https://neural-3d-video.github.io/
Abstract
논문에서는 고품질 view synthesis와 motion interpolation을 가능하게 하는 compact 하면서도 expressive한 representation으로 dynamic real-world의 multi-view video recording을 표현할 수 있는 3D video synthesis를 위한 새로운 접근 방식을 제안합니다.
Our approach takes the high quality and compactness of static neural radiance fields in a new direction: to a model-free, dynamic setting.
논문의 접근 방식은 새로운 방향으로 static neural radiance fields의 high quality 및 compactness을 얻는다: model-free, dynamic setting.
접근 방식의 핵심은 일련의 compact latent codes를 사용하여 scene dynamic 을 나타내는 새로운 time-conditioned neural radiance field 입니다. ray importance sampling 과 결합된 새로운 hierarchical training scheme을 통해 생성된 이미지의 훈련 속도와 perceptual 품질을 크게 높일 수 있습니다.
학습된 representation은 매우 compact해서 모델 크기가 28MB에 불과한 18대의 카메라로 10초 30FPS multi-view video recording 을 나타낼 수 있습니다. 또한, qualitative 및 quantitative 평가를 수행해 논문의 방법이 복잡하고 역동적인 장면에 대해서도 1K 이상의 resolution에서 high-fidelity하고 wide-angle novel views를 렌더링할 수 있음을 보여줍니다.
1. Introduction
동적인 real-world의 장면들은 아래와 같은 이유로 고전적인 mesh-based representations을 사용해서 모델링하기 아주 어렵습니다.😵
- contain thin structures
- semi-transparent objects
- specular surfaces
- topology that constantly evolves over time
이론상, 6D plenoptic function 는 visual reality를 완전히 설명하고 매 순간 가능한 모든 view를 렌더링할 수 있기 때문에 이런 렌더링 문제에 적절한 representation 입니다.
- : camera position in 3D space
- : viewing direction
- : time
→ plenoptic function을 fully measuring하는 것은 space 상의 모든 위치와 모든 가능한 시간에 omnidirectional camera를 두는 것을 요구합니다.
Neural radiance fields (NeRF) 는 이 문제를 circumvent 하는 방법을 제시합니다. → plenoptic function 을 바로 encoding 하는 것이 아닌, scene 의 radiance field 를 implicit(coordinate-based function)한 방법으로 encode 합니다. 이것은 plenoptic function을 approximate하는 ray casting을 통해 샘플링 될 수 있습니다.
😵 하지만 neural radiance field 를 train and render 하기를 요구하는 ray casting은 "각각의" ray 마다 100개의 MLP evaluations을 야기합니다.
→ Really Really bad for dynamic sence 💢 (예를 들어, 10초의 18개 카메라로 기록된 30FPS multi-view video을 보여주기 위해서, per-frame NeRF 는 학습시 15000 GPU 시간과 1 GB 저장공간이 필요합니다.)
그리고 더 중요한 것은, 이렇게 얻어진 representatiosn은 그 사이를 reproduce 할 수단이 없는 discrete한 snapshots set으로 재현한다는 것입니다.
반면에, Neural Volumes은 dynamic objects를 다룰 수 있고 interactive frame rates 로 렌더링할 수도 있습니다. 하지만 고유한 메모리 복잡성으로 인해 reconstructed scene 의 해상도 및 크기를 제한하는 dense uniform voxel grid 가 한계가 됩니다.
✨ 이 논문에서 우리는 고품질 view synthesis와 motion interpolation을 가능하게 하는 complex하고 dynamic한 real-world scenes의 3D video synthesis 에 대한 새로운 접근 방식을 제안합니다.
비디오의 dynamic component는 일반적으로 locally correlated 된 geometric 변형과 프레임들 사이의 appearance changes를 나타냅니다.
이런 사실을 이용해, 논문에서는 dyanmic neural radiance field 를 아래와 같은 2가지의 새로운 contributions 기반으로 reconstruct하는 것을 제안합니다.
