[Paper Review] Mamba: Linear-Time Sequence Modeling with Selective State Spaces
최근 딥러닝 아키텍처의 중심에는 트랜스포머가 자리 잡고 있습니다. 대규모 언어 모델(LLM)뿐만 아니라, 그림을 생성하는 데 쓰이는 디퓨전 모델 또한 트랜스포머 구조를 활용하고 있습니다. 이외에도 시계열 분석이나 추천 시스템과 같은 다양한 분야에서 트랜스포머가 핵심적인 역할을 하고 있습니다.
그러나 트랜스포머를 대체할 수 있는 새로운 아키텍처를 모색하려는 연구는 계속되고 있으며, 그 중에서도 특히 주목받고 있는 것이 State Space Model(SSM)입니다. 최근 "Mamba: Linear-Time Sequence Modeling with Selective State Spaces"라는 논문과 그 모델이 공개되면서, SSM이 트랜스포머의 대안으로서 더욱 관심을 끌고 있습니다.
- Mamba 논문 링크 : https://arxiv.org/pdf/2312.00752
추가적으로 벌써 Survey 논문도 벌써 나왔는데요!! 흥미로운 이미지들만 좀 reference용으로 가져오자면 아래와 같습니다. Mamba 이후로 많은 후속 연구 및 Variation들이 빠르게 연구되고 있는 것들을 확인할 수 있습니다.
-
많은 관심을 받고 있는 SSM 모델
이미지 출처. State Space Model for New-Generation Network Alternative to Transformers: A Survey -
수많은 SSM Variation 모델 : new paradigm shift?!
이미지 출처. State Space Model for New-Generation Network Alternative to Transformers: A Survey
1. Introduction (서론)
서론에서는 Mamba 모델의 필요성과 기존 Transformer 모델의 한계점을 설명하고, Mamba가 이 문제를 어떻게 해결하는지를 소개합니다.
-
기존 Transformer의 문제점: Transformer는 Attention 메커니즘을 기반으로 긴 시퀀스를 처리하는 데 매우 뛰어나지만, 시퀀스 길이에 따라 계산 복잡도가 2차 함수(Quadratic)로 증가하여, 긴 시퀀스 데이터를 다룰 때 매우 비효율적입니다.
- 이러한 문제를 해결하기 위해 많은 연구자들이 Linear Attention과 같은 다양한 방법을 제안했지만, 대부분은 정보 밀도가 높은 데이터(예: 텍스트)에서 Transformer만큼의 성능을 내지 못했습니다.
-
SSM(Structured State Space Models)의 등장: 이러한 한계를 해결하기 위해, Structured State Space Models(SSM)이 등장했습니다.
- SSM은 재귀적 신경망(RNN)과 합성곱 신경망(CNN)의 이점을 결합한 모델로, 시퀀스의 길이에 비례하는 선형적인 계산 복잡도를 가지고 있어 매우 효율적입니다.
- 그러나 SSM은 정보 밀도가 높은 텍스트 데이터에서는 Transformer만큼의 성능을 내지 못했습니다.
-
Mamba 모델의 등장: Mamba는
선택 메커니즘을 도입한 Selective State Space Model(선택적 상태 공간 모델)을 기반으로 하며, 긴 시퀀스를 다루면서도 Transformer 수준의 성능을 유지하면서도 계산 비용을 줄일 수 있는 모델입니다.- 특히, 텍스트, 오디오, 유전체학(genomics) 등의 다양한 데이터 유형에서 매우 우수한 성능을 보여줍니다.
2. State Space Models (상태 공간 모델)
이 장에서는 상태 공간 모델(SSM)의 기본 개념과 작동 원리에 대해 설명합니다.
-
SSM의 작동 원리: 상태 공간 모델은 시스템의 입력을 고차원의 잠재 공간(latent space)으로 변환하여 처리하는 방식으로 동작합니다. 이는 수학적으로 연속 시스템의 이산화(Discretization) 과정으로 표현됩니다.
-
수식으로 표현하자면, 입력 을 잠재 상태 로 변환하고, 이를 통해 출력 을 도출하는 방식입니다.
-
이때, 각 시점에서 상태 공간의 변화를 나타내는 주요 매개변수 가 주어집니다.
-
-
연속 시스템에서 이산 시스템으로의 변환: SSM에서는 연속적인 시스템의 매개변수를 이산화(discretization)하여 계산합니다. 이를 통해 모델은 연속 데이터를 효율적으로 처리할 수 있습니다.
- 이 때, 선형 시간 불변 시스템(LTI, Linear Time-Invariant System)의 개념이 사용됩니다. 이 시스템은 시간에 따라 변하지 않는 선형적인 연산을 수행하므로, 긴 시퀀스 처리에 매우 효율적입니다.
💡 결국 이산화하면 RNN이랑 같은 거 아닌가?
- DSBA 연구실의 천재원 석사생의 PYSR을 보면 이에 대한 답변을 얻을 수 있습니다.
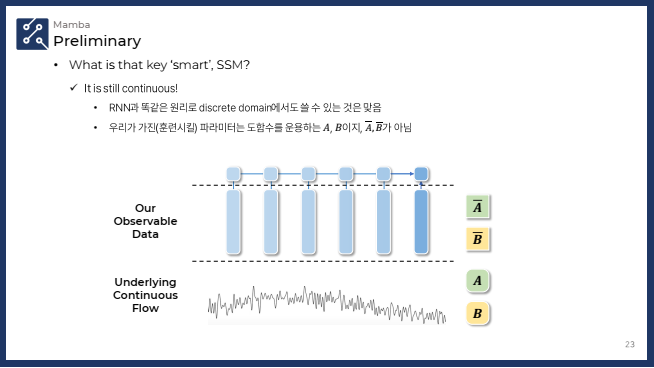
✔️ SSM (State Space Model)의 연속성
- SSM은 연속적인 시간 흐름에 따라 시스템의 상태를 모델링하는 방식입니다. 이때 A와 B는 연속적 시스템을 표현하는 중요한 매트릭스들로, 시간에 따른 시스템의 상태 변화를 기술합니다.
- A: 상태 변화를 결정하는 매트릭스. 이전 상태 에 곱해져서 시스템의 상태가 어떻게 변하는지 정의합니다.
- B: 입력을 상태로 변환하는 매트릭스. 입력 를 받아 상태에 반영하는 역할을 합니다.
- A̅와 B̅는 SSM에서 이산화 된 버전의 매트릭스들로, 연속적인 시스템을 이산적인 형태로 변환하여 시퀀스 데이터를 처리할 수 있게 만듭니다. A̅와 B̅는 연속적인 SSM 모델의 도함수를 기반으로 이산적 시퀀스 처리에 맞게 변환된 것입니다.
- SSM의 장점은 이러한 연속적인 흐름을 기반으로 시스템의 미세한 변화를 더 잘 모델링할 수 있다는 점입니다.
- 시간 변화가 연속적인 시스템에서 데이터를 잘 반영할 수 있기 때문에 시스템의 물리적 성질을 더 정확하게 반영할 수 있습니다.
✔️ RNN (Recurrent Neural Network)의 이산화
- RNN은 기본적으로 이산화된 시퀀스 데이터를 처리하는 데 중점을 둡니다. RNN은 각 시간 스텝에서 이전 상태와 현재 입력을 바탕으로 다음 상태를 업데이트합니다.
- RNN은 연속적인 시간 흐름을 명시적으로 모델링하지 않으며, 이전 상태와 현재 상태 간의 단순한 관계에 의존합니다.
- RNN의 한계는 시간의 연속성을 명확하게 다루지 않기 때문에, 시간에 따른 미세한 변화를 반영하는 데에는 한계가 있을 수 있다는 점입니다.
- 연속적인 시간 흐름을 반영하지 않는 구조이므로, 물리적 시간 흐름이 중요한 문제에 대해서는 성능이 제한적일 수 있습니다.
-
SSM 구조: SSM의 구조는 주로 입력 데이터를 잠재 상태로 변환한 후 이를 기반으로 출력을 도출하는 방식으로, 각 채널이 독립적으로 작동하는 특징이 있습니다. 이로 인해 계산의 병렬화가 가능해져 매우 효율적으로 작동할 수 있습니다.
-
SSM 아키텍처 개요 : SSM(상태공간모델) 아키텍처는 독립적인 시퀀스 변환 모델로, 엔드 투 엔드 신경망 아키텍처에 통합될 수 있습니다.
- SSM 아키텍처는 SSNN(State Space Neural Networks)라고도 하며, 이 경우에는 SSM 레이어가 CNN(합성곱신경망) 레이어와 유사한 역할을 합니다.
- Introduction에는 아래 잘 알려진 몇 가지 SSM 아키텍처를 간단하게 소개합니다:
- Linear Attention (Katharopoulos et al. 2020): 자가 주의의 근사로, 재귀성을 포함하므로 일종의 선형 SSM으로 볼 수 있습니다.
- H3 (Dao, Fu, Saab et al. 2023): 이 모델은 S4를 사용하는 재귀를 일반화하며, SSM이 두 개의 게이트가 있는 연결 사이에 위치하는 형태입니다. H3는 표준 지역 합성을 추가하여 이를 shift-SSM으로 간주합니다.
- Hyena (Poli et al. 2023): H3와 동일한 아키텍처를 사용하지만, S4 레이어를 MLP 매개변수화된 전역 합성으로 대체합니다.
- RetNet (Y. Sun et al. 2023): 이 아키텍처는 추가적인 게이트를 더하고, 더 단순한 SSM을 사용하여 다중 헤드 주의(MHA) 변형을 통해 대안적인 병렬 계산 경로를 제공합니다.
- RWKV (B. Peng et al. 2023): 이 모델은 언어 모델링을 위해 설계된 RNN으로, 다른 선형 주의 근사의 일종인 Attention-free Transformer(S. Zhai et al. 2021)를 기반으로 합니다. 주요 "WKV" 메커니즘은 LTI 재귀를 포함하며, 두 개의 SSM의 비율로 볼 수 있습니다.
(참고) LSSL 및 deepSSM 차원 계산 방식
- 슬라이드에 나온 수식과 제가 쓴 수식이 상이합니다. 저는 앞에 쓴 수식에 맞도록 hidden dim을 h로, time input을 x로 정의했습니다.
1. LTI(Linear Time-Invariant) 시스템의 정의
- LTI 시스템은 시간에 따라 시스템의 특성이 변하지 않으며, 선형적이고 시간 불변적입니다. 즉, 같은 입력이 주어지면 언제든지 동일한 방식으로 처리되고, 시간의 흐름에 따라 시스템의 행동이 달라지지 않는 특성을 가집니다.
- 이는 두 가지 주요 특성에 의해 정의됩니다:
- 선형성: 입력과 출력의 관계가 선형입니다. 즉, 입력의 합이 출력의 합으로 선형적으로 변환됩니다.
- 시간 불변성: 시스템의 상태 변화는 시간에 의존하지 않습니다. 즉, 시간에 따라 시스템의 성능이나 동작이 달라지지 않습니다.
- 이는 두 가지 주요 특성에 의해 정의됩니다:
❓ 그렇다면 자연스럽게 드는 의문점은?
- 🤔 : 흠.. 얘를 차원으로 어떻게 확장을 시킬까? 하는 생각을 하게 됩니다.
- 단순하게 생각해보면, 아래 그림의 SSM 모델처럼 입력과 출력이 차원으로 확장하는 식으로 생각해볼 수도 있긴 합니다만!⚠️⚠️
- 확장된 방정식:
- 각 요소의 디멘션 변화:
- : 히든 스테이트는 여전히 차원을 가집니다.
- : 입력이 이제 차원의 벡터로 확장됩니다.
- : 출력 역시 차원의 벡터로 확장됩니다.
- : 히든 스테이트의 업데이트를 담당하며 차원은 변하지 않습니다.
- : 입력을 히든 스테이트로 변환하는 역할을 하며, 차원을 처리합니다.
- : 히든 스테이트를 출력으로 변환하는 매트릭스.
