the system uses neural representations to separate and recombine content and style of arbitrary images
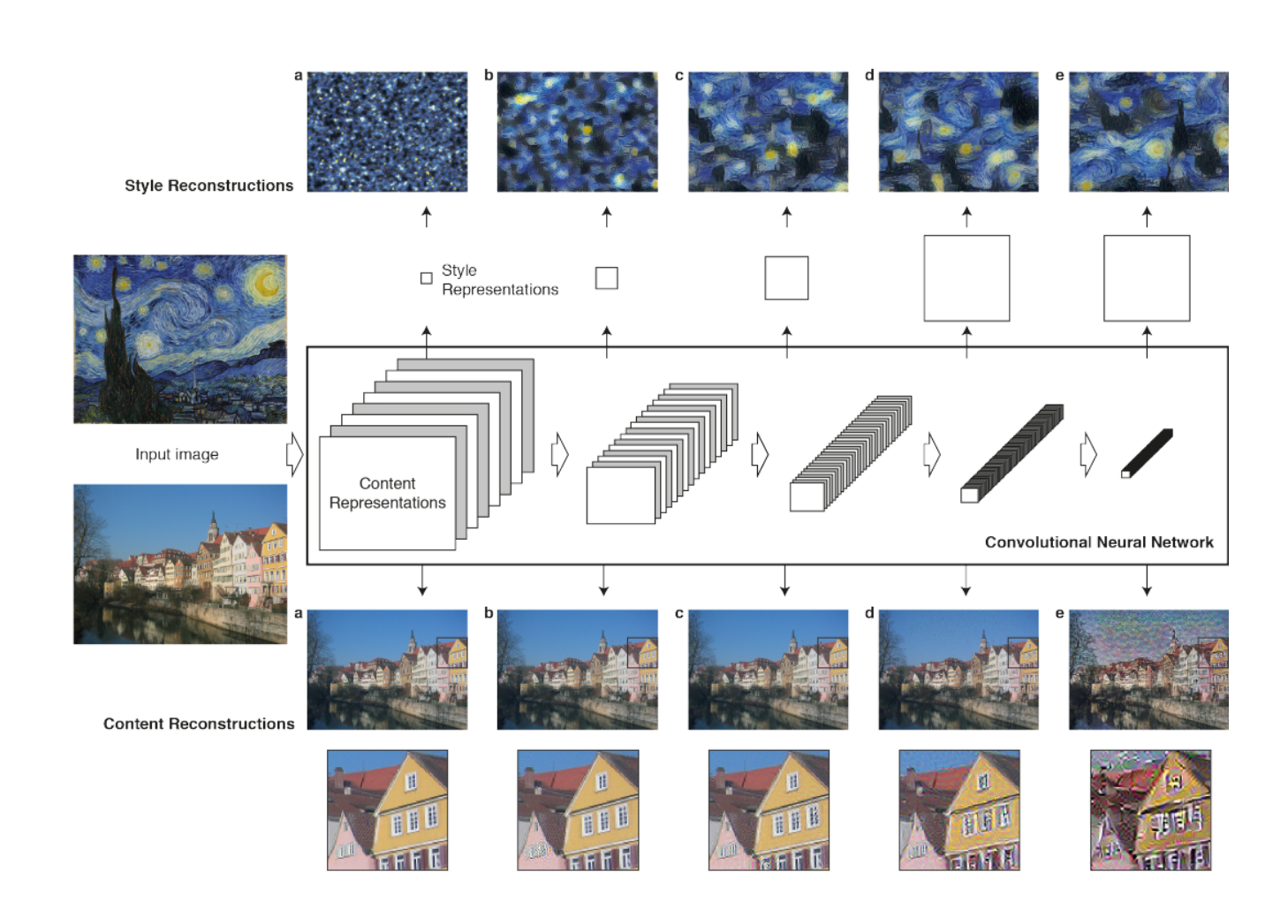
Along the CNN, the input image is transformed into representations (actual content of the image compared to its detailed pixel values)
The representations of content and style in the CNN are separable
Previous approaches(non-photorealistic rendering) mainly rely on non-parametric techniques to directly manipulate the pixel representation of an image.
