1. 유튜브 댓글 워드 클라우드 시각화
1) 라이브러리 임포트
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
import time
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator2) 크롤링할 동영상 주소 접속 준비
- 교수님께서 작성하신 코드는 유튜브 동영상 페이지에서 공유 버튼 클릭 시 복사할 수 있는 url 주소를 활용할 때 가장 적합한 코드이다. 따라서 해당 루트를 통해 얻은 주소만 활용하자.
options = webdriver.ChromeOptions()
options.add_argument('--headless')
# 크롤링하는 화면을 보여주지 않겠다는 코드(코랩은 원래 안됨, spider 활용)
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver', options=options)
driver.get('https://youtu.be/qWbHSOplcvY')
driver.implicitly_wait(3)
time.sleep(1.5)
driver.execute_script('window.scrollTo(0,800)')
# 원래 커서 위치에서 800픽셀만큼 내리기
time.sleep(3)3) 모든 댓글 수집 위한 최대 스크롤
- 유튜브 웹페이지는 최초 일정 갯수의 댓글만 먼저 로드한 후에 사용자가 스크롤을 할 경우에만 추가적으로 댓글을 띄워주도록 만들어졌다. 따라서 selenium을 활용해 해당 유튜브의 모든 댓글을 크롤링하기 위해서는 끝까지 스크롤을 해줘야 한다.
last_height = driver.execute_script("return document.documentElement.scrollHeight")
# 최초 로드시 화면이 가진 스크롤 높이 최대 픽셀값을 추출
while True: # for 문과 달리 무한 루프인데 조건을 충족하면 코드를 벗어남
driver.execute_script("window.scrollTo(0, document.documentElement.scrollHeight);")
# 지금 보고 있는 화면이 가진 스크롤 높이 최대 픽셀값만큼 실행
# 즉, 위에서 받은 최대 스크롤 값을 실행하는 것
# ; = window 함수의 특징으로서 code가 끝났으니 다음으로 넘어가라는 표시
time.sleep(1.5)
new_height = driver.execute_script("return document.documentElement.scrollHeight")
# 기존에 받아온 최대 스크롤값을 실행한 후 추가로 생긴 화면이 가진 스크롤 높이 최대 픽셀값 추출
if new_height == last_height: # 추가 스크롤 값 없으면 멈춰
break
last_height = new_height # 스크롤 더 있으면 다시 담아줘(last height 리셋)
time.sleep(1.5)
try:
driver.find_element_by_css_selector('#dismiss-button > a').click()
#유튜브 프리미엄 프로모션 팝업창 닫기
time.sleep(1.5)
except:
pass4) 스크롤 후 댓글 크롤링
- 종전에는 컬럼별로 명명하고 크롤링한 값을 append해서 데이터프레임에 담았는데, 이번에는 리스트로 댓글 왕창, 아이디 왕창 각각 담은 후에 데이터 프레임으로 변환한다.
- 1) 댓글 아이디보다 댓글 내용이 더 중요하므로 comment_list에 담긴 태그 리스트의 갯수만큼 for문을 돌게 한다.
- 2) 각 태그에 있는 text를 추출해오고 다시 줄바꿈, tab, 공백 값 삭제 및 뒤쪽 빈칸 삭제한다.
- 3) 전처리한 text 값을 아이디와 내용 리스트에 담는다.
html_source = driver.page_source
#print(html_source)
soup = BeautifulSoup(html_source, 'html.parser') #파싱 가능한 형태로 만듦
id_list = soup.select('div#header-author > h3 > #author-text > span')
# 아이디 리스트 변수(html 태그 리스트를 담은 것)
comment_list = soup.select('yt-formatted-string#content-text')
# 댓글 리스트 변수(html 태그 리스트를 담은 것)
id_final = [] # 리스트 형태라고 선언
comment_final = [] # 리스트 형태라고 선언
for i in range(len(comment_list)):
temp_id = id_list[i].text
temp_id = temp_id.replace('\n','').replace('\t','').replace(' ','').strip()
id_final.append(temp_id) # 댓글 작성자 담기
temp_comment = comment_list[i].text
temp_comment = temp_comment.replace('\n','').replace('\t','').strip()
comment_final.append(temp_comment) # 댓글 내용 담기5) 리스트를 데이터프레임으로 변환
- 딕셔너리 문법을 활용하여 컬럼명과 리스트를 각각 짝지어주고 데이터프레임을 만든다.
