VGG16 모델 구현 후, batch size=512, epoch=100으로 학습 진행
학습되는 과정에서 각 epoch 마다 val_loss와 val_accuracy가 출력된다. val_loss와 val_accuracy는 모델의 성능을 평가하고 모니터링하는 데 도움이 되는 중요한 지표 중 하나이다.
val_loss는 모델을 학습하는 동안 검증 데이터 세트(validation dataset)에서 발생한 손실(loss) 값을 나타내는 지표이다.
손실은 모델의 예측과 실제 타겟(목표) 간의 차이를 측정하는 지표로, 낮은 손실은 모델이 예측과 실제 값 사이의 차이를 최소화하고 높은 정확도를 달성하는 것을 나타낸다. val_loss는 검증 데이터에 대한 손실을 나타내며, 모델이 검증 데이터에서 얼마나 좋은 성과를 내고 있는지를 평가하는 데 사용된다.
일반적으로 val_loss가 낮을수록 모델의 성능이 좋다고 할 수 있다. 손실은 모델이 얼마나 정확하게 예측하는지를 측정하며, 최소화되어야 하는 값이다. 따라서 낮은 val_loss는 모델이 검증 데이터에서 예측을 더 정확하게 수행하고 있다는 것을 나타낸다.
val_accuracy는 모델을 학습하는 동안 검증 데이터 세트 (validation dataset)에서 모델의 정확도(accuracy)를 나타내는 지표이다.
학습 과정에서 데이터를 사용하여 모델을 학습하고, 학습 데이터에 대한 정확도를 계산하며, 또한 검증 데이터를 사용하여 모델을 평가하고 검증 데이터에 대한 정확도를 계산한다. val_accuracy는 검증 데이터에 대한 정확도를 나타내며, 이는 모델이 새로운 데이터에 얼마나 정확하게 예측하는지를 측정하는 중요한 지표 중 하나이다.
일반적으로 val_accuracy가 높을수록 모델의 성능이 좋다고 할 수 있다. 검증 데이터는 모델이 학습되지 않은 데이터로, 모델의 일반화(generalization) 능력을 평가하는 데 사용된다. 따라서 높은 val_accuracy는 모델이 새로운 데이터에도 잘 일반화되고 정확하게 예측한다는 것을 나타낸다.
학습을 진행하는 과정에서 val_loss값의 변동은 자연스러운 현상이다.
-> val_loss값의 변동이 일어나는 이유
1) 학습 데이터와 검증 데이터의 차이: 학습 데이터와 검증 데이터는 서로 다를 수 있다. 모델은 학습 데이터로 학습하고 검증 데이터로 평가되며, 두 데이터 세트 사이에는 차이가 있을 수 있다. 이러한 차이 때문에 val_loss는 에폭 간에 변동할 수 있다.
2) 데이터 셔플링: 학습 데이터는 일반적으로 에폭마다 셔플링된다. 이로 인해 학습 데이터의 배치가 에폭 간에 변경되므로 val_loss 값이 변할 수 있다.
3) 학습률 및 옵티마이저 설정: 모델의 학습률 및 옵티마이저 설정은 val_loss에 영향을 미칠 수 있다. 이러한 하이퍼파라미터를 조정하면 val_loss의 변동을 줄일 수 있을 수 있다.
4) 과적합(Overfitting): 에폭이 증가함에 따라 모델이 학습 데이터에 더 적합하게 되면, val_loss가 초기에 감소하다가 다시 증가할 수 있다. 이것은 모델이 학습 데이터에 너무 맞춰져 검증 데이터에서의 일반화 능력이 감소하는 과적합 상황을 나타낼 수 있다.
