[Paper Review] Transferring Inductive Bias Through Knowledge Distillation - (2/3)
Inductive-Bias-Series
안녕하세요 :) 오늘은 지난번 포스팅에 이어서 "Transferring Inductive Bias Through Knowledge Distillation" 논문에 대한 정리를 이어나가 보도록 하겠습니다. 이전 포스팅에서 본 논문에서 다루게 될 주요 개념들인 Knowledge Distillation과 Inductive Bias에 대한 설명을 해보았는데요. 이번 포스팅에서는 해당 기법들을 적용하여 저자가 수행한 실험들 중 첫번째 시나리오에 대해서 이갸기를 풀어가보도록 하겠습니다.
이전 포스트가 궁금하신 분은 여기를 통해 확인해 보실 수 있습니다.
논문의 목적(복습)
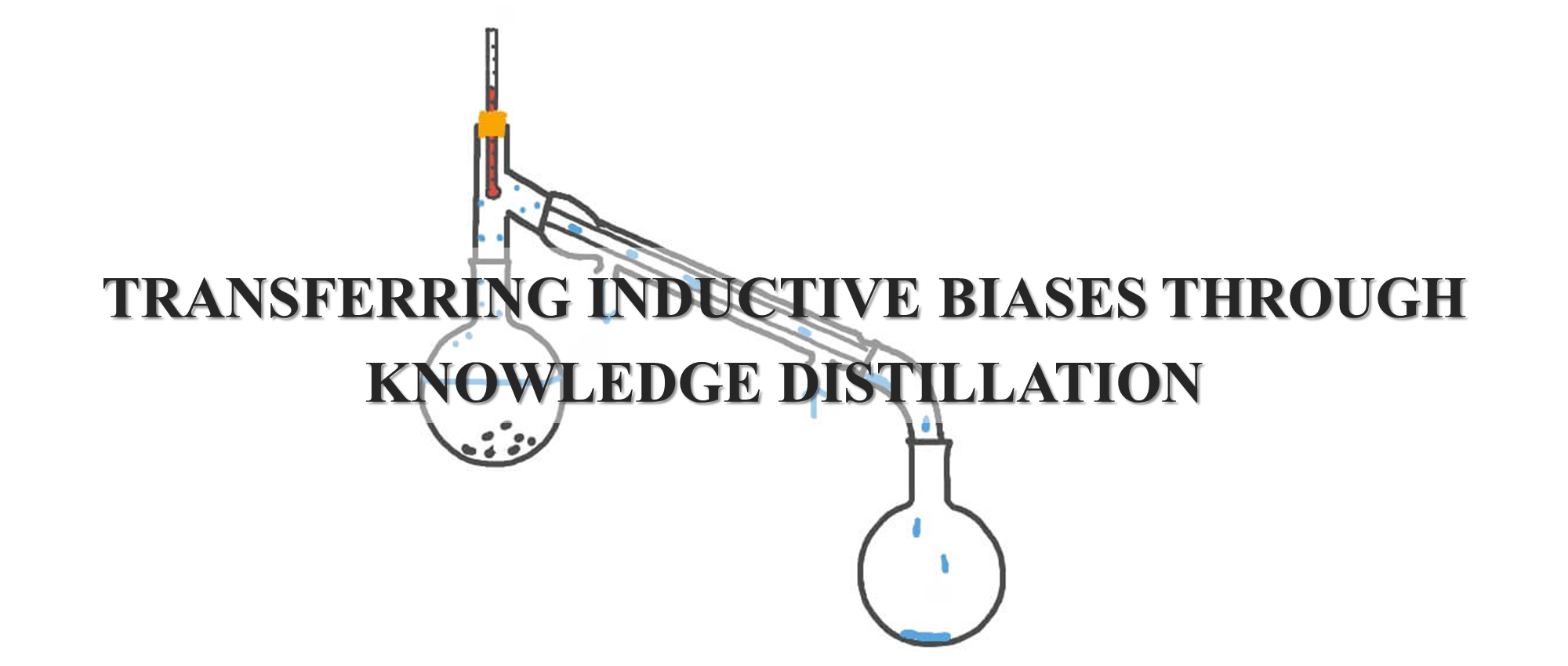
본 논문은 "Knowledge Distillation에서 Teacher Model이 Student Model에 전하는 Dark Knowledge에 과연 Inductive Bias에 대한 정보가 존재할까?" 라는 질문에서 비롯된 의문점을 확인하기 위해 두가지 시나리오를 가지고 실험을 전개합니다. 첫 번째 시나리오는 RNNs(Teacher Model)과 Transformers(Student Model)를, 그리고 두 번째 시나리오는 CNNs(Teacher Model)과 MLPs(Student Model)를 비교합니다.
