[논문정리] DIGAN : Generating Videos with Dynamics-aware Implicit Generative Adversarial Networks
논문
https://openreview.net/forum?id=Czsdv-S4-w9
ABSTRACT
long video generation을 위해 본 논문에서는 implicit neural representations (INRs)을 비디오에 사용하는 새로운 네트워크인 dynamics-aware implicit generative adversarial network (DIGAN)을 제안합니다. 논문에서 제시하는 DIGAN 은 더 긴 비디오를 생성할 수 있고, 다양한 데이터 셋에서 superiority 를 증명했다고 합니다. Let's dive into paper! 😀
1. Introduction
Deep generative models은 이미지, 텍스트, 오디오 등 다양한 도메인에서 realistic한 samples을 합성하는 데 좋은 성능을 보였습니다. 이제는 video generation이 다음 챌린지로 대두되었고 video distribution을 학습할 수 있는 방법들이 제안되었습니다. 👀
하지만 여전히 video signals의 특성때문에 real-world videos를 표현하기에는 부족합니다.(continuously correlated across spatio-temporal directions) 특히, 이전 연구들은 비디오를 RGB values의 3D grid로 생각하고 convolutional과 같은 discrete한 decoders로 모델링 했습니다. 하지만 이런 discrete한 모델링은 생성된 비디오의 scalability를 제한하고 continuous 한 temporal dynamics을 무시할 수 밖에 없습니다.😢
또한, implicit neural representations (INRs)이 continuous signals을 표현하는 새로운 패러다임으로 등장했습니다. INR은 signal을 input coordinates와 대응하는 signal values로 매핑해주는 neural network로 인코딩합니다.
Consequently, INR amortizes the signal values of arbitrary coordinates into a compact neural representation instead of discrete grid-wise signal values, requiring a large memory proportional to coordinate dimension and resolution.
이와 관련하여 INR은 3D scenes 과 같은 complex한 signals을 모델링하는 데 매우 효과적이고, 메모리 감소와 임의의 resolution으로의 upsampling 같은 compactness와 continuity한 특징을 가집니다.
INR-GAN 을 기반으로 본 논문에서는 continuous signals을 통합함으로써 video generation model을 디자인 했습니다. 뒤에서 나오겠지만 이 방법은 3D grids 없이 video를 인코딩할 수 있고 자연스럽게 continuous한 spatio-temporal dynamics을 모델링할 수 있습니다. 👍
Contribution📝
논문에서는 video generation을 위한 새로운 INR-based GAN 구조인 dynamics-aware implicit generative adversarial network (DIGAN)을 제안합니다.
- Generator
- Decomposes the motion and content (image) features
- Incorporates the temporal dynamics into the motion features.
- Encourages the temporal coherency of videos
- Create videos with diverse motions by sharing the initial frame
- Discriminator
- Detects unnatural motions from a pair of images (+ time difference)
- Using 2D convolutional network
2 RELATED WORK
Image generation.
대표적인 image generation 모델인 GAN은 높은 resolution 이미지를 빠르게 inference해서 합성할 수 있습니다.
Video generation.
이미지에서의 GAN이 높은 성능을 자랑하는 것을 따라서 비디오에서의 generation도 이것을 많이 따랐습니다. 본 논문에서는 이와는 조금 다르게 INR을 사용한다고 합니다.
Implicit Neural Representations.
줄여서 INR은 최근에 high-frequency sinusoidal activations이 continuous signal modeling을 상당히 향상시켰습니다. 아쉽게도 이전에는 single signal을 모델링 하는 것에 초첨이 맞춰있었는데 본 논문에서는 video에도 적용했다고 합니다.
Generative models with INRs.
single gisnal에서의 INR이 성공적인 결과를 보여준 이후로 generative modeling에 INR을 적용하는 연구들도 진행되었습니다. 본 논문에서는 temporal dynamics를 incorporating 함으로써 INR-based GANS을 video generation으로 확장합니다.
3. Dynamic-aware Implicit Generative Adversarial Network
Video generations 의 GOAL 🥅 : To learn the model distribution to match with the data distribution , where a video is defined as a continuous function of images it for time , and an image it is a function of spatial coordinates .
비디오를 이미지의 discretized sequence로 바라보는 이전의 접근방법들은 생성된 비디오들의 cubic complexity 때문에 scaling하기 힘들고, continuous한 dynamics을 무시해버립니다.
