
2017년, "Attention is All You Need"라는 논문과 함께 등장한 트랜스포머(Transformer)는 AI 모델의 혁신적인 변화를 이끌었습니다. 현재, 대형 언어 모델(LLM)과 생성 AI는 언어, 비디오, 이미지 등의 데이터 처리에서 압도적인 성능을 발휘하며 우리 삶의 다양한 영역에서 활용되고 있습니다.

그러나 트랜스포머 기반 모델은 높은 연산 복잡도, 막대한 자원 소비, 긴 시퀀스 처리의 한계 등 본질적인 제약을 가지고 있습니다.
이러한 문제를 해결하기 위해 많은 대안적인 아키텍처가 제안되었습니다. 이러한 기술은 효율성을 극대화하면서도 성능을 유지하거나 향상시키는 것을 목표로 하며, AI의 차세대 기술을 이끌어갈 잠재력을 가지고 있습니다. 최근 Mixture of Experts(MoE), Mamba, Mamba-2, Jamba-2, RetNet 등 많은 연구들이 진행되고 있습니다.
저도 이러한 연구들에 많은 관심을 가지고 있습니다만... 시간이 없어서 현재 Mamba만 깊게 파고, 다른 것들은 제대로 살펴보고 있지 못하고 있네요.. ㅠㅠ 😂

감사하게도 제가 애청하는 Youtube 크리에이터 안될공학님께서 제가 관심있는 주제를 이번에 다뤄주셔서 이를 베이스로 한번 트렌드를 정리해보는 글을 작성해보게 되었습니다.

트랜스포머를 넘어 MoE와 SSM까지, 미래 AI의 방향은? | AGI 구현 위한 요구 컴퓨팅 량 너무 높아 - 안될공학
이 글에서는 안될공학님께서 다뤄주신 서사에 따라서 이러한 혁신적인 모델들을 통합적으로 살펴보며, 트렌스포머 이후의 미래 AI 기술의 발전 방향을 탐구합니다.
1. 트랜스포머: 혁신과 한계