# 데이터 프레임 만들기 (리스트 -> 딕셔너리 활용 -> 데이터프레임)
youtube_dict = {"아이디": id_final, "댓글 내용": comment_final}
youtube_df = pd.DataFrame(youtube_dict)6) 데이터프레임 정보 확인
- 데이터 수 및 null값 수 그리고 데이터의 형식을 확인한다.
youtube_df.info()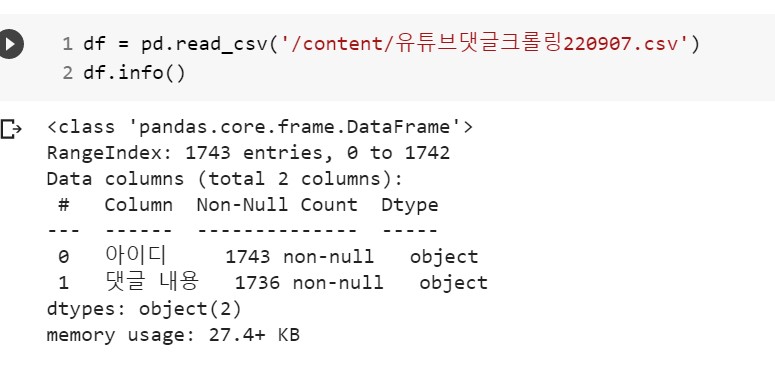
7) 크롤링한 데이터 csv 파일로 저장
- 워드클라우드를 위한 text 정제 작업 전에 저장하는 이유는 사용자가 입력한 이모티콘이 무드 분석을 할 때 중요한 자료이기 때문이다. (습관 들이기)
youtube_df.to_csv('유튜브댓글크롤링220907.csv', encoding ='UTF-8-sig', index = False)8) csv 파일 읽어온 후 정보 확인
df = pd.read_csv('/content/유튜브댓글크롤링220907.csv')
df.info()- 데이터프레임 변환 직후 데이터 수와 csv 파일의 데이터 수가 다른 것을 확인할 수 있다.
- 알고 싶진 않지만 확인해보자.
9) 데이터의 수 차이가 발생한다면
- csv파일과 info로 본 null값 개수 불일치하는 경우 두 가지 방법으로 오류의 원인을 찾아볼 수 있다.
