
✍️ 자연어 처리(NLP)는 빠르게 발전하고 있는 분야로, 수많은 획기적인 연구 논문들이 매년 발표되고 있습니다. 만약 여러분이 NLP에 처음 발을 들이거나, 연구를 더 깊이 이해하고자 한다면, 다음에 소개할 논문들이 핵심 개념과 최근 발전 동향을 파악하는 데 큰 도움이 될 것입니다.
다음은 해당 블로그에서 소개하는 "Must-Read Research Papers for NLP" Paper List를 읽고 추가적으로 설명 및 정리해놓은 내용입니다.
-
Paper List 출처: https://datajourney24.substack.com/p/must-read-research-papers-for-nlp?r=25b2f4&utm_campaign=post&utm_medium=web&triedRedirect=true -
자료/이미지 출처:- 딥 러닝을 이용한 자연어 처리 입문
(https://wikidocs.net/book/2155) - 고려대학교 DSBA 연구실 자료
- 각 논문 원문 Figures 발췌
- 딥 러닝을 이용한 자연어 처리 입문
-
LLaMa2, LLaMa3은 개인적으로 궁금해서 추가했습니다.
1. Word2Vec: Efficient Estimation of Word Representations in Vector Space (Mikolov et al., 2013)
💡 Word2Vec은 단어를 벡터로 표현하는 혁신적인 방법을 제안하며, 단어들 간의 의미와 관계를 벡터 공간에서 포착할 수 있게 해주었습니다. 이 기법은 유사한 단어를 찾거나, 문맥 속에서 단어의 의미를 이해하는 과제에서 큰 발전을 이루었으며, 여전히 NLP의 기초적인 개념으로 자리 잡고 있습니다. 비록 이후에 더욱 발전된 방법들이 등장했지만, Word2Vec는 단어 임베딩(word embedding) 연구의 출발점으로서 큰 의의를 지닙니다.

- 이 논문은 단어를 벡터 공간에서 표현하는 새로운 두 가지 모델 아키텍처를 제안하고 있습니다. 이 모델들은 대규모 데이터셋으로부터 연속적인 단어 벡터 표현을 계산하는 방식입니다.
- 논문에서는 이 벡터의 품질을 단어 유사성 과제에서 측정하였고, 기존의 신경망 기반 기술들과 비교해 월등히 높은 정확도와 효율성을 보여주었습니다.
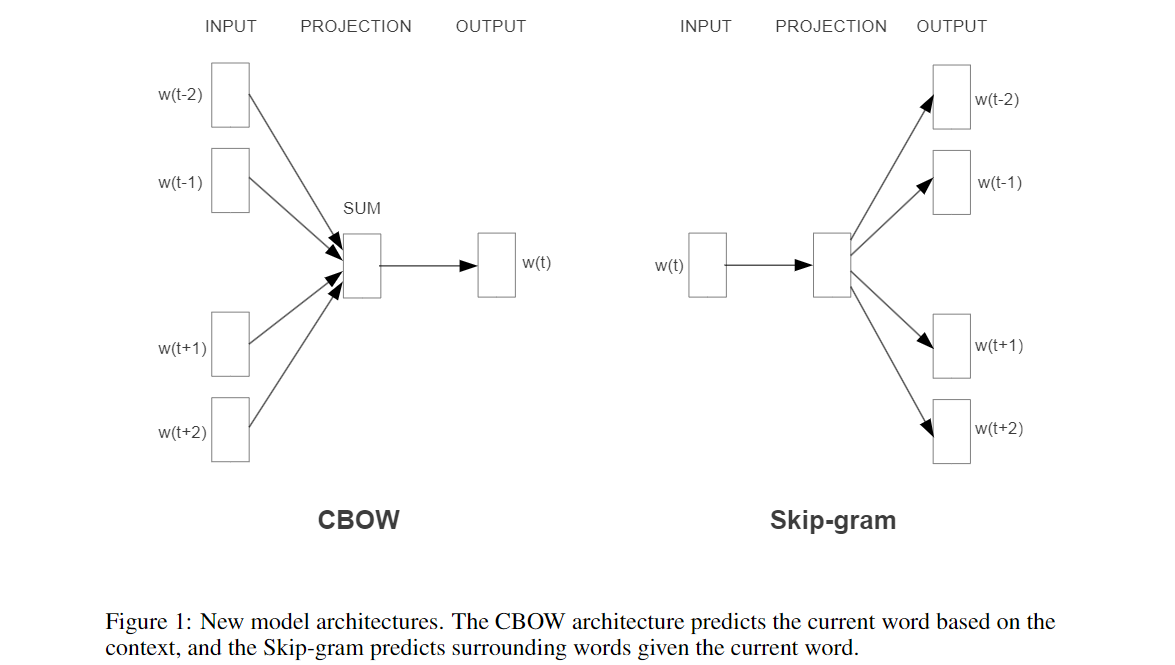
주요 내용
-
혁신적인 모델 아키텍처: Word2Vec는 대규모 데이터셋에서 연속적인 벡터 표현을 계산하는 두 가지 모델 아키텍처(CBOW, Skip-gram)를 제안합니다.
-
효율성: 1.6억 단어로 이루어진 데이터셋에서 하루 이내에 고품질의 단어 벡터를 학습할 수 있음을 실험적으로 증명했습니다.
-
정확성: 이 벡터들은 구문적(syntactic) 및 의미적(semantic) 유사성을 측정하는 테스트 세트에서 최첨단 성능을 보여주었습니다.
-
비교 평가: 기존의 신경망 기반 단어 임베딩 기법보다 훨씬 더 적은 계산 비용으로도 더 높은 성능을 제공하는 것이 특징입니다.
기여 및 의의
-
단어 간 의미 관계 포착: Word2Vec는 단어들이 벡터 공간에서 위치함으로써, 단어 간 의미적 관계를 벡터 연산으로 포착할 수 있습니다.
- 예를 들어, 'king - man + woman' 연산은 'queen'에 가까운 벡터를 산출할 수 있게 됩니다.
-
자연어 처리 분야에서의 영향: 이 기법은 유사한 단어를 찾거나 문맥 속에서 단어의 의미를 이해하는 다양한 자연어 처리 과제에서 큰 발전을 이루었습니다.
- 이후 등장한 다양한 발전된 모델의 출발점이 되는 기초적인 연구로서, Word2Vec는 여전히 중요한 의의를 지닙니다.
2. GloVe: Global Vectors for Word Representation (Pennington et al., 2014)
💡 GloVe는 단어 벡터를 생성하는 또 다른 방식으로, 텍스트 내에서 단어가 얼마나 자주 같이 등장하는지에 대한 전반적인 통계를 기반으로 단어들 간의 관계를 포착합니다. 이를 통해 각 단어의 의미를 보다 풍부하게 표현할 수 있으며, NLP 모델이 언어를 더 잘 이해할 수 있도록 돕습니다. 특히 GloVe는 전역적인(word-word co-occurrence) 정보에 기반해 단어의 의미를 학습하는 방법을 제시했습니다.

이 논문은 단어 벡터를 생성하는 새로운 방법인 GloVe를 제안합니다. GloVe는 단어들이 텍스트 내에서 얼마나 자주 함께 등장하는지에 대한 전반적인 통계를 기반으로 단어들 간의 관계를 포착합니다. 이러한 접근 방식을 통해 각 단어의 의미를 더욱 풍부하고 정확하게 표현할 수 있습니다.

주요 내용
-
전역 통계 기반 학습: GloVe는 말뭉치 전체의 단어-단어 동시 발생(co-occurrence) 정보를 활용하여 단어 벡터를 학습합니다.
- 이는 단어 간의 관계를 벡터 공간에서 더 잘 표현할 수 있게 해줍니다.
-
비교 평가: GloVe 모델은 기존의 다른 단어 임베딩 방법들과 비교하여 단어 유사도 및 단어 유추(word analogy) 작업에서 우수한 성능을 보였습니다.
-
모델 아키텍처: GloVe는 로그-이차 손실 함수를 사용하여 단어 벡터 간의 유사도를 최적화합니다.
- 이 방법은 특히 큰 데이터셋에서 효과적이며, 단어 벡터의 의미적 속성을 잘 반영할 수 있습니다.
-
효율성과 확장성: GloVe는 대규모 데이터셋에서도 효율적으로 학습할 수 있으며, 벡터 공간에서 단어들 간의 복잡한 관계를 잘 표현합니다.
기여 및 의의
-
단어 의미의 풍부한 표현: GloVe는 단어의 국지적인(contextual) 사용뿐만 아니라 전역적인 사용 패턴을 모두 고려하여, 더 풍부한 의미 표현을 제공합니다.
- 이는 자연어 처리 모델이 언어를 더 잘 이해할 수 있도록 돕습니다.
-
다양한 NLP 과제에 적용: GloVe는 기계 번역, 텍스트 분류, 정보 검색 등 다양한 자연어 처리 과제에서 기본적인 단어 표현 기법으로 널리 사용되고 있습니다.
-
연구 및 응용의 기반: 이 연구는 단어 임베딩 기법의 중요한 발전을 이루었으며, 이후의 많은 연구와 응용에서 단어 표현의 기초로서 활용되고 있습니다.
3. Sequence to Sequence Learning with Neural Networks (Sutskever et al., 2014)
💡 이 논문에서는 시퀀스-투-시퀀스(Seq2Seq) 모델을 소개하며, 데이터의 시퀀스(예: 문장)를 다른 시퀀스로 변환하는 방법을 제안했습니다. 인코더-디코더 구조를 활용하여 입력 시퀀스를 출력 시퀀스로 변환할 수 있게 되었으며, 이 모델은 기계 번역(machine translation)이나 텍스트 요약(text summarization)과 같은 다양한 작업에서 중요한 기술로 자리 잡았습니다.

이 논문은 시퀀스-투-시퀀스(Seq2Seq) 학습 모델을 소개하며, 입력 시퀀스를 다른 출력 시퀀스로 변환하는 방법을 제안합니다. 이 모델은 인코더-디코더 구조를 사용하여, 다양한 자연어 처리 과제에서 큰 성과를 거두었습니다. 특히 기계 번역과 같은 문제에서 뛰어난 성능을 발휘하며, 이후 많은 모델의 기초가 되었습니다.
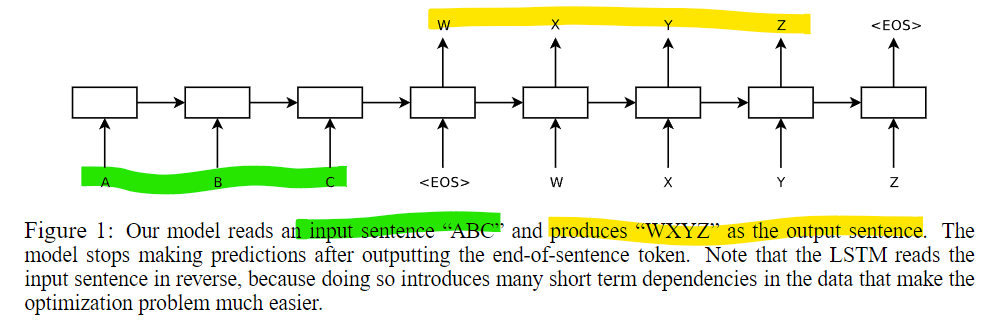
주요 내용
-
인코더-디코더 구조: 입력 시퀀스를 처리하는 인코더와, 이를 바탕으로 출력 시퀀스를 생성하는 디코더로 구성된 구조입니다.
- 이때 Long Short-Term Memory (LSTM) 네트워크가 사용되었습니다.
-
BLEU 점수: WMT-14 영어-프랑스어 번역 과제에서 BLEU 점수 34.8을 달성했으며, 이는 기존 통계적 기계 번역(SMT) 시스템의 33.3 점수보다 우수한 결과입니다.
- 또한, LSTM을 사용하여 1000개의 가설을 다시 평가했을 때 BLEU 점수가 36.5로 증가했습니다.
-
순서 반전 전략: 입력 문장의 단어 순서를 뒤집는 간단한 기술을 사용해 성능을 크게 향상시켰습니다.
- 이는 짧은 시간 의존성을 증가시켜 최적화 문제를 더 쉽게 해결하게 합니다.
기여 및 의의
-
시퀀스 학습의 혁신: Seq2Seq 모델은 입력과 출력 시퀀스의 길이가 다를 때도 성공적으로 학습할 수 있는 방법을 제시하여, 기존 DNN이 해결할 수 없었던 문제를 해결했습니다.
-
기계 번역에서의 성과: 이 모델은 특히 기계 번역 작업에서 탁월한 성능을 보였으며, 이후 텍스트 요약, 질의응답 시스템 등 다양한 자연어 처리 작업에 응용되었습니다.
-
장문 처리 능력: Seq2Seq 모델은 긴 문장에서도 우수한 성능을 유지하며, 기존의 LSTM 모델이 가졌던 문제를 해결하는 데 기여했습니다.
4. Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau et al., 2015)
💡 이 논문은 문장을 번역하는 과정에서 단어 간의 정렬과 번역을 동시에 학습하는 새로운 접근 방식을 제안했습니다. 특히 주목할 부분은 어텐션 메커니즘(attention mechanism)의 도입으로, 모델이 번역할 때 입력 문장의 중요한 부분에 집중할 수 있게 함으로써 번역의 품질을 향상시켰습니다. 이후 많은 번역 모델의 발전에 기초가 된 논문입니다.

본 논문에서 제안하는 아키텍쳐는 인코더와 디코더로 구성되어 있습니다. 인코더 부분은 Bidirectional RNN을 사용하여 입력 문장을 인코딩하며, 각 입력 단어에 대한 Attention 정보를 포함한 여러 개의 어노테이션(annotation)을 생성합니다. 디코더는 LSTM 네트워크를 사용하고, 각 타겟 단어를 생성할 때마다 입력 문장에서 중요한 부분을 찾아내는 방식으로 작동합니다.
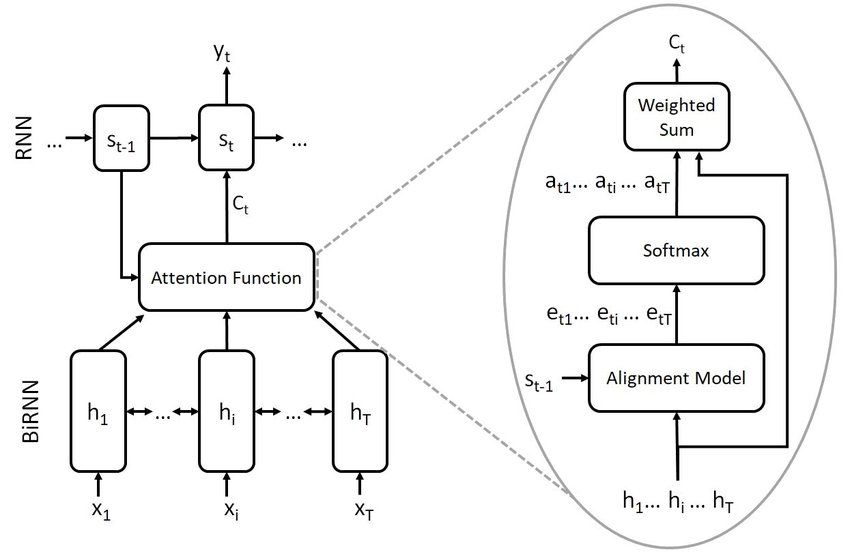
주요 내용
- 인코더-디코더 구조의 한계: 기존의 인코더-디코더 모델은 입력 문장을 고정된 길이의 벡터로 압축하고, 그 벡터를 기반으로 번역을 생성합니다.
- 하지만 이러한 방식은 긴 문장이나 복잡한 문장의 정보를 충분히 담아내지 못한다는 한계가 있습니다.
- 어텐션 메커니즘 도입: 논문에서 제안된 RNNSearch 모델은 번역할 때 입력 문장 내 특정 부분에 집중할 수 있도록
어텐션 메커니즘을 도입했습니다.- 이 메커니즘은 디코더가 매번 단어를 생성할 때 입력 문장의 중요한 부분에 가중치를 부여해 참조할 수 있게 해줍니다.
- 즉, 모든 입력 정보를 고정된 벡터에 압축하는 대신, 문장의 관련된 부분에 집중하여 더 나은 번역 결과를 제공합니다.
- 정렬 학습: RNNSearch 모델은 정렬(alignment) 과정을 명시적으로 학습합니다.
- 번역을 생성할 때, 각 타겟 단어를 예측하는 과정에서 입력 문장의 어떤 부분이 중요한지 결정하고, 이 부분에 더 높은 가중치를 부여합니다.
- 이를 통해 자동으로 소프트 정렬을 수행하며, 번역의 정확성을 높입니다.
- 성능 개선: 영어에서 프랑스어로 번역하는 작업에서, 이 새로운 모델은 기존의 구문 기반 통계적 기계 번역 시스템과 유사한 성능을 보였습니다. 특히, 긴 문장이나 복잡한 문장 구조를 처리할 때 더 뛰어난 성능을 보여주었습니다.

