이번에는 머신러닝을 배웠다
강사님은 이장래 강사님이셨다! 정말 재밌고, 쉽게 말씀해주셔서 이해가 정말 잘됐다
이번에 배운것을 정리해보고자 한다.
1. 결측치 확인 및 제거
#결측치 확인 방법
titanic.isna().sum()
#행 제거
titanic.dropna(axis=0,inplace=True)
#열 제거
titanic.dropna(axis=1,inplace=True)
#특정값으로 채우기
##평균값으로 구하기
mean=titanic['Age'].mean()
##NaN을 평균값으로 채우기
titanic['Age'].fillna(mean,inplace=True)
#앞뒤 값으로 채우기
air['Ozone'].fillna(method='ffill',inplace=True)
air['Ozone'].fillna(method='bfill',inplace=True)
#선형 보간법으로 채우기
air['Ozone'].interploate(method='linear',inplace=True)-
결측치 확인 방법 : data.isna().sum()
-
평균값으로 채우기 : 평균값 먼저 구하고 data.fillna(평균값 변수,inplac=True)
-
앞뒤 값으로 채우기
- 이 방법은 시계열 데이터에 자주 사용됨
- data['변수이름'].fillna(method='ffill',inplace=True)
- data['변수이름'].fillna(method='bfill',inplace=True)
-
선형 보간법으로 채우기
- data['변수이름'].interploate(method='linear',inplace=True)
2. 가변수화
#가변수하고 싶은 칼럼들 리스트로 선언
dumm_cols=['변수1','변수2','변수3']
x=pd.get_dummies(data,columns=dumm_cols,drop_first=True,dtype=int)- pd.get_dummies()
3. 데이터 분리하기
#타겟값 설정
target='변수명'
x=data.drop(columns=target,inplace=True)
y=data.loc[:,target]- x변수 : data.drop(colums=target,inplace=True)
- y변수 : data.loc[:,target]
4. 상관관계 확인
data.corr(numeric_only=True).style.background_gradient()- 상관관계의 경우 수치형 데이터만 되기 때문에
- data.corr(numeric_only=True)
5. 머신러닝
-
지도학습
-학습대상이 되는 데이터에 정답을 주어 규칙성 즉, 패턴을 배우게 하는 학습 방법 -
비지도 학습
- 정답은 없으나, 데이터만으로 학습
-
강화학습
- 선택한 결과에 대해 보상을 받아 행동 개선을 하면서 배우는 방법
-
데이터 분리