1) 노트패드플러스플러스로 열면 태그값을(확장) 찾기
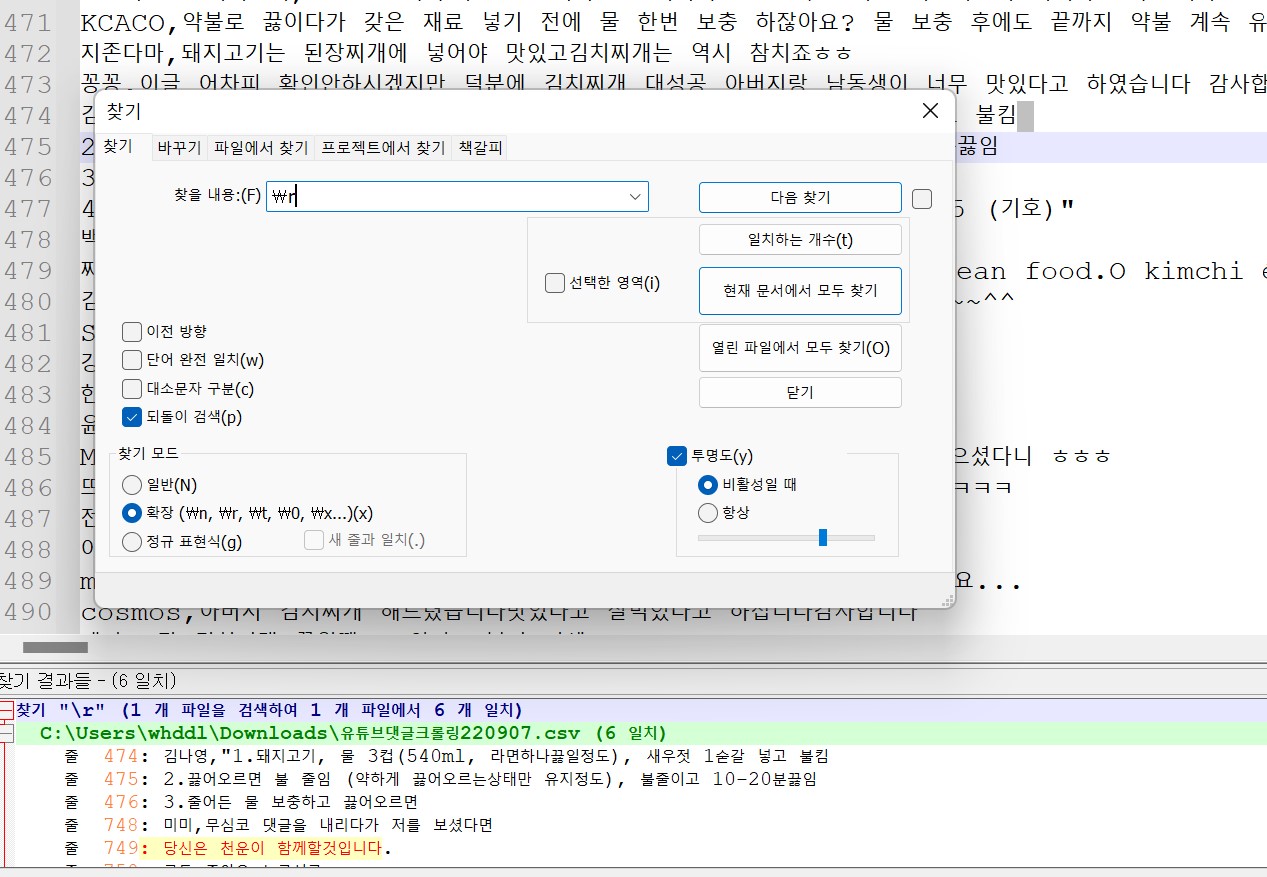
2) text 출력해서 찾기

10) 오류 일으키는 값을 찾아서 삭제하기
temp_comment = comment_list[i].text
temp_comment = temp_comment.replace('\n','').replace('\t','').replace('\r','').strip()
comment_final.append(temp_comment) # 댓글 내용 담기11) 워드 클라우드 시각화 위한 text 합치기
text = " ".join(li for li in youtube_df['댓글 내용'].astype(str))
text12) 워드 클라우드 시각화
import numpy as np
from PIL import Image #PIL : Python Imaging Library
mask = Image.open('/content/1.jpg')
mask = np.array(mask)
plt.subplots(figsize=(25,15))
wordcloud = WordCloud(background_color='black', width = 1000, height=700, mask = mask,
font_path=fontpath).generate(text)
plt.axis('off')
plt.imshow(wordcloud, interpolation='bilinear')
plt.show()
2. 유튜브 쇼츠 댓글 워드 클라우드 시각화
- 개인과제를 진행할 동영상을 고르던 중 한문철 변호사의 채널이 떠올라 무심코 검색해보니 유튜브 쇼츠 영상이 떴다. 쇼츠를 본 순간 과연 오늘 배운 코드가 적용될지 궁금했다.