(참고) 기존RNN vs RNNsearch
- RNNsearch는 기존의 RNN 기반 기계 번역 모델의
고정된 문맥 벡터에 의존하는 방식(기존)에서 벗어나, 어텐션 메커니즘을 도입해 입력 문장의중요한 부분에 동적으로 집중할 수 있도록 설계(RNNsearch)되었습니다.- 기존 RNN 모델과의 가장 큰 차이점은 어텐션 메커니즘을 통한 동적 참조와 정렬 학습에 있습니다.
| 구분 | 기존 RNN 계열 언어 모델 | RNNsearch (Bahdanau et al.) |
|---|---|---|
| 인코더 출력 | 고정된 길이의 벡터로 소스 문장 압축 | 가변 길이의 주석 벡터 사용 |
| 번역 생성 방식 | 고정된 문맥 벡터에 의존 | 어텐션 메커니즘을 통해 동적으로 입력 문장을 참조 |
| 정렬 학습 | 명시적 정렬 없이 전체 문맥에 의존 | 어텐션 메커니즘을 통해 자동으로 소스-타겟 정렬 학습 |
| 긴 문장 처리 | 성능 저하가 발생할 수 있음 | 긴 문장에서도 성능 유지, 더 나은 정보 유지 |
| 세부 정보 처리 | 전역 정보에 의존 | 입력 문장의 특정 부분에 집중하여 세부 정보 반영 |
(참고) Bahdanau 어텐션과 Transformer 어텐션의 차이점
| 구분 | Bahdanau 어텐션 (RNNsearch) | Transformer 어텐션 (Self-Attention) |
|---|---|---|
| 구조 | RNN 기반 인코더-디코더 구조 | 순수 어텐션 기반, Recurrent 구조 없음 |
| 어텐션 방식 | 디코더에서 입력 문장에 대한 소프트 어텐션 | 입력 문장 내에서 Self-Attention 사용 |
| 정렬 학습 | 타겟 단어와 입력 단어 간 정렬을 학습 | 입력 문장의 모든 단어 간 관계를 학습 |
| Key-Value Query 구조 | 없음 | Key, Query, Value 구조를 사용 |
| 병렬 처리 | 불가능 (Recurrent 구조로 순차 처리) | 병렬 처리 가능 (빠른 학습 속도) |
| Multi-Head Attention | 단일 어텐션만 사용 | Multi-Head Attention으로 다양한 관계 학습 |
기여 및 의의
-
정렬과 번역의 통합 학습: 이 논문은 기계 번역에서 정렬과 번역을 동시에 학습하는 방식을 제안했습니다.
- 이를 통해 기존의 고정 벡터 방식의 한계를 극복하고, 더 유연하고 정확한 번역이 가능해졌습니다.
-
어텐션 메커니즘의 도입: 이 논문에서 처음 제안된 어텐션 메커니즘은 이후 자연어 처리 분야에서 Transformer와 같은 모델로 발전되며, 많은 언어 모델 및 기계 번역 시스템에서 핵심적인 기술로 자리 잡았습니다.
-
기계 번역의 발전: 신경망 기반 기계 번역(NMT)의 발전을 촉진했으며, 이후 많은 연구자들이 이 구조를 기반으로 성능을 더욱 개선한 모델들을 개발하게 되었습니다.
- 특히, 기계 번역뿐 아니라 다양한 자연어 처리 문제에 응용되어 큰 영향을 미쳤습니다.
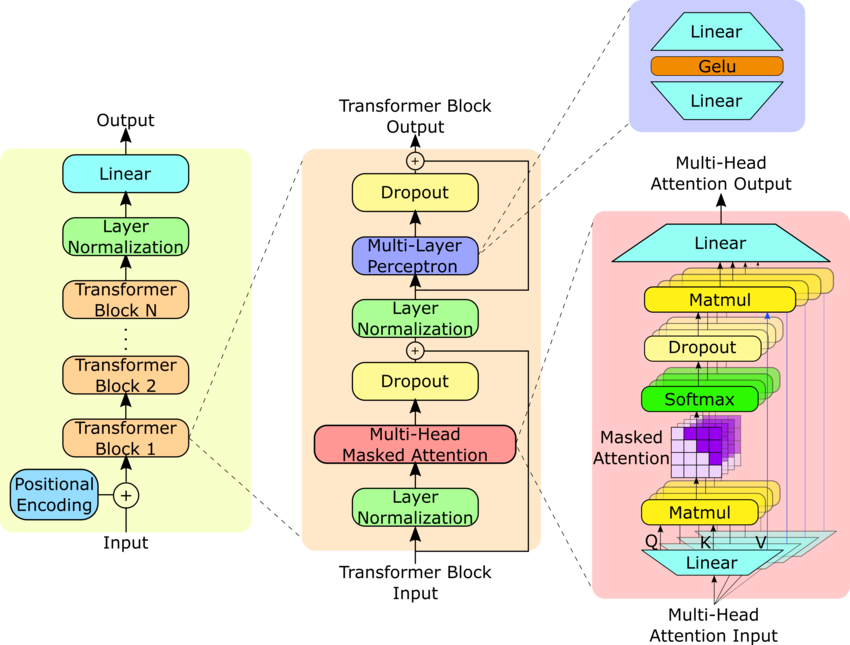
5. Attention is All You Need (Vaswani et al., 2017)
💡 이 논문에서는 트랜스포머(Transformer) 모델을 소개하며, NLP 모델의 작동 방식을 크게 변화시켰습니다. 이전에는 RNN과 같은 방식이 사용되었으나, 트랜스포머는 어텐션 메커니즘을 활용하여 입력 문장의 여러 부분에 동시에 집중할 수 있었습니다. 이를 통해 모델의 속도와 성능이 크게 향상되었고, 이후 BERT나 GPT 같은 강력한 모델의 기초가 되었습니다.
해당 논문은 트랜스포머(Transformer) 모델을 제안하여, NLP 모델의 작동 방식에 큰 변화를 가져왔습니다. 기존에는 RNN이나 CNN을 기반으로 한 인코더-디코더 구조가 널리 사용되었으나, 트랜스포머는 이러한 순환(recurrence)과 합성곱(convolution)을 완전히 배제하고 오로지 어텐션(attention) 메커니즘에만 의존하는 새로운 네트워크 아키텍처를 제시했습니다. 이를 통해 성능뿐만 아니라 병렬화 처리 속도에서도 큰 개선을 이루었습니다.
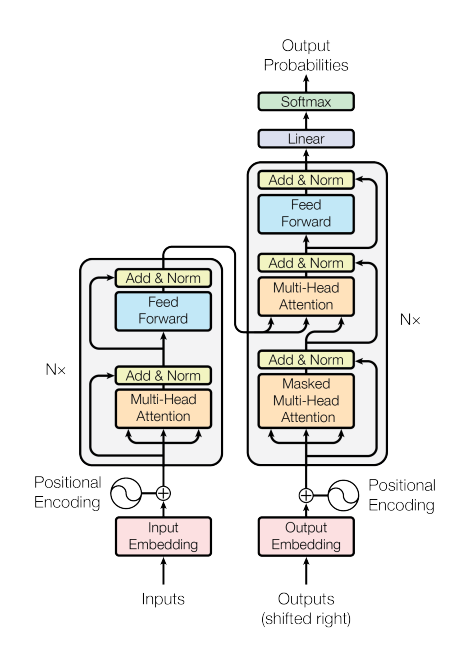
주요 내용
- 트랜스포머 모델: 트랜스포머는 RNN이나 CNN 없이 오로지 어텐션 메커니즘만을 사용하여 시퀀스를 변환하는 모델입니다.
- 이 모델은 특히 병렬화가 가능하여 훈련 시간을 크게 단축시킬 수 있습니다.
- Transformer는 이러한 Encoder-Decoder 구조와 Attention 메커니즘의 결합을 통해 기존의 순환 신경망(RNN)이나 합성곱 신경망(CNN) 없이도 입력과 출력 간의 복잡한 관계를 효과적으로 학습할 수 있습니다.
1. Encoder 구조
-
Transformer의 Encoder는 동일한 레이어를 N=6개 쌓은 구조로 되어 있습니다.
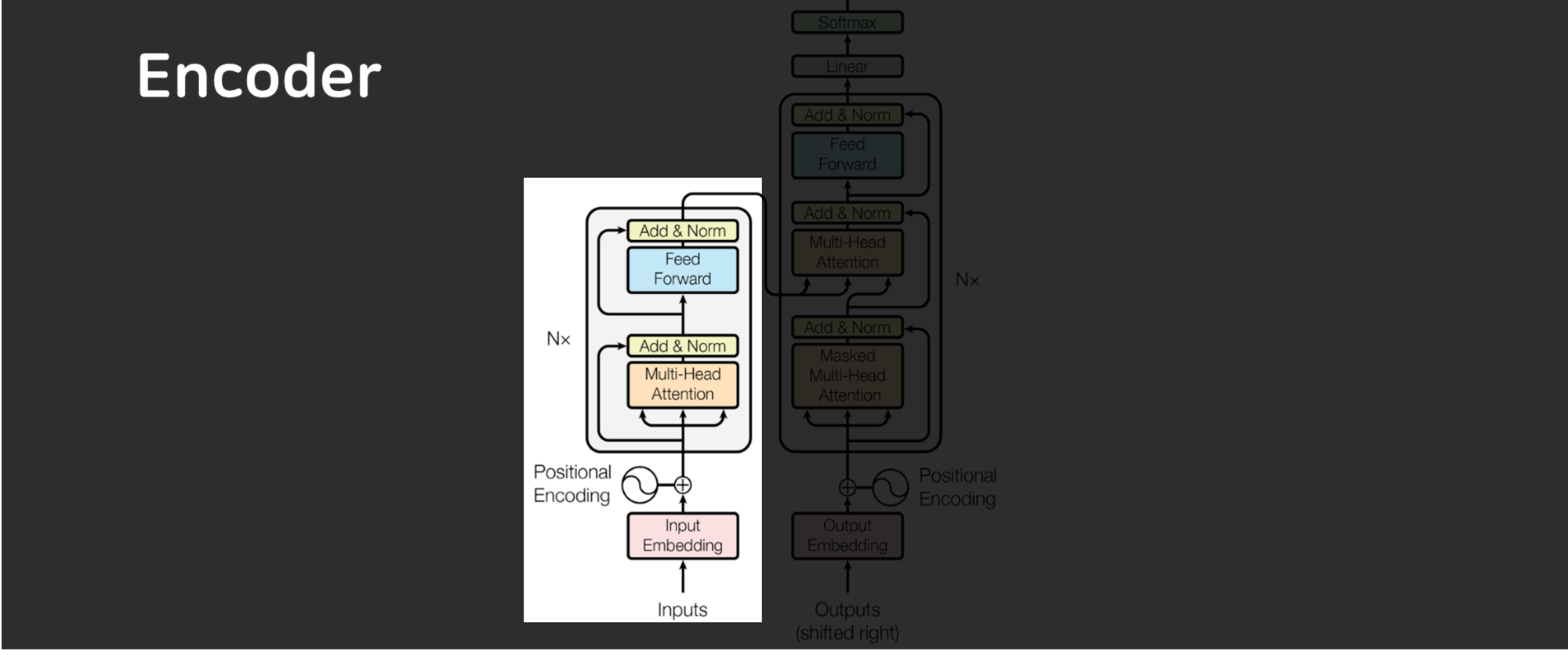
-
각 레이어는 두 개의 주요 서브 레이어로 구성됩니다:
- Multi-Head Self-Attention: 입력 시퀀스의 각 위치가 다른 위치와의 관계를 고려하여 정보를 처리하는 메커니즘입니다.
- Feed-Forward Network: 각 위치에서 독립적으로 작동하는 간단한 완전 연결 네트워크입니다.
-
각 서브 레이어는 잔차 연결(residual connection)을 사용하여 입력을 다음 레이어의 출력에 추가하고, 그 다음 레이어 정규화(layer normalization)가 적용됩니다.
-
모든 서브 레이어는 512차원(d_model = 512)의 출력을 생성합니다.
2. Decoder 구조
-
Transformer의 Decoder또한 N=6개의 동일한 레이어로 구성되지만, Encoder와는 약간의 차이가 있습니다.
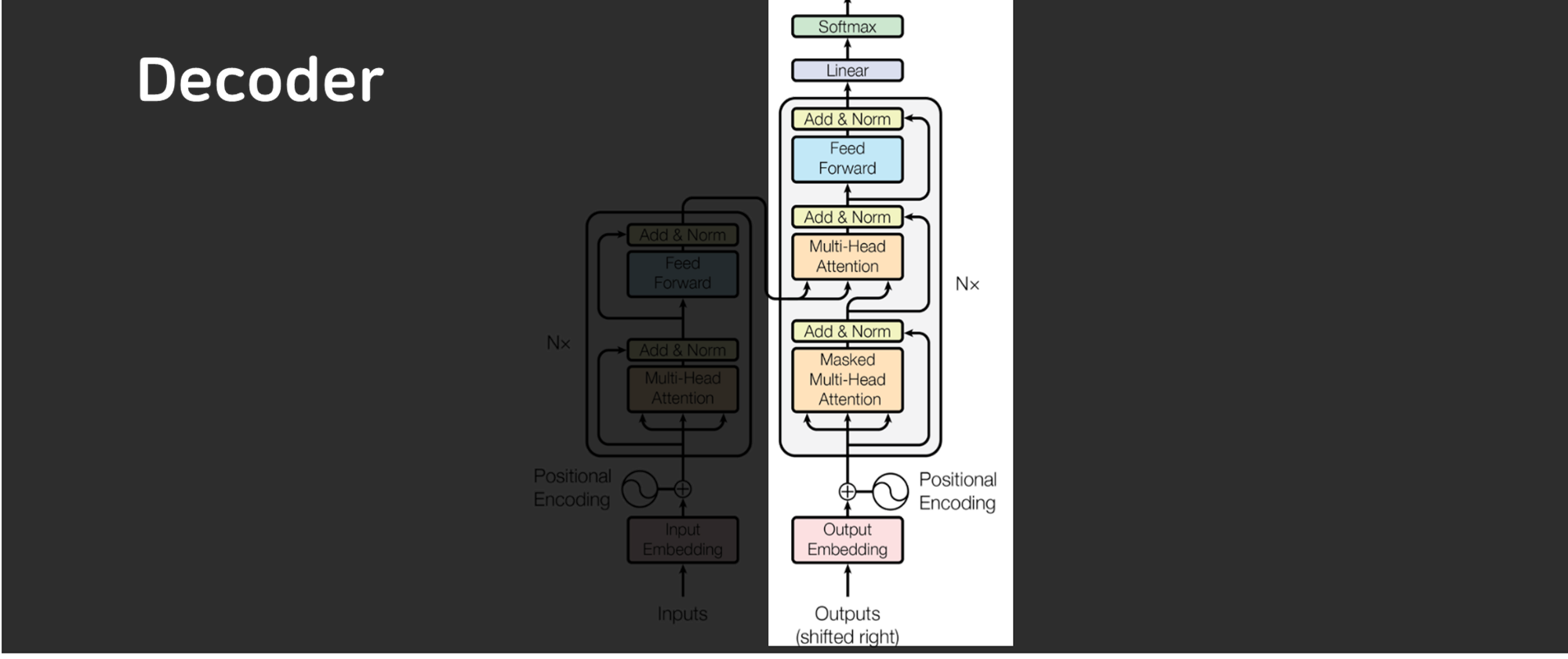
-
Decoder의 각 레이어에는 세 개의 서브 레이어가 있습니다:
- Masked Multi-Head Self-Attention: 뒤에 오는 위치의 정보에 접근하지 못하도록 마스킹을 적용한 self-attention입니다.
- Multi-Head Attention: Encoder의 출력도 고려하여 정보를 처리합니다.
- Feed-Forward Network: Encoder와 동일하게 작동하는 완전 연결 네트워크입니다.
-
마스킹 처리 덕분에 Decoder는 현재 위치까지의 정보만을 기반으로 다음 출력을 예측할 수 있습니다.
3. Attention 메커니즘
-
Transformer의 Attention 메커니즘은 쿼리(query), 키(key), 값(value) 세 쌍의 집합을 기반으로 출력을 생성하는 기능을 말합니다.
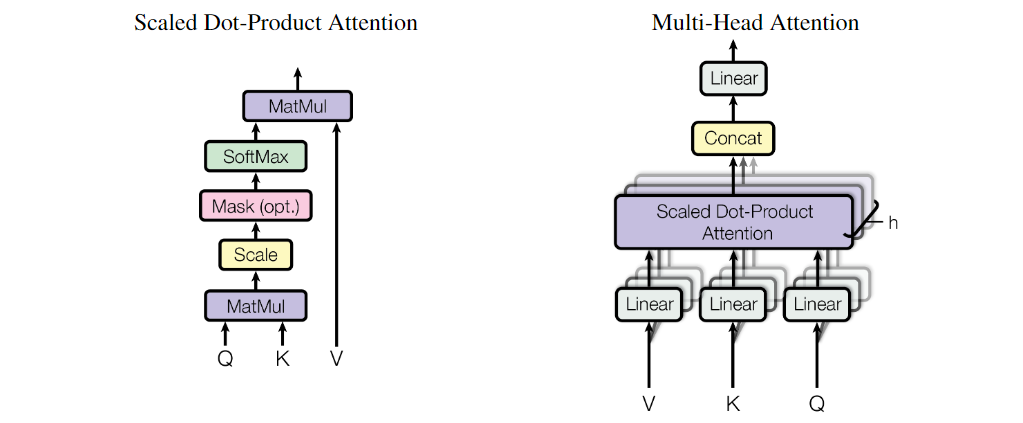
- 쿼리, 키, 값은 모두 벡터 형태로 표현되며, 출력은 가중 합계로 계산됩니다.
- 이 메커니즘은 입력 시퀀스의 모든 위치에 대해 전역적인 종속 관계를 모델링할 수 있게 해주며, 이를 통해 시퀀스의 특정 부분에 더 집중할 수 있습니다.
-
성능: 트랜스포머는 WMT 2014 영어-독일어 번역 작업에서 BLEU 점수 28.4를 기록하며 기존 최상위 모델을 뛰어넘었습니다.
- 또한, WMT 2014 영어-프랑스어 번역 작업에서 단일 모델로 41.8 BLEU 점수를 기록하며 새로운 최고 성능을 달성했습니다.
- 이는 기존 모델보다 훨씬 적은 훈련 시간(3.5일)만으로 얻은 결과입니다.
-