vgg19 모델을 이용한 학습 결과
test dataset 에서의 모델 평가 결과 : loss: 1.1373 - accuracy: 0.8821
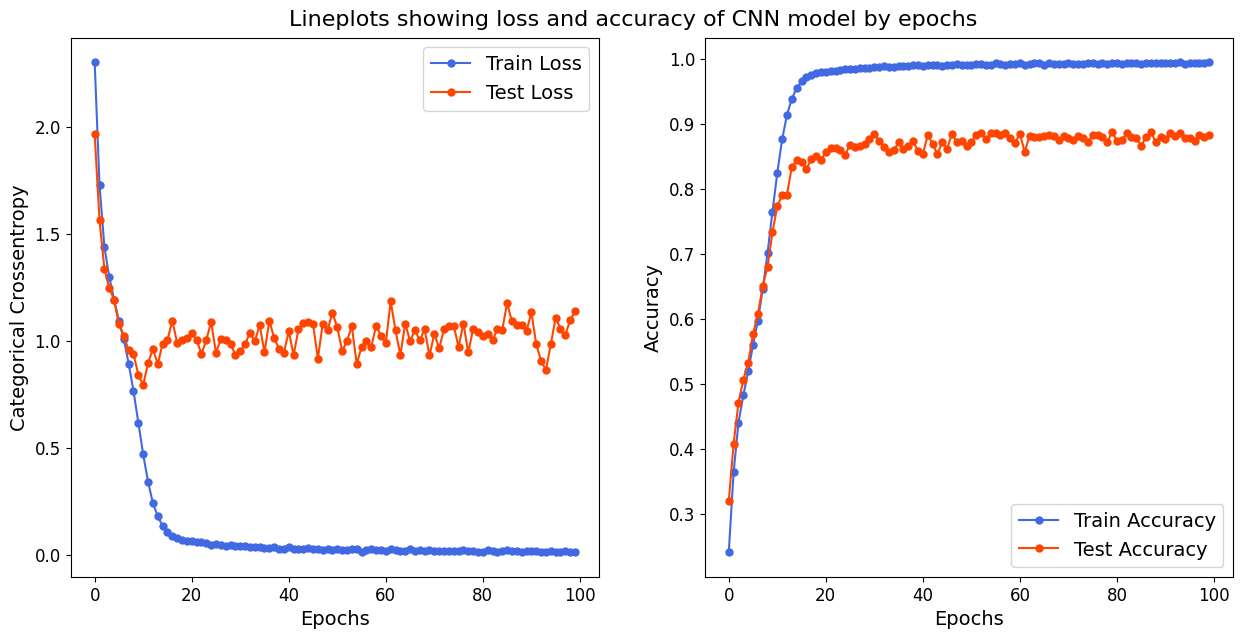

에폭 30이후부터는 거의 변화 없이 일정한 양상을 보인다.
검증 데이터의 손실도가 1.0 근처로 나타나고 약간의 변동성이 보이긴 하지만
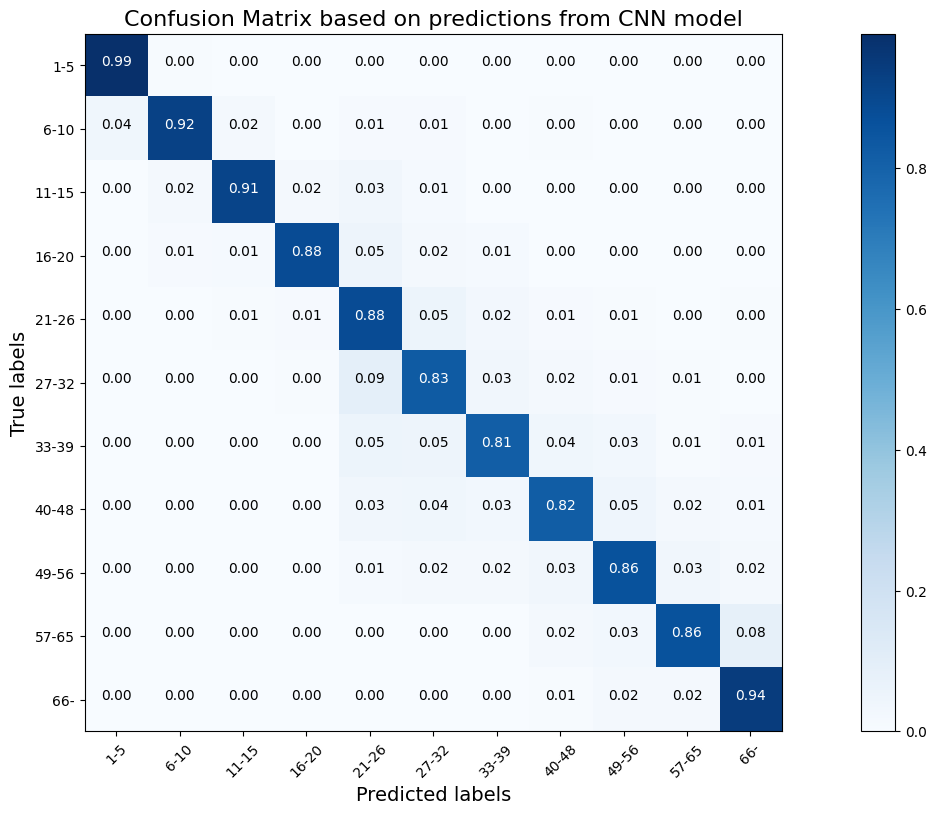
혼동 행렬도 비교해보면 에폭 30일때보다 정확도가 증가한 것을 확인할 수 있다.
해당 모델을 이용하여 웹 캠을 돌려본 결과 이전에 발생했던 나이 예측의 불안전성이 조금은 해소되었음 또한 확인할 수 있었다.