본 논문에서는 implicit neural representations(INRs)를 사용하면서 여기에 temporal dynamics를 통합함으로써 비디오를 continuous signals 로 직접적으로 모델링합니다. 그래서 video generation을 위한 INR-based GAN, 즉 dynamics-aware implicit generative adversarial network(DIGAN) 을 제안합니다.✨
3.1 Generative Modeling with Implicit Neural Representations
signal value에 corresponding하는 coordinate mapping의 signal 이 있다고 생각해봅시다.
(예를 들어, 비디오를 인 로 생각하면 됩니다. - 는 space-time coordinates, 는 RGB values. )
INR은 로 parametrized 된 neural network 을 통해 바로 모델링하는 것을 목표로 합니다. (using a multi-layer perceptron (MLP).) 그리고 이전 연구에서 high-frequency input 를 ( for ) 사용한 sinusoidal activations이 3D scenes 과 같은 복잡한 신호의 모델링을 크게 향상시키는 것을 알아냈습니다. 여기서, pre-defined 된 입력 좌표의 grid 값을 계산해서 INR 를 신호의 standard discrete grid interpretation으로 디코딩할 수 있습니다. (e.g. for videos of size .)
이제 이런 INRs을 generative models에 활용해볼 수 있습니다.👊
즉, generator 는 prior distribution 으로부터 INR parameter 로 latent ∼ 를 매핑합니다. 여기서 INR parameter 는 generate 된 signal 와 대응합니다. INR 기반의 generative models은 좌표의 function을 합성하기 때문에 고정된 크기의 parameter 만을 합성하면 됩니다. 그래서 복잡한 신호에 대해 생성된 outputs 의 complexity를 줄여줘서 특히 높은 차원의 signals 에서 좋은 특성을 줄 수 있습니다. 😀
CVPR 2021인 INR-GAN은 INR의 weights를 합성하는 새로운 generator 를 제시하고 INR에서 디코딩된 가짜 이미지를 식별하기 위해 기존의 convolutional GAN discriminator 구조를 사용해서 inter- extra- polation 및 빠른 inference 같은 흥미로운 특성을 보여줬습니다.
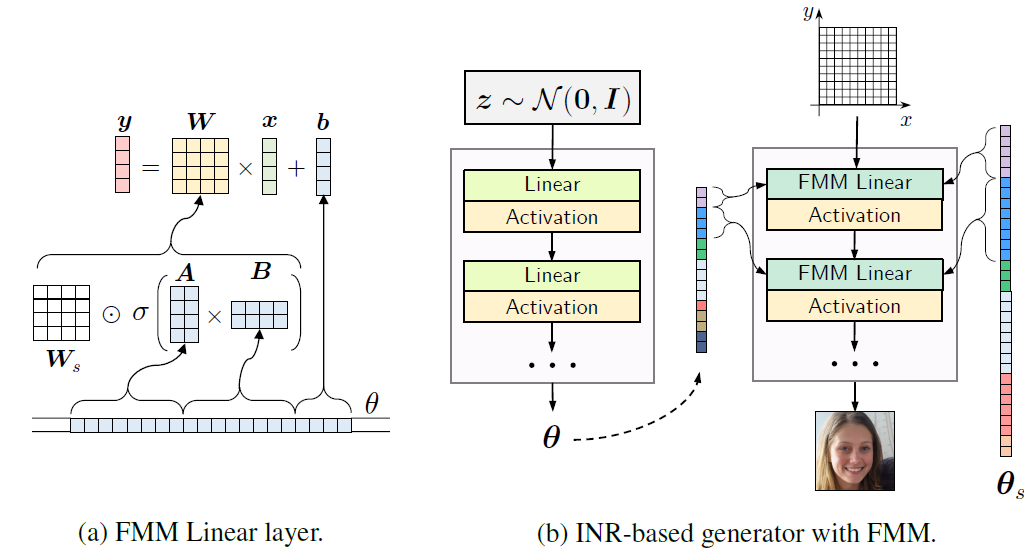
3.2 Incorporating Temporal Dynamics for Implicit GANS
DIGAN은 INR 기반의 video GAN으로 temporal dynamics을 INRs과 통합했습니다. 간단하게 video INRs은 image INRs에서 추가로 time cooridnate를 추가해서 입력 값이 이제 3D coordinate 가 됩니다. 본 논문의 careful한 generator와 discriminator를 더 자세하게 아래서 살펴봅시다.
