Abstract
본 논문에서는 masked autoencoder(MAE)를 소개하고 있습니다.
대략적으로 이 논문의 중요한 두가지 디자인은
- Asymmetric한 encoder-decoder 구조를 가지고 있어서, encoder는 mask token이 없는 visible한 patches의 subset에 대해서만 보고, decoder는 mask token 또한 보면서 recontruct를 합니다.
- 논문에서는 이미지에다가 높은 비율의 masking을 하는 것이(e.g. 75%) 더 의미있는 self-supervisory task 결과를 낸다.
는 것입니다. Dive into paper! 😀
1. Introduction
unlabeled images로 학습하기 위해 NLP 분야 모델에서는 self-supervised learning이 대세입니다. autoregressive modeling GPT나 BERT의 masked autoencoding은 '데이터의 어떤 부분을 remove해서 그 remove 된 content를 예측'하도록 학습합니다. 이 방법은 천억 개 이상의 매개변수가 포함된 NLP 모델을 학습할 수 있게 합니다.
이런 masked autoencoder를 computer vision에도 적용할 수 있습니다. 그러면 vision 과 language 간에 masked autoencoding이 다른 점은 무엇일까요 ?
- Architectures were different.
→ Solution : Vision Transformers (ViT) - Information density is different between language and vision
→ Solution : masking a very high portion of random patches. - Autoencoder's decoder plays a different role between reconstructing text and images. (vision은 pixel을 reconstruct 하기 때문에 낮은 semantic 을 띄지만, language는 words를 예측하기 때문에 훨씬 semantic 하다.)
→ Solution : In images, the decoder design palys a key role in determining the semantic level of the learned latent representations.
논문에서는 masked autoencoder (MAE) 를 소개합니다.
2. Related Work
-
Masked Language modeling
-
Autoencoding
-
Maked image encoding
-
Self-supervised learning
3. Approach
다른 autoencoder와는 다르게 논문에서는 asymmetric한 design을 가지고 있습니다. encoder는 mask token이 없는 부분에 대해서만 동작하고, deocer는 lightweight 하고 latent representataion과 mask token 모두를 사용해 recontruct 합니다.

Masking
ViT처럼 image를 겹치지 않게(non-overlapping) patch들로 나누고, patch 부분과 mask 부분을 나눠서 sampling합니다. ("random sampling")논문에서는 high masking ratio가 redundancy를 크게 제거하고,
MAE encoder
Encoder는 visible한 pathces 즉, unmasked된 patches에만 적용됩니다. 기존 ViT와 동일하게 positional embedding을 추가해 linear projection으로 patches를 embed하고, Transformer blocks으로 진행합니다. 중요한건 no mask tokens are used!
MAE decoder
Decoder는 (i) encoded 된 visible patches (ii) mask tokens 둘다 사용합니다. positional embedding도 모든 token에 추가되고 Transformer blocks을 가지고 있습니다.Deocoder는 image reconstructino을 위해 pre-training 때만 사용되는데, 그래서 encoder design과 independently 하게 디자인 될 수 있고 논문에서는 lightweight한 decoder (small) 를 사용합니다. (Asymmetric❗️)
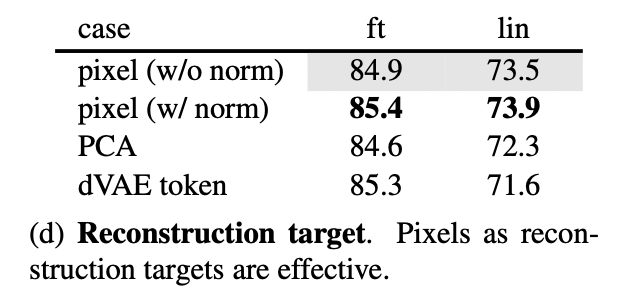
Reconstruction target
MAE는 maked된 patch의 pixel value를 예측해서 입력값을 reconstruct 합니다. Decoder 각각의 출력값은 patch를 나타내는 pixel values의 벡터이고, 이 outputdms reconstructed image 형태를 위해 reshaped 됩니다. 그래서 loss function은 maked patches에 대해서만, pixel space에서 reconstructed & original 이미지의 MSE를 계산합니다.
