[Paper Review] MM-Groundung-DINO : An Open and Comprehensive Pipeline for Unified Object Grounding and Detection

본 리뷰는 원문을 최대한 직역한 내용입니다. 여기서 "우리는"은 저자를 지칭합니다. 참고 부탁드립니다.
초록
Grounding-DINO는 Open-Vocabulary Detection (OVD), Phrase Grounding (PG), Referring Expression Comprehension (REC)을 포함한 다양한 비전 작업을 다루는 최첨단 open-set detection 모델입니다.
- 이 모델의 효과성으로 인해 다양한 하위 애플리케이션의 주류 아키텍처로 널리 채택되고 있습니다.
- 하지만 그 중요성에도 불구하고 원본 Grounding-DINO 모델은 훈련 코드의 비공개로 인해 포괄적인 공개 기술 세부사항이 부족합니다.
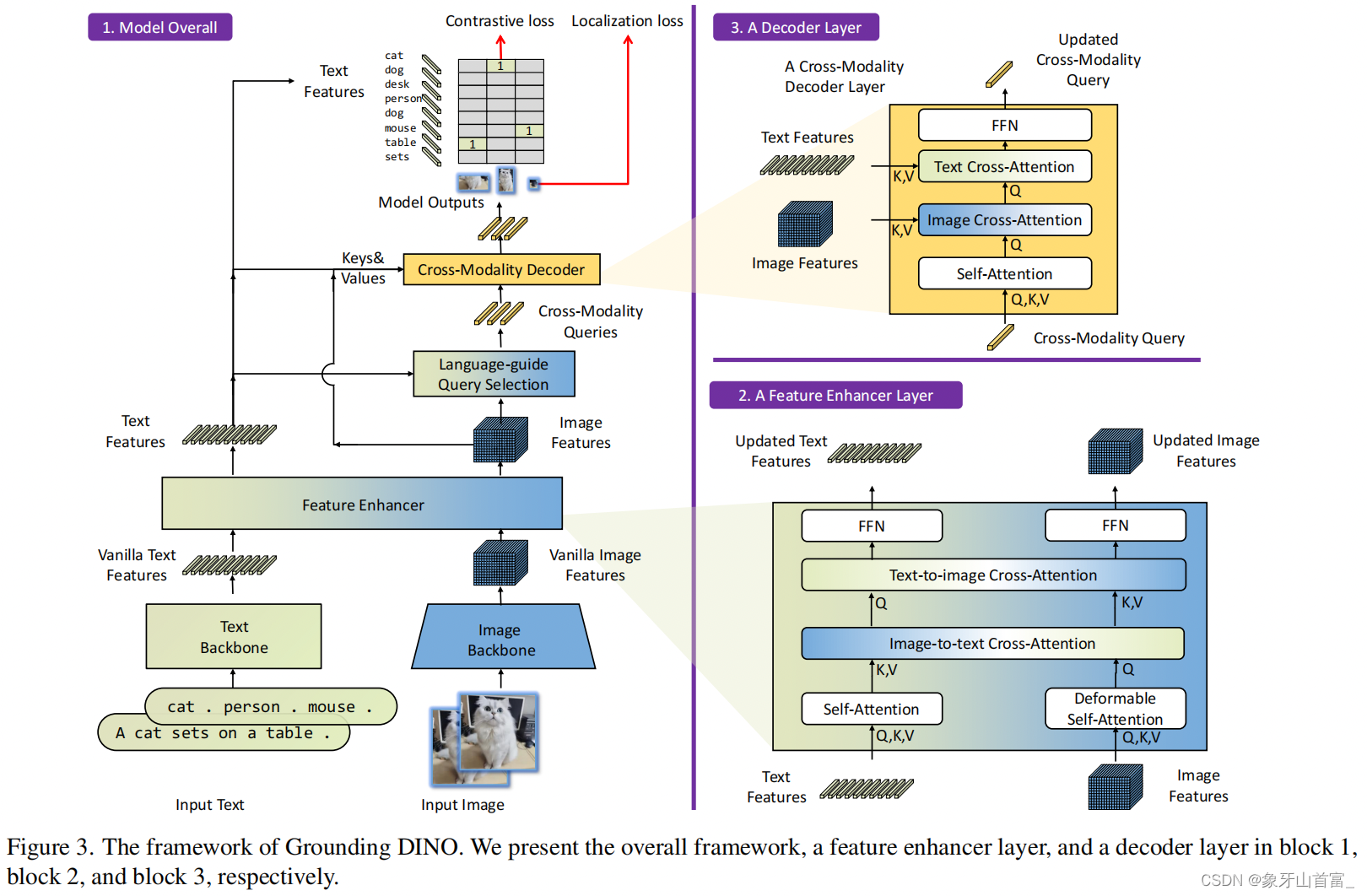
Image from Grounding Dino Paper
이러한 격차를 해소하기 위해, 저희는 MMDetection toolbox로 구축된 오픈소스의 포괄적이고 사용자 친화적인 파이프라인인 MM-Grounding-DINO를 제시합니다.