본 연구는 (1) 정말 선생 모델들이 가지고 있는 Inductive Bias가 얼마나 유의미한가를 보여주가, (2) 선생 모델에게 지식은 전수 받은 학생 모델이 정말 선생 모델과 유사한 학습의 결과물을 보여주는 가 를 보여주는 것을 목적으로 실험을 진행하였습니다.
이번 포스팅에서는 첫번째 시나리오(RNNs vs Transformers)에 대해 다뤄보도록 하겠습니다.
Scenerio 1
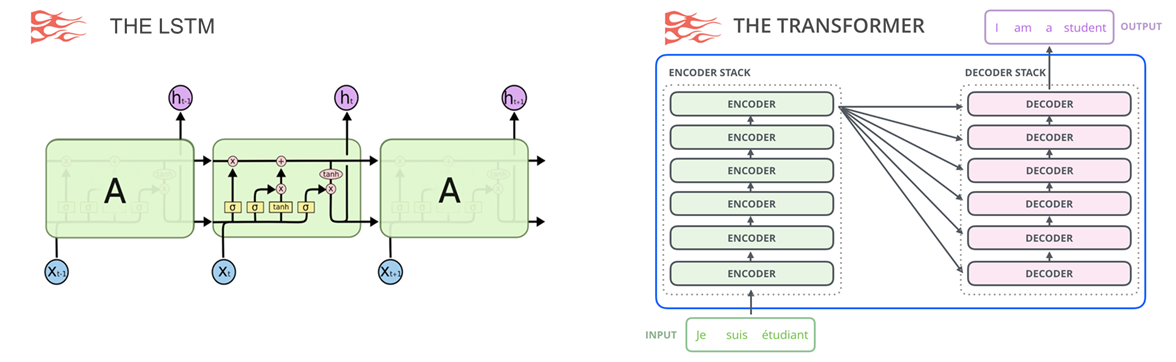
먼저 첫번째 시나리오는 RNN중 대표적인 모델인 LSTM과 Transformer를 비교합니다. 두 모델 모두 Natural Language Processing(자연어 처리)에서 많이 사용되는 모델이며, Transformer는 LSTM에 비해 비교적 최신에 나온 논문으로 학습 데이터가 충분히 많으면 수많은 목표(task)에 있어서 뛰어난 성능을 보여주는 모델입니다.
- LSTM (논문 : Long short-term memory, 1997) (링크)
- Vanila Transformer (논문 : Attention is all you need, 2017) (링크)
Picture from "https://jalammar.github.io/illustrated-transformer"
데이터가 충분히 많다면 비교적 최근에 나온 Transformer이 LSTM보다 더 좋은 예측 성능을 갖는 것이 자명합니다. 하지만, 데이터가 한정적(limited)인 상황에서는 특정 task에서 LSTM이 Transformer가 더 강력한 모델이라는 연구가 존재합니다. 논문에서 예로 드는 task가 바로 "Subject-verb agreement prediction task"인데요. 해당 task는 "Assessing the Ability of LSTMs to Learn Syntax-Sensitive Dependencies (2016)"이라는 논문에서 구문(syntax) 정보를 학습하는데 유용하다고 소개되었습니다.
이를 이해하기 위해서는 영문법을 조금 알고가야 하는데요. 영어 3인칭 현재형 동사의 형태는 구문 주어의 머리가 복수인지 단수인지에 따라 달라지며, 이러한 동사는 주어 옆에 항상 위치해 있지 않아도 됩니다. 좌측에 있는 문장들은 바로 옆에 붙어있는 케이스들이며, 우측에 있는 예시는 떨어져있는 케이스입니다.
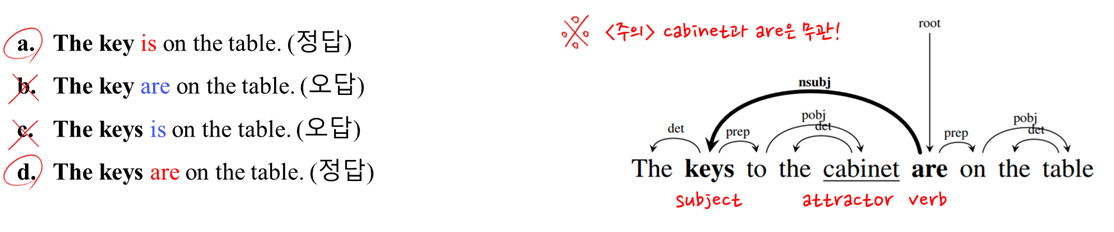
이러한 문법 특징을 이용하여 LSTM이 한정된 리소스를 가지고 학습하면, Transformer(FAN)보다 좋다는 것을 "The Importance of Being Recurrent for Modeling Hierarchical Structure (2018)"에서 주장합니다. 본 논문에서 사용한 평가 기준은 아래 그림과 같이 Input 문장 이후에 올 (a) 단어가 어떤 것인가를 예측 또는 (b) 단수인지 복수인지 를 얼마나 잘 예측하는 가를 평가 지표로 잡게 됩니다. 그리고 아래 그래프에서 distance란 구문 주어와 3인칭 현재형 동사의 거리, # of attracters는 구문 주어(정답, 참고해야할 명사) 외에 3인칭 현재형 동사를 유혹하는 다른 명사들의 갯수를 의미합니다.
