Abstract
본 논문에서는 random latent vector 와 pixel의 좌표값이 주어졌을 때 각각의 pixel의 color value(RGB)를 독립적으로(independently) 계산할 수 있는 새로운 image generator 구조를 제안합니다. 이미지 합성 시에 spatial convolutions 과 같이 pixel 들끼리 서로 연관이 있는 연산을 하지 않으면서, state-of-the-art 의 convolutional generators와 비슷한 generation quality를 냅니다. Let's dive into paper! 😀
1. Introduction
DCGAN (Deep Convolutional GAN)의 등장 이후로 지금까지 spatial convolutional layers 기반의 generators 가 많이 사용되었습니다. (or at least spatial self-attention) 또한 최근에, NeRF, INR 과 같은 다양한 연구들이 같은 장면의 이미지들을 서로 다른 deep architectures (deep multi-layer perceptrons)를 사용해서 encoded/synthesized 하는 것을 보여줬습니다. 이런한 구조는 spatial convolutions or spatial self-attention을 사용하지 않는다는 장점이 있지만, 하나의 개별 장면에 제한적입니다.
본 논문에서는 we investigate whether deep generators for unconditional image class synthesis can be built using similar architectural ideas, and, more importantly, whether the quality of such generators can be pushed to state-of-the-art. → and it works!

