[논문정리] UPST-NeRF: Universal Photorealistic Style Transfer of Neural Radiance Fields for 3D Scene
논문
Abstract
3D scenes photorealistic stylization 은 주어진 style 이미지에 따라 임의의 새로운 뷰에서 photorealistic images를 생성하는 동시에 다른 viewpoints에서 렌더링할 때 일관성을 보장하는 것을 목표로 합니다.
하지만, 현재 neural radiance fields를 사용한 stylization methods는 objectionable한 artifacts가 포함된 새로운 view images를 생성합니다. 뿐만 아니라, 3D scene을 위한 universal photorealistic stylization도 만족하지 못합니다. 그래서 styling image는 neural radiation field를 기반으로 하는 3D scene representation network를 재학습해야 합니다.
논문에서는 이런 이슈를 다루기 위해 새로운 3D scene photorealistic style transfer framework 를 제안합니다. 2D style image로 photorealistic한 3D scene style transfer 를 실현할 수 있습니다. 실험을 통해 저자들의 방법이 임의의 style images의 photorealistic한 3D style transfer을 실현 할 뿐만 아니라, visual quality 및 consistency 측면에서 기존의 방법들보다 우수하다는 것을 증명합니다.
1. Introduction
최근 몇년간, neural radiation field 기반의 3D implicit representation 방법은 scene realism에서 뛰어난 성능으로 인해 큰 발전을 이루었습니다. 이러한 scenes의 appearance를 제어함으로써 style transfer은 artistic creation 시간과 전문 지식의 필요성을 줄일 수 있었습니다.
대부분의 이런 방법들은 stylized scenes의 consistency 문제를 어떻게 해결할 것인지에 초점을 두었습니다.
이러한 방법들은 artistic style의 transfer만 실현할 수 있을 뿐 realistic style의 transfer는 실현할 수 없습니다. 만약 3D scenes의 스타일을 transfer할 때 photorealistic images를 style images로 사용하면, stylized scenes에는 불쾌한 artifacts가 포함됩니다.
이 논문에서는 주어진 style examples set에 따라 photorealistic 3D scene을 stylize하는 것을 목표로 합니다. 논문에서의 방법은 임의의 새로운 views에서 scene의 stylized images를 생성하는 동시에 다른 viewpoints 에서 렌더링된 이미지의 consistent를 보장할 수 있고, 이를 위해 주어진 style image set으로 NeRF를 stylizing하는 문제를 제시합니다.
Some examples of our stylization method are presented in Fig. 1.

NeRF는 MLP를 사용해 implicitly 하게 학습한다. (mapping from the queried 3D point with its colors and densities) scene rendering의 성능을 비약적으로 높이긴 했지만, 아직도 너무 긴 학습시간과 비효율적인 videw rendering이다.
논문에서는 scene을 빠르게 reconstruct하기 위해서 DirectVoxelGO의 영감을 받아, voxel grids를 사용한다.
- density voxel grid : occupancy probability를 예측하기 위해 사용.
- feature voxel : color predicting 위해 얕은 MLP(RGBNet)를 사용
Since the implicit continuous volumetric representation is built on the millions of voxel grid parameters, it is unclear which parameters control the style information of the 3D scene.
✨ 이것을 해결하기 위한 한가지 방법은 먼저 새로운 view images를 렌더링한 다음 image stylization을 수행하여 기존 image/video stylization 접근 방식을 새로운 view rendering 기술과 결합하는 것입니다.
- Stylizing-3D-Scene의 영향을 받아, HyperNet과 HyperLinear를 사용하여 2D stylized learnable latent codes의 ambiguities를 conditioned inputs으로 처리합니다.
- Stylizing-3D-Scene과 다르게, 논문에서는 VGG와 함께 StyleEncoder를 사용하여 style images에서 style features를 추출합니다.
- 그런 다음 style features를 HyperNet의 입력으로 사용하여 HyperLiner의 가중치를 업데이트합니다.
- 마지막으로, style of updating the scene 을 달성하기 위해 HyperLiner를 사용해 RGBNet의 정보를 변경합니다.
보다 사실적으로 표현하기 위해, AdaIN(Adaptive Instance Normalization)을 직접 사용하여 새로운 view 의 스타일을 제한하는 대신,
논문에서는 예측된 색상 값을 제한하는 데 사용되는 target을 얻기 위해 다양한 views에서 truth value RGB를 처리하도록 2D photorealistic style transfer network를 trained했습니다..
