
거품 정렬 알고리즘
# 거품 정렬
# 입력: 리스트 a
# 출력: 없음(입력으로 주어진 a가 정렬됨)
def bubble_sort(a):
n = len(a)
for i in range(n):
for j in range(0, n - i - 1):
if a[j] > a[j + 1]: # 앞이 뒤보다 크면
print(a) # 정렬 과정 출력(참고용)
a[j], a[j + 1] = a[j + 1], a[j] # 두 자료의 위치를 맞바꿈
d = [2, 4, 5, 1, 3]
bubble_sort(d)
print(d) # 실행결과: [1, 2, 3, 4, 5]- 실행결과
[2, 4, 5, 1, 3]
[2, 4, 1, 5, 3]
[2, 4, 1, 3, 5]
[2, 1, 4, 3, 5]
[2, 1, 3, 4, 5]
[1, 2, 3, 4, 5][2 4 5 1 3] ← 2 < 4이므로 그대로 둡니다.
[2 4 5 1 3] ← 4 < 5이므로 그대로 둡니다.
[2 4 5 1 3] ← 5 > 1이므로 5와 1의 위치를 서로 바꿉니다.
[2 4 1 5 3] ← 5 > 3이므로 5와 3의 위치를 서로 바꿉니다.
[2 4 1 3 5] ← 다시 앞에서부터 반복, 2 < 4이므로 그대로 둡니다.
[2 4 1 3 5] ← 4 > 1이므로 서로 위치를 바꿉니다.
[2 1 4 3 5] ← 4 > 3이므로 서로 위치를 바꿉니다.
[2 1 3 4 5] ← 4 < 5이므로 그대로 둡니다.
[2 1 3 4 5] ← 다시 앞에서부터 반복, 2 > 1이므로 서로 위치를 바꿉니다.
[1 2 3 4 5] ← 더는 바꿀 것이 없으므로 정렬을 마칩니다(최종 결과).
알고리즘 분석
입력에 대한 거품 정렬의 계산 복잡도는 O(n제곱)입니다. 하지만 거품 정렬은 자료 위치를 서로 바꾸는 횟수가 선택 정렬이나 삽입 정렬보다 더 많기 때문에 실제로 더 느리게 동작한다는 단점이 있습니다.
내림차순 정렬
# 거품 정렬
# 입력: 리스트 a
# 출력: 없음(입력으로 주어진 a가 정렬됨)
def bubble_sort(a):
n = len(a)
for i in range(n):
for j in range(0, n - i - 1):
if a[j] < a[j + 1]: # 뒤가 앞보다 크면
print(a) # 정렬 과정 출력(참고용)
a[j], a[j + 1] = a[j + 1], a[j] # 두 자료의 위치를 맞바꿈
d = [2, 4, 5, 1, 3]
bubble_sort(d)
print(d) # 실행결과: [5, 4, 3, 2, 1]List[2,5,6,3,1]을 거품정렬하는 과정
[2, 5, 6, 3, 1]
[5, 2, 6, 3, 1]
[5, 6, 2, 3, 1]
[5, 6, 3, 2, 1]
[6, 5, 3, 2, 1]삽입정렬
1 | 학생이 열 명 모인 운동장에 선생님이 등장합니다.
2 | 선생님은 열 명 중 제일 앞에 있던 승규에게 나와서 줄을 서라고 합니다. 승규가 나갔으니 이제 학생이 아홉 명 남았습니다.
3 | 이번에는 선생님이 준호에게 키를 맞춰 줄을 서라고 합니다. 준호는 이미 줄을 선 승규보다 자신이 키가 작은 것을 확인하고 승규 앞에 섭니다.
4 | 남은 여덟 명 중 이번에는 민성이가 뽑혀 줄을 섭니다. 민성이는 준호보다 크고 승규보다는 작습니다. 그래서 준호와 승규 사이에 공간을 만들어 줄을 섭니다(삽입).