(참고) MMDetection은 오픈소스 객체 탐지(Object Detection) 툴박스로, 주로 PyTorch 기반으로 개발된 컴퓨터 비전 라이브러리입니다. 이는 다양한 객체 탐지 알고리즘을 쉽게 학습, 평가, 배포할 수 있도록 도와주는 프레임워크입니다.
이 모델은 사전 훈련을 위해 풍부한 비전 데이터셋을, fine-tuning을 위해 다양한 detection 및 grounding 데이터셋을 채택합니다. 저희는 보고된 각 결과에 대한 포괄적인 분석과 재현을 위한 세부 설정을 제공합니다.
- 언급된 벤치마크에서의 광범위한 실험은 저희의 MM-Grounding-DINO-Tiny가 Grounding-DINO-Tiny baseline을 능가함을 보여줍니다. 연구 커뮤니티에 모든 모델을 공개합니다.
https://github.com/open-mmlab/mmdetection/tree/main/configs/mm_grounding_dino
1. 서론
객체 detection 작업은 일반적으로 이미지를 모델에 입력하여 제안을 얻은 다음, 이를 multi-modal alignment를 통해 텍스트와 매칭하는 것을 포함하며, 이는 대부분의 최첨단 multi-modal 이해 아키텍처의 핵심 구성 요소입니다.
현재 객체 detection은 입력 텍스트의 유형에 따라 세 가지 하위 작업으로 세분화할 수 있습니다: Open-Vocabulary Detection (OVD), Phrase Grounding (PG), Referring Expression Comprehension (REC).
- Zero-shot 설정에 따라, Open-Vocabulary Detection (OVD) 모델은 기본 카테고리에서 훈련되지만 대규모 언어 어휘 내에서 기본 및 새로운 카테고리를 모두 예측해야 합니다.
- Phrase grounding (PG) 작업은 카테고리뿐만 아니라 모든 후보 카테고리를 설명하는 구문을 입력으로 받아 해당 박스를 출력합니다.
- Referring Expression Comprehension (REC) 작업의 주요 목표는 주어진 텍스트 설명으로 지정된 대상을 정확히 식별하고 이후 bounding box를 사용하여 그 위치를 표시하는 것입니다.
최근 몇 년간 위의 작업들을 해결하기 위해 수많은 비전 grounding 및 detection 모델이 탐구되었습니다.
- 이러한 grounding 모델 중에서 Grounding-DINO는 뛰어난 성능으로 주류 아키텍처가 되었습니다.
- Closed-set detector DINO를 기반으로, Grounding-DINO-Large는 COCO 훈련 데이터 없이 COCO에서 최첨단 zero-shot 성능(mAP 52.5)을 달성합니다.
Grounding-DINO는 feature enhancer, query selection module, decoder를 포함하여 다양한 단계에서 비전과 언어 modality의 통합을 실행합니다.