Main contributions
- 논문에서는 주어진 style images로 3D scenes을 사실적으로 stylizing하기 위해 neural radiance fields의 새로운 universal photorealistic style transfer를 제안합니다.
- 논문에서는 neural radiation field의 geometric consistency 제약을 파악하고 2D method를 사용하기 위해 scene stylization의 latent codes로서 사실적인 style images의 features를 제어하기 위해 hyper network를 사용하는 것을 제안합니다.
- 논문에서는 scene의 photorealistic style transfer을 실현하기 위해, scene style을 제한하기 위해 다른 새로운 views에서 2D photorealistic style images를 처리하는 효율적인 2D style transfer network를 설계했습니다.
2. Related Work
Novel View Synthesis.
View synthesis 는 하나의 물체에 대해 물체를 중심으로 주변에서 사진을 찍어 다른 각도에서도 물체를 예
측하는 테스크입니다. 앞에서와 같은 이유로 본 논문에서는 NeRF기반이지만 DirectVoxelGo도 차용하는 방법을 제시하고 있습니다.
Neural radiance field, 줄여서 NeRF는 multi-layer perceptron을 사용해서 카메라의 ray를 따라 생기 는 5D coordinate를 Input으로 하여 Output인 density와 color를 가지고 volume rendering 방식을 이용하 여 이 정보를 project해 평면에 나타나는 색을 표현하게 됩니다.NeRF는 MLP 네트워크를 통해서 opacity와 radiance의 continuous volumetric field를 모델링합니다.
Image and video style transfer.
style transfer는 content image 와 style image 가 주어졌을 때 이미지의 주된 형태는 content image와 유사하게 유지하면서 스타일만 우리가 원하는 style image와 유사하게 바꾸는 작업입니다.
Image는 물론 Video에서도 style transfer가 많이 적용되는데 이제 이 style transfer task을 artistic한 style 을 transfer하는 것과 photorealistic한 style을 transfer하는 것 이렇게 두개의 카테고리로 나눌 수 있습니다.
오른쪽 그림에서 photorealistic style transfer가 원본 이미지의 형태를 잘 유지하면서 style을 입힌것을 볼 수 있습니다.
3D sence style transfer.
이제 3D scene에도 style transfer를 적용할 수 있는데 reference image를 통해서 3D 장면의 스타일을 바꾸 는 것입니다. 이런 task에서는 spatial consistency를 잘 유지해주는 것이 중요한 문제이고, 이 논문에서 차용한 Stylizing-3D-Scene의 hyper network는 blurry한 결과와 inconsistent한 모습을 해결하기 위해 사용되었다 고 합니다.
현재 나와있는 대부분의 방법들은 새로운 view에서의 3D scene synthesis를 렌더링할 때 생기는 artifacts 때 문에 좋은 결과를 내기 힘들다고 합니다.
3. Preliminaries
NeRF 는 scene을 opacity와 radiance의 continuous volumetric field로 모델링하기 위해 MLP network를 이용합니다.
- : density predicting
- : radiance color predicting
- : 3D position
- : viewing direction
- : corresponding density
- : view-dependent color emission
- : intermediate embedding tensor with dimension
- : positional encoding.

pixel 의 색상을 렌더링하기 위해 카메라 중심에서 pixel을 통과하는 ray :
- : number of sampling points on between the pre-defined near and far planes;
- : probability of termination at the point
- : accumulated transmittance from the near plane to point
- : distance to the adjacent sampled point
- : pre-defined background color.
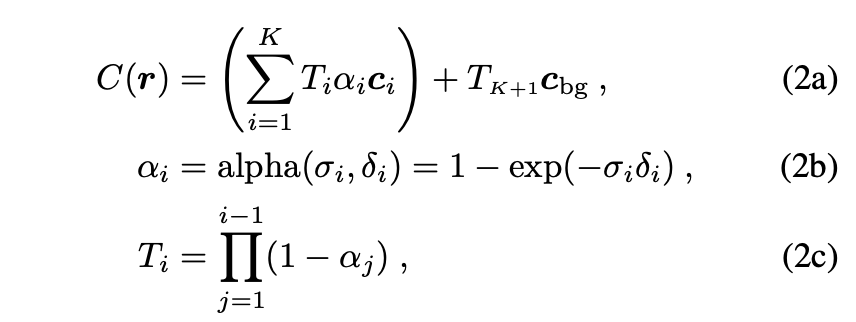
training 단계에서, NeRF는 training set에 있는 이미지의 픽셀 색상 과 렌더링된 픽셀 색상 사이의 Mean Square Error(MSE)를 최소화하여 모델을 최적화합니다. (: set of rays in a sampled mini-batch.)