-
첫째, neural radiance fields 를 space-time domain으로 확장 합니다.
→ time을 바로 입력으로 사용하지 않고, compact한 latent codes set으로 scence motion과 appearance changes 를 parameterize 합니다. -
둘째, dynamic radiance fields 에 대한 새로운 importance sampling strategies를 제안합니다.
→ 종종 캡쳐된 dynamic video는 프레임 사이에서 적은 양의 pixel 변화를 나타냅니다. 이는 훈련에 가장 중요한 픽셀을 선택하여 훈련 진행을 크게 높일 수 있습니다. 특히 time dimension에서, 프레임에서 coarse-to-fine hierarchical한 샘플링으로 훈련을 진행합니다. ray/pixel dimension 에서는 다른 것보다 더 time-variant pixels을 샘플링하는 경향이 있습니다.
이런 방법을 통해 high quality reconstruction 결과를 유지하면서 long sequences의 훈련 시간을 크게 단축할 수 있습니다.
Contributions ✨
- Real-world scenes의 고품질 3D video synthesis를 달성하는 temporal latent codes를 기반으로 하는 새로운 dynamic neural radiance field를 제안합니다.
- Spatiotemporal 영역에서 hierarchical training 과 importance sampling을 기반으로 하는 새로운 훈련 전략을 제시합니다. 이는 훈련 속도를 크게 높이고 더 긴 시퀀스에 대해 더 높은 품질의 결과로 이어집니다.
- 연구 목적으로 까다로운 4D 장면을 다루는 time-synchronized 및 calibrated multi-view videos 를 제공합니다.
2. Related Work
Novel View Synthesis for Static Scenes
Novel view syn- thesis has been tackled by explicitly reconstructing textured 3D models of the scene and rendering from arbitrary viewpoints.
3D Video Synthesis for Dynamic Scenes
we seek a unified space-time representation that enables continuous viewpoint and time interpolation, while being able to represent an entire multi-view video sequence of 10 seconds in as little as 28MB.
3. DyNeRF: Dynamic Neural Radiance Fields
논문에서는 알려진 intrinsic 및 extrinsic parameters를 사용해 time-synchronized 된 multi-view videos 에서부터 dynamic 3D scenes을 재구성하는 문제 를 해결합니다.
이러한 multi-camera recordings 에서 재구성하려는 representation은 임의의 시점에서 광범위한 viewpoints로부터 사실적인 이미지를 렌더링할 수 있어야 합니다.
Dynamic neural radiance fields (DyNeRF)
- NeRF 기반 구축
- 다수의 video cameras로 포착된 입력 비디오로부터 바로 최적화됨.
- training 중에 jointly하게 최적화되는 일련의 temporal latent embeddings으로 제어할 수 있는, 새로운 continuous한 space-time neural radiance field representation.
논문의 representation은 여러 카메라의 방대한 양의 입력 비디오를 공간과 시간 모두에서 지속적으로 queried할 수 있는 compact 6D representation으로 압축합니다. 그리고 학습된 embedding은 명시적인 geometric tracking 없이도 복잡한 광도 및 위상 변화와 같은 장면의 상세한 시간적 변화를 정확하게 캡처합니다.
3.1 Representation
Dynamic Neural Radiance Fields.
3D video를 표현하는 문제는 6D plenoptic function을 학습하는 것❗️
6D plenoptic function maps a 3D position , direction , time , to RGB radiance and opacity .
(NeRF를 기반으로 하면서 time dependency를 추가했습니다.):which is realized by a Multi-Layer Perceptron (MLP) with trainable weights Θ.
1차원 time variable 는 positional encoding을 통해서 higher dimensional space로 매핑될 수 있습니다.(NeRF가 입력 x와 d를 다루는 방식과 비슷.)