- 이러한 심층 융합 접근법은 open-set 맥락에서 객체 detection을 크게 향상시키며, DETR 기반 구조는 하드코딩된 모듈 없이 end-to-end 네트워크로 만듭니다.
2. 접근 방법
이 섹션에서는 모델과 데이터셋을 자세히 소개합니다. 달리 명시되지 않는 한, MM-G는 MM-Grounding-DINO를, G-DINO는 Grounding-DINO를 나타냅니다.
2.1 모델
언급한 바와 같이, 저희 모델은 Grounding-DINO를 기반으로 하며 거의 변경되지 않았습니다. 저희 프레임워크는 Figure 3에 나와 있습니다. [Batchsize, 3, H, W] 형태의 이미지와 텍스트 설명이 주어지면, 저희 모델은 설명을 해당 생성된 bounding box와 정렬할 수 있습니다.
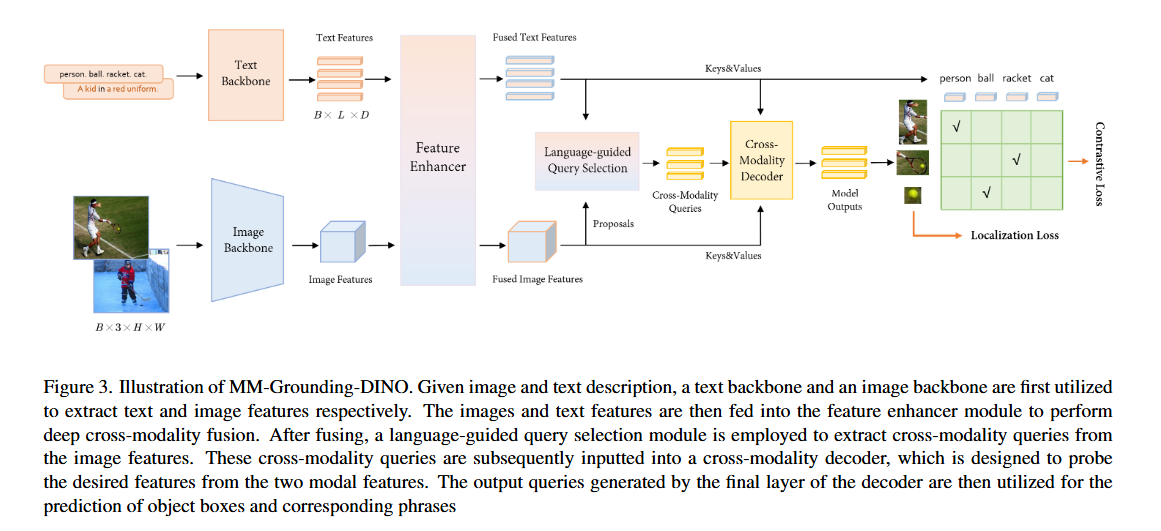
모델의 구성 요소는 다음과 같습니다:
- 텍스트 특성 추출을 위한 텍스트 backbone
- 이미지 특성 추출을 위한 이미지 backbone
- 이미지와 텍스트 특성을 깊이 융합하는 feature enhancer
- query 초기화를 위한 language-guided query selection module
- 박스 개선을 위한 cross-modality decoder
특성 추출 및 융합:
- 이미지-텍스트 쌍이 주어지면,
이미지 backbone을 사용하여 다중 스케일에서 이미지 특성을 추출하고, 동시에텍스트 backbone을 사용하여 텍스트 특성을 추출합니다. - 그런 다음 두 특성을
feature enhancer module에 입력하여 cross-modality 융합을 수행합니다.

Language-Guided Query Selection:
- 텍스트를 객체 detection 가이드로 활용하는 것을 최적화하기 위해, Grounding-DINO는 language-guided query selection module을 설계했습니다.
- 이 모듈은 입력 텍스트 특성과의 코사인 유사성을 기반으로 num_query 제안을 decoder query로 선택합니다.