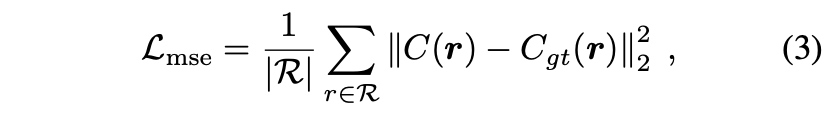
4. Our Approach
Overview of the universal photorealistic style transfer of neural radiance fields (Figure 2)
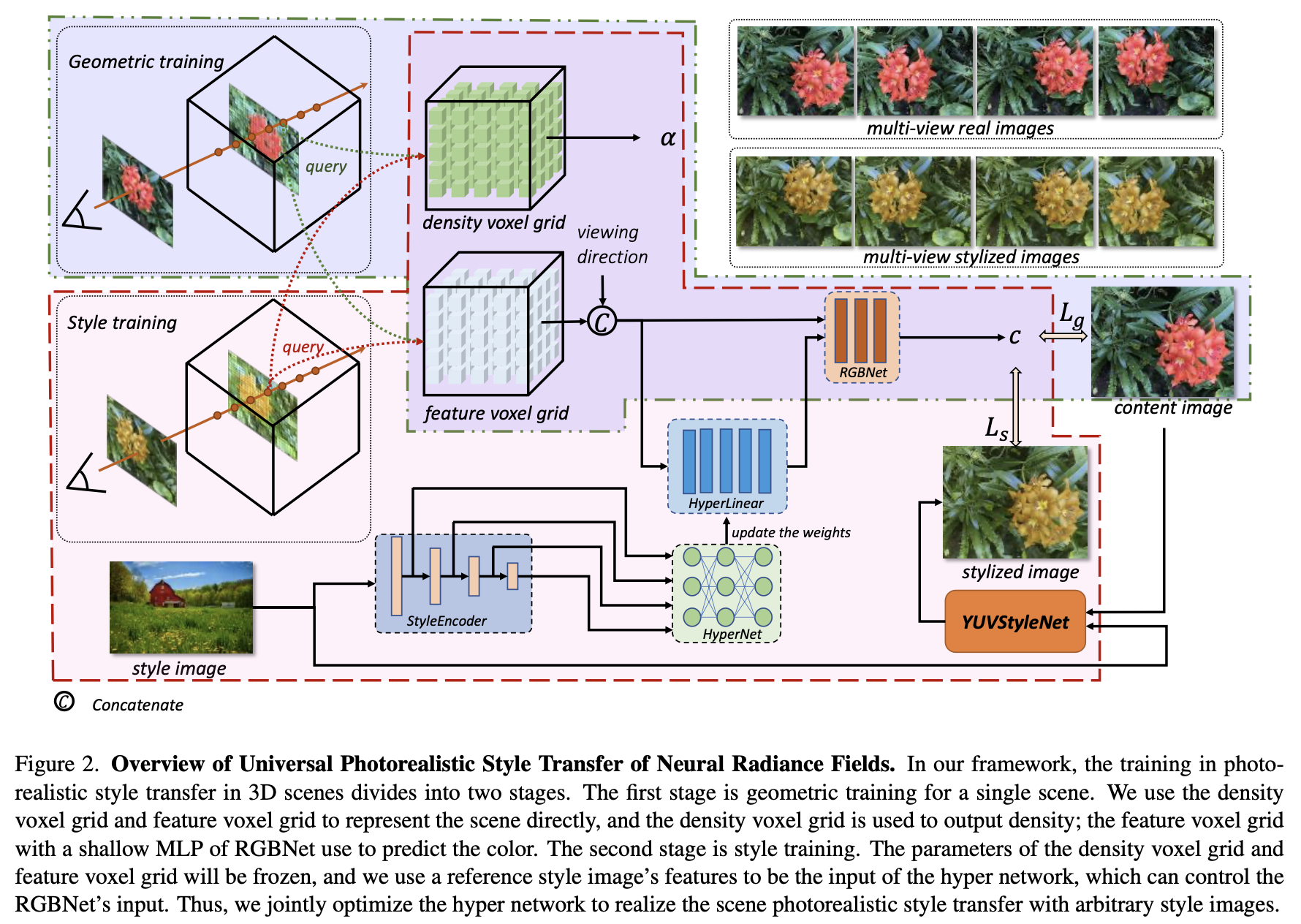
🥅 논문에서의 Goal은 주어진 scene의 여러 이미지들을 통해서, geometric consistency 를 유지하면서 reference style image에 따라 scene의 임의의 시점에서 photorealistic한 styled image를 생성하는 것입니다.