하지만, 논문에서는 실험적으로 이렇게 디자인하는 것이 복잡한 topological 변화와 flames 같은 time- dependent volumetric effects가 있는 복잡한 dynamic 3D scenes를 캡처하는 것이 어렵다는 것을 발견했습니다.
Dynamic Neural Radiance Fields.
Figure 2에서와 같이 논문에서는 time-variant latent codes 를 통해 dynamic scene을 모델링합니다.
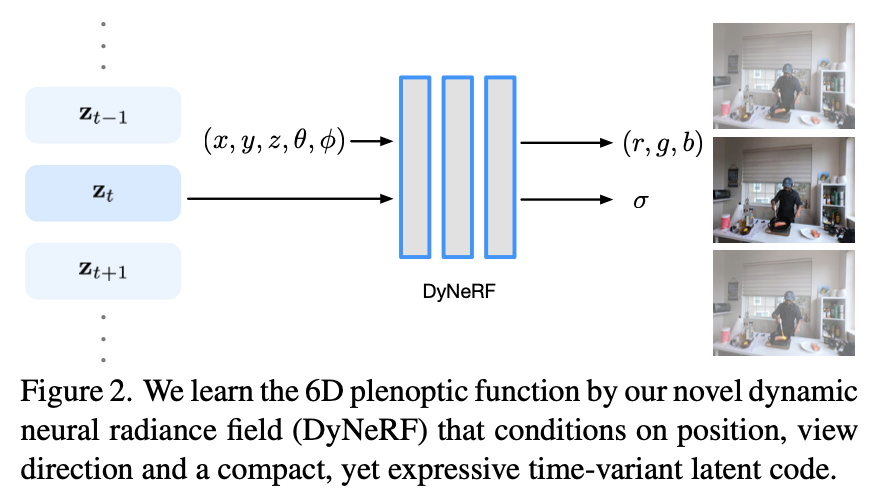
discrete time variable 에 의해 indexed 된 time-dependent latent codes set을 학습합니다.:
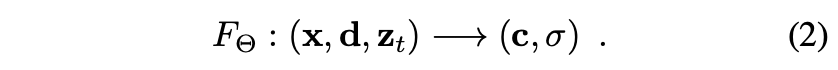
latent codes는 특정 시간에서 dynamic scene 상태의 compact representation을 알려줍니다. (which can handle various complex scene dynamics, including deformation, topological and radiance changes.) 그리고 입력 위치 좌표에 positional encoding을 적용하여 더 높은 차원의 벡터에 매핑합니다.
하지만, time-dependent latent codes 에는 positional encoding을 적용할 수 없기 때문에 논문에서는 학습전에 latent codes {}를 독립적으로 모든 프레임에서 무작위로 초기화합니다.
Rendering.
We use volume rendering techniques to render the radiance field given a query view in space and time.
Given a ray (origin and direction defined by the specified camera pose and intrinsics), the rendered color of the pixel corresponding to this ray is an integral over the radiance weighted by accumulated opacity:
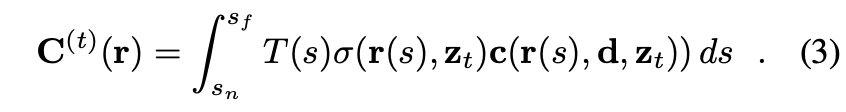
where and denote the bounds of the volume depth range and the accumulated opacity .
We apply a hierarchical sampling strategy as [39] with stratified sampling on the coarse level followed by importance sampling on the fine level.