5 | 마찬가지로 남은 학생을 한 명씩 뽑아 이미 줄을 선 학생 사이사이에 키를 맞춰 끼워 넣는 일을 반복합니다. 마지막 남은 학생까지 뽑아서 줄을 세우면 모든 학생이 제자리에 줄을 서게 됩니다.

쉽게 설명한 삽입 정렬 알고리즘
# 쉽게 설명한 삽입 정렬
# 입력: 리스트 a
# 출력: 정렬된 새 리스트
# 리스트 r에서 v가 들어가야 할 위치를 돌려주는 함수
def find_ins_idx(r, v):
# 이미 정렬된 리스트 r의 자료를 앞에서부터 차례로 확인하여
for i in range(0, len(r)):
# v 값보다 i번 위치에 있는 자료 값이 크면
# v가 그 값 바로 앞에 놓여야 정렬 순서가 유지됨
if v < r[i]:
return i
# 적절한 위치를 못 찾았을 때는
# v가 r의 모든 자료보다 크다는 뜻이므로 맨 뒤에 삽입
return len(r)
def ins_sort(a):
result = [] # 새 리스트를 만들어 정렬된 값을 저장
while a: # 기존 리스트에 값이 남아 있는 동안 반복
value = a.pop(0) # 기존 리스트에서 한 개를 꺼냄
ins_idx = find_ins_idx(result, value) # 꺼낸 값이 들어갈 적당한 위치 찾기
result.insert(ins_idx, value) # 찾은 위치에 값 삽입(이후 값은 한 칸씩 밀려남)
return result
d = [2, 4, 5, 1, 3]
print(ins_sort(d)) # 실행결과: [1, 2, 3, 4, 5]1 | 리스트 a에 아직 자료가 남아 있다면 → while a:
2 | 남은 자료 중에 맨 앞의 값을 뽑아냅니다. → value = a.pop(0)
3 | 그 값이 result의 어느 위치에 들어가면 적당할지 알아냅니다.
→ ins_idx = find_ins_idx(result, value)
4 | 3번 과정에서 찾아낸 위치에 뽑아낸 값을 삽입합니다.
→ result.insert(ins_idx, value)
5 | 1번 과정으로 돌아가 자료가 없을 때까지 반복합니다.
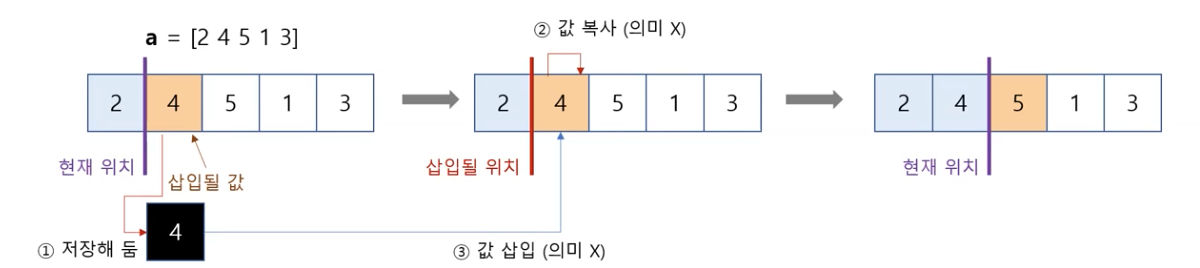
[2, 4, 5, 1, 3]이 정렬되는 과정
① 시작
a = [2 4 5 1 3]
result = []
② a에서 2를 빼서 현재 비어 있는 result에 넣습니다.
a = [4 5 1 3]
result = [2]
③ a에서 4를 빼서 result의 2 뒤에 넣습니다(2 < 4).
a = [5 1 3]
result = [2 4]
④ a에서 5를 빼서 result의 맨 뒤에 넣습니다(4 < 5).
a = [1 3]
result = [2 4 5]
⑤ a에서 1을 빼서 result의 맨 앞에 넣습니다(1 < 2).