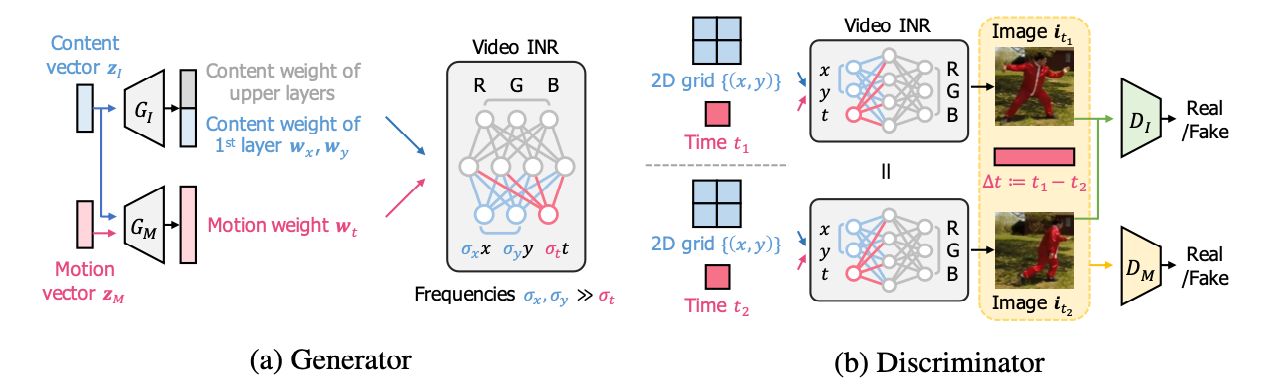
Generator.
naive한 확장은 video INRs synthesize 를 위해 INR의 첫번째 레이어를 수정해 추가적으로 시간 좌표를 추가해주는 방식인데, 이런 방식은 전체 INR parameter 를 한번에 합성해서, 비디오의 space와 time의 차이를 간과할 수 있습니다. (e.g.,smooth change of frames over the time direction.)
이런 문제를 완화하기 위해, 먼저 비디오 INR의 spatial 및 temporal term이 분해되는 것을 적용하면 비디오 INR의 첫 번째 레이어(without sinusoidal activations)의 출력은 로 해석될 수 있습니다. 여기서 는 첫 번째 레이어의 weights와 biases 이고 는 좌표 의 주파수입니다. 여기서 라는 것만 image INRs과 다르기 때문에, video INRs의 첫번째 레이어 출력은 content parameter { } 에 의해 결정되는 initial frame() 부터 time 만큼의 continuous trajectory로 볼 수 있습니다.
→ 그래서 space-time decomposition view를 활용해 저자들은 temporal dynamics을 motion parameter 에 포함합니다.
👊 To be specific, we propose three components to improve the motion parameter considering the temporal behaviors.
- Using a smaller time-frequency than space-frequencies .
- Sampling a latent vector for motion diversity in addition to the original content (image) latent vector .
- Applying a non-linear mapping on top of the motion features at time to give more freedoms to motions, i.e., .
Discriminators.
일반적으로 이전의 video discriminators는 image discriminator 와 motion(또는 video) discriminator 의 두 가지 discriminator를 사용했습니다. image의 경우 2D convolutional 구조를 사용할 수 있지만, motion (or video)는 입력이 이미지 시퀀스(e.g., the entire videos)인 3D convolutional 네트워크가 필요합니다.
본 논문에서는 계산 비용이 많이 드는 3D 대신 효율적인 2D convolutional video discriminator 를 제안합니다.👍 여기서 저자들은 전체 시퀀스를 생성해야 하는 autoregressive models 과 달리 비디오 INR은 임의 시간 의 두 프레임을 효율적으로 생성할 수 있음을 강조합니다. INR의 이러한 속성을 활용해서, 입력 채널을 확장하여 에 대한 한 쌍의 이미지와 시간 차이로 구성된 triplet을 구별하기 위해 이미지 판별기를 채택합니다.
흥미롭게도 이 판별자는 전체 시퀀스를 관찰하지 않고도 dynamics을 학습할 수 있고 또한, 두 프레임은 continuity 로 인해 높은 correlation을 가집니다. (+ discriminator can focus on the artifacts in the motion.)
4. Experiments
4.1 Video Generation
Model.
- INR-GAN architecture based
- Content generator 은 INR-GAN generator과 동일하고, Motion generator 이 추가.