- 쇼츠 동영상에는 일반 동영상과 다른 점이 있었다. 바로 팝업처럼 동영상이 재생된다는 점과 댓글을 확인하기 위해서는 댓글 버튼을 클릭해야 한다는 점이었다.
- 실습 당시 활용했던 '유튜브 프리미엄 프로모션 닫기 버튼 클릭'코드를 써봤지만, driver에는 'findcss_element'라는 기능이 없다는 오류 문구가 뜰 뿐이었다.
- 이래저래 시도하던 중 우리팀 PL님이 버튼을 해결했다는 희소식에 코드를 사용할 수 있었다.
🤗무한감사 우리 PL님🤗 - 유튜브 일반 동영상과 같은 부분은 생략하고 기록하고자 한다.
1) 댓글 버튼 클릭해 활성화 시키기
- 댓글 클릭을 위해 새로운 모듈을 임포트한 후, 댓글 버튼을 감싸고 있는 태그의 ID 이름을 selector로 지정한다.
from selenium.webdriver.common.by import By
driver.find_element(By.CSS_SELECTOR, "#comments-button").click()2) 코드 그대로 활용해 크롤링하기
- 댓글이 수집되어 확인해보니 천개가 넘는 댓글이 있었지만 20개만이 수집되어 있었다.
- 스크롤이 되지 않아 수집되지 않은 것이라는 판단에 다들 해결방안을 고민했다.
- 마우스 커서를 댓글 팝업창 위에 올릴 수 있도록 커서 위치를 조정하는 방안부터 스크롤이 불가능 하면 있는 정보를 활용하자는 취지로 댓글 작성 시기를 클릭해 원본 동영상으로 이동하도록 코딩하고 그 곳에서 크롤링하는 방법이 나오기도 했다.
- 교수님께 도움을 요청했고 결론은 예상한대로 스크롤이 댓글 팝업창이 아닌 이전 화면에서 이루어지고 있었기 때문이었다.
3) 댓글 창에서 스크롤하기
# locator(즉, 스크롤할 위치) 지정
reply_body = driver.find_element(By.XPATH, "//div[@id='contents']")
# 참고. selector로도 지정가능 -> reply_body = driver.find_element(By.CSS_SELECTOR, "#contents")
last_height = driver.execute_script("return arguments[0].scrollHeight", reply_body)
while True:
driver.execute_script('arguments[0].scrollTop = arguments[0].
scrollTop + arguments[0].scrollHeight;', reply_body)
time.sleep(1.5)
new_height = driver.execute_script("return arguments[0].scrollHeight" , reply_body)
print('last_height: ', last_height, 'new_height: ', new_height)
if new_height == last_height:
break
last_height = new_height
time.sleep(1.5)-
일반 유튜브 동영상과 달리 팝업으로 댓글창이 뜨기 때문에 댓글이 속한 div를 변수(reply_body)로 설정해 그 안에서 최대 스크롤 값을 가져올 수 있도록 한다.
-
이 때, 댓글이 속한 div의 Xpath나 css selector의 이름으로 수집 가능하다.
