1. 선형분류모델 로지스틱 회귀
1) 선형 분류 모델의 C(규제) 설정에 따른 결정 경계 비교
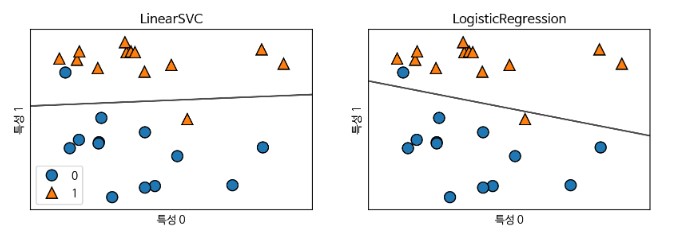
- 선형분류 모델에는 두가지 방식이 있는데 하나는 로지스틱 회귀 하나는 Linear SVC
- 두 모델이 어떻게 결정 경계를 그리는지 확인하기 위해 아래와 같이 차트를 그려보고자 한다.
#라이브러리 임포트
import mglearn
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
import warnings
warnings.filterwarnings('ignore')- 싸이킷 런에서 제공하는 분류함수를 임포트한다.
plt.rc('font', family ='NanumBarunGothic')
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
X, y = mglearn.datasets.make_forge()- 기본적으로 mglearn에서 제공하는 forge 데이터를 활용
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
for model, ax in zip([LinearSVC(max_iter=5000), LogisticRegression()], axes):
#()안에는 규제 관련 디폴트 값이 들어있는데 일반적으로 잘 기능하는 값이 들어가있다. 먼저 기본을 돌리고 규제 변경해서 적용한다.
clf = model.fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=False, eps=0.5,
ax=ax, alpha=.7)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)
ax.set_title(clf.__class__.__name__)
ax.set_xlabel("특성 0")
ax.set_ylabel("특성 1")
axes[0].legend()
plt.show()-
subplot이라는 함수가 두개의 차트를 그리게 되어 있어서 fig, axes로 받았다. 만약 fig를 사용하지 않을 것이라면 언더스코어로도 사용 가능
예시). _, axes = plt.subplots... -
'1, 2'은 행=1 열=2의 구조로 두개 차트 배치
-
기존에는 for문을 작성할 때 한 개의 변수만을 사용했다면 저 위의 for문처럼 반점을 기준으로 두 개의 변수를 사용할 수 있다.
-
다른 설정 값은 추가 공부가 필요함:(
-
로지스틱 회귀 모델이 아래쪽 세모 값을 최대한 제대로 분류하고자 결정경계를 세모에 바짝 붙여 그린 것을 확인할 수 있다.
mglearn.plots.plot_linear_svc_regularization()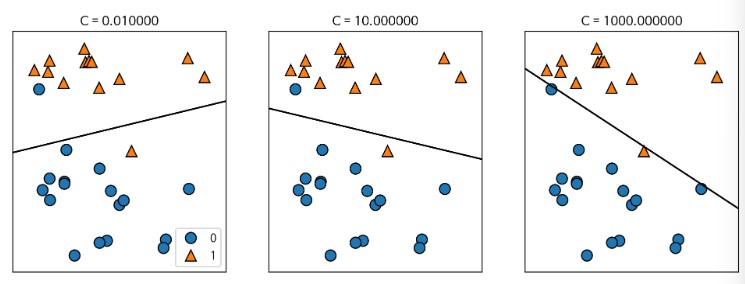
- C규제(공부를 덜 시키겠다 -> 과대적합을 피하겠다는 아이디어) 설정 값(디폴트 값은 1)
- C 설정 값이 낮으면 (0.01, 0.001, ...) 규제를 강화 -> 일반화를 시켜 -> 과소 적합시킴 -> (알파는 반대로 적용 규제 값이 작으면 규제 풀어주는 건데.. 니 맘대로 공부해)
- C 설정 값이 높으면(10, 100, 100, ...) 규제를 완화 -> 과대 적합
- 좌. 공부 좀 그만해(규제 강화)
- 중. 공부 좀 더 해(규제 완화)
- 우. 공부 너 하고 싶은대로 최대한 해봐(규제 거의 없앰) -> 동그라미를 아래 쪽으로 편입시키기 위해 결정경계를 바짝 그림(결국 동그라미가 아래쪽에 포함) -> 과대적합된 상태이기 때문에 좋은 모델은 아님!
