1. KNeighborsClassifier 알고리즘 활용한 타이타닉 생존자 예측
1) 문제정의
- KNeighborsClassifier 타이타닉 생존자(1), 사망자(0) 예측
2) 데이터 준비하기
import pandas as pd
import seaborn as sns
# 원래 차트 그리는 라이브러리인데, 제공하는 데이터 셋 활용하고자 함
df = sns.load_dataset('titanic')
df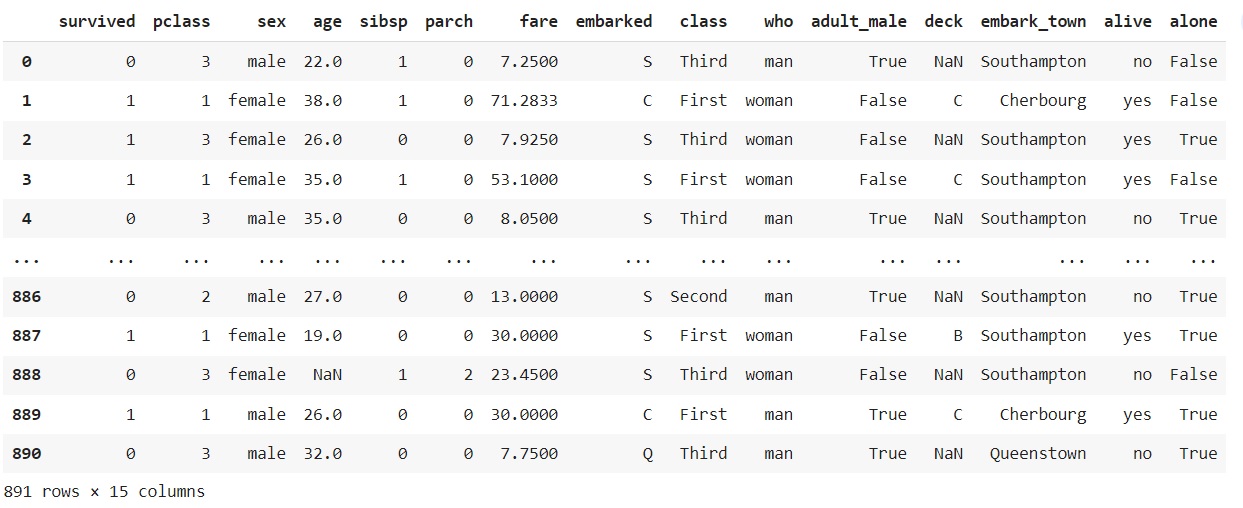
3) 데이터 탐색 및 데이터 전처리
-
df.info()를 통해 데이터 구성과 형태를 확인한다.
-
독립변수(x)와 종속변수(y)가 하나의 df에 통합되어 있어 분리 추출 필요
-
머신러닝은 NaN값을 반드시 처리해줘야 하는데 그 방법은 값을 채워주는 것과 삭제하는 것 두 가지 방법이 있다.

-
NaN 값이 많은 deck는 삭제하여야 하고 embaked와 중복된 데이터를 가지는 embarked_town 역시 삭제한다.
