
이 문서는 머신러닝 인강을 보면서 SVM(Support Vector Machine) 알고리즘을 정리한 내용입니다.
강의에서 설명이 빠르게 지나간 부분이나, 스스로 더 궁금했던 내용을 보충해서 정리했습니다.
SVM (Support Vector Machine) 정리
1. SVM이란?
SVM은 지도학습(Supervised Learning) 알고리즘 중 하나로
이진 분류 문제에 주로 사용되며, 회귀 문제로도 확장 가능합니다.
처음엔 단순히 "선을 그어 분류한다"고 생각했지만,
"어떻게 선을 그을까?"가 핵심이라는 걸 깨달았습니다.
- 목적: 두 클래스를 가장 잘 구분할 수 있는 초평면(Decision Boundary) 찾기
- 이때 가장 가까운 포인트들과의 거리, 즉 마진(Margin)을 최대화
2. 마진(Margin)과 서포트 벡터(Support Vector)
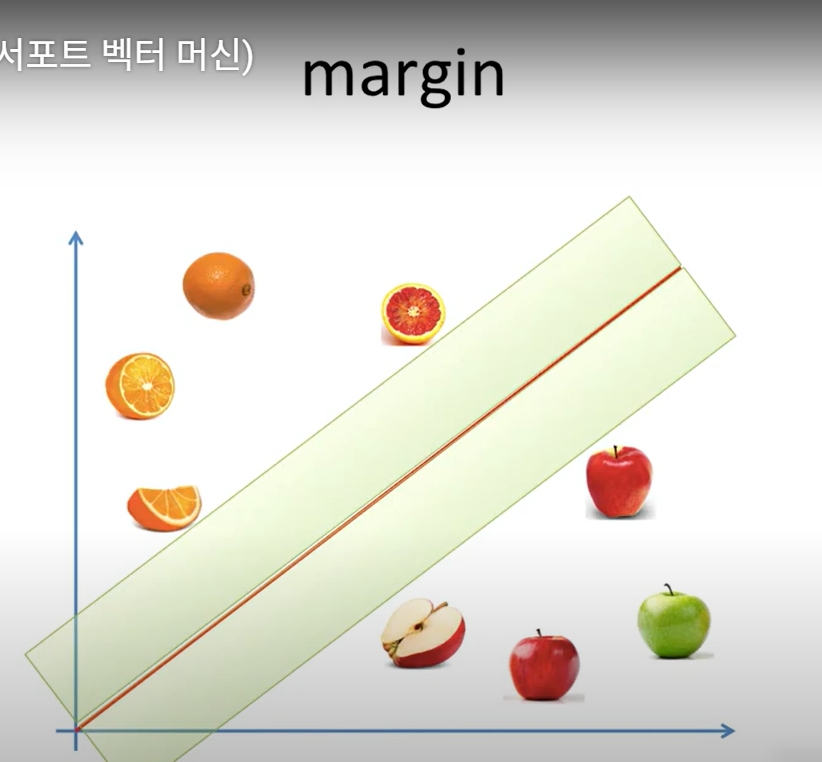
- 마진: 분류 경계와 가장 가까운 포인트(서포트 벡터) 간의 거리
- Support Vector: 모델 경계를 결정짓는 핵심 포인트들
모델 학습 시 모든 데이터를 쓰지 않고,
Support Vector만 사용해서 계산량을 줄이고 일반화 성능을 높입니다.
3. 수학적으로 보면
Hard Margin (완전히 분리 가능한 경우)
Minimize: (1/2) * ||w||²
Subject to: yᵢ(w·xᵢ + b) ≥ 1Soft Margin (일부 오차 허용)
Minimize: (1/2)||w||² + C * ∑ ξᵢ
Subject to: yᵢ(w·xᵢ + b) ≥ 1 - ξᵢ, ξᵢ ≥ 0- C는 오차에 얼마나 민감하게 반응할지 조절하는 하이퍼파라미터입니다.
4. 비선형 문제와 커널 트릭 (Kernel Trick)
현실 데이터는 대부분 선형 분리 불가능합니다.