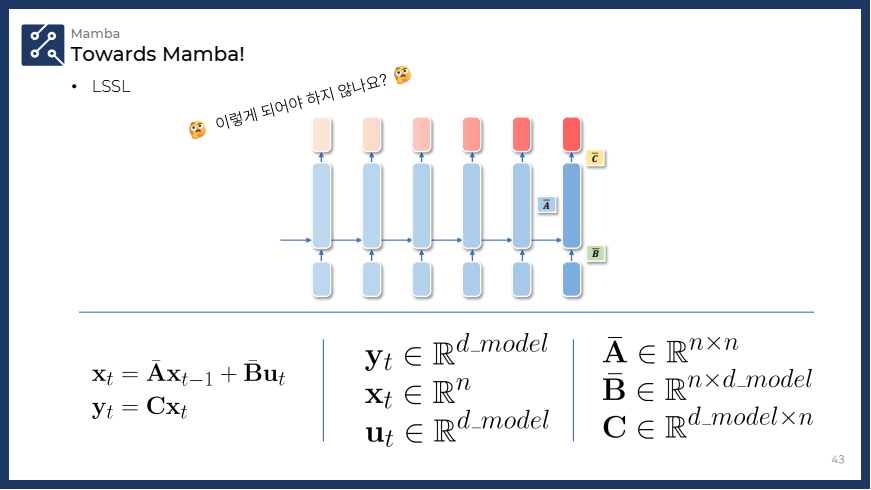
💡 하지만!! 위와 같은 방법은 성립하지 않습니다.
- 결론부터 말씀드리자면, State Space Model(SSM)은 본질적으로 LTI(Linear Time-Invariant) 시스템이며, 이 특성 때문에 입력과 출력이 차원으로 확장되었을 때, 차원별로 독립적인 SSM 처리가 필요하게 됩니다.
❓ 왜 그럼 성립하지 않는가
=> SSM은 본질적으로 LTI 시스템
-
SSM 자체가 LTI 시스템이기 때문에, 기본적으로 선형성과 시간 불변성이 보장되어야 합니다. 이를 기반으로, SSM은 다음의 두 가지 중요한 특성을 가집니다:
- 선형성: 시스템의 입력과 출력 사이의 관계는 선형입니다. 즉, 입력이 변하면 출력도 선형적으로 변하며, 이는 시스템의 동작을 결정하는 선형 매트릭스에 의해 제어됩니다.
- 시간 불변성: 시스템은 시간에 따라 변화하지 않고 항상 동일한 방식으로 동작합니다. 입력이 언제 들어오든, 시스템의 상태와 출력은 동일한 방식으로 계산됩니다.
-
따라서 SSM의 모든 연산은 시간에 따라 변하지 않아야 하며, 입력 차원과 상관없이 동일한 방식으로 동작해야 합니다.
입력과 출력이 차원으로 확장될 때의 문제
-
만약 입력과 출력이 차원으로 확장된다면, 모든 차원을 동시에 처리하기 위해 하나의 공통된 SSM 매트릭스(, , )를 사용하는 방식으로는 문제가 생길 수 있습니다. 왜냐하면:
- SSM은 본질적으로 LTI 시스템이기 때문에, 각 차원은 서로 독립적으로 처리되어야만 선형성과 시간 불변성이 보장됩니다.
- 여러 차원을 하나의 SSM 시스템에서 처리하는 방식은, 차원 간 상호작용을 야기할 수 있습니다. 이는 각 차원이 개별적으로 독립적으로 처리되지 않기 때문에, 시간에 따른 입력 처리 방식이 달라질 가능성이 생깁니다.
-
따라서 차원의 입력을 하나의 SSM으로 처리하는 방식은 LTI 시스템의 요구 사항을 위배할 수 있습니다. 차원별로 독립적인 처리가 이루어지지 않으면 차원 간의 상호작용이 발생하고, 시간에 따라 결과가 달라질 수 있기 때문입니다.
💡 그렇다면 어떻게 되는가?
=> 각 차원의 SSM을 독립적으로 처리
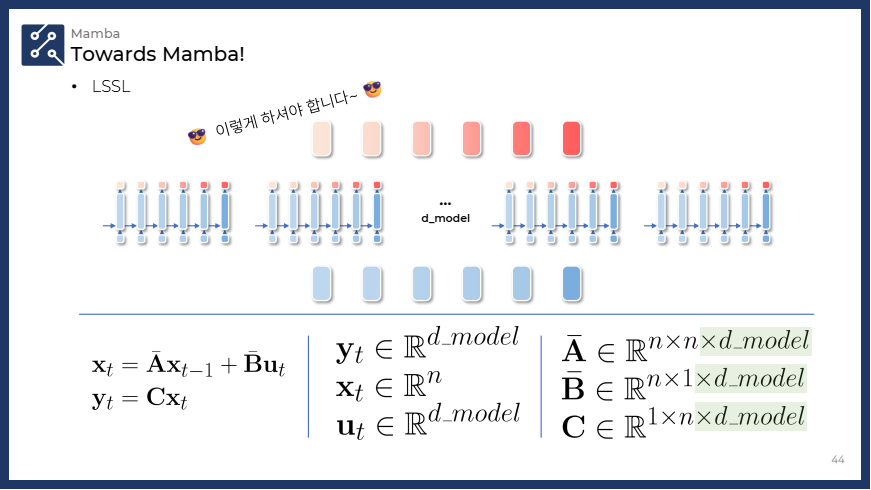
- 설명:
- 차원의 입력 벡터가 주어질 때, 각 차원은 개별적인 SSM을 거칩니다.
- 즉, 개의 SSM이 독립적으로 존재하며, 각각 크기의 매트릭스를 사용하여 히든 스테이트를 업데이트합니다.
- 이 경우 입력과 출력의 차원을 맞추기 위해 와 의 차원도 에 따라 확장됩니다.
- 최종 디멘션:
3. Selective State Space Models (선택적 상태 공간 모델)
이 장에서는 선택적 상태 공간 모델(SSSM, Selective State Space Models)에 대해 설명하며, 이를 통해 기존 SSM의 성능을 어떻게 개선할 수 있는지 다룹니다.
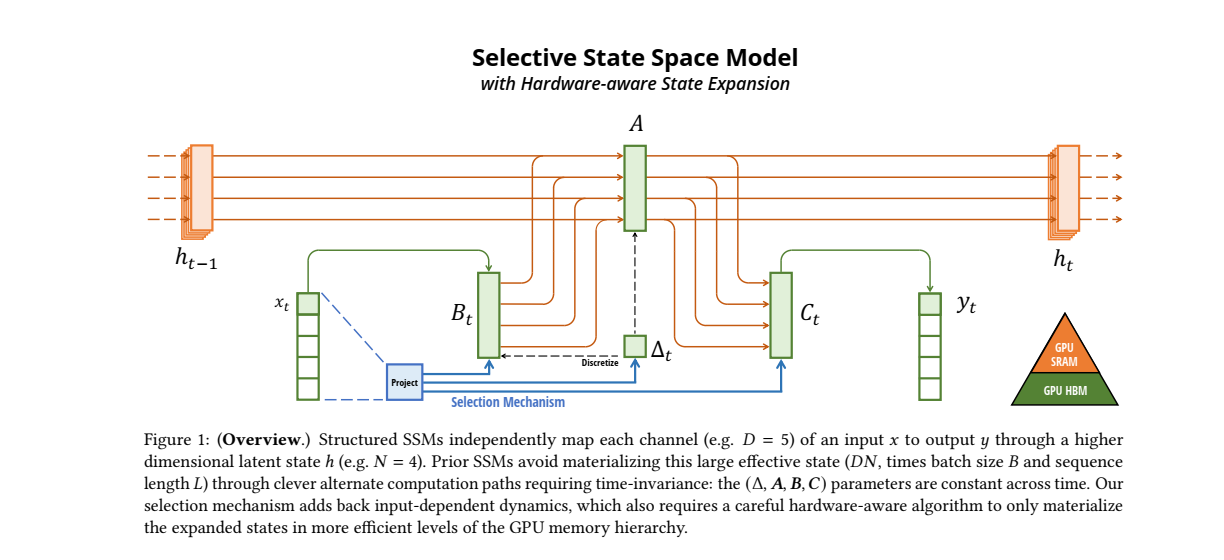
📊 Figure 1 설명
1. (입력 데이터)
- 입력 데이터 (초록)는 시퀀스의 현재 시점에서 들어오는 데이터입니다. 이 데이터는 여러 채널(D)로 나누어져 있고, 각각의 채널이 독립적으로 처리됩니다.
- 예를 들어, 그림에서는 로, 5개의 입력 채널을 의미합니다.
- (이전 시점의 상태)
- 는 이전 시점에서 계산된 잠재 상태(latent space)를 의미합니다. 이 잠재 상태는 시간에 따라 이어져 있으며, 이전 시점의 정보가 현재 시점에 영향을 미칩니다.
- 예를 들어 그림에서는 의 고차원 공간에서 정의되어 있습니다.
- (SSM의 주요 매개변수)
- 이
네 가지 매개변수는 SSM에서 중요한 역할을 합니다. 각 매개변수는 시퀀스 데이터를 처리하고, 잠재 상태 를 업데이트하며, 최종 출력 를 계산하는 데 사용됩니다.
- : 입력 데이터 와 상호작용하여 새로운 상태를 만듭니다.
- (참고 수식) ▶
- 이때 는 입력 의존적이며, 입력에 따라 동적으로 변화합니다.
- : 잠재 상태 를 업데이트하는 데 필요한 중요한 매개변수입니다. 이전 상태와 현재 입력에 기반하여 새로운 상태를 계산할 때 사용됩니다.
- : 계산된 잠재 상태 를 출력 로 변환하는 데 사용됩니다.
- (참고 수식) ▶
- 이를 통해 최종적으로 시퀀스의 각 시점에서 모델의 출력을 얻습니다.
- : 이 매개변수는 시간 차원을 조절하는 역할을 합니다.
- 시간에 따라 상태 공간에서의 변화를 조정하여 모델이 시퀀스를 따라 중요한 정보를 기억하거나 잊도록 도와줍니다.
- 선택 메커니즘 (Selection Mechanism)
- 선택 메커니즘은 이 모델의 핵심적인 요소로, SSSM에서 입력 데이터를 선택적으로 처리하게 만듭니다.
- 이 메커니즘은 시퀀스 데이터를 필터링하여 중요한 정보만을 선택하고, 불필요한 정보는 무시할 수 있도록 돕습니다. ✨ 즉, 정보 압축 및 선택적 기억을 수행하는 방식입니다. ✨
- 그림에서는 이 메커니즘이 입력 와 상호작용하여 와 를 조절하는 방식으로 표현됩니다. (파랑)
- GPU 메모리 계층 (GPU Memory Hierarchy)
- SSSM의 중요한 특징 중 하나는 하드웨어 친화적인 알고리즘을 사용하는 것입니다.
- 이 모델은 GPU의 고속 메모리(SRAM)와 대용량 메모리(HBM) 계층을 효과적으로 활용하여, 잠재 상태의 계산을 최적화합니다.
- 이 구조를 통해 SSSM은 큰 시퀀스 데이터도 효율적으로 처리할 수 있으며, 계산 자원을 효율적으로 활용하여 더 빠르게 결과를 도출할 수 있습니다.