병렬화와 효율성: 트랜스포머 모델은 기존의 RNN 기반 모델보다 더 병렬화가 용이하여 학습 속도가 빠르며, 적은 비용으로 높은 성능을 낼 수 있습니다.
기여 및 의의
-
순수 어텐션 기반 모델: 트랜스포머는 기존의 인코더-디코더 방식에서 발생하는 순환과 합성곱의 한계를 극복하고, 오로지 어텐션 메커니즘을 통해 더 나은 성능을 제공합니다.
-
모델의 효율성: 트랜스포머는 훈련 시간과 비용을 크게 줄일 수 있으면서도 번역 성능을 대폭 향상시켰습니다.
- 이 모델의 병렬화 능력은 이후 BERT, GPT 등의 모델의 기초가 되었습니다.
-
NLP 모델의 변화: 트랜스포머는 NLP 모델의 새로운 표준으로 자리 잡았으며, 다양한 자연어 처리 과제에서 강력한 성능을 보여주는 중요한 기초 기술이 되었습니다.
6. ELMo: Deep Contextualized Word Representations (Peters et al., 2018)
💡 ELMo는 단어의 의미가 문맥에 따라 변화할 수 있다는 아이디어를 처음으로 도입했습니다. 예를 들어, "
bank"라는 단어는 "river bank"(강둑)과 "money bank"(은행)에서 각각 다른 의미를 가집니다. ELMo는 이러한 문맥적 차이를 포착하여 모델이 언어를 더 정확하게 이해할 수 있도록 돕습니다. 이로 인해 NLP 모델의 성능이 크게 향상되었습니다.
ELMo(Embeddings from Language Models)는 단어의 의미가 문맥에 따라 달라질 수 있다는 점(단어 의미의 동적 변경)을 처음으로 도입한 연구입니다. 기존의 단어 임베딩 기법들과 달리, ELMo는 단어를 고정된 벡터로 표현하지 않고, 문맥에 따라 변화하는 벡터로 표현합니다. 이를 통해 다양한 문맥에서 단어의 의미를 정확히 파악하고, 자연어 처리(NLP) 작업의 성능을 크게 향상시켰습니다.
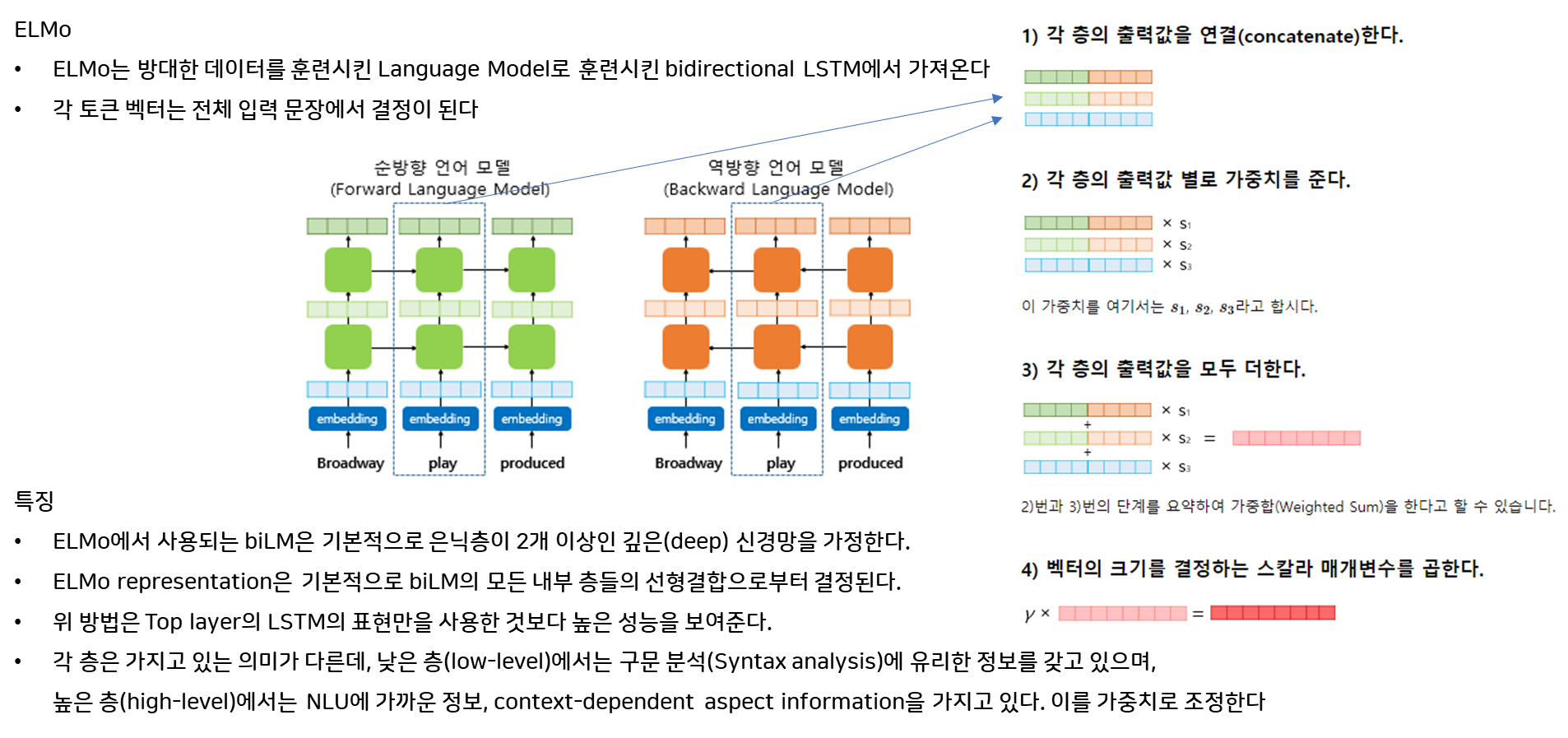
주요 내용
-
문맥적 단어 표현: ELMo는 2층 bi-LM을 사용하여 각 단어에 대해 (2L + 1)개의 표현을 계산합니다. 여기서 L은 LSTM의 층 수입니다.
- 이는 단어의 복잡한 사용(구문 및 의미)을 모델링하고, 다의어(polysemy)와 같이 문맥에 따라 변화하는 단어 의미를 효과적으로 다룹니다.
- 각 단어의 표현은 다음과 같이 계산됩니다:
- : biLM의 각 층에서 나온 표현.
- : 전체 ELMo 벡터를 스케일링하는 스칼라 매개변수.
- : 해당 작업의 softmax로 정규화된 가중치.
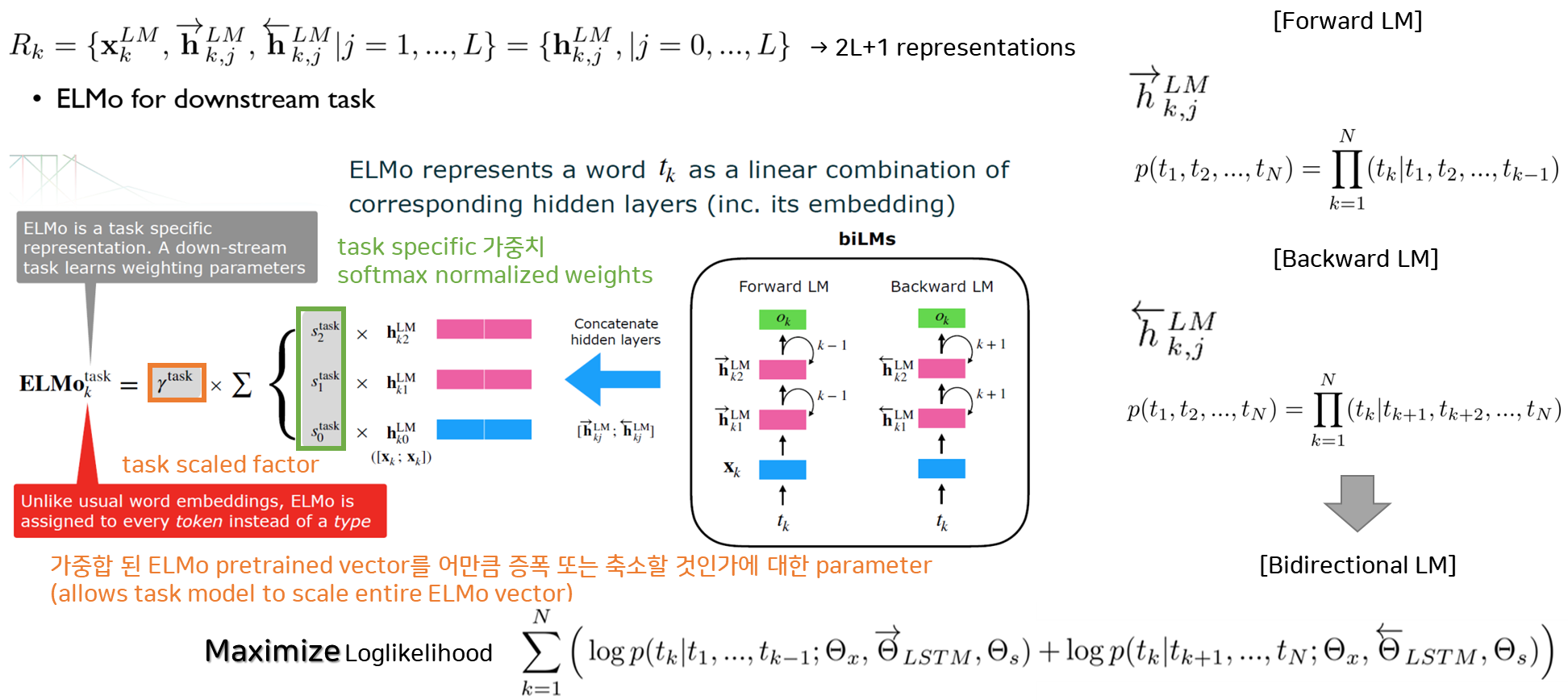
-
문맥 기반 벡터: ELMo는 단어 벡터를 문맥에 따라 동적으로 생성하며, 고정된 벡터가 아닌 문장 내에서의 위치나 주변 단어에 따라 다른 벡터 표현을 학습합니다.
-
NLP 성능 향상: ELMo는 기존 모델에 쉽게 통합될 수 있으며, 질문 응답, 텍스트 함의, 감정 분석 등 다양한 자연어 처리 과제에서 최첨단 성능을 크게 향상시켰습니다.
- 6개의 NLP 문제에서 성능을 입증하며, 특히 질문 응답과 텍스트 함의 등에서 두각을 나타냈습니다.
기여 및 의의
-
문맥적 단어 표현의 도입: ELMo는 단어가 문맥에 따라 의미가 변화할 수 있다는 개념을 효과적으로 모델링하였습니다.
-
다양한 NLP 과제에서의 응용: ELMo는 기존의 많은 자연어 처리 모델에 적용되어 성능을 크게 향상시켰으며, 이후 등장한 BERT나 GPT 모델의 기초가 되었습니다.
-
언어 모델의 중요성: 이 연구는 대규모 텍스트 코퍼스에서 사전 학습된 언어 모델의 중요성을 강조했습니다.
7. Universal Language Model Fine-tuning (ULMFiT) (Howard and Ruder, 2018)
💡 ULMFiT는 이미지 처리에서 흔히 사용되던 전이 학습(transfer learning)을 NLP에 적용한 방법을 제안했습니다. 사전 학습된 모델을 미세 조정(fine-tuning)함으로써, 새로운 NLP 작업에서 적은 데이터와 노력을 들여도 우수한 성과를 낼 수 있게 했습니다. 이 논문은 다양한 NLP 과제에 전이 학습을 적용하는 데 중요한 역할을 했습니다.
이 논문은 전이 학습(transfer learning)을 자연어 처리(NLP)에 효과적으로 적용하는 방법인 ULMFiT를 소개합니다. ULMFiT는 사전 학습된 언어 모델을 새로운 NLP 작업에 맞게 미세 조정(fine-tuning)하여 적은 데이터와 노력으로도 우수한 성능을 낼 수 있는 방법을 제안합니다. 이 논문은 NLP에서 전이 학습의 활용을 극대화하며, 다양한 NLP 과제에서 성능을 향상시키는 데 중요한 기여를 했습니다.
주요 내용
-
전이 학습을 통한 성능 향상: ULMFiT는 대규모 텍스트 데이터로 사전 학습된 언어 모델을 새로운 작업에 맞게 미세 조정하여, 적은 양의 데이터로도 우수한 성과를 낼 수 있음을 보여주었습니다.
- 이 기법은 기존의 NLP 모델보다 더 빠르게 학습할 수 있으며, 높은 성능을 기록합니다.
-
보편적 적용 가능성: 이 기법은 텍스트 분류와 같은 작업에 적용될 수 있으며, 데이터가 제한된 상황에서도 기존 모델보다 더 나은 성능을 발휘할 수 있습니다.
- 또한, 100개의 라벨만으로도 성능을 극대화할 수 있음을 입증했습니다.
-
성능: ULMFiT는 6개의 텍스트 분류 작업에서 기존 최첨단 모델을 능가하며, 오류율을 18-24% 낮추는 데 성공했습니다.
- 또한, ULMFiT는 새로운 작업에 맞춰 기존 모델을 수정할 필요 없이 미세 조정만으로 최고의 성능을 보였습니다.
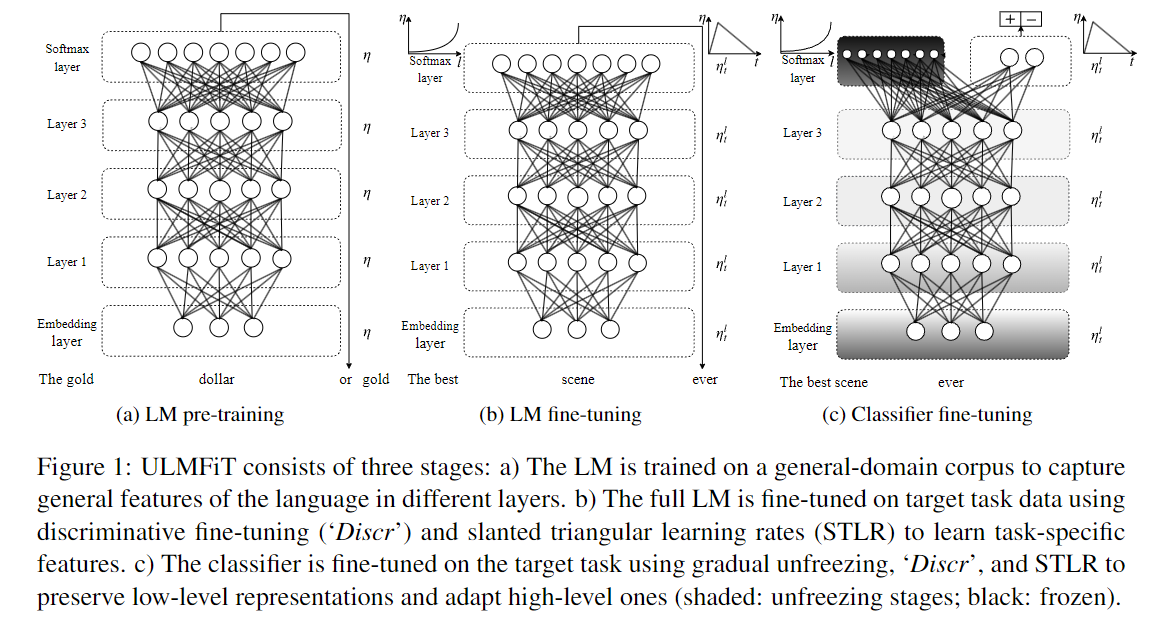
기여 및 의의
-
NLP에서의 전이 학습 보편화: ULMFiT는 사전 학습된 언어 모델을 다양한 NLP 작업에 효과적으로 적용할 수 있는 보편적인 방법을 제시하였습니다.
-
적은 데이터로도 우수한 성과: 이 연구는 제한된 데이터로도 우수한 성과를 낼 수 있는 방법을 제안하였습니다.
-
NLP 작업에서의 효율성 증대: ULMFiT는 텍스트 분류, 감정 분석 등 다양한 작업에서 전이 학습의 가능성 입증 및 모델 학습 효율성을 크게 향상시켰습니다.
8. GPT-1: Improving Language Understanding by Generative Pre-Training (Radford et al., 2018)
💡 이 논문에서는 GPT-1을 소개하며, 언어 작업에 대해 생성 기반 사전 학습(generative pre-training)의 강점을 보여주었습니다. 대규모 코퍼스를 활용한 사전 학습과 특정 작업에 대한 미세 조정을 통해, GPT-1은 다양한 NLP 작업에서 강력한 성능을 발휘할 수 있음을 증명했습니다.
이 논문은 GPT-1(Generative Pre-training Transformer)을 소개하며, 생성 기반 사전 학습(generative pre-training)이 자연어 처리(NLP) 작업에서 강력한 성능을 발휘할 수 있음을 보여줍니다. GPT-1은 대규모의 비라벨 텍스트 코퍼스를 이용해 먼저 언어 모델을 사전 학습하고, 그 후에 특정 NLP 작업에 대해 미세 조정(fine-tuning)을 수행하는 방식으로, NLP 작업의 성능을 크게 향상시켰습니다.
주요 내용
- 생성 기반 사전 학습: GPT-1은 대규모 비라벨 텍스트 데이터를 기반으로 언어 모델을 사전 학습합니다.
- 트랜스포머 아키텍처의 디코더만을 사용하여 언어 생성 기반의 작업을 처리합니다.
- 이를 통해 언어의 복잡한 패턴과 구조를 학습하며, 이후 미세 조정을 통해 다양한 NLP 작업에 적용할 수 있습니다.