트랜스포머의 핵심: Attention 메커니즘
트랜스포머는 어텐션(Attention) 메커니즘을 기반으로 데이터를 처리하며, 텍스트, 음성, 비디오 등 다양한 데이터 유형에서 놀라운 성능을 보여주었습니다.
- 모든 단어의 관계를 계산해 문맥을 파악.
- 멀티헤드 어텐션(Multi-head Attention)을 통해 병렬적으로 단어 간 관계를 계산.
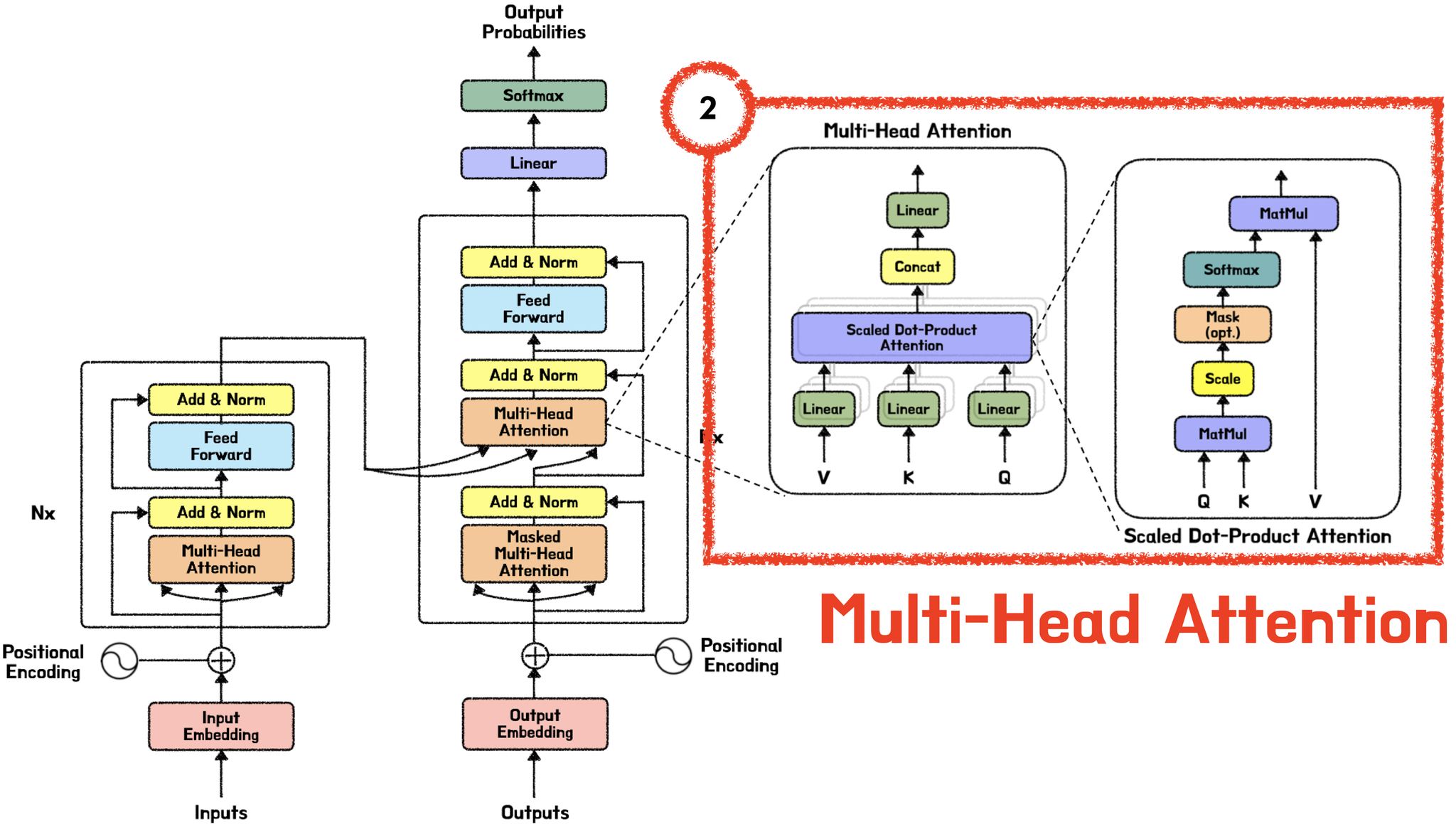
출처 : https://www.blossominkyung.com/deeplearning/transformer-mha
주요 한계
- 연산 복잡도: 모든 단어 간의 관계를 계산해야 하기 때문에 의 연산량을 요구하며, 데이터 길이가 길어질수록 계산 부담이 기하급수적으로 증가합니다.
- 자원 소모: 대규모 GPU 메모리와 연산 자원이 필요해 높은 전력 소모와 비용이 뒤따릅니다.
- 장거리 의존성(Long-range Dependency): 초기 입력 정보와 뒷부분 정보를 연결짓는 데 한계를 보이며, 긴 문맥을 처리하는 데 비효율적입니다.
2. Mixture of Experts(MoE): Sparse 연산으로 효율성 향상
MoE의 개념과 작동 원리
MoE(Mixture of Experts)는 조건부 연산(Conditional Computation)을 통해 필요한 경우에만 특정 전문가 네트워크(Experts)를 활성화하는 방식으로 작동합니다.
- 트랜스포머와 비교하여 모델의 용량을 크게 늘리면서도 연산 비용은 줄임.
- 각 전문가 네트워크는 고유한 파라미터를 가지고, 게이팅 네트워크(Gating Network)가 활성화 여부를 결정.