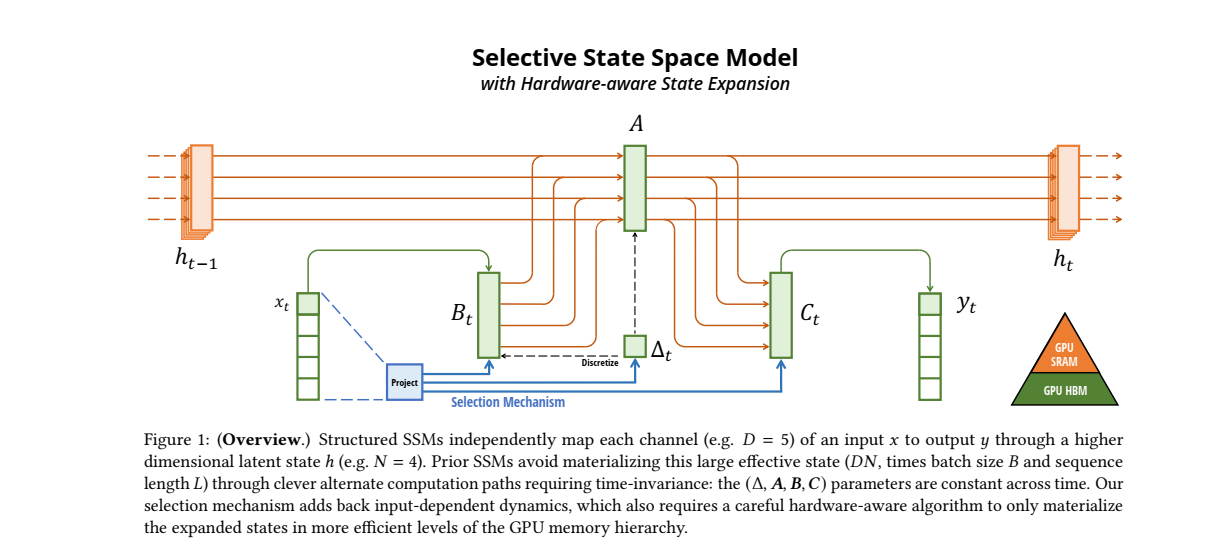
3.1 Motivation: Selection as a Means of Compression
이 섹션은 선택 메커니즘(selection mechanism)이 왜 중요한지를 설명합니다. 주요 내용은 데이터 압축 과 관련된 문제이며, 선택적 메커니즘이 이를 어떻게 해결하는지를 다룹니다.
- 선택의 필요성: 시퀀스 모델링의 주요 과제 중 하나는 컨텍스트(문맥) 정보를 효과적으로 압축하는 것입니다.
Transformer는 정보의 압축을 하지 않고, 모든 정보를 저장하여 처리하는 방식으로 작동하지만, 이로 인해 비효율적인 계산이 발생합니다.- 반면,
RNN과 같은 재귀 모델은 정보를 압축하여 처리하지만, 압축된 정보가 손실되면 성능이 떨어질 수 있습니다.
- 선택적 압축: SSSM(S4)은 컨텍스트 정보를 선택적으로 압축하여 저장하거나 잊을 수 있습니다.
- 즉, 시퀀스 내에서 중요한 정보는 기억하고, 불필요한 정보는 무시하는 방식입니다. 이를 통해 정보 압축을 최적화하고, 모델이 시퀀스 전반에 걸쳐 중요한 정보를 놓치지 않도록 합니다.
본문에서는 Figure2를 통해 "정보 선택 및 복사 작업" 또는 "정보 필터링 작업" Task들을 소개하며, 기본적인 LTI 시스템은 선택적 메커니즘과 문맥 처리 능력이 필요한 Selective Copying Task와 Induction Heads Task에 적합하지 않음을 지적합니다.
-
1. Copying Task (Figure2 왼쪽 이미지)
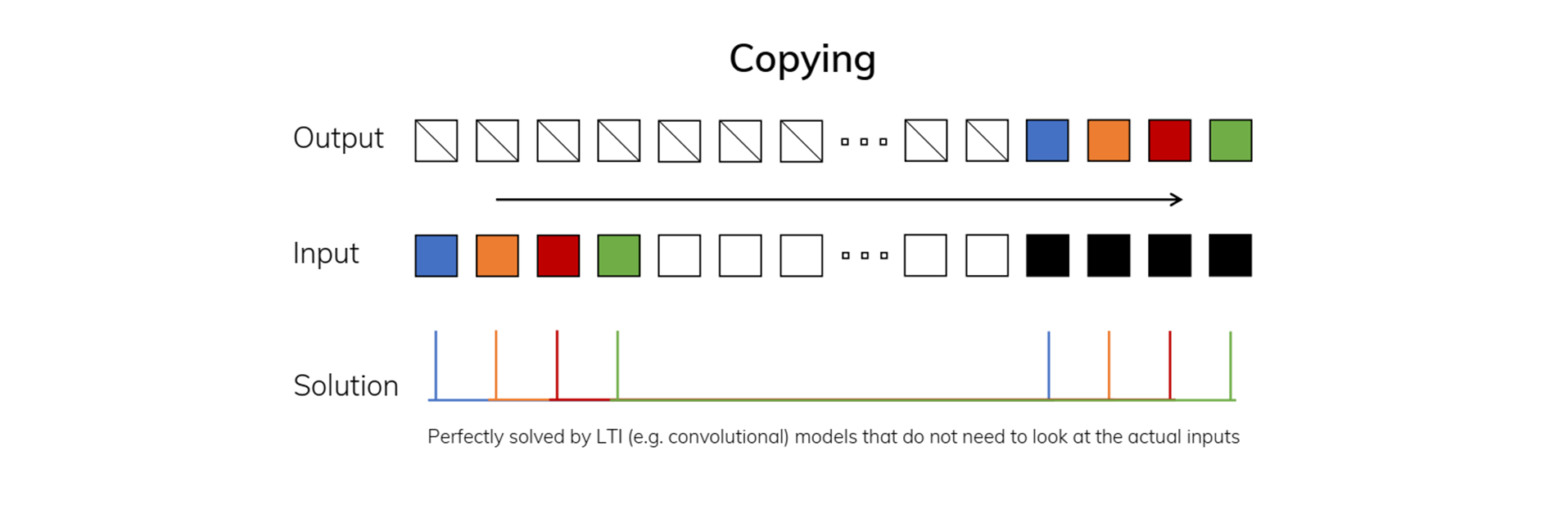
-
문제: Copying Task는 시퀀스 데이터를 기억하고, 특정 위치에서 복사하는 작업입니다.- 이때, 입력과 출력 간의 간격이 일정하게 유지됩니다. 모델은 시퀀스의 일정한 간격에 있는 데이터를 기억하고, 그대로 복사하면 됩니다.
-
해결방법: 이 작업은 매우 간단한 패턴이기 때문에 시간 불변 모델(Time-Invariant Model)로 쉽게 해결할 수 있습니다.- 시간 불변 모델은 모든 시점에서 동일한 방식으로 데이터를 처리하는 모델로, 선형 재귀 모델(Linear Recurrence Model)이나 글로벌 합성곱 모델(Global Convolution Model) 같은 방식이 사용될 수 있습니다.
- 이러한 모델은 입력 간의 일정한 간격을 인식하고, 그에 따라 데이터를 복사하는 데 적합합니다.
-
결과: Copying Task는 간격이 고정되어 있어, LTI(Linear Time-Invariant) 모델로 쉽게 처리할 수 있는 단순한 작업입니다.- 모델은 시간 흐름에 따라 동일한 방식으로 데이터를 복사하여 이 작업을 완벽히 해결할 수 있습니다.
-
-
2. Selective Copying Task (Figure2 오른쪽 위 이미지)
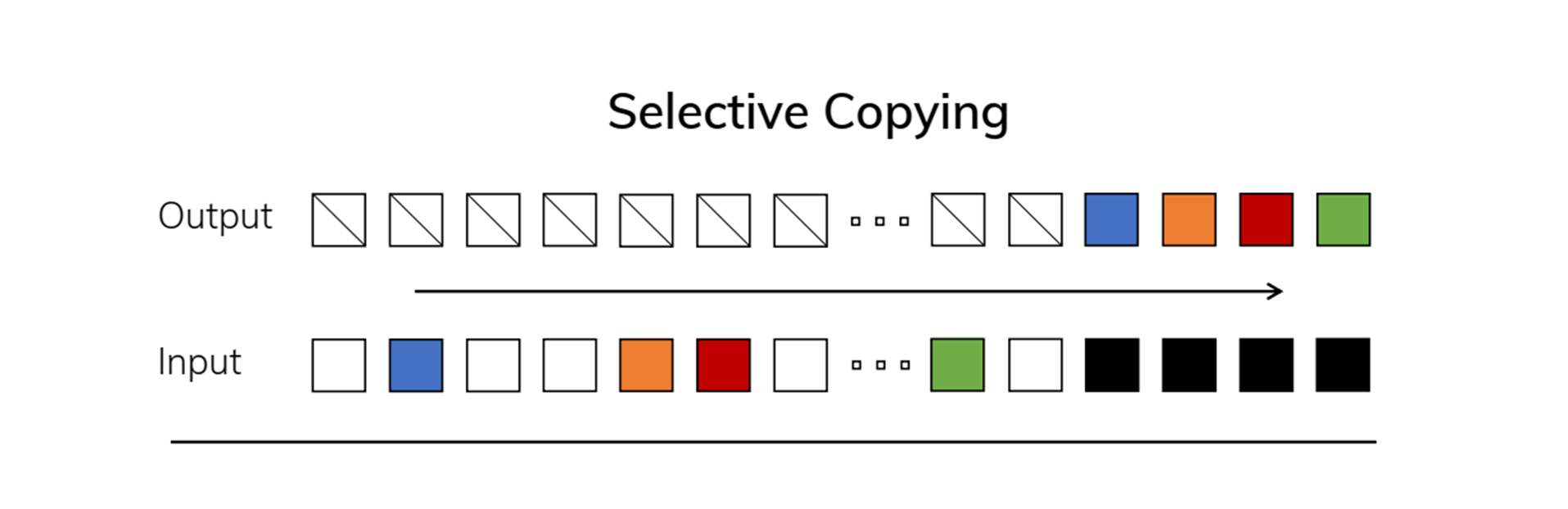
-
문제: Selective Copying Task는 Copying Task와 달리, 입력과 출력 간의 간격이 일정하지 않고 랜덤하게 변동됩니다.- 모델은 시퀀스 내에서 중요한 정보를 선택적으로 기억하고, 나머지 불필요한 정보는 무시해야 합니다.
-
해결방법: 이 문제를 해결하려면 시간 가변 모델(Time-Varying Model)과 선택적 메커니즘(Selection Mechanism)이 필요합니다.선택적 메커니즘은 모델이 입력 데이터를 분석하여 중요한 정보를 선택적으로 기억하고, 불필요한 데이터는 무시할 수 있게 만듭니다.- Selective State Space Model(SSSM)과 같은 구조를 사용하면, 입력 시퀀스 내에서 어떤 정보가 중요한지 선택하고, 중요한 정보를 선택적으로 기억할 수 있습니다.
-
결과: Selective Copying Task는 시간 가변적 처리와 선택적 메커니즘을 통해 해결됩니다.- 이로 인해 모델은 각 시점에서 중요한 데이터를 선택하고, 불필요한 정보는 무시하여 불규칙한 입력 간격에서도 정확하게 복사 작업을 수행할 수 있습니다.
-
-
3. Induction Heads Task (Figure2 오른쪽 하단 이미지)
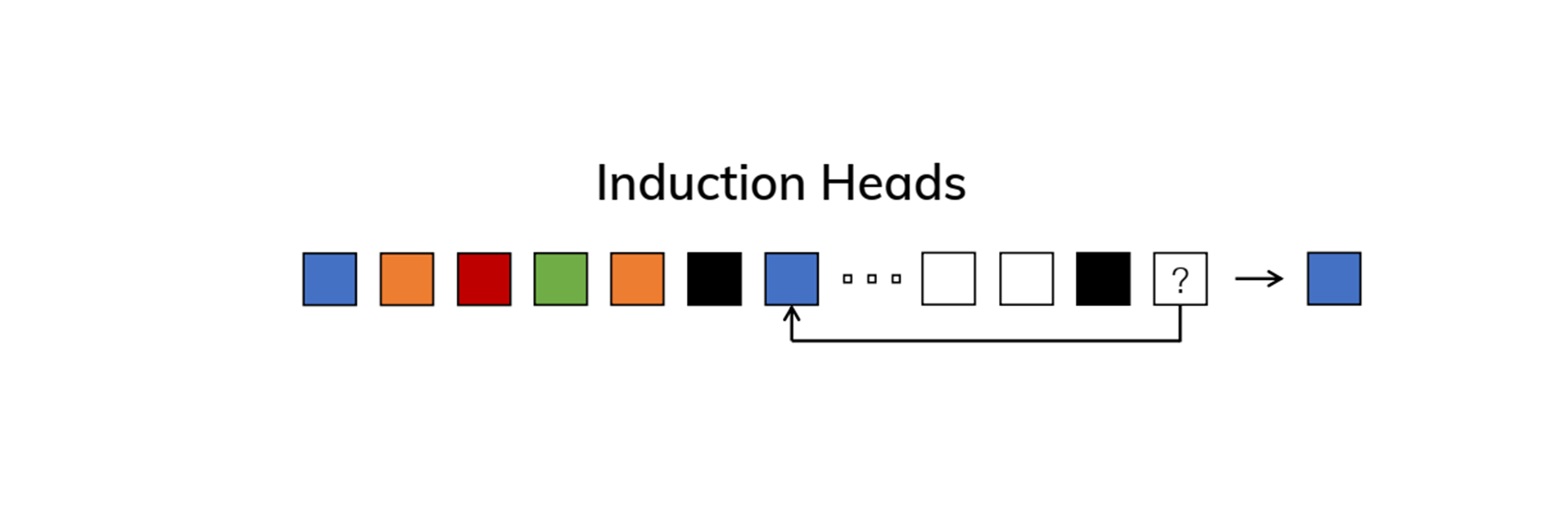
-
문제: Induction Heads Task는 연관 기억(Associative Recall) 문제로, 모델이 이전에 학습된 정보를 바탕으로 문맥(Context)을 이해하고, 문맥에 맞는 출력을 유추해야 합니다.- 이 작업에서는 주어진 시퀀스에서 특정 패턴이 주어진 후, 비슷한 패턴이 다시 나올 때 올바른 출력을 예측할 수 있어야 합니다. 이는 문맥 기반의 학습과 회상을 요구합니다.