Cross-modality Decoder:
- Grounding-DINO의 cross-modality decoder layer는 cross-modality 학습을 위해 텍스트와 이미지 특성을 추가로 통합하도록 설계되었습니다.
- Self-attention 후, 아키텍처는 이미지 cross-attention layer, 텍스트 cross-attention layer, FFN layer를 순서대로 통합합니다.
차이점:
MM-G와 G-DINO의 주요 차이점은 contrastive embedding module에 있습니다.
- CLIP에서 영감을 받아, contrastive embedding module을 초기화할 때 bias를 추가했습니다.
- 이는 초기 loss 값을 크게 줄이고 모델의 수렴을 가속화할 수 있습니다.

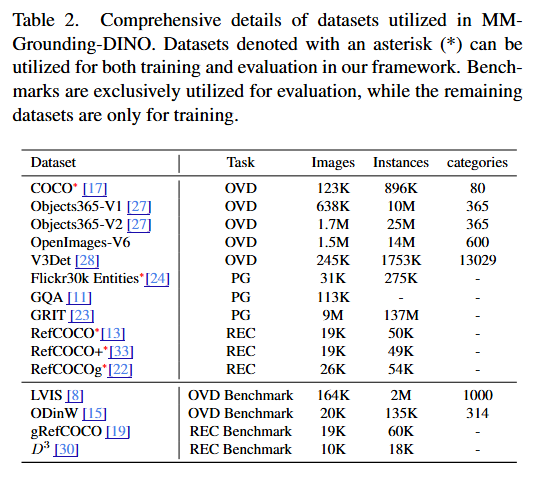
2.2 데이터셋 준비
저희 데이터 형식은 Open Grounding-DINO의 형식에서 영감을 받아 MMDetection의 형식으로 수정되었습니다. MM-Grounding-DINO는 다른 종류의 주석을 가진 데이터셋으로 세 가지 작업을 다루도록 설계되어, 사용한 15개 데이터셋을 세 그룹으로 나누었습니다.
OVD 데이터셋:
- 훈련에 사용하는 데이터셋은 COCO, Objects365V1, Objects365V2, V3Det, Open-Images를 포함하며, 평가 데이터셋은 COCO, LVIS, ODinW12/35를 포함합니다.
PG 데이터셋:
- 훈련 데이터셋은 GQA, GRIT, Flickr30K Entities를 포함하며, Flickr30K Entities 데이터셋은 평가에도 사용됩니다.
REC 데이터셋:
- 훈련 데이터셋은 RefCOCO, RefCOCO+, RefCOCOg를 포함합니다. 평가를 위해서는 RefCOCO, RefCOCO+, RefCOCOg, gRefCOCO, Description Detection Dataset(D³)을 포함하는 더 광범위한 데이터셋 세트를 활용합니다.
2.3 훈련 설정
텍스트 입력 규칙:
- OVD 훈련을 위해, detection 데이터셋의 모든 카테고리를 "People. Ball. Racket. Cat."과 같은 긴 문자열로 연결합니다.
- PG 및 REC 작업의 경우, M-DETR을 따라 사전 훈련 단계에서 텍스트 내에서 언급되는 모든 객체에 주석을 달아 이 작업에 대한 모델의 적용에 약간의 수정을 가합니다.