Simple implementation
(그림 참고 )
1. Generate a token for every input patch
2. Randomly shuffle the list of tokens and remove the last protion of the list
3. After encoding, we append alist of mask tokens to the list of encoded patches, and unshuffle this full list to align all tokens with their targets.
4. Decoder is applied to this full list.
4. ImageNet Experiments
Baseline: ViT-Large
ViT-L trained from scratch vs. fine-tuned from our baseline MAE
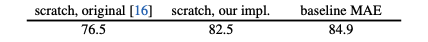
4.1 Main Properties
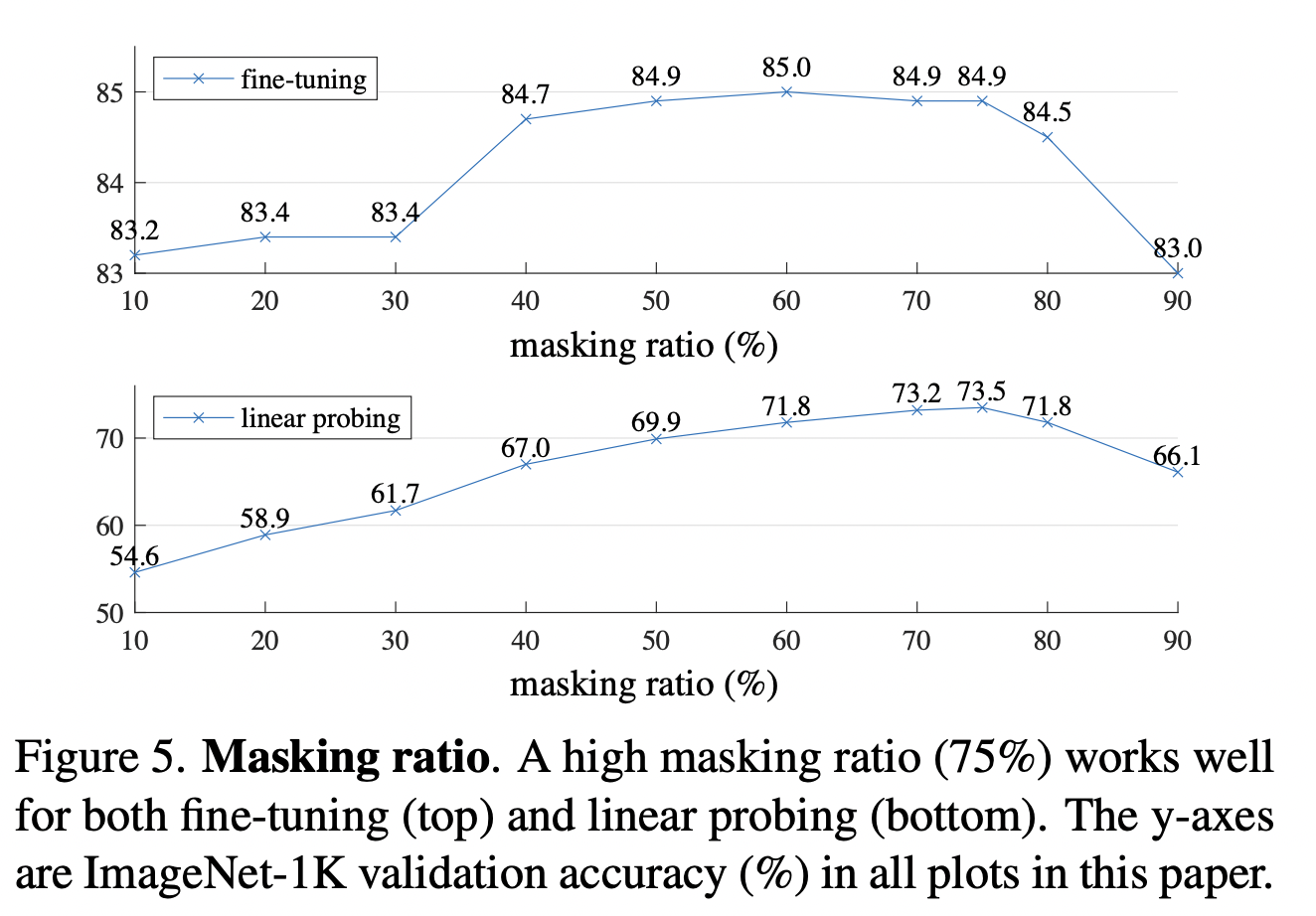
Masking ratio
masking 비율이 미치는 영향을 보여주는 그래프로, optimal ratio는 되게 높은 걸 알 수 있다.(대략 75%)
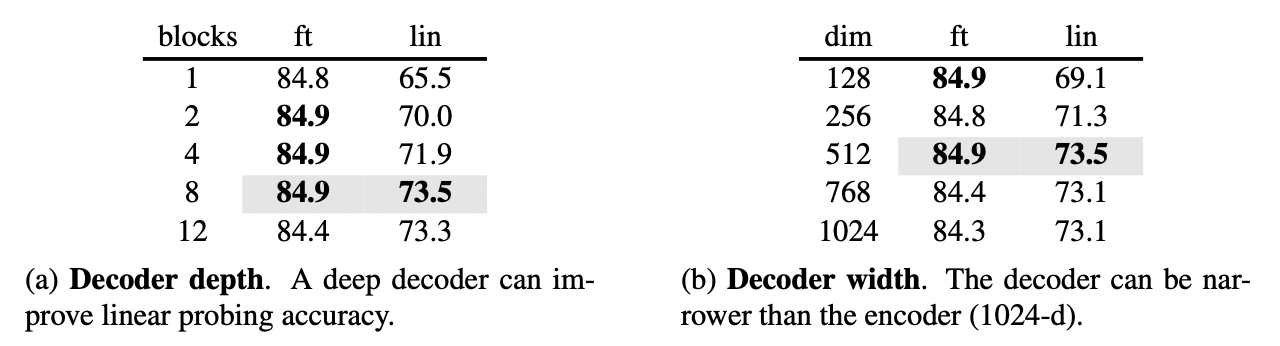
Decoder design
Mask token

Reconstruction target
Data augmentation

Mask sampling strategy


Training schedule
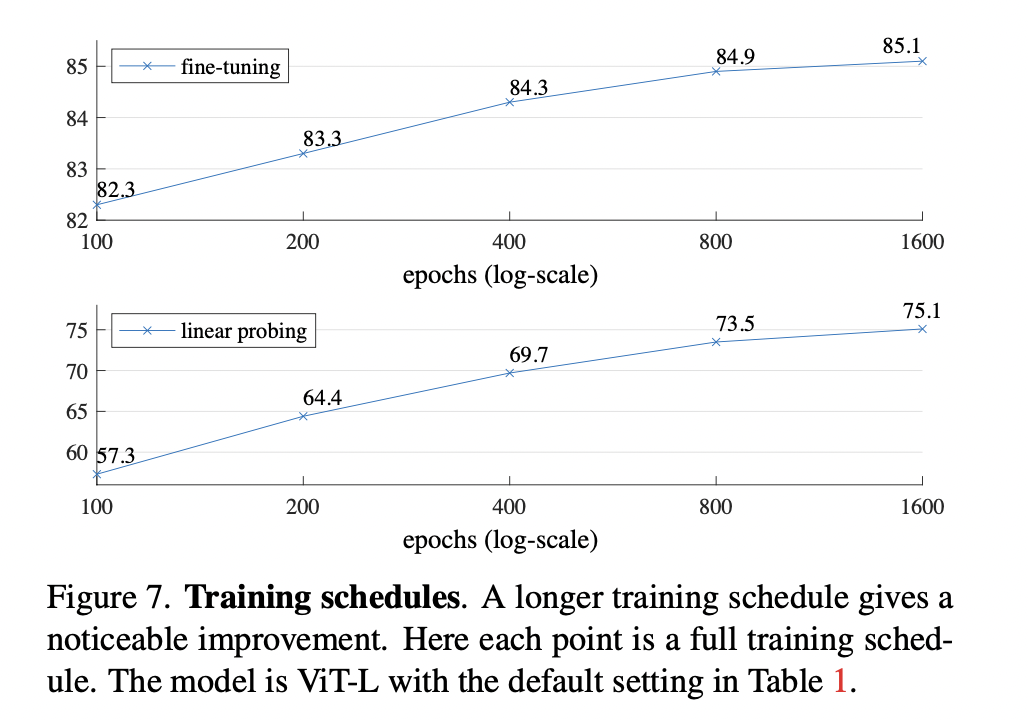