rdf = df.drop([‘deck, ‘embarked_town’], axis =1)
#해당 데이터를 포함한 열 전체 삭제를 위해 열 기준을 부여
rdf.info()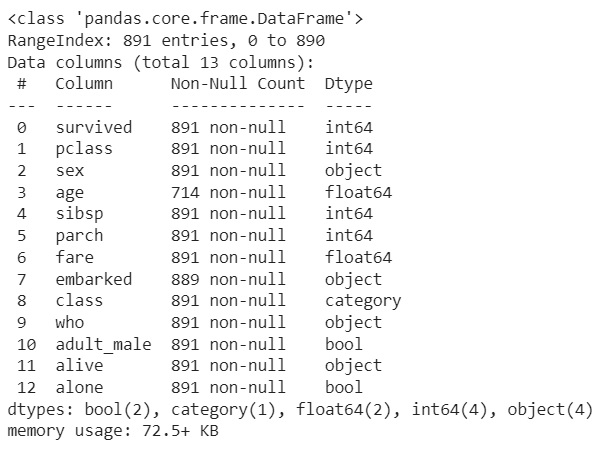
rdf = rdf.dropna(subset=[‘age’], how=’any’, axis=0)
#여기서 how = ‘any’는 기본값
#나이 열에 NaN값이 있다면 그 값이 속한 모든 행을 삭제하라는 의미- age 데이터를 삭제하는 것은 바람직하지 않다. 재난 상황에서 나이는 생존 순서에 큰 영향을 미치는 요소이기 때문
- 나이가 채워지지 않은 행(rows)만 지우자.
- 비운 값을 임의의 값을 주면 수치에 영향을 주기 때문에 해당 행 삭제(891 -> 714; 177건 삭제)
- age 컬럼을 빼고 학습시키는 것도 한 방법임
rdf.head(150)
- 수정된 데이터를 확인한다.
4) 학습에 필요한 컬럼(feature)을 추출
- 생존 시 큰 영향을 끼치는 feature위주로 추출
- 생존여부(survived), 객실등급(pclass), 성별(sex), 나이(age), 같이 탑승한 형제/배우자(sibsp), 부모자녀수(parch)
rdf = rdf [['survived','pclass','sex','age','sibsp','parch']]
rdf.head()
- 데이터를 살펴보니 성별 컬럼의 값이 범주형(; 중간이 없음 남성이거나 여성임)으로 구성되어 있다.
- male=0, female=1 수치이기 때문에 큰 수치를 가진 값이 가중치를 받게 되면서 부각됨.(더 찾기 쉬워짐) -> 여성이 더 중요한 것처럼 보임 따라서 원핫 인코딩 활용한다.
- 원핫 인코딩 -> male[1,0], female[1,0]
- 동일한 비교조건으로 만들어줌, 내 성별처리될 때 1값을 갖도록 -> 언제든 1만 찾으면 된다.
- 인코딩 중요성: 같은 데이터를 어떻게 인코딩(전처리) 했기에 성능이 좋아졌는지도 중요한 issue임
onehot_sex = pd.get_dummies(rdf['sex'])
# 컬럼 내 unique를 확인하는 절차. 2가지 성별로 이루어진 것 -> 컬럼 형태로 제공해줌
onehot_sex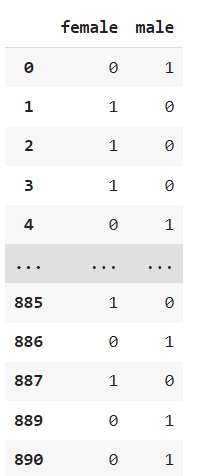
- 위와 같이 만든 성별 컬럼을 기존의 rdf와 머지한다.
ndf =pd.concat([rdf, onehot_sex], axis =1)
ndf.head()
- 이후 필요없어진 기존 성별 컬럼을 삭제한다.
del ndf['sex']
#이 코드도 가능하다: ndf.drop(['sex'], axis = 1, inplace =True)5) 데이터셋 분리하기
- 문제지와 정답지가 한 개의 데이터프레임에 들어있기 때문에 두 개를 분리하자.