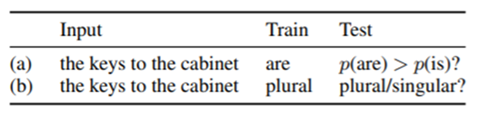
From "The Importance of Being Recurrent for Modeling Hierarchical Structure (2018)"
RNNs' Inductive Bias
자! 이제 문법 공부가 끝났으니 본격적으로 모델에 대해 이야기 해볼까요? RNN(Recurrent Neural Network)은 시퀀스(Sequence) 모델입니다. 즉, 그 말은 입력과 출력을 시퀀스 단위로 처리를 한다는 의미인데요. 여기서 비교 모델로 사용하는 LSTM 역시 이러한 RNN을 근본으로 하는 모델이므로, 가볍게 RNN에 대한 개념과 RNN의 Inductive Bias(귀납적 편향)에 대해 이야기하고 넘어가도록 하겠습니다.
아래 그림을 참고하면서 설명드리도록 하겠습니다. 해당 그림에서 공통적인 부분에 대해 먼저 설명드리자면, 빨간색 박스는 input, 파란색 박스는 output, 초록색 박스는 (hidden) state입니다.
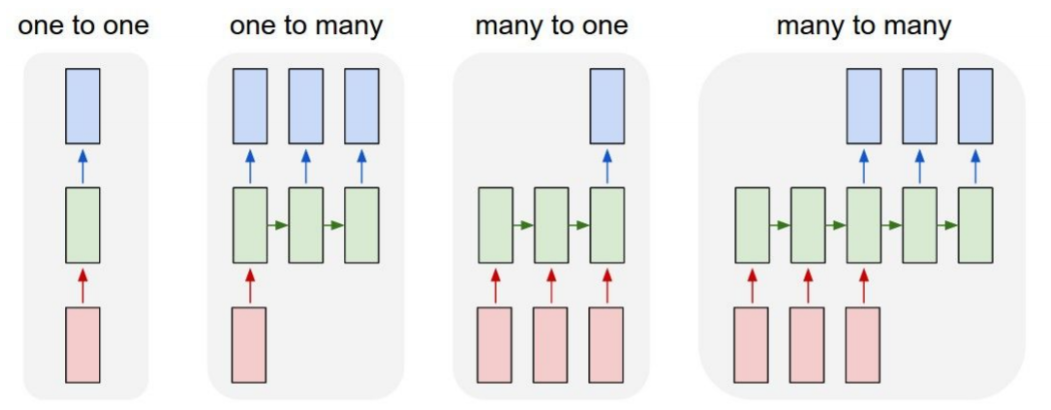
Picture from CS231n
-
one-to-one: Vanila Neural Network
우리가 통상적으로 알고 있는 뉴럴네트워크로, 하나의 input에 하나의 output이 대응되는 구조입니다. -
one-to-many: Recurrent Neural Network
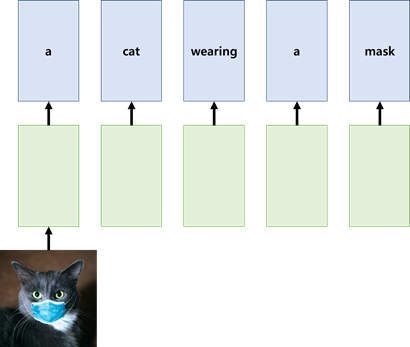
하나의 input에 여러 개의 output이 대응되는 구조로, 대표적인 예시로 이미지가 하나가 들어갔을 때 이를 설명하는 문장(sequence of words)이 결과로 나오는 Image Captioning Task가 존재합니다.
many-to-one: Recurrent Neural Network
여러 개의 input에 하나의 output이 대응되는 구조로, 대표적인 예시로 문장이 들어갔을 때 해당 문장의 어조(감성)을 분류하는 Sentiment Analysis가 존재합니다.
