논문
1.[논문정리] A Neural Algorithm of Artistic Style
the system uses neural representations to separate and recombine content and style of arbitrary images
2.[논문정리] Video Textures
Abstract 이 논문은 새로운 medium인 video texture에 대해 소개한다. 비디오 클립을 분석해 구조를 추출하고 임의 길이의 비슷하게 보이는 새로운 비디오를 합성하는 기술을 제시한다. video texture 와 view morphing 기술을 결합
3.[논문정리] MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions
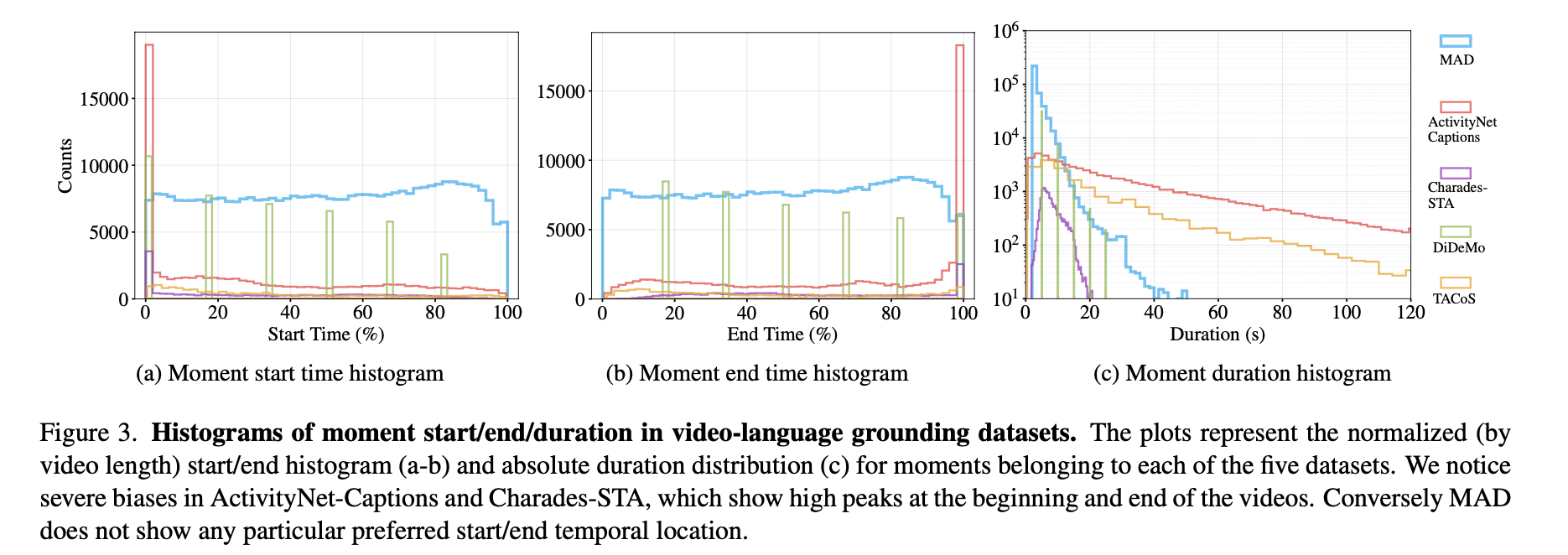
Abstract 최근의 video-language research 관심이 높아지면서 large-scale datasets도 함께 발전되었다. 그와 비교해서 video-language grounding task를 위한 datasets에는 제한된 노력이 들었고, 최신 기술
4.[논문정리] You Only Look Once: Unified, Real-Time Object Detection

