[Paper Review] Transferring Inductive Bias Through Knowledge Distillation - (3/3)
Inductive-Bias-Series
안녕하세요 :) 오늘은 지난번 포스팅에 이어서 "Transferring Inductive Bias Through Knowledge Distillation" 논문에 대한 정리를 이어나가 보도록 하겠습니다. 이전 포스팅에서 본 논문에서 다루게 될 주요 개념들인 Knowledge Distillation과 Inductive Bias에 대한 설명과 RNNs vs Transformers에 대하 실험을 진행한 Scenario 1에 대해 이야기를 풀어봤는데요.
이전 포스트가 궁금하신 분은 아래 링크들을 통해 확인하실 수 있습니다.
1. 논문에 필요한 개념: Knowledge Distillation & Inductive Bias (링크)
2. 논문 시나리오 1 : RNNs vs Transformers (링크)
논문의 목적(복습)
본 논문은 "Knowledge Distillation에서 Teacher Model이 Student Model에 전하는 Dark Knowledge에 과연 Inductive Bias에 대한 정보가 존재할까?" 라는 질문에서 비롯된 의문점을 확인하기 위해 두가지 시나리오를 가지고 실험을 전개합니다. 첫 번째 시나리오는 RNNs(Teacher Model)과 Transformers(Student Model)를, 그리고 두 번째 시나리오는 CNNs(Teacher Model)과 MLPs(Student Model)를 비교합니다.
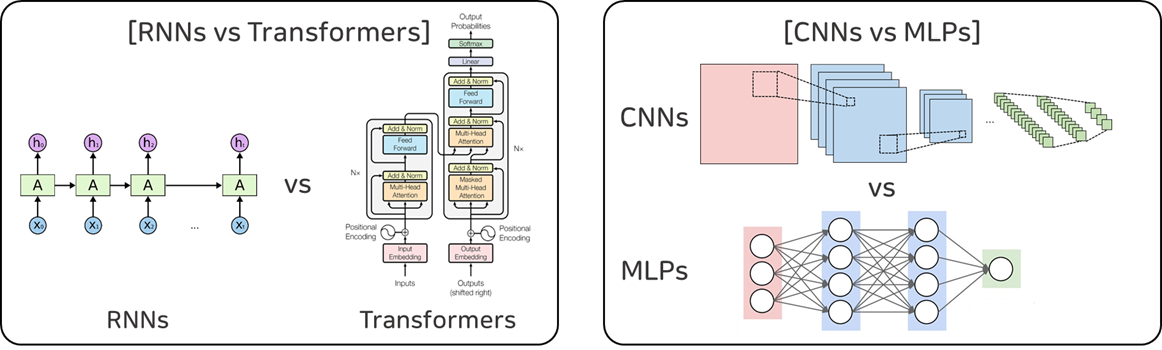
본 연구는 (1) 정말 선생 모델들이 가지고 있는 Inductive Bias가 얼마나 유의미한가를 보여주가, (2) 선생 모델에게 지식은 전수 받은 학생 모델이 정말 선생 모델과 유사한 학습의 결과물을 보여주는 가 를 보여주는 것을 목적으로 실험을 진행하였습니다.
이번 포스팅에서는 두번째 시나리오(CNNs vs MLPs)에 대해 다뤄보도록 하겠습니다.
Scenerio 2
Convolutional Neural Nets (CNNs)
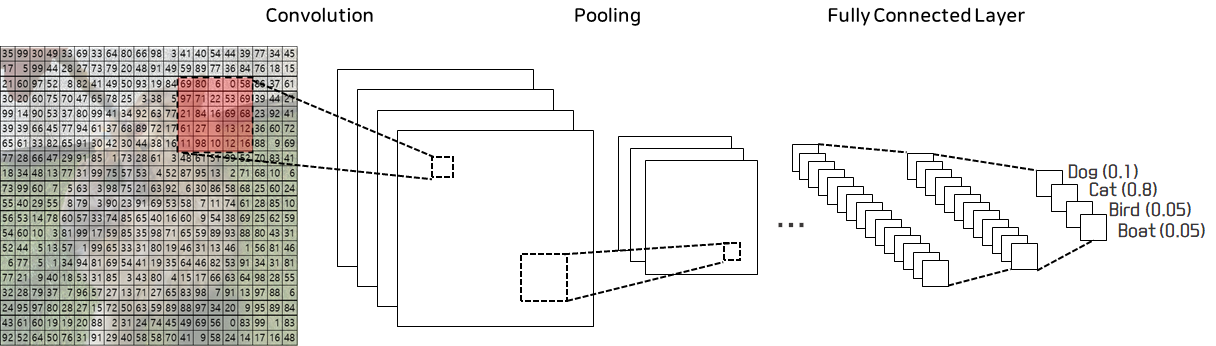
컴퓨터 비전에 대해 관심있는 분들은 왠만하면 들어봤을 용어가 바로 CNN일 텐데요. CNN은 Convolutional Neural Network의 줄임말로, 한글로는 합성곱신경망이라고도 합니다. 모델에 이미지가 들어오게 되면 Convolution Layer과 Pooling Layer를 통해 이미지의 특징들(Features)을 추출하고, 추출된 특징들을 Fully Connected Layer에 통과시켜 주어진 task를 수행하게 됩니다. 간단하게만 살펴볼까요?
