✅ 프로그래머스 단어 변환
문제링크 : https://programmers.co.kr/learn/courses/30/lessons/43163
두 개의 단어 begin, target과 단어의 집합 words가 매개변수로 주어질 때, 최소 몇 단계의 과정을 거쳐 begin을 target으로 변환할 수 있는지 return 하도록 solution 함수를 작성해주세요.
접근방식
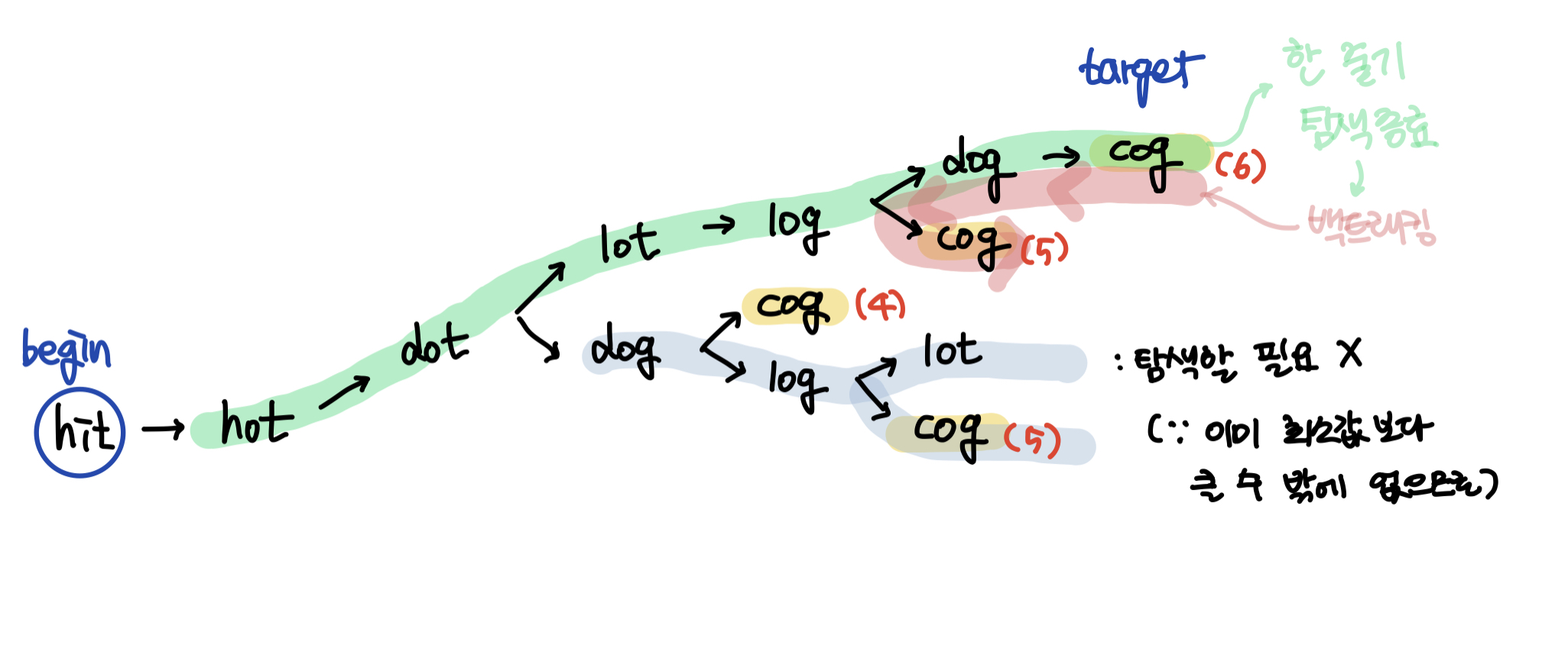
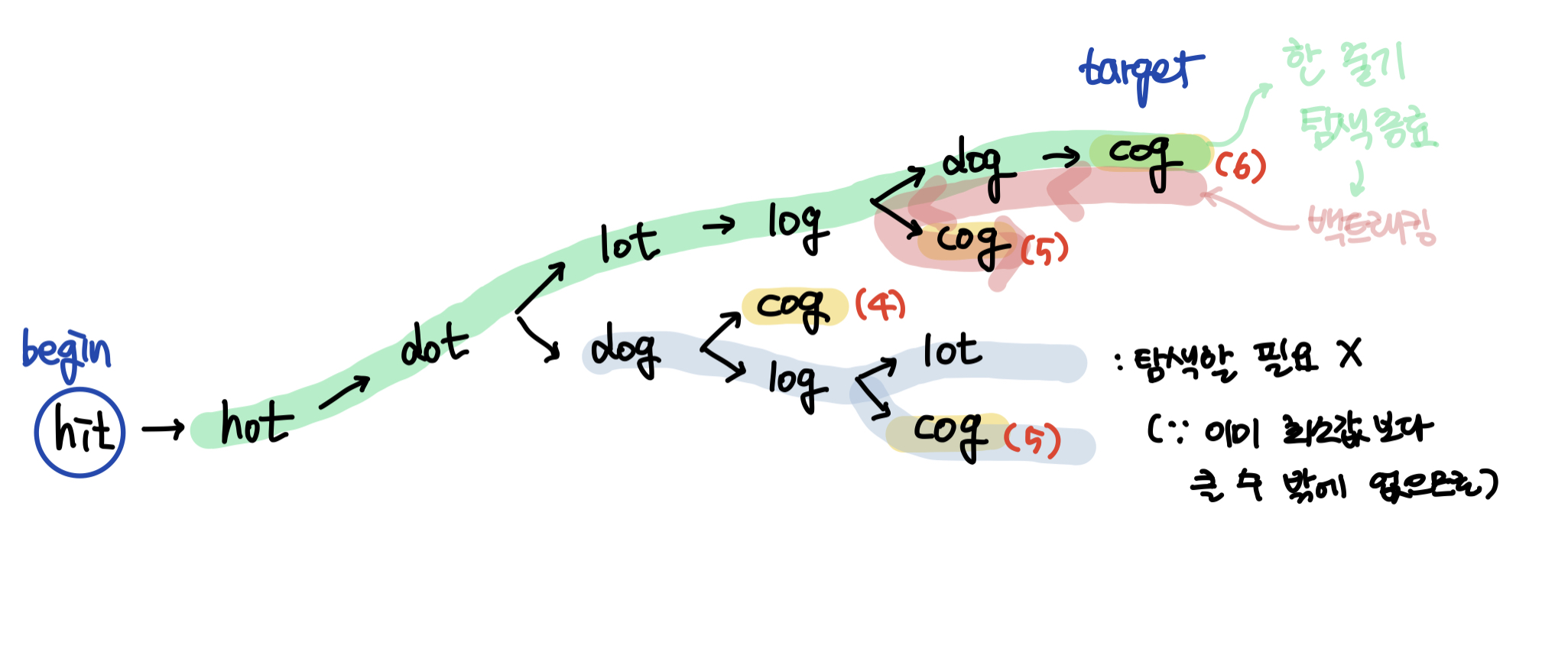
이렇게 예제 1번의 풀이과정을 가시화시켜보면 하나의 줄기를 탐색해나가며 변환단계의 최소값을 구하면 된다는 것을 알 수 있다.
- 하나의 줄기씩 한 방향으로 갈 수 있을때까지 탐색해나가므로 dfs 풀이법을 떠올릴 수 있다.
- 변환 단계의 최소값이므로 한번 사용한 단어는 재사용하지 않는것이 암묵적인 규칙임을 알 수 있다. (단어를 재사용하면 변환단계가 더 길어지므로 최소값이 될 수 없으므로 해가 될 수 없다.)
-> 따라서 단어별로 방문여부를 체크할 배열이 필요하다. - 탐색함수를 재귀적으로 호출해나가면서
target단어와 같아졌을때는 함수호출을 종료하는 종료조건을 염두해둔다. - 문제에서 한 번에 한 개의 알파벳만 바꿀 수 있다고 하였다. 따라서 하나의 줄기씩 탐색을 해나갈때