By using DNN trained on object recognition, it carry out manipulations in feature spaces(high level of an image)
Perfoming a complex-cell would be a possibel way to obtain a content-independent representation of the appearance of a visual input.
Methods
It used the feature space provided by the 16 convolutional and 5 pooling layers of the VGG19 Network.(NO fully connected layers)
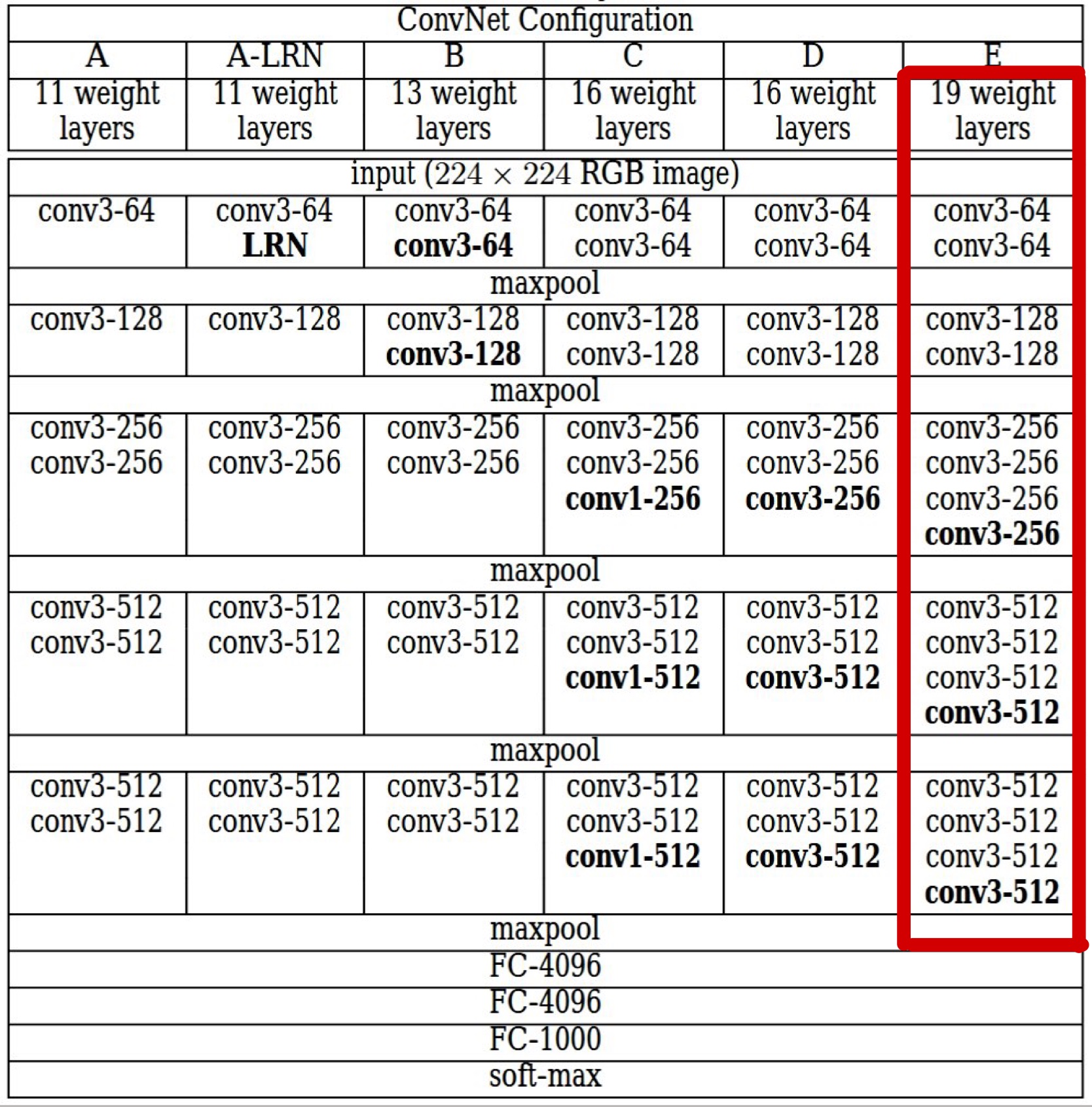
replace max-pooling to average pooling
Content Loss
: original image
: generated image
: the activation of the filter at position in layer
, : respective feature representation in layer
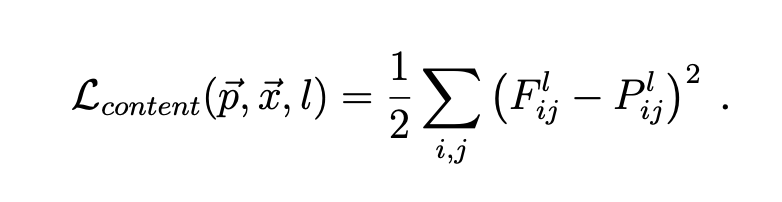
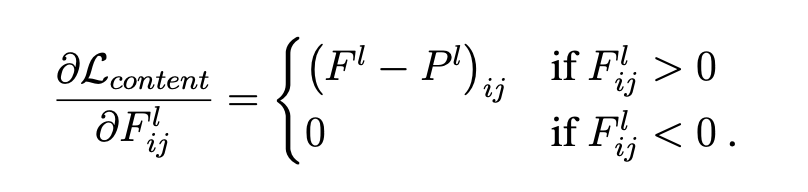