Loss Function.
network parameters 와 latent codes {}는 rendered colors 와 ground truth colors 사이의 -loss를 최소화 하는 방향으로 동시에 학습된다. 또한 모든 training camera views 및 recording의 모든 시간 프레임 에서 이미지 픽셀에 해당하는 모든 rays 에 대해서도 더해줍니다.:
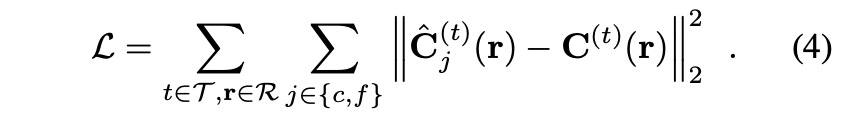
3.2. Efficient Training
비디오 데이터에 ray casting–based neural rendering의 추가적인 문제는 아주 많은 양의 training time이 필요하다는 것입니다. Epoch당 훈련 반복 횟수는 입력인 multi-view videos의 총 픽셀 수에 따라 linearly하게 확장됩니다. 고품질의 결과를 얻으려면 각 ray를 여러 번 다시 방문해야 하므로 이런 샘플링 프로세스는 3D videos를 대규모로 학습하기 위한 ray-based neural reconstruction 방법의 가장 큰 bottlenecks 중 하나입니다.
(예를 들어 10초, 30FPS, 18개 카메라의 1MP multi-view 비디오 시퀀스의 경우 한 epoch에 약 74억 개의 ray samples이 있으며, 이는 8개의 NVIDIA Volta 클래스 GPU를 사용하여 처리하는 데 약 4일이 소요됩니다.)
그러나 natural video의 경우 dynamic scene의 많은 부분이 time-invariant 이거나 관찰된 전체 비디오에서 특정 타임스탬프에서 작은 time-variant radiance 변화만 포함합니다. 따라서 uniformly sampling rays는 time-invariant observations과 time-variant 사이에 imbalance를 일으킵니다.
이것은 매우 비효율적이고 reconstruction quality 에 영향을 미칩니다.: time-invariant 영역은 더 빨리 높은 재구성 품질에 도달하고 쓸데없이 oversampled되는 반면, time-variant 영역은 추가 샘플링이 필요하여 훈련 시간이 늘어납니다.
3D video의 context에서 temporal redundancy을 탐색하기 위해 training process를 가속화하기 위한 두 가지 전략을 제안합니다(Fig 3 참조).
(1) coarse-to-fine frame selection을 통해 데이터를 최적화하는 hierarchical training.
(2) temporal variance가 더 높은 영역 주변의 rays를 선호하는 importance sampling.
특히 이 전략은 학습시 time frame set S 와 pixel set 에서 "important" rays에 초점을 줌으로써 아래와 같이 약간 다른 loss function을 구성합니다.
→ These two strategies combined can be regarded as an adaptive sampling approach, contributing to significantly faster training and improved rendering quality. 👍
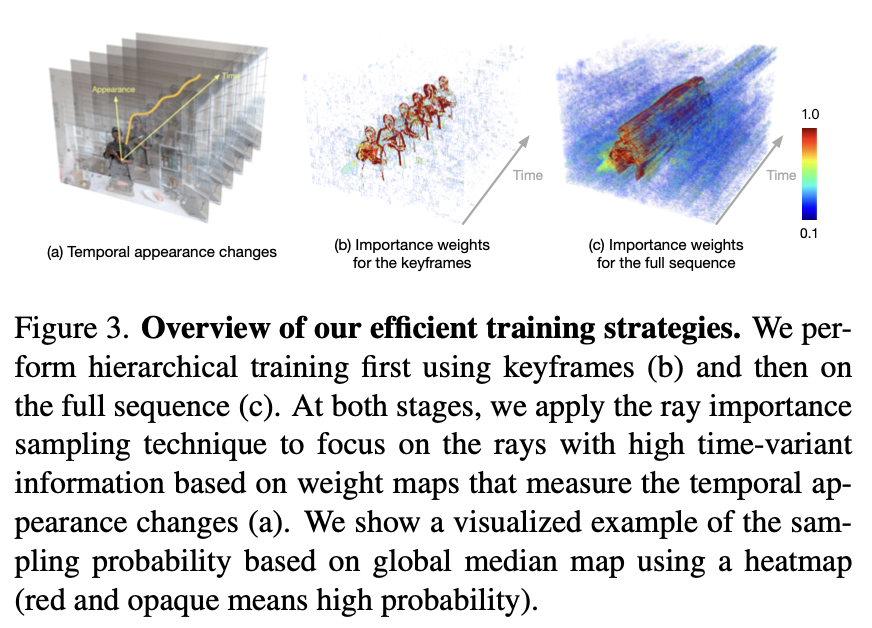
Hierarchical Training.