- 학습용
- 검증용(validation)
- 훈련용
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=1)- 과대적합
- 학습데이터만 잘 맞는 모델
- 과소적합
- 모델이 너무 단순하여 학습데이터가 적절하게 학습되지 않음
model=사용하고 싶은 모델 선언()
#모델 훈련
model.fit(x_train,y_train)
#예측값
y_pred=model.predict(x_test)5.1 회귀모델
-
값을 예측
-
정확한 값을 예측하기 어렵기 떄문에 실제값과 예측값의 차이를 확인
-
오차를 하나의 값으로 나타낼때 모델에 대해 설명하기 쉬움
- SSE : 오차 제곱의 합
- MSE: 오차 제곱의 합의 평균
- RMSE : MSE의 오차값
- MAE : 오차 절대값 합의 평균
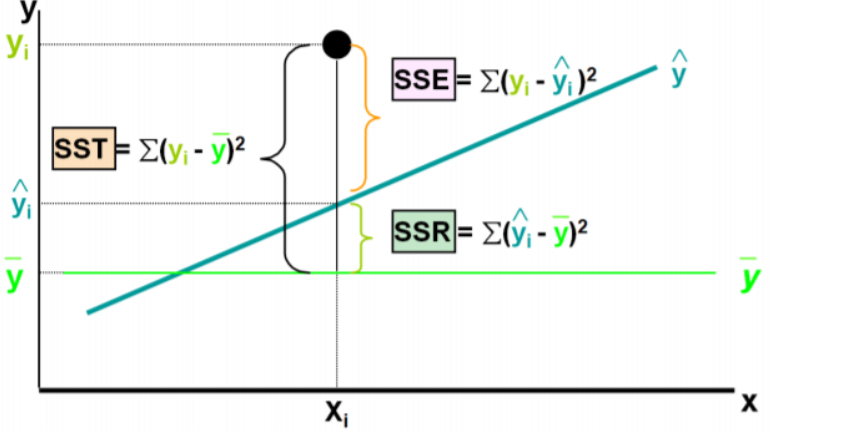
- SST : 전체 오차
- SSR : 회귀식이 잡아낸 오차
- SSA : 회귀식이 잡아내지 못한 오차
SST=SSR+SSA
- 결정 계수
- MSE로 설명하기엔 한계가 있음
- 모델 성능을 잘 해석하게 만든 것이 MSE의 표준화된 결정계수
- 전체 오차 중에서 회귀식이 잡아낸 오차 비율
- R^2 = SSE/SST=1-SSE/SST
- 모델이 설명을 얼마나 잘했는지 나타냄MSE,RMSE,MPE -> 작을수록 좋음
R2 Score -> 클수록 좋음
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_absolute_percentage
from sklearn.metrics import mean_squared_error
from sklearn.metrics import root_mean_squared_error
from sklearn.metrics import r2_score
print(mean_absolute_error(y_test,y_pred))
print(r2_score(y_test,y_pred))
최선의 회귀모델 -> 전체 데이터의 오차합이 최소
결국 오차값이 최소가 되는 가중치(기울기), 편향(y절편) 찾기
- .coef,intercept
5.1.1 단순회귀
- x값 하나로 y 설명
- y=w0+w1x1(최선의 w0,w1)
5.1.2 다중회귀
- .여러 독립 변수가 종속 변수에 영향
- 각 독립변수의 최적의 가중치와 편향 찾기
- 독립 변수가 여러개이기 때문에 독립변수이름과 같이 출력
5.2 분류모델
- 주어진 데이터 분류
- 예측값과 실제값이 같을수록 좋은 모델
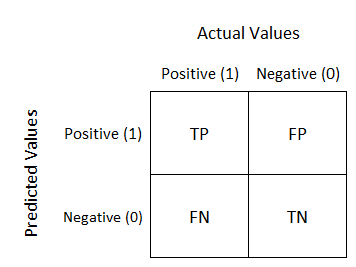
- TN : 진짜 음성
- TP : 진짜 양성
- FN : 원래 양성인데 음성으로 판단
- FP : 원래 음성인데 양성으로 판단
FN의 경우가 손실비용이 더 크다