X = ndf[['pclass','age', 'sibsp', 'parch', 'female', 'male']]
y = ndf['survived']- ndf -> 문제집(data, feature, 독립변수) X과 정답지(target, label, 종속변수) y로 데이터 분리
X.shape- 결과값: (714, 6)
y.shape- 결과값(714, )
- Train과 Test 데이터로 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 7)- 데이터 확인
X_train.shape- 결과값: (499, 6)
X_test.shape- 결과값: (215, 6)
6) 이웃의 수(결정경계)에 따른 성능평가
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3)- 이웃의 수를 3으로 설정하여 성능평가
#이웃에 수에 따른 정확도를 저장할 리스트 변수 선언
train_scores = []
test_scores = []
num_settings = range(1,11) #유지 보수 용이성을 위해 변수로 선언
for num_neighbor in num_settings:
#모델 생성
clf = KNeighborsClassifier(n_neighbors=num_neighbor)
clf.fit(X_train, y_train)
#훈련 세트 정확도 저장
train_scores.append(clf.score(X_train, y_train))
#테스트 세트 정확도 저장
test_scores.append(clf.score(X_test, y_test))
#예측 정확도 비교 그래프 그리기
plt.figure(dpi=100)
plt.plot(num_settings, train_scores, label='훈련 정확도')
plt.plot(num_settings, test_scores, label='테스트 정확도')
plt.ylabel('정확도')
plt.xlabel('이웃의 수')
plt.legend()
plt.show() # Sweet spot = 7
7) 모델성능평가
#y_test와 y_pred를 비교
#모델 설정 후 학습하기
clf = KNeighborsClassifier(n_neighbors = 7)
clf.fit(X_train, y_train)
#예측하기
y_pred = clf.predict(X_test)- y_pred는 머신러닝 모델을 이용해 예측한 y hat값을 말한다.
from sklearn import metrics
#모델의 성능평가 지표 계산 ->accuracy(정확도), precision, recall, f1_score
print('테스트 성능평가 n_neighbors = 7')
print('accuracy: ', metrics.accuracy_score(y_test, y_pred))
print('precision: ', metrics.precision_score(y_test, y_pred))
print('recall: ', metrics.recall_score(y_test, y_pred))
print('f1: ', metrics.f1_score(y_test, y_pred))- 결과값
테스트 성능평가 n_neighbors = 7
accuracy: 0.8186046511627907
precision: 0.8205128205128205
recall: 0.7191011235955056
f1: 0.7664670658682635
knn_report = metrics.classification_report(y_test, y_pred)
print(knn_report)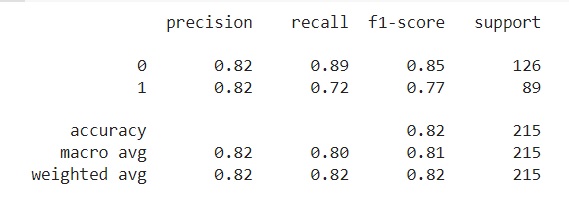
2. 선형회귀모델
1) 선형회귀함수(wave 데이터 셋)
1-1) 데이터 준비하기
import mglearn
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
X, y = mglearn.datasets.make_wave(n_samples=1000)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 7) - 라이브러리 임포트 후 1000개의 데이터를 불러와 7:3의 비율로 훈련과 테스트 데이터 분리하기
X_train.shape
- 결과값: (700,1)
- feature가 1개인 700개의 훈련 데이터
X_test.shape- 결과값: (300,1)
- feature가 1개인 300개의 테스트 데이터
1-2) 모델 설정하기
lr = LinearRegression()- 선형회귀함수를 lr 변수에 지정
1-3) 선형회귀모델로 데이터 학습하기
lr.fit(X_train, y_train)- 결과값: LinearRegression()
1-4) lr 객체 확인하기
- 선형함수의 절편과 기울기를 확인할 수 있다.
print('lr.coef_:', lr.coef_)
# w 가중치, 기울기
# 언더바는 설정한 변수가 아닌 클래스에서 제공해주는 변수 말하는 것)
print('lr._:', lr.intercept_)
# 절편- 결과값:
lr.coef: [0.45623134]
lr.: 0.06677447605800867
1-5) 성능평가
- score() 함수 -> R2(결정계수; 0-1 사이 값으로 나옴) -> 1과 가까우면 예측을 잘한 모델
- 오차 범위를 봐서 오차율이 낮아 가장 비슷하게 예측한 모델을 찾는 것.
