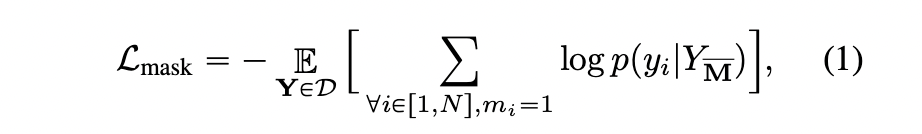
Abstract
Generative transformer 모델들이 image를 tokens sequence로 처리하고, raster scan ordering으로 디코딩하는 한계를 지적하면서, bidirectional transformer decoder, MaskGIT 을 사용해 새로운 image synthesis paradigm을 제안합니다. Let's dive into paper 😀
1. Introduction
NLP 분야에서 transformer가 좋은 결과를 내는 경향을 따라서, CV 분야에서는 generative transformer models에 대한 연구가 활발합니다. autoregressive model을 사용해서 생성되는 이미지는 두가지 단계가 있습니다.
1. Quantize an image to a sequence of discrete tokens(or visual words)
2. Autoregressive model(e.g. transformer) is learned to generate image tokens sequentially based on the previously generated result (i.e. autoregressive decoding)
논문에서는 새로운 Masked Generative Image Transformer(MaskGIT),인 bidirectional transformer 를 소개합니다.
2. Related Work
2.1 Image Synthesis
2.2. Masked Modeling with Bi-directional Transformers
3. Method
"Design a new image synthesis paradigm utilizing parallel decoding and bi-directional generation."
(앞에서 언급한) 첫번째 stage는(tokenization) VQGAN 모델과 동일하고, 두번째 stage에서는 Masked Visual Token Modeling(MVTM)을 통한 bidirectional transforemr를 학습합니다.
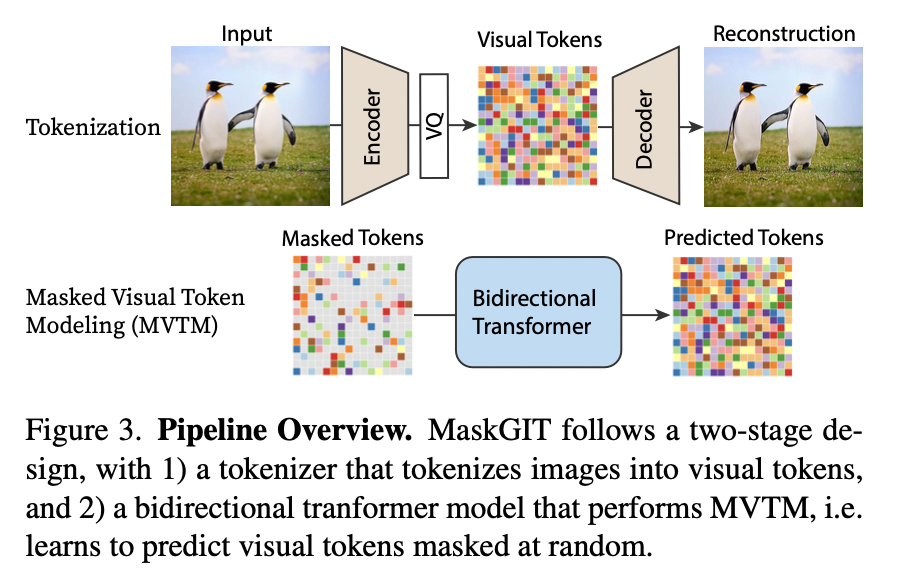
3.1. MVTM in Training
- : latent tokens obtained by inputting the image to the VQ-encoder
- : corresponding binary mask
- : length of the reshaped token matrixTraining 동안, tokens subset을 샘플링하고 [MASK] token으로 바꿉니다. 즉, token 는 이면 [MASK] token으로, 이면 그대로 입니다.
여기서 sampling 과정은 mask scheduling function 로 parameterize 되어서, 아래와 같이 실행됩니다.
1. 0부터 1까지의 ratio를 샘플링하고,
2. 에서 uniform하게 mask를 할 token을 선택합니다.