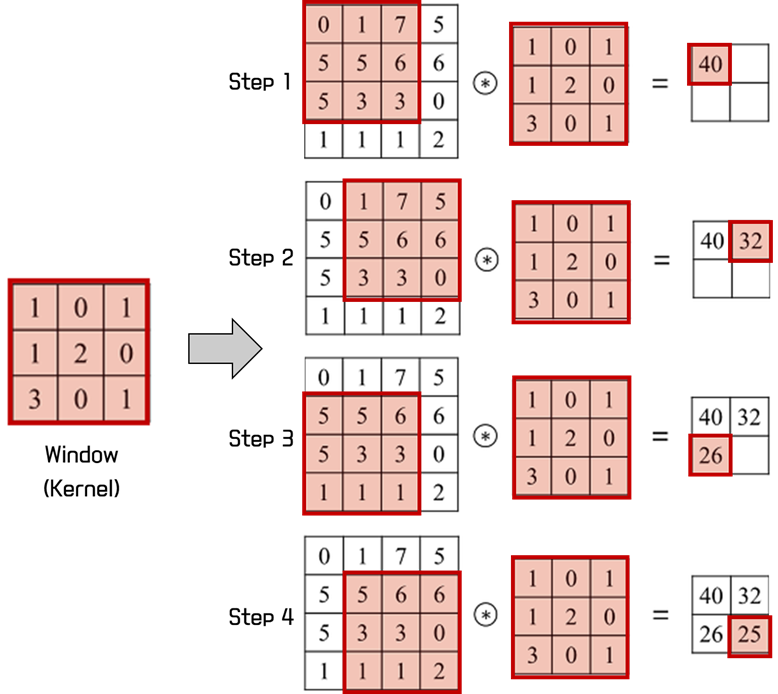
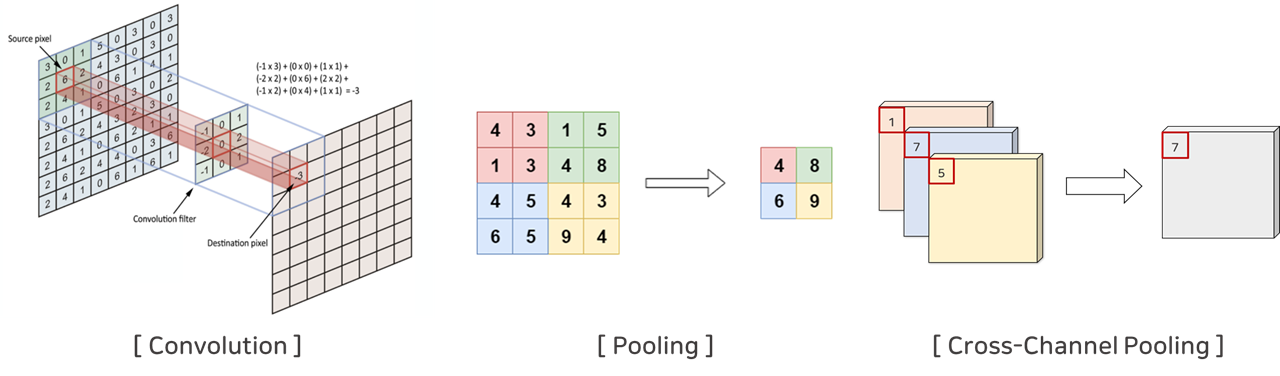
Convolution Layer은 아래 그림처럼 Window(Kernel)가 이미지를 이동하면서 각각의 겹쳐지는 픽셀과의 곱을 더한 더하는 연산(Convolution, 합성곱)을 수행하는 Layer입니다. 이때 Window의 값들은 모델이 학습하게 되며, Window의 역할은 데이터(이미지)의 특징을 맵 형태인 Feature Map(또는 Activation Map)으로 출력해주는 역할입니다.
