
지금까지 공부했던 내용들을 정리한 문서입니다. 참고 서적을 정리한 내용도 있지만 제가 알고 있는 지식을 기반으로 정리한 내용도 있기 때문에 틀린 부분이 있을 수 있습니다. 혹시 발견하신다면 피드백 부탁드립니다 😁
기계 학습 개요
🎯 기계 학습의 정의
기계학습(machine leraning)은 인공지능의 하위 집합으로, 데이터의 수학적 모델을 사용하는 방법으로써 학습(learning) 혹은 훈련(training)이라 불리는 과정을 통해 데이터에서 컴퓨터가 자동으로 규칙을 찾는 기법을 말한다. 기계학습은 빅데이터 분석 관점에서 보았을 때 예측적 분석(predictive analysis) 기법에 속하며, 기존의 전통적인 프로그래밍 방법과는 달리 데이터 내의 패턴을 기계 스스로 분석하여 결과를 예측할 수 있도록 한다.
 전통적인 방법과 기계학습
전통적인 방법과 기계학습
💡 기계 학습에 필요한 것들
- 기계 학습 알고리즘
- 학습 데이터(training data), 평가 데이터(test data)
- 기계 학습 모델 성능 평가 지표
기계 학습 알고리즘
1️⃣ 지도 학습 (Supervised Learning)
지도 학습은 훈련 데이터(training data)로 부터 하나의 함수를 유추하는 기계 학습 방법론이다. 훈련 데이터는 상황 혹은 특성을 나타내는 입력 데이터와 결과 혹은 정답을 나타내는 출력 데이터를 포함하고 있으며, 기계 학습 모델은 입력 데이터와 출력 데이터 사이의 규칙을 찾는 것을 목표로 학습한다. 이 방법은 결과를 예측할 수 있을 때 유용하다.
지도 학습은 회귀와 분류로 세분화 할 수 있다.
💡 회귀와 분류
- 회귀 (regression): 연속적인 값의 입력 데이터를 학습하고 예측하는 방법
- 분류 (classification): 입력 데이터를 분석하여 데이터의 특성을 잘 나타낼 수 있는 카테고리로 분류하는 방법
2️⃣ 비 지도 학습 (Unsupervised Learning)
비 지도 학습은 출력 데이터 없이 입력 데이터 만으로 학습하는 기계 학습 방법론이다. 출력 데이터가 없기 때문에 기계는 스스로 데이터의 특성을 분석하여 숨겨진 구조와 패턴을 찾는 것을 목표로 학습한다. 이 방법은 결과를 예측하지 못하는 경우에 유용한 방법이다.
비 지도 학습의 대표적인 예로 군집화(clustering)가 있다.
💡 군집화(clustering): 데이터의 특성을 분석하여 일정한 수의 군집으로 유사한 속성을 갖는 데이터끼리 묶는 방법
✅ 자기 지도 학습 (Self-supervised Learning)
자기 지도 학습은 출력 데이터(정답 값)가 없는 데이터 셋을 가지고 기계가 스스로 데이터의 특성을 찾아내어 레이블(label)을 만들고, 이를 지도 학습에 이용하는 기계 학습 방법론이다. 비지도 학습의 일종으로, 스스로 레이블을 생성하고 학습한다는 측면에서 자기 지도 학습이라고 부른다. 이러한 학습 방법으로 미루어 보아 지도 학습과 비지도 학습의 중간 형태를 가지고 있다고 볼 수 있다. 비교적 최근에 제안된 기계 학습 방법론으로, 기존에 언급되던 레이블링(labeling)의 단점(작업자의 편향된 사전 지식, 시간과 비용 소요 등)을 해결할 수 있다는 장점이 있다.
자기 지도 학습은 Contrastive 방법과 Non-Contrastive 방법으로 세분화 할 수 있다.
💡 자기 지도 학습 알고리즘
- Non-Contrastive SSL: 학습 데이터로 양성(positive) 데이터만 사용하는 방법, 오직 양성(positive) 데이터 간의 거리를 최소화 하는 방향으로 학습한다.