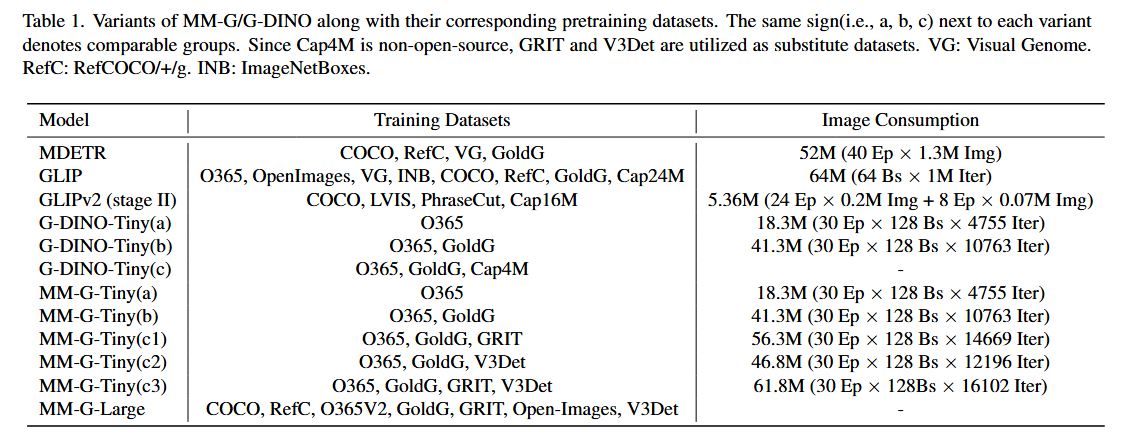
모델 종류:
- Grounding-DINO와 유사하게, 언어 인코더로 잘 사전 훈련된 BERT-based-uncased 모델을, 이미지 backbone으로 Swin Transformer를 선택합니다.
데이터 증강:
- 랜덤 리사이즈, 랜덤 클립, 랜덤 플립 외에도 데이터 증강에서 랜덤 negative sample을 도입합니다.
- 다른 이미지에서 랜덤하게 샘플링된 카테고리나 텍스트 설명을 negative 예제로 ground-truth 설명과 함께 positive 예제로 연결합니다.
컴퓨팅 리소스:
- 총 batch size 128로 30 epoch 동안 32개의 NVIDIA 3090 GPU에서 MM-G-Tiny를 훈련했습니다.
3. 주요 결과
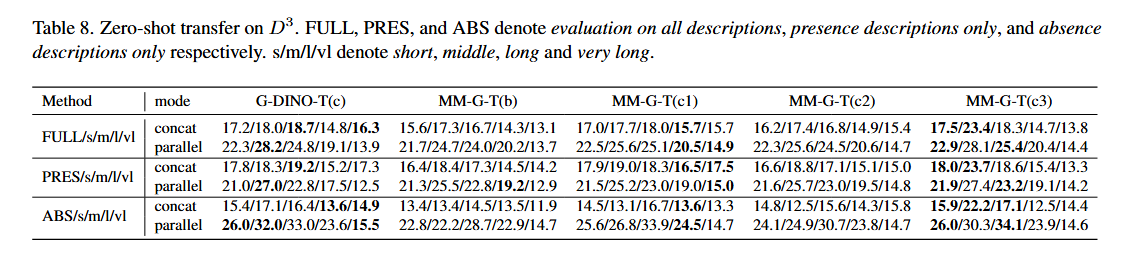
3.1 Zero-shot Transfer
Zero-shot 설정에서, MM-G 모델은 처음에 기본 데이터셋에서 훈련되고 이후 새로운 데이터셋에서 평가됩니다.
COCO 벤치마크:
- O365 데이터셋과 다른 PG/REC 데이터셋에서 사전 훈련된 MM-Grounding-DINO를 평가했습니다.
- Grounding-DINO를 따라 COCO 데이터셋을 zero-shot 학습 baseline 설정에 활용했습니다.
- Table 3에서 MM-Grounding-DINO-Tiny와 Grounding-DINO-Tiny를 비교했습니다.
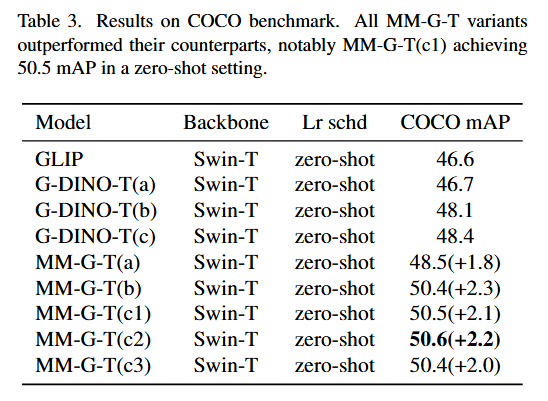
결과는 O365로만 훈련된 MM-G(a)(mAP 48.5)조차도 O365, Gold-G, Cap4M으로 훈련된 G-DINO(c)(mAP 48.4)를 능가할 수 있음을 보여줍니다.
