Dive into Deep Learning
1.Dive into Deep Learning
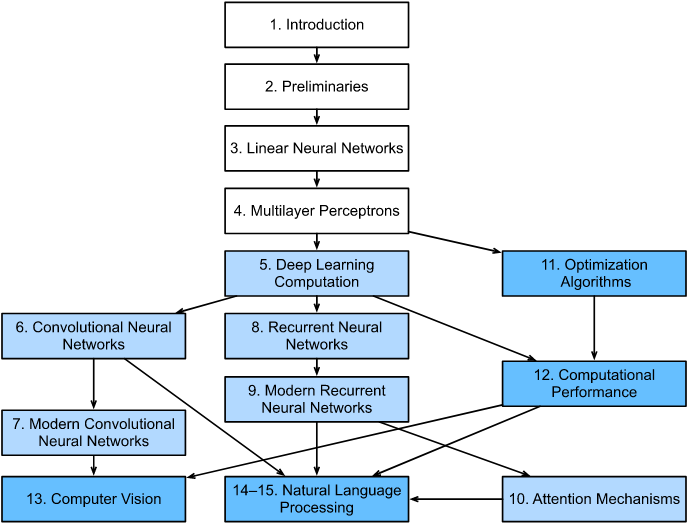
Book's structure
2.1. Introduction

학습내용: https://d2l.ai/chapter_introduction/index.html 1. Introduction 최근까지, 우리가 사용하는 거의 모든 컴퓨터 프로그램들은 sw developer들에 의해서 코딩되어왔다. 이런 제품이 시스템을 100% 자동으로
3.2. Preliminaries

딥러닝 시작을 위해, 몇가지 기본 스킬을 쌓을 필요가 있다. 모든 기계학습은 데이터에서 정보를 빼내는 것에 초점을 둔다. 그래서 우리는 데이터를 저장하고, 다루고, 전처리하는 전형적인 스킬부터 배우기 시작할 것이다.더나아가, 기계 학습은 일반적으로 큰 데이터 세트를 사
4.2.1. Data Manipulation
2.1. Data Manipulation 어떤 일이든 해내기 위해서는, 데이터를 저장하거나 다루는 어떤 방법이 필요하다. 일반적으로 우리가 데이터를 가지고 해야할 두가지 중요한 일이 있다: (i) 데이터를 얻기 (ii) 컴퓨터에 들어오면 데이터를 처리하기. 데이터를
5.2.2. Data Preprocessing
강의 : https://d2l.ai/chapter_preliminaries/pandas.html지금까지 우리는 이미 tensors에 저장된 데이터를 다루는 다양한 기술을 소개했다. 딥러닝을 적용해서 실제 문제를 해결하기 위해서는, tensor 형식으로 깔끔하게
6.2.3. Linear Algebra
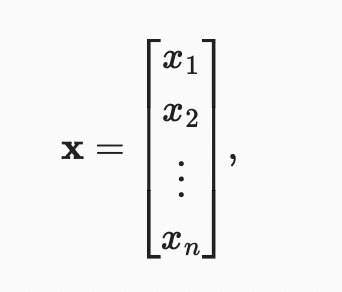
강의 : https://d2l.ai/chapter_preliminaries/linear-algebra.html이제 데이터를 저장하고 조작할 수 있으므로 이 책에서 다루는 대부분의 모델을 이해하고 구현하는 데 필요한 기본 linear algebra(선형 대수)의
7.2.4. Calculus
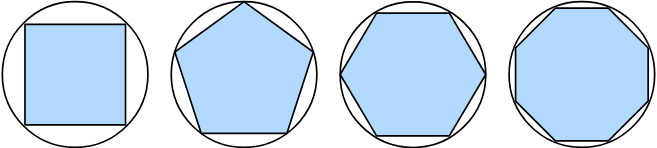
강의: https://d2l.ai/chapter_preliminaries/calculus.html다각형의 면적을 찾는 것은 고대 그리스인들이 polygons(다각형)을 삼각형으로 나누고 그들의 면적을 합한 2,500년 전까지 신비롭게 남아 있었다. 원과 같은
8.2.5. Automatic Differentiation
강의: https://d2l.ai/chapter_preliminaries/autograd.htmlsection 2.4에서 설명했듯이, 미분은 거의 모든 딥러닝 최적화 알고리즘에 중요한 단계이다. 이러한 도함수를 얻기 위한 계산은 간단하지만, 일부 기본 미적분만
