<오소진 교수님의 파이썬 프로그래밍>
데이터 분석하는 사람은 데이터를 어디서 찾을 수 있을지 잘 파악하고 있어야 한다. 인구통계는 행정안전부, 수도권 교통 정보는 티머니 등.. 자료 출처를 명확히 가지고 있는 것이 힘이다.
cf.인구데이터는 모든 데이터와 비교할 수 있는 기초 데이터가 된다.
모든 분석 작업 전, 루틴이 되어야할 "데이터 세팅"
1) 엑셀 csv파일로 다운로드 후 노트패드 플러스 플러스로 열기
2) 파일의 마지막 자료값의 공백을 지우기
3) 인코딩을 euc-kr에서 UTF-8bom으로 미리 바꾸기: 한글 깨짐을 방지
4) 파일 형식을 all types로 설정 후 다른 이름으로 저장
csv 파일을 읽어들이고 업로드한 파일의 경로를 복사하여 데이터를 읽는다. 그리고 그 데이터가 잘 읽히는지 프린트문으로 출력하여 확인한다.
특정 값을 추출해서 데이터를 확인하는 방법은
1) 단순하게 == 연산자로 찾기: 띄어쓰기와 모든 문자열을 완벽하게 만들거나 원하는 문자열만 split해야해서 복잡함
2) in 연산자를 활용해 원하는 문자열을 포함한 값 추출

전국에 같은 동이름을 가진 지역이 여러 곳이라면, and 연산자를 활용하여 특별시, 광역시 등으로 먼저 필터링하고 원하는 동이름을 추출한다.
참고. 동에 해당하는 동번호가 필요없다면, "split(')'[0])"을 통해 괄호'('로 시작하는 값을 자르고, 첫번째 값만 추출할 수 있다.

추출한 행(row)의 값을 모두 프린트하고 프린트 된 값의 갯수를 len 함수를 통해 확인할 수 있다.

두 개 동네의 인구구조를 비교할 때, result값과 주소 값을 두개 명명하고 주소 값의 경우 입력자가 input할 수 있게 세팅한다.
단, 입력자가 데이터에 있는 값을 정확하게 입력한다는 가정하에 사용할 수 있는 문이며, 그렇지 않다면, result= [] si = input, dong = input 문으로 작성하여 오류를 줄일 수 있다.
✌<개인과제>✌
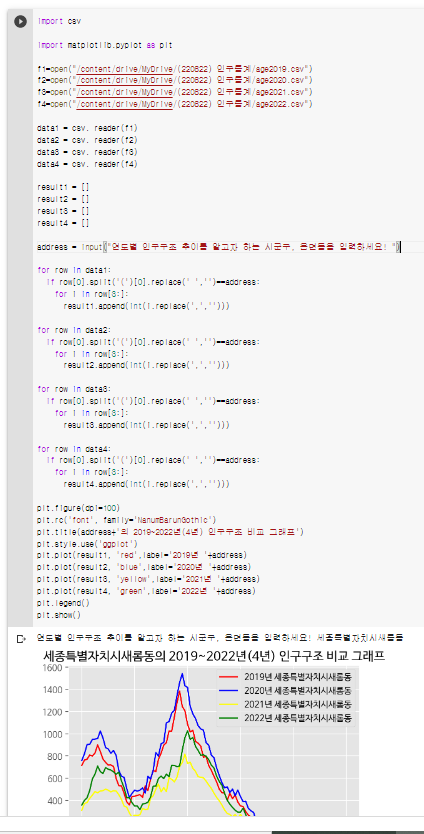
동일지역에 대한 연도별 인구구조 추이를 보기 위해서는 4개년도 연도별 자료를 각각 불러오고 읽으며 각 result1~4 값을 명명해줘야 한다.
참고. 시각화할 때, 폰트가 깨지지 않도록 런타임 다시 시작 후 아래 코드를 실행해줘야 한다.
import matplotlib as mpl
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina'
!apt -qq -y install fonts-nanum
import matplotlib.font_manager as fm
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
plt.rc('font', family='NanumBarunGothic')
mpl.font_manager._rebuild()