논문의 프레임워크에서 single scene은 두가지 단계로 학습합니다.
- geometric training
- style training.
그리고 rendering processing에서는, 임의의 reference image의 스타일에 따라 photorealistic한 style transfer을 통해서 새로운 viewpoints를 합성할 수 있습니다.
4.1. Scene Geometric Reconstruction
DirectVoxelGO와 유사하게, 논문에서는 3D scene을 표현하기 위해 voxel grid를 사용합니다. 이러한 scene representation은 interpolation을 통해 3D positions을 query하는 데 효율적입니다.
- : queried 3D point
- : voxel grid
- : dimension of the modality
- : total number of voxels.
Trilinear interpolation is applied if not specified otherwise.
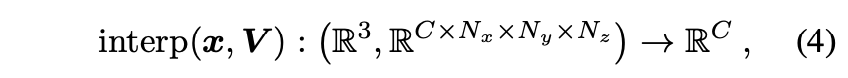
- alpha (Eq. (2b)) functions sequentially for volume rendering
- softplus: activation function
- : density voxel grid.
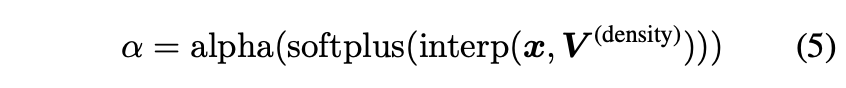
For view-dependent color emission predicting can be expressed as:
- : view-dependent color emission
- : feature voxel grid
- : hyperparameter for feature-space dimension.
By default, we set equal to 128. The MLP is shown in Fig. 2 as RGBNet.
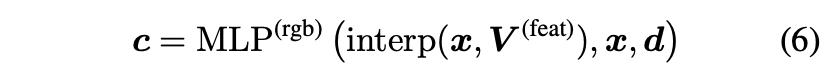
Eq.3에서는 photometric loss를 사용했습니다. DirectVoxelGO와 비슷하게, per-point rgb loss와 background entropy loss 그리고 modification loss를 아래와 같이 통합합니다.
background entropy loss은 렌더링된 background probability를, in Eq. (2), foreground나 background에 집중하기 위해서 정규화해줍니다.

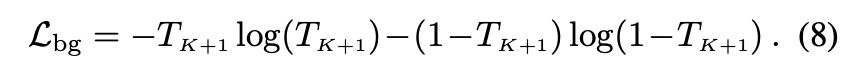
마지막으로, geometric training 단계의 전반적인 training objective는 아래와 같습니다.
where are hyperparameters of the loss weights.
4.2. YUVStyleNet for 2D photorealistic stylization
2D photorealistic stylization은 reference image의 스타일을 content target에 transfer 하는 작업으로, 카메라로 찍은 것처럼 그럴듯하게 photorealistic result 를 만듭니다.