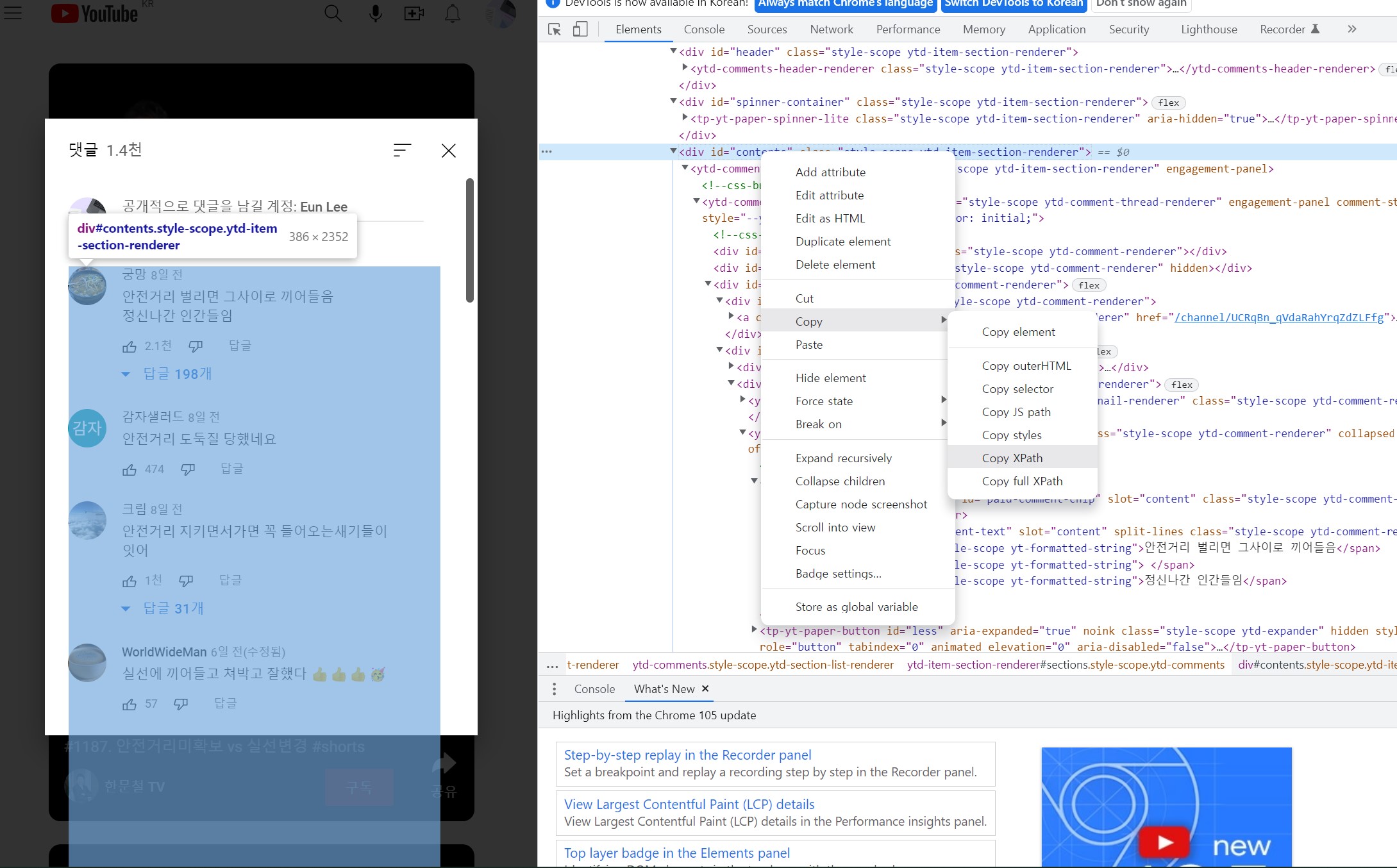
-
교수님께서 작성하신 Xpath와 내가 실제로 Xpath를 복사한 값이 달라서 고민 중이다. 원래 복사되는 값은 @id="contents" 인데, 작은 따옴표로만 코드가 실행된다. 아마 큰 따옴표로 감싸진 상황에서 큰 따옴표로 또 감싸면 안 되는 것 같긴 한데 다시 확인이 필요하다.
-
window 객체의 scrollTo는 문서를 지정된 좌표로 스크롤해주는 기능을 한다.
-
.scrollTop()은 선택한 요소의 스크롤바 수직 위치를 반환하거나 스크롤바 수직 위치를 수집한다.
-
arguments[0]' means first index of page starting at 0.
-
Where an 'Element' is the locator on the web page. (이 코드에서는 reply_body)
-
스크롤 참고사이트: https://www.guru99.com/scroll-up-down-selenium-webdriver.html (자바스크립트를 활용한 코드이긴 하지만 참고 가능)