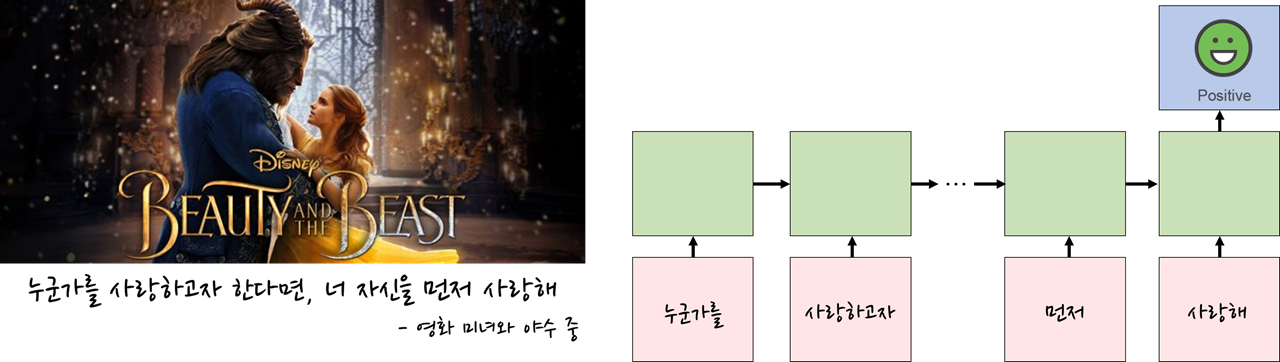
many-to-many: Recurrent Neural Network
여러 개의 input에 여러 개의 output이 대응되는 구조로, 대표적인 예시로 영어 문장이 들어갔을 때 이를 한국어 문장으로 번역하는 Machine Translation이 존재합니다.
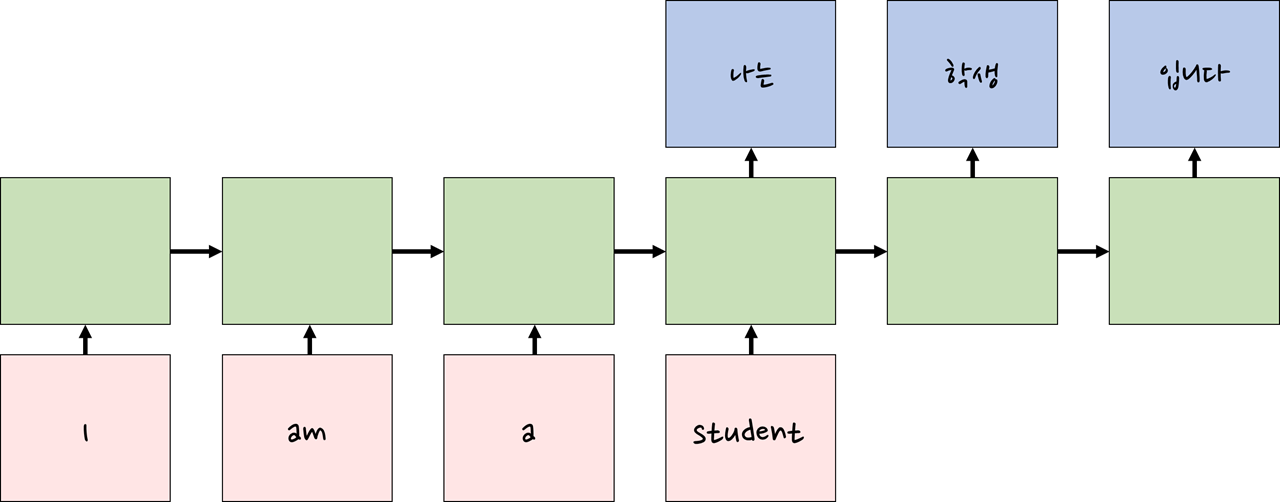
이렇듯 RNN은 매 Timestep마다 새로운 input이 들어오면, 이를 fucntion에 통과시키고 state를 업데이트하게 ouput을 반환하게 됩니다. 이때, function은 전부 동일하며, 동일한 parameter를 사용합니다. 또한, 다음 state는 이전 state 정보만을 받을 수 있으며, 더 이전 정보나 미래 정보는 절대 볼 수 없습니다.
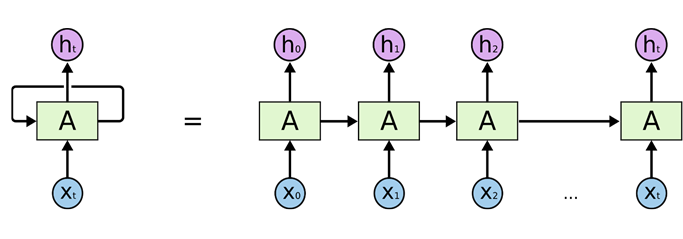
이러한 앞에서 소개한 RNN의 특징들이 바로 RNN의 inductive bias입니다. RNN의 inductive bias는 다음과 같이 총 3가지로 논문에서 이야기하고 있는데 이는 각각 다음과 같습니다.