a = [3]
result = [1 2 4 5]
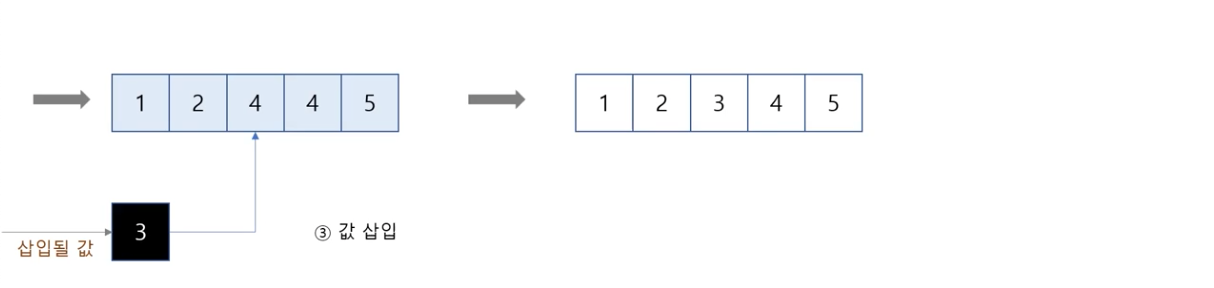
⑥ a에서 마지막 값인 3을 빼서 result의 2와 4 사이에 넣습니다(2 < 3 < 4).
a=[]
result = [1 2 3 4 5]
⑦ a가 비어 있으므로 종료합니다.
result = [1 2 3 4 5] → 최종 결과
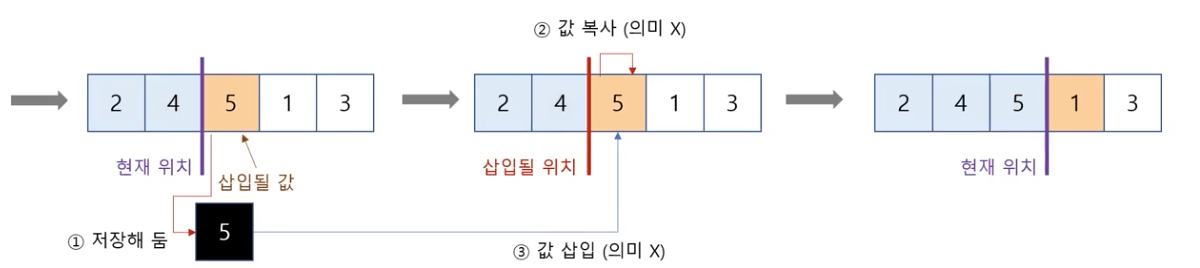
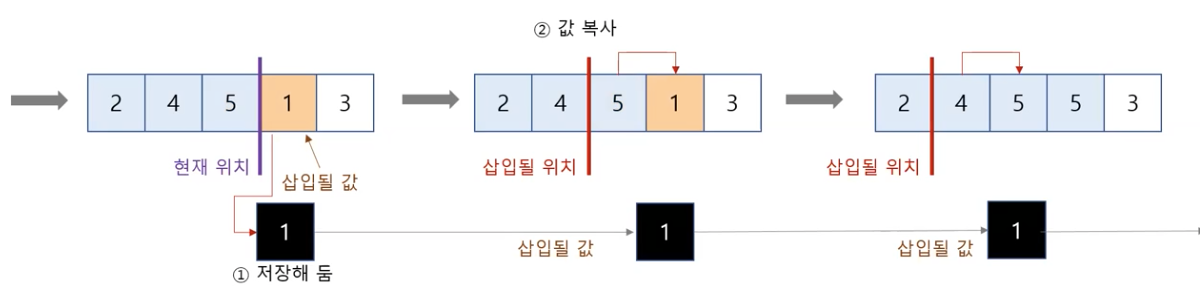
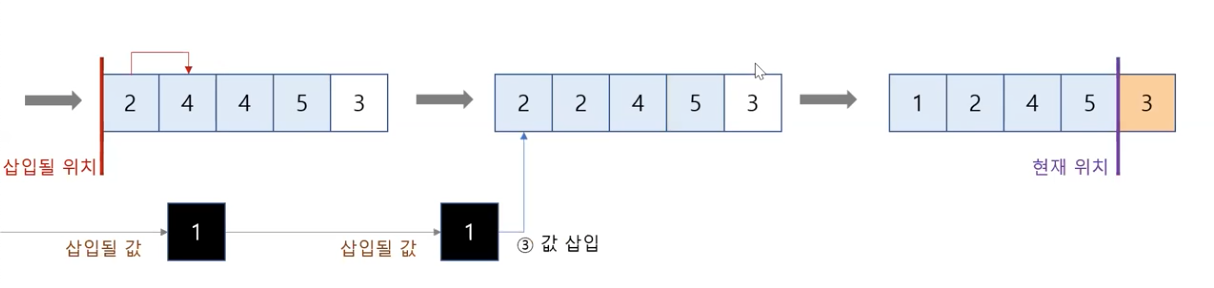
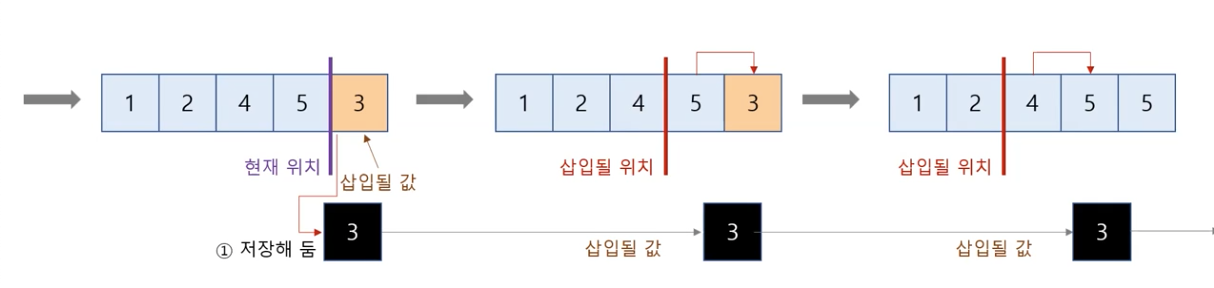
삽입 방법
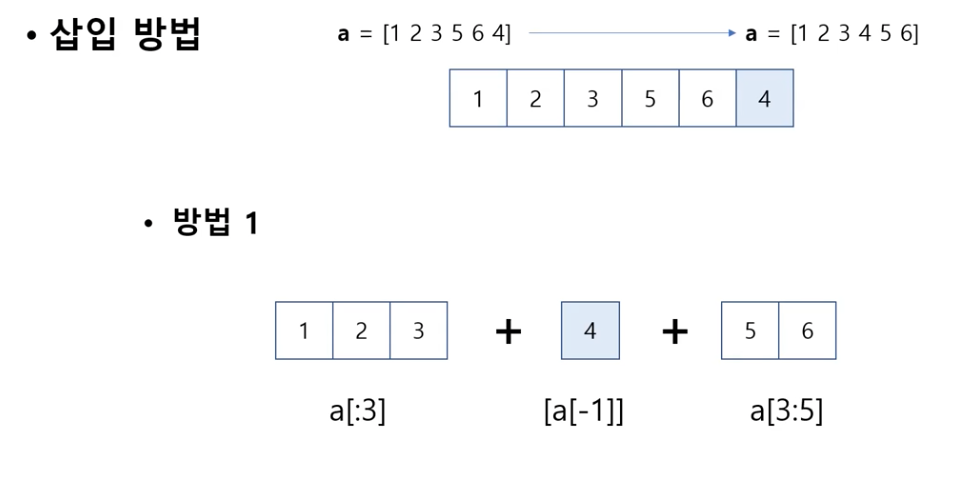