-
해결방법: 이 문제를 해결하기 위해서는 모델이 문맥을 학습하고 연관 지어 기억할 수 있어야 합니다.- 단순한 Copying 작업과 달리, 모델은 이전 시점의 문맥을 연관 지어 기억하고, 필요한 시점에서 이를 회상하여 적절한 출력을 유추해야 합니다.
- 선택적 메커니즘과 함께 연관 기억 메커니즘을 사용하면, 모델이 문맥을 기반으로 필요한 정보를 기억하고, 새로운 입력이 들어올 때 그 정보를 다시 사용할 수 있습니다.
- Selective State Space Model (SSSM)은 이러한 문맥 기반 학습에 적합한 구조를 제공합니다.
-
결과: Induction Heads Task는 문맥 기반의 연관 기억이 중요한 작업입니다. 선택적 메커니즘과 연관 기억 메커니즘을 통해 모델은 문맥 정보를 학습하고, 새로운 입력과 관련된 패턴을 연관 지어 회상할 수 있게 됩니다. 이는 문맥에 맞는 예측을 가능하게 해줍니다.
-
정리
-
Copying Task: 일정한 간격의 시퀀스 데이터를 단순히 복사하는 작업으로, 시간 불변 모델(LTI)을 통해 쉽게 해결됩니다. 이 작업은 고정된 구조의 LTI 모델이 시간 인식을 필요로 하지만, 정보 선택이 단순하기 때문에 처리할 수 있습니다. -
Selective Copying Task: 입력과 출력 간의 간격이 랜덤하게 변동하는 작업으로, 시간 가변 모델과 선택적 메커니즘을 통해 중요한 정보만 선택적으로 기억함으로써 해결됩니다. 이 작업은 내용 인식이 필수적이므로, 기존 LTI 모델에서는 효과적으로 처리하기 어렵습니다. -
Induction Heads Task: 연관 기억 문제로, 문맥 정보를 학습하고 연관 지어 회상하는 능력이 필요합니다. 선택적 메커니즘과 문맥 기반 기억을 통해 해결할 수 있습니다. 이 작업은 복잡한 상관관계를 이해하고 기억하는 것이 중요하여, 보다 발전된 모델 구조가 요구됩니다.
3.2 Improving SSMs with Selection (선택을 통한 SSM 성능 향상)
이 섹션에서는 선택 메커니즘을 기본 SSM 구조에 통합하여, 모델의 성능을 향상시키는 방법을 설명합니다. SSM (S4)는 고정된 파라미터를 사용하여 간단한 구조로 작동하는 반면, SSM + Selection (S6)는 입력 데이터를 동적으로 처리하여 선택적으로 정보를 강조하거나 무시할 수 있는 보다 복잡한 구조입니다.
-
선택 메커니즘: SSSM(S4+Selection, S6)은 SSM의 주요 매개변수()를 입력에 따라 선택적으로 변동시킴으로써 데이터를 처리합니다.
- 이를 통해 모델은 시퀀스의 중요한 부분을 선택적으로 기억하고, 불필요한 부분은 무시할 수 있습니다.
-
시간 불변성을 포기하고 효율성 극대화: 이 선택 메커니즘은 시간 불변성을 유지하지 않기 때문에, 시간에 따라 동적으로 변화하는 시퀀스를 처리할 수 있지만, 이를 효율적으로 구현하기 위해서는 추가적인 알고리즘이 필요합니다.
기본 SSM (S4)과 SSM + Selection (S6)의 알고리즘을 한번 비교하면서 차이점을 살펴보겠습니다.

기본 SSM 구조 (Algorithm 1: SSM (S4))

-
입력:
- : 입력 데이터로, 형태는 (B, L, D)입니다.
- 여기서 B는 배치 크기(batch size), L은 시퀀스 길이, D는 채널 수를 나타냅니다.
-
출력:
- : 출력 데이터로, 입력과 같은 형태를 갖습니다. 즉, (B, L, D)입니다.
-
매개변수:
- , , : 이 세 개의 매개변수는 SSM의 핵심 파라미터로, 각각 잠재 상태와 입력 데이터를 변환하는 역할을 합니다.
- : 시간 스케일을 조정하는 매개변수로, 상태 공간 모델에서 시간적 변화와 관련된 역할을 합니다.
-
작동 방식:
- , , 파라미터가 설정됩니다.
- 값이 파라미터로 설정됩니다.
- 주어진 와 , , 값들을 기반으로 이산화(discretization)가 이루어집니다.
- 상태 공간 모델이 시간 불변(Time-invariant)인 재귀(recursion) 또는 합성곱(convolution)을 통해 계산됩니다.
💡 핵심 특징: 이 알고리즘은 시간 불변적 구조로, 입력 데이터를 고정된 방식으로 처리합니다. 이는 동일한 매개변수를 모든 시점에 적용한다는 의미입니다.
⏱ 계산 방식:
선형 재귀또는합성곱 연산을 사용하여 시간 불변적 처리만 가능합니다.
🔎 (심화) S4 (SSM) 알고리즘의 텐서 연산 및 차원 변환
- S4는 고정된 파라미터와 이산화 방식을 사용하여 모든 시퀀스에 동일한 연산을 적용하고, 그 결과로 일정한 recurrence 또는 convolution을 수행합니다.
-
입력 텐서 (x):
(B, L, D)의 형태를 가지며, B는 배치 크기, L은 시퀀스 길이, D는 각 토큰의 차원을 나타냅니다.- 즉,
B개의 샘플에 대해L개의 시퀀스를 처리하며, 각 시퀀스는D차원의 벡터로 표현됩니다.
- 즉,
-
S4에서는
(D, N)의 고정된 파라미터가 모든 시퀀스에 동일하게 적용됩니다. -
파라미터 A, B, C:
A,B,C는 모두(D, N)형태로 존재하며, 여기서 D는 입력 차원, N은 숨겨진 차원(hidden state)의 크기입니다.A: Structured 매트릭스로 연산을 담당합니다.B:(D, N)크기의 파라미터로서, 입력 텐서와 곱해져 새로운 상태(state)를 생성하는 역할을 합니다.C: 역시(D, N)크기를 가지며 출력 텐서 생성에 영향을 미칩니다.
-
이산화 (discretization): 연속적 시스템을 이산화하여 연산을 수행하는데, 이때 사용하는
Δ는(D)크기의 파라미터입니다. 이 파라미터는 시간 간격을 이산화하여 A, B 매트릭스의 값을 변환합니다. -
S4에서는 고정된 Δ가 사용됩니다. 이산화된 Δ는 각 시퀀스에 대해 각각의 매트릭스 A, B와 곱해져 를 업데이트합니다.
-
최종 출력 y:
(B, L, D)크기의 결과를 반환하며, 이는 time-invariant 방식으로 recurrence나 convolution 연산이 적용됩니다.


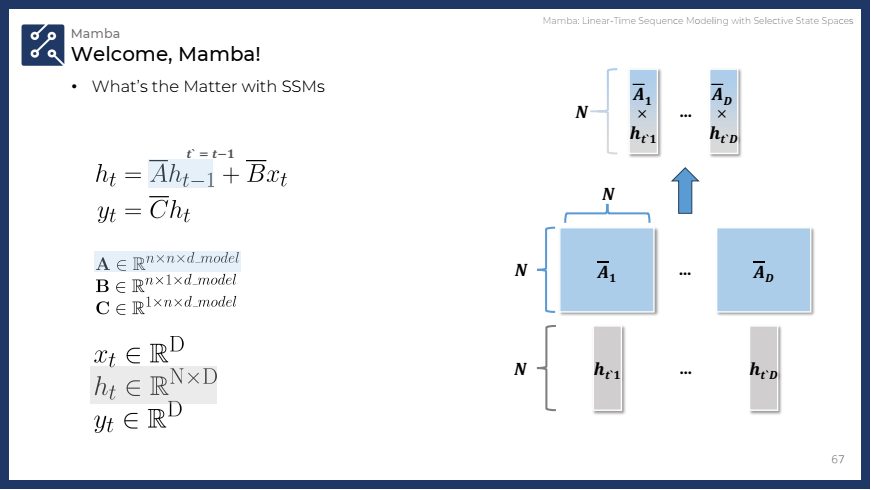


✅ (결론) S4는 고정된 파라미터와 이산화 방식을 사용하여 모든 시퀀스에 동일한 연산을 적용하고, 그 결과로 일정한 recurrence 또는 convolution을 수행합니다.
선택적 SSM 구조 (Algorithm 2: SSM + Selection (S6))

-
입력 및 출력:
- S4와 동일하게, 입력 데이터는 로 (B, L, D)의 형태를 가지며, 출력 데이터도 같은 (B, L, D) 구조입니다.
-
주요 차이점:
- 선택 메커니즘 적용: 입력 데이터에 따라 파라미터가 변화합니다.
- 즉, S6에서는 입력 의존적인 선택(selectivity)이 추가되어 시점에 따라 달라지는 방식으로 처리됩니다.
- 선택적 SSM에서는 , , 파라미터가 입력에 따라 동적으로 변화합니다
- 선택 메커니즘 적용: 입력 데이터에 따라 파라미터가 변화합니다.
-
매개변수 변화:
- , : S4에서는 고정된 매개변수였으나, S6에서는 , 와 같은 함수로 입력 에 따라 변화합니다.
- : S4에서는 고정된 값이었으나, S6에서는 를 통해 입력에 따라 변화합니다. 이는 모델이 시점에 따라 가변적인 시간 스케일을 적용할 수 있게 만듭니다.
-
작동 방식:
- 매개변수 , , 와 시간 스케일 는 입력 데이터 에 따라 변화합니다.
- 각 시점에서 재귀적 계산(recurrence)만 수행되며, 이는 시간에 따라 변화하는 time-varying 모델입니다.
💡 핵심 특징: S6는 시간 가변(time-varying) 구조로, 입력에 따라 매번 다른 방식으로 데이터를 처리할 수 있습니다. 이 선택 메커니즘은 중요한 정보는 기억하고, 불필요한 정보는 무시할 수 있도록 만듭니다.
⏱ 계산 방식: 시간 가변적이기 때문에 재귀적 연산만을 수행하며, 시퀀스 전반에서 중요한 정보를 선택적으로 처리할 수 있습니다.
🔎 (심화) S6 (SSM + Selection) 알고리즘의 텐서 연산 및 차원 변환
- S6는 입력 종속적인 파라미터와 시간 변이에 따른 연산을 사용하여 시퀀스마다 다른 연산이 이루어지며, 이는 동적 모델링에 더 적합합니다.