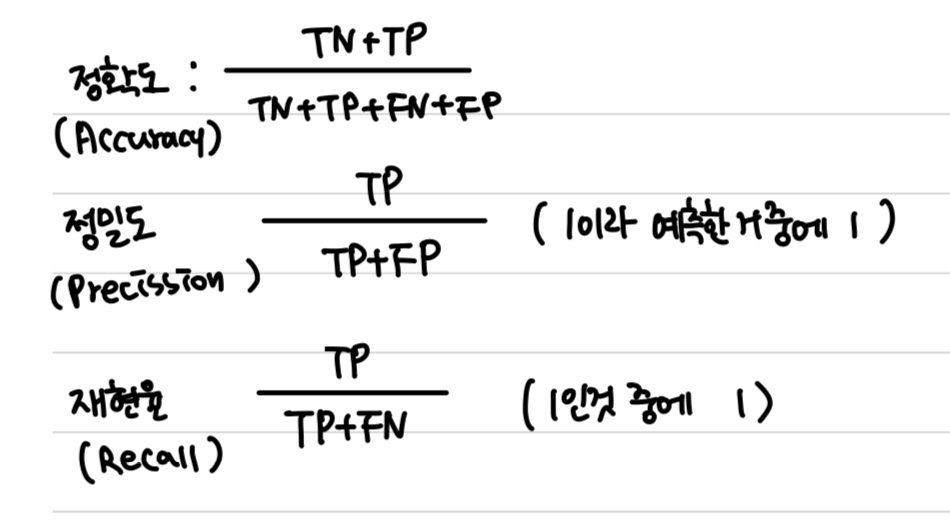
- F1-Score
- 정밀도와 재현율의 평균
- 관점이 다를때 큰 의미를 가짐
- 정밀도와 재현율이 적절히 요구될때 사용
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
5.4 KNN
- K-Nearest Neighbor : 가장 가까운 이웃 k개
- K개의 인접 이웃값들을 찾아 그 값들로 새로운 값 예측
- 회귀와,분류 모두 사용
K개의 값에 따라 다르게 예측할 수 있기 때문에 최적의 K값을 찾는 것이 중요하다
- 일반적으로 K는 홀수다
- 과반수 이상의 이웃이 나오지 않는 경우가 있을수도 있기 떄문에
- 1이면 너무 편향되어 있음
- Scaling이 필요
- 정규화 : 각 변수가 0과 1 사이
- 표준화 : 각 변수가 평균 0, 표준편차 1
from sklearn.preprocessing import MinMaxScaler
from sklearn.negihbors import KNeighborsRegressor
from sklearn.metrics import mean_absoulte_error,r2_score
#데이터 스케일링
scaler=MinMaxScaler
x_train_s=x_train.fit_scaler(x_train)
x_test_s=scaler.transform(x_test)
#선언
model=KNeighborsRegressor
#학습
model.fit(x_train_s,y_train)
#예측
y_pred=model.predict(x_test)
#평가
print(mean_absolute_error(y_test,y_pred))
print(r2_score(y_test,y_pred))
#예측값,실젯값 시각화
plt.plot(y_test.values,label='Actual')
plt.plot(y_pred,label='Predicted')
plt.legend()
plt.ylabel()
plt.show5.5 DecisionTree
-
분류, 회귀에 모두 가능
-
스케일링 등 전처리 필요 x
-
분석 과정이 직관적, 이해하기 쉬움(설명하기 쉬움)
-
의미있는 질문하기가 중요
-
과적합되기가 쉽기 때문에 가지치기가 장요
-
분류
- 마지막 노드 = 최빈값 반환
-
회귀
- 샘플들의 평균
불순도(impurity)
-
순도가 높을수록 분류가 잘 된것
-
DT는 불순도가 낮은 속성으로 결정됨
-
지니 불순도 : 1-(양성클래스^2-음성클래스^2)
- 분류가 얼마나 잘됐는지 평가지표 (얼마나 순도가 증가했는지, 불순도가 감소했는지)
-
특징
- 지니 불순도가 낮으수록 순도가 높음
- 지니 불순도 0~0.5 사이의 값 (이진분류)
- 0인 경우: 순수
- 0.5인 경우 : 완벽하게 섞임
-