- 훈련과 테스트 데이터의 차이를 확인하기
print('훈련 세트의 R2: ', lr.score(X_train, y_train))
print('테스트 세트의 R2: ', lr.score(X_test, y_test))-
결과값:
훈련 세트의 R2: 0.6066271469632917
테스트 세트의 R2: 0.6491816600811464 -
최소 70점 이상은 나와야 활용가능 수준
-
이 모델은 underfitting된 상태임(과소적합)
참고. 과대적합 예시: 훈련 세트의 R2: 1, 테스트 세트의 R2: 0.602 -
linearRegression() 모델이 feature의 특성을 잘 이해하지 못한 상황
-> 모델 변경해야 함(왜냐면 코드에서 설정할 수 있는 것이 없기 때문에) -
지금 데이터 셋에 맞지 않는 모델인 것.
-
다른 특징을 살려 가중치를 주는 등 다른 설정을 가진 모델이 필요
2) 선형회귀함수(보스턴 주택가격 데이터 셋)
2-1) 데이터 준비하기 및 모델 학습하기
#데이터 준비하기
X, y = mglearn.datasets.load_extended_boston()
#훈련과 테스트 데이터로 분리하기
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 7)
#모델 학습하기
lr = LinearRegression().fit(X_train, y_train)- 머신러닝 모델 만들 때, 항상 데이터를 X.shape -> X_train.shape / X_test.shape를 확인해야 한다.
2-2) lr객체 확인하기
print('lr.coef_:', lr.coef_) # w 가중치, 기울기
print('lr._:', lr.intercept_) # 절편2-3) 성능평가
print('훈련 세트의 R2: ', lr.score(X_train, y_train))
print('테스트 세트의 R2: ', lr.score(X_test, y_test))- 결과값:
훈련 세트의 R2: 0.9362446974205851
테스트 세트의 R2: 0.653116377505280 - 과대적합된 상태 -> 복잡도 낮추기(feature 줄이기) -> 모델을 바꿔줘야 한다.
3. 릿지(ridge) 회귀
- 선형함수의 한계인 ‘과대적합’을 완화하기 위해 규제 기능이 있는 선형 모델
#라이브러리 임포트
from sklearn.linear_model import Ridge
ridge = Ridge().fit(X_train, y_train)
#alpha default 값 = 1.0(이미 1.0정도로 규제 받는 중)
3-1) 성능평가
print('훈련 세트의 R2: ', ridge.score(X_train, y_train))
print('테스트 세트의 R2: ', ridge.score(X_test, y_test))- 결과값:
훈련 세트의 R2: 0.8757324956698626
테스트 세트의 R2: 0.7634665096262168 - 여전히 과대적합된 상태 -> 복잡도 낮추기(feature 줄이기); 규제 조정
# alpha 값만 조정하여 성능평가
ridge10 = Ridge(alpha=10).fit(X_train, y_train)
print('훈련 세트의 R2: ', ridge10.score(X_train, y_train))
print('테스트 세트의 R2: ', ridge10.score(X_test, y_test))- alpha = 10 규제하는 값을 1에서 10으로 올리면 -> 공부를 덜 한다.
- 결과값:
훈련 세트의 R2: 0.7797772908465949
테스트 세트의 R2: 0.6875527140060758 - 규제를 줄였더니 과소적합이 되어버림
# alpha 값만 조정하여 성능평가
ridge001 = Ridge(alpha=0.1).fit(X_train, y_train)
print('훈련 세트의 R2: ', ridge001.score(X_train, y_train))
print('테스트 세트의 R2: ', ridge001.score(X_test, y_test))- alpha = 0.1 규제하는 값을 1에서 0.1으로내리면 -> 공부 더 한다.
- 규제를 아예 풀어주면 linear Regression이다.
