검증 데이터는 모델의 훈련 중에 사용되지 않는다. 하지만 모델의 일반화 능력을 평가하고 성능을 모니터링하기 위해 사용되는 경우가 존재한다.
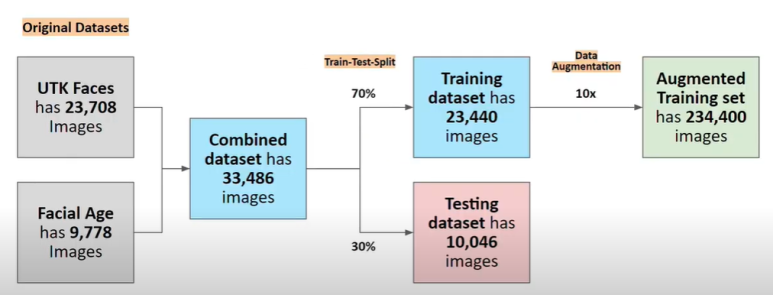
우리는 약 2만 3천장의 UTK Faces데이터셋과 약 1만 장의 Facial Age 데이터셋을 결합하여 3만 3천장의 원본 데이터셋을 이용하기로 하였다.
여기서 70프로는 훈련용으로, 30프로는 검증용으로 임의로 분리하였다.
그 후, 전처리 과정을 적용하여 2만 3천장의 사진을 10배 증강하여 23만 장의 사진을 준비하였다.
따라서, 우리는 23만장의 훈련(train) 데이터와 1만장의 검증(val) 데이터를 가지고 모델을 학습시킨다.(검증 데이터는 훈련 데이터와 전혀 다른 데이터셋이어야 한다. )
다음이 1만장의 검증 데이터셋의 일부분이다.

근데, 해당 데이터들로 모델 학습했더니 출력 결과가 매우 이상했다.
그래서, 데이터 분포들 확인해 보았더니 다음과 같다.
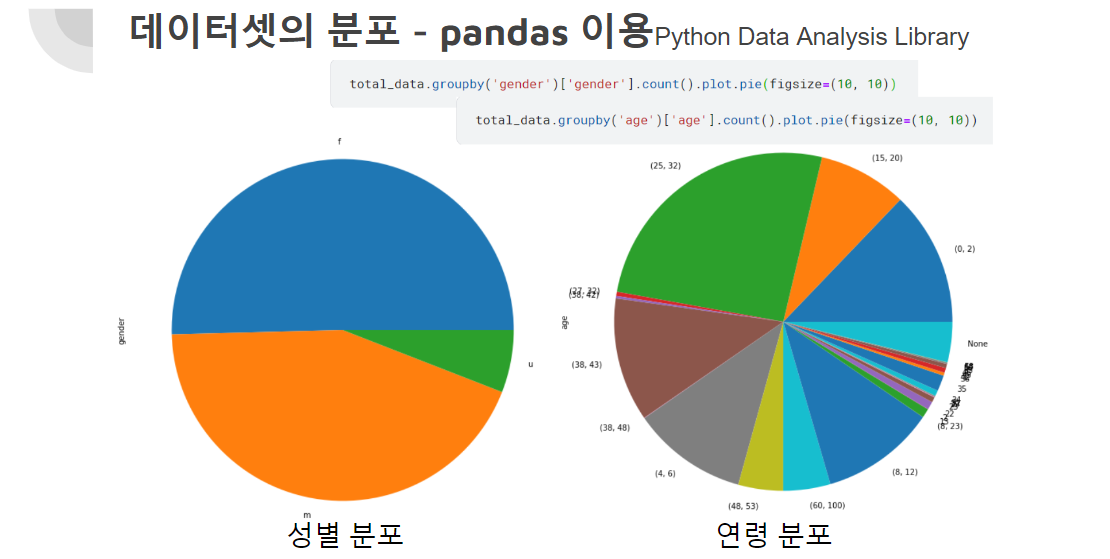
성별은 그래도 분포가 나름 고른 편인데, 연령은 그렇지 않다.
특정 연령의 분포가 불규칙적으로 많다. -> 이러한 특징이 모델의 결과에 예측을 끼쳤을 것이라고 유추해보자.
이를 바탕으로 연령별 분포를 고르게 하기 위해 시도할 수 있는 점
->1) 연령별 데이터 수를 동일하게 만든다.
->2) 연령 범주를 다시 나눈다.
1번의 방법을 시도하기에는 조금 어려운 점이 있을 것 같다. 가능하긴 하지만 데이터가 워낙 많기 때문에, 분류해내는 데 시간이 조금 더 걸릴 것.
그래서 우선은 2번의 방법으로 딥러닝 학습을 위한 클래스 범주를 고르게 나누기로 결정하고 시도해보았다.