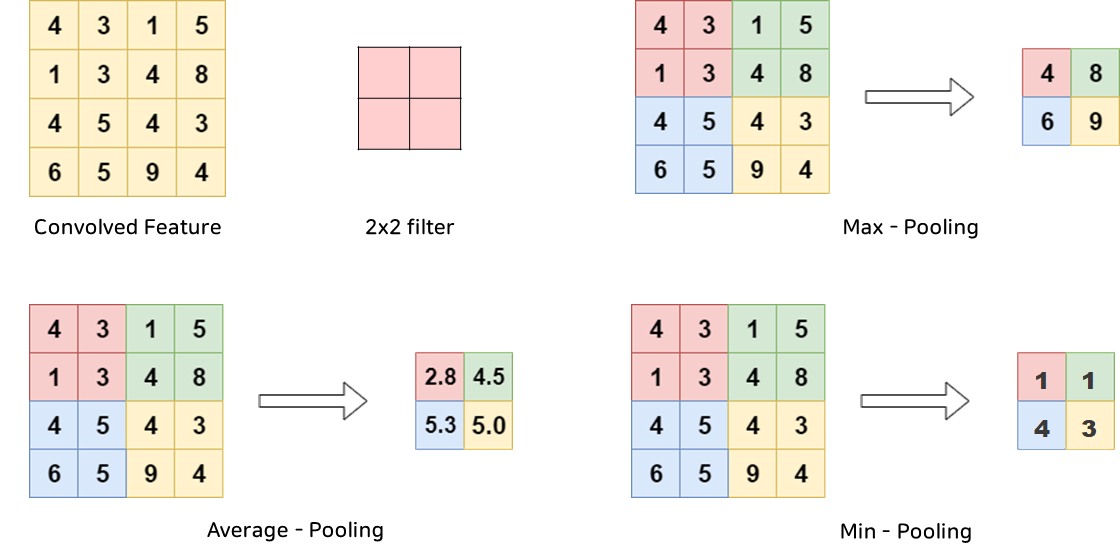
Pooling Layer는 앞의 Convolution Layer의 출력 값(Feature Map)를 입력으로 받아서 Feature Map의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용하게 됩니다. 이때 수행하게 되는 연산을 Pooling(풀링) 연산이라고 하는데, 이는 정사각 행렬(Filter)의 특정 영역 안에 값의 대푯값을 구하는 방식으로 동작합니다. Pooling에는 Max Pooling, Average Pooling, Min Pooling이 존재합니다. 이름에서 알 수 있다시피 Max Pooling은 가장 큰 값이, Average Pooling은 평균값이, Min Pooling은 가장 작은 값이 살아남도록 하는 것입니다.(사진참고)
Multi Layer Perceptrons (MLPs)
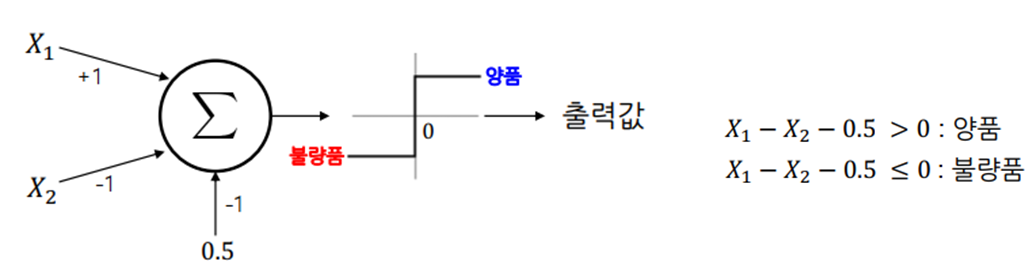
Multi Layer Perceptron에 대해 논하기 전에 먼저 Perceptron에 대해 다룰 수 밖에 없겠죠? 퍼셉트론(Perceptron)은 Frank Rosenblatt가 1957년에 제안한 초기 형태의 인공 신경망으로 다수의 입력으로부터 하나의 결과를 내보내는 알고리즘입니다. 이는 입력값의 선형결합 값을 구하고, 그 값이 0(threshold)보다 큰지를 여부로 분류하는 방법입니다.
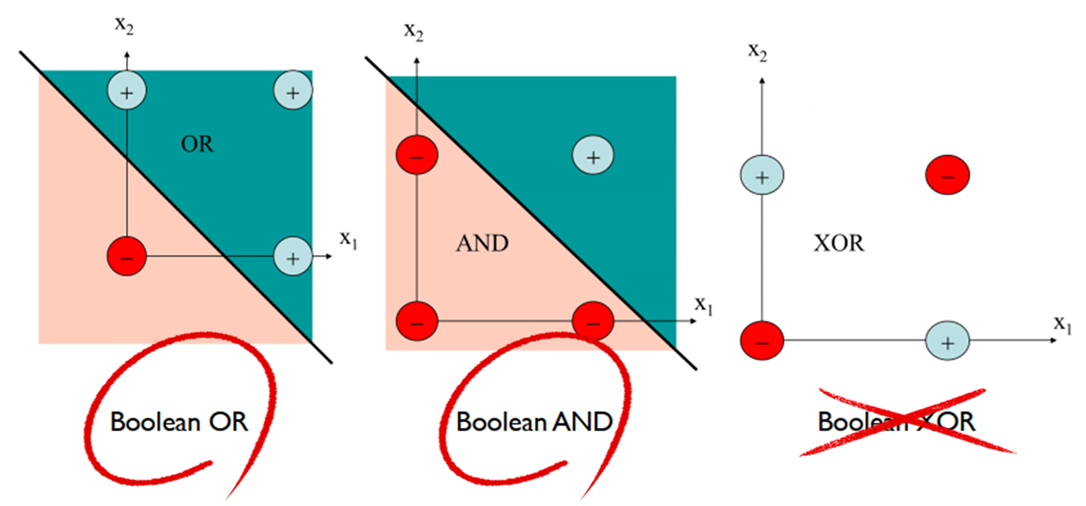
단층 퍼셉트론은 OR/AND/XOR 중 OR과 AND문제를 풀 수 있었지만 XOR문제는 풀 수가 없었습니다.