이럴 땐 고차원 공간으로 데이터를 변환해야 선형 분리가 가능해집니다.
근데 고차원 연산은 부담이 크기 때문에,
커널 트릭(Kernel Trick)을 통해 효율적으로 계산합니다.
자주 쓰이는 커널
| 커널 | 설명 |
|---|---|
| Linear | 선형 문제 |
| Polynomial | 다항식 특성 확장 |
| RBF (가우시안) | 비선형 문제 대응에 가장 널리 사용됨 |
| Sigmoid | 신경망에서 사용되는 함수 기반 |
5. 주요 하이퍼파라미터
| 파라미터 | 설명 |
|---|---|
| C | 오차 허용도. 크면 정확하지만 과적합 위험 |
| gamma | RBF에서 포인트의 영향력 반경 조절 |
| kernel | 어떤 커널 함수를 쓸지 설정 |
6. C와 gamma의 조합 영향
| 설정 | 분류 경계 | 과적합 위험 | 일반화 |
|---|---|---|---|
| C ↓ | 마진 넓음 | 과소적합 가능 | ↑ |
| C ↑ | 마진 좁음 | 과적합 가능 | ↓ |
| gamma ↓ | 부드러운 경계 | 낮음 | ↑ |
| gamma ↑ | 복잡한 경계 | 높음 | ↓ |
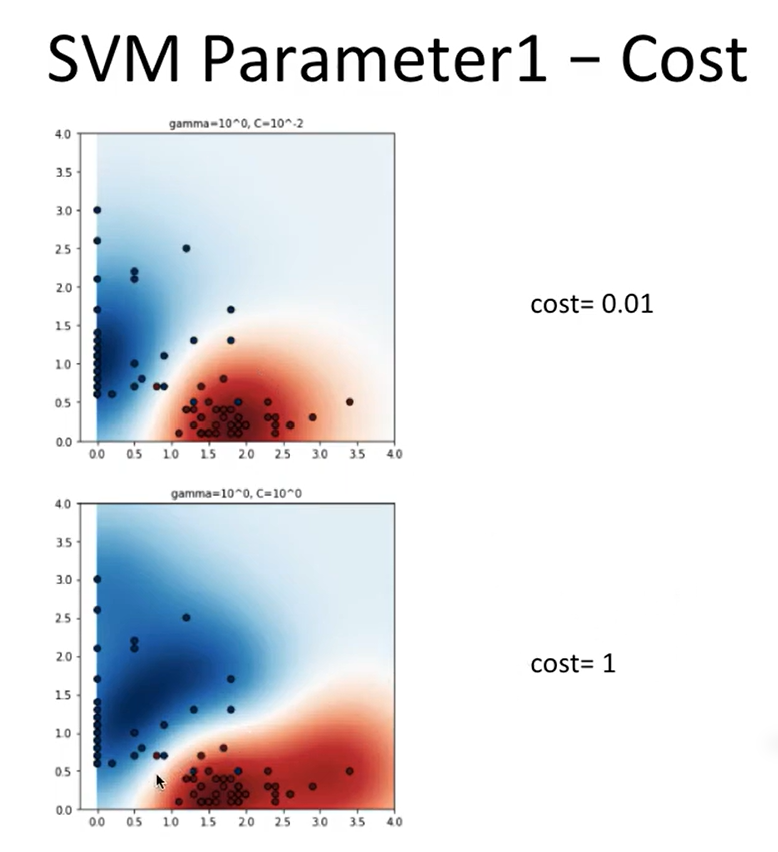
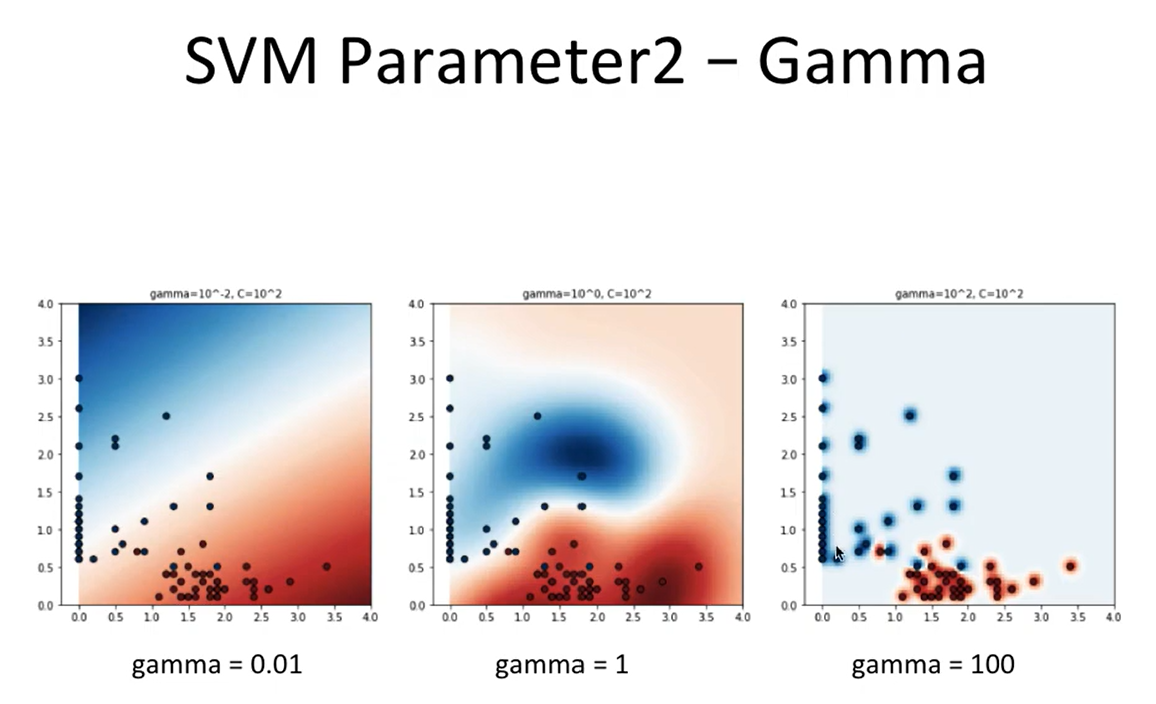
7. 하이퍼파라미터 튜닝 (GridSearchCV)
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
param_grid = {
'C': [0.1, 1, 10, 100],