논문에서는 style training 단계에서 scene의 새로운 view에서 이미지의 photorealistic style transfer을 위한 2D photorealistic style transfer 네트워크를 설계했고, YUVStyleNet라 이름 붙였습니다.(Figure. 3)
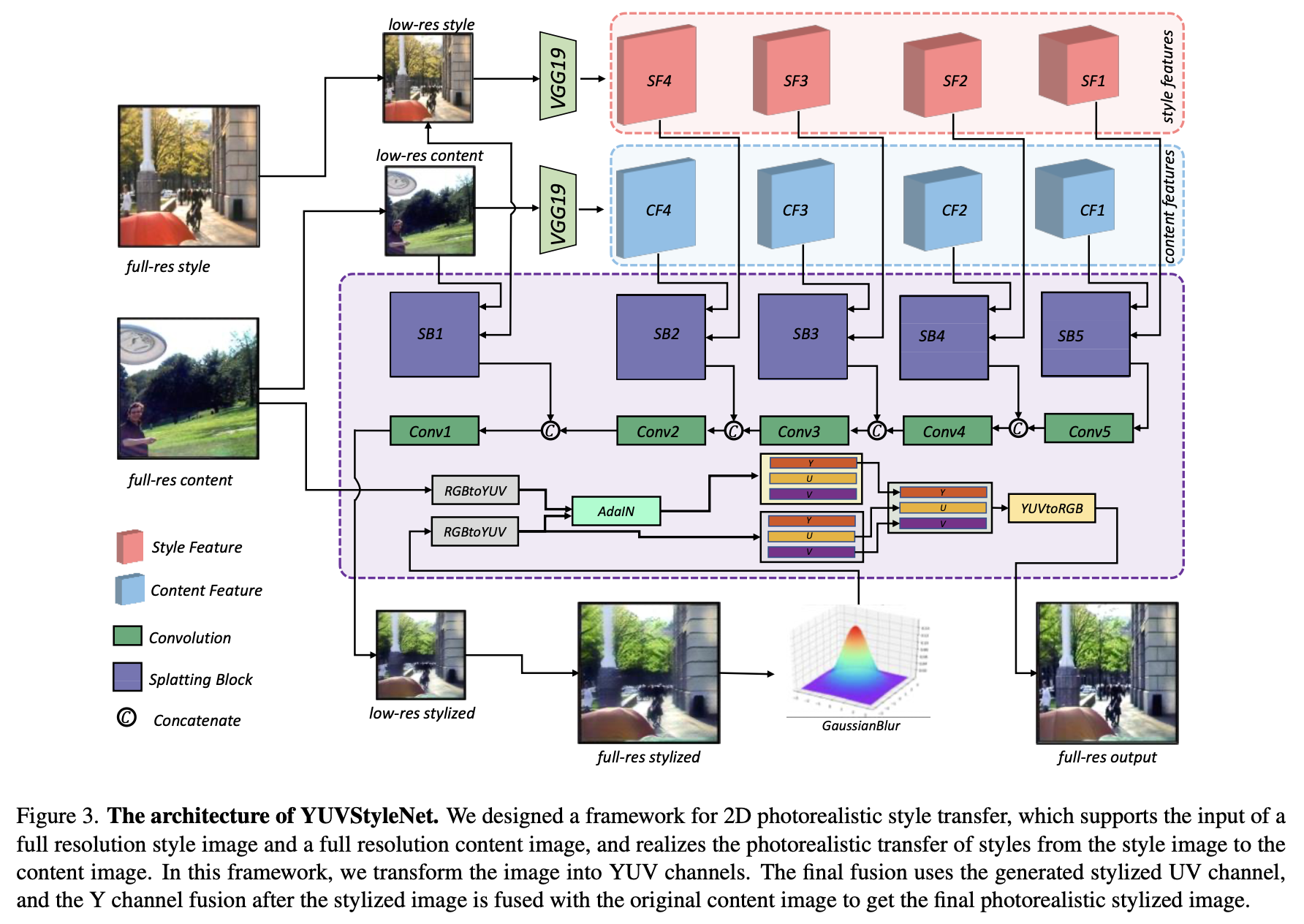
GPU 메모리를 줄이고 처리 속도를 높이기 위해, 입력인 full-resolution style image 와 the content image 를 downsampling해서 각각 low-resolution images 와 로 만들어 줍니다.(size of low-resolution image is 512 by default.)
그리고, pre-trained된 VGG model을 사용해 style features {} | 와 content features {} | 를 각각 다른 scales에서 뽑습니다.
해당하는 scale의 style features and content features와 해당하는 low-resolution style image and content image는 splatting block module의 입력으로 feature 쌍으로 사용되어 해당 scale에서 출력 {} | 를 얻습니다.
그리고 먼저 convolution을 통해서 입력 feature와 feature를 뽑고, adaptive instance normalization (AdaIN)을 사용해서 splatting block module으로 features를 결합합니다.
Splatting block의 출력 features를 각각 low-scale features와 연결한 후, convolution 연산을 통해 최종적으로 low resolution stylized image 를 얻습니다.
upsampling을 통해서, 입력 와 동일한 scale인 stylized image 를 얻습니다. 그리고 color transfer를 부드럽게 하기 위해, Gaussian filter를 사용하여 를 처리해 를 얻습니다.
그리고 원본 content image와 를 and 처럼 YUV domain로 전환하고, AdaIN을 통해 을 얻습니다.
생성된 photorealistic stylized image의 밝기를 원본 이미지와 동일하게 하기 위해 에서 Y 채널을 추출하고 에서 UV 채널을 추출하여 새로운 style image 를 얻습니다.