- Spatial frequencies (smaller temporal frequency performs better
- Same discriminator of INR-GAN (only differ for the input channels: 3 and 7)
Datasets
- UCF-101
- Tai-Chi- HD
- Sky Time-lapse
- Kinetics-600
Evaluation
All models are trained on 16 frame videos of 128×128 resolution.
- Inception score(IS)
- Frechet video distance(FVD)
- Kernel video distance (KVD)
Main results.
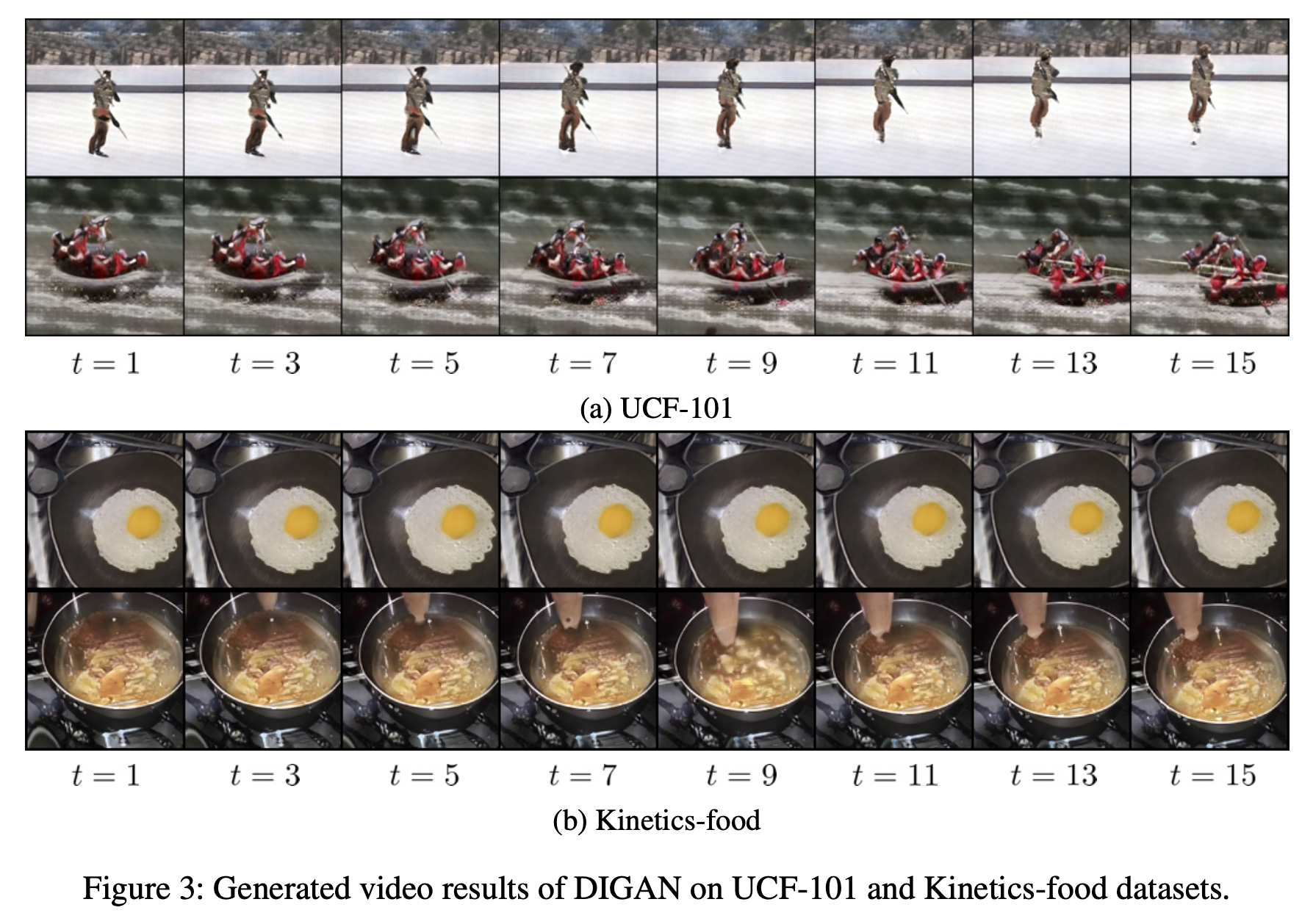
Qualitative
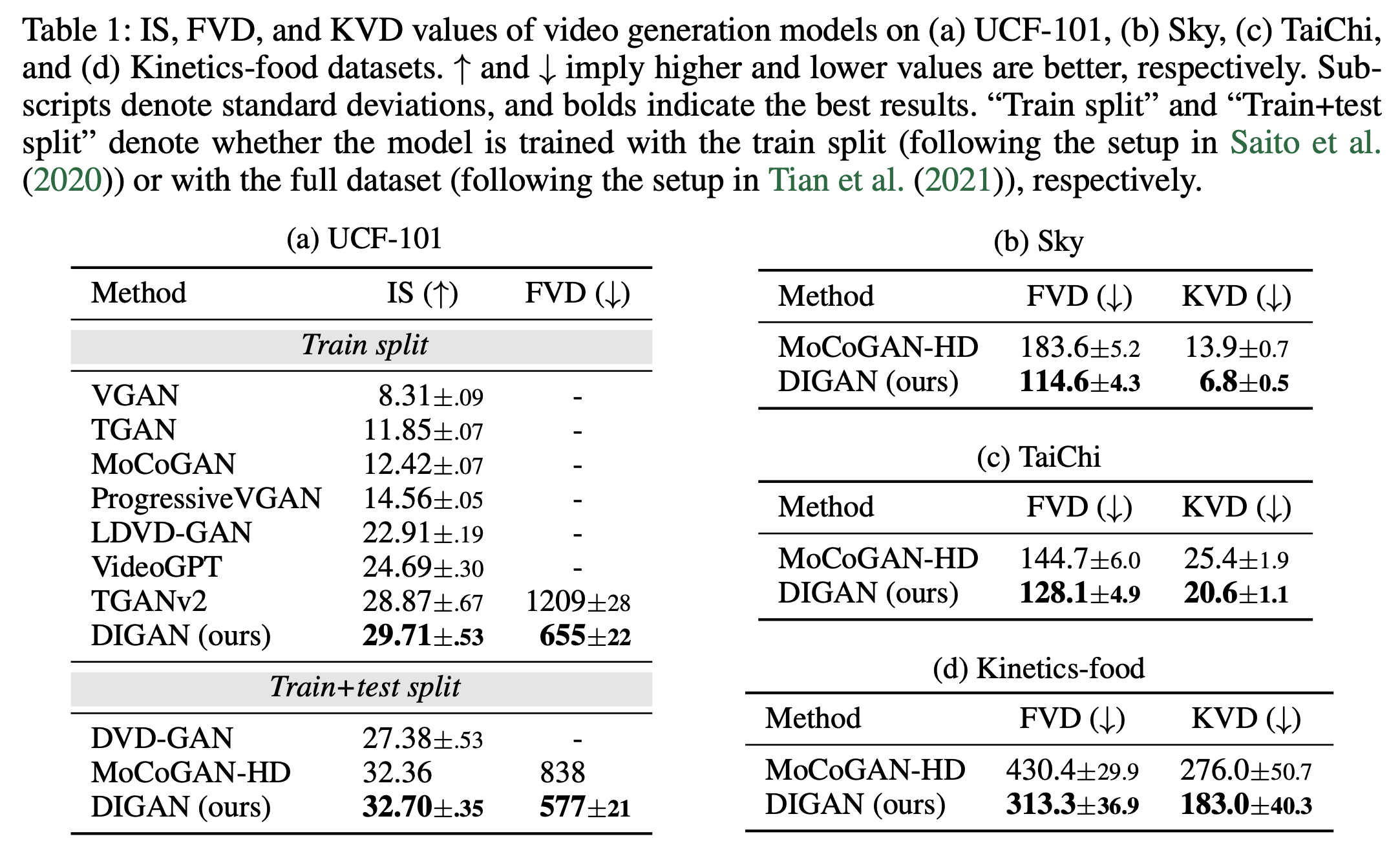
Quantitative
4.2 Intriguing Properties
Long video generation.
DIGAN의 motion discriminator가 긴 이미지 시퀀스 대신 한 쌍의 이미지만 처리 하기 때문에 DIGAN이 긴 비디오에 대해 효율적으로 훈련될 수 있습니다.

Time interpolation and extrapolation.
DIGAN은 입력 좌표를 컨트롤해서 시간에 따라 더 자연스럽고 쉽게 interpolate 하거나 extrapolate 할 수 있습니다.