-
Sequential-lity: 모델에 넣어주는 데이터들이 순차적으로 들어오도록 강제하는 "순차성" -
Memory Bottleneck: 해당 timestamp 바로 이전의 hidden state정보만을 모델이 받을 수 있기 때문에, 해당 hidden state가 더 이전 과거의 내용까지 전부 함축적으로 갖추도록 강제하는 "메모리의 병목성" -
Recursion: 모든 함수가 동일하도록 강제하는 "재귀성"
Transformers' Inductive Bias
Transformer는 아래 그림과 같이 인코더에서 입력 시퀀스(ex. I am a student)를 입력받고, 디코더에서 출력 시퀀스(ex. Je suis étudiant)를 출력하는 인코더-디코더 구조의 모델입니다. 본 모델은 RNN처럼 순차적으로 단어가 들어가지 않아도 Self-Attention과 Feed Forward Neural Network만으로도 좋은 성능을 낼 수 있다는 것을 보여준 획기적인 논문(방법론)입니다. 본 포스트에서 Transformer에 대한 개념 전반을 다루기에는 너무 길어지기 때문에 RNN에 비해 제약이 적다는 정도만 이해하시고 넘어가면 좋을 것 같습니다.
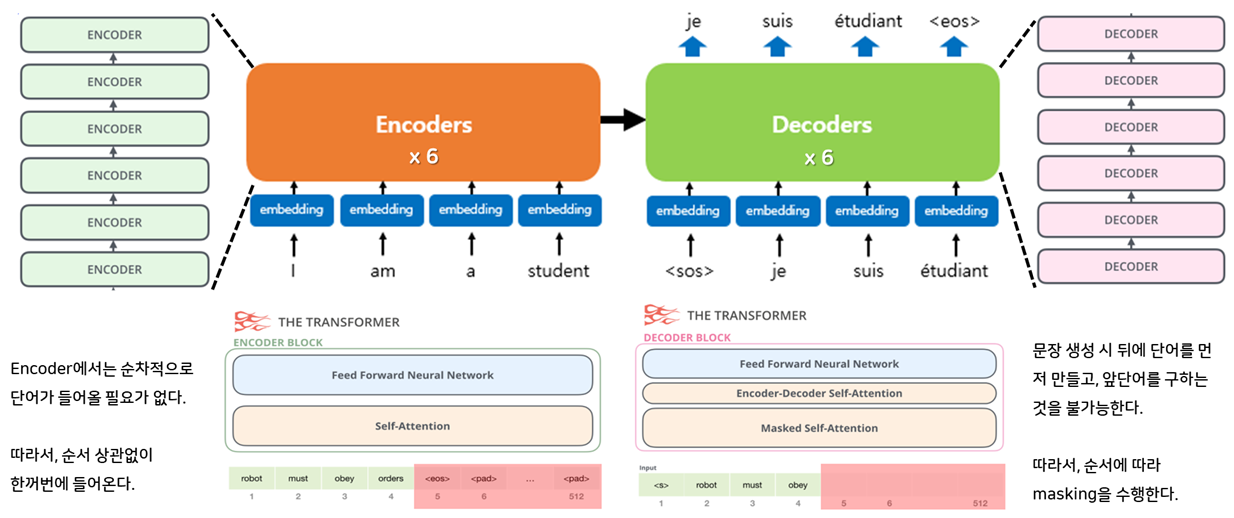
Picture from "딥러닝을 이용한 자연어처리 입문 (유원준)"
Transformer의 경우, RNN에 비해 제약 또는 Inductive Bias가 훨씬 약한 이유는 아래와 같습니다.