그리고 마지막으로 RGB space로 변환함으로써 을 얻을 수 있습니다.👏
논문에서는 AdaIN을 참조해서 style loss 와 content loss 를 정의합니다. 추가로, 더 photorealistic한 효과를 얻기 위해, 생성된 style image 와 원본 content image 간의 제약 조건으로 Peak Signal to Noise Ratio (PSNR)와 Structural Similarity (SSIM)를 비교합니다. 그래서 PSNR loss 와 SSIM loss 를 추가합니다.
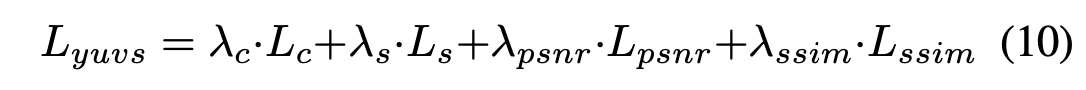
4.3. Style Learning in 3D Scene
임의의 style images를 입력으로 사용해 scene의 스타일을 바꾸기 위해, 논문에서는 scene rendering 할때 RGBNet의 입력 features를 제어하기 위한 hyper network (HyperNet)와 a hyper linear network (HyperLinear)를 디자인 했습니다.
다시 Figure 2의 style training stage를 살펴보자.
- corresponding view에서 쿼리된 'feature voxel grid'의 feature는 HyperLinear 네트워크의 입력으로 view direction feature와 연결됩니다.
- HyperLinear의 출력은 RGBNet의 입력으로 직접 사용되어 color generation을 컨트롤합니다.
- style image는 pre-trained 된 feature extraction network 인 VGGNet을 통해 추출되어 HyperNet의 입력으로 사용됩니다.
- HyperNet의 출력은 HyperLinear의 weight를 제어하고 style features를 통해 scene의 color를 수정하는 데 사용됩니다.
3D style training 단계에서, 우리는 Eq. 7, 8, 9를 optimizing해서 style transfer의 훈련 과정을 제한합니다. Section 4.1에서 말한것과 다른점은 을 YUVStyleNet으로 바꿨다는 것이다.
우리는 rays의 mini-batch를 통해 해당 content image를 얻고(Fig. 4), MS-COCO에서 무작위로 수집된 style image를 YUVStyleNet의 입력으로 사용하고 predicted image를 로 사용합니다. 따라서 식.7을 아래와 같이 수정할 수 있습니다: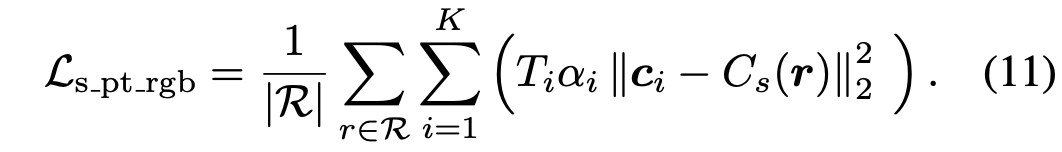
그리고 loss constraint of scene style transfer 은 아래와 같습니다.(는 loss weights의 hyperparameters.):
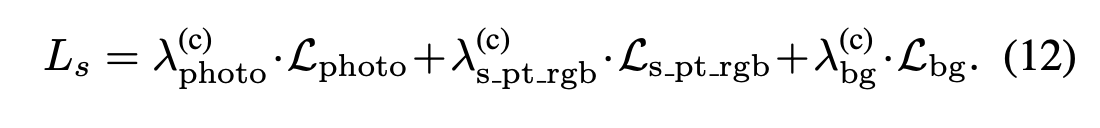
그리고 style training 단계에서는, geometry training 과정에서 최적화된 density voxel grid와 feature voxel grid를 froze 시킵니다. 동시에 YUVStyleNet의 파라미터와 VGG를 feature extraction을 위한 디코더로 사용하는 StyleEncoder의 파라미터도 froze 시킵니다.
5. Experiments
5.1. Qualitative Results
Photorealistic style transfers with artistic style images.

Photorealistic style transfer with photorealistic style images.

Video stylization.

5.2. Quantitative Results
Table 1. Short-range consistency.