저자들은 논문의 구조가 spatial convolutions or spatial attention을 사용하지 않았음에도 StyleGANv2 와 비슷한 성능을 낼 수 있다고 강조합니다. 대신에 논문의 generators는 개별 pixels의 coordinate encodings와 랜덤 벡터의 sidewise multiplicative conditioning (weight modulation)을 사용합니다. 또한 각각 pixel의 색상은 서로 independently하게 예측되는 특징을 가지고 있어서 본 논문의 image generator 구조 이름을 Conditionally-Independent Pixel Synthesis (CIPS) generators 라고 합니다.
2. Related Work
- CoordConv technique (COCO-GAN
- Scene-representation networks
- neural radiance fields (NeRF) networks
- Generative Radiance Fields (GRAF)
3. Method
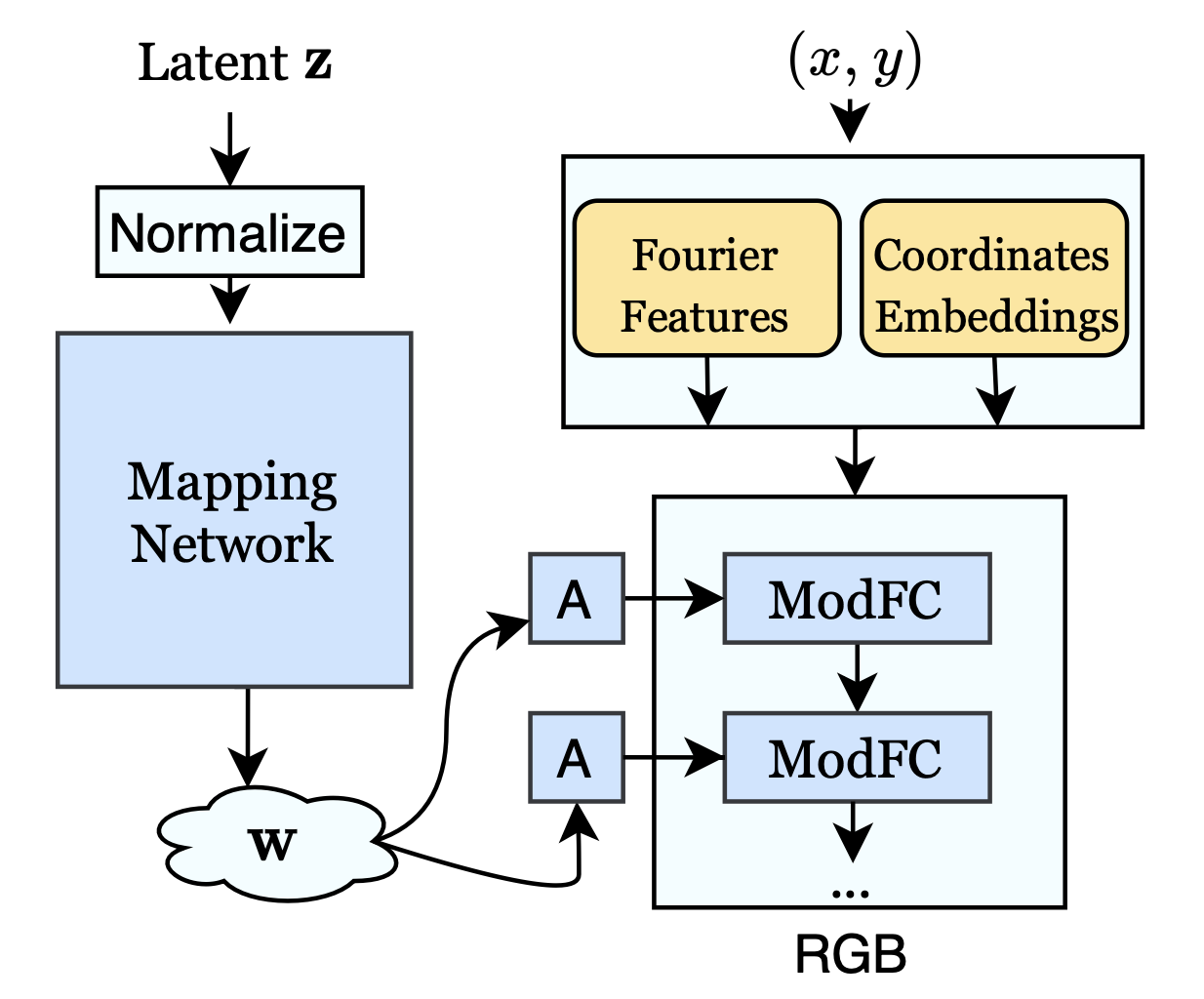
논문의 generator network는 아래와 같은데, 고정된 resolution 의 이미지를 합성하고 multi-layer perceptron 타입의 구조 를 가지고 있습니다.
👀 좀 더 살펴보면
- 각 픽셀끼리 합성하기 위해서, random vector (shared across all pixels) 와 pixel 좌표 {} {} 를 입력으로 받습니다.
- 그리고 해당 픽셀의 RGB 값 를 반환합니다. . → 이제 전체적인 output image 를 계산하기 위해서, random part 는 고정한 상태에서 generator 는 coordinate grid의 각각의 쌍 에 대해 evaluated 됩니다.