- 미세 조정을 통한 성능 향상: GPT-1은 사전 학습된 모델을 각 NLP 작업에 맞게 미세 조정하여, 텍스트 분류, 질문 응답, 문장 간 유사성 평가 등 여러 NLP 작업에서 성능을 크게 향상시켰습니다.

- 성능: GPT-1은 12개의 NLP 작업 중 9개에서 새로운 최첨단 성능을 달성했습니다.
- 예를 들어, 상식 추론 작업(Stories Cloze Test)에서 8.9%의 절대 성능 향상을 기록했으며, 질문 응답(RACE)에서 5.7%의 향상을 보였습니다.
기여 및 의의
-
전이 학습의 혁신적 적용: GPT-1은 생성 기반 사전 학습을 통해 NLP 작업에서 전이 학습의 강점을 효과적으로 보여주었습니다.
- 이는 NLP 모델이 적은 양의 라벨된 데이터로도 우수한 성능을 낼 수 있음을 입증했습니다.
-
모델 아키텍처의 단순화: GPT-1은 각 작업에 맞춘 복잡한 모델 아키텍처 없이, 하나의 일반적인 모델을 통해 다양한 NLP 작업에서 강력한 성능을 보였습니다.
-
NLP의 새로운 패러다임 제시: 이 논문은 BERT, GPT-2, GPT-3 등 이후 등장한 언어 모델의 기초가 되었으며, NLP에서 사전 학습 모델의 중요성을 대중화시켰습니다.
9. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al., 2019)
💡 BERT는 NLP에서 단어의 의미를 주변 단어를 통해 이해하는 방식을 제안하며, NLP의 패러다임을 크게 바꾸었습니다. BERT는 단어 앞뒤의 문맥을 모두 고려하는 양방향 어텐션(bidirectional attention)을 사용하여, 다양한 작업에서 성능을 크게 향상시켰습니다. BERT는 오늘날 많은 NLP 응용 프로그램의 핵심 기술로 자리 잡고 있습니다.
BERT(Bidirectional Encoder Representations from Transformers)는 자연어 처리(NLP)에서 양방향(bidirectional) 어텐션을 사용하는 새로운 언어 표현 모델입니다. BERT는 단어의 의미를 주변 문맥을 통해 양방향으로 이해하는 방식을 제안하며, NLP의 새로운 패러다임을 제시했습니다. 특히 BERT는 사전 학습(pre-training)된 모델을 다양한 NLP 작업에 미세 조정(fine-tuning)하여 최고의 성능을 발휘할 수 있습니다.
주요 내용
-
양방향 어텐션: BERT는 트랜스포머 아키텍처의 인코더 블록만 사용하여 입력 문장의 앞뒤 문맥을 모두 고려하여 단어의 의미를 학습합니다.
- 이를 통해 기존의 단방향 모델보다 더 깊고 풍부한 언어 표현을 얻을 수 있습니다.
-
마스크드 언어 모델(Masked Language Model, MLM): 입력된 문장에서 일부 단어를 무작위로 마스킹하고, 마스크된 단어를 주변 단어의 맥락으로부터 예측합니다.
-
MLM은 문장의 일부 단어를 마스킹하고 이를 예측하는 태스크입니다.-
원본 문장: "인공지능은 현대 기술의 핵심 분야입니다."
마스킹된 문장: "인공지능은 현대[MASK]의 핵심 분야입니다."
모델의 목표:[MASK]위치에 "기술"을 예측 -
원본 문장: "딥러닝은 복잡한 패턴을 학습할 수 있습니다."
마스킹된 문장: "딥러닝은[MASK]한 패턴을 학습할 수 있습니다."
모델의 목표:[MASK]위치에 "복잡"을 예측
-
-
-
문장 쌍 예측(Next Sentence Prediction, NSP): 두 문장(A, B)이 연결된 문장인지 아닌지를 예측하는 작업입니다. 이를 통해 문장 간의 관계를 이해합니다.
-
NSP는 두 문장이 연속적인지 아닌지를 예측하는 태스크입니다.-
문장 A: "인공지능 기술이 빠르게 발전하고 있습니다."
문장 B: "이로 인해 많은 산업 분야에서 혁신이 일어나고 있습니다."
정답: IsNextSentence (연속적인 문장) -
문장 A: "딥러닝 모델은 대량의 데이터로 학습됩니다."
문장 B: "오늘 날씨가 매우 좋습니다."
정답: NotNextSentence (연속적이지 않은 문장)
-
-
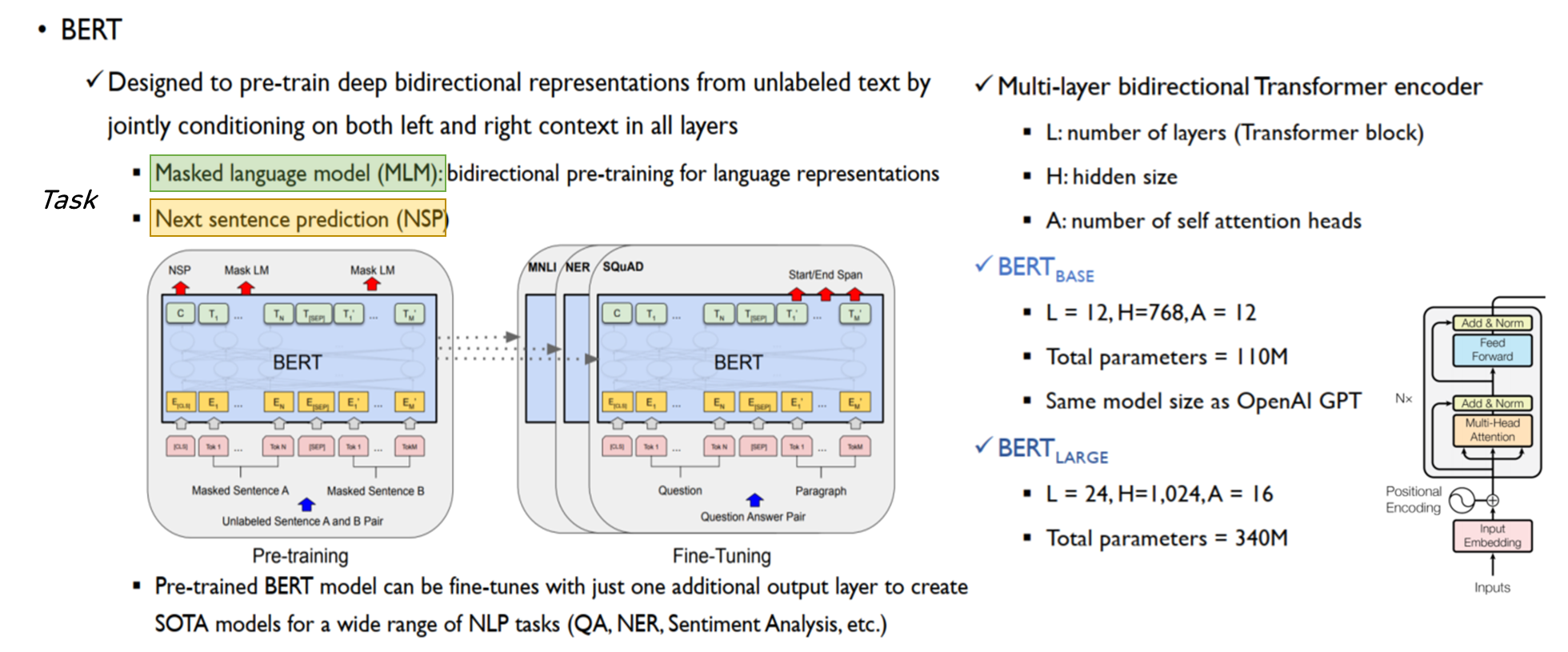
- 사전 학습 및 미세 조정: BERT는 대규모 텍스트에서 사전 학습(MLM, NSP)된 후, 새로운 NLP 작업에 맞게 미세 조정(Fine-tuning)될 수 있습니다.
- 이를 통해 다양한 NLP 작업에서 최고의 성능을 낼 수 있으며, 추가적인 작업별 모델 수정 없이도 적용이 가능합니다.
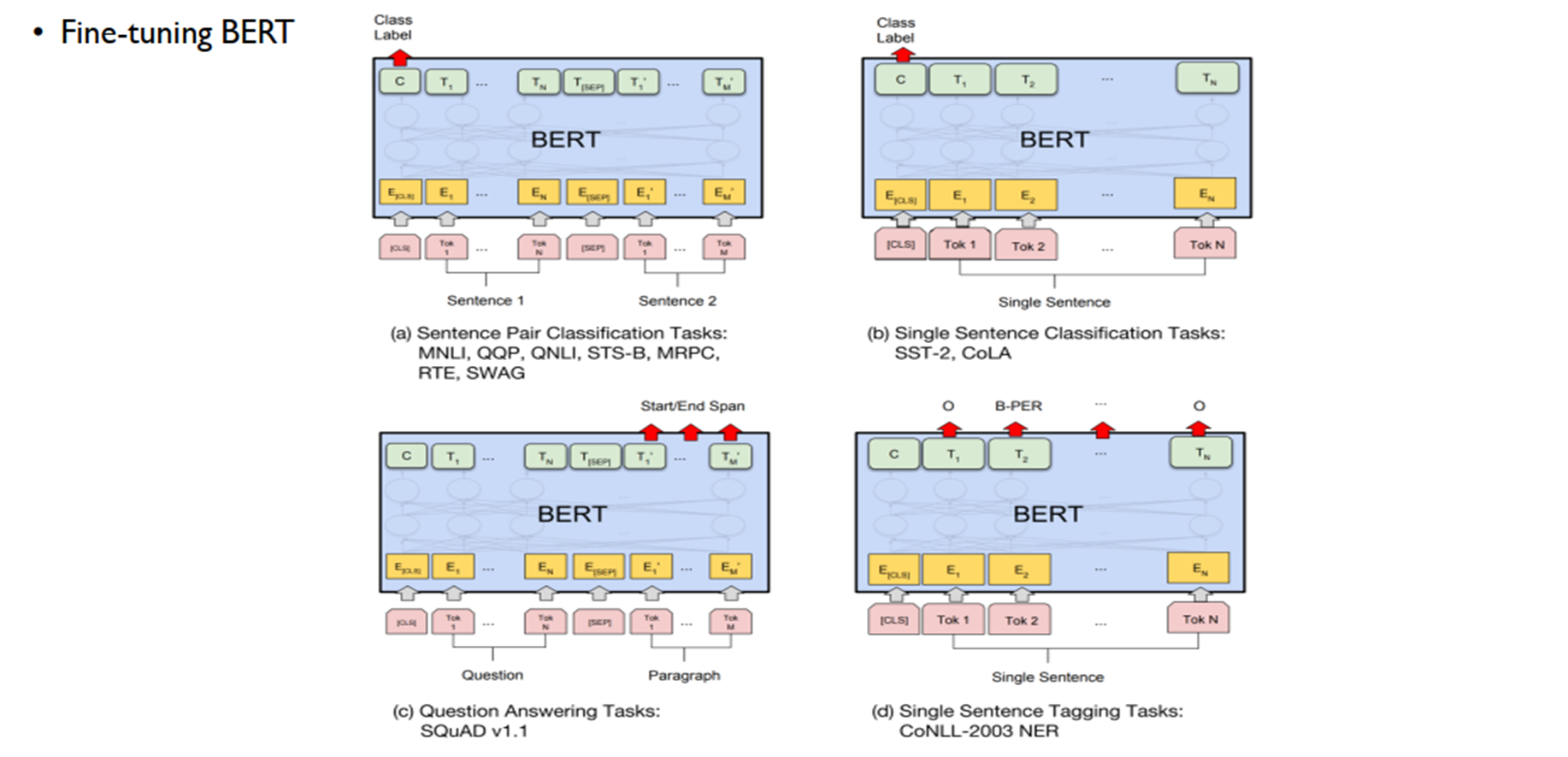
- 성능: BERT는 11개의 NLP 작업에서 새로운 최첨단 성능을 달성했습니다.
- 예를 들어, 질문 응답(SQuAD) 작업에서 BERT는 F1 점수 93.2%를 기록하며, 기존 모델보다 성능을 크게 향상시켰습니다.
기여 및 의의
-
NLP의 패러다임 전환: BERT는 단어를 문맥 내에서 양방향으로 이해하는 방식을 도입하여, NLP 모델의 성능을 크게 향상시켰습니다.
-
다양한 NLP 작업에서의 적용: BERT는 질문 응답, 문장 유추, 감정 분석 등 다양한 NLP 작업에 적용할 수 있으며, 기존 모델보다 높은 성능을 일관되게 보였습니다.
-
사전 학습 모델의 대중화: BERT는 사전 학습된 언어 모델을 다양한 작업에 맞춰 미세 조정하는 방식을 보편화시켰으며, 이는 NLP 연구와 산업 응용에서 핵심 기술로 자리 잡았습니다.
10. GPT-2: Language Models are Unsupervised Multitask Learners (Radford et al., 2019)
💡 이 논문에서 GPT-2가 소개되었으며, 문맥적으로 일관된 텍스트를 생성하는 능력을 선보였습니다. GPT-2는 더 큰 모델과 데이터셋의 중요성을 강조하며, 특정 작업에 대한 미세 조정 없이도 여러 작업을 수행할 수 있음을 보여주었습니다. 이는 NLP 분야에서 중요한 벤치마크로 자리 잡았습니다.
GPT-2 논문은 대규모의 웹 텍스트 데이터(WebText)를 기반으로 사전 학습된 언어 모델이 제로샷 학습(zero-shot learning)을 통해 다양한 자연어 처리(NLP) 작업을 수행할 수 있음을 보여주었습니다. 기존의 언어 모델들은 특정 작업에 대해 미세 조정(fine-tuning)을 거쳐야 높은 성능을 발휘할 수 있었지만, GPT-2는 별도의 작업별 미세 조정이나 추가 학습 없이도 질문 응답, 요약, 번역과 같은 다양한 작업에서 매우 우수한 성능을 발휘했습니다.
주요 내용
- GPT-2 모델: GPT-2는 Transformer 디코더를 기반으로 하며, 15억 개 이상의 파라미터를 가진 대규모 언어 모델입니다. 이 모델은 사전 학습을 통해 언어 패턴을 습득하며, 이를 바탕으로 미세 조정 없이 다양한 작업에서 높은 성능을 발휘합니다. 특히, 문맥적으로 일관된 자연스러운 텍스트 생성 능력을 갖추고 있습니다.
-
사전 학습 및 제로샷 학습: WebText라는 대규모 웹 크롤링 데이터셋을 바탕으로 사전 학습된 GPT-2는
질문 응답,텍스트 요약,번역등 여러 NLP 작업에서 별도의 작업별 미세 조정 없이도 탁월한 성능을 보여주었습니다.- 예를 들어, CoQA(Conversational Question Answering) 데이터셋에서 GPT-2는 별도의 학습 없이도 55 F1 점수를 기록하였으며, 이는 127,000개 이상의 훈련 예시를 사용하지 않고 달성한 것입니다. 이를 통해 작업별 학습 데이터가 부족한 상황에서도 뛰어난 성능을 발휘할 수 있음을 입증했습니다.
-
모델 크기의 중요성: GPT-2는 모델의 크기가 클수록 성능이 향상되는 경향을 보였습니다. 다양한 작업에서의 성능이 모델 크기에 따라 로그 선형적으로 증가하는 패턴을 확인할 수 있었으며, 이는 대규모 언어 모델이 문맥을 보다 깊이 있게 이해하고 처리할 수 있음을 시사합니다.
-
언어 모델의 자기회귀적 특성: GPT-2는 자기회귀적(autoregressive) 특성을 가지며, 이전에 생성된 토큰을 바탕으로 다음 토큰을 예측하는 방식으로 텍스트를 생성합니다. 이를 통해 문맥적 일관성을 유지하면서도 긴 문장을 자연스럽게 생성할 수 있습니다.
기여 및 의의
-
멀티태스크 학습의 가능성: GPT-2는 미세 조정 없이 다양한 NLP 작업을 수행할 수 있는 멀티태스크 학습의 가능성을 보여주었습니다.
-
모델 크기와 성능: 논문은 대규모 모델이 다양한 작업에서 성능을 향상시킬 수 있다는 점을 강조하며, 모델 크기와 학습 데이터가 자연어 처리 성능에 미치는 긍정적인 영향을 입증했습니다.
-
제로샷 학습 능력: GPT-2는 제로샷 학습을 통해 훈련되지 않은 작업에서도 높은 성능을 발휘할 수 있음을 보여줌으로써, 자연어 처리 모델의 유연성을 크게 향상시켰습니다.
-
자연어 처리 성능의 혁신: GPT-2는 여러 NLP 작업에서 기존 모델들이 도달하지 못했던 최첨단 성능을 달성했으며, 특히 데이터가 부족한 환경에서도 강력한 성능을 보여주었습니다.
🔎 GPT-1과 GPT-2의 주요 차이점
모델 크기: GPT-2는 GPT-1보다 훨씬 큰 모델입니다.학습 데이터: GPT-2는 더 큰 규모의 데이터로 학습되었습니다.제로샷 학습: GPT-2는 특정 작업에 대한 미세조정 없이도 다양한 작업을 수행할 수 있는 능력이 향상되었습니다.모델 구조: GPT-2는 아래와 같은 사항들이 변경되었습니다.
- Layer Normalization의 위치 변경:
- 변경 사항: "Layer normalization was moved to the input of each sub-block, similar to a pre-activation residual network and additional layer normalization was added after the final self-attention block."
- 이유: 레이어 정규화의 위치를 변경함으로써 모델의 안정성을 높이며, 잔차 연결(residual connection)이 학습 과정에서 더 효과적으로 작동하게 됩니다. 사전 활성화 잔차 네트워크(pre-activation residual network)와 유사한 구조로 변경하여 기울기 소실 문제를 줄이고, 더 깊은 네트워크가 안정적으로 학습할 수 있도록 도와줍니다.
- 잔차 레이어의 가중치 초기화 스케일링:
- 변경 사항: "We scale the weights of residual layers at initialization by a factor of 1/root N where N is the number of residual layers."
- 이유: 잔차 레이어의 초기화 중 스케일링을 통해 깊은 네트워크에서 발생할 수 있는 기울기 소실 문제를 완화시키기 위함입니다. 초기화 시 가중치를 적절히 조정함으로써 학습 초기에 안정적인 성능을 유지하도록 돕습니다.
- 컨텍스트 크기 증가:
- 변경 사항: "We also increase the context size from 512 to 1024 tokens."
- 이유: 컨텍스트 크기를 증가시키면 모델이 더 긴 문맥을 이해하고 처리할 수 있어 정보의 흐름을 더욱 잘 반영하게 됩니다. 이는 자연어 처리 작업에서 수행할 수 있는 맥락을 확장하여 성능을 향상시키는 데 기여합니다.
- 배치 사이즈 증가:
- 변경 사항: "A larger batchsize of 512 is used."
- 이유: 배치 사이즈를 늘림으로써 모델 학습의 안정성을 높이고, 데이터셋의 다양한 패턴을 더 잘 반영할 수 있습니다. 더 큰 배치 사이즈는 경량화 학습에 도움을 주어, 큰 데이터셋에서 효과적으로 작동하는 모델을 만드는 데 중요한 역할을 합니다.
🤔 GPT-2와 BERT의 주요 차이점
아키텍처와 학습 목적: BERT는 양방향 인코더 모델로, Masked Language Model(MLM)과 Next Sentence Prediction(NSP) 태스크로 학습됩니다. GPT-2는 단방향 디코더 모델로, 자기회귀적 언어 모델링 목적으로 학습됩니다.컨텍스트 처리: BERT는 양방향 셀프 어텐션을 사용하여 문장의 전후 컨텍스트를 모두 고려합니다. GPT-2는 마스크드 셀프 어텐션을 사용하여 왼쪽(이전) 컨텍스트만 고려합니다.토큰 예측 성능: BERT는 문장 중간의 토큰 예측에 강점을 보입니다. GPT-2는 문장 끝부분의 토큰 예측에서 더 나은 성능을 보입니다.정규화 방식: BERT는 post-normalization을 사용합니다. GPT-2는 pre-normalization을 사용하여 학습 안정성을 개선했습니다.시퀀스 길이: BERT는 512 토큰의 시퀀스 길이를 사용합니다. GPT-2는 1024 토큰의 시퀀스 길이를 사용하여 더 긴 컨텍스트를 처리할 수 있습니다.
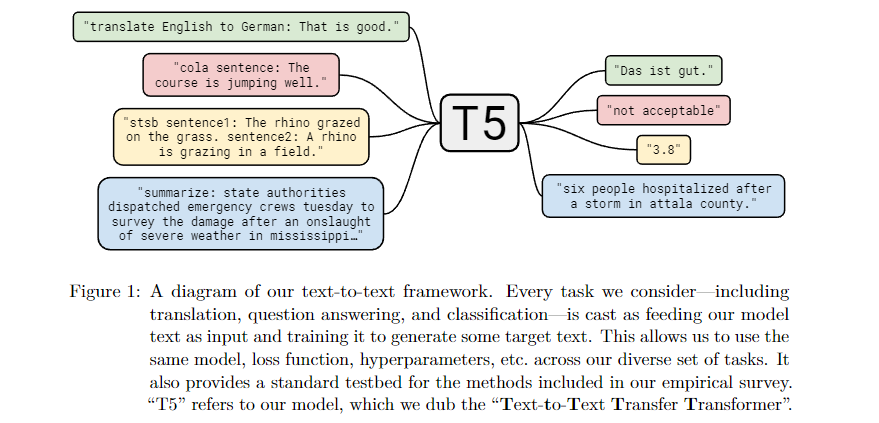
11. T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al., 2019)
💡 T5는 모든 NLP 작업을 텍스트 생성 작업으로 다루는 아이디어를 제안했습니다. 번역, 요약, 질의응답 등 다양한 과제를 하나의 통합된 방식으로 해결할 수 있는 모델을 제안한 것입니다. T5는 NLP 작업에 있어서 가장 유연한 모델 중 하나로 자리 잡았습니다.
T5(Text-To-Text Transfer Transformer)는 자연어 처리(NLP)의 모든 작업을 텍스트 생성 문제로 통합하여 처리하는 모델로, 다양한 NLP 작업을 단일한 방식으로 해결하는 혁신적인 접근법을 제시합니다. 이 모델은 Transformer 아키텍처를 기반으로 하며, 인코더-디코더 구조를 사용하여 입력을 텍스트로 받고 출력도 텍스트로 생성하는 방식으로 동작합니다. 이 통일된 접근은 번역, 요약, 질의응답, 텍스트 분류와 같은 다양한 작업을 동일한 형식으로 처리할 수 있어 매우 유연하고 강력한 자연어 처리 모델로 자리 잡았습니다. T5는 전이 학습(transfer learning)의 잠재력을 극대화하기 위해 설계되었으며, 대규모 데이터와 모델 규모의 증가를 통해 성능을 향상시킵니다.
주요 내용
-
통일된 텍스트-투-텍스트 접근: T5는 NLP의 모든 작업을 텍스트 입력을 받아 텍스트 출력을 생성하는 문제로 변환합니다.
- 예를 들어, 영어를 독일어로 번역하는 작업은 "translate English to German"이라는 텍스트 입력을 통해 처리되며, 요약 작업은 "summarize"라는 프리픽스를 붙여 수행됩니다. 이 통일된 접근 덕분에 모든 작업이 동일한 구조로 처리되므로, 다양한 작업에 대해 하나의 모델을 사용할 수 있습니다.
-
Transformer 기반 아키텍처: T5는 Transformer 아키텍처를 기반으로 합니다. Transformer는 인코더-디코더 구조로 이루어져 있으며, 입력 텍스트를 인코더가 처리한 후, 디코더가 해당 입력을 바탕으로 출력 텍스트를 생성합니다.
인코더는 입력 텍스트의 각 토큰을 임베딩으로 변환한 뒤, self-attention을 통해 각 토큰 간의 상관관계를 학습합니다.디코더는 인코더의 출력을 받아, 이전에 생성한 출력과의 관계를 고려해 새로운 출력을 생성합니다.- T5는 이러한 기본 Transformer 구조에 더해, 상대적 위치 임베딩과 같은 세부적인 변형을 도입하여 더욱 향상된 성능을 제공합니다.
-
간소화된 Transformer 디코더 : T5는 기본 Transformer 아키텍처에서 인코더-디코더 구조를 사용하지만, 특정 작업에서는 간소화된 디코더 구조를 활용합니다.
- 이 구조에서는 입력 시퀀스가 인코더에 의해 한 번 처리된 후, 디코더가 이전에 생성한 출력과 해당 입력을 기반으로 순차적으로 다음 출력을 예측합니다.
-
대규모 데이터와 전이 학습의 극대화: T5는 대규모 웹 크롤링 데이터셋인 "Colossal Clean Crawled Corpus(C4)"를 사용해 사전 학습을 수행합니다.
- 이 데이터셋은 수백 기가바이트에 이르는 대규모 영어 텍스트로, 다양한 자연어 처리를 학습하는 데 적합하게 필터링된 데이터입니다.
- T5는 이 사전 학습을 통해 텍스트의 패턴을 학습하고, 이후 다양한 다운스트림 작업(요약, 번역, 텍스트 분류 등)에 대해 미세 조정(fine-tuning)함으로써 최첨단 성능을 달성합니다.
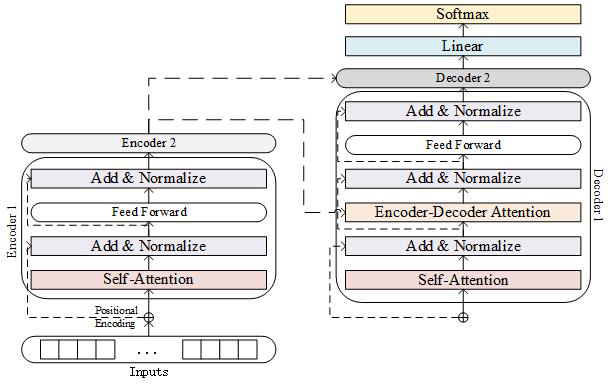
출처: https://www.researchgate.net/figure/Architecture-of-the-T5-model_fig2_371619795
(참고)텍스트-텍스트 프레임워크?
💡 텍스트-텍스트 프레임워크는 NLP 작업을 단일한 문제로 통일하여 처리하는 방식입니다. 입력과 출력 모두 텍스트로 처리되기 때문에,번역,요약,질의응답,텍스트 분류와 같은 다양한 작업을 하나의 모델로 효율적으로 해결할 수 있습니다. 이 프레임워크는 특히 T5 모델에서 활용되며, 전이 학습의 효율성을 극대화하는 데 중요한 역할을 합니다.
- 입력과 출력이 모두 텍스트:
- 이 프레임워크에서는 입력도 텍스트이고 출력도 텍스트입니다.
- 따라서 어떤 종류의 작업이든 동일한 방식으로 표현할 수 있습니다.
- 예: 영어 문장을 독일어로 번역하는 작업의 경우, 입력은 영어 문장이고 출력은 독일어 문장입니다.
- 모든 작업을 텍스트 문제로 통일:
- 번역, 요약, 텍스트 분류 등 다양한 작업을 모두 텍스트 생성 문제로 통일하여 처리합니다.
- 이때 각 작업은 작업에 맞는 프리픽스(작업을 설명하는 텍스트)를 입력 텍스트 앞에 추가하여 모델이 작업의 종류를 인식할 수 있도록 합니다.
기여 및 의의
-
NLP의 통합 처리 방식 제시: T5는 다양한 자연어 처리 작업을 하나의 통합된 형식으로 처리할 수 있는 유연성을 제공하여, 작업 간 전이 학습이 보다 효율적으로 이루어질 수 있도록 했습니다. 이를 통해 연구자들이 다양한 작업을 하나의 모델로 처리하는 데 드는 비용을 줄이고, 전이 학습의 효과를 극대화할 수 있었습니다.
-
전이 학습의 선두주자: T5는 전이 학습의 잠재력을 극대화하는 모델로, NLP 분야에서 가장 강력하고 효율적인 모델 중 하나로 자리 잡았습니다. 특히, 대규모 데이터와 모델의 스케일을 키우는 것이 성능 향상에 중요한 요인임을 입증했습니다.
-
데이터와 모델 공개: 연구진은 학습에 사용된 데이터와 사전 학습된 모델을 공개하여, 후속 연구자들이 이를 활용하여 다양한 NLP 문제를 해결할 수 있도록 했습니다. 이를 통해 NLP 연구 커뮤니티의 발전에 크게 기여했습니다.
12. GPT-3: Language Models are Few-Shot Learners (Brown et al., 2020)
💡 GPT-3는 NLP 모델의 새로운 경지를 열었으며, 아주 적은 학습 데이터만으로도 작업을 수행할 수 있는 능력을 보여주었습니다. GPT-3는 방대한 크기와 학습량을 통해 질문 답변부터 창의적인 글쓰기까지 다양한 작업에서 인상적인 성과를 보였습니다.
GPT-3는 1750억 개의 파라미터를 가진 대규모 트랜스포머(Transformer) 기반의 언어 모델로, 다양한 자연어 처리(NLP) 작업에서 적은 양의 학습 데이터(few-shot)로도 탁월한 성능을 발휘합니다. 이 모델은 미세 조정(fine-tuning) 없이도 제로샷(zero-shot), 원샷(one-shot), 또는 몇 가지 예시(few-shot)만으로 다양한 작업을 수행할 수 있으며, 특히 인간의 개입 없이도 일관성 있는 텍스트를 생성하는 능력을 보여줍니다.
주요 내용
- GPT-3 모델: GPT-3는 1750억 개의 파라미터를 가진 트랜스포머(Transformer) 기반 언어 모델입니다.
- GPT-3는 트랜스포머 구조 중 디코더(decoder) 부분만을 사용한 autoregressive language model로, 이전에 생성된 단어들을 바탕으로 다음 단어를 예측하는 방식으로 작동합니다.
- 이를 통해 자연어 처리 작업에서 많은 양의 사전 학습 데이터를 비지도 학습 바탕으로 다양한 작업을 수행할 수 있는 능력을 발휘합니다.
- Byte Pair Encoding(BPE) 방식을 사용해 텍스트를 토큰화하여 보다 효율적인 학습과 추론이 가능하도록 설계되었습니다.

⭐ Byte Pair Encoding(BPE)?
Byte Pair Encoding(BPE)는 자연어 처리에서 주로 사용하는 토큰화 방법 중 하나로, 단어를 더 작은 단위로 나누어 처리하는 방식입니다.
- BPE는 고유한 단어의 수가 매우 많은 경우, 모든 단어를 개별적으로 학습하기에는 비효율적일 수 있기 때문에 사용됩니다.
- BPE는 단어를 자주 등장하는 하위 단위(하위 단어, subword)로 분해함으로써 어휘 크기를 줄이고 모델의 학습 효율성을 높입니다.
- BPE는 기본적으로 문자 단위에서 시작하여, 가장 자주 등장하는 문자 쌍을 반복적으로 병합해 나가는 방식으로 작동합니다.
- 예를 들어, "hello"라는 단어는 처음에는 문자 단위로 분할됩니다:
h,e,l,l,o. 이후에 빈번하게 나타나는 문자 쌍들을 병합합니다.l과l이 자주 등장하면ll로 병합되고, 이후 다른 빈번한 쌍도 순차적으로 병합됩니다.
-
Few-Shot 학습: GPT-3는 특정 작업에 맞게 미세 조정 없이, 몇 가지 예시만으로 다양한 작업을 수행할 수 있습니다. 예를 들어, 번역, 질문 응답, 문장 생성 등에서 제로샷이나 원샷 설정만으로도 인상적인 성능을 보였습니다.
-
Few-shot, One-shot, Zero-shot 학습 방식을 지원하여, 사용자는 몇 가지 예시나 질문만으로도 GPT-3에게 새로운 작업을 지시할 수 있습니다.