단층 퍼셉트론으로는 해결할 수 없자 이제 해결책으로 제시된 방법이 두개의 퍼셉트론을 결합한 중 퍼셉트론 (2-layer Perceptron)인데, 이렇게 층이 여러개인 퍼셉트론을 다층 퍼셉트론(Multilayer Perceptron)이라고 칭합니다. 이러한 다층 퍼셉트론이 우리가 알고 있는 인공신경망(ANN, Artificial Neural Network)가 되게됩니다.
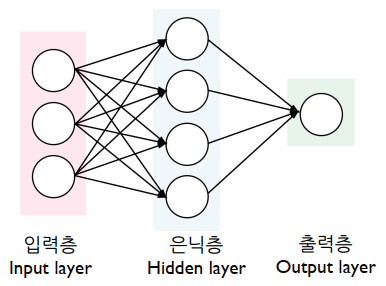
Source : https://blog.goodaudience.com/artificial-neural-networks-explained-436fcf36e75
인공 신경망(또는 다층 퍼샙트론)은 위 그림과 같이 입력층, 은닉층, 출력층으로 구성이 됩니다. 입력층은 입력변수의 값이 들어오는 층, 은닉층은 다수 노드 또는 층들이 포함될 수 있으며 데이터로부터 숨겨진 의미(특징)을 학습하는 층, 출력층은 결과를 출력하는 층입니다.
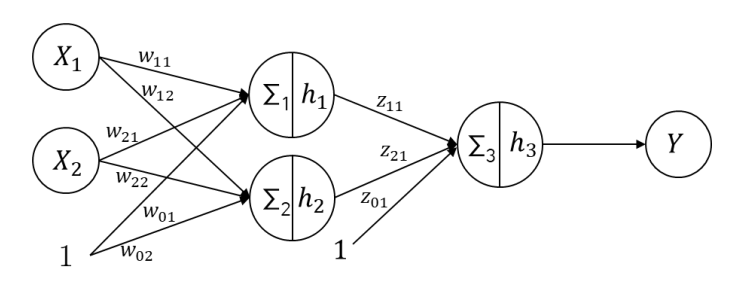
뉴럴네트워크에는 소개하지 않고 넘어갈 수 없는 중요한 용어들이 존재하는 데요. 이는 아래와 같습니다.
- 파라미터(Parameter) : 층 간 노드를 연결하는 가중치 (𝑤11, 𝑤11, ⋯ , 𝑧11)로, 알고리즘으로 학습되어지는 값입니다.
- 하이퍼파라미터(Hyper-Parameter) : 은닉층 개수, 은닉노드 개수, activation function로, 모델을 정의하는 사용자가 임의로 결정하는 값입니다.
- 활성화 함수(Activation Function) : 딥러닝 네트워크에서는 노드에 들어오는 값들에 대해 곧바로 다음 레이어로 전달하지 않고 주로 활성화 함수라고 불리우는 비선형 함수를 통과시킨 후 값을 전달합니다.
활성화 함수의 종류는 다양하지만 대표적이고, 고전적인 몇 가지만 소개하자면 아래와 같습니다.
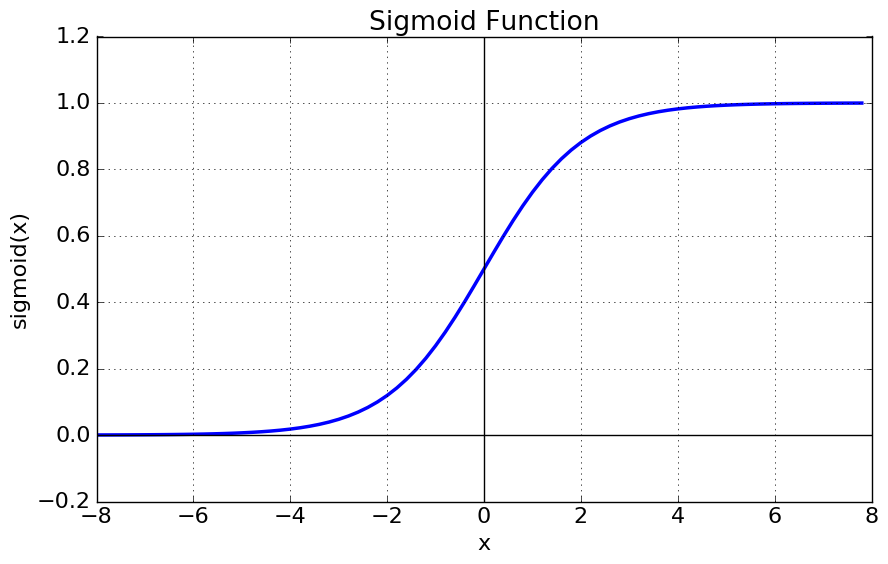
- 시그모이드 함수(Sigmoid Function) : 시그모이드(sigmoid)는 S자 형태라는 의미로, 식은 아래와 같습니다.