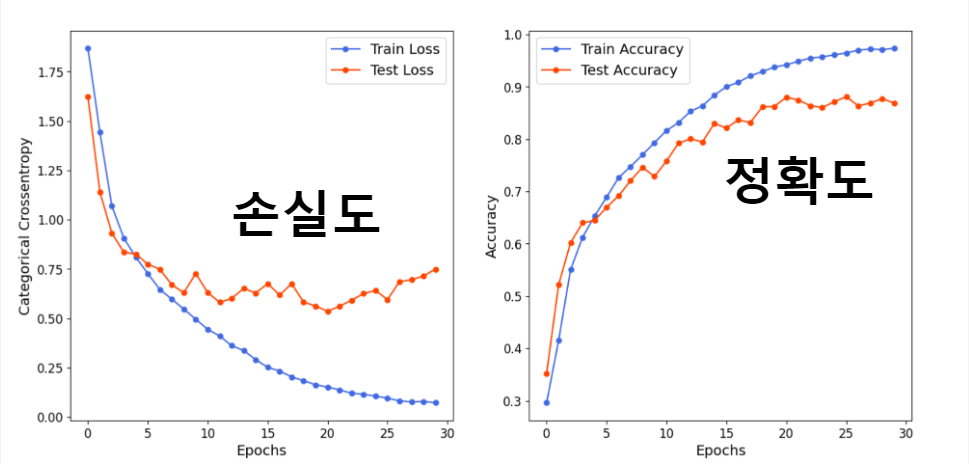
vgg19 모델을 이용한 학습 결과(에폭30)
Resnet 모델을 이용한 학습 결과(에폭30)
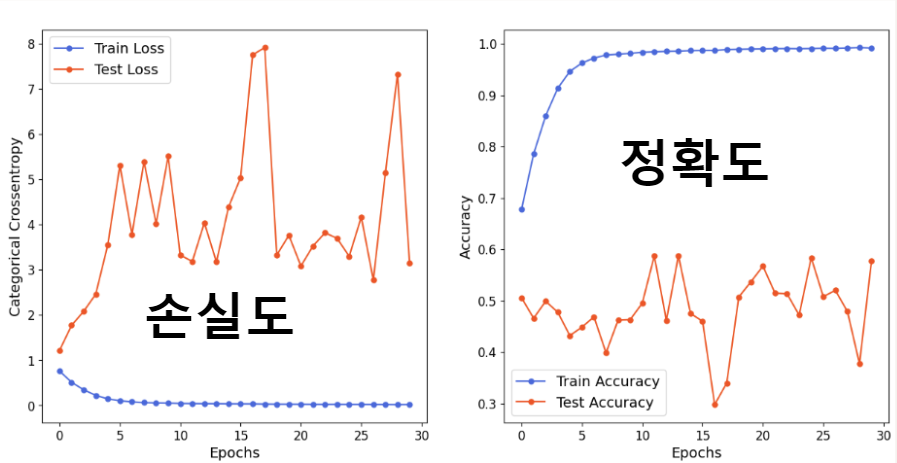
->ResNet 모델은 과적합이 계속 발생하였다. 이거에 대한 연구는 병행해서 다시 진행할 계획
우선, 프로젝트 기간과 우리가 사용할 수 있는 colab 의 컴퓨팅 단위 개수의 제한으로 인해 일단 가장 성능이 좋게 나온 VGG16을 최종 모델로 선정하고 실제 테스트에 들어갔다.
그러나,

위의 두 결과처럼 안경 착용 여부가 연령 출력에 영향을 미친다는 것을 발견하였다.
이를 해결하기 위해 기존 데이터셋을 확인해 보았다.
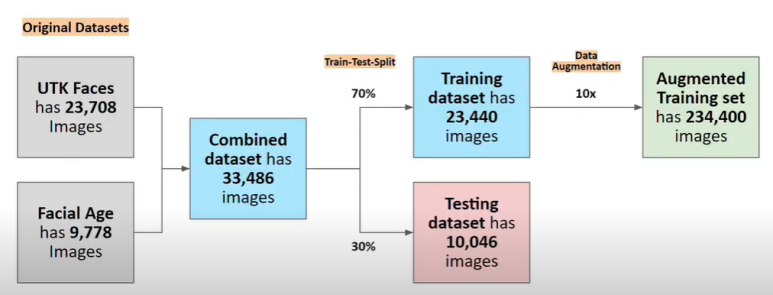
우리는 연령 분석을 할 때 UTK Faces 2만3천장과 Facial Age 약 1만장의 사진을 합쳐서 이용하였다.
따라서 합쳐진 Combined dataset에 안경 쓴 사람이 혹시 노년층에 많이 분포되어있는지 확인하였다.

실제 확인한 결과, 젊은 사람들 중에는 40명에 한 명 꼴로 안경 쓴 사람이 존재하며 매우 적었고 중년층 이후에는 안경 쓴 사람의 사진이 많음을 확인하였다.
->이거에 대한 해결책 다음 포스트.