words벡터에서 현재의 단어와 한글자만 다른 단어만이 탐색 후보가 될 수 있으므로 다른 문자가 한개인지 판별하는 함수도 작성해야한다.
문제 풀이 방법
가장 간단해 보이는 다른문자가 한개인지 판별하는 함수부터 작성해보자.
매개변수로 두개의 문자열을 받아 for문을 돌려가며 단어가 다를때마다 count에 1을 더해가며,
한글자만 다를때만 단어 변환을 진행 할 수 있으므로 count가 1보다 클때는 false를 반환하게끔 작성하면 된다.
bool check_diff(string a, string b){
int dif_cnt =0;
for(int i=0; i<a.size();i++){
if(a[i]!=b[i]){
dif_cnt++;
}
}
// 다른 문자가 1개일때
if(dif_cnt==1){
return true;
}
// 다른문자가 한개가 아닐때
return false;
}재귀함수를 작성해보자.
이제 dfs를 구현하기위해 재귀함수를 작성해보자.
주의해야될 것은 target 문자열과 동일하게 변환이 완료되어 재귀 호출이 종료되었을 경우, 다른 최소 경로의 변환과정이 있을 수 있기 때문에 해당 탐색과정에서 다시 가장 가까운 갈림길로 돌아와서 (back-tracking) 이곳부터 다른 방향으로 다시 탐색을 진행해야한다는 것이다.