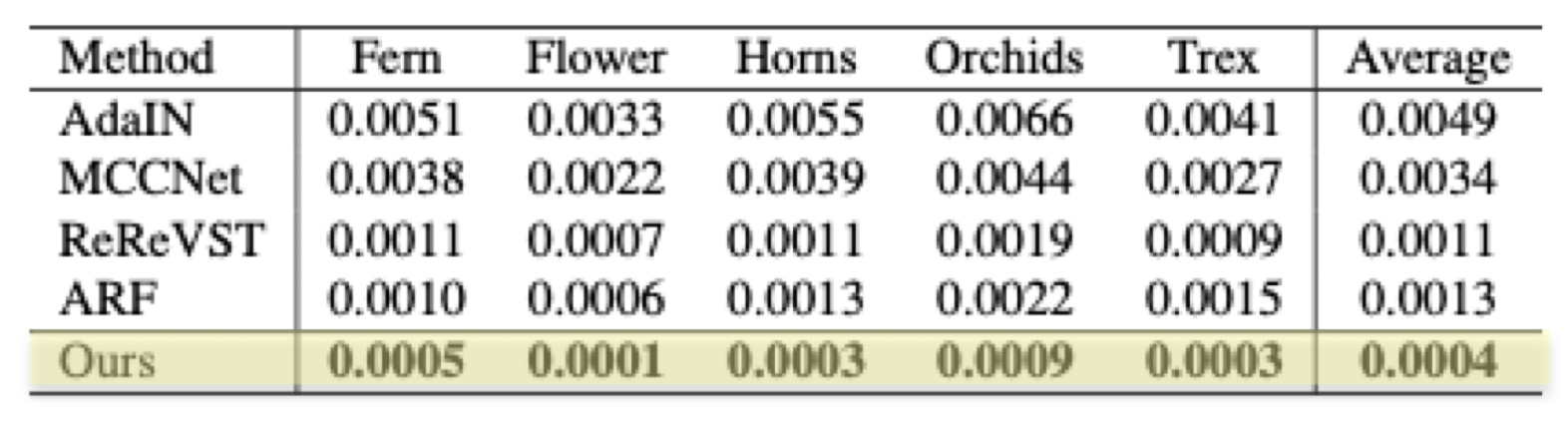
Table 2. Long-range consistency.
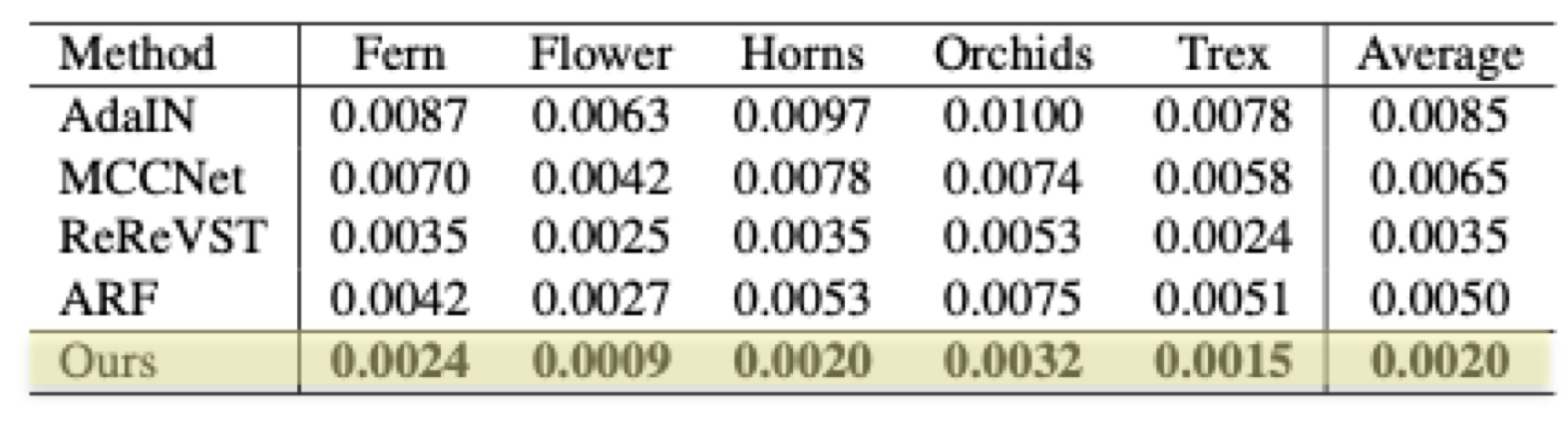
User study.