-
논문에서는 모든 비디오 프레임에서 DyNeRF을 training 시키는 것이 아니라 먼저, 고정된 time intervals 에서 equidistantly 하게 모든 이미지를 샘플링한 keyframes에서 학습시킨다.({}.)
-
모델이 keyframe supervision에 수렴하면, full video와 동일한 temporal resolution을 가진 final model을 초기화하기 위해 사용합니다.
-
각각의 segment내 장면의 per-frame motion이(neighboring keyframes으로 구분됨) 부드럽기 때문에, coarse embeddings 사이를 linearly interpolating함으로써 fine-level latent embeddings을 초기화합니다.
-
마지막으로 모든 프레임의 데이터를 함께 사용해서 훈련하고(), 추가로 network weights와 latent embeddings을 최적화합니다.
→ coarse keyframe model은 이미 비디오 전체에서 time-invariant 정보의 근사치를 캡처했기 때문에 fine full-frame training은 프레임당 time-variant만 학습하면 됩니다.✨
Ray Importance Sampling.
논문에서는 입력 비디오의 temporal variation을 기반으로 다른 중요도로 시간에 따른 rays 를 샘플링할 것을 제안합니다. time 에서 관찰된 각 ray 에 대해 weight 를 계산합니다.
training iteration마다 무작위로 time frame 를 고릅니다. 먼저 frame 의 모든 입력 views에서 rays의 weights를 normalize한 다음, inverse transform sampling을 적용하여 이러한 가중치를 기반으로 rays를 선택합니다.
각 ray의 weight를 계산하기 위해, 서로 다른 insights를 기반으로 세 가지 implementations을 제안합니다.
- Global-Median (DyNeRF-ISG): We compute the weight of each ray based on the residual difference of its color to its the global median value across time.
- Temporal-Difference (DyNeRF-IST): We compute the weight of each ray based on the color difference in two consecutive frames.
- Combined Method (DyNeRF-IS): Combine both strategies above.
논문에서는 high learning rate으로 DyNeRF-ISG를 훈련하면 dynamic detail을 매우 빠르게 복구하지만, 시간이 지남에 따라 약간의 jitter가 발생한다는 것을 실험적으로 관찰했습니다. 반면에 low learning rate으로 DyNeRF-IST를 훈련하면 여전히 다소 blurry한 부드러운 시간 시퀀스가 생성됩니다.
따라서 논문에서는 최종 전략인 DyNeRF-IS(이후에서는 DyNeRF)에서 두 방법의 이점을 결합합니다. 이 전략은 먼저 DyNeRF-ISG를 통해 sharp한 세부 정보를 얻은 다음 DyNeRF-IST를 통해 temporal motion을 부드럽게 합니다.
4. Experiments
4.1. Evaluation Settings
Plenoptic Video Datasets.
- We build a mobile multi-view capture system using 21 GoPro Black Hero 7 cameras.
- We capture videos at a resolution of 2028 × 2704 (2.7K) and frame rate of 30FPS.
- The multi-view inputs are time-synchronized.
- We obtain the camera intrinsic and extrinsic parameters using COLMAP.
- We employ 18 views for training, and 1 view for qualitative and quantitative evaluations for all datasets except one sequence observing multiple people moving, which uses 14 training views.