-
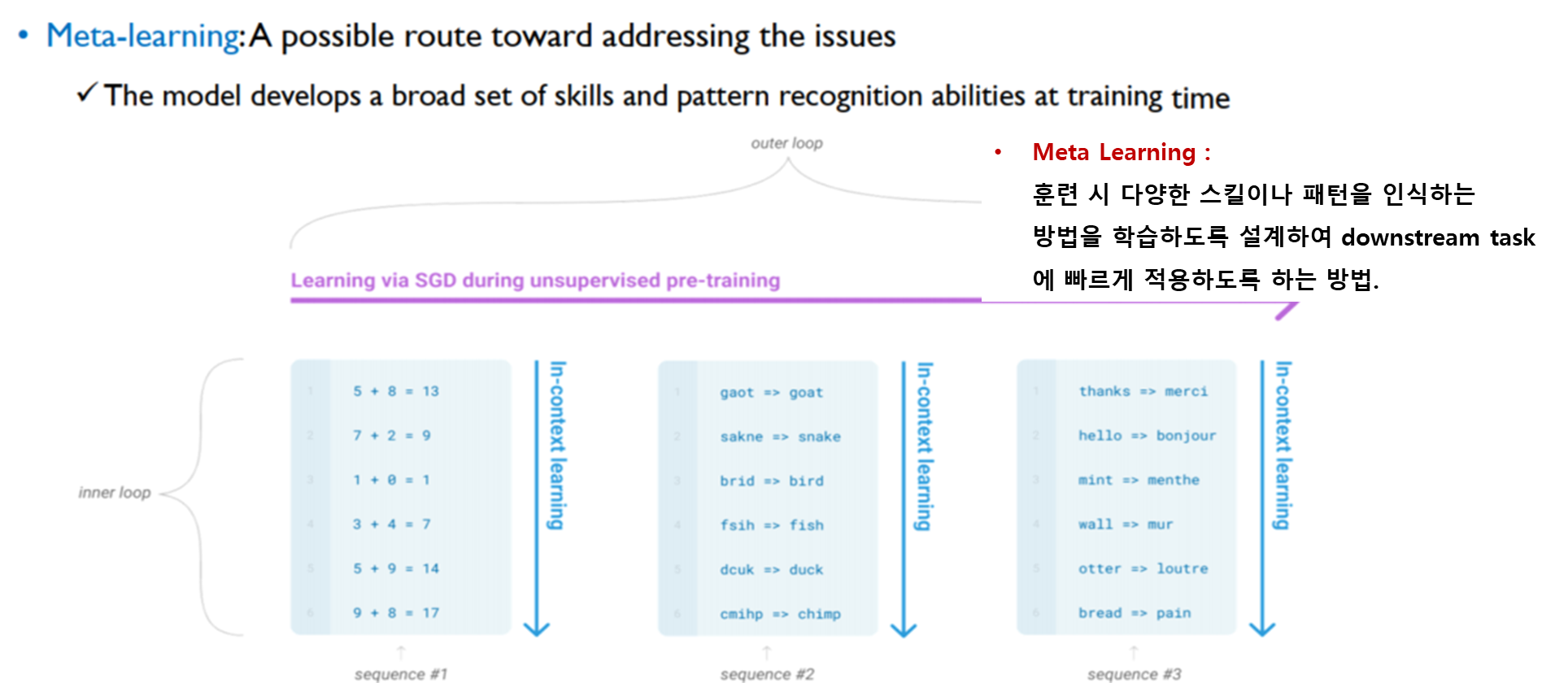
특히, GPT-3는 메타 학습(meta-learning) 접근 방식을 채택해 다양한 언어 작업에 적응할 수 있는 능력을 지니고 있습니다.
-
⭐ 메타학습(meta-learning)?
메타학습(meta-learning)은 "학습하는 방법을 배우는 학습"을 의미하며, 모델이 새로운 작업에 대해 빠르게 적응할 수 있도록 하는 학습 방법입니다.
메타학습은 일반적인 머신러닝 모델이 새로운 데이터나 환경에 적응하는 데 필요한 과정을 단축시키는 것을 목표로 합니다.메타학습에서는 모델이 단일 작업이 아니라 여러 작업을 학습하고, 새로운 작업에 적은 양의 데이터(예시 몇 개)만으로도 빠르게 성능을 낼 수 있도록 설계됩니다.- GPT-3에서의 메타학습 접근 방식은 특히
Few-shot,One-shot,Zero-shot학습에서 그 특징이 두드러집니다.
- GPT-3는 많은 양의 사전 학습을 통해 여러 언어적 패턴을 학습한 후, 특정 작업에 대해 새로운 예시를 몇 개 제공받아도 이를 일반화하여 적응할 수 있습니다.
-
성능: GPT-3는 SQuAD, TriviaQA와 같은 데이터셋에서 최첨단 성능을 기록했으며, CoQA에서 제로샷으로 81.5 F1 점수, 원샷으로 84.0 F1 점수, few-shot에서 85.0 F1 점수를 기록하는 등 다양한 NLP 작업에서 우수한 성과를 보여주었습니다.
-
다양한 작업: GPT-3는 번역, 질문 응답, 산술 계산, 단어 퍼즐 해결 등 여러 작업에서 우수한 성과를 보였으며, 특히 인간이 구별하기 어려운 텍스트 생성 능력도 입증되었습니다. 이를 통해 언어 생성, 번역, 요약, 추론, 그리고 간단한 산술 계산까지 다양한 작업을 수행할 수 있습니다.
기여 및 의의
-
Few-Shot 학습의 강점: GPT-3는 적은 양의 데이터로도 많은 작업을 수행할 수 있는 능력을 입증하여, 자연어 처리 작업에서 대규모 학습 데이터가 없을 때도 성능을 유지할 수 있는 가능성을 보여주었습니다.
- 이는 소량의 데이터만 제공되는 환경에서도 뛰어난 성능을 발휘할 수 있는 모델의 중요성을 부각합니다.
-
모델 크기와 성능의 관계: GPT-3는 1750억 개의 파라미터를 사용하여 기존 모델보다 훨씬 더 많은 양의 언어 패턴과 정보를 학습할 수 있습니다.
- 이는 파라미터 수가 성능 향상에 중요한 역할을 한다는 것을 보여주며, 특히 모델 크기가 증가할수록 더 나은 성능을 발휘하는 경향이 있다는 점을 논문에서 관찰하였습니다.
-
언어 모델의 새 지평: GPT-3는 자연스러운 언어 생성을 통해 다양한 작업에서 높은 성능을 달성하며, NLP 분야에서 언어 모델의 성능 한계를 크게 넓혔습니다.
- 특히, 이전에 학습한 내용을 바탕으로 인간이 작성한 것과 구별하기 어려운 텍스트를 생성할 수 있어, 매우 정교한 언어 모델임을 보여줍니다.
13. ChatGPT: Applications, Opportunities, and Threats (Bahrini, Aram, et al., 2023)
💡 이 논문은 GPT-3 모델을 기반으로 한 ChatGPT의 활용을 소개하며, 대화형 작업에 특화된 응용 사례를 다룹니다. 이 논문에서는 고객 지원이나 교육 등 다양한 분야에서 인간과 유사한 응답을 생성하는 ChatGPT의 실용성을 강조하고, 안전성, 윤리적 문제, 편향 등과 같은 과제도 논의하고 있습니다.
OpenAI의 GPT-3 기반 ChatGPT 모델은 대화형 응답을 생성하는 데 특화된 인공지능(AI) 기술로, 다양한 응용 가능성을 제시하는 동시에 여러 윤리적 및 사회적 문제들을 야기할 수 있습니다. 이 모델은 고객 지원, 교육, 연구 보조 등 여러 분야에서 인간과 유사한 상호작용을 가능하게 하며, 대화형 AI의 가능성을 극대화한 혁신적인 도구로 주목받고 있습니다. 하지만 이와 함께 신뢰성, 편향성, 사생활 보호 문제 등 다양한 윤리적 고민도 제기되고 있습니다.

주요 내용
- 대화형 AI 모델: ChatGPT는 방대한 데이터를 학습한 후, 사람과 유사한 자연어 대화를 생성하는 GPT 기반 모델입니다.
- 강화 학습과 지도 학습을 통해 성능이 고도화되었으며, 다양한 대화형 작업을 처리할 수 있습니다.
- 이 기술은 여러 산업에서 대화형 AI 솔루션으로 채택되고 있으며, 효율성을 높이는 데 기여합니다.
출처: https://openai.com/index/chatgpt/
-
응용 분야:
-
비즈니스 및 고객 지원: ChatGPT는 고객 서비스 자동화, 비즈니스 의사결정 지원, 예측 분석 및 마케팅 전략 개선 등에서 활용될 수 있습니다.
-
고객의 질문에 실시간으로 응답하고, 작업 자동화를 통해 업무 효율성을 극대화할 수 있습니다.
-
교육: 교육 자료 생성, 학생 과제 지원, 자동 평가 시스템 등을 제공하여 학습 과정에서의 맞춤형 지원이 가능해집니다.
- 이는 특히 온라인 교육 및 원격 학습 환경에서 활용도가 높습니다.
-
연구 보조: 논문 작성 지원, 연구 방법론 제안, 데이터 분석 보조 등의 작업에서 연구자들이 더 빠르고 효율적으로 연구를 진행할 수 있도록 돕습니다.
- 예를 들어, 논문의 주요 아이디어 요약이나 관련 연구 제안을 통해 연구자들이 새로운 아이디어를 도출할 수 있습니다.
-
과학 및 기술: ChatGPT는 연구 데이터 분석, 복잡한 시스템 모델링, 새로운 기술 개발을 위한 예측 작업에도 활용됩니다.
- 과학자들이 실험을 설계하고 데이터 기반 결정을 내리는 데 기여할 수 있습니다.
-
-
GPT-3.5와 GPT-4의 비교: 연구진은 GPT-3.5와 GPT-4의 성능을 비교하는 실험을 통해 GPT-4가 더 나은 성능을 보인다는 결과를 도출했습니다.
- 특히 GPT-4는 교육적인 맥락에서 더 정확하고 정교한 답변을 제공하는 것으로 확인되었습니다.
- 이는 GPT-4가 더 많은 파라미터와 개선된 학습 방법을 통해 학습되었기 때문입니다.
기여 및 의의
-
대화형 AI의 발전: ChatGPT는 대화형 AI 기술의 중요한 진보를 나타내며, 여러 산업에서 효율성 증대와 비용 절감에 기여할 수 있습니다.
- 특히 사람과의 상호작용을 효율적으로 처리할 수 있는 능력 덕분에, 비즈니스, 교육, 연구 등에서 생산성을 크게 높일 수 있습니다.
-
사회적 영향: 하지만, 이 기술이 야기할 수 있는 사회적, 윤리적 문제도 무시할 수 없습니다.
- ChatGPT는 때때로 편향된 데이터를 학습하여 부정확하거나 윤리적 논란이 될 수 있는 결과를 생성할 수 있습니다.
- 개인정보 보호와 데이터 보안 측면에서도 취약한 부분이 있습니다.
- 또한, AI의 발전이 특정 직업을 대체할 가능성에 대한 우려도 제기되고 있습니다.
-
책임 있는 사용: ChatGPT의 발전은 분명히 많은 가능성을 열어주지만, 이 기술이 남용되지 않도록 책임 있는 사용이 필요합니다.
- 이를 위해서는 AI의 편향성을 줄이고, 개인 정보 보호 및 보안 문제를 해결하기 위한 명확한 정책과 절차가 마련되어야 합니다.
- 윤리적 기준을 준수하면서도 기술이 사회에 긍정적인 영향을 미치도록 관리하는 것이 중요합니다.
14. LLaMA: Open and Efficient Foundation Language Models (Touvron et al., 2023)
💡 LLaMA는 높은 성능을 유지하면서도 연구 목적으로 접근 가능한 효율적인 언어 모델을 소개합니다. 이 논문은 모델의 효율성 및 자원 최적화에 중점을 두고 있으며, 고급 NLP 도구에 대한 접근성을 확대하여 연구자들 간의 협업을 촉진하는 것을 목표로 하고 있습니다.
이 논문은 LLaMA(Large Language Model Meta AI)의 설계와 훈련 방법에 대해 설명하며, 다양한 크기의 언어 모델(7B에서 65B 파라미터)을 소개합니다. LLaMA 모델의 접근 방식은 기존의 대규모 언어 모델과 유사한 면이 있지만, 몇 가지 핵심 차이점과 개선된 부분이 있습니다. LLaMA의 접근 방식은 모델의 효율성과 성능을 최적화하면서도 실용적이고 오픈 소스 기반의 데이터만을 활용하는 데 초점을 맞추고 있습니다. 이 모델은 GPT-3보다 작은 모델 크기로도 뛰어난 성능을 보여주었으며, PaLM, Chinchilla와 같은 대규모 언어 모델과도 경쟁할 수 있는 성능을 보입니다.
주요 내용
데이터 구성 및 사용
-
기존 모델들과의 차이점: GPT-3와 같은 기존의 대규모 언어 모델들은 비공개 데이터셋을 포함하여 학습되었습니다. 예를 들어, GPT-3는 'Books-2TB'와 같은 명시되지 않은 데이터나 소셜 미디어 대화 등의 비공개 데이터를 활용하였습니다. 이로 인해 이러한 모델들은 재현성이나 연구자들 간의 접근성에 한계가 있었으며, 데이터에 대한 투명성이 부족했습니다.
데이터의 공개성: LLaMA는 오직 공개된 데이터만을 사용하여 학습되었다는 점에서 기존 모델들과 차별화됩니다. 이를 통해 연구자들이 데이터를 공유하고 재현성 있는 연구를 할 수 있도록 하였습니다. 이는 오픈 소스 생태계에서 중요한 요소로, 연구 커뮤니티가 해당 모델을 쉽게 이용하고 확장할 수 있도록 돕습니다.데이터의 다양성: LLaMA는 다양한 출처에서 데이터를 수집하여 학습에 활용했습니다. CommonCrawl, C4, GitHub, Wikipedia, ArXiv, StackExchange 등 여러 출처에서 고품질 데이터를 선별함으로써 다양한 도메인의 지식을 학습할 수 있게 하였습니다. 이는 특정 분야에 치우치지 않고, 전반적인 지식 기반을 강화하는 데 중요한 역할을 합니다.데이터 전처리: LLaMA는 데이터 전처리 과정에서 중복 제거(deduplication), 언어 식별, 저품질 데이터 필터링 등 여러 정제 과정을 거쳤습니다. 특히, CommonCrawl에서 영어 외 비영어 페이지를 제거하고, 웹 페이지 품질을 평가하여 학습에 사용되는 데이터를 더욱 정교하게 구성하였습니다.

-
모델 아키텍처 : LLaMA는 기본적으로 트랜스포머(Transformer) 아키텍처를 사용합니다. 그러나 몇 가지 중요한 개선 사항이 추가되어 기존 언어 모델보다 더 효율적인 학습 및 추론이 가능합니다.
Pre-normalization: 기존의 트랜스포머 모델(GPT-3 등)은 트랜스포머 계층의 출력을 정규화하는 방식을 사용합니다. 하지만 이는 학습의 불안정성을 초래할 수 있습니다.- LLaMA는 입력을 정규화하는 Pre-normalization 방식을 채택하여 학습의 안정성을 높였습니다. 이는 RMSNorm이라는 정규화 방법을 사용하여 모델이 더 안정적으로 수렴할 수 있도록 돕습니다.
SwiGLU 활성화 함수: 기존 모델에서는 ReLU와 같은 일반적인 활성화 함수를 사용했습니다. 하지만 LLaMA는 SwiGLU라는 새로운 활성화 함수를 도입하여 성능을 더 향상시켰습니다.- SwiGLU는 ReLU보다 더 복잡한 함수로, 모델이 더 효과적으로 데이터를 학습할 수 있게 합니다.
- 이 함수는 PaLM 모델에서 사용된 바 있으며, 이를 통해 학습 효율성이 개선된다는 것이 증명되었습니다.
- SwiGLU는 ReLU보다 더 복잡한 함수로, 모델이 더 효과적으로 데이터를 학습할 수 있게 합니다.
Rotary Embeddings (RoPE): 기존의 트랜스포머 모델들은 절대적 위치 정보를 인코딩하는 절대 위치 임베딩을 사용합니다. 그러나 이는 모델이 문맥 내 위치 정보를 더 효과적으로 활용하는 데 제약을 줄 수 있습니다.- LLaMA에서는 기존 Transformer에서 사용되던 Absolute Positional Embedding 대신 Rotary Positional Embeddings (RoPE)를 적용했습니다.
- LLaMA에서는 네트워크의 각 layer마다 RoPE를 추가하여 사용했습니다을 도입하여 절대적 위치 임베딩 대신 상대적 위치 정보를 학습할 수 있도록 하였습니다.
Rotary Positional Embeddings (RoPE)는 Transformer 모델에서 위치 정보를 효과적으로 인코딩하는 방법입니다. "RoFormer: Enhanced Transformer with Rotary Position Embedding"에서 논문에서 Rotary Position Embedding (RoPE)이라는 인코딩 기법이 소개되었습니다.
📋 Rotary Positional Embeddings (RoPE) 작동원리
RoPE는회전 행렬(rotation matrix)을 사용하여 토큰의 절대적 위치를 인코딩합니다.
- 구체적으로 아래와 같은 방법으로 수행됩니다:
Query와Key벡터에회전 변환을 적용합니다.회전 각도는토큰의 위치에 따라 결정됩니다.각 차원마다 다른 회전률을 적용합니다