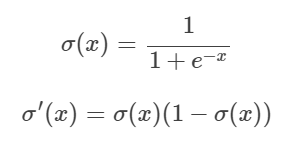
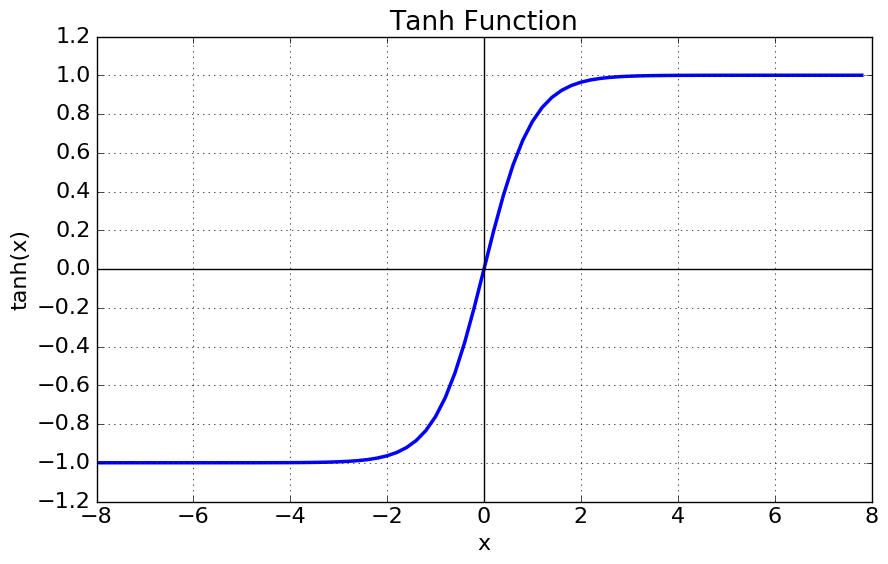
- tanh 함수(Hyperbolic tangent function) : tanh(Hyperbolic tangent)는 쌍곡선 함수의 일종으로, 식은 아래와 같습니다.
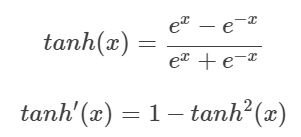
- Rectified Linear Unit(ReLU) : Gradient Vanishing 현상을 막기 위해 제안된 함수로, x 가 양수면 Gradient가 1로 일정하게 되므로 Gradient가 죽는 것을 방지할 수 있도록 설계하였습니다. 식은 아래와 같습니다.
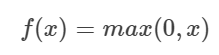
CNNs VS MLPs
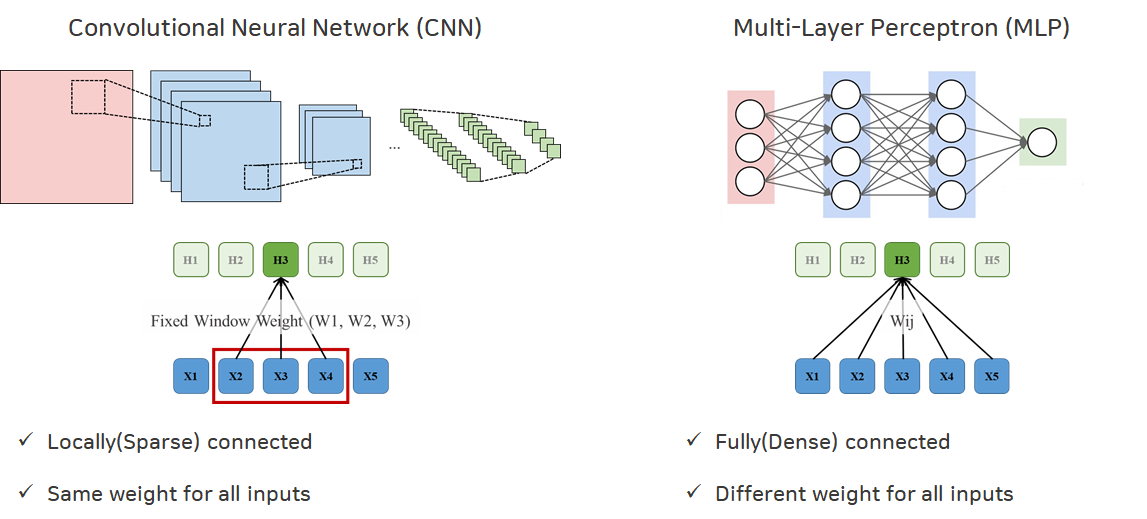
위에 개념들을 보면서 눈치채신 분들도 이미 계시겠지만, CNN은 MLP에 비해 구조적으로 제약(Inductive Bias)을 더 많이 두게 됩니다. 아래 그림을 보시면 CNN의 경우 Window가 지나다니면서 input에 Fixed된 Window Weight들을 동일하게 곱해주는 반면, MLP의 경우는 input에 다른 Weight들을 곱해주는 것을 확인할 수 있습니다.