-
입력 텐서 (x):
(B, L, D)로 동일하지만, 입력 값에 따라 다양한 매트릭스 연산이 이루어집니다. -
S6에서는 입력
x에 따라(B, L, N)차원의 파라미터들이 각 시퀀스별로 다르게 생성됩니다. 이를 통해 각 시퀀스마다 다른 매핑이 일어납니다.
-
파라미터 변환 (sB, sC, sΔ): S6에서는 파라미터들이 입력에 종속적으로 변환됩니다.
sB(x): 입력x에 따라(B, L, N)차원으로 변환됩니다. 즉, 각 배치 B의 각 시퀀스 L에 대해, 숨겨진 차원 N을 생성합니다. 이때 기존 S4에서 모든 시퀀스가 동일한 B 매트릭스를 사용했던 것과 달리, 이제는 각 시퀀스마다 다른 B가 적용됩니다.sC(x): 역시 입력에 따라(B, L, N)차원으로 변환됩니다.sΔ(x): 입력에 따라 시간 간격을 나타내는Δ역시(B, L, D)로 변환됩니다. 즉, 각 배치와 각 시퀀스마다 다른 Δ 값이 주어집니다.
-
이산화 연산 (discretization): S4와 유사하게 이산화를 통해 연산이 이루어지지만, 여기서는 입력에 종속적으로 변환된 Δ가 사용되므로 더 복잡한 형태의 연산이 발생합니다.
-
S6에서는
sΔ(x)가 각 시퀀스별로 다르게 계산됩니다. 이산화된 Δ는 각 시퀀스에 대해 각각의 매트릭스 A, B와 곱해져 를 업데이트합니다.




✔️ 이때 각 시퀀스는 고유한 Δ를 가지고 있기 때문에 S6에서는 토큰마다 서로 다른 연산이 적용됩니다.
- 최종 출력 y: S6의 최종 출력 역시
(B, L, D)차원을 가지지만, S4와 달리 입력에 따라 동적으로 변화한 recurrence 방식을 사용합니다. 특히, 각 시퀀스마다 다르게 이산화된 파라미터가 적용되기 때문에 각 토큰에 맞는 연산이 수행됩니다.
✅ (결론) S6는 입력 종속적인 파라미터와 시간 변이에 따른 연산을 사용하여 시퀀스마다 다른 연산이 이루어지며, 이는 동적 모델링에 더 적합합니다.
💬 Time In-Variant? 무슨 뜻이지?
시간 불변적 처리라는 개념은 "모델의 매개변수(가중치)가 시간에 따라 변하지 않는다는 것"을 의미합니다.
- 즉, 모델이 입력 시퀀스의 각 시점(t)에 대해 동일한 매개변수를 사용한다는 것을 의미합니다.
- 이는 다음과 같은 의미를 가집니다:
정적인 가중치: 기존 SSM 모델에서 사용되는 매개변수 A, B, C 등은 시점마다 고정되어 있습니다. 따라서, 같은 입력에 대해서는 항상 같은 출력을 생성합니다.
- 예를 들어, 과거의 입력이 미래의 출력에 영향을 미칠 때, 출력에 영향을 주는 가중치가 변하지 않기 때문에 특정 입력에 대해 적합하게 조정되지 않습니다.
입력 의존성 부족: 입력 데이터의 특성에 따라 모델이 동적으로 반응하지 못합니다.
- 예를 들어, 어떤 특정 입력이 매우 중요할 때 그 입력에 대한 반응을 강화하거나, 반대로 덜 중요한 정보는 무시하는 방법이 없습니다. 그래서, 입력 시퀀스의 맥락이나 중요한 정보에 따라 모델이 학습된 행동을 변화시킬 수 있는 능력이 제한됩니다.
🔎 S4와 S6의 차이점 분석
- 입력 의존성
- S4: 고정된 파라미터를 사용하여, 모든 시점에서 동일한 계산을 수행합니다. 즉, 모든 시점에서 동일한 방식으로 입력 데이터를 처리합니다.
- S6: 선택 메커니즘을 통해 입력 데이터 에 따라 매개변수들이 동적으로 변화합니다. 이는 데이터의 특성에 따라 각 시점에서 필요한 정보를 선택적으로 처리할 수 있게 만듭니다.
- 시간 불변성(Time-invariant) vs 시간 가변성(Time-varying)
- S4: 시간 불변적인 구조로, 동일한 파라미터가 모든 시점에 적용됩니다. 이는 주로 합성곱(convolution)이나 재귀(recursion) 형태로 데이터를 처리합니다.
- S6: 시간 가변적인 구조로, 입력에 따라 매개변수들이 변화하고, 재귀적 방식으로 계산이 이루어집니다. 이를 통해 시퀀스의 각 시점에서 중요한 정보는 기억하고, 불필요한 정보는 무시하는 선택적 처리가 가능합니다.
- 효율성
- S4: 시간 불변성을 유지하는 SSM은 계산의 병렬화가 가능하여, 비교적 효율적인 계산을 수행할 수 있습니다.
- S6: 선택 메커니즘을 추가함으로써 더 많은 계산이 필요할 수 있지만, GPU의 메모리 계층을 활용한 하드웨어 최적화가 가능해져 효율성을 유지합니다. 특히, 입력 데이터의 특성에 따라 동적인 계산을 수행하여 더 높은 성능을 낼 수 있습니다.
3.3 Efficient Implementation of Selective SSMs (효율적인 선택적 SSM 구현)
이 섹션에서는 Selective State Space Model(SSSM)을 하드웨어에서 효율적으로 구현하는 방법을 다룹니다. 특히, GPU 등을 활용하여 메모리 사용과 계산을 최적화하는 방법에 대해 설명하고 있습니다.
3.3.1 Motivation of Prior Models (이전 모델들의 동기)
이 항목에서는 선택적 상태 공간 모델(SSSM)이 나오기 전, 기존 상태 공간 모델(SSM)이 어떻게 동작했는지, 그리고 왜 개선이 필요했는지를 설명합니다.
-
1. 기존 상태 공간 모델의 동작 원리
- SSM(Structured State Space Model)은 시퀀스 데이터를 처리하기 위해 잠재 상태(latent state)를 사용하는 모델입니다. 이 모델은 시퀀스 내의 정보를 재귀적으로 처리하여, 시점 간의 의존성을 유지하면서 긴 시퀀스 데이터를 효율적으로 처리할 수 있습니다.
- SSM은 시간 불변적(time-invariant)으로 설계되어, 각 시점에서 동일한 방식으로 데이터를 처리합니다. 이는 선형 재귀적 구조(linear recurrence)나 합성곱 연산(convolution)을 사용하여 계산됩니다.
-
2. 기존 모델의 한계
고정된 파라미터: 기존의 SSM은 모든 시점에서 동일한 파라미터로 데이터를 처리합니다. 이는 입력 데이터의 특성이나 중요도에 따라 가변적으로 처리할 수 없다는 한계를 지니고 있습니다. 즉, 모든 데이터를 동일하게 취급하기 때문에 중요한 정보만 선택적으로 처리하는 기능이 부족합니다.복잡한 계산: 시퀀스가 길어질수록 계산 복잡도가 크게 증가합니다. 특히 고차원의 상태 공간에서 작업할 경우, 계산 비용이 매우 높아지며 메모리 사용량도 크게 증가합니다.효율성 문제: SSM은 시퀀스 데이터를 처리할 때 모든 정보를 기억해야 하기 때문에, 메모리 사용량이 매우 크고 계산 시간도 길어집니다. 이는 긴 시퀀스를 처리할 때 효율성이 떨어지는 문제를 초래합니다.
-
3. 개선 필요성
- 입력에 따라 유동적인 처리가 필요합니다. 기존 모델은 모든 시점에서 동일한 방식으로 데이터를 처리했지만, 입력의 중요도에 따라 선택적으로 데이터를 처리하는 기능이 있으면 더 효율적으로 작동할 수 있습니다.
- 또한, 메모리와 계산 자원을 더 효율적으로 사용하기 위해, 기존 모델보다 더 적은 자원으로 높은 성능을 낼 수 있는 최적화된 방식이 필요했습니다.
3.3.2 Overview of Selective Scan: Hardware-Aware State Expansion (선택적 스캔: 하드웨어 인식 상태 확장의 개요)
이 항목에서는 Selective Scan의 개념과, 이를 통해 SSSM이 하드웨어 상에서 어떻게 효율적으로 구현될 수 있는지를 설명합니다. 여기서 중요한 개념은 하드웨어의 메모리 계층을 최적화하여 선택적 상태 공간 모델의 성능을 극대화하는 방법입니다.
-
1. Selective Scan의 개념
Selective Scan은 시퀀스 내에서 중요한 정보를 선택적으로 처리하고, 불필요한 정보는 무시하는 과정을 의미합니다. 이를 통해 모델은 중요한 정보만을 선택적으로 기억하면서, 불필요한 연산을 줄일 수 있습니다.- 시간 가변적(time-varying)이라는 특성을 가진 Selective Scan은 각 시점에서 동적으로 변화하는 상태를 기반으로 연산을 수행합니다.
- 이때 각 시점에서 입력 데이터를 분석하여 중요한 정보만 선택적으로 처리하기 때문에, 메모리 사용과 계산 자원을 절약할 수 있습니다.
-
2. 하드웨어-인식 상태 확장 (Hardware-Aware State Expansion)
-
Hardware-Aware State Expansion은 선택적 상태 공간 모델의 계산을 하드웨어 효율성을 고려하여 최적화하는 방법입니다. -
GPU 메모리 계층 활용: 현대 GPU는 고속 메모리(SRAM)와 대용량 메모리(HBM)를 가지고 있습니다. 선택적 SSM에서는 이러한 메모리 계층을 적절히 활용하여, 자주 사용되는 중요한 데이터는 고속 메모리에 저장하고, 덜 중요한 데이터는 대용량 메모리에 저장함으로써 계산 속도와 메모리 사용을 최적화할 수 있습니다.
- 고속 SRAM은 즉각적인 데이터 접근을 제공하고, 대용량 HBM은 복잡한 연산에 필요한 대량의 데이터를 저장합니다.
- 이 조합은 GPU가 그래픽 렌더링, 머신 러닝, 과학적 시뮬레이션 등 데이터 집약적인 작업을 효과적으로 수행할 수 있게 합니다.
-
Kernel Fusion : Hardware-aware Algorithm
- 처음 등장하는 개념은 아니고, "FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness"에 나오는 idea라고 합니다.
- GPU의 주요 병목 현상은 SRAM과 DRAM 사이의 Copy and PASTE에서 발생하는 것을 확인하였고, 저자는 이러한 memory IO 로 발생하는 병목현상을 줄이기 위하여 kernel fusion을 사용하였습니다.
- Mamba는 계산 자체보다는 메모리 전송 과정에서 병목이 발생하는 GPU의 구조를 고려해 성능을 극대화했습니다.
- 입력 벡터와 가중치 매개변수를 고성능 메모리로 전송한 후 모든 계산을 한 번에 처리하고, 다시 메인 메모리로 데이터를 전송합니다.
- 이로 인해 데이터 전송 시간은 그대로 유지되면서도 16배 확장된 벡터를 사용하는 데 필요한 추가 계산 시간을 거의 무료로 사용할 수 있게 됩니다.