- 결과값:
훈련 세트의 R2: 0.9125098146021692
테스트 세트의 R2: 0.8089413689482263
4. 라쏘(lasso) 회귀
- feature selelection을 스스로 하는 모델
import numpy as np
from sklearn.linear_model import Lasso
lasso = Lasso().fit(X_train, y_train)
print('테스트 세트의 R2: ', lasso.score(X_train, y_train))
print('테스트 세트의 R2: ', lasso.score(X_test, y_test))
print('학습에 사용한 특성 개수: ', np.sum(lasso.coef_!= 0)) - 결과값:
테스트 세트의 R2: 0.27862849764292086
테스트 세트의 R2: 0.2797470720895442
학습에 사용한 특성 개수: 4 (104개 중 단 4개만 사용)
import numpy as np
from sklearn.linear_model import Lasso
lasso001 = Lasso(alpha = 0.001).fit(X_train, y_train)
print('테스트 세트의 R2: ', lasso001.score(X_train, y_train))
print('테스트 세트의 R2: ', lasso001.score(X_test, y_test))
print('학습에 사용한 특성 개수: ', np.sum(lasso001.coef_!= 0))- 규제를 줄였더니 사용한 특성 개수가 증가함
- 결과값:
테스트 세트의 R2: 0.9199605151535164
테스트 세트의 R2: 0.8259021584252655
학습에 사용한 특성 개수: 77
lasso001.coef_
- 특성 104개가 모두 입력되어 있고 0으로 표시된 특성은 예측에 활용하지 않은 특성임
5. 자동차 연비 데이터셋을 활용하여 다양한 모델 성능평가하기
5-1) 문제정의
- 단순 회귀 모델을 사용하여 1970년대 후반/1980년대 초반 자동차연비(MPG)예측
5-2) 기본 라이브러리 임포트
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns5-3) 데이터 준비하기
df = pd.read_csv('/content/auto-mpg.csv', header= None) #컬럼명 없을 때 넘버링으로 대신해줘
df.columns = ['mpg','cylinders','displacement','horsepower','weight',
'acceleration','model year','origin','name']
df.head()

df.info() 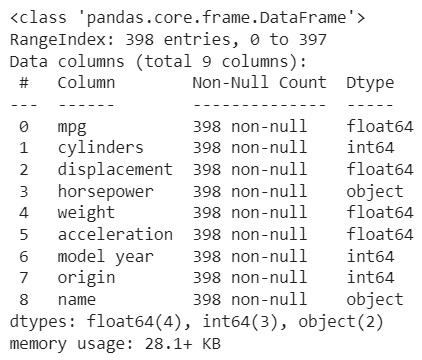
- 마력 컬럼은 숫자로 나와야 하는데 object로 타입이 정해졌다면 문제가 있는 것
- 시각화를 해보면 legend를 통해 중복인 데이터 등을 확인할 수 있다.
5-4) 데이터 전처리
df['horsepower'].unique()
- '?'데이터 포함한 행 삭제 필요
- ‘?’ -> NaN 값으로 변경 -> dropna 이용해 삭제 -> horsepower dtype float으로 변환
# 1) ? -> np.nan 형태로 변경
df['horsepower'].replace('?', np.nan, inplace=True) df.isna()sum()
# 2) NaN값 삭제
df.dropna(subset=['horsepower'], axis=0, inplace=True)- NaN값을 삭제하고 난 후 해당 열의 데이터를 확인해야 한다.
df['horsepower'].unique() 
# 3) 데이터 타입 object -> float
df['horsepower'] = df['horsepower'].astype('float')- 데이터 형태 변환 후 최종적으로 확인 필요
df.info()
5-5) feature 선택
- 단순회귀 -> 독립변수(feature) 1개로 예측
X = df[['weight']] #feature
y = df[['mpg']]- 다항회귀모델은 X로 설정하는 df컬럼에 다른 feature열을 추가해주면 된다.
- 이때 origin이나 cylinders과 같이 범주형인 데이터는 원핫인코딩을 한 후에 데이터를 돌려보면 모델의 정확도를 훨씬 높일 수 있다.