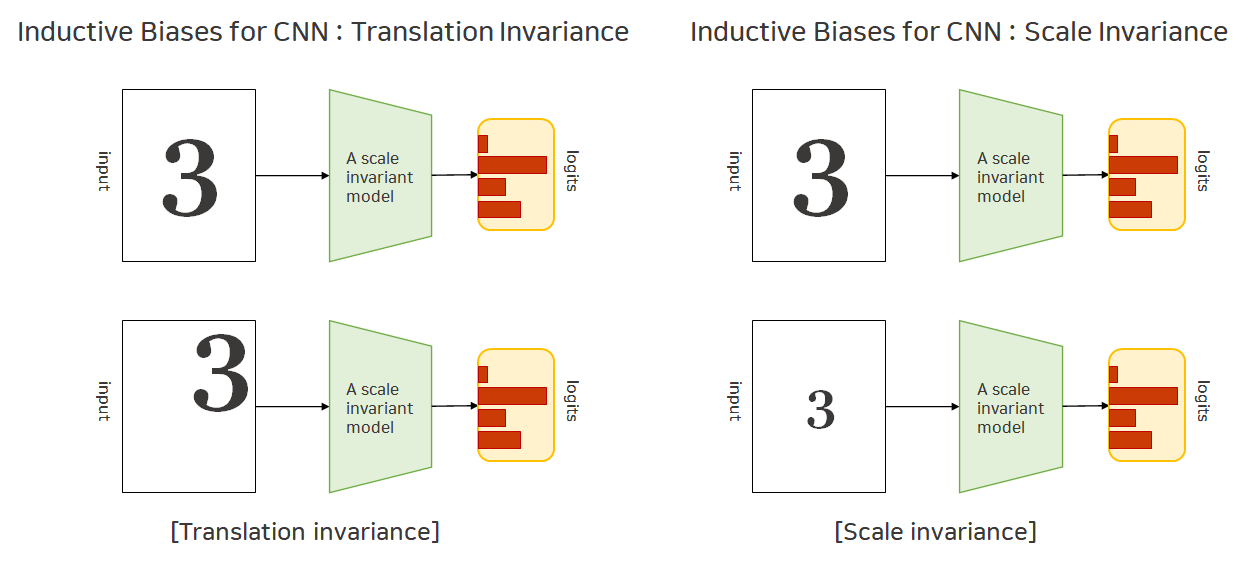
CNN의 Inductive Bias로는 크게 두가지를 들 수 있습니다. 이는 바로 Translation Invariance와
Scale Invariance입니다. Translation Invariance는 물체를 이동(translate) 시켜도 출력 값인 Logit 값은 변하지 않는다는 것이고, Scale Invariance는 물체의 스케일(scale)을 아무리 바꾸어도 출력 값인 Logit 값은 변하지 않는다는 것을 의미합니다.
이러한 Inductive Bias는 CNN의 아래의 특성들로 인해 Translation과 Scaling을 수행해도 값이 보존할 수 있게됩니다. 바로 Convolution 연산, Pooling 연산, 그리고 Cross-Channel Pooling 연산을 통해 이를 보존하게 됩니다. 앞에 두 연산은 앞에 Convolutional Neural Nets (CNNs) 파트에서 소개드렸으니, 간단하게 Cross-Channel Pooling 연산은, 한 채널 내에서 Pooling 연산을 수행하는 기본 Pooling과는 다르게, 여러 개의 채널 안에서 이루어지며 Channel간에 Pooling을 수행한 것으로 이해하시면 될 것 같습니다.(아래 그림 참고)
실험 설계 및 결과
본 시나리오 역시 마찬가지로 CNN모델이 MLP모델보다 Translation과 Scaling에 더 좋은 Inductive Bias를 가지고 있는가, 그리고 과연 CNN모델을 Teacher로, MLP모델을 Student로 Knowledge Distillation을 수행하였을 때 좋은 성능이 나오는가를 실험을 통해 보이고자 하였습니다.