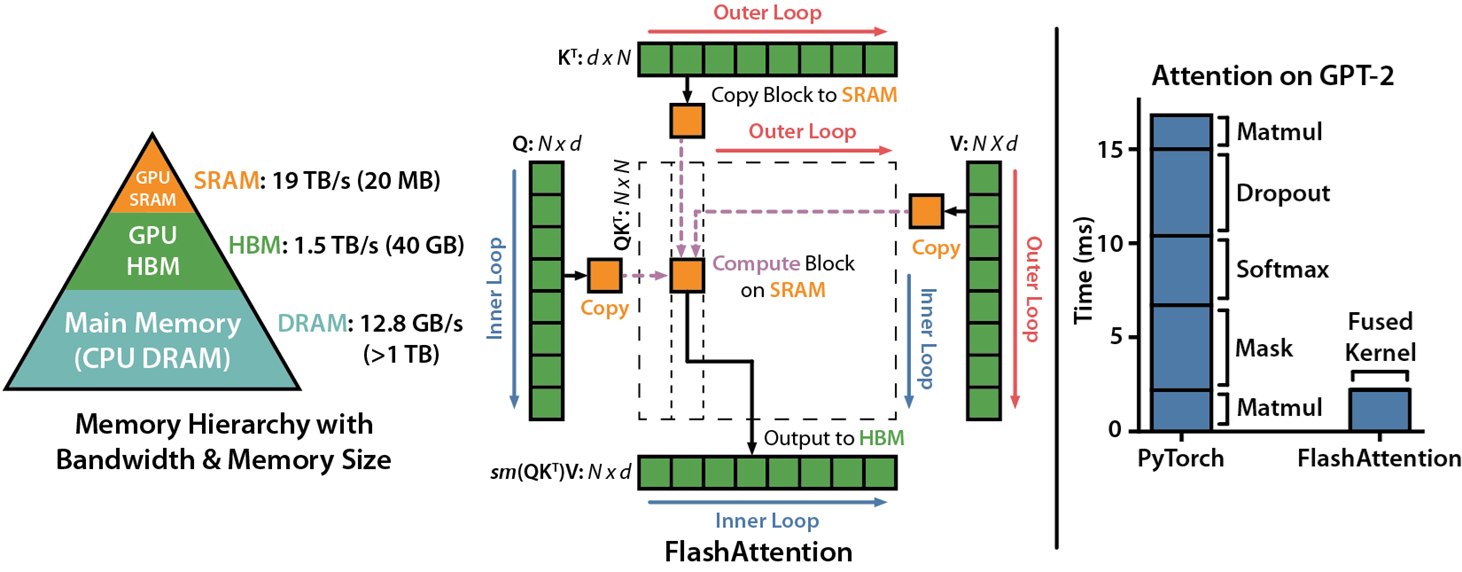
아래 그림은 개략적으로 "입력 벡터와 가중치 매개변수를 고성능 메모리로 전송한 후 모든 계산을 한 번에 처리하고, 다시 메인 메모리로 데이터를 전송"하는 과정을 도시화한 그림입니다. (Source: https://youtu.be/N6Piou4oYx8)
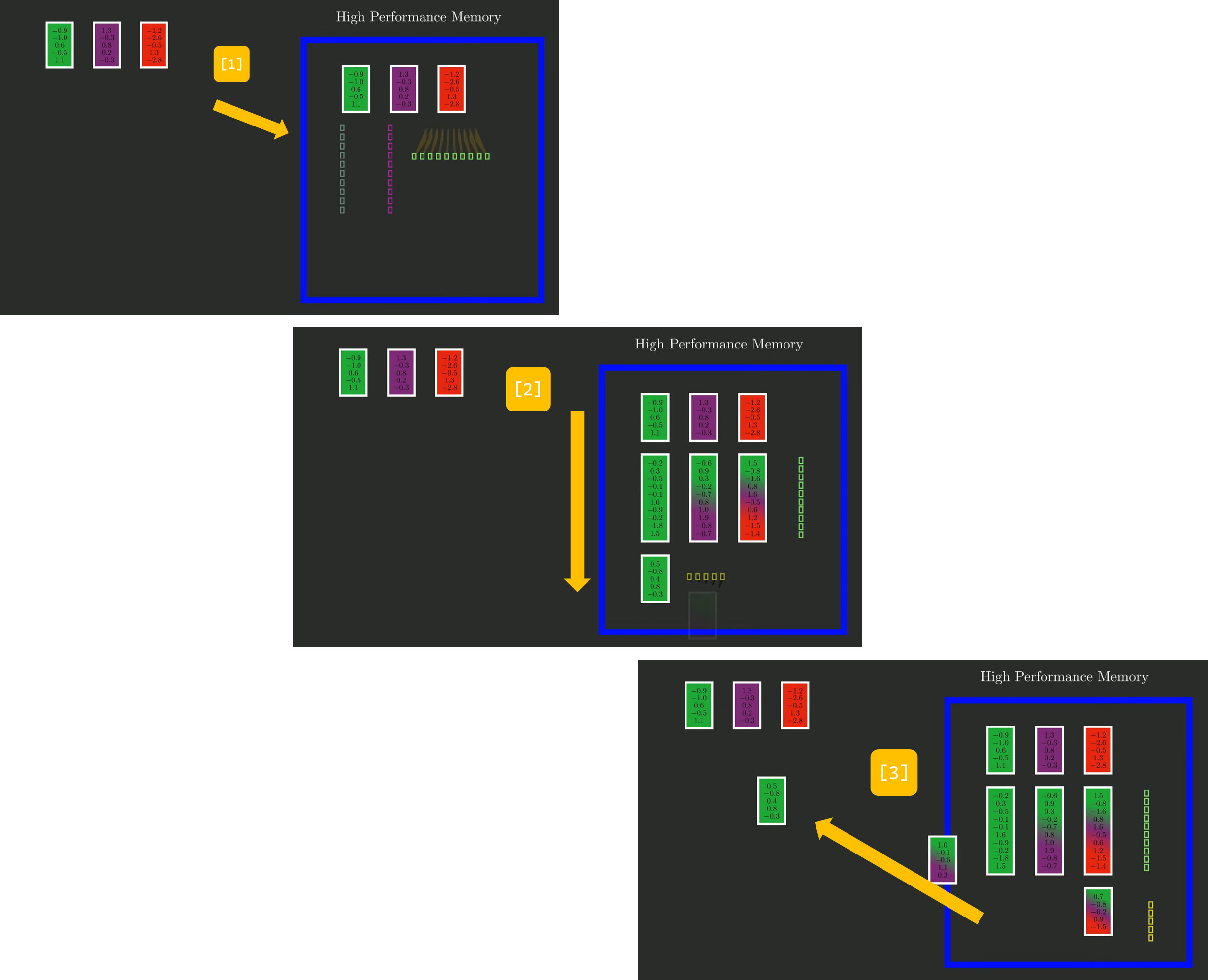
- Scan Operation: Selective Scan 계산을 병렬로 처리할 수 있도록 설계하여, 시퀀스의 여러 시점을 동시에 처리하는 방식을 사용합니다.
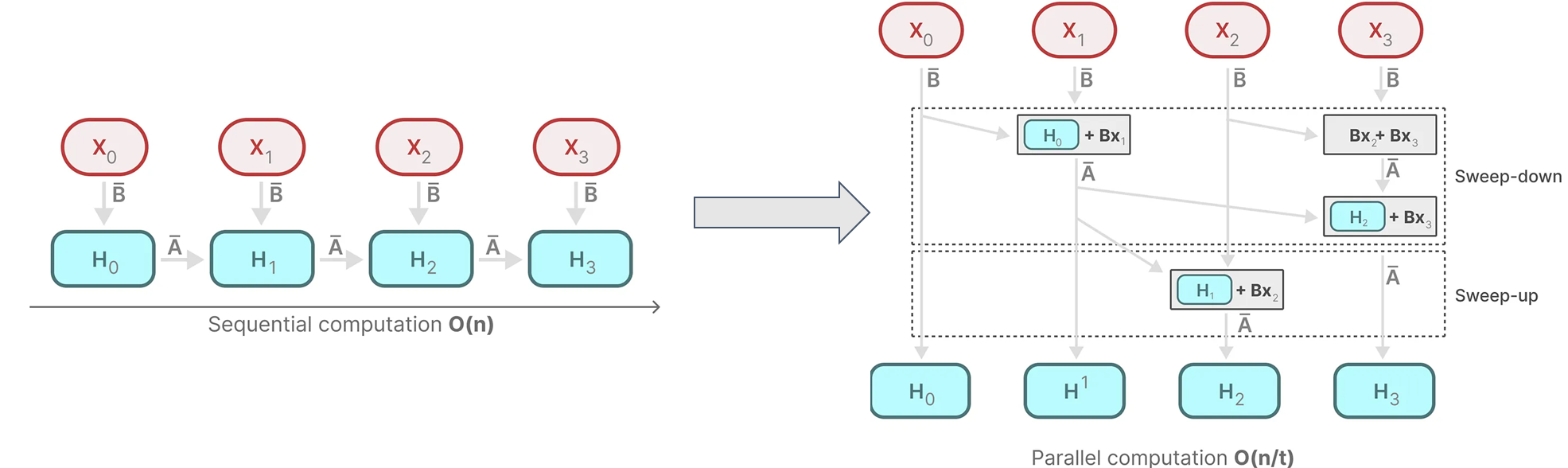
- 병렬 스캔 알고리즘(Parellel Scan Operation)을 통해 입력 시퀀스를 동시에 처리하면서, 선택적으로 필요한 정보를 처리하고 나머지는 건너뛰는 방식입니다.
- 이를 통해 전체 시퀀스를 순차적으로 처리하는 방식보다 더 빠르고 효율적으로 연산을 수행할 수 있습니다.
- 결합규칙(association rule) 기반 접근법을 사용하여 "먼저 계산할 수 있는 것은 계산해주자!" 라는 간단하지만 강력한 방법을 사용했습니다.
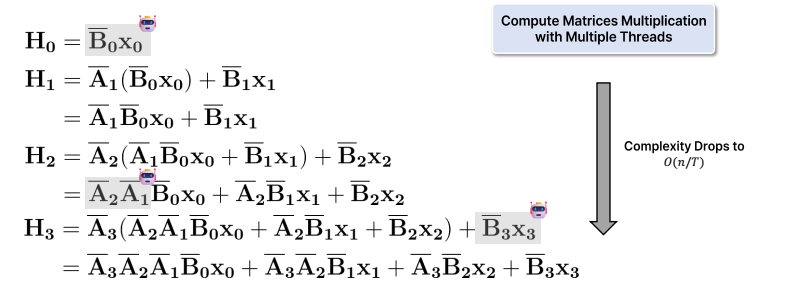
- 이 방법을 사용하면 의 시간 내에 병렬 처리를 수행할 수 있어 계산 속도가 크게 향상됩니다.
- 3. 시간 가변적 선택 처리
- Selective SSM은 시간 가변적이기 때문에, 각 시점마다 다른 방식으로 데이터를 처리합니다. 이로 인해, 각 시점에서 중요한 정보를 선택적으로 처리하고, 재귀적 연산(recurrent operation)을 통해 이전 상태를 기반으로 다음 상태를 계산합니다.
- 각 시점에서 처리되는 데이터의 양을 줄이기 위해, Selective Scan을 통해 입력 데이터를 분석하고 필요한 정보만 선택합니다. 이를 통해 메모리 사용량과 계산량을 줄이고, 연산 속도를 크게 향상시킬 수 있습니다.
3.4 A Simplified SSM Architecture (단순화된 SSM 아키텍처)
- Mamba 아키텍처: SSM을 MLP 블록과 결합하여 간단한 형태의 아키텍처를 만들었습니다. 이 아키텍처는 Transformer처럼 복잡한 구조를 갖지 않으며, 단순하지만 강력한 성능을 보여줍니다.
- 여러 개의 Mamba 블록을 반복적으로 쌓아 모델의 깊이를 확장할 수 있습니다.
- Mamba 블록은 현대 신경망의 다층 퍼셉트론(MLP) 블록과 대부분의 SSM 아키텍처의 기초가 되는 H3 블록을 조합한 것입니다.