의사코드로 나타내보자면 다음과 같다.
for(int i=0; i<words.size();i++){
if(한개의 문자만 다르다 && 탐색하지 않은 단어이다){
1. 방문표시
-> visited[i]=true;
2. 그 단어부터 탐색을 다시 시작하기 위해 재귀적으로 함수를 호출한다.
이때 단계가 하나 추가되었으므로 step+1을 인자로 넘긴다.
-> dfs(...,step+_1);
3. dfs 재귀 호출하여 종료되어 여기로 돌아오면, 백트래킹(방문 표시 해제)하여 다음분기점부터 다시 탐색을 시작한다.
-> visited[i]=false;
}
}dfs 구현과정에 있어서 중요한 요소로는 종료조건과 재귀함수의 매개변수로 무엇을 지정할 것인지이다.
종료조건은 DFS함수를 호출해나가며 탐색중인 단어와 target단어가 같아졌을때이므로
if(current==target){
return;
}이렇게 나타낼 수 있다.
여기서 현재 탐색중인 단어가 매개변수로 주어져야 종료조건으로써 참조를 할 수 있다는 점을 알 수 있다.
또한 DFS함수를 재귀적으로 호출할때 단어 변환이 몇단계째 진행되고있는지를 넘겨주어야 현재 탐색중인 단계가 최소값인지 비교할 수 있다.
따라서 dfs함수의 매개변수는 다음과 같다.
void dfs(string current, string target, vector<string>words, int step){
// current : 현재 탐색중인 단어
// step : 현재 단어 변환이 몇단계째인지
words배열은 50개이하의 단어로 이루어져있다고 하였으므로 단어의 변환 과정은 최대 50단계 일것임을 알 수 있다.
따라서 전역변수 answer를 50으로 초기화해놓은 후에,
dfs함수 내에서 매개변수로 주어진 step과 answer의 최소값을 비교해나가며 answer값을 갱신해나가면 전역변수 answer은 항상 최소값을 유지하게 된다.
answer = min(answer,step);
또한 dfs함수 호출시에 answer(항상 최소값임)보다 큰 step이 매개변수로 전달되어 호출되었을 경우에는 어차피 해가 될 수 없기때문에 탐색할 필요가 없어서 바로 return해줌으로써 효율적으로 탐색을 진행 할 수 있다.
if(answer <= step)
return;전체 코드
주석 참고해서 이해하시면 좋을 것 같습니다 :)
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
int answer = 50;
bool visited[50];
//다른 문자가 1개인지 확인하는 함수
bool check_diff(string a, string b){
int dif_cnt =0;
for(int i=0; i<a.size();i++){
if(a[i]!=b[i]){
dif_cnt++;
}
}
// 다른 문자가 1개일때
if(dif_cnt==1){
return true;
}
// 다른문자가 한개가 아닐때
return false;
}
void dfs(string begin, string target,vector<string>words,int step){
// step이 이전에 찾은 answer보다 크면 탐색할 필요가 없다
if(answer <= step)
return;
if(begin==target){
answer = min(answer,step);
return;
}
for(int i=0; i<words.size();i++){
// 한개의 문자만 다르고 방문 하지 않은 단어이면 탐색 시작
if(check_diff(begin,words[i]) && !visited[i]){
visited[i]=true;
// 그 단어부터 탐색을 다시 시작한다. 단계가 하나 추가되었으므로 step+1을 인자로 넘긴다.
dfs(words[i],target,words,step+1);
// dfs 재귀 호출하여 종료되어 여기로 돌아오면, 백트래킹 (방문 표시 해제) 하여 다음분기점부터 다시 탐색을 시작한다.
visited[i]=false;
}
}
return;
}
int solution(string begin, string target, vector<string> words) {
dfs(begin,target,words,0);
// 탐색후 target문자열을 만나지 못했을 때
if(answer == 50)
return 0;
return answer;
}
끝 💫
dfs함수내에서 다른 단어개수가 한개인지 확인하게끔 작성했을때는 너무 복잡했었는데 함수를 분리하니 훨씬 직관적이고 코드 작성도 더 용이해졌다.
step값이 answer보다 클때는 애초에 탐색할필요없다는것을 이용해서 탐색 case를 줄이는 코드가 없어도 모든 테스트케이스가 통과되긴 하지만 넣어주는게 효율성 측면에서 더 좋을 것 같다.
그리고 dfs,bfs 문제를 풀다보면 이렇게 백트래킹을 해야되는 경우가 생겨서 백트래킹이 필요한 경우와 아닌 경우가 어떤건지 헷갈렸었는데, 말그대로 이전 노드로 돌아가서 다시 탐색이 필요한 경우에 넣어주면 된다는 걸 명심해야겠다.
이런것들을 더 잘 생각해내는 연습을 많이 해봐야겠다!
나중에 다시풀면 못풀듯하다ㅠㅠ
꼭 다시풀어보자 🤦♀️
프로그래머스 bfs/dfs 유형의 다른 문제 풀이법