9.2.6. Probability
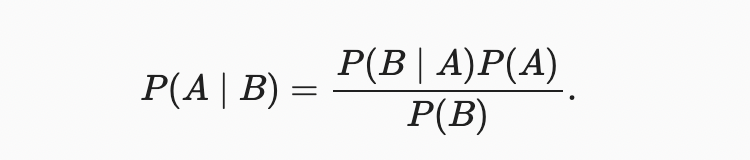
강의: https://d2l.ai/chapter_preliminaries/probability.html 2.6. Probability 어떤 형태로든지, 기계학습은 예측을 만드는 것이다. 우리는 환자의 임상 병력을 고려할 때 내년에 심장마비를 겪을 확률을 예측하고 싶을
10.3. Linear Neural Networks
강의 : https://d2l.ai/chapter_linear-networks/index.htmldeep neural networks(심층 신경망)에 대한 세부 사항에 들어가기 전에 신경망 훈련의 기본 사항을 다루어야 한다. 이 챕터에서는 간단한 신경망 아키텍
11.3.1. Linear Regression
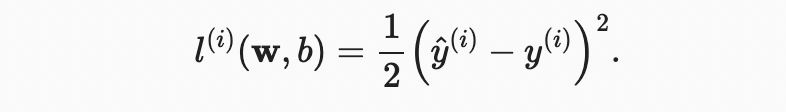
3.1. Linear Regression 회귀 분석은 하나 이상의 독립 변수와 종속 변수 사이의 관계를 modeling하는 방법 집합을 말한다. 자연과학과 사회과학에서 회귀의 목적은 입력과 출력 사이의 관계를 characterize(특징짓는)하는 데 있다. 반면에 기계
12.3.2. Linear Regression Implementation from Scratch
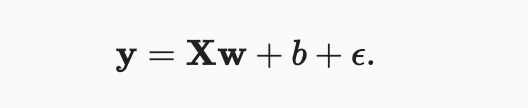
이제 선형 회귀 분석의 핵심 아이디어를 이해했으니 코드의 실제 구현을 통해 작업을 시작할 수 있다. 이 섹션에서는 데이터 파이프라인, 모델, 손실 함수 및 미니배치 확률적 그레이디언트 강하 옵티마이저를 포함한 전체 방법을 처음부터 구현한다. 현대의 딥 러닝 프레임워크는
13.3.3. Concise Implementation of Linear Regression
In this section, we will show you how to implement the linear regression model from Section 3.2 concisely by using high-level APIs of deep learning fr
14.3.4. Softmax Regression
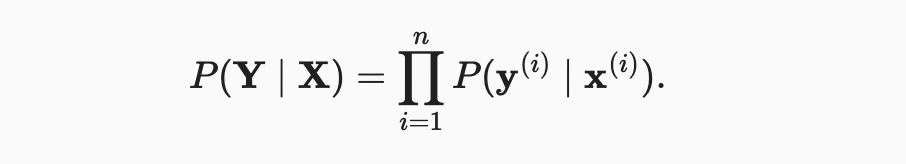
3.4. Softmax Regression 섹션 3.1에서는 선형 회귀를 도입하여 섹션 3.2의 처음부터 구현 작업을 수행하고 섹션 3.3의 딥 러닝 프레임워크의 고급 API를 사용하여 무거운 리프팅을 수행했다. 회귀는 how much? or how many?를 대