💌 추천 Reference:
- MoE에 대해서 더 자세하게 알고 싶으신 분들은 아래 링크에 들어가서 읽어보시길 바랍니다:
https://huggingface.co/blog/moe
MoE 사례: Switch Transformer
링크: https://arxiv.org/pdf/2101.03961제목: Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
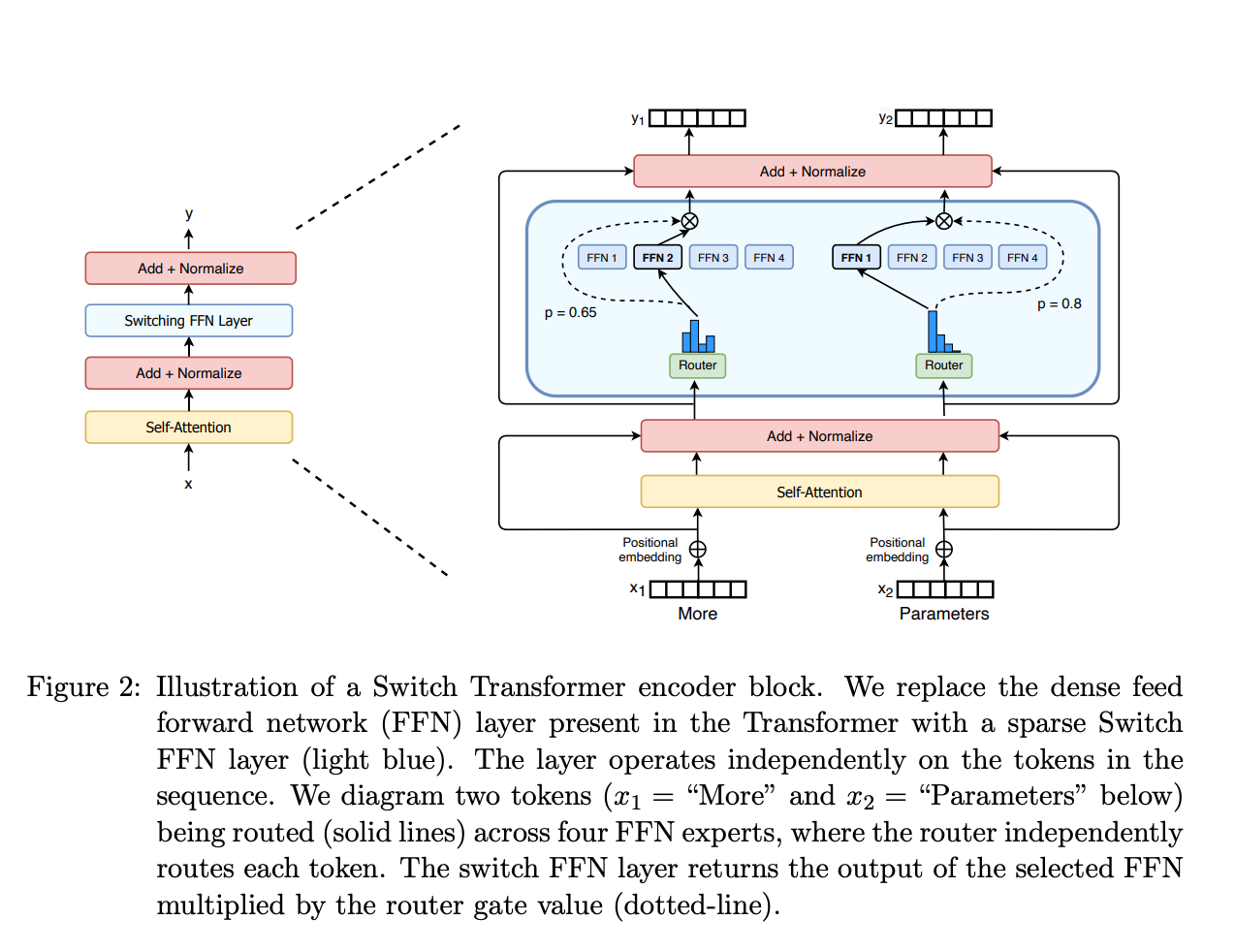
출처: MoE layer from the Switch Transformers paper
구글의 Switch Transformer는 MoE의 대표 사례로, 다음과 같은 특징을 보입니다:
- 기존 GPT-3 대비 학습 시간을 17%로 단축.
- 병목 현상을 방지하기 위해 토큰의 입력을 균형 있게 분배.
MoE의 장점
1. 효율성: 모델의 용량을 확장하면서도 계산 비용은 최소화.
2. 특화된 학습: 각 전문가가 특정 데이터에 최적화되어 높은 성능을 발휘.
3. 자원 절약: 필요한 전문가만 활성화하여 불필요한 계산을 방지.
3. State Space Models(SSM): 긴 시퀀스 처리의 혁신
SSM의 개념과 작동 원리
SSM(State Space Models)은 시퀀스 데이터를 시간적으로 모델링하여, 현재 상태와 과거 상태를 효율적으로 연결합니다.