2) 유방암 데이터셋을 사용한 로지스틱 회귀(Logistic Regression) 성능평가
- 규제 강도를 결정하는 C 설정에 따른 성능 비교(보통 10배 차이로 만듦)
- 1) 디폴트 값이 적용된 모델 그리기
- 2) 디폴트 값에 비해 10배 단위로 완화(10) 및 강화(0.1)된 모델 그리기
2-1) 데이터 준비하기
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# 데이터 가져오기
cancer = load_breast_cancer()
# 데이터 분리하기
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target,
stratify = cancer.target, random_state = 7)- 'stratify = cancer.target' 의미 = 데이터 비율을 기준으로 데이터를 분리해줘 즉,랜덤이 아니라 악성과 양성의 비율을 확인하고 학습과 테스트 데이터에 적정하게 분리
cancer.data.shape- 결과값: (569, 30)
X_train.shape # 75%- 결과값: (426, 30)
X_test.shape # 25%- 결과값: (143, 30)
y_train.shape- 결과값: (426, )
y_test.shape- 결과값: (143, )
2-2) 모델 설정하기
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression() # C = 12-3) 모델 학습하기
logreg.fit(X_train, y_train)2-4) LogisticRegression C=1(기본) 규제 L2 모델 성능평가
print('logreg 훈련 세트 점수: {:.8f}'.format(logreg.score(X_train, y_train)))
print('logreg 테스트 세트 점수: {:.8f}'.format(logreg.score(X_test, y_test)))- 결과값:
logreg 훈련 세트 점수: 0.96009390
logreg 테스트 세트 점수: 0.94405594
2-5) 모델 설정 및 학습 후 규제 L2 성능평가
# 규제 디폴트 값
print('----------------규제기본-----------------')
logreg = LogisticRegression().fit(X_train, y_train)
print('logreg 훈련 세트 점수: {:.8f}'.format(logreg.score(X_train, y_train)))
print('logreg 테스트 세트 점수: {:.8f}'.format(logreg.score(X_test, y_test)))
# 규제 강화
print('----------------규제강화-----------------')
logreg001 = LogisticRegression(C=0.01).fit(X_train, y_train)
print('logreg001 훈련 세트 점수: {:.8f}'.format(logreg001.score(X_train, y_train)))
print('logreg001 테스트 세트 점수: {:.8f}'.format(logreg001.score(X_test, y_test)))
# 규제 완화
print('----------------규제완화-----------------')
logreg100 = LogisticRegression(C=100).fit(X_train, y_train)
print('logreg100 훈련 세트 점수: {:.8f}'.format(logreg100.score(X_train, y_train)))
print('logreg100 테스트 세트 점수: {:.8f}'.format(logreg100.score(X_test, y_test)))- 결과값:
----------------규제기본-----------------
logreg 훈련 세트 점수: 0.96009390
logreg 테스트 세트 점수: 0.94405594
----------------규제강화-----------------
logreg001 훈련 세트 점수: 0.92957746
logreg001 테스트 세트 점수: 0.94405594
----------------규제완화-----------------
logreg100 훈련 세트 점수: 0.94366197
logreg100 테스트 세트 점수: 0.94405594 - 최종적으로 테스트 점수가 가장 높은 모델을 선택하는 것이 좋고
- 모델별로 테스트 점수가 같다면 훈련과 테스트 정확도 점수 차가 가장 적은 것이 가장 좋은 모델
- 규제 종류는 L1과 L2 노름을 사용할 수 있지만 디폴트 값으로는 L2를 사용한다.