Our captured data demonstrates a variety of challenges for video synthesis, including
(1) objects of high specularity, translucency and transparency,
(2) scene changes and motions with changing topology (poured liquid),
(3) self- cast moving shadows
(4) volumetric effects (fire flame)
(5) an entangled moving object with strong view-dependent effects (the torch gun and the pan)
(6) various lighting conditions (daytime, night, spotlight from the side)
(7) multiple people moving around in open living room space with outdoor scenes seen through transparent windows with relatively dark indoor illumination.
Our collected data can provide sufficient synchronized camera views for high quality 4D reconstruction of challenging dynamic objects and view-dependent effects in a natural daily indoor environment, which, to our knowledge, did not exist in public 4D datasets. We will release the datasets for research purposes.
Immersive Video Datasets.
We also demonstrate the generality of our method using the multi-view videos from [6] directly trained on their fisheye video input.
Baselines. We compare to the following baselines:
- Multi-View Stereo (MVS): frame-by-frame rendering of the reconstructed and textured 3D meshes using commercial software RealityCapture.
- Local Light Field Fusion (LLFF): frame-by-frame rendering of the LLFF-produced multiplane images with the pretrained model.
- NeuralVolumes (NV): One prior-art volumetric video rendering method using a warped canonical model.
We follow the same setting as the original paper.
- NeRF-T: a temporal NeRF baseline as described in Eq.1
- DyNeRF: An ablation setting of DyNeRF without our proposed hierarchical training and importance sampling.
Due to page limit, we provide more ablation analysis of our importance sampling strategies and latent code dimension in Supp. Mat.
Metrics.
We evaluate the rendering quality on test view and the following quantitative metrics:
(1) Peak signal-to-noise ratio (PSNR)
(2) Mean square error (MSE)
(3) Structural dissimilarity index measure (DSSIM)
(4) Perceptual quality measure LPIPS
(5) Perceived er- ror difference FLIP
(6) Just-Objectionable-Difference (JOD)
Higher PSNR and scores indicate better reconstruction quality and higher JOD represents less visual difference compared to the reference video. For all other metrics, lower numbers indicate better quality.
길이가 60 frames 미만인 비디오의 경우 전체 비디오에서 프레임별로 모델을 평가하고, 고해상도 렌더링에서는 많은 연산량이 필요하기 때문에 10 frames마다 모델을 평가하여 길이가 300 frames 이상인 비디오에 대해 frame-by-frame metrics을 계산합니다.(Table 1)
continuous video frames 스택이 필요한 video metric JOD의 경우, 전체 시퀀스에 대한 모델을 평가합니다. (Table 2)
We verified on 2 video sequences with a frame length of 300 that the PSNR differs by at most 0.02 comparing evaluating them every 10th frame vs. on all frames. 모든 모델을 1K 해상도에서 평가하고, 평가된 모든 프레임 결과의 평균을 기록합니다.
Implementation Details.
- PyTorch
- same MLP architecture as in NeRF except that we use 512 activations for the first 8 MLP layers instead of 256.
- We employ 1024-dimensional latent codes.
- In the hierarchical training we first only train on keyframes that are K = 30 frames apart.
- Adam optimizer with parameters β1 = 0.9 and β2 = 0.999.
- In the keyframe training stage, we set a learning rate of 5e−4 and train for 300K iterations.
We set the latent code learning rate to be 10× higher than for the other network parameters. The per-frame latent 0.01 codes are initialized from N (0, √D ), where D = 1024. The total training takes about a week with 8 NVIDIA V100 GPUs and a total batch size of 24576 rays.
4.2. Results
서로 다른 시퀀스에 대한 새로운 view rendering results (Fig. 1 and Fig. 4).
논문에서의 방법은 최대 10초 길이의 30FPS multi-view 비디오를 고품질로 표현할 수 있고, reconstructed model은 1K 해상도에서 거의 사실적인 continuous novel-view rendering을 가능하게 합니다.
✨ interpolated latent codes로 렌더링하면 두 개의 인접한 입력 프레임 사이의 dynamics을 부드럽고 그럴듯하게 표현할 수 있습니다.