- 상태 공간(State Space)을 통해 현재와 과거 정보를 연결.
- 트랜스포머의 복잡도를 해결하고 메모리 사용량을 감소.
- 모든 토큰 간 관계를 계산하지 않아도 됨.
- 시퀀스 데이터(텍스트, 음성 등)의 순서 정보를 자연스럽게 처리.
SSM 사례: Mamba
-
제목: Mamba: Linear-Time Sequence Modeling with Selective State Spaces -
SSM(State Space Models) 기반으로 긴 문맥 처리 능력과 빠른 학습 속도를 제공.
-
불필요한 상태 정보 업데이트를 줄여 효율성을 향상.
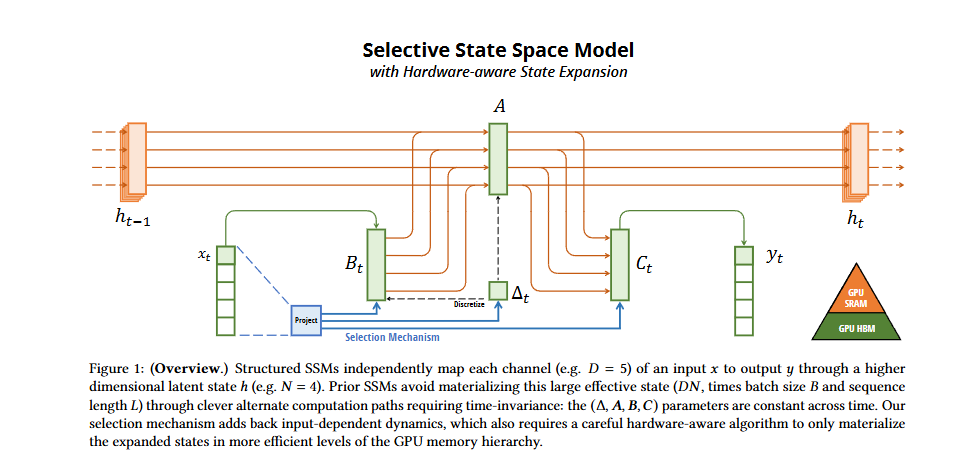
출처: SSM Model from the Mamba paper
Mamba 특징
-
선택 메커니즘 추가
- 기존 SSM 모델이 입력에 따라 특정 정보를 선택하거나 무시하는 능력이 부족한 점을 보완하기 위해, 입력 의존적 파라미터를 도입하여 선택적 정보 처리가 가능하게 설계.
-
효율적 하드웨어 구현
- 새로운 알고리즘을 통해 GPU 메모리 계층에서 효율적으로 작동하며, 기존 SSM 대비 최대 3배 빠른 속도를 제공.
-
단순화된 아키텍처
- Mamba는 Attention이나 MLP 블록 없이도 강력한 성능을 발휘하도록 설계된 간단한 구조 채용.
SSM + MoE + Transformer 사례: Jamba
-
제목: Jamba: A Hybrid Transformer-Mamba Language Model -
트랜스포머 레이어와 Mamba 레이어를 번갈아 배치한 하이브리드 모델.
-
긴 문맥에서 트랜스포머의 강점과 SSM의 효율성을 결합.
-
대규모 파라미터를 효율적으로 처리하며 긴 입력에서도 높은 성능을 발휘.