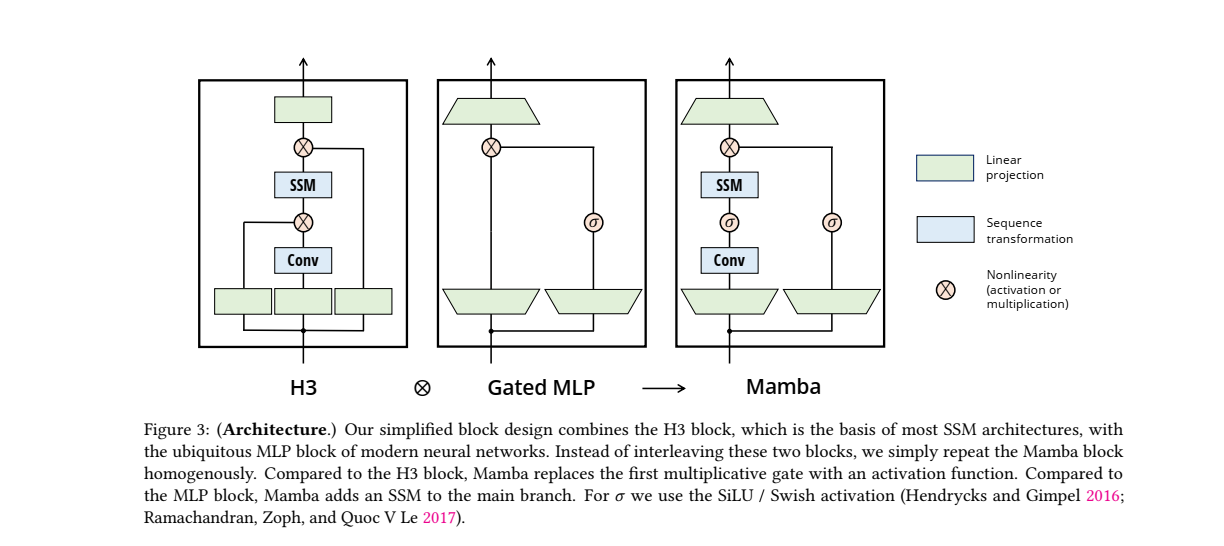
위 그림은 H3 블록, Gated MLP 블록, 그리고 Mamba 블록의 구조를 비교한 것입니다. 각 블록은 현대 신경망에서 사용되는 구조적 차이점을 시각적으로 보여주며, 이를 통해 Mamba 아키텍처가 어떻게 설계되었는지를 설명합니다. 그림에 대한 주요 해석은 아래와 같습니다.
1. H3 Block
H3는 고차원 데이터를 효과적으로 처리하기 위해 설계된 블록 구조로, RNN과 CNN의 장점을 결합하여 순차적 데이터를 처리하는 데 강력한 성능을 보여주고 있습니다.- 이 블록은 과거의 정보와 현재 입력을 기반으로 미래의 출력을 예측하는 방식으로 작동합니다.
- H3의 주요 특징은 긴 시퀀스를 효율적으로 처리할 수 있는 능력과, 시퀀스의 모든 요소에 대한 정보를 고려할 수 있는 구조적 특성입니다.
- 구성 요소:
- SSM: 상태 공간 모델(State Space Model)은 시퀀스 변환을 담당합니다. 이는 주로 재귀적인 특성을 활용하여 시퀀스 데이터를 처리합니다.
- Conv: 합성곱 층이 추가되어 로컬 정보를 처리합니다. 합성곱은 일반적으로 공간적 연관성을 다루는 데 효과적입니다.
- 곱셈 게이트(Multiplicative Gate): SSM과 Conv 사이에 곱셈 게이트가 있어 데이터의 흐름을 조절합니다.
- 동작 원리:
- H3 블록은 SSM과 합성곱 층을 교차 배치하여 각각의 시퀀스 데이터와 로컬 데이터를 처리하며, 곱셈 게이트를 통해 중요한 정보를 통과시키거나 억제할 수 있습니다. 이 구조는 데이터를 처리할 때 유연성을 제공하지만, 계산적으로 복잡할 수 있습니다.
2. Gated MLP
-
Gated MLP는 다층 퍼셉트론(MLP)과 곱셈 게이트(Multiplicative Gate)를 결합하여 입력 데이터에 대한 비선형 변환을 수행하는 구조입니다.
- MLP는 일반적으로 고정된 입력 데이터를 처리하는 데 탁월한 능력을 가지고 있으며, 곱셈 게이트는 데이터의 특성에 따라 중요한 정보를 강조하고, 불필요한 정보는 억제할 수 있도록 도와줍니다.
-
구성 요소:
- MLP: 다층 퍼셉트론(Multi-Layer Perceptron) 블록은 입력 데이터를 비선형적으로 변환합니다.
- 곱셈 게이트(Multiplicative Gate): H3와 마찬가지로 곱셈 게이트가 추가되어, 데이터를 선택적으로 처리하는 역할을 합니다.
-
동작 원리:
- Gated MLP는 MLP와 곱셈 게이트를 결합하여, 입력 데이터에 대한 유연한 변환을 수행합니다. 데이터의 특성에 따라 중요한 정보는 곱셈을 통해 강조되고, 불필요한 정보는 억제될 수 있습니다.
- 그러나 Gated MLP는 비시퀀스 데이터를 처리하는 데는 효과적이지만, 시퀀스 처리에 필요한 메커니즘(예: SSM)이 포함되어 있지 않다는 점에서 시퀀스 기반 작업에 최적화된 구조는 아닙니다.
3. Mamba Block
-
Mamba 블록은 현대 신경망의 다층 퍼셉트론(MLP) 블록과 SSM(Structured State Space Model) 아키텍처에서 중요한 역할을 하는 H3 블록을 결합한 설계입니다.
- 이 구조는 기존의 MLP와 SSM 블록을 교차하거나 혼합하는 대신, 동일한 Mamba 블록을 동질적으로 반복하는 방식으로 설계되었습니다.
-
구성 요소:
- SSM: H3 블록과 마찬가지로 상태 공간 모델(SSM)이 존재하여 시퀀스 데이터를 처리합니다.
- Conv: 합성곱 층이 추가되어, 시퀀스 내의 국소적인 정보 처리에 기여합니다.
- 활성화 함수(SiLU/Swish): H3와는 다르게, 곱셈 게이트 대신 활성화 함수가 사용됩니다. 이 함수는 비선형성을 추가하여 데이터의 표현력을 높입니다.
-
동작 원리:
- Mamba 블록은 SSM과 Conv를 결합하여 시퀀스 및 로컬 데이터를 모두 처리합니다.
- 곱셈 게이트 대신 비선형 활성화 함수(SiLU 또는 Swish)를 사용하여 계산 복잡성을 줄이고 효율성을 높였습니다. 활성화 함수는 데이터의 흐름을 조절하는 데 더 간단한 방식을 사용하며, 게이트의 필요성을 제거하여 더 단순한 구조를 만들었습니다.
- Mamba 블록은 두 가지 주요 연산(SMM, Conv)을 한 블록 내에서 반복하는 간단하면서도 강력한 구조를 채택했습니다.
-
Mamba와 다른 블록의 차이점
- 복잡성 감소: H3 블록에서는 곱셈 게이트를 사용하여 데이터를 선택적으로 처리하지만, Mamba는 이를 제거하고 활성화 함수로 대체함으로써 계산 복잡성을 줄였습니다.
- 단순화된 아키텍처: Mamba는 SSM과 Conv를 동일한 블록 내에서 반복적으로 사용하여 매우 균일하고 단순한 아키텍처를 유지하면서도 성능을 최적화했습니다. 이는 전체적으로 더 빠르고 효율적인 계산을 가능하게 합니다.
- 비선형 활성화: Mamba에서는 곱셈 게이트 대신 SiLU/Swish와 같은 비선형 활성화 함수를 사용하여 데이터의 흐름을 조절합니다. 이는 모델의 표현력을 유지하면서도 계산 복잡성을 줄이는 중요한 변화입니다.
✨ Mamba 블록은 H3 및 Gated MLP와 비교하여 더 단순하고 효율적인 아키텍처를 제공합니다. SSM과 Conv를 적절히 결합하여 시퀀스 데이터와 로컬 정보를 동시에 처리하며, 활성화 함수로 비선형성을 부여하여 모델의 성능을 높였습니다.
3.5 Properties of Selection Mechanisms (선택 메커니즘의 특성)
-
선택 메커니즘의 효과: 선택 메커니즘은 불필요한 데이터를 무시하고, 중요한 데이터를 선택적으로 처리하는 능력을 가집니다. 이를 통해 시퀀스의 긴 문맥을 처리할 때 효율성이 증가하며, 긴 시퀀스에서도 성능 저하가 발생하지 않습니다.
-
변수 간 상호작용: 선택 메커니즘은 시퀀스의 각 요소들이 상호작용하는 방식을 조절하며, 이러한 조절 능력은 특히 텍스트나 DNA와 같은 이산적인 데이터에서 효과적입니다.
3.6 Additional Model Details (추가 모델 세부사항)
- 실수 및 복소수 처리: 선택적 SSM은 복소수와 실수를 모두 처리할 수 있지만, 특정 작업에서는 실수 기반 모델이 더 나은 성능을 보일 수 있습니다.
- 초기화 및 파라미터화: 선택적 파라미터의 초기화 방식에 따라 모델의 성능이 달라지며, 각 파라미터에 대한 자세한 설명을 통해 모델의 안정성을 유지합니다.
4. Empirical Evaluation
Mamba 모델을 다양한 데이터 유형과 시퀀스 길이에서 테스트한 결과를 소개합니다.
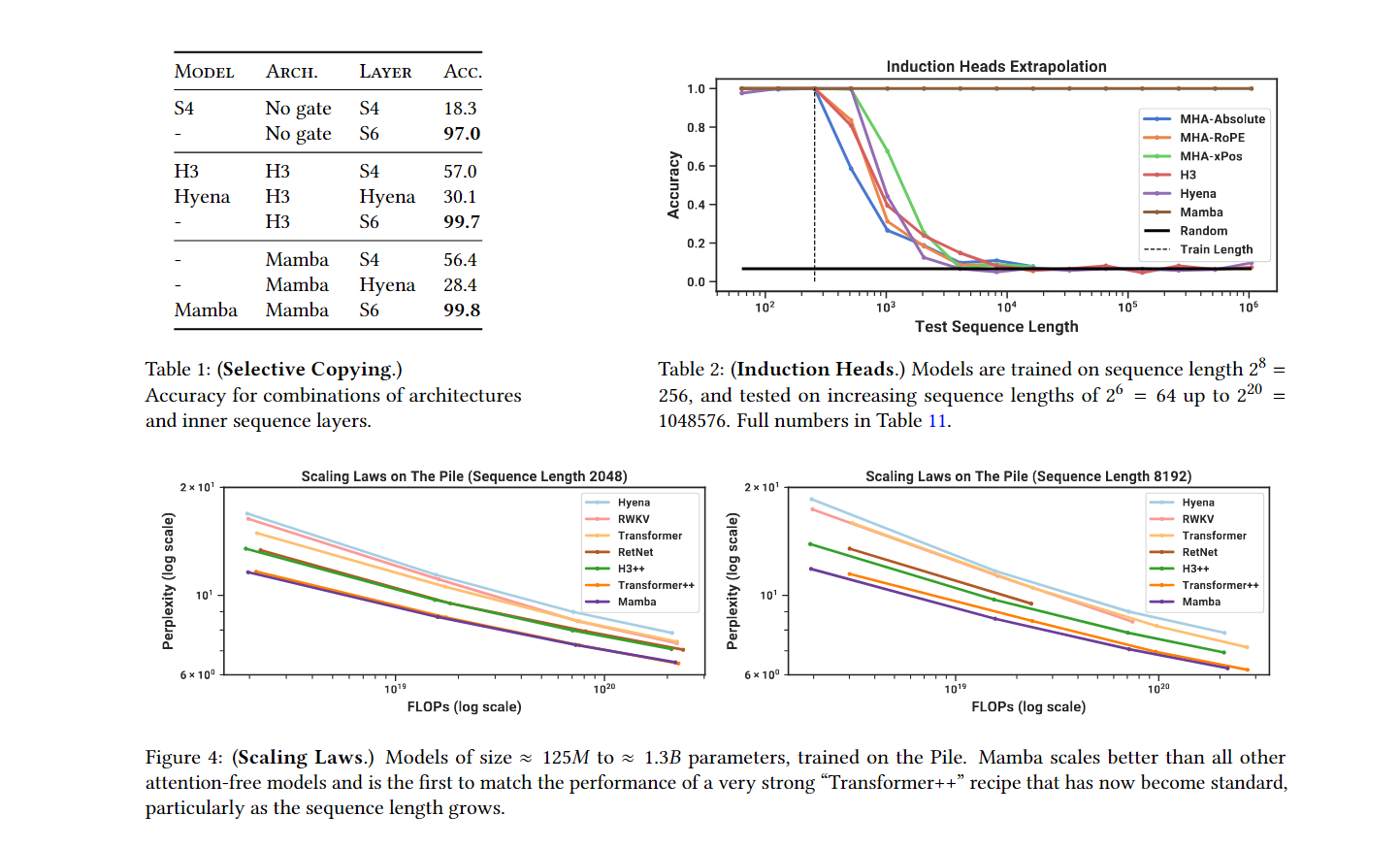
4.1 Synthetic Tasks (합성 작업)
-
Selective Copying: 선택 메커니즘을 사용한 Mamba는 시퀀스의 중요한 부분을 기억하고 나머지를 무시하는 작업에서 뛰어난 성능을 보입니다. 시퀀스 길이가 매우 길어도 Mamba는 성능 저하 없이 정확도를 유지합니다.
