
선택 정렬로 줄 세우기
‘키 순서로 줄 세우기’는 대표적인 정렬 문제의 예이다.
왜냐하면, 이 문제는 ‘학생의 키라는 자료 값을 작은 것부터 큰 순서로 나열하라’는 문제와 같은 말이기 때문이다.

1 . 학생 열 명이 모여 있는 운동장에 선생님이 등장합니다.
2 . 선생님은 학생들을 둘러보며 키가 가장 작은 사람을 찾습니다. 키가 가장 작은 학생으로 ‘선택’된 민준이가 불려 나와 맨 앞에 섭니다. 민준이가 나갔으므로 이제 학생은 아홉 명 남았습니다.
3 . 이번에는 선생님이 학생 아홉 명 중 키가 가장 작은 성진이를 선택합니다. 선택된 성진이가 불려 나와 민준이 뒤로 줄을 섭니다.
4 . 이처럼 남아 있는 학생 중에서 키가 가장 작은 학생을 한 명씩 뽑아 줄에 세우는 과정을 반복하면 모든 학생이 키 순서에 맞춰 줄을 서게 됩니다.
쉽게 설명한 선택 정렬 알고리즘
# 쉽게 설명한 선택 정렬
# 입력: 리스트 a
# 출력: 정렬된 새 리스트
# 주어진 리스트에서 최솟값의 위치를 돌려주는 함수
def find_min_idx(a):
n = len(a)
min_idx = 0
for i in range(1, n):
if a[i] < a[min_idx]:
min_idx = i
return min_idx
def sel_sort(a):
result = [] # 새 리스트를 만들어 정렬된 값을 저장
while a: # 주어진 리스트에 값이 남아 있는 동안 계속
min_idx = find_min_idx(a) # 리스트에 남아 있는 값 중 최솟값의 위치
value = a.pop(min_idx) # 찾은 최솟값을 빼내어 value에 저장
result.append(value) # value를 결과 리스트 끝에 추가
return result
d = [2, 4, 5, 1, 3]
print(sel_sort(d)) # 실행결과: [1, 2, 3, 4, 5]1 | 리스트 a에 아직 자료가 남아 있다면 → while a:
2 | 남은 자료 중에서 최솟값의 위치를 찾습니다.
→ min_idx = find_min_idx(a)
3 | 찾은 최솟값을 리스트 a에서 빼내어 value에 저장합니다.
→ value = a.pop(min_idx)
4 | value를 result 리스트의 맨 끝에 추가합니다. → result.append(value)
5 | 1번 과정으로 돌아가 자료가 없을 때까지 반복합니다.
[2, 4, 5, 1, 3]을 정렬하는 과정
① 시작
a = [2 4 5 1 3] → 쉼표 생략
result = []
② a 리스트의 최솟값인 1을 a에서 빼내어 result에 추가합니다.
a = [2 4 5 3]
result = [1]
③ a에 남아 있는 값 중 최솟값인 2를 a에서 빼내어 result에 추가합니다.
a = [4 5 3]
result = [1 2]
④ a에 남아 있는 값 중 최솟값인 3을 같은 방법으로 옮깁니다.
a = [4 5]
result = [1 2 3]
⑤ a에 남아 있는 값 중 최솟값인 4를 같은 방법으로 옮깁니다.
a = [5]
result = [1 2 3 4]
⑥ a에 남아 있는 값 중 최솟값인 5를 같은 방법으로 옮깁니다.
a=[]
result = [1 2 3 4 5]
⑦ a가 비어 있으므로 종료합니다.
result = [1 2 3 4 5] → 최종 결과
일반적인 선택 정렬 알고리즘
‘일반적인 선택 정렬 알고리즘’은 입력으로 주어진 리스트 a 안에서 직접 자료의 위치를 바꾸면서 정렬시키는 프로그램이다.
# 선택 정렬
# 입력: 리스트 a
# 출력: 없음(입력으로 주어진 a가 정렬됨)
def sel_sort(a):
n = len(a)
for i in range(0, n - 1): # 0부터 n -2까지 반복
# i번 위치부터 끝까지 자료 값 중 최솟값의 위치를 찾음
min_idx = i
for j in range(i + 1, n):
if a[j] < a[min_idx]:
min_idx = j
# 찾은 최솟값을 i번 위치로
a[i], a[min_idx] = a[min_idx], a[i]
d = [2, 4, 5, 1, 3]
sel_sort(d)
print(d) # 실행결과: [1, 2, 3, 4, 5]| 2 4 5 1 3 ← 시작, 전체 리스트인 2, 4, 5, 1, 3을 대상으로 최솟값을 찾습니다.
| 1 4 5 2 3 ← 최솟값 1을 대상의 가장 왼쪽 값인 2와 바꿉니다.
1 | 4 5 2 3 ← 1을 대상에서 제외하고 4, 5, 2, 3에서 최솟값을 찾습니다.
1 | 2 5 4 3 ← 4, 5, 2, 3 중 최솟값인 2를 4와 바꿉니다.
1 2 | 5 4 3 ← 2를 대상에서 제외하고 5, 4, 3에서 최솟값을 찾습니다.
1 2 | 3 4 5 ← 5, 4, 3 중 최솟값인 3을 5와 바꿉니다.
1 2 3 | 4 5 ← 3을 대상에서 제외하고 4, 5에서 최솟값을 찾습니다.
1 2 3 | 4 5 ← 최솟값 4를 4와 바꿉니다(변화 없음).
1 2 3 4 | 5 ← 4를 대상에서 제외합니다. 자료가 5 하나만 남았으므로 종료합니다.