where
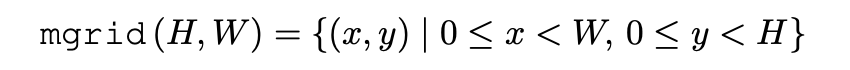
set of integer pixel coordinates.
- StyleGAN과 마찬가지로, mapping network (also a perceptron)은 를 style vector 로 바꿔줍니다.
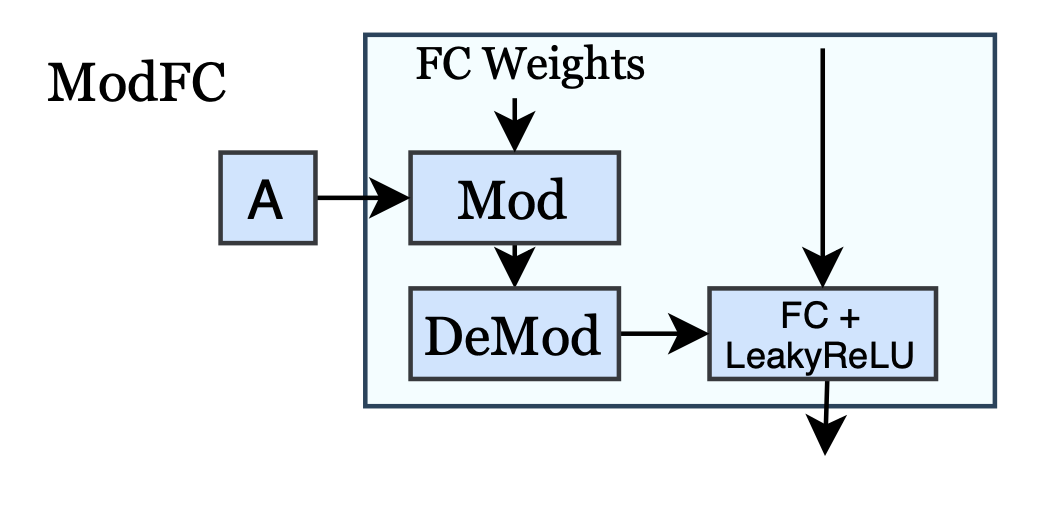
- 이제 StyleGANv2 와 마찬가지로, weight modulation을 통해서 생성 과정 중 style 를 주입해줍니다.
- 논문의 generator의 모든 modulated fully-connected (ModFC) layer 는 로 쓰여질 수 있습니다.
- : input
- : learnable weight matrix modulated with the style
- : learnable bias
- : output.
- 논문의 generator의 모든 modulated fully-connected (ModFC) layer 는 로 쓰여질 수 있습니다.
Modulation
- Style vector 가 small net(A) 를 통해 scale vector 로 mapping 된다. (A in Fig. 2)
- 의 번째 entry는 아래와 같이 계산되고, 이런 linear mapping 후에, LeakyReLU function 을 에 적용합니다.
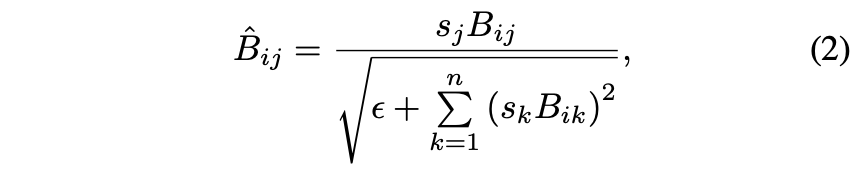
is a small constant
- 두 레이어마다 intermediate feature maps 에서 RGB 값으로 skip connections 을 추가하고 다른 레이어에 해당하는 RGB outputs 의 contributions 를 더해줍니다.
😀 Independence of the pixel generation process makes our model parallelizable at inference time and, additionally, provides flexibility in the latent space .
3.1. Positional encoding