'gamma': [0.001, 0.01, 0.1, 1],
'kernel': ['rbf']
}
grid = GridSearchCV(SVC(), param_grid, cv=5)
grid.fit(X_train, y_train)Scikit-learn을 사용하면 간단하게 하이퍼파라미터 튜닝이 가능합니다.

8. 시각적 흐름 요약 (내가 정리하며 이해한 단계)
- 마진과 디시전 바운더리의 관계
- Support Vector만으로 예측 가능한 구조
- 선형 분리 불가능 → 커널로 고차원 매핑
- C, gamma 값 조절 → 경계의 부드러움 / 복잡함 변화
9. 실무 팁
- 데이터 스케일링 필수! (
StandardScaler)
→ 거리 기반 알고리즘이라 크기 차이가 클 경우 성능 저하됨 - 고차원 데이터에서 효과적 (특히 RBF 커널)
- 대용량 데이터셋에서는 속도 문제 고려
10. 정리 요약
| 항목 | 설명 |
|---|---|
| 마진 | Support Vector와 경계 간 거리 |
| C | 마진과 오차 간 균형 조절 |
| gamma | 포인트 영향 범위 조절 |
| 커널 | 고차원 비선형 문제 해결 방식 |
| GridSearch | 자동 파라미터 최적화 |
11. 내가 정리하면서 느낀 점
처음엔 그냥 복잡해 보였는데,
결국 핵심은 "어떤 기준으로 데이터를 나눌 것인가"였음.
수학적으로 최적화된 경계를 찾는 게 포인트고,
커널 트릭이나 C/gamma 튜닝을 하면서 모델이 어떻게 달라지는지 직접 보는 것이 제일 중요했다.

기록과 회고를 통해 성장하는 데이터, AI 엔지니어 지망생입니다.