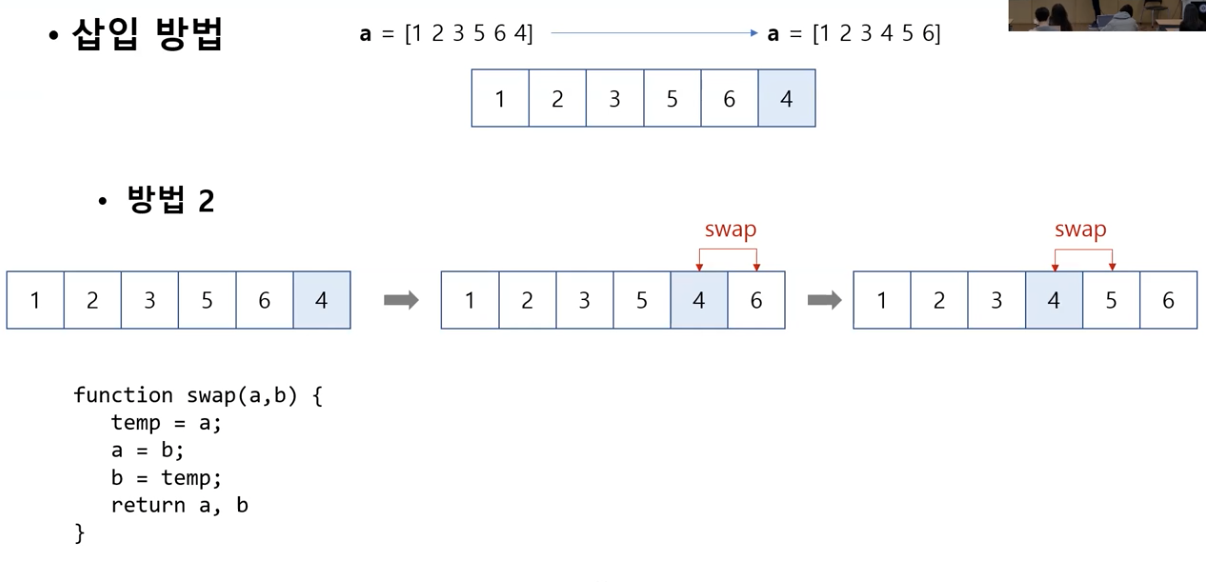
일반적인 삽입 정렬 알고리즘
# 삽입 정렬
# 입력: 리스트 a
# 출력: 없음(입력으로 주어진 a가 정렬됨)
def ins_sort(a):
n = len(a)
for i in range(1, n): # 1부터 n -1까지
key = a[i] # i번 위치에 있는 값을 key에 저장
# j를 i 바로 왼쪽 위치로 저장
j = i - 1
# 리스트의 j번 위치에 있는 값과 key를 비교해 key가 삽입될 적절한 위치를 찾음
while j >= 0 and a[j] > key:
a[j + 1] = a[j] # 삽입할 공간이 생기도록 값을 오른쪽으로 한 칸 이동
j -= 1
a[j + 1] = key # 찾은 삽입 위치에 key를 저장