- Objects365, Gold-G, GRIT로 훈련된 MM-G-T(c)는 50.5 mAP의 성능을 보여주어 COCO 벤치마크에서 G-DINO(c)보다 2.1 AP 향상되었습니다.
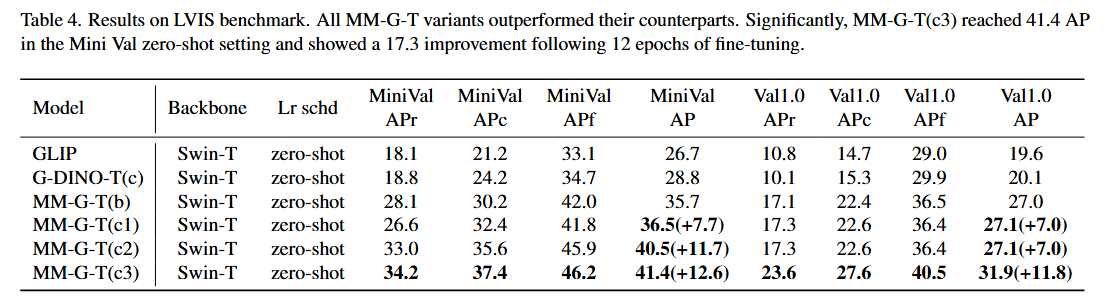
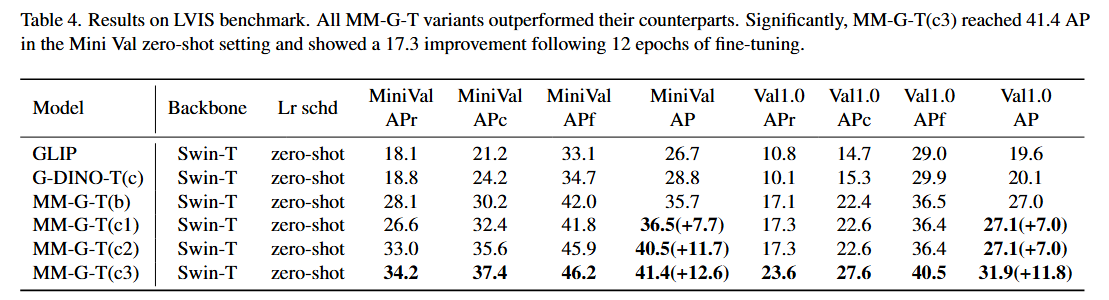
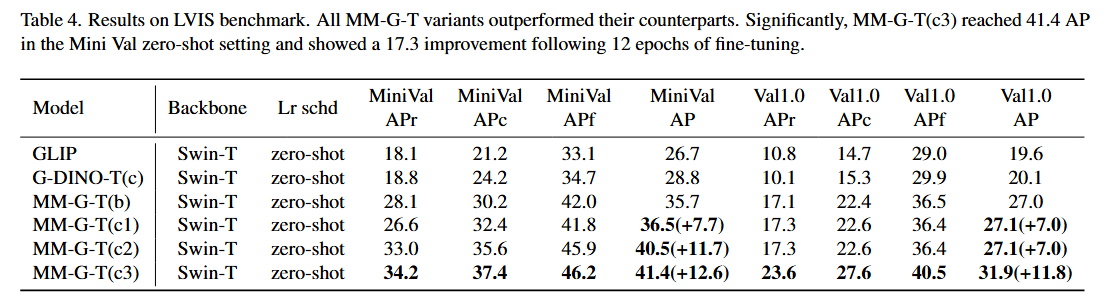
LVIS 벤치마크:
- LVIS 데이터셋은 평가를 위해 1000개 이상의 고유 카테고리를 포함하는 long-tail detection 데이터셋입니다.