# L2 규제에 대한 feature들의 가중치를 확인
plt.plot(logreg100.coef_.T, '^', label="C=100")
plt.plot(logreg.coef_.T, 'o', label="C=1")
plt.plot(logreg001.coef_.T, 'v', label="C=0.01")
plt.xticks(range(cancer.data.shape[1]), cancer.feature_names, rotation=90)
xlims = plt.xlim()
plt.hlines(0, xlims[0], xlims[1])
plt.xlim(xlims)
plt.ylim(-5, 5)
plt.xlabel("특성")
plt.ylabel("계수 크기")
plt.legend()
plt.show()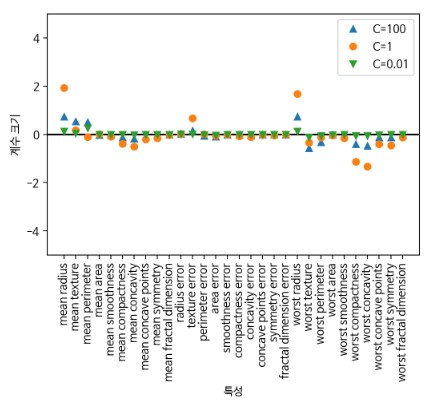
- 모든 feature를 사용하지만 가중치가 매우 낮음(미묘한 차이)
2-6) 모델 설정 및 학습 후 규제L1 성능평가
# 모델의 해석이 중요한 요소 일때도 규제 L1을 사용하며 몇가지 특성만 사용하므로
# 해당 모델에 중요한 특성이 무엇이고 효과가 어느 정도인지 설명하기 쉬움
# 규제 디폴트 값
print('----------------규제기본-----------------')
logreg = LogisticRegression(penalty='l1',solver='liblinear').fit(X_train, y_train)
print('logreg 훈련 세트 점수: {:.8f}'.format(logreg.score(X_train, y_train)))
print('logreg 테스트 세트 점수: {:.8f}'.format(logreg.score(X_test, y_test)))
# 규제 강화
print('----------------규제강화-----------------')
logreg001 = LogisticRegression(C=0.01, penalty='l1', solver='liblinear').fit(X_train, y_train)
print('logreg001 훈련 세트 점수: {:.8f}'.format(logreg001.score(X_train, y_train)))
print('logreg001 테스트 세트 점수: {:.8f}'.format(logreg001.score(X_test, y_test)))
# 규제 완화
print('----------------규제완화-----------------')
logreg100 = LogisticRegression(C=100, penalty='l1', solver='liblinear').fit(X_train, y_train)
print('logreg100 훈련 세트 점수: {:.8f}'.format(logreg100.score(X_train, y_train)))
print('logreg100 테스트 세트 점수: {:.8f}'.format(logreg100.score(X_test, y_test)))- 결과값:
----------------규제기본-----------------
logreg 훈련 세트 점수: 0.96009390
logreg 테스트 세트 점수: 0.94405594
----------------규제강화-----------------
logreg001 훈련 세트 점수: 0.91549296
logreg001 테스트 세트 점수: 0.91608392
----------------규제완화-----------------
logreg100 훈련 세트 점수: 0.98591549
logreg100 테스트 세트 점수: 0.95104895
# L1 규제에 대한 feature들의 가중치를 확인
plt.plot(logreg100.coef_.T, '^', label="C=100")
plt.plot(logreg.coef_.T, 'o', label="C=1")
plt.plot(logreg001.coef_.T, 'v', label="C=0.01")
plt.xticks(range(cancer.data.shape[1]), cancer.feature_names, rotation=90)