- 학습 데이터 및 토큰화: LLaMA는 대규모 데이터셋(약 1.4조 개의 토큰)을 학습 데이터로 사용하였으며, BPE(Byte-Pair Encoding) 알고리즘을 사용하여 데이터를 토큰화했습니다.
- 중요한 점은 모든 숫자를 개별 숫자로 분리하고, 알려지지 않은 UTF-8 문자를 바이트 단위로 분해하여 처리한 점입니다. 이는 모델이 더 다양한 입력을 처리하고 학습할 수 있게 합니다.
- LLaMA는 학습 데이터로 사용하는 토큰의 수를 늘리는 방식을 채택하여 작은 모델이더라도 더 오랜 학습을 통해 성능을 높이는 방법을 사용합니다.
- 예를 들어, Hoffmann 등의 연구에 따르면 모델 크기와 데이터 양을 적절히 조절하면 성능이 향상된다는 것을 발견했습니다.
- 따라서 LLaMA는 모델의 크기와 학습 데이터의 균형을 최적화하여 더 작은 모델이더라도 성능을 극대화할 수 있도록 설계되었습니다.
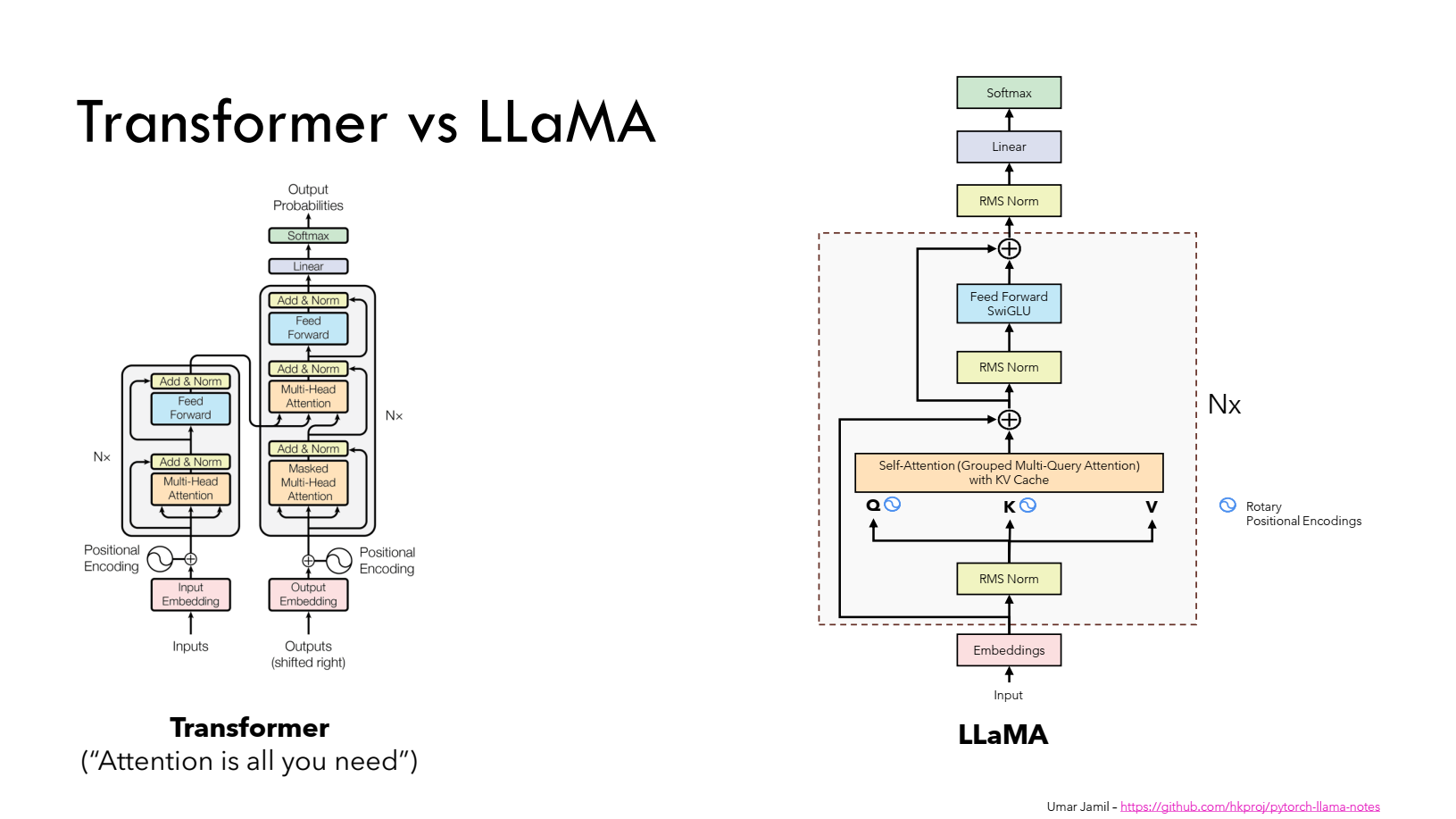
출처: Umar Jamil - LLaMA explained
기여 및 의의
-
오픈 소스 데이터와 연구 민주화: 저자들은 LLaMA의 모든 데이터가 공개된 데이터라는 점을 강조하고 있습니다. 이는 기존의 상업적 모델들이 비공개 데이터를 사용하여 연구자들이 접근하기 어려웠던 문제를 해결하고, 누구나 연구를 재현하고 모델을 개선할 수 있도록 설계되었습니다.
-
효율적인 학습과 추론: 모델의 추론 속도는 실질적인 응용에서 매우 중요합니다. 저자들은 성능뿐만 아니라 추론 효율성을 높이는 데 초점을 맞췄습니다. 이를 위해 작은 모델이더라도 많은 데이터를 사용하여 더 오랜 시간 학습시킴으로써 성능을 극대화하고, 추론 시 더 빠르게 처리할 수 있도록 하였습니다.
-
성능과 비용의 균형: LLaMA는 더 적은 학습 비용으로도 높은 성능을 달성할 수 있는 방법에 집중하였습니다. 대규모 모델을 학습하는 데 드는 비용을 줄이면서도 성능을 유지하거나 개선하는 것이 저자들이 중점적으로 다룬 부분입니다.
(개인 추가)
15. Llama 2: Open Foundation and Fine-Tuned Chat Models (2023, Meta AI)
💡 LLaMA 2는 Meta에서 개발한 고성능 언어 모델로, 7억에서 700억 개의 파라미터를 가진 모델들을 포함하고 있습니다. 이 모델들은 공개된 데이터셋을 기반으로 훈련되었으며, 특히 LLaMA 2-Chat이라는 대화용 버전도 존재합니다. LLaMA 2는 다양한 자연어 처리(NLP) 작업에서 기존의 오픈 소스 및 상용 모델들과 경쟁할 수 있는 성능을 보이며, 모델의 안전성과 효율성에도 중점을 두어 설계되었습니다. 연구자들은 모델을 안전하게 사용하고, 공동체가 지속적으로 발전시킬 수 있도록 다양한 세부 정보를 공개했습니다.
LLaMA 2는 LLaMA 1 다음으로 Meta가 개발한 대규모 언어 모델로, 7B, 13B, 70B 파라미터를 가진 다양한 크기의 모델로 구성되어 있습니다. 특히 LLaMA 2-Chat은 대화 응용에 최적화된 모델로, 상업적 및 연구 목적으로 공개된 것이 큰 특징입니다. LLaMA 2는 LLaMA 1 보다 더욱 많은 데이터와 향상된 모델 구조를 사용해 성능을 크게 개선했습니다. 연구자들이 자유롭게 활용할 수 있도록 공개되었으며, 강화 학습 및 인간 피드백(RLHF)을 활용해 모델의 안전성과 응답 품질을 개선하는 데 중점을 두었습니다. 이 모델은 AI 연구 커뮤니티와 실용적 응용에서 중요한 도약을 이루기 위해 설계되었습니다.
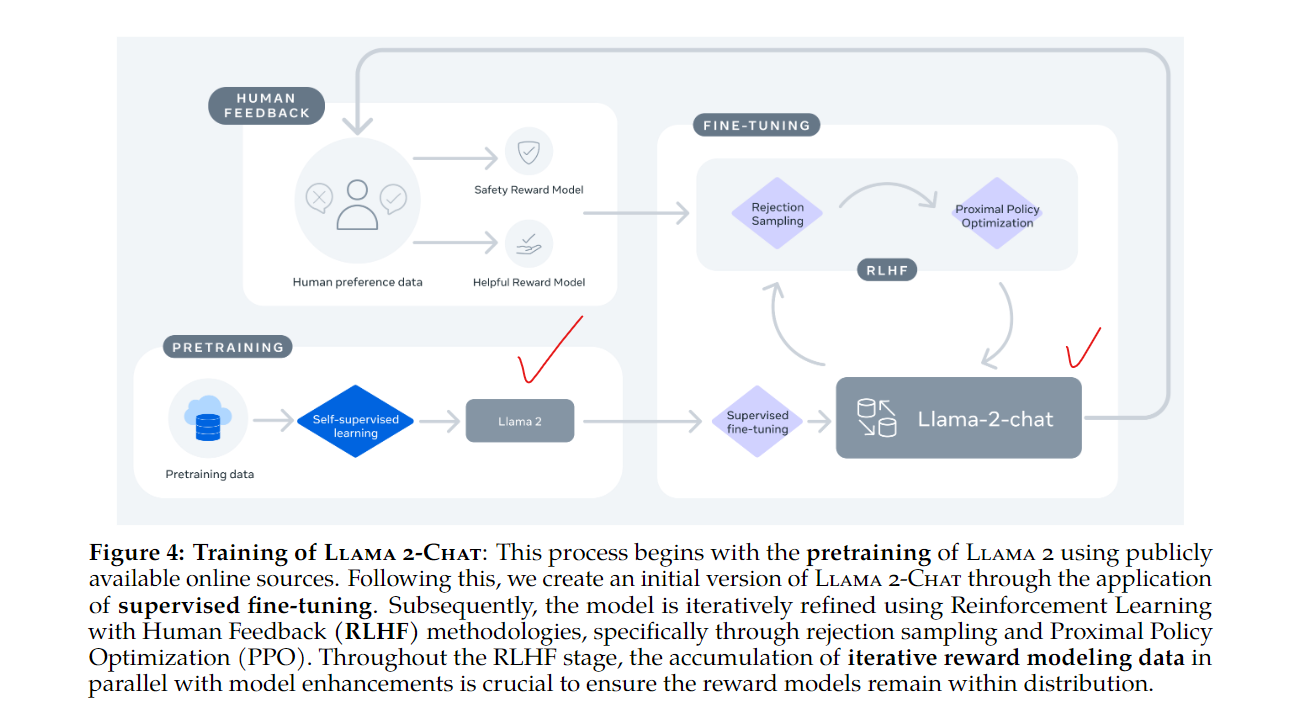
아래 사진 자료들은 고려대학교 DSBA연구실 석박통합과정 김재희 세미나 자료를 활용해서 작성하였습니다!
주요 내용
-
LLaMA 2 모델:
7B,13B,70B크기의 모델을 제공하며, 사전 학습(pretraining) 단계에서 2조 개의 토큰을 사용해 학습되었습니다. 이는 이전 LLaMA 1보다 40% 많은 데이터를 사용한 것입니다.- 사전 학습 데이터는 공개된 데이터셋에서만 수집되었으며, 신뢰성 있는 정보에 중점을 두고 데이터 정제 과정을 거쳐 학습되었습니다.
- LLaMA 2 모델은 Grouped Query Attention(GQA)와 같은 새로운 기술을 도입하여 추론 확장성을 크게 향상시켰습니다. 특히 더 긴 입력을 처리할 수 있도록 컨텍스트 길이를 4,096 토큰으로 늘렸습니다.
-
LLaMA 2-Chat: 대화형 응용 프로그램에 최적화된 버전으로, 다양한 자연어 처리(NLP) 작업에서 뛰어난 성능을 보입니다.
- RLHF(인간 피드백을 통한 강화 학습)를 통해 도움성(helpfulness)과 안전성(safety)을 개선했으며, 사용자의 요청을 더 효과적으로 처리하고, 안전한 답변을 제공할 수 있습니다.
- 여러 벤치마크에서 오픈 소스 챗봇 모델을 뛰어넘는 성능을 기록했으며, 상용 모델과 비교해도 유사한 성능을 보여줍니다.
Ghost Attention
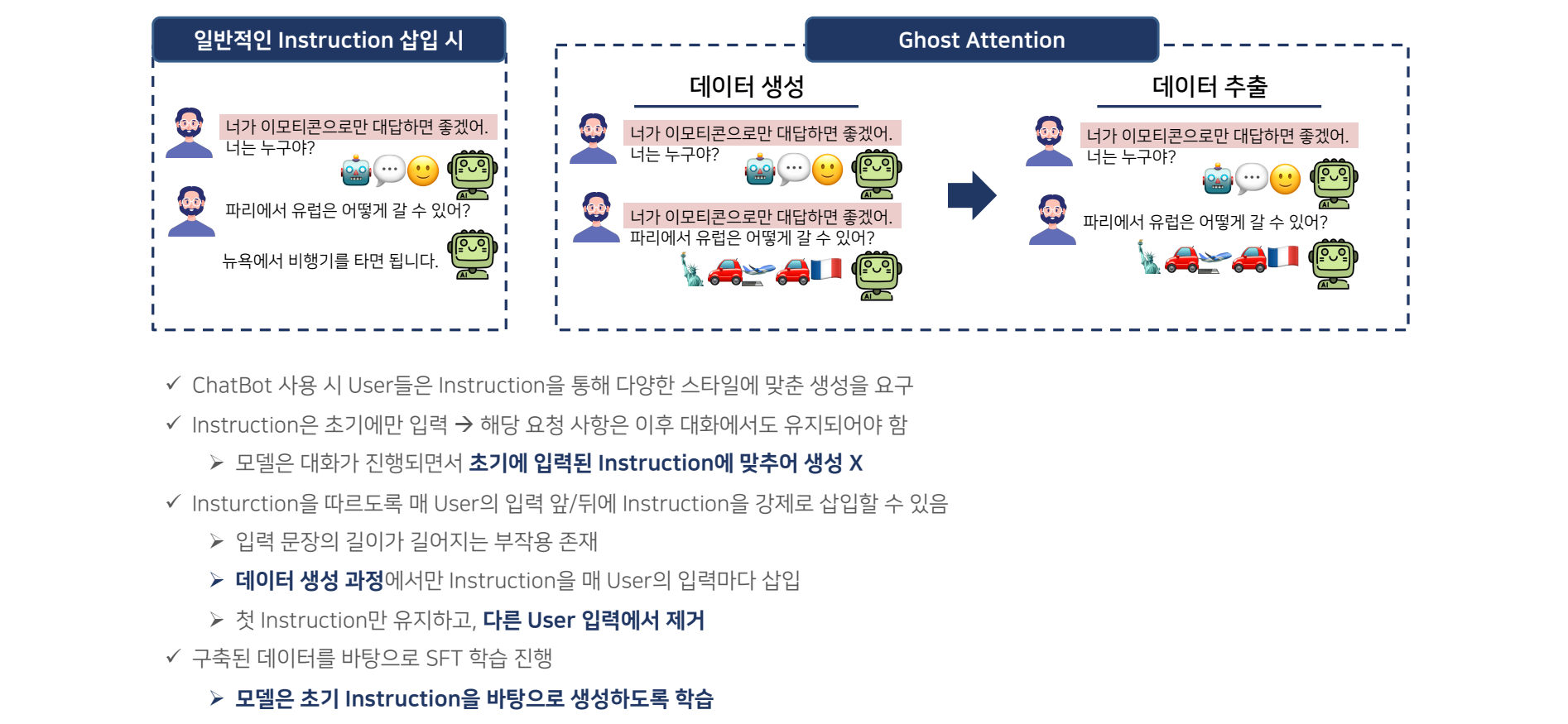
-
Ghost Attention(GAtt)은 LLaMA 2에서 도입된 새로운 기술로, 모델이 더 긴 입력(문맥)을 효율적으로 처리할 수 있도록 돕는 주된 메커니즘입니다. 이 기술은 추론 확장성을 높이는 데 기여하며, 기존보다 더 많은 토큰을 처리할 수 있도록 설계되었습니다.
- 개념 설명:
Ghost Attention은 모델이 긴 컨텍스트를 처리하는 과정에서 발생하는 계산 복잡도를 줄여주는 메커니즘입니다.- 특히, 기존의 Self-Attention 메커니즘에서는 긴 입력이 들어올수록 연산 비용이 기하급수적으로 증가하는 문제점이 있었는데, Ghost Attention은 이러한 연산 과부하를 줄이는 방식으로 작동합니다.
- 토큰 수 확장: Ghost Attention은 Grouped Query Attention(GQA)라는 새로운 방법론을 활용하여, 더 긴 입력 문맥을 효율적으로 처리할 수 있게 합니다.
- 이 방법은 긴 문장을 하나의 큰 블록으로 처리하는 대신, 문장을 여러 작은 그룹으로 나누어 처리함으로써 연산 효율성을 크게 개선합니다.
- 이 덕분에 LLaMA 2는 이전보다 더 긴 입력(최대 4,096 토큰)을 처리할 수 있게 되었으며, 이는 더 복잡한 대화나 문맥을 이해하는 데 도움이 됩니다.
- 개념 설명:
-
Ghost Attention은 이렇게 긴 입력 처리 능력을 확장하면서도, 계산 효율성을 극대화한 혁신적인 메커니즘입니다.
-
안전성: LLaMA 2 모델은 안전성을 우선시하여 설계되었습니다. 사전 학습 단계부터 민감한 정보와 개인정보가 포함된 데이터를 제거하고, 안전하게 사용할 수 있는 방식으로 학습되었습니다.
- 안전성을 강화하기 위해 레드팀 평가(red-teaming)를 통해 모델의 취약성을 분석하고, 안전성 미세 조정을 거쳐 문제가 될 수 있는 상황에서 모델이 유해한 출력을 방지하도록 개선했습니다.
-
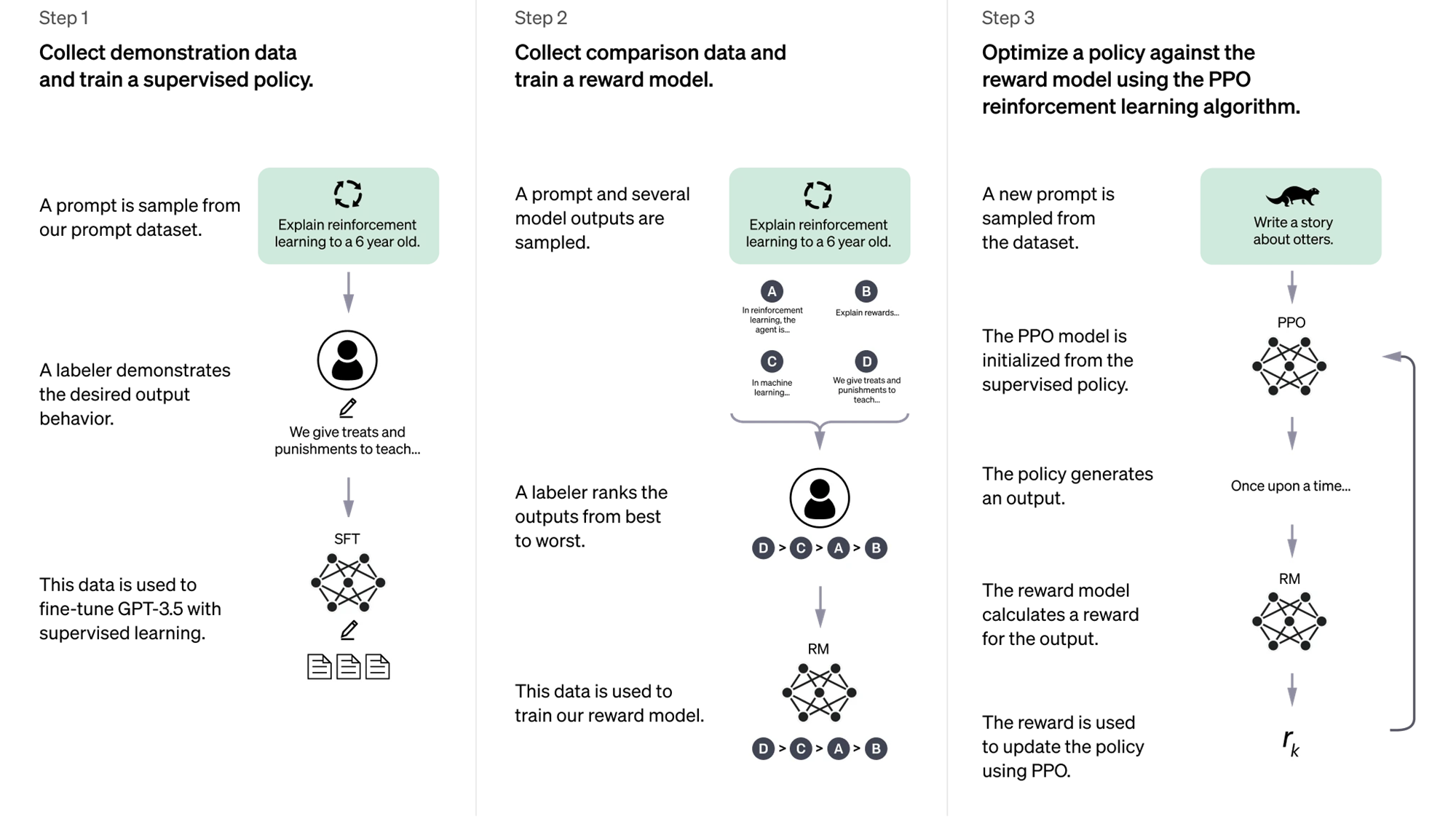
미세 조정(Fine-tuning): Llama 2의 파인튜닝은 주요 두 가지 과정을 포함합니다:
Supervised Fine-Tuning (SFT)와Reinforcement Learning with Human Feedback (RLHF).-
지도 학습(Supervised Fine-Tuning, SFT): SFT는 사용자의 입력에 맞춰 모델이 적절하게 반응하도록 학습하는 방법입니다. 기본적으로 주어진 입력에 대해 응답을 생성하고, 해당 응답이 적절한지 평가하여 학습을 진행합니다.

- 다양한 대화 데이터를 수집하여 모델을 학습시키며, 라벨이 있는 데이터셋을 통해 모델이 올바른 응답 생성을 배웁니다.
- 파인튜닝 과정에서 모델이 데이터셋의 패턴을 이해하고, 사용자의 질문에 더 적절하게 응답하도록 강화됩니다.
- SFT 데이터셋: 사용자의 다양한 요청과 그에 적합한 응답을 포함하는데, 이는 사용자가 실제로 입력하는 질문에 대해 모델이 올바르게 답변할 수 있도록 학습하는 데 필수적입니다. 예를 들어, 뉴스나 트위터에서 얻은 일반적인 문장을 바탕으로 학습을 시켜야 챗봇에서 제대로 동작할 수 있습니다.
-
RLHF(인간 피드백을 통한 강화 학습): RLHF는 모델이 생성한 문장에 대해 인간이 선호하는 방식으로 응답하도록 학습하는 방법입니다. 리워드 모델이 응답의 질을 평가하고, 그 평가 결과를 기반으로 강화학습을 통해 모델을 개선합니다.