- 또한 일반적으로는 다양한 feature를 모두 활용해서 “양질의 데이터(;특정 특성을 가진 데이터가 많지 않고 각각의 데이터의 특성들이 전체 특성을 골고루 가진 상태),”를 테스트 하는 것이 좋기 때문에 활용가능한 feature는 모두 사용하는 것을 추천.
5-6) 데이터 셋 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 7)
X_train.shape- 결과값: (274, 1)
X_test.shape- 결과값: (118,1)
5-7) 모델 설정 후 학습하기
- 선형회귀함수
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
print('훈련 세트의 R2: ', lr.score(X_train, y_train))
print('테스트 세트의 R2: ', lr.score(X_test, y_test))-
결과값:
훈련 세트의 R2: 0.6874675811766633
테스트 세트의 R2: 0.702814782084018 -
릿지회귀함수
from sklearn.linear_model import Ridge
ridge = Ridge().fit(X_train, y_train)
print('훈련 세트의 R2: ', ridge.score(X_train, y_train))
print('테스트 세트의 R2: ', ridge.score(X_test, y_test))-
결과값:
훈련 세트의 R2: 0.6874675811766633
테스트 세트의 R2: 0.7028147827762304 -
라쏘회귀함수
from sklearn.linear_model import Lasso
lasso = Lasso().fit(X_train, y_train)
print('테스트 세트의 R2: ', lasso.score(X_train, y_train))
print('테스트 세트의 R2: ', lasso.score(X_test, y_test))
print('학습에 사용한 특성 개수: ', np.sum(lasso.coef_!= 0))- 결과값:
테스트 세트의 R2: 0.6874675569356257
테스트 세트의 R2: 0.7028388999869983
학습에 사용한 특성 개수: 1
참고. 릿지와 라쏘 모델을 이용하여 예측할 때 알파값을 조정할 수 있는데, 무작위를 알파값을 넣는 것보다 그래프를 그려보고 그 훈련 및 테스트 정확도의 추이를 확인한 후에 범위를 좁혀 조정하는 것이 효율적이다.
- 릿지 알파값 조정에 따른 예측 정확도 그래프
#릿지 최적의 알파값 확인
train_scores = []
test_scores = []
alpha = np.arange(0.0001, 100, 0.001) # 유지 보수 용이성을 위해 변수로 선언
for n in alpha:
# 모델 생성 및 학습
ridge = Ridge(alpha=n).fit(X_train, y_train)
# 훈련 세트 정확도 저장
train_scores.append(ridge.score(X_train, y_train))
# 테스트 세트 정확도 저장
test_scores.append(ridge.score(X_test, y_test))
# 예측 정확도 비교 그래프 그리기
plt.figure(dpi=100)
plt.plot(alpha, train_scores, label='훈련 정확도')
plt.plot(alpha, test_scores, label='테스트 정확도')
plt.ylabel('정확도')
plt.xlabel('알파 값')
plt.legend()
plt.show()

- 라쏘 알파값 조정에 따른 예측 정확도 그래프
#라쏘 최적의 알파값 확인
train_scores = []
test_scores = []
alpha = np.arange(0.0001, 1, 0.001) # 유지 보수 용이성을 위해 변수로 선언
for n in alpha:
# 모델 생성 및 학습
lasso = Lasso(alpha=n).fit(X_train, y_train)
# 훈련 세트 정확도 저장
train_scores.append(lasso.score(X_train, y_train))
# 테스트 세트 정확도 저장
test_scores.append(lasso.score(X_test, y_test))
# 예측 정확도 비교 그래프 그리기
plt.figure(dpi=150)
plt.plot(alpha, train_scores, label='훈련 정확도')
plt.plot(alpha, test_scores, label='테스트 정확도')
plt.ylabel('정확도')
plt.xlabel('알파 값')
plt.legend()
plt.show()

또한 max(train_scores) 나 max(test_scores)로 최대 정확도를 수치로 확인가능하다.