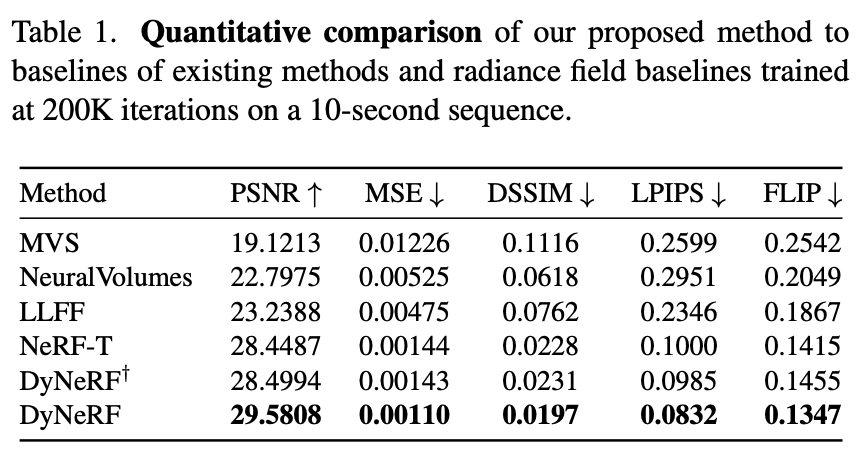
Quantitative Comparison to the Baselines.
Tab. 1 shows the quantitative comparison of our methods to the baselines using an average of single frame metrics.
Tab. 2 shows the comparison to baselines using a perceptual video metric.

→ our method is able capture and render significant more photo-realistic images, in all the quantitative measures.👍 DyNeRF model variants trained with our proposed training strategy perform significantly better in all metrics.👍
Qualitative Comparison to the Baselines.
We highlight visual comparisons of our methods to the baselines in Fig. 5 and Fig. 6. The visual results of the rendered images and FLIP error maps highlight the advantages of our approach in terms of photorealism that are not well quantified using the metrics.
In Fig. 5 we compare to the existing methods.

In Fig. 6, we compare various settings of the dynamic neural radiance fields.

Comparisons on Training Time.
Our method only requires 1.3K GPU hours for the same video, which reduces the required compute by one order of magnitude.
Results on Immersive Video Datasets.
We further demonstrates our DyNeRF model can create reasonably well 3D immersive video using non-forward-facing and spherically distorted multi-view videos with the same parameter setting and same training time.
Fig. 7 shows a few novel views rendered from our trained models.

Limitations.
(1) Highly dynamic scenes with large and fast motions are challenging to model and learn, which might lead to blur in the moving regions. As shown in Fig. 8, we observe it is particularly difficult to tackle fast motion in a complex environment, e.g. outdoors with forest structure behind.
(2) Training still takes a lot of time and compute resources. Finding ways to further decrease training time and to speed up rendering at test time are required.
(3) Viewpoint extrapolation beyond the bounds of the training views is challenging and might lead to artifacts in the rendered imagery.
(4) We discussed the importance sampling strategy and its effectiveness based on the assumption of videos observed from static cameras. We leave the study of this strategy on videos from moving cameras as future work.

5. Conclusion
- We have proposed a novel neural 3D video synthesis approach that is able to represent real-world multi-view video recordings of dynamic scenes in a compact, yet expressive representation.
- As we have demonstrated, our approach is able to represent a 10 second long multi-view recording by 18 cameras in under 28MB.
- Our model-free representation enables both high-quality view synthesis as well as motion interpolation.
- At the core of our approach is an efficient algorithm to learn dynamic latent-conditioned neural radiance fields that significantly boosts training speed, leads to fast convergence, and enables high quality results.
We see our approach as a first step forward in efficiently training dynamic neural radiance fields and hope that it will inspire follow-up work in the exciting and emerging field of neural scene representations.