masked tokens의 negative log-likelihood를 minimize! ()
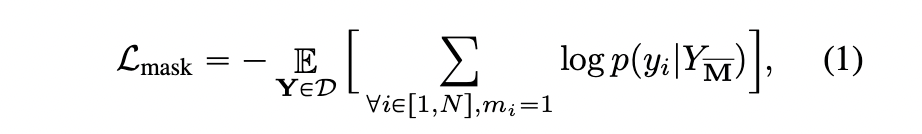
3.2. Iterative Decoding
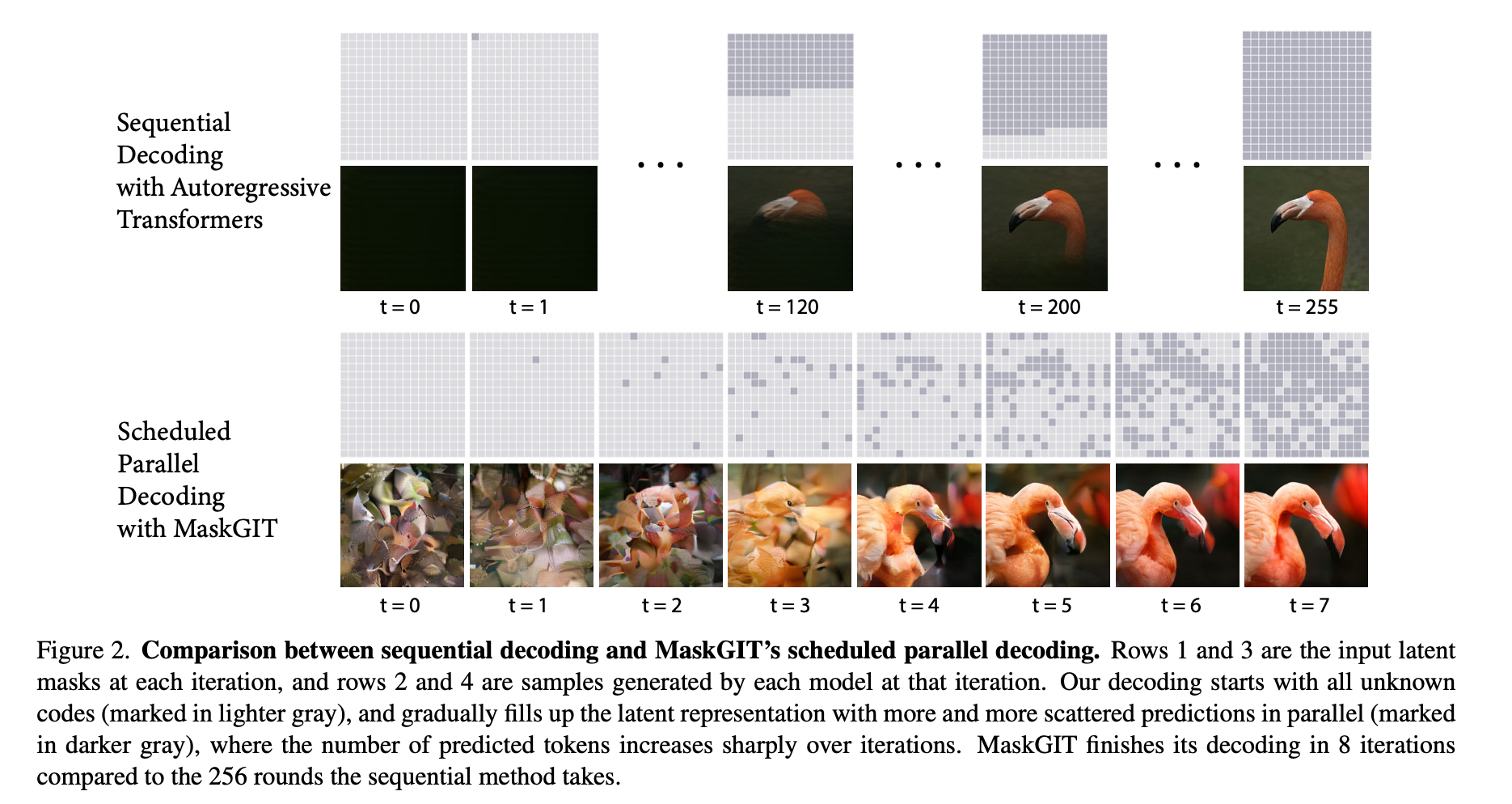
논문에서는 MTVM의 bi-directional self-attention 덕분에 image의 모든 tokens들이 parallel하게 생성될 수 있는 decoding 방법을 제시하고 있습니다.
- Predict. Given the masked tokens at the current iteration, our model predicts the probabilities, denoted as , for all the masked locations in parallel.
- Sample. At each masked location , we sample a token based on its prediction probabilities over all possible tokens in the codebook. After a token is sampled, its corresponding prediction score is used as a “confidence” score indicating the model’s belief of this prediction. For the unmasked position in , we simply set its confidence score to 1.0.
- Mask Schedule. We compute the number of tokens to mask according to the mask scheduling function by , where is the input length and is the total number of iterations.
- Mask. We obtain by masking tokens in . The mask is calculated from:
3.3. Masking Design
논문에서는 생성된 이미지 퀄리티가 masking design에 의해 크게 영향을 받고, mask scheduling function으로 세가지 함수를 제안합니다.
