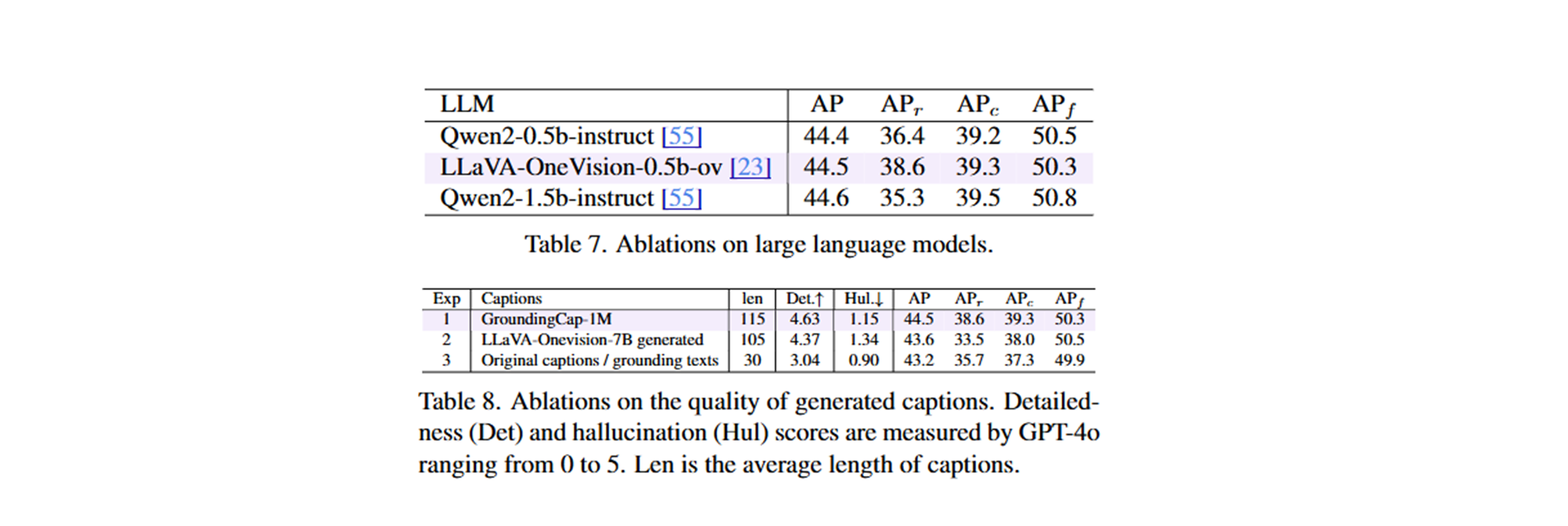
다른 Large Language Model의 효과:
- 기본적으로 Qwen2-0.5b-instruct에서 fine-tuning된 LLaVA-OneVision-0.5b-ov의 LLM을 사용합니다.
- LLaVA-OneVision-0.5b-ov의 LLM은 풍부한 multi-modal 데이터로 pre-train되었지만 다른 vision encoder를 사용하더라도 pretraining이 여전히 성능을 향상시킵니다.
- 특히 rare class에서 (+2.2% APr) 향상됩니다.
생성된 Caption 품질의 효과:
- GroundingCap-1M의 caption이 가장 높은 상세성 점수와 적당한 환각을 가지고 있어 데이터셋의 뛰어난 품질을 검증합니다.
- 인간이 주석한 caption은 환각이 적지만(0.90 vs 1.34), LLaVA caption에서도 여전히 환각이 있습니다.
6. Conclusion
본 연구에서는 기존 open-vocabulary detector의 성능을 향상시키는 새로운 훈련 목표를 탐구했습니다. Large language model을 활용하여 image-level 상세 caption과 region-level 거친 grounding phrase를 모두 생성함으로써 detector는 상세한 caption으로부터 더 많은 정보와 이미지에 대한 포괄적 이해를 받고 풍부한 vision-language 표현을 구축합니다.
결과로 나온 detector인 LLMDet은 광범위한 벤치마크에서 최첨단 성능을 달성합니다. 또한 개선된 LLMDet이 강력한 large multi-modal model을 구축하여 상호 이익을 달성할 수 있음을 보여줍니다. 본 연구가 최고 성능의 large language model로 vision model을 향상시키는 통찰을 제공하기를 희망합니다.

결국 성능 향상의 근거가 LLM이 만든 캡션 품질에 전적으로 달려있는데, 그렇다면 이건 object detector 개선이 아니라 LLM 캡션 엔진에 종속된 변형 모델일 뿐인건가요 ?
논문은 벤치마크 수치로 성능 향상을 강조하지만, 실제 환경에서는 긴 캡션 생성의 비용과 latency가 발목을 잡을 수 있을것 같기도 하고 ..GroundingCap-1M 데이터셋이 진짜 1M급 퀄리티인지, 아니면 양으로 커버한 noisy dataset인지가 관건인 것 같네요
좋은 글 감사합니다