1 2 3 4 5 | ← 최종 결과

파이썬에서 두 자료 값 서로 바꾸기
리스트 안에서 두 자료 값의 위치를 서로 바꾸는 데 다음과 같은 문장이 사용
a[i], a[min_idx] = a[min_idx], a[i]파이썬에서 두 변수의 값을 서로 바꾸려면 다음과 같이 쉼표를 이용해 변수를 뒤집어 표현하면 됩니다.
x, y = y, x
>>> x = 1
>>> y = 2
>>> x, y = y, x
>>> x
2
>>> y
1내림차순 정렬
오름차순 선택 정렬에서 최솟값 대신 최댓값을 선택하면 내림차순 정렬(큰 수에서 작은 수로 나열)이 된다.
다음과 같이 비교 부등호 방향을 작다(< )에서 크다( >)로 바꾸기만 해도 내림차순 정렬 프로그램이 된다. 여기서는 변수 이름의 의미를 맞추려고 변수 min_idx를 max_idx로 바꾸었다.
# 내림차순 선택 정렬
# 입력: 리스트 a
# 출력: 없음(입력으로 주어진 a가 정렬됨)
def sel_sort(a):
n = len(a)
for i in range(0, n - 1):
max_idx = i # 최솟값(min) 대신 최댓값(max)을 찾아야 함
for j in range(i + 1, n):
if a[j] > a[max_idx]: # 부등호 방향 뒤집기
max_idx = j
a[i], a[max_idx] = a[max_idx], a[i]
d = [2, 4, 5, 1, 3]
sel_sort(d)
print(d)알고리즘 분석
자료를 크기 순서로 정렬하려면 반드시 두 수의 크기를 비교해야 한다. 따라서 정렬 알고리즘의 계산 복잡도는 보통 비교 횟수를 기준으로 따진다.
선택 정렬의 비교 방법은 리스트 안의 자료를 한 번씩 비교하는 방법과 거의 같다. 따라서 이 알고리즘은 비교를 총 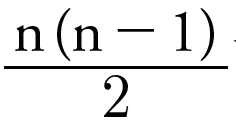 번 해야 하는 계산 복잡도가 O(n제곱)인 알고리즘이다.
번 해야 하는 계산 복잡도가 O(n제곱)인 알고리즘이다.
선택 정렬 알고리즘은 이해하기 쉽고 간단하여 많이 이용된다. 하지만 비교 횟수가 입력 크기의 제곱에 비례하는 시간 복잡도가 O(n제곱)인 알고리즘이므로 입력 크기가 커지면 커질수록 정렬하는 데 시간이 굉장히 오래 걸린다.
거품 정렬
- 서로 인접한 두 원소를 검사하여 정렬하는 알고리즘
- 인접한 2개의 레코드를 비교하여 크기가 순서대로 되어 있지 않으면 서로 교환한다.
- 선택 정렬과 기본 개념이 유사하다.
-
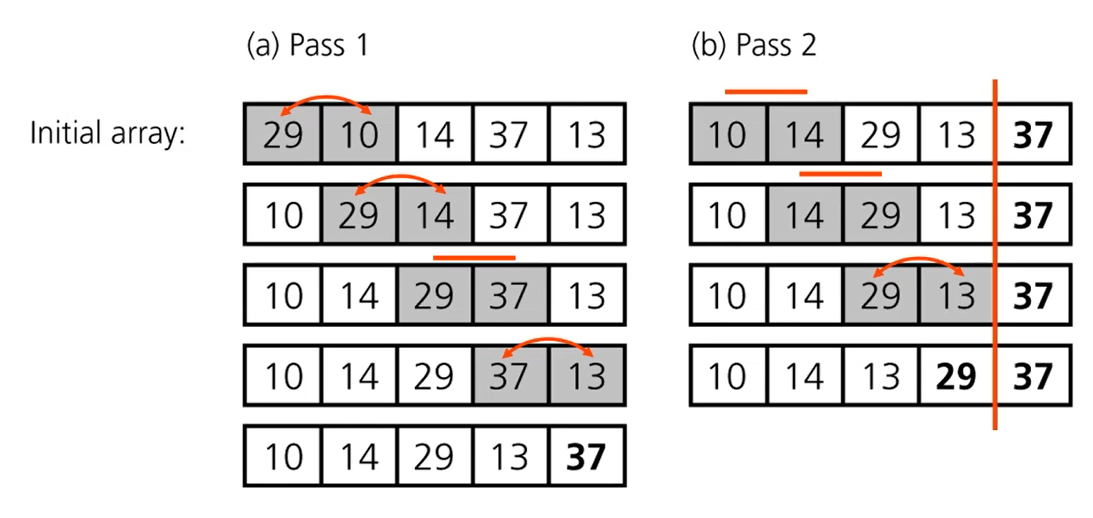
버블 정렬은 첫 번째 자료와 두 번째 자료를, 두 번째 자료와 세 번째 자료를, 세 번째와 네 번째를, … 이런 식으로 (마지막-1)번째 자료와 마지막 자료를 비교하여 교환하면서 자료를 정렬한다.
-
1회전을 수행하고 나면 가장 큰 자료가 맨 뒤로 이동하므로 2회전에서는 맨 끝에 있는 자료는 정렬에서 제외되고, 2회전을 수행하고 나면 끝에서 두 번째 자료까지는 정렬에서 제외된다. 이렇게 정렬을 1회전 수행할 때마다 정렬에서 제외되는 데이터가 하나씩 늘어난다.