Gram matrix
: inner product between the vectorised feature map and in layer
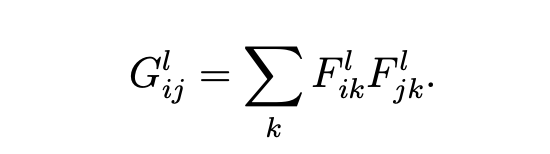
Using gradient descent to find another image that matches the sytle representation of the original image.
Style loss
Minimising the mean-squared distance between the entries of the Gram matrix from the original image and the Gram matrix of the image to be generated.
: original image
: generated image
, : respective style representation in layer
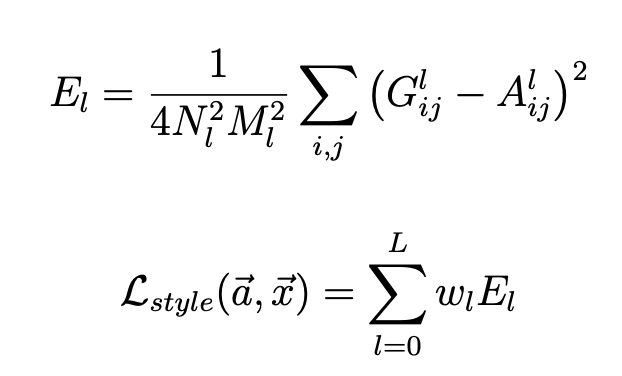
: weighting factors
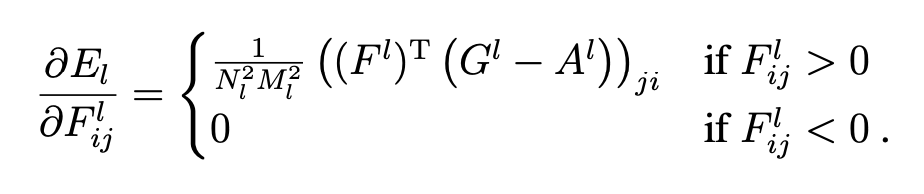
Loss function
: photograph
: artwork

: weighting factor for content reconstruction
: weighting factor for style reconstruction