In particular, DIGAN is remarkably effective for time extrapolation as INRs regularize the videos smoothly follow the scene flows defined by previous dynamics.

Figure 4 shows that DIGAN can even extrapolate to 4× longer frames while MoCoGAN-HD fails on the Sky dataset.

Non-autoregressive generation.
DIGAN can generate samples of arbitrary time.: 미래 프레임에서 과거/중간 프레임을 추론하거나 전체 비디오를 한 번에 병렬로 계산할 수 있습니다. (autoregressive한 방식으로는 불가능)


Diverse motion sampling.
Note that the shape of clouds moves differently, but the tree in the left below stays. The freedom of variations conditioned on the initial frame depends on datasets.

Space interpolation and extrapolation.
Qualitative and Quantitative results for space interpolation (i.e., upsampling) on the TaiChi dataset.


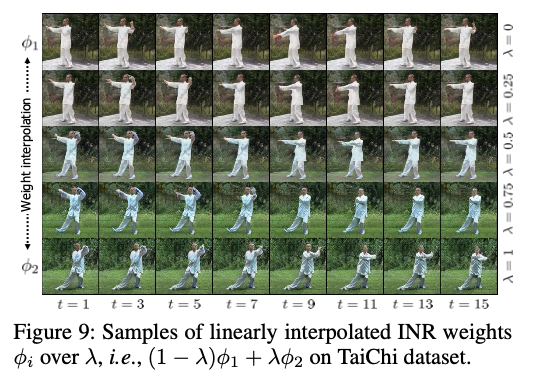
INR weight interpolation.
The videos smoothly vary over interpolation, e.g., cloth color changes from white to blue.
4.3 Ablation Study
We note that the motion vector and MLP remarkably affect FVD when applied solely, but the all-combination result is saturated.

On the other hand, Figure 10 verifies that the motion discriminator considers the time difference of a given pair of images.
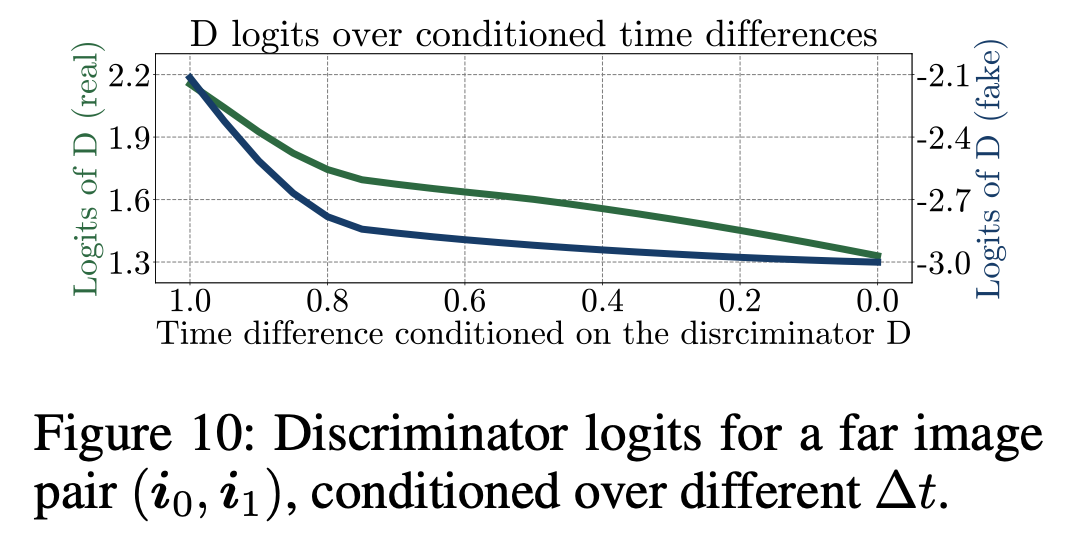
Specifically, we provide a far image pair , i.e., the first and the last frames, with the time difference ∆t. The motion discriminator thinks the triplet is fake if and real if , as the real difference is . Namely, the discriminator leverages to identify whether the input triplets are real or fake.
5. Conclusion
논문에서는 video generation을 위해 비디오의 temporal dynamics을 통합해서 implicit neural representation (INR)-based generative adversarial network (GAN), DIGAN을 제안했습니다. 다양한 실험으로 DIGAN의 성능을 보여줬습니다. 👏