엔프로피 : -음성비율log2(음성비율)-양성비율log2(양성비율)
- 0~1 사이 값
- 0 : 순수하게 분류
- 1: 완벽하게 섞임
- 단지 속성의 불순도를 표현
- 0~1 사이 값
-
정보 이득
- 어떤 속성이 얼마나 많은 정보를 제공하는가
- 정보이득이 크다=어떤 속성으로 분할할때 불순도가 줄어든다
하이퍼파리미터
- max_depth : 깊이
- min_samples_split: 노드 분할하기 위한 최소 샘플 수 (디폴트 값 2)
- min_samples_leaf: 최소한의 노드(디폴트 값 1)
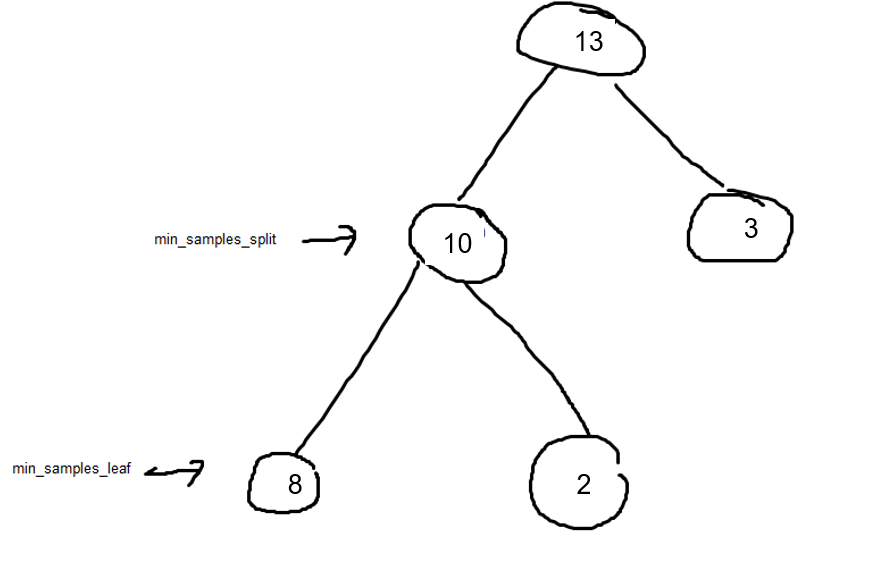
중요도
- 트리 구성에 중요한 역할을 한 변수
#라이브러리 임포트
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix,classification_report
#모델선언
model=DecisionTreeClassifier()
#모델학습
model.fit(x_train,y_train)
#예측값 구하기
y_pred=model.predict(x_test)
#성능
print(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))
# 시각화 모듈 불러오기
from sklearn.tree import export_graphviz
from IPython.display import Image
# 이미지 파일 만들기
export_graphviz(model, # 모델 이름
out_file='tree.dot', # 파일 이름
feature_names=x.columns, # Feature 이름
class_names=['die', 'survived'], # Target Class 이름
rounded=True, # 둥근 테두리
precision=2, # 불순도 소숫점 자리수
filled=True,max_depth=3) # 박스 내부 채우기#시각화할 깊이
# 파일 변환
!dot tree.dot -Tpng -otree.png -Gdpi=300
# 이미지 파일 표시
Image(filename='tree.png')
#중요도 시각화
# 데이터프레임 만들기
df = pd.DataFrame()
df['feature'] = list(x)
df['importance'] = model.feature_importances_
df.sort_values(by='importance', ascending=True, inplace=True)
# 시각화
plt.figure(figsize=(5, 5))
plt.barh(df['feature'], df['importance'])
plt.show()5.6 로지스틱 회귀
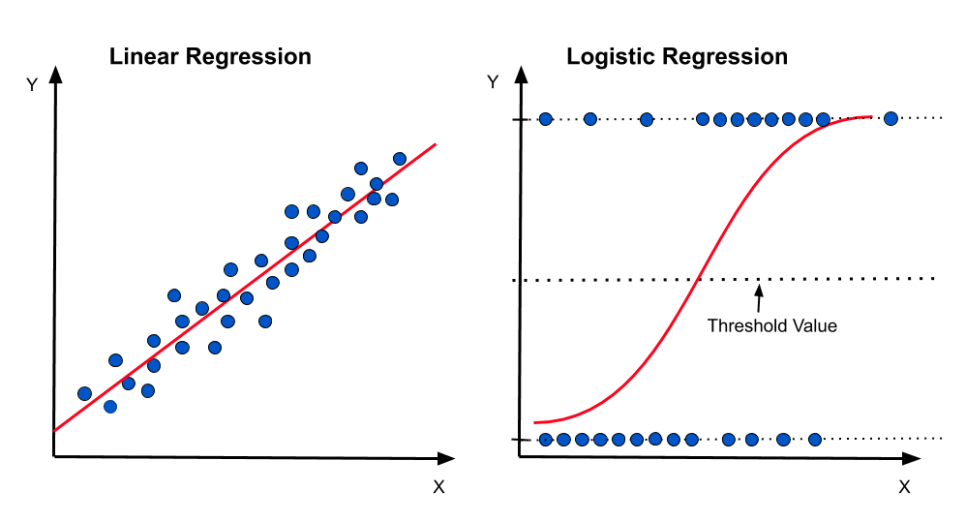