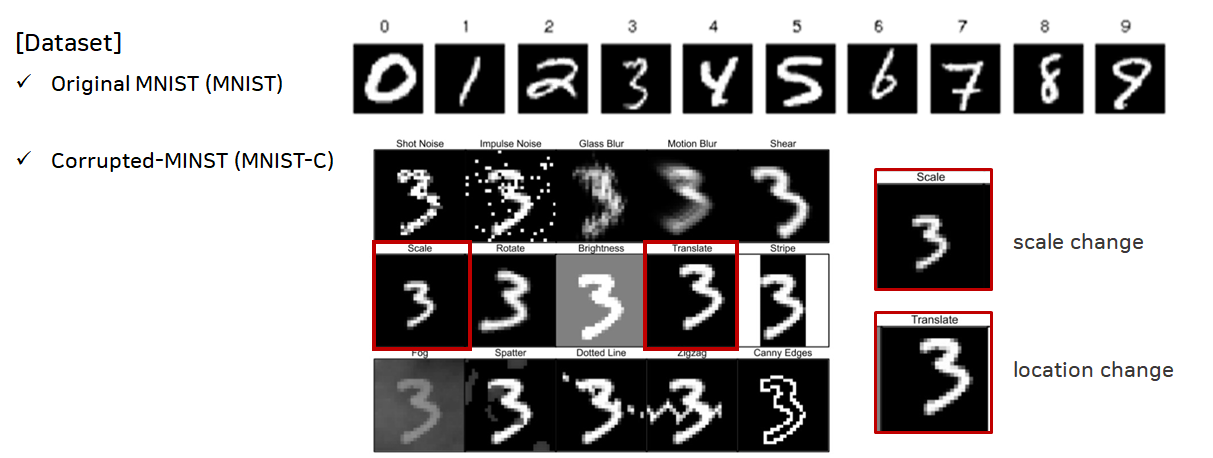
모델 Training을 위해 MNIST 데이터 셋을 사용하였고, Inference 성능 확인을 위해 기본 MNIST 데이터 뿐만 아니라 MNIST-C(Corrupted) 중 Traslated와 Scaled 데이터를 사용하였습니다.
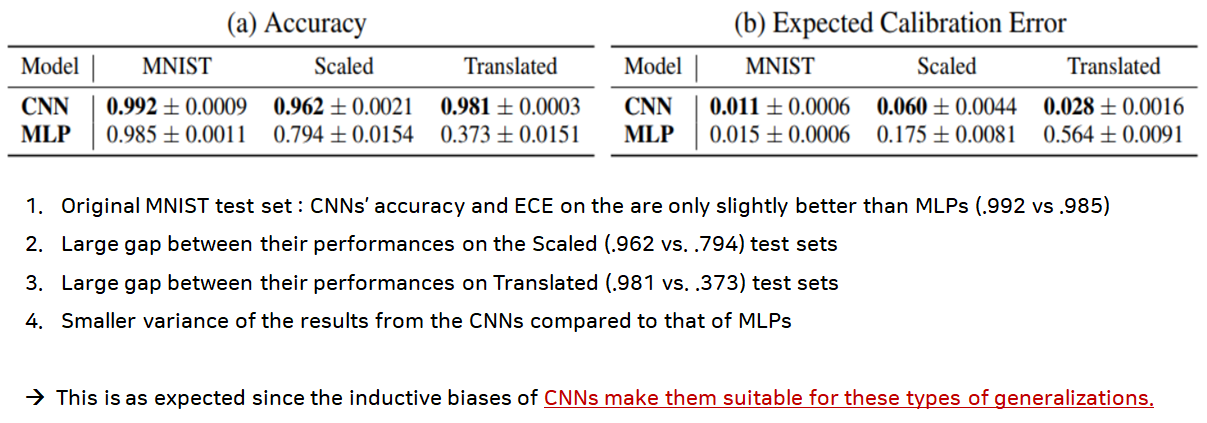
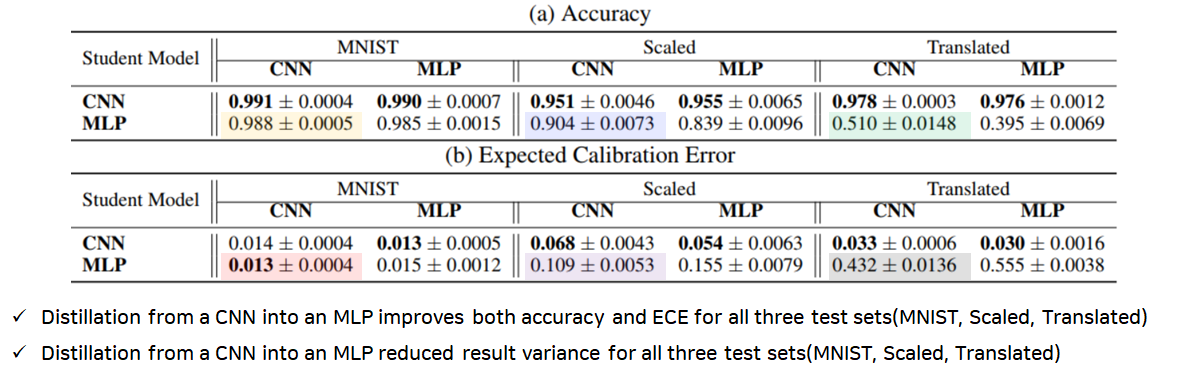
먼저, 각각 CNN모델과 MLP모델의 성능을 확인해보았는데요. Original MNIST 데이터에 대해서는 CNN과 MLP 둘 다 좋은 성능을 나타내는 것을 확인할 수 있습니다. 하지만, 그 외의 Translated와 Scaled MNIST-C 데이터에서는 성능(Accuracy, Expected Calibration Error) 차이가 크게 벌어질 뿐만 아니라, 값의 분산도가 큰 것을 확인할 수 있습니다. 이를 통해 CNN이 가진 구조적인 편향(Inductive Bias)를 통해 Translation과 Scaling에 MLP보다 강하다는 것을 확인할 수 있습니다.