- Contrastive SSL: 학습 데이터로 양성(positive) 데이터와 음성(negative) 데이터를 같이 사용하는 방법, 양성 데이터 간의 거리를 최소화하고 음성 데이터 간의 거리를 최대화 하는 방향으로 학습한다.
3️⃣ 준 지도 학습 (Semi-supervised Learning)
준 지도 학습은 주로 입력 데이터에 대한 출력 데이터가 현저히 적을 때 사용되는 기계 학습 방법론이다. 출력 데이터가 있는 입력 데이터를 분석한 특징을 바탕으로 나머지 즉, 출력 데이터가 없는 데이터의 특성을 학습하고 예측하는 것을 목표로 한다.
이러한 학습 방법이 사용 되는 이유는 모든 데이터에 대해 레이블링(labeling)을 하는 작업이 쉽지 않기 때문이다. 레이블링 작업자가 질 좋은 데이터 셋을 만들기 위해서는 해당 데이터에 대한 해박한 지식을 갖추고 있어야 한다. 그러나 이러한 방법은 작업자의 편향된 사전 지식이 포함될 수 있으며, 또한 데이터가 많을 수록 작업이 어려워지는 만큼 시간과 비용이 많이 들어간다는 단점이 있다. 따라서 모든 정답 값(출력 데이터)을 알지 못하는 경우, 준 지도 학습 방법을 사용하여 결과를 향상 시킬 수 있다.
4️⃣ 강화 학습 (Reinforcement Learning)
강화 학습은 어떤 환경(environment) 안에서 정의된 에이전트(agent)가 특정 목표를 이루기 위해 일련의 행동(action)을 여러 번 수행하면서 가장 목표를 잘 달성할 수 있는 행동 규칙을 찾아가는 기계 학습 방법론이다. 여기서 목표 달성은, 주어진 조건에서 행동 선택 마지막 순간에 왔을 때 환경이 에이전트에게 주는 보상(reward)액의 합이 최대치에 도달하는 것을 의미한다. 보상은 에이전트가 시간에 따른 상태(state)를 고려하여 매 순간 선택하는 행동에 따라 결정되며, 에이전트는 정책(policy)에 따라 행동을 결정하게 된다. 즉 강화 학습은, 환경과 에이전트가 행동, 상태, 보상이라는 정보를 가지고 상호 작용하면서 특정 목표를 달성하는 학습 과정을 의미한다.
기계 학습 데이터의 구성
일반적으로 기계 학습에 사용되는 데이터 셋은 학습 데이터(train data)와 평가 데이터(test data)로 구성되어 있다. 준비된 데이터 셋에서 기계 학습 모델 훈련에는 학습 데이터를, 모델 성능 평가에는 평가 데이터를 사용한다.
기계 학습 모델 성능 평가
🎯 성능 검증 방법
인공지능 모델의 성능 평가를 위해서는 모델 훈련에 사용되지 않은 데이터, 즉 평가 데이터가 필요하다. 훈련에 사용된 데이터를 성능 평가에 사용할 경우, 이미 모델이 학습을 마친 데이터이기 때문에 예측을 잘 할 가능성이 높다. 정확한 성능 평가를 위해서는 추가적으로 데이터를 확보하는 것이 필요하다.
단순히 평가 데이터만을 가지고 모델 성능을 평가할 수 있지만, 평가 데이터 셋 구성에 따라 모델 성능이 달라질 수 있다는 단점이 존재한다. 때문에 기계 학습 모델이 다루는 문제에 대하여 학습 설정을 일반화하고 신뢰성이 높은 모델을 만들어 평가하기 위해서는 다른 검증 방법이 필요하다. 여기에는 일반적으로 교차 검증 방법이 사용된다.
교차 검증(cross validation)이란 원본 데이터 셋을 학습 데이터, 검증 데이터(validation data), 평가 데이터(test data)로 나눈 후 학습과 검증 데이터의 조합을 여러 개 두고 각 조합 별 성능 평가를 수행하여 얻은 결과를 평균한 값으로 최종 성능을 결정하는 기법이다. 검증 데이터는 평가 데이터와 다르게 학습 중 최적의 하이퍼 파라미터(hyperparameter)를 탐색하기 위해 사용되기 때문에 최종 모델 성능 평가에는 활용되지 않는다. 원본 데이터의 수가 적을 경우 학습, 검증, 평가 데이터로 나누기 어렵기 때문에(각 그룹별 데이터 수가 너무 적어지므로), 전체 데이터를 가지고 교차 검증을 수행한 결과를 최종 성능으로 사용하기도 한다.