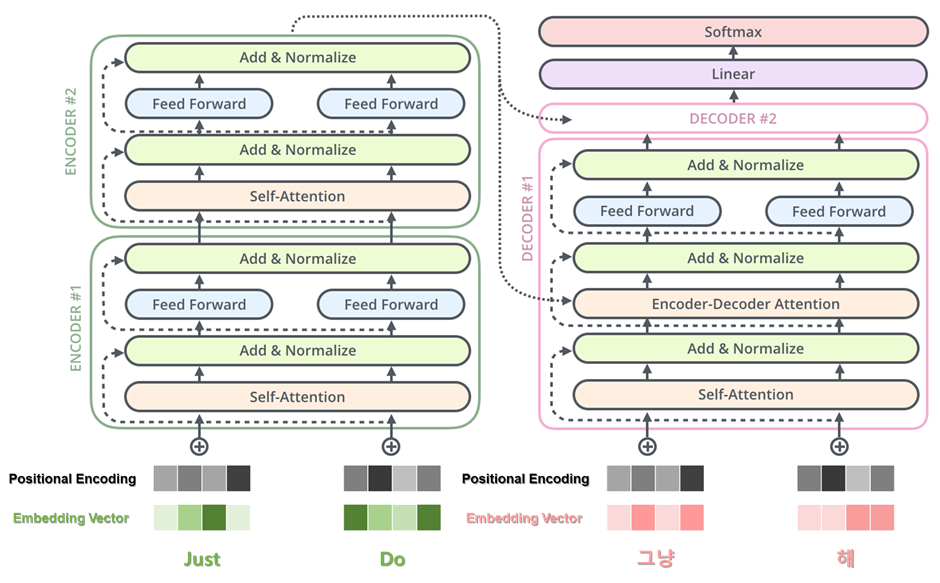
Picture from "https://jalammar.github.io/illustrated-transformer"
-
Transformer는 토큰들의 위치 정보를 임배딩하기 위해 positional encoding 을 더해주는 데 이는 단순한 sin함수와 cos함수로 도출된 벡터값으로, 모델 단에서 강제적로 데이터를 순차적으로 받게하는 RNN과 같은
Sequential-lity가 존재하지 않습니다. -
Transformer는 전체 토큰에 대한 정보를 Self-attention을 통해 전반적으로 받을 수 있기에, 이전 timestamp의 hidden-state만을 전달받을 수 있는 RNN과 같은
Memory Bottleneck이 존재하지 않습니다. -
Transformer는 Encoder에서 Decoder로 한번에 가는 구조이므로, 같은 함수가 연속적으로 사용되는 RNN과 같은
recursion이 존재하지 않습니다.
Experiment Settings
Dataset
- Subject-verb agreement dataset of Linzen et al. (2016)
Performance Metric
- μ – Accuracy : micro – accuracy
- D – Accuracy : accuracy over different groups in terms of distance
- A−Accuracy : accuracy over numbers of attractors
Learning Objective
- Language Modelling (LM) Setup : 다음에 올 단어를 직접 예측하는 Setup
- Classification Setup : 다음에 올 단어의 단수 복수를 예측하는 Setup
각각의 Objective에 따른 실험 모델군
-
Language Modelling (LM) Setup :
1.LSTM: Base LSTM
2.Small LSTM: LSTM with smaller parameter
3.Transformer: Base Transformer
4.Small Transformer: Transformer with smaller parameter -
Classification Setup :
1.LSTM: Base LSTM (Sequentiality + Memory bottleneck + Recursion)
2.Transformer: Base Transformer (No Inductive Bias)
3.Transformer-seq: Base Transformer에 Sequentiality를 강제로 추가해준 모델 (Sequentiality)
4.Universal Transformer-seq: Transformer-seq에 Recursion을 강제로 추가해준 모델 (Sequentiality + Recursion)
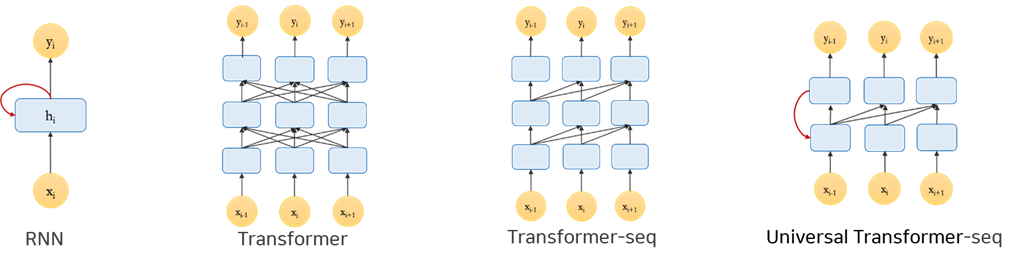
Experiment Results
본 논문은 실험을 통해 다음 2가지를 증명하고자 하였습니다:
- Distillation 없이 실험을 진행하여, 정말 Teacher 모델들이 가지고 있는 "Inductive Bias가 얼마나 유의미한가"를 보여주고자 하였습니다.
- Distillation을 수행하여 Teacher 모델에게 Inductive Bias를 전수 받은 "Student 모델이 정말 Teacher 모델과 유사한 학습의 결과물을 보여주는가"를 보여주고자 하였습니다.