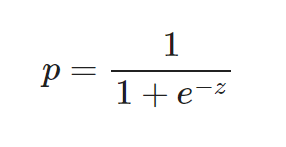
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report,confusion_matrix
model=LogisticRegression()
model.fit(x_train,y_train)
y_pred=model.predict(x_test)
# 5단계: 평가하기
print(classification_report(y_test,y_pred))
print(confusion_matrix(y_test,y_pred))
5.7 K-Fold Cross Validation
- Random Split
- 일반화 성능 즉, 새로운 데이터에 대한 모델의 성능을 제대로 예측할 수 없기 때문에 수행하기 어려움
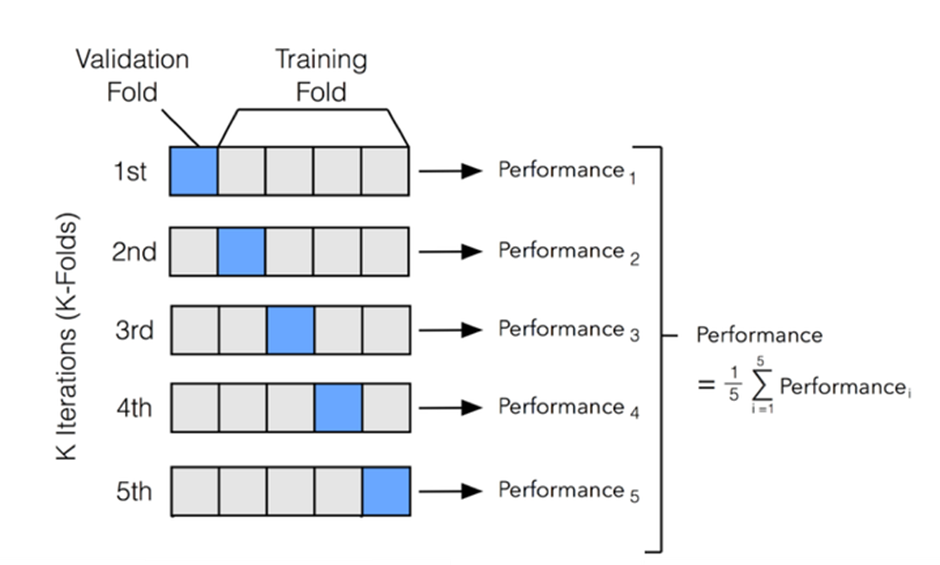
- 일반화 성능 즉, 새로운 데이터에 대한 모델의 성능을 제대로 예측할 수 없기 때문에 수행하기 어려움
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
#선언하기
model=DecisionTreeClassifier(max_depth=5,random_state=1)
#검증하기
cv_score=cross_val_score(model,x_train,y_train,cv=10)
print(cv_score.mean())#정확도
print(cv_score.std())# 표준편차
5.8 하이퍼파라미터
- 튜닝은 방법에 있어서 정답이 없다
5.8.1 GridSearch
from sklearn.model_selection import GridSearchCV
# 파라미터 선언
# max_depth: range(1, 51)
param={'max_depth':range(1,51)}
# Grid Search 선언
# cv=5
# scoring='accuracy'
model = GridSearchCV(DecisionTreeRegressor(), #기본 모델
param,#파라미터 범위
cv=5, #k 분활개수
scoring='accuracy' #평가지표
)5.8.2 Random Search
from sklearn.model_selection import RandomSearchCV
# 파라미터 선언
# max_depth: range(1, 51)
param={'max_depth':range(1,51)}
# Grid Search 선언
# cv=5
# scoring='accuracy'
model = RandomSearchCV(DecisionTreeRegressor(), #기본 모델
param,#파라미터 범위
cv=5, #k 분활개수
scoring='accuracy' #평가지표
)
5.9 Ensemble (앙상블)
- 약한 모델을 올바르게 결합하면 더 정확한 견고한 모델!