💡 하이퍼 파라미터란?
기계학습 모델을 만들 때 개발자가 직접 설정하는 값들을 의미한다. 하이퍼 파라미터에는 학습률(learning rate), 훈련 반복 횟수(epoch) 등이 있다.
 교차 검증 예시 그림
교차 검증 예시 그림
교차 검증 방법들은 대표적으로 다음과 같다.
💡 교차 검증 방법
| 이름 | 설명 | 특징 |
|---|---|---|
| Leave-One-Out Cross Validation (LOOCV) | 전체 데이터에서 샘플 하나씩 돌아가면서 검증 데이터로 사용하고 나머지는 학습 데이터로 사용하는 방법 | 데이터가 n개 있으면 n번 실행하므로 시간이 오래 걸림 |
| K-fold Cross Validation | 전체 데이터를 k개 그룹으로 나누고 한 그룹 씩 돌아가면서 검증 데이터로 사용하고 나머지 그룹들은 학습 데이터로 사용하는 방법 | k값으로 보통 5, 10을 많이 사용함 |
| K-Holdout Cross Validation | k번 성능을 평가하되 한번 평가할 때 마다 전체 데이터에서 무작위로 학습 데이터와 검증 데이터를 만들어 사용하는 방법 | 일부 데이터가 검증 데이터에 중복 되거나 제외 될 수 있음 |
🎯 성능 평가 척도: 분류
분류 모델의 성능 평가는 혼동 행렬(confusion matrix)을 바탕으로 이루어진다. 혼동 행렬이란, 데이터에 대해서 모델이 예측한 분류 결과를 나타내는 표를 말하며, 예측 결과가 맞으면 True, 틀리면 False로 표기한다.
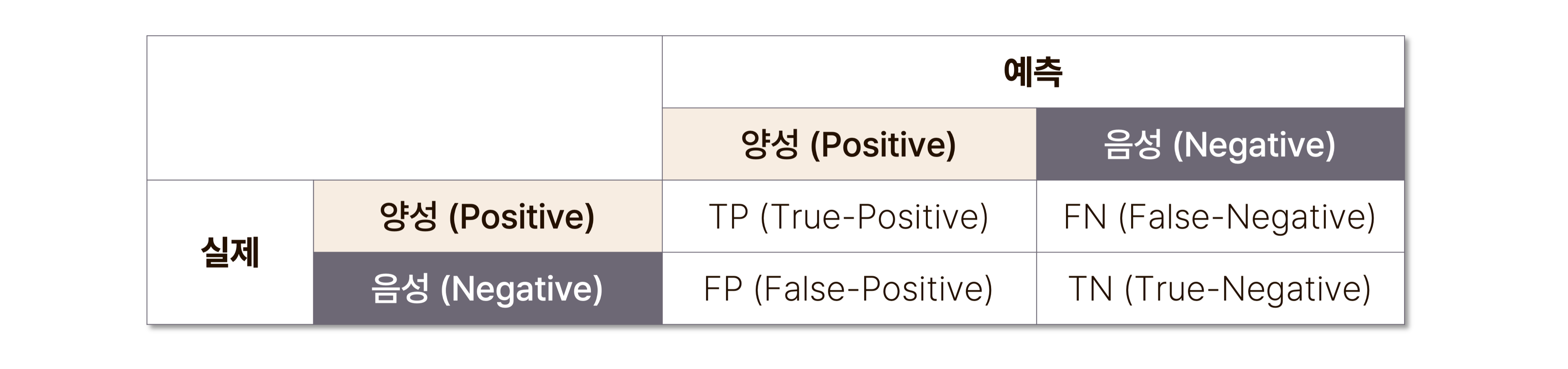
분류 모델 성능 평가 척도는 혼동 행렬의 각 조건에 해당하는 데이터의 개수를 토대로 계산 되며, 종류는 다음과 같다.