-
Induction Heads: LLM의 맥락 학습 능력을 평가하는 Induction Heads 작업에서도 Mamba는 중요한 토큰을 기억하며 성능을 유지합니다. 훈련 시 256 길이의 시퀀스로 학습한 모델이 1백만 길이의 시퀀스에서도 정확한 결과를 보입니다.
4.2 Language Modeling (언어 모델링)
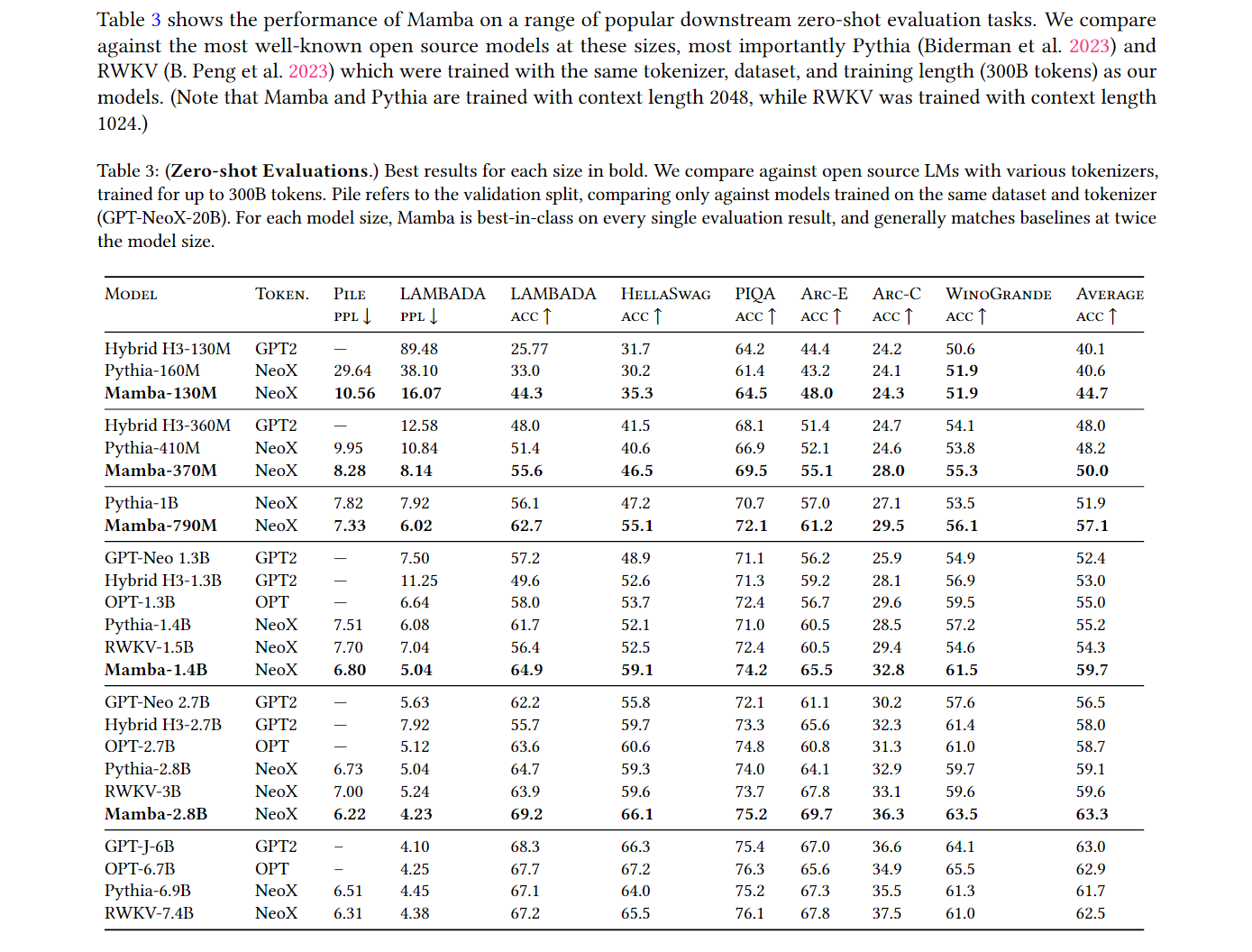
- Mamba의 언어 모델링 성능: Mamba는 텍스트 데이터에서 Transformer와 비슷하거나 더 나은 성능을 보입니다. 특히, 1B 이상의 파라미터를 가진 모델에서는 Transformer와 비슷한 수준의 성능을 내는 첫 번째 선형 시퀀스 모델입니다.
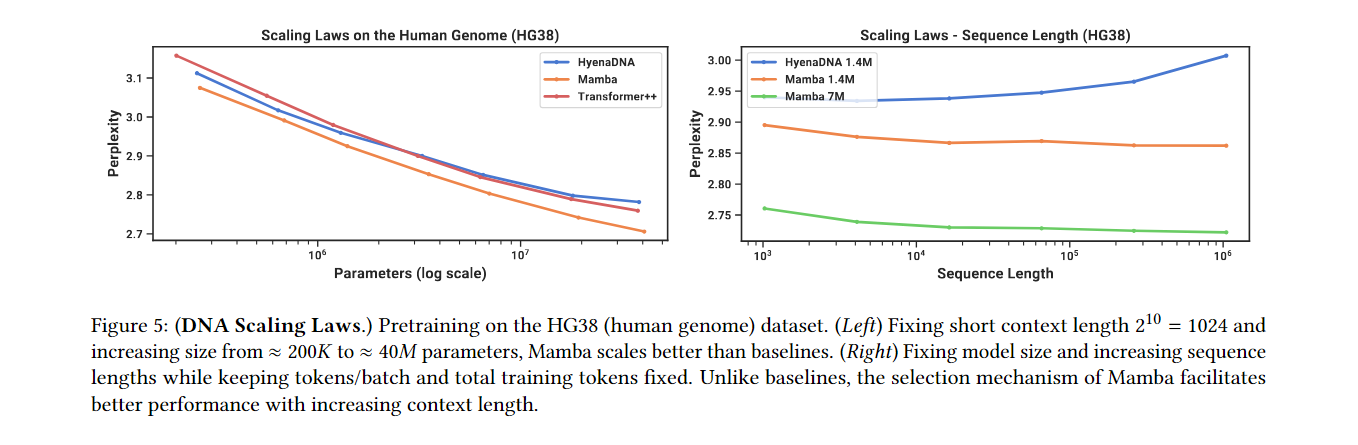
4.3 DNA Modeling (DNA 모델링)
- DNA 시퀀스 처리: Mamba는 긴 시퀀스 데이터를 처리하는 데 뛰어나며, 기존의 Transformer 모델보다 더 나은 성능을 보입니다. DNA의 경우 긴 문맥 의존성이 중요한데, Mamba는 이러한 데이터를 잘 처리합니다.
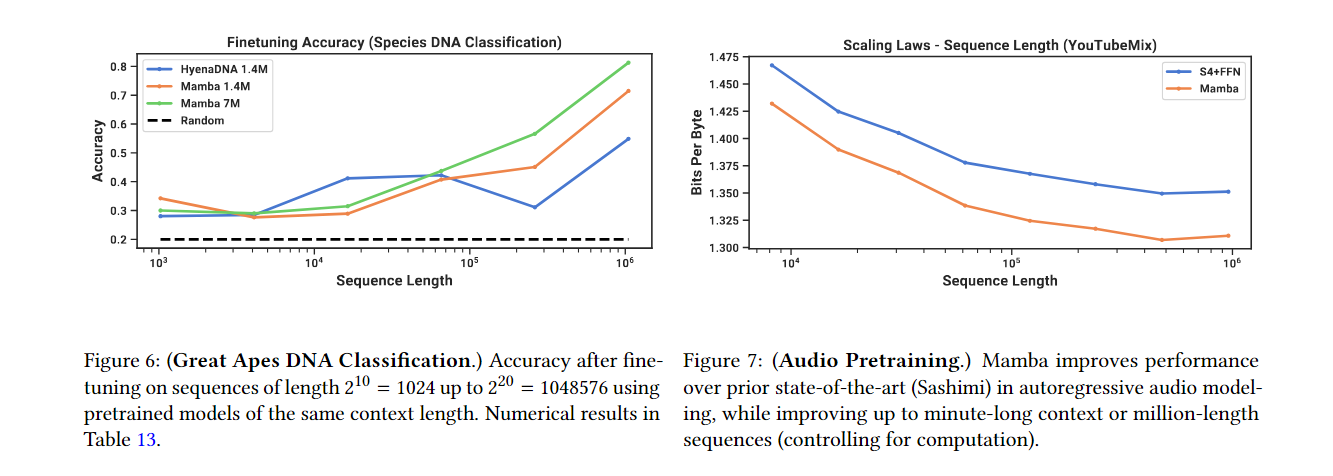
4.4 Audio Modeling and Generation (오디오 모델링 및 생성)
- 오디오 데이터 처리: Mamba는 오디오 데이터를 처리할 때도 효율적이며, 기존 모델보다 더 긴 시퀀스를 처리할 수 있습니다.
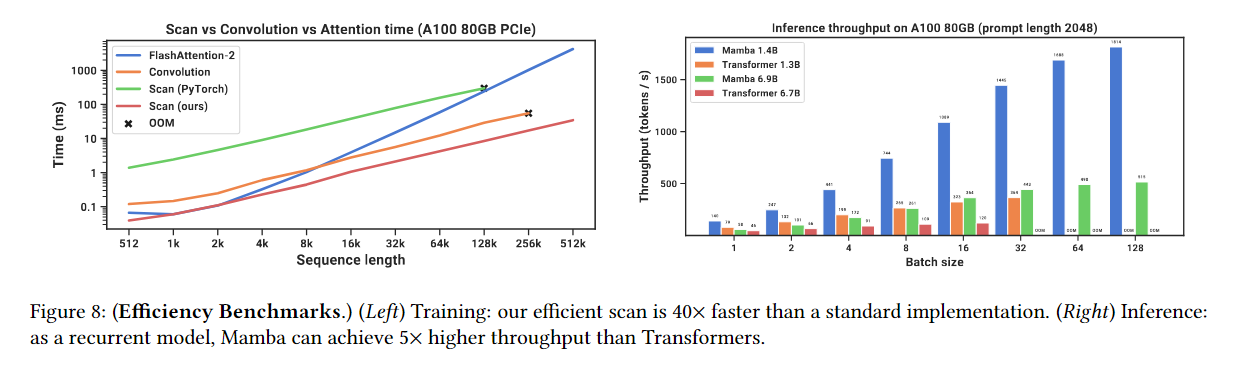
4.5 Speed and Memory Benchmarks (속도 및 메모리 벤치마크)
- 처리 속도: Mamba는 Transformer보다 5배 빠른 추론 속도를 보이며, 긴 시퀀스를 처리할 때 메모리 사용량도 매우 적습니다.
4.6 Model Ablations (모델 에블레이션)
- 파라미터 분석: 선택적 파라미터를 추가할수록 성능이 향상되며, 특히 Delta 파라미터가 모델 성능에 가장 중요한 영향을 미칩니다.
Reference
Paper
- Mamba 논문 : https://arxiv.org/pdf/2312.00752
Blogs
- A Visual Guide to Mamba and State Space Models: https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mamba-and-state
Youtube
- MAMBA from Scratch (https://youtu.be/N6Piou4oYx8)
- Mamba Paper Review, DSBA 천재원 (https://youtu.be/JjxBNBzDbNk)
- Mamba Paper Review, AirLab 이정운 (https://youtu.be/l-dQCTv9wIg)