이제 Inductive Bias가 더 큰 CNN모델을 Teacher모델로 하고, 작은 MLP모델을 Student모델로 Knowledge Distillation(KD)을 수행했을 때 아래와 같은 결과가 나왔는데요. 이를 보면 위의 성능표에 비해서 MLP모델들의 성능이 많이 상승한 것을 확인할 수 있고, 분산도 기존 MLP보다 CNN-MLP가 작은 것을 확인할 수 있습니다.
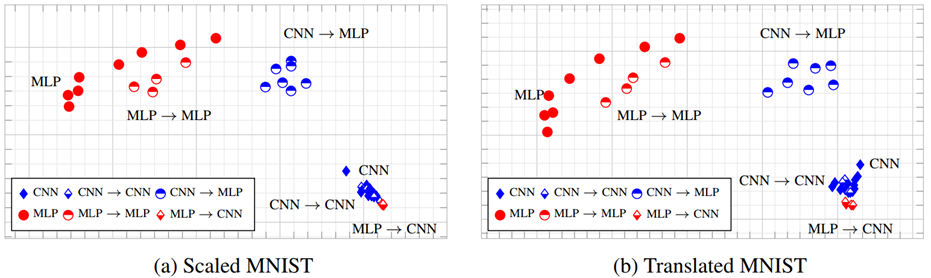
위에서 정량적으로 Inductive Bias가 정말 전달되어 모델 성능이 향상되었는가를 확인했다면, 이번에는 Multi-dimensional Scaling(MDS)를 이용하여 고차원의 Feature Map을 시각화해 보았습니다. 여기서도 마찬가지로 MLP의 분산이 CNN보다 크고, CNN을 Teacher로 학습을 수행하면 분산이 감소하며 시각화되는 위치가 점점 CNN에 가까워지는 것을 확인할 수 있습니다.
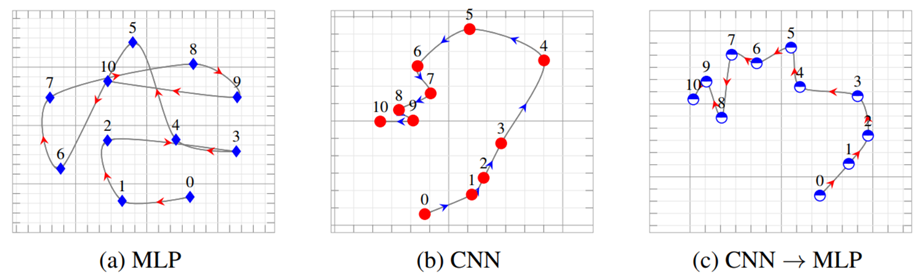
또 한가지 흥미로운 시각화를 수행하였는데요. 아래 그림을 보시면 각각 (a),(b),(c)는 MLP, CNN, CNN->MLP가 epoch별로 학습되어 가는 것을 MDS로 시각화 한 것입니다. (a)의 MLP를 보면 중구난방적으로 해가 수렴하는 것을 볼 수 있고, (b)의 CNN을 보면 뭔가 서서히 특정한 방향으로 수렴해가는 것을 볼 수 있습니다. (c)는 CNN(teacher)->MLP(student)인데 기존 MLP(a)의 학습 양상과는 다르게 규칙적으로 해가 수렴해가는 것을 확인할 수 있었습니다.
Conclusion
본 논문은 Knowledge Distillation(KD)의 경량화 효과 이외에 다른 모델들과 함께 쓰일 수 있다는 점을 착안하여 inductive bias를 과연 KD를 통해 전달할 수 있는 가를 실험을 통해 아래 순서대로 입증해보이고자 하였습니다.
첫째, 특정 task에 적당한 inductive bias를 갖는 것이 정말 중요한 가를 실험을 통해 입증하였습니다.
둘째, 해당 모델이 적당한 inductive bias를 갖고 있다면, inductive bias가 부족한 다른 모델들에게 학습에 가이드라인을 제공해줄 수 있음을 실험을 통해 정량적, 그리고 정성적으로 입증하였습니다.
- 정량적으로 증명 : Accuracy, Expected Calibration Error
- 정성적으로 증명 : 시각화 (Multi-Dimensional Scaling 2D projection)
흥미롭게 읽었던 논문을 무려 3차례에 걸쳐서 자세하게 한번 다루어보았는데요. 이렇게 자세하게 논문을 리뷰하는 방식은 어땠는지 구독자들의 의견 또한 궁금하네요 🙂
긴 글 읽어주셔서 감사합니다 ^~^