Fourier features가 첫번째 layer에만 periodic activation을 적용한 것처럼, 논문에서는 Fourier embedding 을 얻기 위해 sine function을 activation 으로 사용하고, 다른 layer는 LeakyReLU 를 사용합니다.
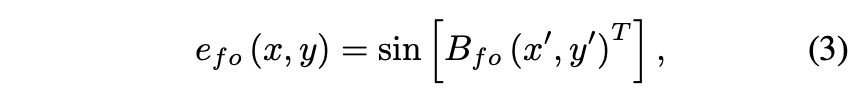
과 은 pixel 좌표로, [-1,1]에서 uniform하게 매핑된다.
하지만 Fourier positional encoding 만 사용하면 wave-like artifacts가 많이 발생되고 좋은 성능을 내지 못하기 때문에, 논문에서는 separate vector 또한 각 spatial position에 학습시킵니다.
→ coordinate embeddings
Full positional encoding 는 Fourier features 와 coordinate embedding 의 concatenation 이 되고, 다음 perceptron layer의 입력이 됩니다. .
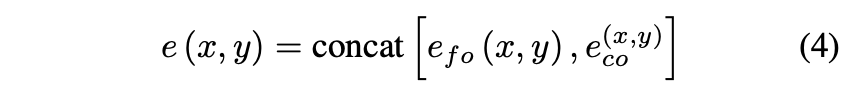
4. Experiments
4.1. Architecture details
- Fourier feature & coordinate embeddings 의 dimension = 512.
- generator had 14 modulated fully-connected layers of width 512.
- LeakyReLU activation’s slope 0.2
- Discriminator has a residual architecture, described in StyleGAN.
- Networks were trained by Adam optimizer with learning rate
- Hyperparameters: .
4.2. Evaluation
Most evaluations are restricted to 256 × 256 resolution.
-
Dataset
- The Flickr Faces-HQ (FFHQ)
- The LSUN Churches