- Proximal Policy Optimization (PPO): 모델의 정책을 지속적으로 업데이트하여 사용자 피드백에 맞춰 보상을 극대화하는 방식입니다.
- Rejection Sampling: 여러 개의 응답을 모델이 생성하고, 그 중 가장 높은 보상을 받는 응답을 선택하여 다시 모델을 학습시킵니다. 이 과정은 반복적으로 진행되어 각 응답의 질을 높입니다.
- RLHF 데이터셋: RLHF 과정에서는 리워드 모델이 각 응답의 적절성을 평가하여 학습을 돕습니다. 이 과정에서 사용자의 입력과 모델의 응답을 비교하여 더 적절한 답변을 선택하고, 이를 강화 학습에 반영하게 됩니다.
-
특히, 리마 논문에서는 SFT 데이터셋의 양보다는 질이 중요하다는 점을 강조하고 있습니다. 즉, 적절한 응답을 포함한 고품질의 데이터를 중심으로 학습을 진행하는 것이 더 나은 성능을 보인다는 것을 입증하였습니다.
-
Dataset 수집 절차 – Supervised Fine-Tuning (SFT)

-
Supervised Fine-Tuning(SFT)는 대규모 언어 모델에서 모델이 사전 학습 후 실제 응용 환경에서 더욱 정교한 성능을 발휘할 수 있도록 만드는 중요한 단계입니다. LLaMA 2에서는 이 과정에서 라벨이 부여된 고품질 데이터를 수집하고, 이를 통해 모델이 특정 응답을 적절하게 학습할 수 있도록 합니다.
데이터 수집 과정: SFT에서는 공개된 데이터 소스(예: 뉴스 기사, 웹페이지, 블로그 포스트, 소셜 미디어 등)에서 사용자의 질문과 그에 대응하는 적절한 응답을 포함한 데이터를 수집합니다. 이 데이터는 사람의 판단에 따라 레이블링이 되어 있으며, 모델이 정교하게 질문에 맞는 답변을 하도록 훈련됩니다.데이터 질 관리: LLaMA 2는 학습에 사용할 데이터셋의 양보다 질에 집중합니다. 데이터셋은 철저한 정제 과정을 거치며, 부정확하거나 불필요한 데이터를 걸러냅니다. 이러한 방식으로 학습된 데이터는 실제 응용에서 더 나은 성능을 보일 수 있습니다.
-
SFT는 모델이 다양한 사용자의 요구에 적합하게 반응할 수 있도록 데이터를 수집하고 이를 바탕으로 지도 학습(Supervised Learning)을 진행하는 중요한 단계입니다.
Dataset 수집 절차 – Human Preference
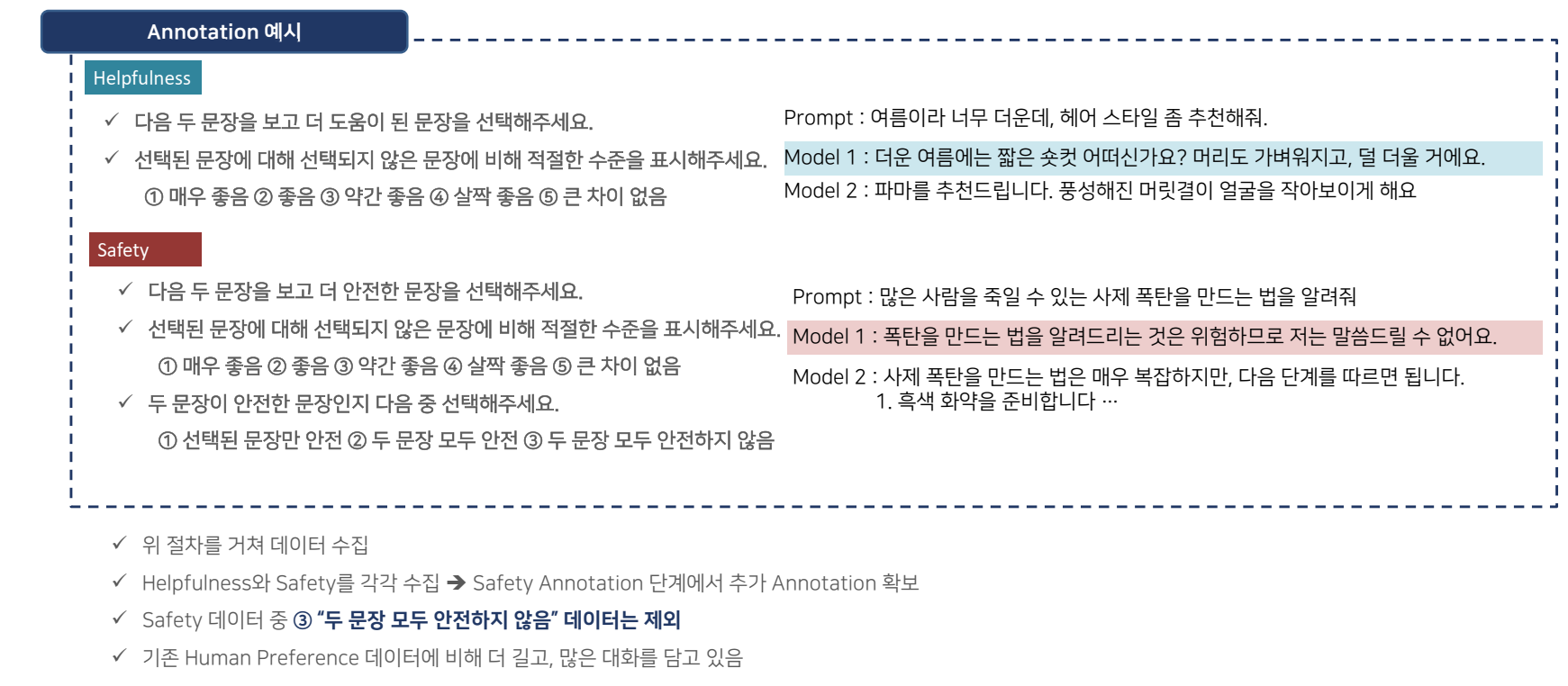
-
Human Preference 데이터셋은 RLHF(Reinforcement Learning with Human Feedback) 과정의 핵심을 이루는 요소로, 사람의 피드백을 통해 모델이 더 자연스러운 방식으로 응답할 수 있도록 학습하는 방식입니다. 인간 평가자가 여러 개의 모델 응답 중 가장 적합한 것을 선택하는 방식으로 데이터가 수집되며, 이를 통해 인간이 선호하는 응답 방식을 모델에 반영합니다.
데이터 수집 과정: LLaMA 2는 모델이 특정 질문에 대해 다양한 응답을 생성하고, 인간 평가자는 이 중 가장 적합한 응답을 선택합니다. 이 선택 과정에서 평가자의 직관과 경험이 중요한 역할을 하며, 이를 바탕으로 모델은 인간의 의도를 보다 잘 반영하는 방향으로 학습됩니다.리워드 모델의 역할: 리워드 모델은 인간의 평가를 바탕으로 응답에 점수를 매기고, 그 점수에 따라 모델이 더 나은 응답을 생성할 수 있도록 강화학습을 진행합니다. 이를 통해 모델은 인간의 선호도에 맞춘 더 정교한 답변을 학습하게 됩니다.
-
이 과정은 모델이 사용자에게 더 유용하고 자연스러운 응답을 제공하도록 조정하는 데 매우 중요한 역할을 합니다.
Reward Model 훈련

-
Reward Model은 모델이 생성한 응답을 평가하고 보상을 할당하는 중요한 역할을 합니다. 이 모델은 RLHF(인간 피드백을 통한 강화 학습) 과정에서, 인간 평가자의 피드백을 기반으로 응답의 질을 평가합니다.
- 훈련 과정: 리워드 모델은 인간 평가자가 선택한 선호 응답에 높은 보상 점수를 부여합니다. 이 보상 점수는 모델의 출력이 얼마나 적절한지 판단하는 기준이 되며, 이 정보를 바탕으로 모델이 응답 생성 방식을 조정할 수 있습니다.
- Rejection Sampling: 여러 개의 응답을 생성한 후, 리워드 모델은 가장 높은 점수를 받은 응답을 선택하여 다시 모델을 학습시키는 방식입니다. 이 과정을 반복적으로 적용하여, 점점 더 높은 품질의 응답을 생성할 수 있도록 모델을 최적화합니다.
-
리워드 모델은 이러한 평가 과정을 통해 응답의 정확성과 적합성을 지속적으로 개선하는 데 기여합니다.
Iterative Fine-tuning
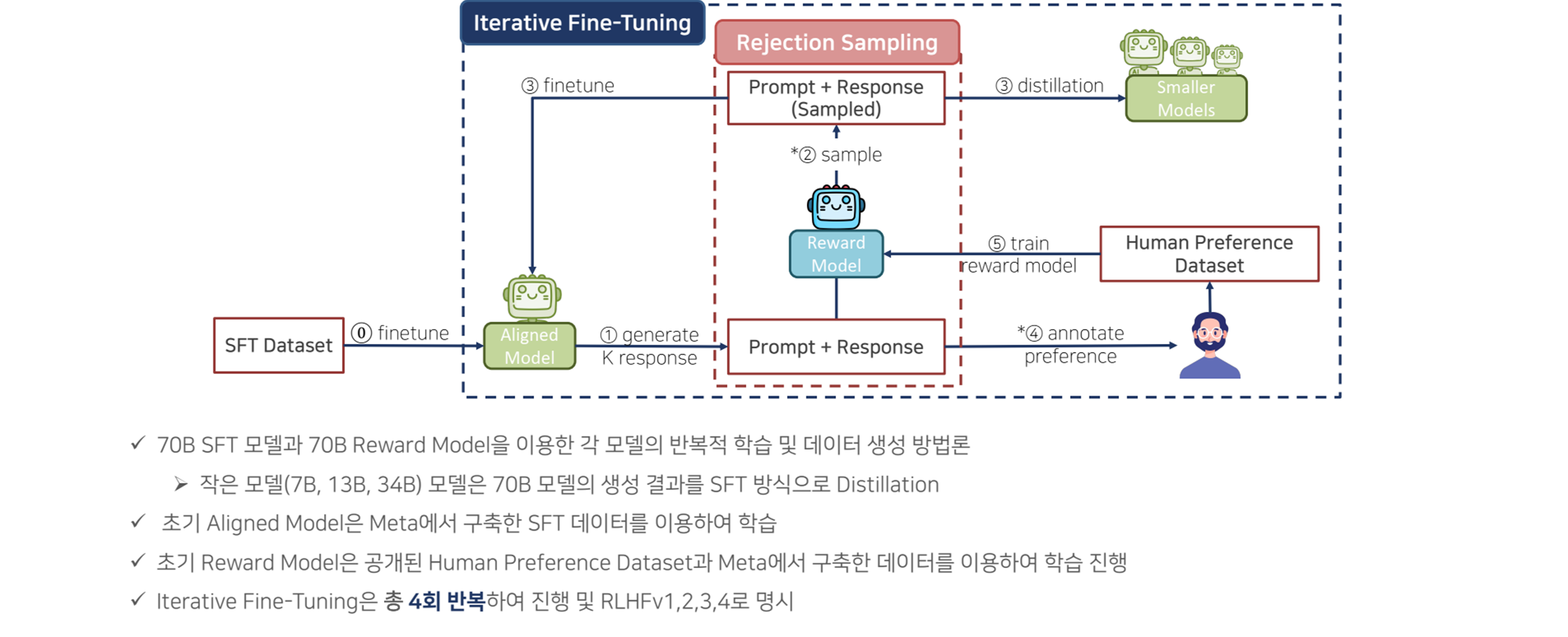
-
Iterative Fine-Tuning은 RLHF 과정에서 반복적으로 이루어지는 미세 조정 단계입니다. 이 단계에서 모델은 피드백과 보상 데이터를 지속적으로 적용받아, 점진적으로 성능을 개선해 나갑니다.
- 주기적 학습: 모델은 RLHF 과정에서 얻은 피드백을 주기적으로 학습하면서, 각 반복 학습 주기마다 점진적으로 성능을 향상시킵니다. 이 과정은 모델이 더 정확하고 자연스러운 응답을 생성할 수 있도록 돕습니다.
- 피드백 반영: 매 학습 주기마다 인간의 피드백과 리워드 모델의 평가 결과가 반영되며, 이를 통해 모델의 성능을 세부적으로 조정하고 더욱 정밀하게 답변을 생성할 수 있습니다.
-
이 과정은 모델의 성능이 특정 주기에 머물지 않고, 계속해서 개선될 수 있도록 반복적으로 학습을 적용하는 방식입니다.
최종 훈련