- 배깅
- 보팅
- 부스팅
- 스태킹
5.9.1 Voting(보팅)
- 예측 결과를 투표를 통해 최종 예측값 결정
- 하드 : 다수 모델이 예측한 결과값
- 소프트 : 결정 확률 평균 -> 가장 확률 높은거
5.9.2 Bagging(배깅)
- 같은 유형의 알고리즘 기반 모델 사용 -> 부트스트랩 한 데이터로 모델 학습
- 복원 추출(중복o)
- 범주형 : 투표
- 연속형 : 평균
- Random Forest
- 여러 DecisionTree들이 Bagging하여 데이터 샘플링
- 모델들이 개별적으로 학습하여 모들 결과 집계해 최종결정
- 랜덤하게 데이터 생성
- 랜덤하게 feature 선정
- 무작위로 뽑은 n개의 feature들 중에 가장 정보이득이 큰 기준으로 트리분할(모델마다 다른 구조의 트리 구성)
5.9.3 Boosting(부스팅)
- 같은 유형의 모델에 대해 순차적으로 학습 수행
- 이전의 모델과 달리 예측하지 못한 데이터에 대해 가중치 부여하여 다음 모델이 학습 및 예측 진행
- 성능은 좋지만 과적합
- 대표 알고리즘 : LightGBM,XGBoost
5.9.4 Stacking(스태킹)
- 여러 모델의 예측값을 최종 모델의 학습 데이터로 사용 예측
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor6. 모델링 방법
- 데이터 파악
- 데이터 분리
- 데이터 찢기
- 여러 모델 import
- 여러 모델로 평가(cv_score.mean())
- 그 중에 가장 성능이 좋은 것을 선택해서 하이퍼파라미터 튜닝
- 최적 파라미터, 예측 최고 성능 print
print('최적 파라미터:',model.best_params_)
print('최고 성능:',model.best_score_)
- 변수 중요도 시각화
# 변수 중요도 시각화
plt.figure(figsize=(5,5))
plt.barh(list(x),width=model.best_estimator_.feature_importances_)
plt.show()- 성능 평가
7. 추가 - 타겟 변수 불균형 맞추기
- Under Sampling
- 다수 클래스의 데이터를 줄여 데이터셋을 균형있게 만드는 방법
- 데이터셋의 크기를 줄여 학습 속도를 높일 수 있지만, 중요한 정보를 포함하고 있는 데이터를 제거할 위험이 있다는 단점이 있음
# 불러오기
from imblearn.under_sampling import RandomUnderSampler
# Under Sampling
under_sample = RandomUnderSampler()
u_x_train, u_y_train = under_sample.fit_resample(x_train, y_train)
# 확인
print('전:', np.bincount(y_train))
print('후:', np.bincount(u_y_train))
- Over Sampling
- 소수 클래스의 데이터를 인위적으로 늘려 클래스 간의 균형을 맞추는 방법
- 소수 클래스에 더 많은 가중치를 주거나 데이터를 복제하여 클래스의 비율을 균등하게 맞춤
- 무작위로 데이터를 복제하는 방식은 오히려 모델이 과적합될 위험이 있음
- 주요 방법은 SMOTE
- 단순히 소수 클래스 데이터를 복제하는 대신, 소수 클래스의 데이터 포인트들 사이에서 새로운 데이터를 합성하여 생성
- 이를 통해 단순 복제로 인한 과적합 문제를 어느 정도 해결할 수 있음
# 불러오기
from imblearn.over_sampling import SMOTE
# Over Sampling
smote = SMOTE()
s_x_train, s_y_train = smote.fit_resample(x_train, y_train)
# 확인
print('전:', np.bincount(y_train))
print('후:', np.bincount(s_y_train))
- Class Weight
- 클래스에 부여하는 가중치를 다르게 설정하여 학습 성능을 향상시키는 방법
- 가중치 부여로 인해 학습 시간이 늘어날 수 있으며, 과도한 가중치 설정은 모델이 특정 클래스에 너무 집중하게 되어 다른 클래스의 성능이 떨어질 수 있음
# 선언하기
model = RandomForestClassifier(max_depth=5, random_state=1, class_weight='balanced')
8. 느낀 점
학교에서 배운 내용이 많았기 때문에 복습하자는 차원에서 들었는데 오히려 새롭게 알게된 내용이 많아서 당황했다. 내가 지금까지 대충 알고 있었구나라는 생각도 들었다. 아직 부족한 점이 많지만 너무 유익한 시간이었다.
내일 미니프로젝트를 진행하는데 팀원분들에게 많은 도움이 되고 싶다
머신러닝은 하면 할수록 재밌는 기분이다!
더 깊숙히 배우고 싶다!!!