- Linear function
- Concave function
- Convex function
4. Experiments

4.1. Experimental Setup
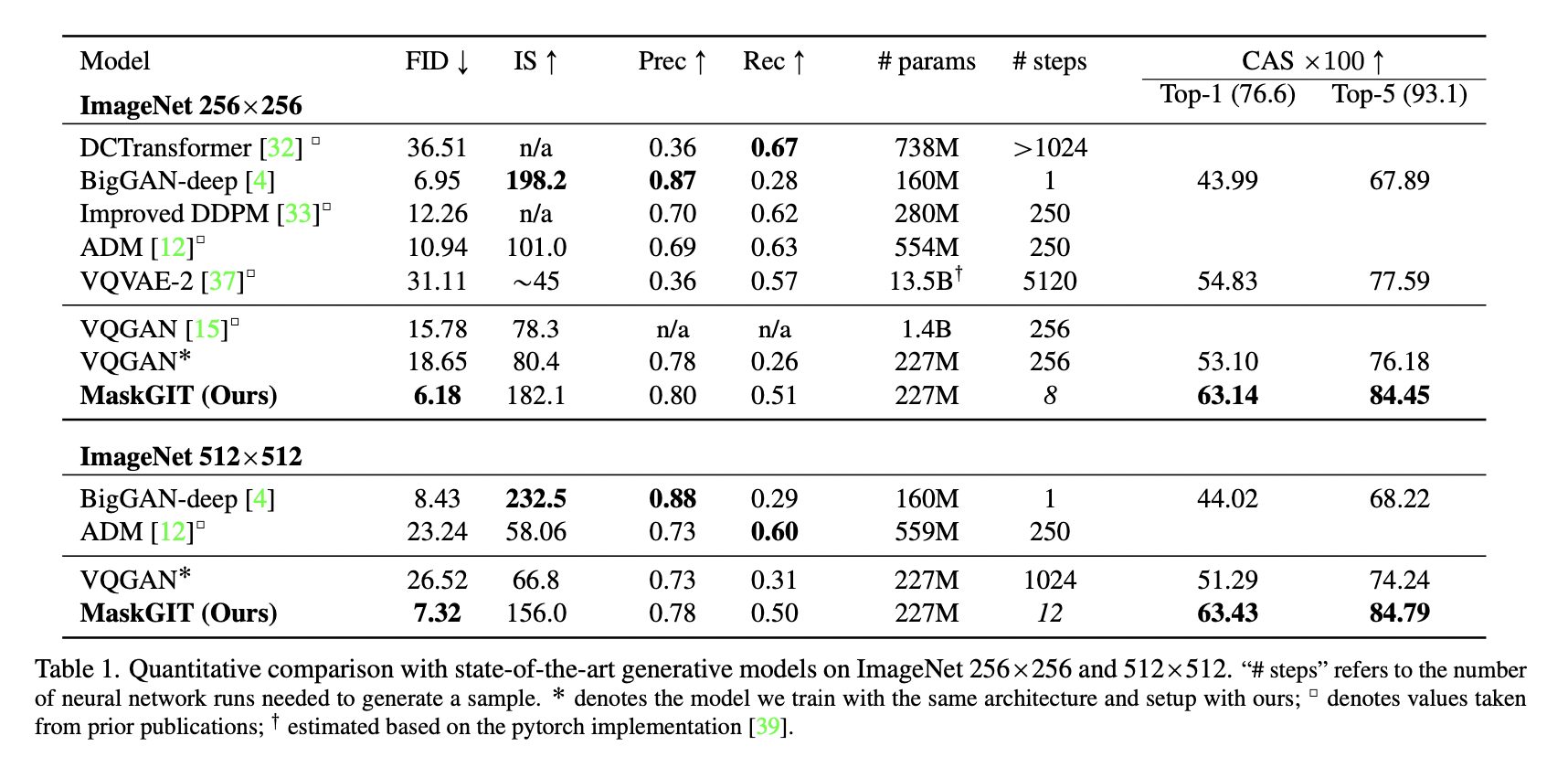
4.2 Class-conditional Image Synthesis
Quality
Speed
Diversity

4.3 Image Editing Applications
Class-conditional Image Editing.

Image Inpainting. & Image Outpainting.
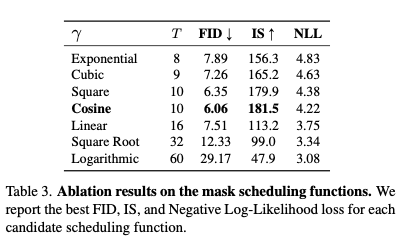
4.4. Ablation Studies
Mask scheduling.
Iteration number.
5. Conclusion
- MaskGIT, a novel image synthesis paradigm using a bidirectional transformer decoder.
- Trained on Masked Visual Token Modeling, MaskGIT learns to generate samples using an iterative decoding process within a constant number of iterations.
- Experimental results show that MaskGIT significantly outperforms the state-of-the-art transformer model on conditional image generation, and our model is readily extendable to various image manipulation tasks.