- Table 4에서 MM-Grounding-DINO-Tiny와 Grounding-DINO-Tiny를 비교했습니다.
- Cap4M 없이 O365와 GoldG로 훈련된 MM-G(a)가 LVIS MiniVal과 Val 모두에서 G-DINO(c)를 +6.9AP 능가함을 관찰했습니다.
ODinW 벤치마크:
- ODinW(Object Detection in the Wild) 벤치마크는 실제 환경에서 모델 성능을 평가하도록 설계된 더 엄격한 벤치마크입니다.
- 저희 MM-G-T(c3)는 ODinW13에서 53.3 mAP, ODinW35에서 28.4 mAP의 점수를 달성하여 G-DINO-T(c)보다 우수한 성능을 보였습니다.
RefCOCO/+/g 및 gRefCOCO 벤치마크:
- REC 작업에서 MM-G의 zero-shot 능력도 평가했습니다. RefCOCO, RefCOCO+, RefCOCOg는 REC 평가를 위해 설정되었으며, 결과는 Table 5에 나와 있습니다.
- 저희 모델은 RefCOCO의 모든 zero-shot 평가 지표에서 baseline을 능가할 수 있습니다.
3.2 GRIT 분석
GRIT는 오픈소스가 아닌 Cap4M의 대체재로 사용된 대규모 데이터셋입니다. 하지만 위의 결과에서 보듯이 GRIT의 성능은 기대에 미치지 못합니다. GRIT의 이미지와 주석을 관찰한 결과, 주요 이유들을 다음과 같이 열거할 수 있습니다:
-
GRIT의 텍스트 주석은 COYO-700M과 LAION-2B의 캡션에서 spaCy로 추출한 구문이나 문장에서 나오며, 인명, 이벤트, 시설, 지정학적 개체와 같은 많은 추상적 구문을 포함하여 모델을 잘못된 방향으로 이끌 수 있습니다.
-
GRIT 데이터셋에서 대부분의 이미지는 단일 주석이 함께 제공됩니다. 단일 주석은 실제로는 이미지의 전체 캡션인 긴 문장과 이미지의 전체 범위에 거의 걸쳐 있는 노이즈가 많은 박스를 포함합니다.
3.3 Fine-tuning을 통한 검증
이 보고서의 기본 fine-tuning은 MM-G-T(c3) 사전 훈련된 모델을 기반으로 합니다.
COCO/LVIS에서의 Fine-tuning: MM-Grounding-DINO의 기능을 철저히 평가하기 위해 세 가지 주요 fine-tuning 접근법을 구현했습니다: close-set fine-tuning, open-set continuing pretraining fine-tuning, open-vocabulary fine-tuning.
Table 10에서 보듯이, MM-G-T는 close-set fine-tuning과 open-set continuing pretraining fine-tuning 모두를 통해 COCO 데이터셋에서 성능이 크게 향상되었습니다.
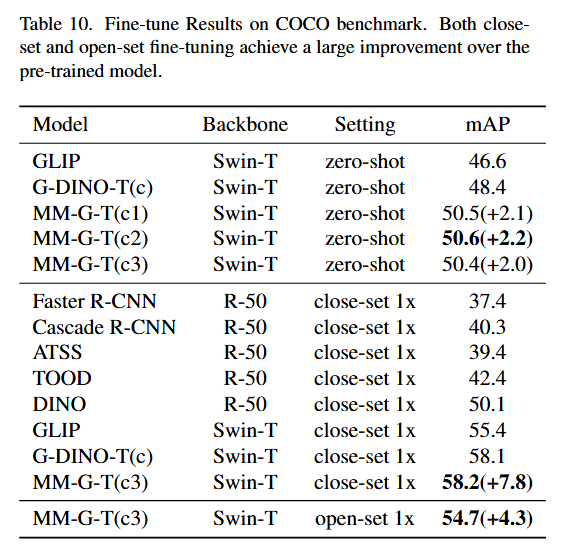
특히 MM-G-T는 12 epoch의 close-set fine-tuning 후 7.8 mAP 증가하여 58.2 mAP에 도달했습니다.