xlims = plt.xlim()
plt.hlines(0, xlims[0], xlims[1])
plt.xlim(xlims)
plt.ylim(-5, 5)
plt.xlabel("특성")
plt.ylabel("계수 크기")
plt.legend()
plt.show()
- 선택적 feature 적용으로 아예 사용하지 않는 feature가 있음
2. SVM(Supportive Vector Machine)을 활용한 타이타닉 생존자 예측
1) 문제정의
- SVM 사용하여 타이타닉 생존자(1), 사망자(0) 예측하는 이진 분류 모델로 정의
2) 기본 라이브러리 임포트
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt3) 데이터 준비하기
df = sns.load_dataset('titanic')4) 데이터 확인하기
df.head()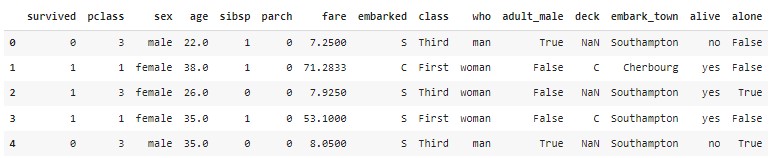
df.info()
5) 데이터 분석하기
df['survived'].value_counts()- 생존자(1)와 사망자(0)의 비율, 즉 예측할 값(y값)이 어떤 비율로 있는지 확인
- 결과값: 0=549, 1= 342
df['survived'].value_counts().plot.pie(autopct='%.2f')- y값의 비율을 파이 차트로 그려보기

df['survived'].value_counts().plot.barh()- y값의 비율을 바 차트로 그려보기

- 어떤 feature를 사용해 예측해야할지 판단하기 위해 각 feature와 y값인 survived의 연관성을 보여주는 차트를 그린다.
attrs = df.columns - 모든 feature를 다 그리고 싶을 때 위와 같이 df의 모든 컬럼을 attrs에 담는다.
plt.figure(figsize=(20,20), dpi=100)
for i, feature in enumerate(attrs):
plt.subplot(5,5,i+1)
sns.countplot(data=df, x=feature, hue='survived')
sns.despine()
- 차트 내에서 한 그래프가 확연히 눈에 띌 때 그 feature를 사용하는 것이 좋음
- 예를 들어 성별, 승선도시 등이 생존여부에 뚜렷한 차이를 보이는 것을 확인할 수 있다.
attrs = ['survived','pclass','sibsp','parch','sex','embarked'] - 특정 feature를 그리고 싶을 때, attrs 변수에 feature를 담는다.
plt.figure(figsize=(14,12), dpi=100)
for i, feature in enumerate(attrs):
plt.subplot(3,3,i+1)
sns.countplot(data=df, x=feature, hue='survived')
sns.despine()
- 위처럼 선택한 feature들만 그려진 것을 확인할 수 있다.
6) 데이터 전처리
df.isna().sum()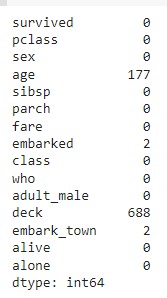
- 1) NaN이 많은 컬럼 삭제; 연령은 중요한 데이터이기 때문에 살리고 deck 삭제
- 2) 중복 컬럼인 embark_town 삭제
rdf = df.drop(['deck','embark_town'], axis=1)
rdf.info()
rdf = rdf.dropna(subset=['age'], how='any', axis =0) #NaN값만 삭제하므로 dropna
rdf.info()- 3) age 컬럼에 데이터가 없는 row 삭제; age가 NaN인 177건만 삭제

- 위처럼 나이 데이터 수에 맞춰 다른 feature의 수가 맞춰진 것을 확인할 수 있다.
most_freq = rdf['embarked'].value_counts(dropna=True)
most_freq - 결과값: <bound method Series.idxmax of S 554, C 130, Q 28
- 4) NaN 처리 방식에는 1) 삭제 2) 채우기 두 방식이 있는데 'embarked'가 사망 여부와 연관성이 짙기 때문에 2개를 버리지 않고 채워보자.