Without Distillation
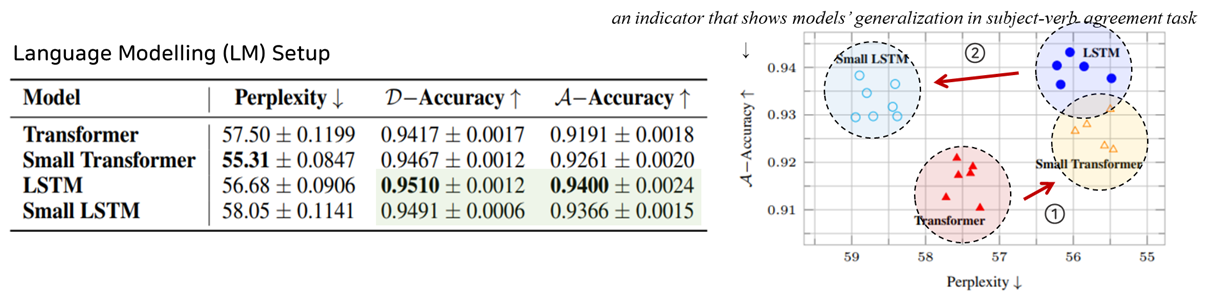
- LSTM이 Transformer보다 전반적으로 좋은 성능(위에서 소개한 평가기준 기반)을 보이는 것으로 보아, 이러한 input의 계층적 구조(hierarchical structure)를 학습함에 있어서 inductive bias가 더 강한 LSTM이 inductive bias가 약한 Transformer보다 좋은 것을 확인할 수 있습니다.
- Transformer 모델은 적은 데이터로 학습을 수행하면 과적합되는 경향이 존재합니다. 따라서, 오히려 모델 사이즈를 줄여주게(small)되면 과적합을 해소되어 모델 성능이 향상합니다.
- 반대로 LSTM은 해당 task를 수행하기에 적합한 Inductive Bias를 가지고 있기에 모델 사이즈를 줄이면 성능이 낮아지게 됩니다.
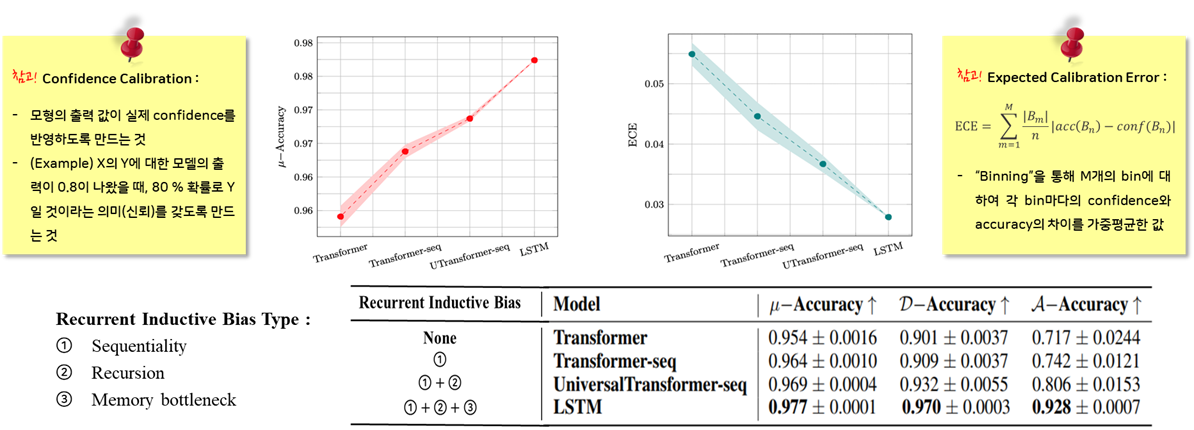
- Inductive Bias가 하나씩 추가될때마다 평가지표의 성능이 좋아지는 것을 확인할 수 있습니다.
- Accuracy의 증가- Expected Calibration Error(ECE)의 감소
※ 여기서 잠깐!
(참고) Calibration Error란, 모형의 출력 값이 실제 confidence를 반영하도록 만드는 것입니다. 예를 들어, X의 Y에 대한 모델의 출력이 0.8이 나왔을 때, 80 % 확률로 Y일 것이라는 신뢰(의미)를 갖도록 만드는 것을 의미합니다. 이러한 Calibration Error는 Bining이라는 작업 통해 M개의 Bin에 대하여 각각의 Bin마다의 Calibration Error를 구하여 평균(Expectation)을 내서 산출하므로, Expectated Calibration Error(ECE)로 평가 지표가 사용됩니다.
With Distillation
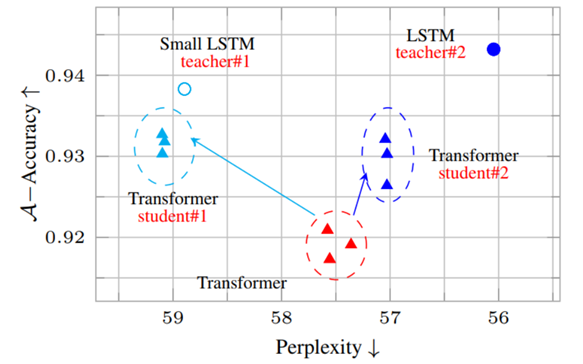
-
LSTM의 지식(Knowledge)를 Transformer에게 전달해줌으로써 기존의 Transformer(빨강)에 비하여 성능이 향상된 것을 확인할 수 있습니다.(하늘, 파랑)
-
또한, 기존의 Tranformer의 perplexity는 teacher model에 근사하게 된 것을 알 수 있습니다.