- The Landscapes dataset
- The Satellite-Buildings2 dataset
- Finally, the Satellite-Landscapes3
-
Evaluation
- Frechet Inception Distance (FID)
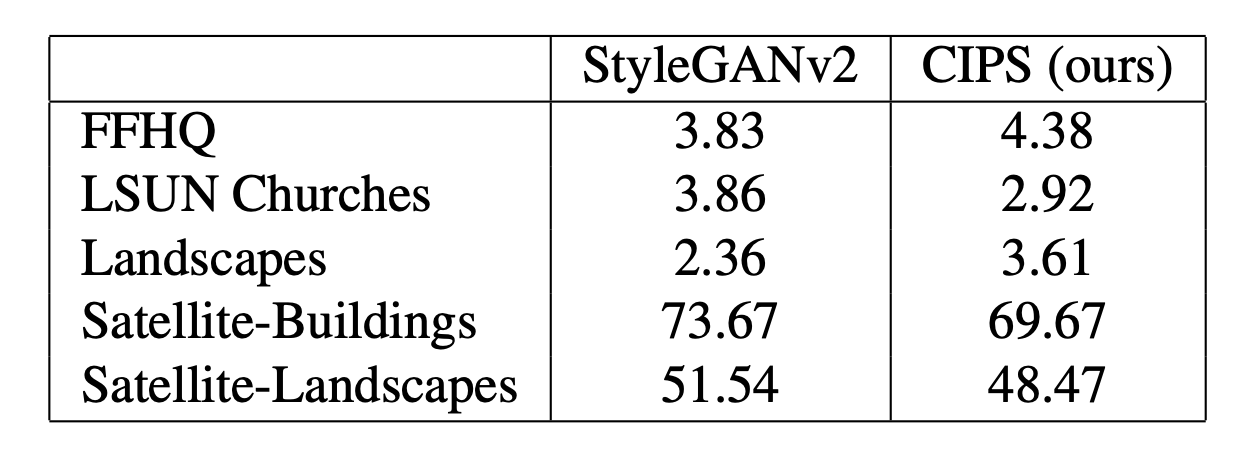
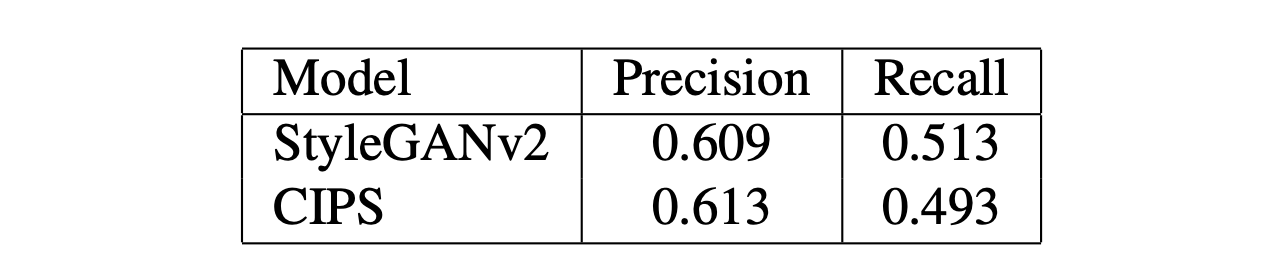
- Precision and Recall measures
4.3. Ablations
with FFHQ dataset.
- Removing Fourier features
- Removing coordinate embeddings (CIPS-NE)
- Replace LeakyReLU activation with sine function in all layers
- Residual connections
- “base” configuration
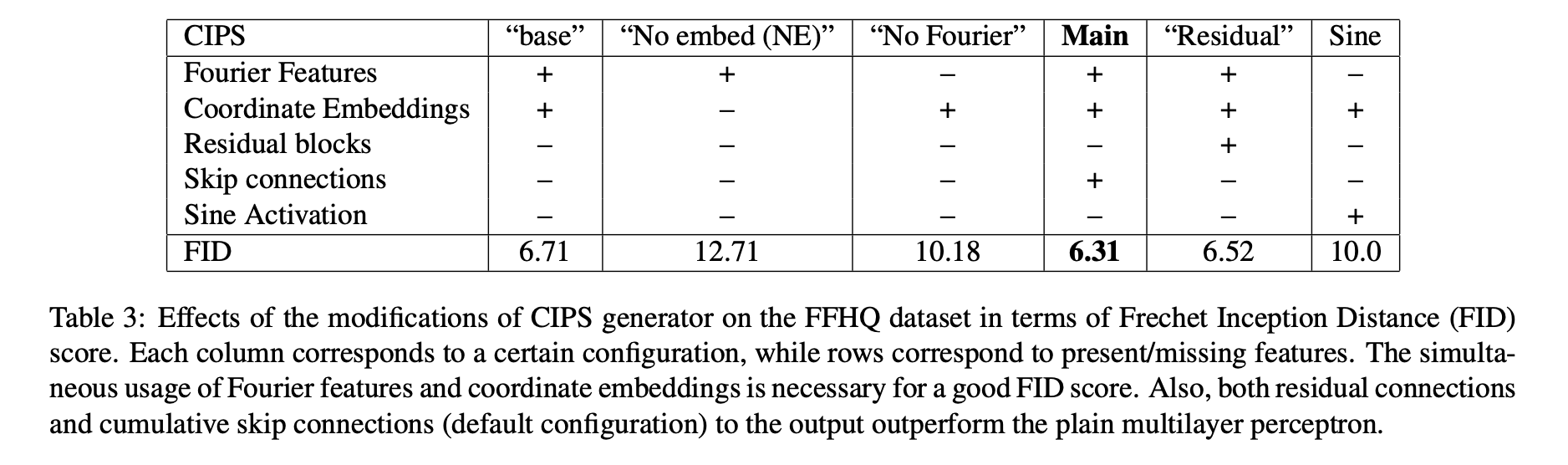
All models were trained for 300K iterations with batch size of 16.
💡 Coordinate embeddings, Residual blocks and Cumulative projection to RGB significantly improve the quality of the model.
4.4. Influence of positional encodings
Fourier features 와 coordinate embeddings 사이의 차이점을 분석하기 위해서, 논문에서는 FFHQ로 학습된 CIPS-base generator의 spectrum을 찍어보았습니다.
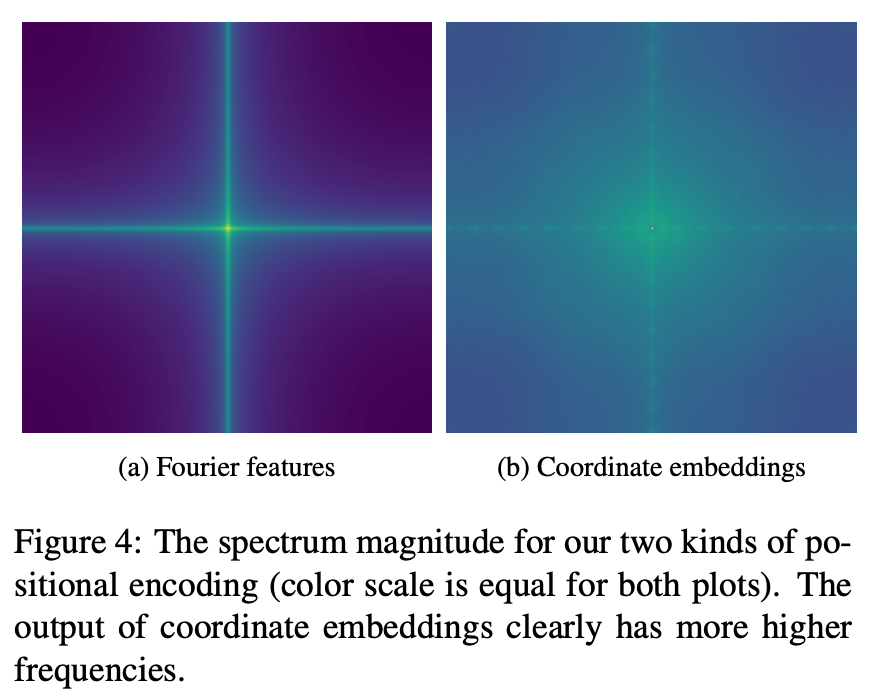
💡 위에 보이는 것과 같이, Fourier encoding은 일반적으로 low-frequency components 를 포함하고 있고, coordinate embeddings 은 더 high-frequency 인 디테일을 보여주고 있습니다.