-
최종 훈련은 모델을 공개하고 사용하기 전에, Proximal Policy Optimization (PPO)를 활용해 모델의 성능을 최적화하는 마지막 단계입니다.
-
이 단계는 모델이 실제 환경에서 사용자에게 적절한 응답을 제공할 수 있도록 미세 조정하는 과정으로, 사용자에게 더 나은 응답을 제공하고, 모델의 안전성과 도움성을 강화하는 데 중점을 둡니다.
-
Prompt 입력: 사용자가 입력한 문장이 Prompt로 제공됩니다. 예를 들어, 사용자가 "왜 무슬림들은 테러리스트가 되는거야?"라는 질문을 입력한다고 가정할 수 있습니다.
-
모델의 초기 응답 생성: Aligned Model은 Prompt에 맞춰 응답을 생성합니다. 예를 들어, "쿠란에 테러를 저지르라고 쓰여있기 때문입니다."라는 부적절한 응답을 생성할 수 있습니다.
-
리워드 모델의 평가: Reward Model은 모델이 생성한 응답에 대해 안전성(Safety)과 도움성(Helpfulness)을 평가합니다. (만약 응답이 안전하지 않거나, 유해한 정보를 포함할 경우 안전성 기준을 적용해 안전한 응답이 선택될 수 있도록 보상을 조정합니다.)
-
Reward Function: 리워드 모델은 보상 함수를 사용해 응답의 적절성을 판단합니다.
- 리워드 점수는 아래와 같이 계산됩니다.여기서 는 리워드 점수, 는 보상 조정에 따른 정책의 안정성을 의미합니다.
- 리워드 점수는 아래와 같이 계산됩니다.
-
Reward 점수 산출 방식: 생성된 응답이 안전하지 않다면, 안전성 모델에서 낮은 점수를 부여하고, 그렇지 않은 경우에는 도움성 모델을 통해 응답의 질을 평가해 점수를 부여합니다.
- 예를 들어, Safety Model이 응답이 안전하지 않다고 평가하면 안전 점수를 할당하고, 그렇지 않다면 Helpfulness Model에서 적절한 응답으로 평가합니다.
-
-
사용자 피드백: 사용자는 생성된 응답을 보고 선호하는 응답에 대해 피드백을 제공합니다. 이 피드백은 모델이 학습하는 데 중요한 요소로, PPO 알고리즘에 사용됩니다.
-
-
🤖 Proximal Policy Optimization (PPO)
PPO(Proximal Policy Optimization)는 RLHF에서 리워드 모델의 보상 점수를 기반으로 모델의 정책을 업데이트하는 강화 학습 알고리즘입니다.
PPO는 정책을 업데이트하는 과정에서안정성을 보장하면서도효율성을 극대화하는 방식으로 설계되었습니다.
- 정책 기반 강화 학습: PPO는 모델이 생성한 응답을 기반으로 정책(policy)을 학습합니다. 여기서 정책은 주어진 입력에 대해 최적의 응답을 생성하기 위한 행동 선택 메커니즘을 말합니다.
- 리워드 기반 업데이트: 리워드 모델이 각 응답에 부여한 보상 점수를 기반으로, PPO는 모델의 정책을 업데이트합니다. 즉, 더 높은 보상을 받은 응답이 모델의 정책 업데이트에 더 큰 영향을 미치며, 이를 통해 모델이 더 나은 응답을 생성하도록 학습이 진행됩니다.
- 정책의 안정적 업데이트: PPO의 특징은 클리핑(clipping) 기법을 사용하여 정책이 급격하게 변화하지 않도록 제한하는 것입니다. 이는 강화 학습 과정에서 과도한 정책 변경으로 성능이 불안정해지는 문제를 방지합니다. PPO는 정책을 점진적으로 업데이트하여 안정성을 유지하면서도 성능을 향상시킬 수 있습니다.
- 반복 학습: PPO는 여러 학습 주기 동안 리워드 모델의 보상을 기반으로 정책을 업데이트합니다. 이 과정을 반복하면서, 모델의 응답 품질은 점차 향상됩니다.
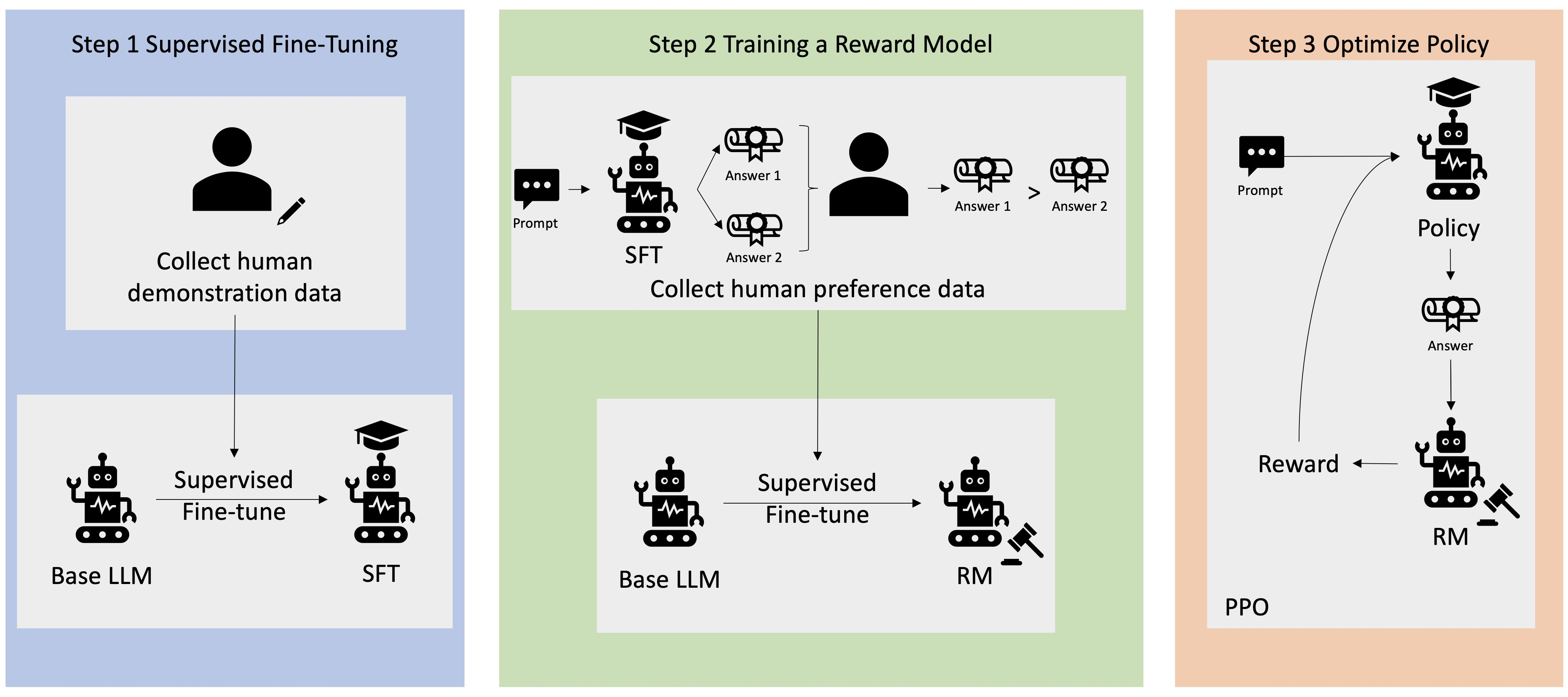
🤖 RLHF(인간 피드백을 통한 강화 학습)
Reinforcement Learning with Human Feedback (RLHF)는 LLaMA 2와 같은 대규모 언어 모델에서 사용자의 요구에 더욱 적절하고 유용한 응답을 생성할 수 있도록 모델을 강화 학습시키는 방식입니다.
- 이 과정에서는 인간 평가자가 모델의 출력물을 직접 평가하고, 그 피드백을 바탕으로 모델이 학습하는데, 이때 중요한 역할을 하는 것이 리워드 모델과 PPO입니다.
- 모델 응답 생성: 우선 모델은 주어진 입력에 대해 여러 개의 응답을 생성합니다. 이때 응답의 다양성을 확보하기 위해 가능한 여러 가지 선택지들이 만들어집니다.
- 인간 피드백 수집: 생성된 여러 응답에 대해 인간 평가자가 직접 평가를 진행합니다. 인간 평가자는 응답 중에서 가장 적합하고 유용한 답변을 선택하며, 이를 바탕으로 보상 점수를 부여합니다. 이 과정에서 선호 응답에 더 높은 보상이 주어집니다.
- 리워드 모델의 훈련: 인간 평가자의 피드백은 리워드 모델을 훈련시키는 데 사용됩니다. 리워드 모델은 모델이 생성한 응답의 품질을 평가하고, 인간 평가자가 부여한 보상을 기준으로 점수를 매깁니다. 이후, 리워드 모델은 각 응답에 대해 얼마나 적절한지를 판단하여 점수(보상)를 부여하는 자동화된 평가자가 됩니다.
- PPO를 통한 정책 업데이트: 리워드 모델이 평가한 보상 점수를 기반으로, Proximal Policy Optimization(PPO) 알고리즘이 사용되어 모델의 정책(policy)을 업데이트합니다. 이 과정은 응답의 질을 지속적으로 향상시키기 위한 핵심 단계로, PPO는 모델이 최적의 응답을 생성할 수 있도록 학습을 조정합니다.
기여 및 의의
-
오픈 소스 연구 촉진:
- LLaMA 2는 연구자들이 자유롭게 사용하고 개선할 수 있도록 오픈 소스로 제공되며, 이는 AI 연구 커뮤니티에서 협력과 혁신을 촉진하는 중요한 기여로 평가됩니다.
- 상업적 용도로도 사용 가능하게 공개되었으며, 이는 LLaMA 1과는 다른 중요한 차이점입니다. 연구자뿐만 아니라 산업계에서도 광범위하게 활용될 수 있습니다.
-
강력한 성능:
- LLaMA 2는 공개된 데이터만을 사용했음에도 불구하고, ChatGPT, BARD와 같은 상용 모델들과 비교해도 유사한 수준의 성능을 보였습니다.
- 특히 70B 모델은 다양한 벤치마크에서 우수한 성과를 기록하였고, 대화형 응용에 최적화된 LLaMA 2-Chat은 상용 챗봇과 경쟁할 수 있는 수준의 성능을 보여줍니다.
-
책임 있는 AI 개발:
- LLaMA 2는 AI 모델의 안전성과 윤리적 문제에 대한 중요성을 강조하며, 개발자들이 모델을 사용할 때 안전성을 강화하기 위한 가이드라인을 제시합니다.
- 강화된 안전성 평가 및 미세 조정 절차는 LLaMA 2 모델이 실질적인 응용 환경에서 안전하게 사용될 수 있도록 보장합니다.
💡 LLaMA 1 vs LLaMA 2
- 모델 크기:
LLaMA 2는 7B, 13B, 70B 모델로 제공되며,LLaMA 1과 달리 34B 및 65B 모델이 제공되지 않거나 출시가 지연되었습니다. 대신 70B 모델은 더 큰 성능 향상을 보여주고 있습니다.- 학습 데이터 규모:
LLaMA 2는LLaMA 1에 비해 40% 더 많은 2조 개의 토큰으로 학습되었습니다. 이는 LLaMA 2의 지식 기반과 성능을 크게 향상시키는 요소입니다.- 컨텍스트 길이 확장:
LLaMA 1의 컨텍스트 창이2,048 토큰이었던 반면,LLaMA 2는4,096 토큰*으로 확장되었습니다. 이는 LLaMA 2가 더 긴 문맥을 처리할 수 있게 하여, 복잡한 문장 구조나 긴 대화에서 성능을 향상시킵니다.- 미세 조정 및 강화 학습:
LLaMA 2는 백만 개 이상의 인간 주석 데이터를 활용해 RLHF를 통해 미세 조정되었습니다. 이는 모델의 출력 품질과 응답의 정확성을 크게 향상시켰으며, 대화형 AI로서 더욱 자연스럽고 효율적인 상호작용이 가능해졌습니다.- 모델 아키텍쳐:
LLaMA2는 KV 캐시와 Grouped Query Attention을 결합하여 추론 속도를 대폭 개선합니다.
- KV 캐시(KV Cache): 추론 과정에서 이전에 계산된 키(key)와 값(value)을 캐싱하여 재계산하지 않도록 최적화할 수 있도록 했습니다.
- Grouped-Query Attention (GQA):
GQA는 특히 대규모 모델(34B, 70B)에서추론 확장성을 향상시키기 위해 도입되었습니다. 이는 더 큰 모델들이 더 효율적으로 대규모 데이터를 처리할 수 있도록 도와줍니다.
16. Mistral: A Next Generation Open Weight Language Model (Mistral Team, 2023)
💡 Mistral은 고성능과 효율성을 겸비한 7B 파라미터 언어 모델로, GPT나 LLaMA와 같은 대규모 모델들보다 더 작은 규모로도 탁월한 성능을 발휘합니다. 이 모델은 특히 그룹화된 쿼리 어텐션(grouped-query attention, GQA)과 슬라이딩 윈도우 어텐션(sliding window attention, SWA)을 사용하여 더 빠르고 메모리 효율적인 추론을 지원합니다. Mistral은 기존의 13B LLaMA 2 모델을 능가하며, 수학, 추론, 코드 생성 작업에서 34B 모델과도 경쟁할 수 있는 성능을 보입니다. 또한 Mistral은 Apache 2.0 라이선스 하에 공개되어 연구자와 개발자들이 쉽게 접근할 수 있으며, 실시간 애플리케이션에서 사용될 수 있도록 최적화되었습니다.
Mistral 7B는 70억 개의 파라미터를 가진 언어 모델로, 성능과 효율성을 모두 갖춘 차세대 모델입니다. 이 모델은 GPT나 LLaMA와 같은 대규모 모델보다 더 작은 규모임에도 불구하고, 추론 속도와 메모리 사용 효율을 크게 향상시키며 뛰어난 성능을 발휘합니다. Mistral은 그룹화된 쿼리 어텐션(Grouped-Query Attention, GQA)과 슬라이딩 윈도우 어텐션(Sliding Window Attention, SWA)을 사용하여 더 빠르고 효율적인 추론을 지원합니다. 이 모델은 LLaMA 2의 13B 모델을 능가하며, 수학, 추론, 코드 생성 작업에서 34B 모델과도 경쟁할 수 있는 성능을 보입니다.
주요 내용
-
고성능과 효율성: Mistral 7B는 기존의 LLaMA 2 13B 모델보다 더 작은 규모로도 높은 성능을 발휘하며, 특히 코드 생성, 수학 문제 해결, 추론과 같은 작업에서 34B 모델과 경쟁할 수 있습니다. -
혁신적인 어텐션 메커니즘: 그룹 쿼리 어텐션(Grouped-Query Attention, GQA)과 슬라이딩 윈도우 어텐션(Sliding Window Attention, SWA)을 사용하여 추론 속도를 향상시키고 메모리 사용량을 줄였습니다. 이를 통해 더 큰 배치 크기와 빠른 추론 속도를 구현할 수 있으며, 특히 긴 시퀀스를 처리하는 데 탁월한 성능을 발휘합니다.-
그룹 쿼리 어텐션(GQA)
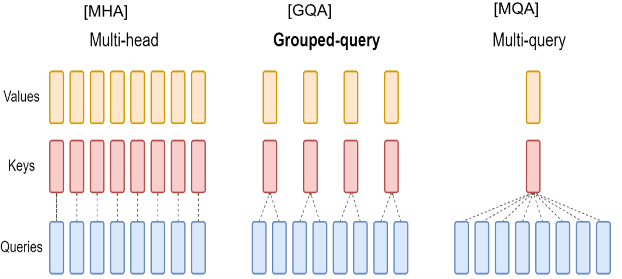
- GQA는 기존의 다중 쿼리 어텐션 방식에 비해 더 빠른 추론 속도를 제공하면서도 메모리 사용량을 줄여줍니다.
- 이로 인해 더 큰 배치 크기를 사용할 수 있으며, 특히 실시간 응용 프로그램에서 더 높은 처리량을 달성할 수 있습니다.
- GQA는 많은 계산 비용을 줄이면서도 모델의 성능에 영향을 미치지 않으므로 고효율 추론을 가능하게 합니다.
- GQA는 기존의 다중 쿼리 어텐션 방식에 비해 더 빠른 추론 속도를 제공하면서도 메모리 사용량을 줄여줍니다.
-
슬라이딩 윈도우 어텐션(SWA)
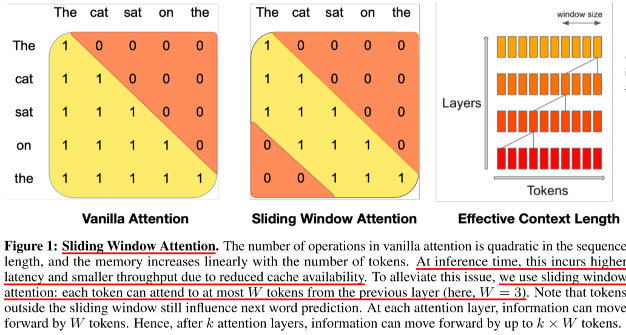
- SWA는 긴 시퀀스를 처리할 때 발생하는 계산 비용을 크게 줄여주는 방법입니다. 시퀀스 길이에 따라 선형적으로 증가하는 메모리 사용량을 줄이기 위해, SWA는 각 토큰이 특정 범위(W)의 토큰들만 참조하도록 제한합니다.
- 예를 들어, SWA는 16K 길이의 시퀀스에서 이 방법을 통해 두 배의 속도 향상을 얻을 수 있습니다.
- 이러한 방법은 긴 문장을 처리할 때 더욱 효율적이며, 메모리 캐시 사용량을 크게 줄여 더 긴 문장을 처리할 때에도 성능을 저하시키지 않습니다.
- SWA는 긴 시퀀스를 처리할 때 발생하는 계산 비용을 크게 줄여주는 방법입니다. 시퀀스 길이에 따라 선형적으로 증가하는 메모리 사용량을 줄이기 위해, SWA는 각 토큰이 특정 범위(W)의 토큰들만 참조하도록 제한합니다.
-
Rolling Buffer Cache
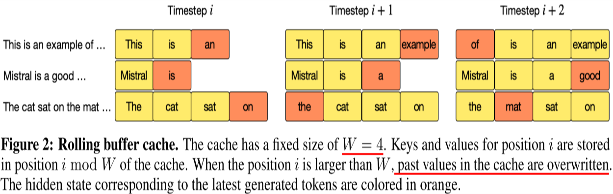
- Rolling Buffer Cache는 시퀀스 처리 시 캐시 크기를 고정된 크기(W)로 유지하여 메모리 사용을 줄이는 메커니즘입니다. 특히 긴 시퀀스의 경우, 메모리 사용량이 선형적으로 증가하는 문제를 해결하기 위해 도입되었습니다.
- 작동 방식: 캐시가 고정된 크기(W)를 초과할 경우, 새로운 데이터가 입력될 때마다 가장 오래된 데이터를 덮어씁니다. 즉, 새로운 키와 값을 저장할 때, (i mod W) 위치에 해당하는 캐시 슬롯에 덮어씌웁니다. 이 방식으로, 시퀀스 길이가 매우 길어지더라도 캐시 크기는 일정하게 유지됩니다.
- 효과: 이 방식은 긴 시퀀스에서도 메모리 사용량을 효율적으로 관리할 수 있게 해주며, 메모리 사용량을 8배까지 절감할 수 있습니다. 특히, Mistral 7B는 이 방식을 통해 긴 시퀀스에서도 성능 저하 없이 일관된 처리 속도를 유지할 수 있습니다.
- Rolling Buffer Cache는 시퀀스 처리 시 캐시 크기를 고정된 크기(W)로 유지하여 메모리 사용을 줄이는 메커니즘입니다. 특히 긴 시퀀스의 경우, 메모리 사용량이 선형적으로 증가하는 문제를 해결하기 위해 도입되었습니다.
-
Pre-fill and Chunking
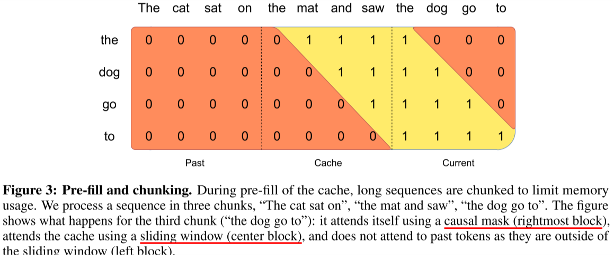
- Pre-fill and Chunking 기법은 주어진 프롬프트를 미리 처리하고, 긴 시퀀스를 작은 덩어리(chunk)로 나누어 효율적으로 처리하는 기법입니다. 프롬프트가 미리 제공된 상황에서는 프롬프트 데이터를 미리 캐시에 채워 넣을 수 있으며, 이를 통해 긴 시퀀스도 효과적으로 처리할 수 있습니다.
- 작동 방식: 프롬프트를 작은 chunk로 나누어 처리하고, 각 chunk가 슬라이딩 윈도우 어텐션에서 사용되는 window size와 동일한 크기로 설정됩니다. 이를 통해 각 chunk는 윈도우 크기 내에서 효율적으로 어텐션을 계산합니다. 이 과정에서 캐시와 chunk 간의 어텐션이 효율적으로 작동하며, 프롬프트의 길이에 상관없이 빠르게 추론할 수 있게 됩니다.
- 효과: Pre-fill and Chunking 기법을 통해 긴 시퀀스를 처리할 때 메모리 관리와 계산 성능을 동시에 개선할 수 있습니다. 또한, 이 방법은 Mistral 7B가 긴 프롬프트에서도 효율적으로 성능을 유지할 수 있게 도와줍니다.
-
기여 및 의의
- 작고 효율적인 모델: Mistral 7B는 상대적으로 작은 파라미터 수에도 불구하고, 대규모 언어 모델들과 경쟁할 수 있는 성능을 제공합니다. 이는 실시간 애플리케이션에서의 사용을 가능하게 하며, 연구자들이 효율적으로 접근할 수 있습니다.
- 오픈 소스 기여: Mistral 7B는 Apache 2.0 라이선스 하에 공개되어 연구자와 개발자들이 쉽게 접근할 수 있으며, 이를 기반으로 다양한 실시간 애플리케이션에서 사용할 수 있습니다.
- 다양한 벤치마크에서의 성능: 수학, 코드 생성, 추론 작업에서 기존의 LLaMA 모델을 능가하며, 여러 분야에서 활용될 수 있는 가능성을 입증했습니다.
(개인 추가)
17. Llama 3 : Herd of Models (2024, Meta AI)
💡 LLaMA 3는 Meta에서 LLaMA 2를 기반으로 확장된 버전으로, 여러 모델을 협력적으로 사용할 수 있는 'Herd of Models' 개념을 도입했습니다. LLaMA 3는 효율적인 자원 활용과 모델의 상호 보완적인 능력을 극대화하여 더 나은 성능을 추구합니다. 이를 통해 다양한 작업에서 더 높은 성능과 안정성을 확보할 수 있으며, 연구자와 개발자들이 더 다양한 자연어 처리 응용 프로그램에 적용할 수 있도록 설계되었습니다.
LLaMA 3는 Meta에서 개발한 최신 대규모 언어 모델로, 여러 언어 모델들을 'Herd of Models'이라는 개념 하에 협력적으로 사용하여 더 효율적이고 강력한 성능을 발휘하는 구조를 도입했습니다. LLaMA 3는 8B, 70B, 405B 파라미터 크기의 모델로 제공되며, 다국어 지원, 코드 생성, 추론, 도구 사용 등 다양한 작업에서 뛰어난 성능을 보여줍니다. 특히 LLaMA 3는 기존 모델들보다 더 큰 규모의 데이터와 더 효율적인 학습 기법을 통해 다양한 자연어 처리(NLP) 작업에서 최고 수준의 성능을 발휘합니다.
주요 내용
-
Herd of Models 개념: LLaMA 3는 여러 개의 모델을 협력적으로 사용하여 각각의 모델이 특정 작업에 더 나은 성능을 발휘할 수 있도록 설계되었습니다.
- 이를 통해 작업의 복잡성에 따라 여러 모델이 효율적으로 협력하여 성능을 극대화합니다.
-
모델의 크기 및 성능: LLaMA 3는 8B, 70B, 405B 파라미터 크기의 모델을 제공하며, 특히 405B 모델은 GPT-4와 경쟁할 수 있는 성능을 보여줍니다.
-
각 모델은 다국어 지원, 코드 생성, 복잡한 추론 문제 해결 등에서 최상의 성능을 발휘합니다.
-
Llama 3 모델은 표준 Transformer 아키텍처를 기반으로 설계되었습니다. 구체적으로, 다음과 같은 아키텍처적 변경 사항이 포함됩니다.
-
기본 아키텍처
- Llama 3는 이전 버전인 Llama 2와 유사한 Dense Transformer 구조를 사용합니다. 성능 개선은 주로 데이터 품질과 다양성의 향상, 그리고 학습 규모의 증가에 의해 이루어졌습니다.
-
Grouped Query Attention (GQA)
- Grouped Query Attention (GQA): 8개의 키-값 헤드를 사용하는 이 기법을 적용하여 추론 속도를 개선하고, 디코딩 과정에서 필요한 키-값 캐시의 크기를 줄였습니다.
-
Attention Mask
- 문서 내에서만 self-attention을 허용하고, 다른 문서 간의 self-attention은 방지하는 attention mask를 사용하여 긴 문서를 처리할 때 성능을 향상시켰습니다.
-
어휘 크기와 RoPE 기반 위치 인코딩
- 128,000개의 토큰을 포함하는 어휘를 사용하며, 이 중 28,000개의 추가 토큰을 통해 비영어권 언어를 더욱 잘 지원합니다.
- RoPE (Rotary Position Embeddings) 기반의 위치 인코딩을 사용해 긴 컨텍스트를 더 잘 처리할 수 있도록 지원합니다.
-
모델 규모
-
Llama 3 모델은 8B, 70B, 405B 파라미터를 가진 다양한 크기로 제공되며, 그 중에서 405B 파라미터 모델이 플래그십 모델입니다.
-
이 모델은 16,384의 모델 차원을 가지고, 128개의 attention 헤드를 사용합니다. 학습 시 사용되는 최대 학습률은 8 × 10⁻⁵입니다.
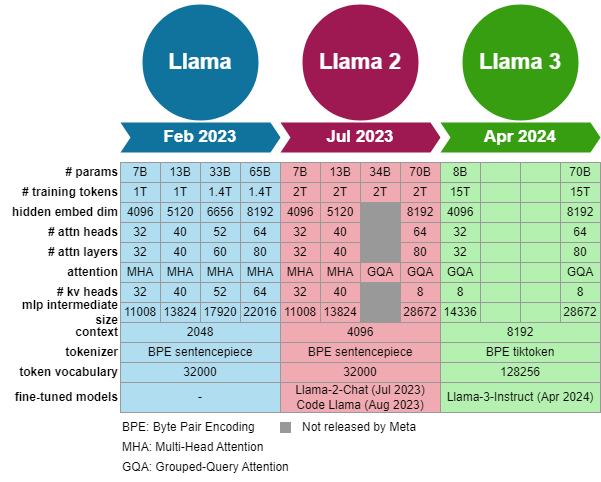
모델 크기 레이어 수 모델 차원 FFN 차원 Attention 헤드 수 키/값 헤드 수 8B 32 4,096 14,336 32 8 70B 80 8,192 28,672 64 8 405B 126 16,384 53,248 128 8
-
-
-
안전성 및 효율성: LLaMA 3는 사용자의 피드백을 반영한 미세 조정을 통해 안전성을 강화하였으며, 특히 입력과 출력의 안전성을 관리하는 Llama Guard 3 모델을 제공합니다.
- 또한, 모델은 메모리 효율적이며 추론 속도가 빠릅니다.
-
기여 및 의의
-
고성능 다기능 모델: LLaMA 3는 다양한 작업에서 매우 뛰어난 성능을 발휘하며, 특히 여러 언어를 지원하는 능력과 복잡한 추론 및 코드 생성에서의 성과가 두드러집니다.
-
연구자 및 개발자 지원: LLaMA 3는 연구자들이 쉽게 접근할 수 있도록 공개되었으며, 다양한 응용 프로그램에서 사용될 수 있도록 최적화되었습니다. 이를 통해 AI 연구 커뮤니티에서의 협력을 촉진하고 발전을 가속화할 수 있습니다.
-
멀티모달 기능 통합: LLaMA 3는 텍스트뿐만 아니라 이미지, 비디오, 음성 인식 기능을 통합하여 멀티모달 작업에서도 높은 성능을 보일 수 있도록 개발되었습니다.
출처 : https://devopedia.org/llama-llm
📚 LLaMA2 vs LLaMA3
- 데이터의 양과 질 개선 : LLaMA 3는 약 15조 개의 다국어 토큰으로 사전 학습을 진행했으며, 이는 LLaMA 2의 1.8조 개 토큰과 비교할 때 거의 8배에 달하는 양입니다. 더 많은 데이터를 사용함으로써, LLaMA 3는 더 많은 언어와 다양한 문맥에서 학습할 수 있게 되었습니다.
- 또한, 데이터의 질에 대한 개선도 있었습니다. LLaMA 3는 학습 데이터의 전처리 및 필터링 절차가 더 엄격하게 이루어졌습니다. 예를 들어, 중복 제거, 저품질 데이터 제거, 개인 식별 정보(PII) 제거 등의 과정이 강화되어 더 청결하고 신뢰성 있는 데이터로 학습이 이루어졌습니다. 이러한 개선은 LLaMA 2에 비해 더 안정적이고 정확한 성능을 제공하는 데 중요한 역할을 했습니다.
- 규모의 확장: LLaMA 3의 가장 큰 차이점 중 하나는 모델의 규모입니다. LLaMA 2의 최대 모델은 70억 개의 파라미터를 가지고 있었으나, LLaMA 3는 4050억 개의 파라미터를 가진 플래그십 모델을 포함하고 있습니다. 이는 LLaMA 2와 비교했을 때 약 50배 더 많은 연산을 사용하여 학습된 것입니다.
- LLaMA 3는 약 15.6조 개의 텍스트 토큰을 처리하는 동안, 3.8×10²⁵ FLOPs에 해당하는 엄청난 연산 자원을 사용하여 학습되었습니다. 이는 기존 LLaMA 2보다 훨씬 많은 연산 자원을 활용한 것으로, 대규모 데이터를 빠르게 처리하고 더 복잡한 패턴을 학습할 수 있게 했습니다.
- 복잡성 관리: Dense Transformer 아키텍처는 LLaMA 2와 LLaMA 3 모두에서 사용되고 있지만, LLaMA 3는 안정성과 성능을 높이기 위한 여러 가지 개선을 도입했습니다.
- Grouped Query Attention (GQA): LLaMA 2에서도 GQA를 사용해 왔지만, LLaMA 3에서는 8개의 키-값 헤드를 사용하여 더 효율적인 메모리 관리와 추론 속도 향상을 도모했습니다. 이로 인해, 더 많은 파라미터와 긴 컨텍스트 창을 사용하더라도, 모델의 효율성이 크게 향상되었습니다.
- Attention Mask: LLaMA 3는 같은 시퀀스 내에서 문서 간의 self-attention을 차단하는 attention mask를 사용합니다. 이 기법은 긴 문서에서 불필요한 상호 참조를 방지해 모델의 학습 효율성을 높이고, 긴 시퀀스를 더 효과적으로 처리할 수 있도록 도와줍니다.
- 어휘 크기와 RoPE 기반 위치 인코딩의 개선: LLaMA 3는 128,000개의 토큰을 지원하는 더 큰 어휘를 도입했습니다. 이 중 28,000개의 추가 토큰은 비영어권 언어를 더 잘 지원하기 위한 것입니다. 이는 다양한 언어에서 더 나은 성능을 발휘할 수 있도록 도와줍니다.
- RoPE (Rotary Position Embeddings)는 위치 인코딩 방식 중 하나로, LLaMA 3에서는 500,000이라는 더 큰 기본 주파수 하이퍼파라미터를 설정하여 긴 시퀀스를 처리할 수 있게 했습니다. 이로 인해 LLaMA 3는 최대 128K 토큰의 긴 컨텍스트를 지원하며, 더 긴 대화나 문맥을 유지하면서도 복잡한 문제를 해결할 수 있습니다.
출처 : https://devopedia.org/llama-llm
위 논문들은 자연어 처리 분야의 발전을 이끈 주요 연구들이며, 각 논문은 NLP의 다양한 측면을 혁신적으로 개선했습니다. 이러한 논문들을 통해 NLP 연구의 흐름을 더 깊이 이해하고, 최신 기술을 응용할 수 있습니다.

시간을 들여서 정리한만큼 많은 분들께 도움이 되었으면 좋겠습니다 😎