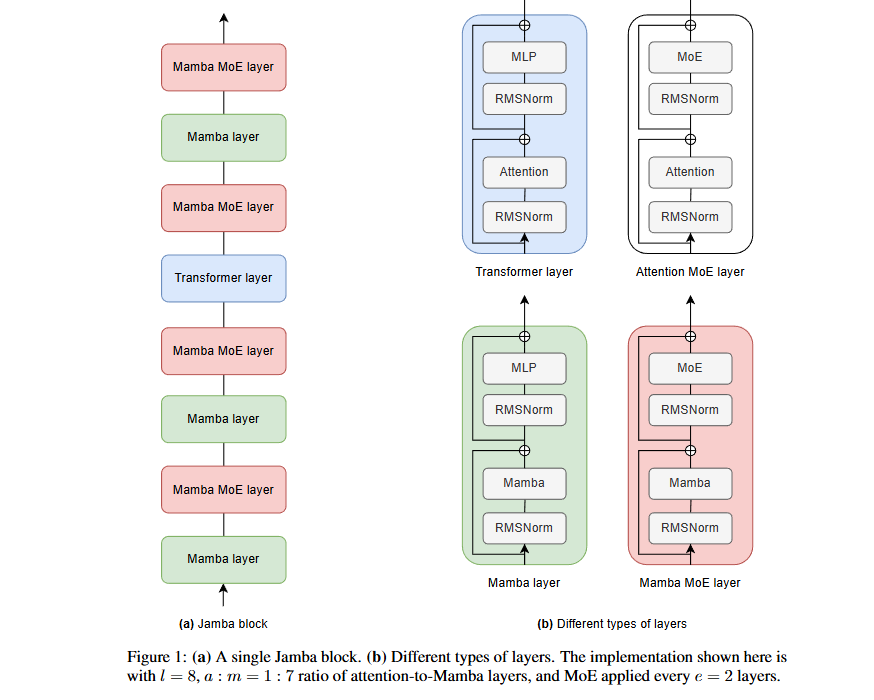
출처: Jamba block from the Jamba paper
Jamba 특징
-
Transformer와 Mamba의 하이브리드화
- Transformer는 Attention 메커니즘을 통해 정확한 문맥 표현 가능.
- Mamba는 긴 문맥을 처리하는 데 적합하며, Transformer의 높은 계산 비용 문제를 해결.
-
긴 문맥 지원
- 기존 Transformer 기반 모델이 문맥 길이에서 제약이 있는 반면, Jamba는 256K 토큰 이상을 처리 가능.
-
높은 처리량과 메모리 효율
- 긴 문맥에서도 작은 메모리 사용량과 높은 처리 속도를 유지.
😂 (쉬어가며) 유튜브 영상의 비유에서 재밌게 느꼇던 점
- 안될공학님의 비유법에 항상 감탄하곤 하는데, 오늘 비유는 더더욱 감탄에 박수치고 갑니다 ㅋㅋㅋㅋ 🙌😁
- 각각 트랜스포머와 SSM을 "나는 솔로"와 "환승 연애" TV 프로그램에 비유하는 데... 크흐.. 어떻게 그런 생각을 하는 것인지...
"트랜스포머" → "나는 솔로":
- "나는 솔로"의 주제처럼, 트랜스포머는 모든 단어가 서로 개별적으로 대화(연산)하며 독립적으로 관계를 형성합니다.
- 이는 각 단어가 다른 단어들과 직접 연결되며 모든 관계를 계산한다는 것을 나타냅니다.
"SSM" → "환승연애":
- "환승연애"는 과거의 관계(상태)를 이어받아 새로운 관계를 형성해 나가는 과정을 묘사합니다.
- SSM은 과거 정보를 유지하면서도 현재와 자연스럽게 연결하며 데이터를 처리하는데, 이는 시간적 순서와 상태 변화를 자연스럽게 반영합니다.

4. 기타 아키텍쳐 및 연구
RetNet: Retentive Network
링크: https://arxiv.org/pdf/2307.08621제목: Retentive Network (RetNet): A Successor to Transformer for Large Language Models
RetNet은 기존 Transformer의 단점을 해결하기 위해 설계된 새로운 언어 모델 아키텍처입니다. 이 모델은 병렬 훈련, 저비용 추론, 성능 확장을 동시에 달성하여 대규모 언어 모델의 새로운 표준이 될 가능성을 제시합니다.
RetNet의 배경
- Transformer는 언어 모델의 표준 아키텍처로 자리 잡았으나, 추론 효율성 및 긴 시퀀스 처리에서 한계가 존재합니다.
- RetNet은 Transformer의 성능을 유지하면서도 O(1) 복잡도로 효율적인 추론 및 긴 시퀀스 처리 효율성을 제공합니다.