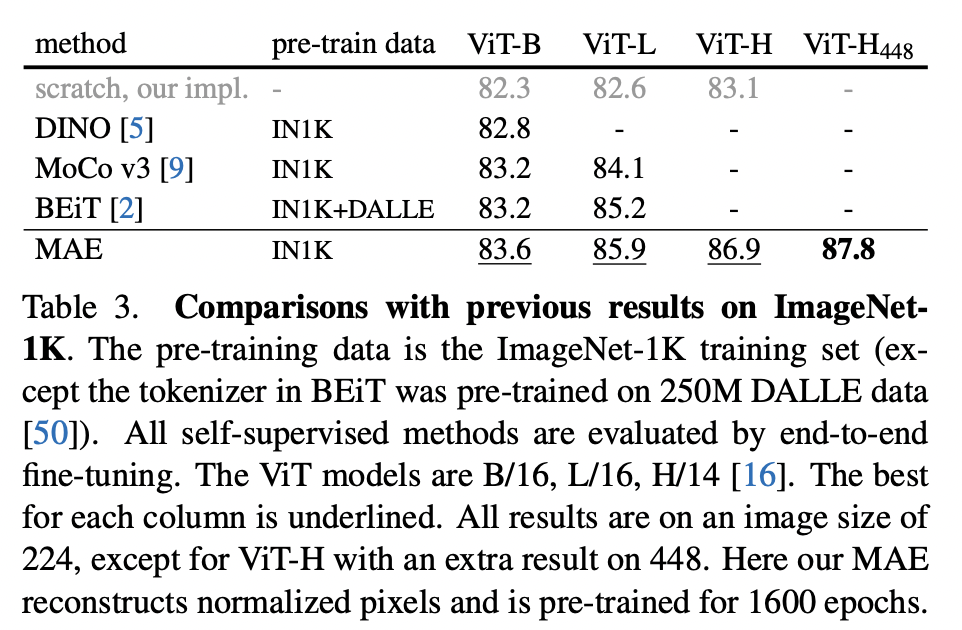
4.2 Comparisions with Previous Results
Comparisons with self-supervised methods.
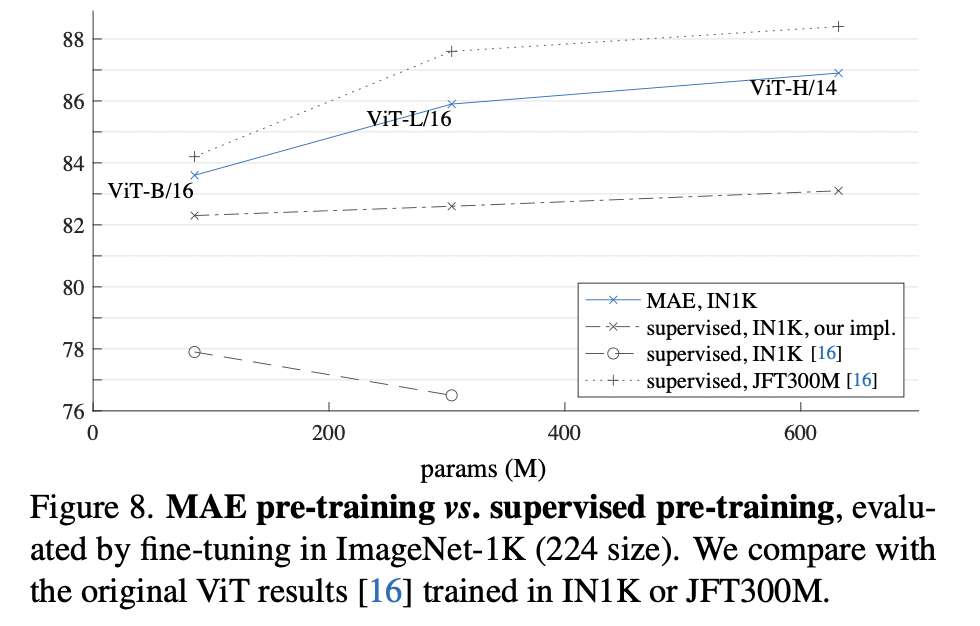
Comparisons with supervised pre-training.
4.3 Partial Fine-tuning
5. Transfer Lerning Experiments
Object detection and segmentation.
Semantic segmentation.
Classification tasks.
Pixels vs. tokens.
6. Discussion and Conclusion