- 가장 비율이 높은 값으로 채워주기(수치화가 가능한 데이터면 평균이 가장 적절함)
rdf['embarked'].fillna(most_freq, inplace=True)
rdf.isna().sum()- 결과값: 'S'
rdf['embarked'].fillna(most_freq, inplace=True)
rdf.isna().sum()- embarked 열의 NaN 값을 승선도시 비율이 높은 도시로 채우기

- NaN값이 없어진 것을 확인할 수 있다.
ndf = rdf[['survived','pclass','sex', 'age','sibsp','parch','embarked']]
ndf.info()
- 5) 학습에 필요한 컬럼 선택하여 담고 정보 확인
ndf.head()- 전처리가 추가로 필요한지 확인하기 위해 출력
# 6-1) 원핫 인코딩 만들기
onehot_sex = pd.get_dummies(ndf['sex'])
onehot_embarked = pd.get_dummies(ndf['embarked'])
# 6-2) ndf 데이터프레임에 연결
ndf = pd.concat([ndf, onehot_sex], axis = 1)
ndf = pd.concat([ndf, onehot_embarked], axis = 1)
ndf.drop(['sex', 'embarked'], axis = 1, inplace = True)
ndf.head()- 6) 문자로 되어 있는 값을 변환 -> 원핫인코딩(범주형 데이터를 머신러닝 모델이 인식할 수 있도록 숫자형으로 변환) -> 필요없는 컬럼 삭제
- ex) 성별 male = [1,0] female = [0,1]
- ex) 승선도시 s = [1,0,0] c = [0,1,0] q = [0,0,1]

- 기존의 성별과 embarked 컬럼이 삭제된 것을 확인할 수 있다.
7) 데이터분리하기
X = ndf[['pclass', 'age', 'sibsp', 'parch', 'female','male', 'C', 'Q', 'S']]
y = ndf[['survived']]
# X (feature, 독립변수, 문제지) 값을 정규화
from sklearn import preprocessing
X = preprocessing.StandardScaler().fit(X).transform(X)
X - 머신러닝은 데이터의 범위가 너무 넓으면 학습해 패턴화하기가 어려움 따라서 정규화(0과 1사이로 값을 줄여줌; 스케일 조정)
- 사람이 해석할 수 없는 상태이지만 머신러닝은 아래와 같이 범위를 축소시키면 더 이해를 잘 함
#train, test set으로 분리(7:3)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify = y, random_state = 7)
print('train shape', X_train.shape)
print('test shape', X_test.shape)- 결과값:
train shape (499, 9)
test shape (215, 9
8) SVM 분류 모델 설정하기
from sklearn import svm
svm_model =svm.SVC(kernel = 'rbf')- 참고1. 모델 객체 생성 'kernel = 'rbf''
- 참고2. 벡터 공간을 맵핑하는 함수 -> 선형(linear), 다항식(poly), 가우시안 RBF9(rbf), 시그모이드(sigmoid)
9) 모델 학습하기
svm_model.fit(X_train, y_train)10) 모델 성능평가
print('logreg 훈련 세트 점수: {:.8f}'.format(svm_model.score(X_train, y_train)))
print('logreg 테스트 세트 점수: {:.8f}'.format(svm_model.score(X_test, y_test)))- 결과값:
logreg 훈련 세트 점수: 0.81563126
logreg 테스트 세트 점수: 0.81395349
11) 모델 성능평가 지표 계산
from sklearn import metrics
y_pred = svm_model.predict(X_test)
# 모델의 성능평가 지표 계산 ->accuracy(정확도), precision, recall, f1_score
print('accuracy: ', metrics.accuracy_score(y_test, y_pred))
print('precision: ', metrics.precision_score(y_test, y_pred))
print('recall: ', metrics.recall_score(y_test, y_pred))
print('f1: ', metrics.f1_score(y_test, y_pred))- recall이 중요한 지표인데 값이 높지 않기 때문에 다른 모델을 사용해야겠다는 판단에 이름
- 결과값:
accuracy: 0.813953488372093
precision: 0.8309859154929577
recall: 0.6781609195402298
f1: 0.7468354430379747