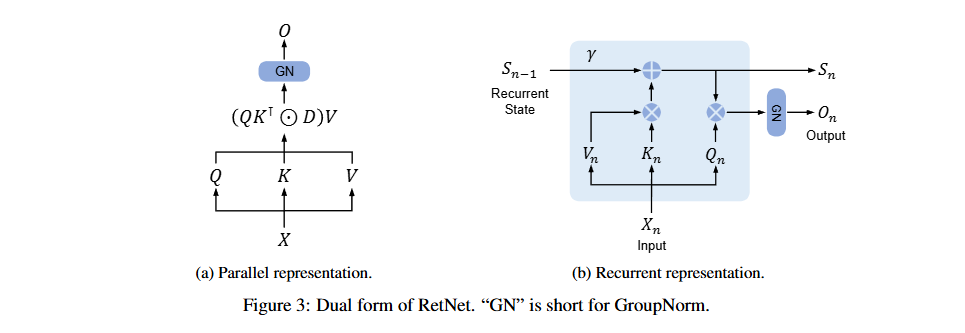
출처: Dual form of RetNet from the RetNet paper
RetNet의 주요 특징
-
Retention 메커니즘
- 시퀀스를 병렬적으로 학습하고, 추론 중에는 순차적으로 정보를 처리하는 하이브리드 방식을 채택.
- 병렬 표현: Transformer와 유사한 방식으로 학습 병렬화 지원.
- 순차 표현: 추론 시 효율성을 위해 순차적 상태 갱신을 사용.
- 청크 병렬 표현: 긴 시퀀스에서 청크 단위 병렬화를 통해 메모리 사용량 감소.
-
Multi-Scale Retention (MSR)
- 각 헤드(head)마다 서로 다른 감쇠율(Decay Rate)을 적용해 다양한 스케일로 시퀀스를 모델링.
- Swish 활성화 함수와 Group Normalization을 사용해 비선형성을 강화하고 학습 안정성을 개선.
-
학습 및 추론
- 학습: 병렬 표현 및 청크 병렬 표현을 활용해 긴 시퀀스 학습 속도 향상.
- 추론: O(1) 복잡도로 효율적이며, 메모리 사용량과 대기 시간을 크게 감소.
V-JEPA: Learning Visual Representations from Video
링크: https://arxiv.org/pdf/2404.08471제목: Revisiting Feature Prediction for Learning Visual Representations from Video
V-JEPA는 비디오 데이터를 활용한 특징 예측(feature prediction)을 기반으로 한 비지도 학습 접근법을 탐구합니다. 이를 위해 V-JEPA라는 비디오 학습 모델 아키텍처를 제안하며, 이는 픽셀 복원(pixel reconstruction) 대신 특징 예측을 사용하여 비디오와 이미지 작업에서 효율적이고 강력한 성능을 보여줍니다.