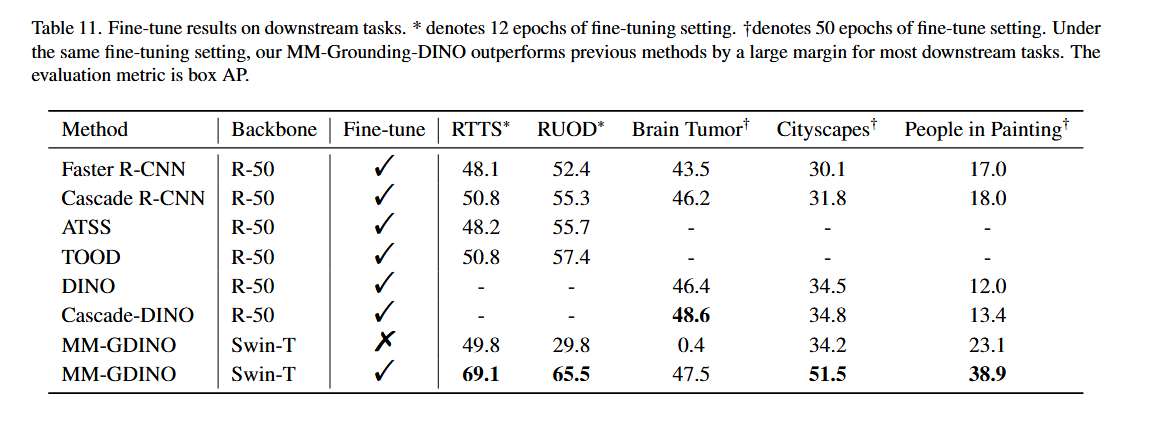
하위 작업에서의 Fine-tuning: MM-Grounding-DINO의 일반화 가능성을 포괄적으로 보여주기 위해 다양한 하위 작업으로 평가를 확장했습니다.
-
안개 속 객체 detection: Real-world Task-driven Testing Set (RTTS)를 활용했으며, MM-Grounding-DINO는 12 epoch의 fine-tuning 후 69.1 AP에 도달했습니다.
-
수중 객체 detection: Real-world Underwater Object Detection dataset (RUOD)에서 평가했으며, 12 epoch의 fine-tuning 후 35.7 mAP 향상을 보여 새로운 벤치마크를 설정했습니다.
-
뇌종양 객체 detection: Brain tumor 데이터셋에서 평가했으며, 이 데이터셋은 설명적 라벨 정보 없이 숫자 식별자만 사용하는 독특한 라벨링 접근법을 사용합니다.
-
Cityscapes 객체 detection: 50개 도시의 거리에서 촬영된 스테레오 비디오 시퀀스가 포함된 광범위한 도시 거리 장면 컬렉션입니다.
4. 결론
이 논문에서 저희는 Grounding-DINO를 기반으로 하고 풍부한 비전 데이터셋으로 사전 훈련된 포괄적이고 오픈소스인 grounding baseline인 MM-Grounding-DINO를 제안했습니다. 이는 OVD, PG, REC 작업을 포괄적으로 다룹니다. OVD, PG, REC 평가를 위한 모든 사용 가능한 벤치마크를 확장했으며, 모든 평가 지표는 MMDetection에서 쉽게 사용할 수 있습니다.
언급된 벤치마크에서의 광범위한 실험은 저희 MM-Grounding-DINO가 Grounding-DINO baseline을 능가(또는 동등한 성능)함을 보여줍니다. 저희 파이프라인이 grounding 및 detection 작업의 추가 연구를 위한 귀중한 자원 역할을 하기를 바랍니다.