Language Modelling(LM) Setup
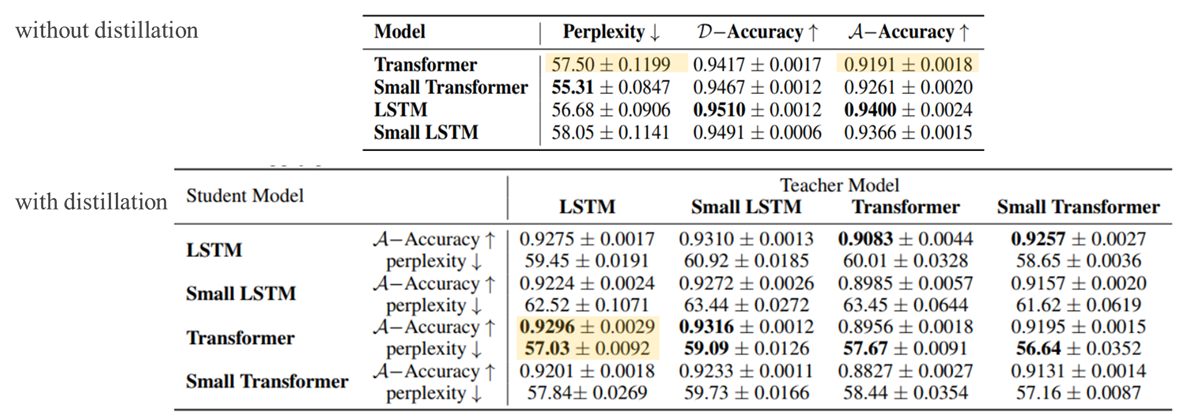
Classification Setup
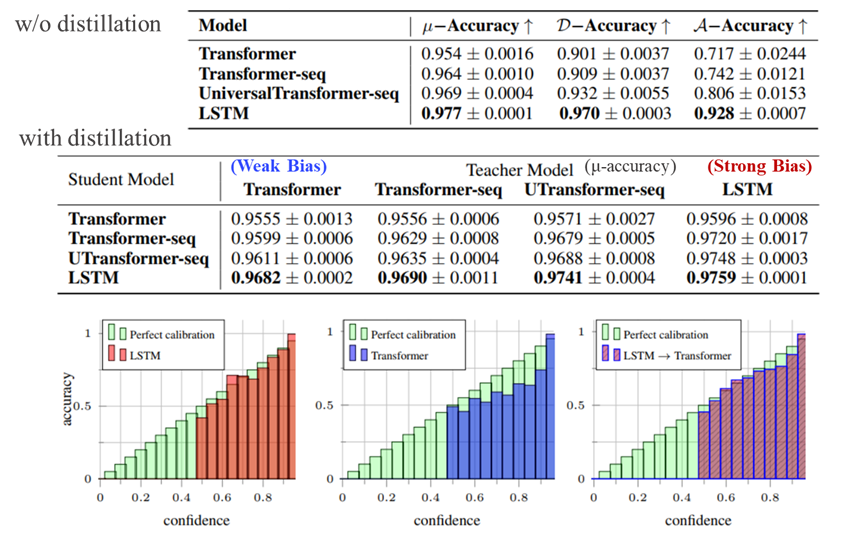
- 좀 더 강한 inductive bias를 가지고 있는 모델을 Teacher 모델로 한 Student Model은 Distillation을 수행하지 않은 모델에 비해 성능이 향상(Acc ↑, ECE ↓)된 것을 확인할 수 있습니다.
마지막으로 Multidimensional Scaling(MDS) 통해 모델 penultimate layer에서의 representation을 시각화 해본 결과는 아래와 같습니다.

기존 Transformer 모델은 Variance가 넓은 반면 Inductive Bias가 높은 순으로 모델은 Variance가 낮고, Distillation을 수행하면 기존 모델이 Teacher 모델과 유사해지며 Variance 또한 감소하는 것을 볼 수 있습니다.
오늘은 시나리오 1에 대하여 자세하게 다루어보았는데요. 빠른 시일 내에 시나리오 2까지 업로드하도록 하겠습니다 :D
긴 글 읽어주셔서 감사합니다 ㅎㅎㅎ