V-JEPA의 배경
- 기존 비디오 모델은 픽셀 수준의 복원이나 이미지 사전 학습 인코더를 사용하는데, 이는 높은 계산 비용과 데이터 종속성을 초래합니다.
- V-JEPA는 특징 예측을 단독 목표로 사용하여 더 간단하고 효율적인 비지도 학습 방법을 제공합니다.
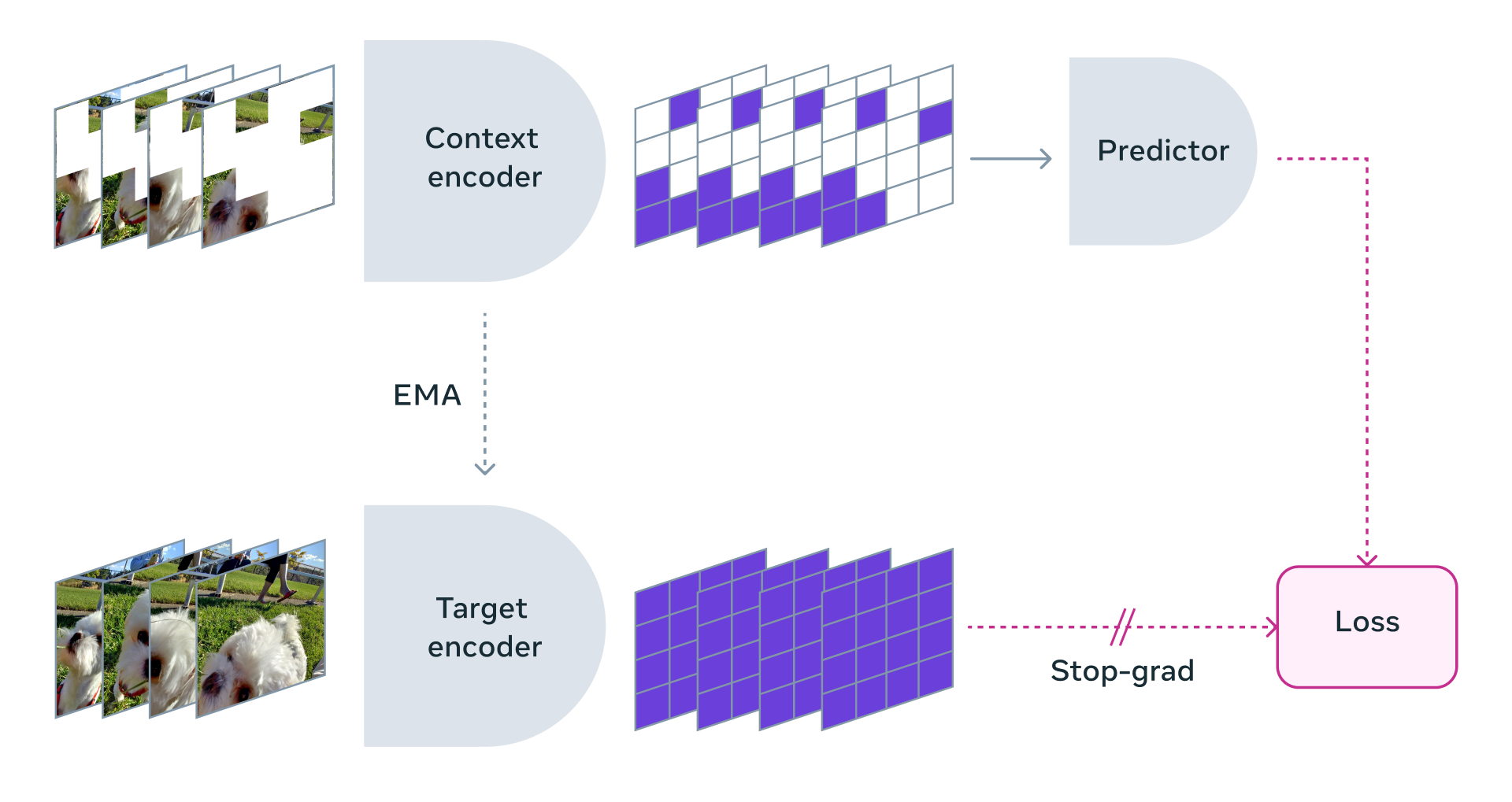
V-JEPA의 주요 특징
-
특징 예측 기반 학습
- 픽셀 복원이 아닌 특징 예측을 통해 더 간결하고 효율적인 학습.
-
Self-supervised learning
- 레이블 없는 데이터에서 비지도 학습 수행.
-
멀티블록 마스킹(Multi-block masking)
- 공간적 및 시간적 연속 블록을 랜덤으로 제거하여 학습 강화를 위한 어려운 예측 작업을 생성.
-
유연한 네트워크 설계
- 비디오 전용 아키텍처로 Vision Transformer(ViT)를 활용.
5. 새로운 기술의 통합과 향후 전망
-
효율성:
MoE와 SSM은 연산량 감소와 자원 효율성을, RetNet과 V-JEPA는 긴 시퀀스 및 비디오 데이터를 처리하는 데 강점을 보입니다. -
범용성:
이 기술들은 언어, 이미지, 비디오 등 다양한 도메인에서 활용 가능하며, 멀티모달 AI로의 확장 가능성을 보여줍니다.
트랜스포머는 현대 AI 기술의 상징적인 모델이지만, 연산 복잡도와 자원 소비라는 한계로 인해 대체 기술이 필요해졌습니다. MoE, SSM, RetNet, V-JEPA와 같은 혁신적인 아키텍처는 이러한 문제를 해결하며, 효율성과 성능 모두를 강화하고 있습니다.
오늘은 개략적으로 해당 모델들에 대해서 살펴보았는데요! 이 모델들은 차세대 AI 기술의 기반을 형성하며, 언어, 비디오, 이미지 등 다양한 데이터 처리에서 새로운 표준이 될 것으로 기대됩니다.
읽어주셔서 감사합니다🙇♂️