그리고 위 그림과 같이 두개의 encodings의 Principal Component Analysis (PCA) 는 동일한 결론을 냅니다.
→ coordinate embeddings 은 각각의 pixel에 대해 independent 하게 학습되고, 은 좌표에서 학습된 함수입니다.

💡 이 실험으로 결과 이미지에서 high-frequency 디테일을 잡는 것이 coordinate embeddings 라는 것을 증명할 수 있습니다.
4.5. Spectral analysis of generated images
The analysis of magnitude spectra for produced images.
The spectrum of StyleGANv2 has artifacts in high-frequency regions, not present in both CIPS generators under consideration.

We also use the azimuthal integration (AI) over the Fourier power spectrum (Fig. 7b). It is worth noting that AI statistics of CIPS-NE are very close to the ones of real images.

However, adding the coordinate embeddings degrades a realistic spectrum while improving the quality in terms of FID (Tab. 3).
4.6. Interpolation
✨ Flexibility of CIPS. → Interpolation ability

Change between the extreme images occurs smoothly and allows for the use of this property, in a similar vein as in the original works StyleGAN2.
4.7. Foveated rendering and interpolation
One of the inspiring applications of our per-pixel generator is the foveated synthesis.
In foveated synthesis, an irregular grid of coordinates is sampled first, more dense in the area, where the gaze is assumed to be directed to, and more sparse outside of that region. After that, CIPS is evaluated on this grid (its size is less than the full resolution), and color for missing pixels of the image is filled using interpolation.

We are also able to interpolate the image beyond the training resolution by simply sampling denser grids. As Fig. 9 suggests, more plausible details are obtained with denser synthesis than with Lanczos filter.

4.8. Panorama synthesis
As CIPS is built upon a coordinate grid, it can relatively easily use non-Cartesian grids. Fig. 11a and 11b provide examples of panorama samples obtained with the resulting model.

As each pixel is generated from its coordinates and style vector only, our architecture admits pixel-wise style interpolation (Fig. 11c). In these examples, the style vector blends between the central part (the style of Fig. 11a) and the outer part (the style of 11b).
4.9. Typical artifacts
Our belief is that this behaviour is caused by the LeakyReLU activation function that divides the coordinate grid into parts. For each part, CIPS effectively applies its own inverse discrete Fourier transform.
As CIPS generators do not use any upsampling or other pixel coordination, it is harder for the generator to safeguard against such behaviour.

5. Conclusion
- 이 논문은 CIPS라는 새로운 generator model을 제시해, conditionally independent pixel synthesis 방법으로 좋은 성능을 낼 수 있습니다. (color value is computed using only random noise and coordinate position.)
- 주요 insight는 spatial convolutions, attention 이나 upsampling 연산이 없는 구조이지만 최근 모델들과 비슷하게 좋은 성능을 낸다는 것입니다.
- coordinate grid를 바로 직접적으로 사용하는 것은 cylindrical panoramas 같이 더 복잡한 데이터 구조를 다루기 쉽게 해줍니다.