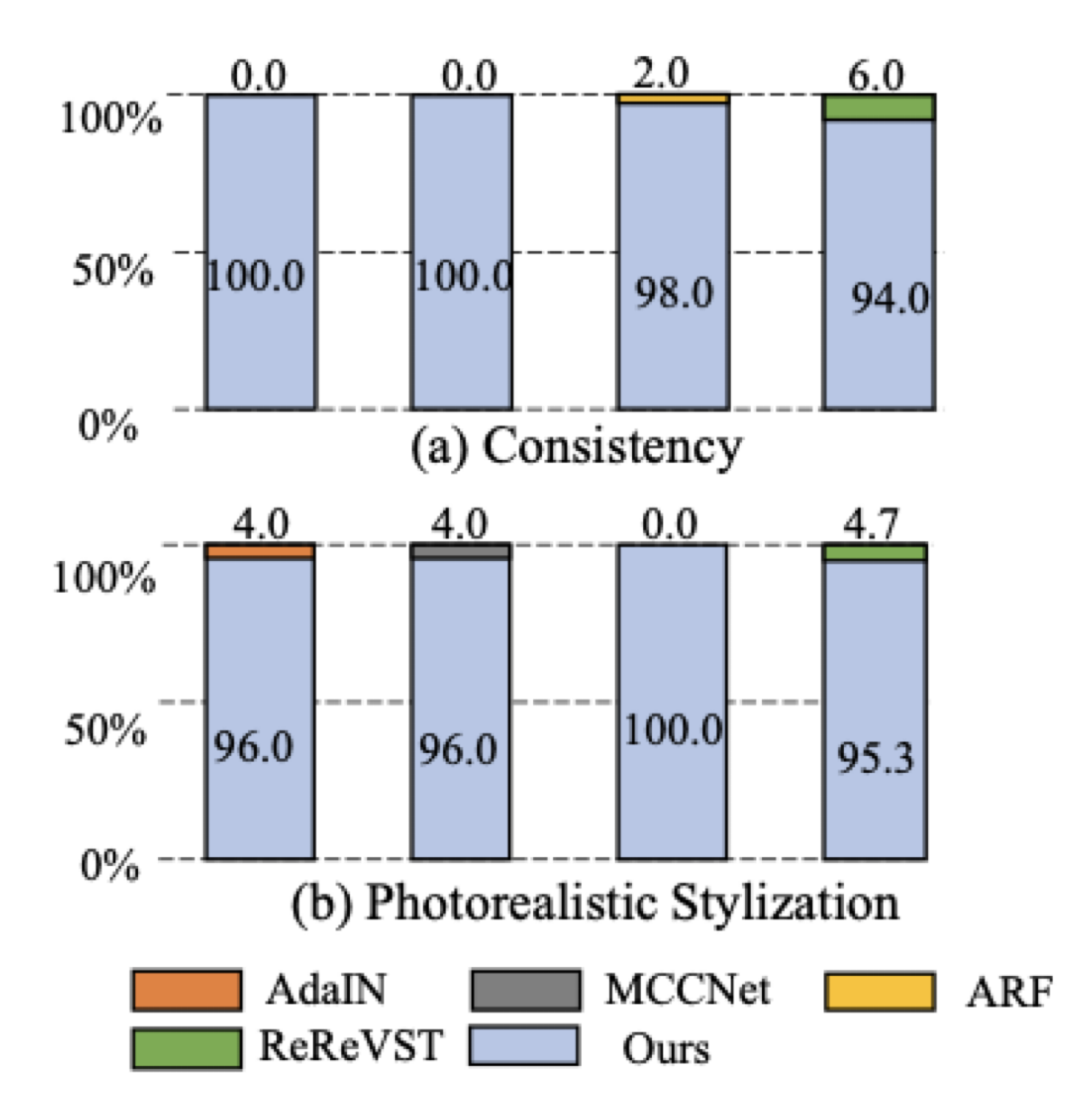
5.3. Ablation Study
The impact of voxel grid gradient propagation in the style training stage.

The impact of a batch size of rays in style training.

Comparisions on Tanks and Temples datasets.

6. Conclusion
- We present a universal photorealistic style transfer method with neural radiance fields for the 3D scene.
- We directly reconstruct the geometric representation through the voxel grid .
- We use a hyper network to control the weights and pre-trained 2D photorealistic style network to perform photorealistic style transfer.
- Our method outperforms state-of-the-art methods but, our direct optimization of scene geometry via voxel grid has limitations in large 3D scenes.