d = [2, 4, 5, 1, 3]
ins_sort(d)
print(d) # 실행결과: [1, 2, 3, 4, 5]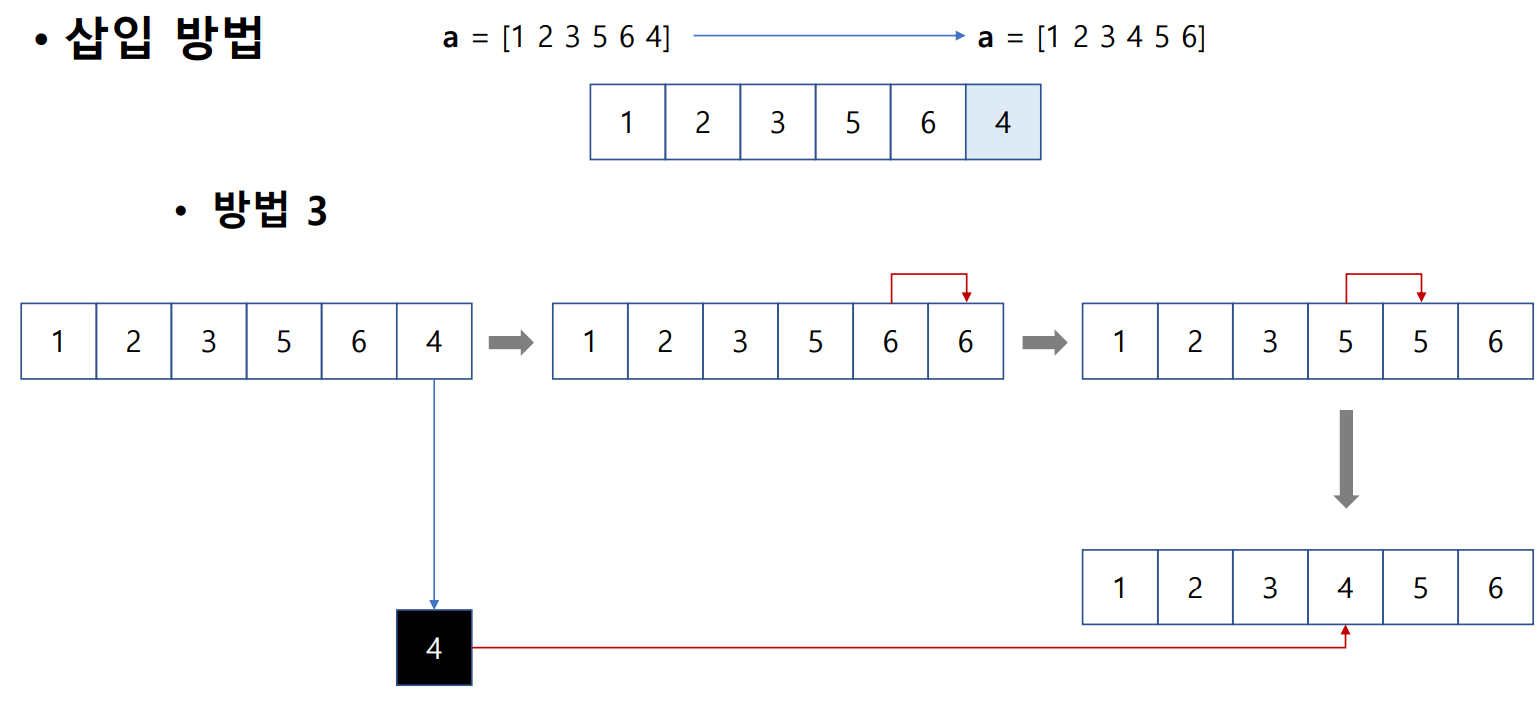
알고리즘 분석


삽입 정렬 알고리즘의 계산 복잡도는 조금 생각해 볼만 한 점이 있다. 최선의 경우에 조금 독특한 결과가 나타나기 때문이다. 삽입 정렬 알고리즘의 입력으로 이미 정렬이 끝난 리스트, 예를 들어 [1, 2, 3, 4, 5]와 같은 리스트를 넣어 주면 O(n)의 계산 복잡도로 정렬을 마칠 수 있다. 하지만 이런 경우는 특별한 경우이다.
일반적인 입력일 때 삽입 정렬의 계산 복잡도는 선택 정렬과 같은 O(n제곱)이다. 따라서 선택 정렬과 마찬가지로 정렬할 입력 크기가 크면 정렬하는 데 시간이 굉장히 오래 걸린다.

내림차순 정렬
# 삽입 정렬
# 입력: 리스트 a
# 출력: 없음(입력으로 주어진 a가 정렬됨)
def ins_sort(a):
n = len(a)
for i in range(1, n): # 1부터 n -1까지
key = a[i] # i번 위치에 있는 값을 key에 저장
# j를 i 바로 왼쪽 위치로 저장
j = i - 1
# 리스트의 j번 위치에 있는 값과 key를 비교해 key가 삽입될 적절한 위치를 찾음
while j >= 0 and a[j] < key:
a[j + 1] = a[j] # 삽입할 공간이 생기도록 값을 오른쪽으로 한 칸 이동
j -= 1
a[j + 1] = key # 찾은 삽입 위치에 key를 저장
d = [2, 4, 5, 1, 3]
ins_sort(d)
print(d) # 실행결과: [5, 4, 3, 2, 1]