https://arxiv.org/abs/1506.02640YOLO, a new approach to object detection.✨we frame object detection as a regression problem to spatially separate
5.[논문정리] StyleGAN-V : A Continuous Video Generator with the Price, Image Quality and Perks of StyleGAN2
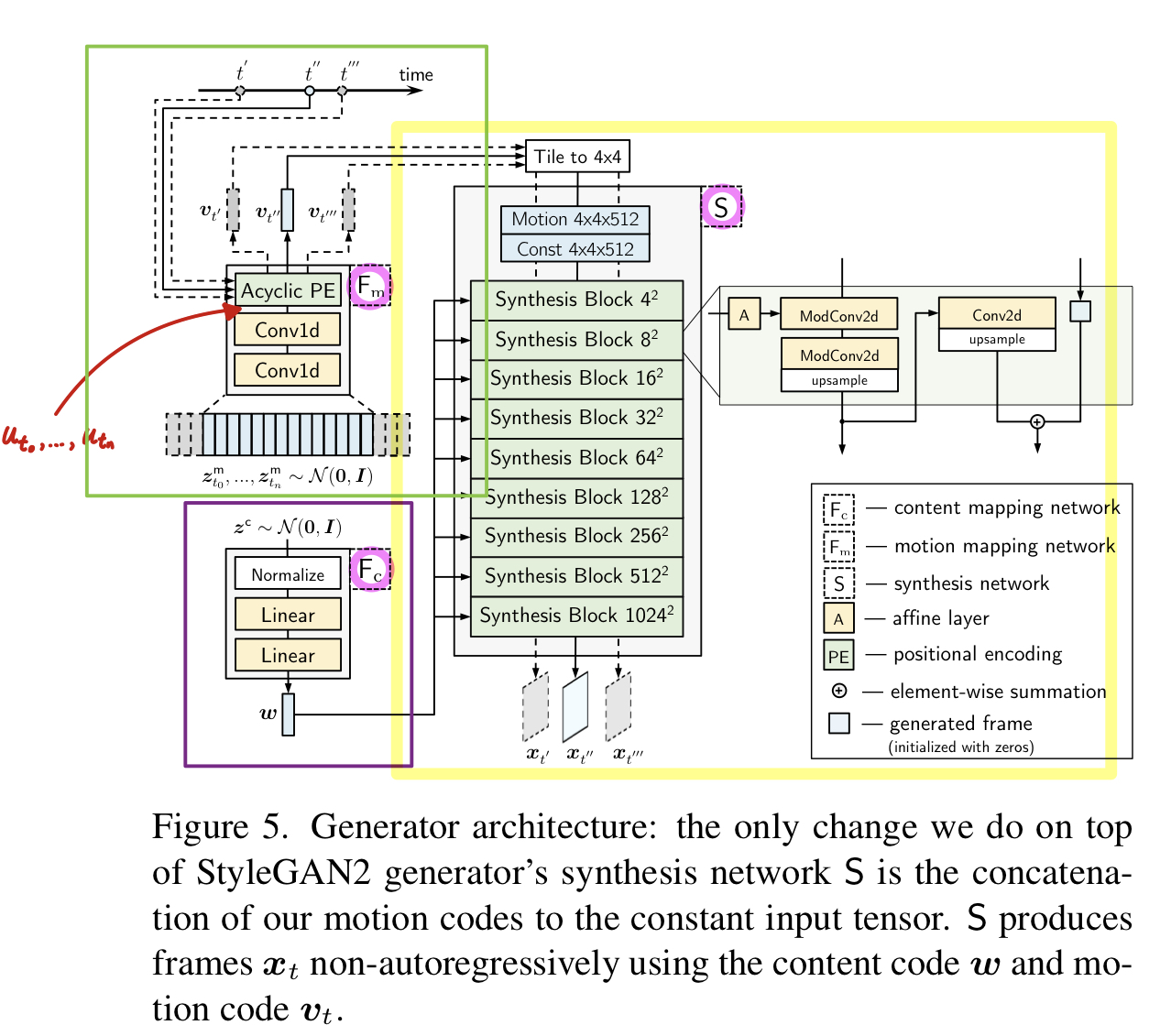
Abstract 비디오는 continuous한 events를 보여주지만 대부분의 video synthesis 프레임워크는 시간에 따라 discretely하게 다룹니다. 논문에서는 video를 time-continuous signals로 다루고, continuous-ti
6.[논문정리] Neural 3D Video Synthesis from Multi-view Video
https://neural-3d-video.github.io/ Abstract We propose a novel approach for 3D video synthesis that is able to represent multi-view video recordings
7.[논문정리] UPST-NeRF: Universal Photorealistic Style Transfer of Neural Radiance Fields for 3D Scene

Abstract 3D scenes photorealistic stylization aims to generate photorealistic images from arbitrary novel views according to a given style image whil
8.[논문정리] Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization (AdaIN)

Abstract Gatys et al. recently introduced a neural algorithm that renders a content image in the style of another image, achieving so-called style tr
9.[논문정리] Image Generators with Conditionally-Independent Pixel Synthesis(CIPS)

Abstract 1. Introduction
10.[논문정리] DIGAN : Generating Videos with Dynamics-aware Implicit Generative Adversarial Networks
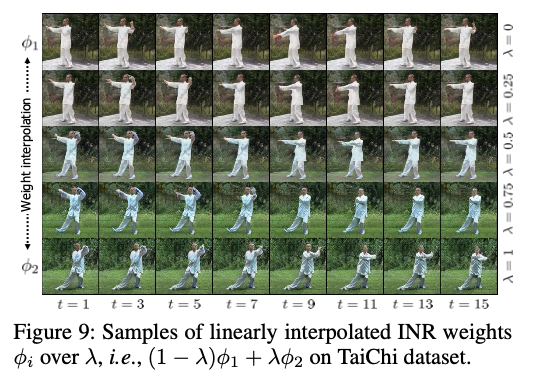
ABSTRACT long video generation을 위해 본 논문에서는 implicit neural representations (INRs)을 비디오에 사용하는 새로운 네트워크인 dynamics-aware implicit generative adversarial
11.[논문정리] A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild
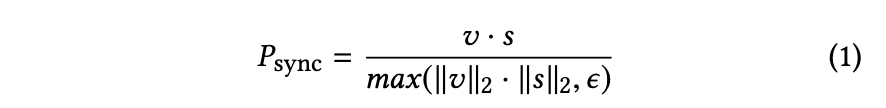
Abstract In this work, we investigate the problem of lip-syncing a talking face video of an arbitrary identity to match a target speech seg- ment. Cur
12.[논문정리] Masked Autoencoders Are Scalable Vision Learners
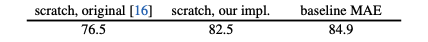
Abstract 본 논무에선느 masked autoencoder(MAE)를 소개하고 있습니다. 대략적으로 이 논문의 중요한 두가지 디자인은 Asymmetric한 encoder-decoder 구조를 가지고 있어서, encoder는 mask token이 없는 visibl
13.[논문정리] MaskGIT: Masked Generative Image Transformer
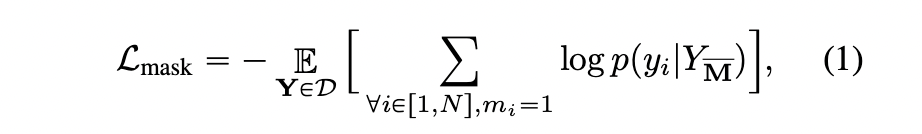
Abstract 1. Introduction 2. Related Work 2.1 Image Synthesis 2.2. Masked Modeling with Bi-directional Transformers 3. Method 3.1. MVTM