💡 분류 모델 성능 평가 척도
| 종류 | 설명 | 계산 방법 |
|---|---|---|
| 정확도 (Accuracy) | 전체 사례 중 올바르게 예측한 사례 비율 | |
| 정밀도 (Precision) | 양성이라고 예측 한 것 중 실제 양성인 데이터의 비율 | |
| 재현율 (Recall) | 실제 양성 데이터에서 모델이 양성이라고 예측한 데이터의 비율 | |
| 특이도 (Specificity) | 실제 음성 데이터에서 모델이 음성이라고 예측한 데이터의 비율 | |
| F1-Score | 정밀도와 재현율의 조화 평균 | |
| AUC (Area Under the Curve) | ROC Curve를 이용한 모델 종합 성능 척도 | ROC Curve 아래 면적 값, 1에 가까울 수록 모델이 좋은 성능을 가지고 있음을 의미 |
이상적으로는 모든 척도의 수치가 높으면 좋은 모델이지만, 척도 간의 트레이드 오프(trade-off) 관계를 고려해야 정확한 성능 평가가 가능하다. 여기서 트레이드 오프란, 서로 대립되어 균형을 이루고 있는 상태를 의미하며, 정밀도-재현율, 재현율-특이도가 트레이드 오프 관계를 형성하고 있다.
🎯 성능 평가 척도: 회귀
회귀 모델의 성능 평가는 분류 모델과는 달리 정해진 범주가 없기 때문에 예측할 수 있는 값의 범위가 넓다. 따라서 회귀 모델은 실제 값과 얼마나 유사한 값을 예측했는 지가 중요하며, 이를 평가하기 위해 예측 값과 실제 값의 오차 정도를 계산하여 성능을 평가한다.
오차 값이 작을 수록 좋은 성능을 가진 회귀 모델임을 의미한다. 종류는 다음과 같다.
💡 회귀 모델 성능 평가 척도
| 종류 | 설명 | 계산 방법 |
|---|---|---|
| MSE (Mean squared Error) | 평균 제곱 오차 | |
| RMSE (Root Mean Squared Error) | 평균 제곱근 오차 | |
| MAE (Mean Absolute Error) | 평균 절대 오차 | |
| (R squared) | 결정 계수, 0~1 사이 값을 가지며 1에 가까울 수록 실제와 유사한 값을 예측했음을 의미 |
🎯 성능 평가 시 주의 사항
기계 학습 모델 성능 평가 이후 반드시 확인해야 할 부분은 모델의 과소 적합 혹은 과잉 적합 여부이다.
💡 과소 적합과 과잉 적합
- 과소 적합 (underfitting): 데이터 특징이 전혀 학습되지 않아 학습 데이터 셋에 대하여 처음부터 모델이 제대로 작동하지 않는 현상
- 과잉 적합 (overfitting): 모델이 학습 데이터에 특화 되어 해당 데이터에 대해서는 굉장히 잘 작동하지만 새로운 데이터에 대해서는 잘 작동하지 않는 현상
 과소, 과잉 적합 예시 그림
과소, 과잉 적합 예시 그림
보통 과소 적합이 되었을 시 테스트 데이터 셋에서도 잘 작동하지 않기 때문에 문제를 발견하기 쉽지만, 과잉 적합의 경우 모델 성능이 높게 나오기 때문에 새로운 데이터로 평가 해보기 전까지는 문제를 파악하기 어려울 수 있다. 따라서 모델 성능을 분석할 때는 성능의 좋고 나쁨을 떠나 모델이 제대로 만들어졌는지 확인할 필요가 있다.
References
오다카 토모히로,『기초부터 배우는 인공지능』, 성안당(2021).고민삼,『Machine Learing』, 강의 교안.Self-supervised learning, Wikipedia(2022)Yuandong Tian, "Demystifying a key self-supervised learning technique: Non-contrastive learning", Meta AI, 2021.07.07
, https://ai.facebook.com/blog/demystifying-a-key-self-supervised-learning-technique-non-contrastive-learning/